

概述
这一章的核心是:
系统可能崩溃、事务可能失败、磁盘也可能损坏。Recovery System 的任务是在这些失败之后,仍然保证事务的 atomicity 和 durability,并把数据库恢复到一致状态。
恢复系统围绕一条主线展开:
- 失败前:记录足够的信息,尤其是 log
- 失败后:根据 log 执行 redo 和 undo
- 为了效率:使用 checkpoint、log buffering、group commit、fuzzy checkpoint
- 为了高可用:使用 remote backup systems
- 为了高并发:支持 early lock release 和 logical undo
- 工业级算法:ARIES
这一章最重要的思想是:
先把“怎么恢复”写进稳定存储,再允许真正修改数据库。
这就是 Write-Ahead Logging(WAL) 的直觉。
目录
- 概述
- 目录
- Failure Classification
- Storage Structure
- Recovery and Atomicity
- Log-Based Recovery
- Recovery Algorithm
- Buffer Management
- Failure with Loss of Nonvolatile Storage
- Remote Backup Systems
- Early Lock Release and Logical Undo
- ARIES
- Recovery in Main-Memory Databases
- Shadow Copying 与 Shadow Paging
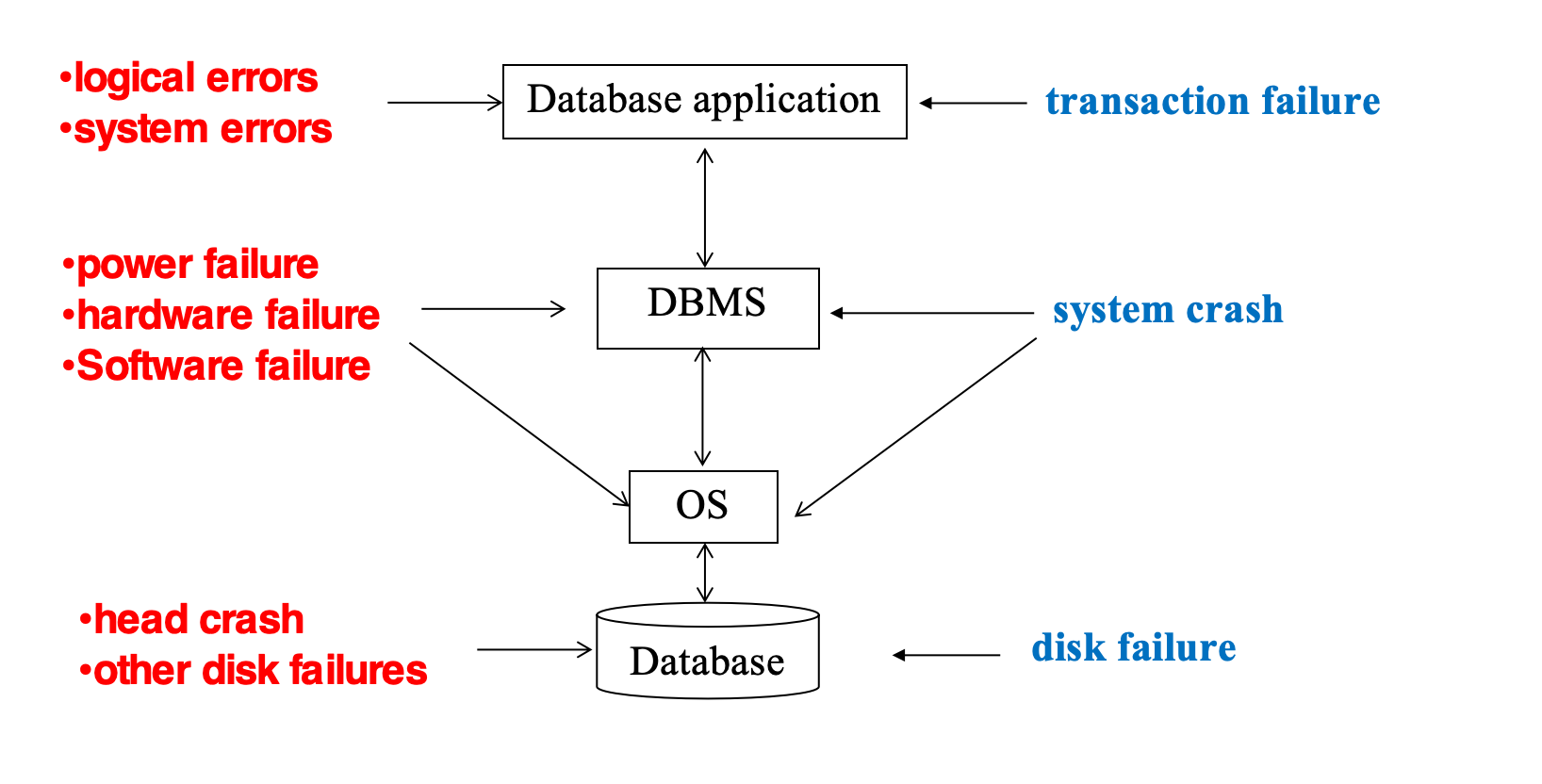
Failure Classification
数据库系统需要处理三类失败:
- Transaction failure
- System crash
- Disk failure
这三类失败对应的恢复尺度不同:
- transaction failure:只处理单个事务,其他事务可以继续执行
- system crash:整个 DBMS / OS / 机器掉电,需要重启后统一恢复
- disk failure:数据库或日志所在介质本身损坏,需要备份、dump 或远程备份参与恢复
Transaction failure
事务失败分两种:
- Logical errors:事务因为自身内部条件不能继续执行
- 例如输入错误、数据不存在、溢出、资源限制等
- 违反完整性约束,例如插入重复主键、违反外键约束
- System errors:数据库系统因为某种错误条件终止一个活跃事务
- 典型例子:deadlock
- 事务被选为 deadlock victim 时,会被系统强制 rollback
这类失败通常只影响某个事务。恢复动作是 abort / rollback 该事务。
关键问题是:事务没有执行到 commit,但已经做了部分更新。根据 atomicity,这些部分更新必须全部撤销。撤销的依据就是 log 中记录的 old value。
System crash
系统崩溃指 power failure、hardware failure、software failure 等导致系统停止运行。
采用 fail-stop assumption:
系统崩溃会丢失 volatile storage 中的内容,但不会破坏 nonvolatile storage 中已经写好的内容。
这个假设依赖数据库系统和硬件层的大量完整性检查。
可以把 system crash 想象成“突然掉电”:正在并发执行的事务中,有些还没完成,需要 undo;有些已经提交,但修改的数据可能还停留在 buffer,没有真正写到磁盘,需要 redo。因此系统重启后必须先进入 recovery 过程,不能直接对外服务。
Disk failure
磁盘失败指 head crash 或类似故障破坏磁盘上的全部或部分数据。
特点:
- 非易失存储内容也可能丢失
- 假设破坏是可检测的
- 磁盘通常用 checksum 检测坏块或不完整写入
磁盘失败的朴素恢复思路是:先恢复最近一次 backup / dump,再把 backup 之后已经提交事务的日志重新做一遍。这个过程能恢复正确性,但会带来不可用时间,因此银行等关键系统通常还会配置 remote backup / hot-spare,实现异地热切换。
Storage Structure
恢复系统必须先区分不同存储层的可靠性。
Volatile / Nonvolatile / Stable Storage
Volatile storage
Volatile storage 在系统崩溃后不能保存内容。
例子:
- main memory
- cache memory
Nonvolatile storage
Nonvolatile storage 在系统崩溃后通常能保存内容。
例子:
- disk
- tape
- flash memory
- non-volatile / battery-backed RAM
但 nonvolatile storage 仍然可能因为磁盘损坏、介质损坏等原因丢失数据。
Stable storage
Stable storage 是一种理想化存储:
无论发生什么失败,内容都不会丢失。
现实中没有真正的 stable storage,只能通过多个非易失介质上的多副本近似实现。
这里有一个递归问题:数据库修改靠 log 恢复,但 log 本身也要存储。如果 log 所在磁盘损坏,恢复依据也会丢失。因此理论上假设 log 放在 stable storage 上,工程上用多副本、RAID、远程副本近似实现。
Stable Storage 的近似实现
基本方法:
- 每个 logical block 维护多个 physical copies
- 多个副本放在不同磁盘上
- 也可以放在 remote sites,防火灾、洪水等灾难
- 副本数量越多,单个磁盘或单个机房故障导致全部副本丢失的概率越低
- 副本最好放在独立故障域中:不同磁盘、不同机器、不同机房,甚至异地
一次 block transfer 可能有三种结果:
- Successful completion:写入成功完成
- Partial failure:写到一半失败,目标块内容错误
- Total failure:还没真正更新目标块就失败,目标块保持旧值
假设每个 block 有两个副本,output 操作可以这样执行:
1. 先写第一个 physical block2. 第一个副本写成功后,再写第二个 physical block3. 第二个副本写成功后,才认为 output 完成恢复时:
- 如果某个副本 checksum 错误,用另一个副本覆盖它
- 如果两个副本都没有 checksum 错误,但内容不同,用第一个副本覆盖第二个副本
- 为了避免恢复时比较所有块,可以在 nonvolatile RAM 或磁盘特殊区域记录正在写的块,只检查这些可能不一致的块
Data Access
数据库永久存放在磁盘上,运行时只把部分 block 放入内存。
两类 block:
- Physical block:磁盘上的 block
- Buffer block:主存 buffer 中的 block
磁盘和内存之间的数据移动由两个操作完成:
input(B) : 把磁盘上的 physical block B 读入主存output(B) : 把主存中的 buffer block B 写回磁盘为了简化讨论,本章假设每个 data item 都完整存放在一个 block 内。
注意 input / output 是磁盘块和内存 buffer 之间的移动;事务内部的 read / write 是 buffer 和事务私有工作区之间的数据移动。恢复系统关心这两个层次的错位:一个事务可能已经 write(X) 修改了 buffer,但包含 X 的 block 还没有 output 到磁盘。
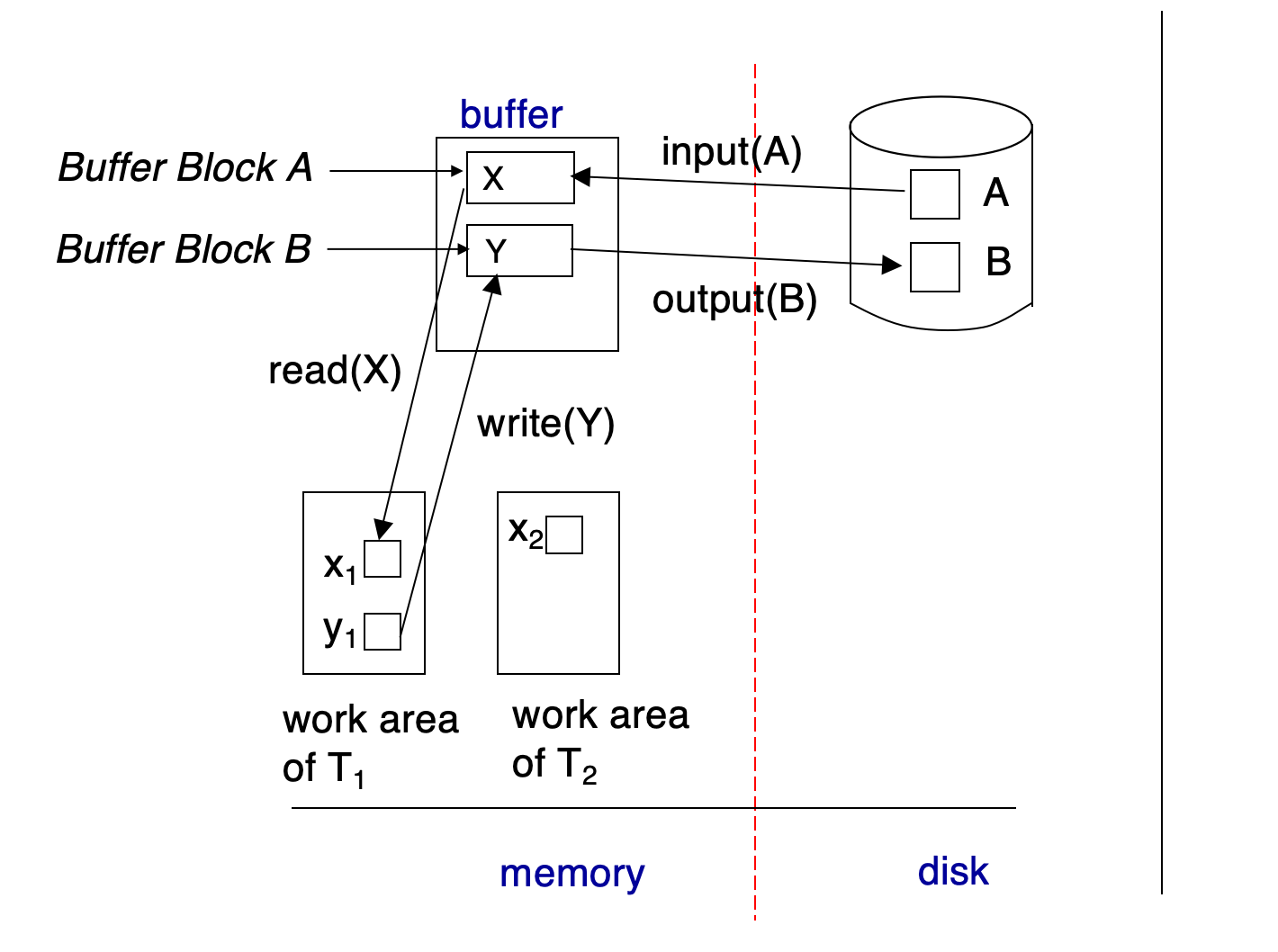
Transaction 的 private work-area
每个事务 Ti 有自己的私有工作区,保存它访问和更新的数据项的本地副本。
Ti对数据项X的本地副本记作xiread(X):把 buffer block 中的X读入本地变量xiwrite(X):把本地变量xi写回 buffer block 中的X
注意:
write(X)只是把值写到内存 buffer,不一定马上执行output(BX)写回磁盘。
这句话是后面 redo / undo 的根源:
- 已提交事务的更新可能只在 buffer 里,crash 后丢失,所以要 redo
- 未提交事务的更新可能已经 output 到磁盘,所以要 undo
- commit 和 data page 写盘没有一一对应关系,真正的边界由 log 决定
事务规则:
- 第一次访问
X前,必须执行read(X) - 后续可以直接访问本地副本
xi write(X)可以在事务 commit 前任意时刻执行
Recovery and Atomicity
恢复算法的目标:
即使发生失败,也要保证数据库一致性、事务原子性和持久性。
恢复算法分两部分:
- 正常执行时的动作:记录足够信息,让未来可以恢复
- 失败后的动作:根据记录恢复数据库内容
本章默认:
- 并发控制使用 strict 2PL,所以没有 dirty read
- 恢复算法应尽量具备 idempotence(幂等性)
- strict 2PL 的意义是避免 dirty read,使一个未提交事务的脏数据不会被其他事务继续依赖
幂等性指:
一个恢复动作执行多次,结果和执行一次相同。
这点很重要,因为恢复过程中也可能再次崩溃。恢复算法必须允许重复执行。
Log-Based Recovery
Log Records
为了保证失败后的原子性,在真正修改数据库前,系统先把修改信息写到 stable storage 中的 log。
Log 是一串 log records,用来记录数据库的更新活动。
常见 log record:
<Ti start> 事务 Ti 开始<Ti, X, V1, V2> Ti 把 X 从旧值 V1 改为新值 V2<Ti commit> Ti 提交<Ti abort> Ti 回滚完成其中:
V1:old value,用于 undoV2:new value,用于 redo
更新日志必须在对应数据库修改前写出。
日志通常是顺序追加的流水账文件。相比在磁盘上到处随机修改 data page,顺序写 log 的 I/O 代价更低,所以数据库愿意先把每次更新记入 log,再择机把脏页刷回磁盘。
Ti 是事务的唯一标识。实际系统中还会维护每个事务自己的日志链,例如每条日志记录指向同一事务的前一条日志记录,这样 rollback 时不需要从整个 log 末尾逐条搜索该事务的记录。
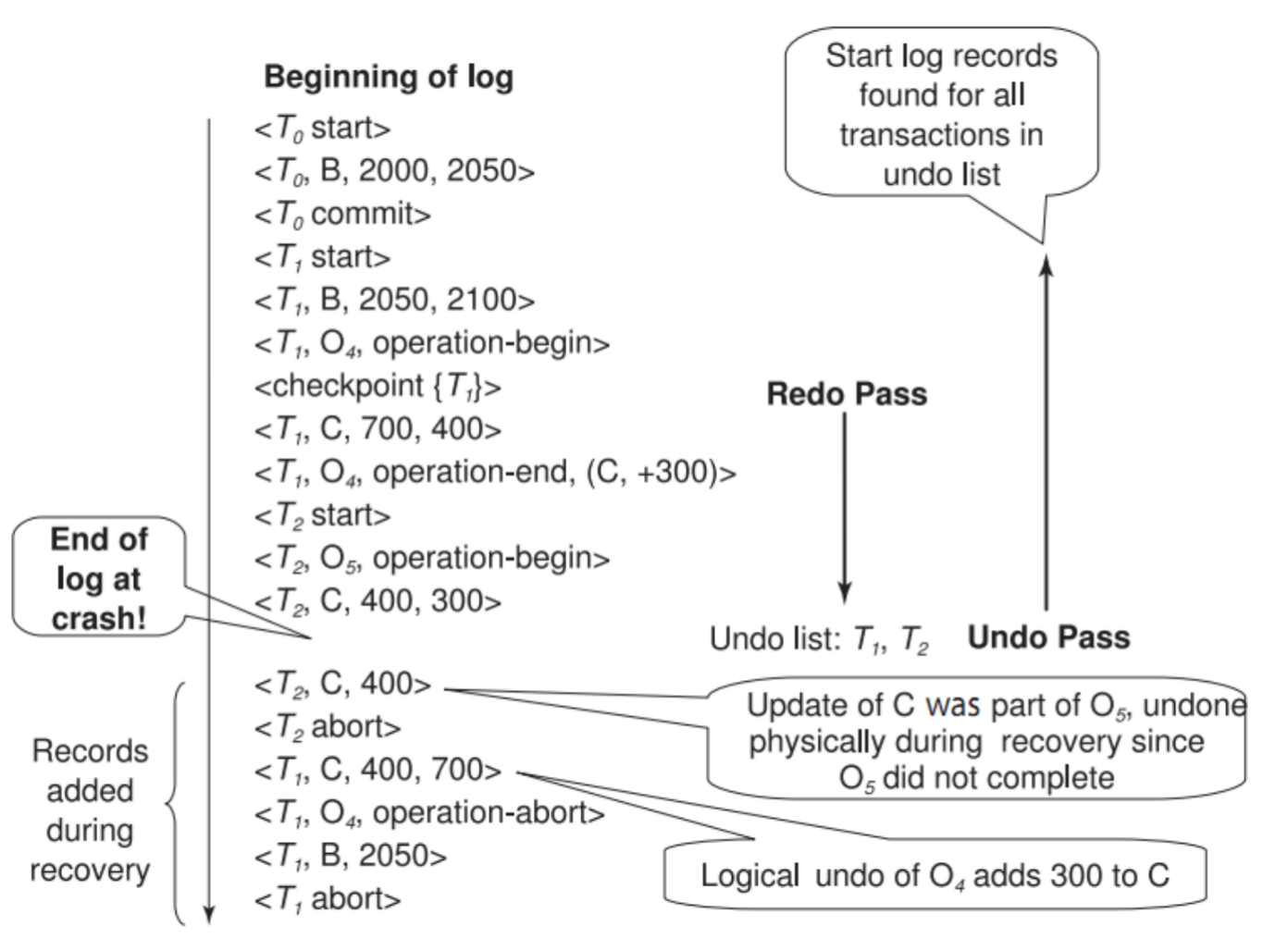
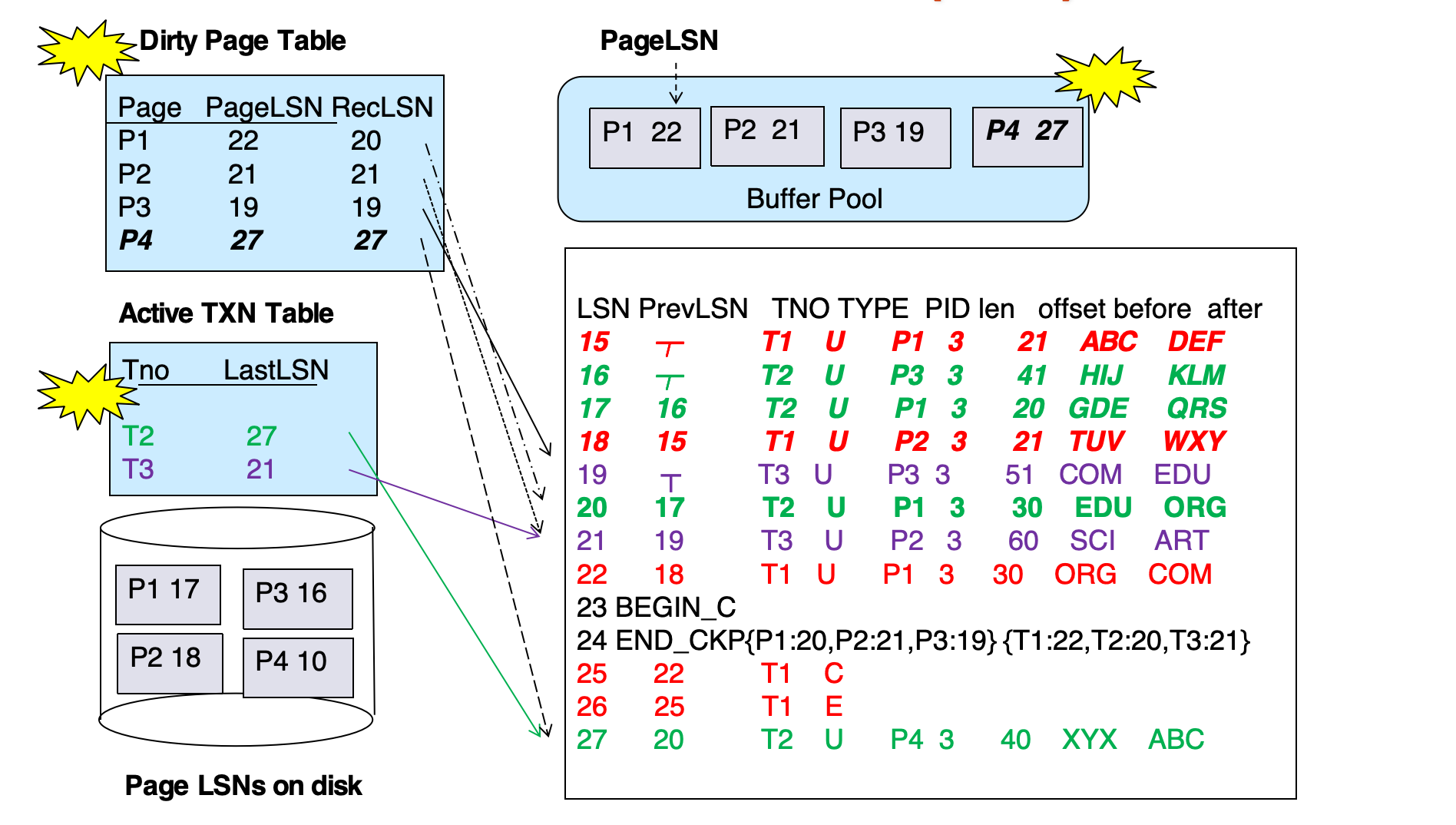
log 例子:

解释:
T1、T3已 commitT2在正常执行过程中 rollback,产生补偿日志<T2, C, 500>、<T2, B, 300>,最后<T2 abort>T4在 recovery 中被 undo,产生<T4, A, 100>,最后<T4 abort>
这体现了 redo pass repeats history,然后 undo pass 撤销未完成事务。

WAL
Write-Ahead Logging(WAL,先写日志原则):
在内存中的数据块被写回数据库前,与该数据块有关的 log records 必须先写到 stable storage。
更直观地说:
先写 log,再写 database page原因:
- 如果数据库页已经写入磁盘,但 log 没写入,崩溃后无法 undo
- 如果 log 已经写入,但数据库页没写入,崩溃后可以 redo
WAL 是 log-based recovery 的核心约束。
WAL 可以分成两个约束理解:
- data page 写盘前:该 page 相关的所有 update log 必须已经写到 stable storage
- commit log 写盘前:该事务之前的所有 log records 必须已经写到 stable storage
因此,事务是否已经提交的唯一可靠标志是:<Ti commit> 已经进入 stable storage。commit log 只停在 log buffer 里时,系统 crash 后只能把它当成未提交事务处理。
Concurrency Control and Recovery
并发事务共享:
- 一个 disk buffer
- 一个 log file
恢复算法通常要求:
如果事务
Ti修改了某个 item,则在Ticommit 或 abort 前,其他事务不能修改同一个 item。
否则会出现问题:
T1 updates AT2 updates A and commitsT1 aborts如果此时用 T1 的 old value 恢复 A,会把 T2 的已提交更新也覆盖掉。
解决方法:
- 对更新的数据项加 exclusive lock
- 持有到事务结束
- 也就是 strict 2PL
后面讲的 logical undo 可以放宽这个要求,支持 early lock release。
Immediate Modification 与 Deferred Modification
Immediate-modification scheme
Immediate modification 允许未提交事务的更新先进入 buffer,甚至写到磁盘。
特点:
- 更新 log record 必须先写出
- 修改后的 block 可以在 commit 前或 commit 后写到 stable storage
- block 写出顺序可以和事务更新顺序不同
这要求恢复算法同时支持:
- 对已提交事务 redo
- 对未提交事务 undo
Deferred-modification scheme
Deferred modification 把真正的数据库更新推迟到事务 commit 时执行。
优点:
- 恢复逻辑更简单
- 未提交事务不会污染数据库
缺点:
- 需要保存事务本地更新副本
- 事务读自己已经更新的数据时,需要从本地副本读
- 大事务会产生较大额外开销
本章主要围绕 immediate modification 展开。
Transaction Commit
事务进入 commit 状态的判定标准:
当
<Ti commit>log record 被写到 stable storage 后,事务Ti才算真正 committed。
同时要求:
Ti的所有先前 log records 已经写到 stable storageTi修改过的数据页可以仍在 buffer 中,之后再写到磁盘
也就是说:
commit 只要求 commit log 稳定落盘不要求所有 data pages 立刻落盘这正是 no-force policy 的基础。
事务 commit 不等于数据页都写盘事务 commit 只要求 commit log 及其之前日志稳定落盘这也是 group commit 能成立的原因:多个事务的 commit log 可以在同一个 log block 中一起刷出,刷出后这些事务一起变成 committed。
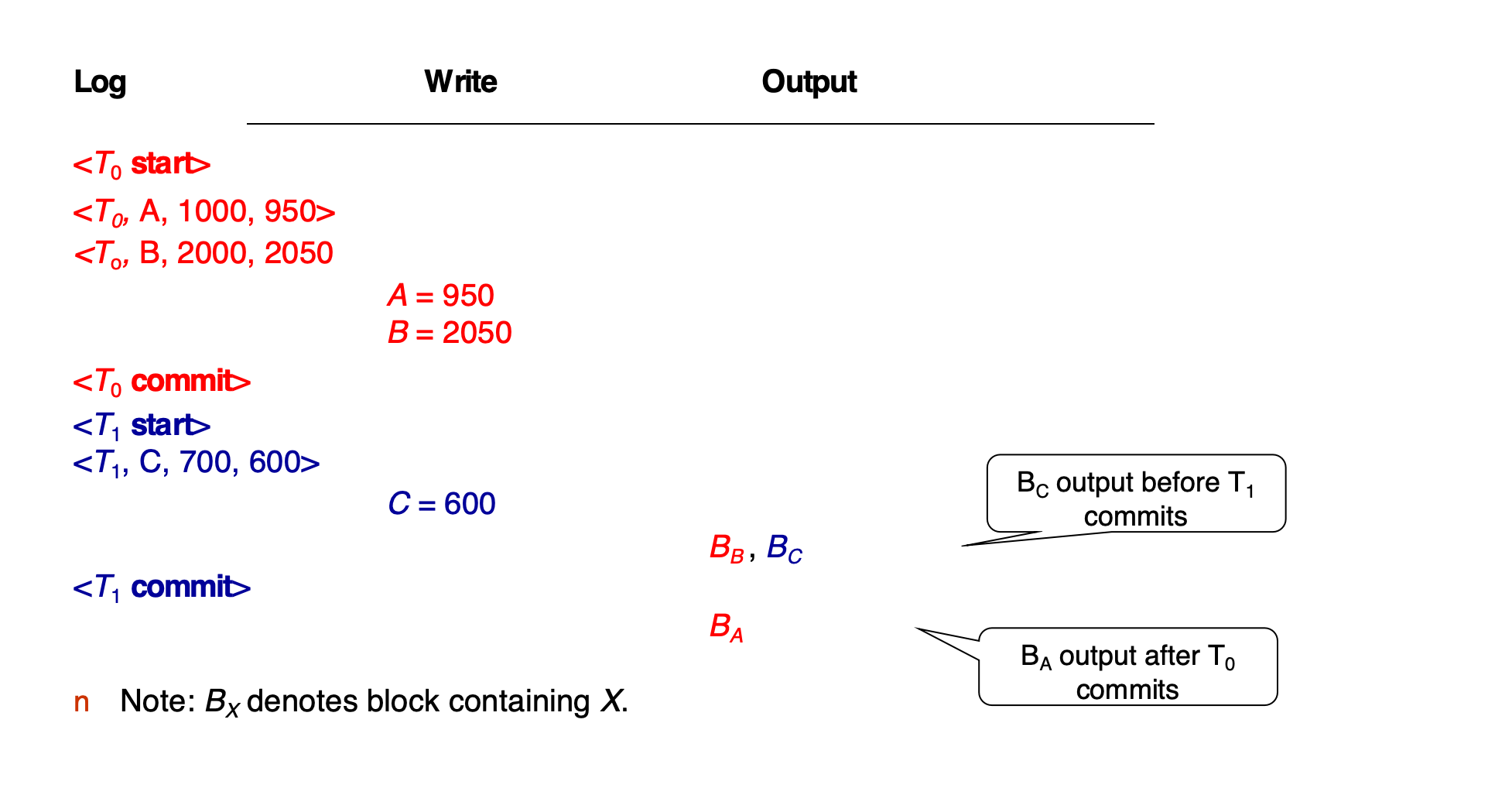
log / write / output 例子:
Log Write Output<T0 start><T0, A, 1000, 950><T0, B, 2000, 2050> A = 950 B = 2050<T0 commit><T1 start><T1, C, 700, 600> C = 600 BB, BC<T1 commit> BA其中 BX 表示包含 X 的 block。
要点:
BC可以在T1 commit前 outputBA可以在T0 commit后才 output- 数据块 output 的时间不必等同于事务 commit 时间
- 只要满足 WAL,恢复算法就能处理
Undo 与 Redo
对更新日志:
<Ti, X, V1, V2>定义:
- undo:把
X恢复为 old valueV1 - redo:把
X设置为 new valueV2
undo(Ti)
undo(Ti) 从 Ti 的最后一条更新日志开始,逆序扫描:
<Ti, X, V1, V2> -> write X = V1每次 undo 后,还要写一条 compensation log:
<Ti, X, V1>当事务 undo 完成,写:
<Ti abort>redo(Ti)
redo(Ti) 从事务第一条更新日志开始,正序扫描:
<Ti, X, V1, V2> -> write X = V2redo 不需要写新的 log。
恢复时如何判断 Undo / Redo
系统崩溃后,根据 log 判断事务状态。
事务 Ti 需要 undo:
log 中有 <Ti start>但没有 <Ti commit>也没有 <Ti abort>事务 Ti 需要 redo:
log 中有 <Ti start>并且有 <Ti commit> 或 <Ti abort>这里 <Ti abort> 的事务也要 redo,原因是:
abort 本身也是由一系列补偿动作构成的。崩溃恢复时要 redo 这些补偿动作,保证事务已经被完整撤销。
所以判断事务状态时不要只看是否出现过 update log。正确顺序是:
有 commit log:该事务已经提交,redo有 abort log:该事务已经完整回滚,redo 其补偿动作只有 start / update,没有 commit / abort:crash 时未完成,undo这也是为什么恢复算法先 redo repeating history,再 undo incomplete transactions。
Repeating History
如果一个事务之前已经被 undo,并且 <Ti abort> 已经写入 log,之后系统又崩溃,那么 recovery 会 redo 这个事务的所有历史动作。
这包括:
- 原来的更新动作
- 后来的补偿日志动作
这种策略叫:
Repeating history(重复历史)
直觉:
先把数据库恢复到崩溃那一刻的状态再撤销当时仍未完成的事务虽然看起来浪费,但它让恢复逻辑非常统一。
假设三个崩溃时间点对应不同 log:

(a) T0 未提交时崩溃 -> undo(T0) -> B 恢复为 2000,A 恢复为 1000 -> 写 <T0, B, 2000>, <T0, A, 1000>, <T0 abort>
(b) T0 已提交,T1 未提交时崩溃 -> redo(T0), undo(T1) -> A = 950, B = 2050, C 恢复为 700 -> 写 <T1, C, 700>, <T1 abort>
(c) T0 和 T1 都已提交时崩溃 -> redo(T0), redo(T1) -> A = 950, B = 2050, C = 600Checkpointing
如果每次 recovery 都从 log 开头扫描,会很慢:
- 系统运行时间越长,log 越长
- 很多早已写入磁盘的事务被重复 redo,浪费时间
所以系统周期性执行 checkpoint。
一个基本 checkpoint 操作:
1. 把当前内存中的所有 log records 写到 stable storage2. 把所有 modified buffer blocks 写到 disk3. 写一条 <checkpoint L> 到 stable storage其中 L 是 checkpoint 时仍然 active 的事务列表。
基本 checkpoint 的问题:
执行 checkpoint 时需要暂停所有更新。
它的高代价主要来自两点:
- checkpoint 要强制刷出 log buffer,满足 WAL
- 还要集中刷出所有 modified buffer blocks,形成大量同步 I/O
因此基本 checkpoint 虽然让恢复更快,但正常运行时会造成明显停顿。
后面会用 fuzzy checkpointing 降低这个开销。
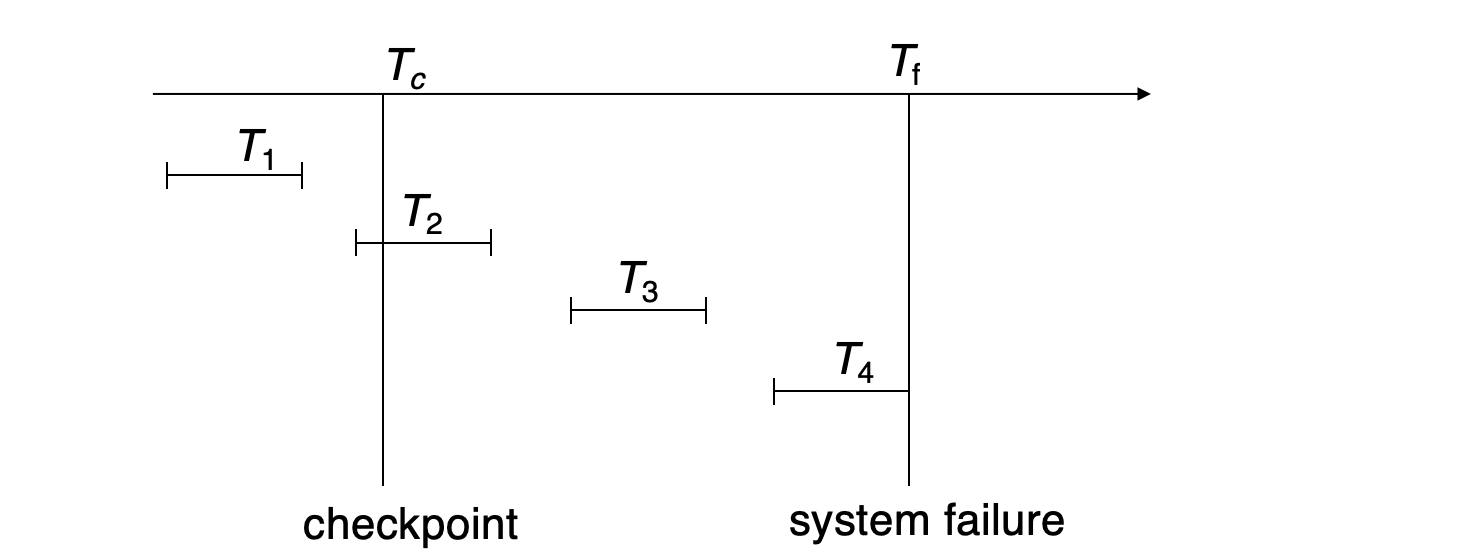
checkpoint 后的恢复范围
恢复时:
- 从 log 末尾向前找最近的
<checkpoint L> - 只有
L中的事务,以及 checkpoint 后新开始的事务,可能需要 redo / undo - 对于
L中事务,为了 undo,可能还要继续向前找到它们的<Ti start> - 更早的 log 可以在安全时删除
checkpoint log 例子:
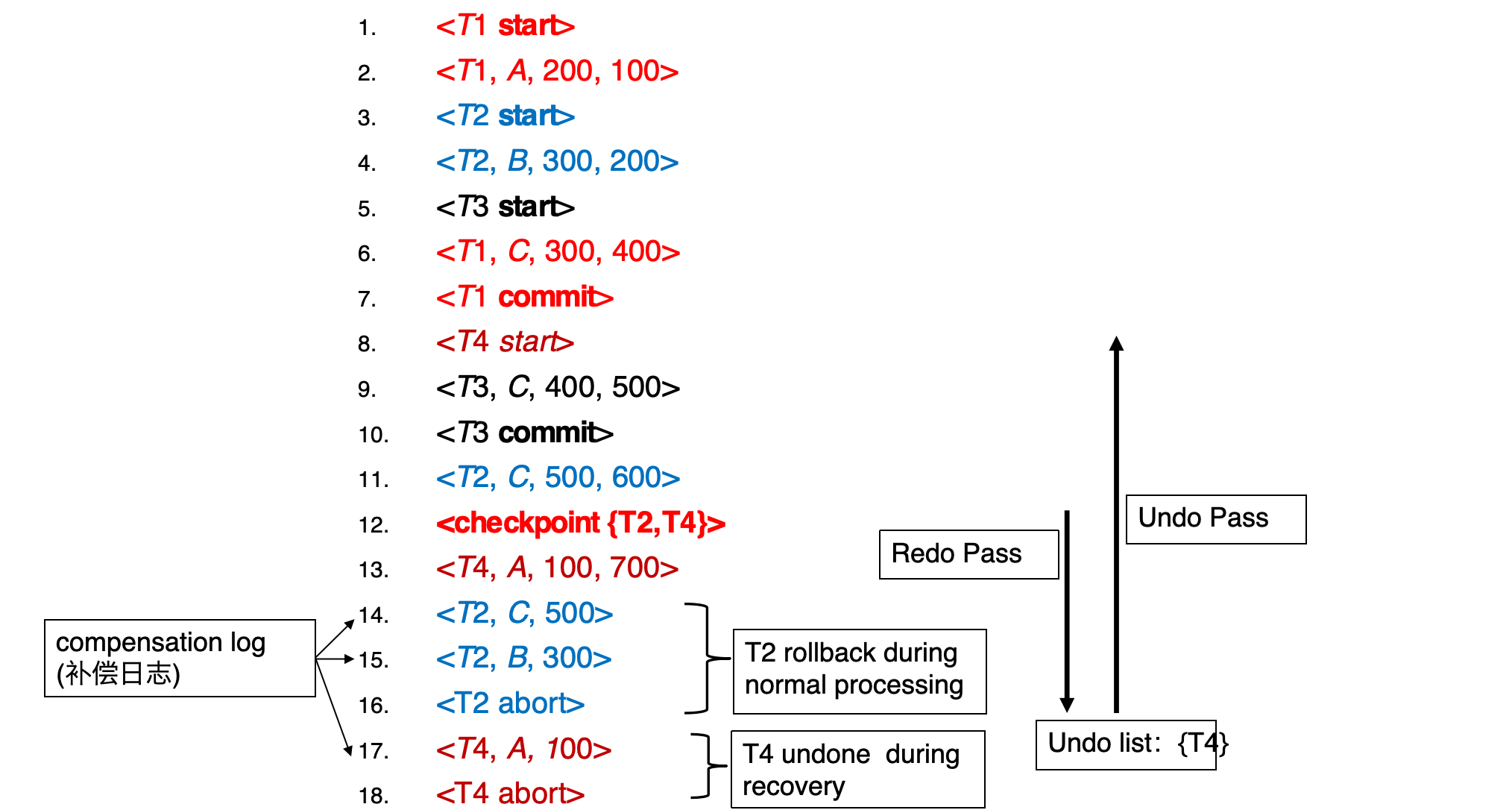
checkpoint 时活跃事务是 {T2, T4}。
恢复时只需要关注:
- checkpoint 列表里的
T2, T4 - checkpoint 后开始的新事务
T1 和 T3 已经在 checkpoint 前完成并落盘,不再需要考虑。
易错点:checkpoint 中的列表 L 只记录 checkpoint 时仍 active 的事务。L 中事务在 checkpoint 前的日志仍可能需要用于 undo,所以恢复时可能还要继续向前找到这些事务的 <Ti start>。
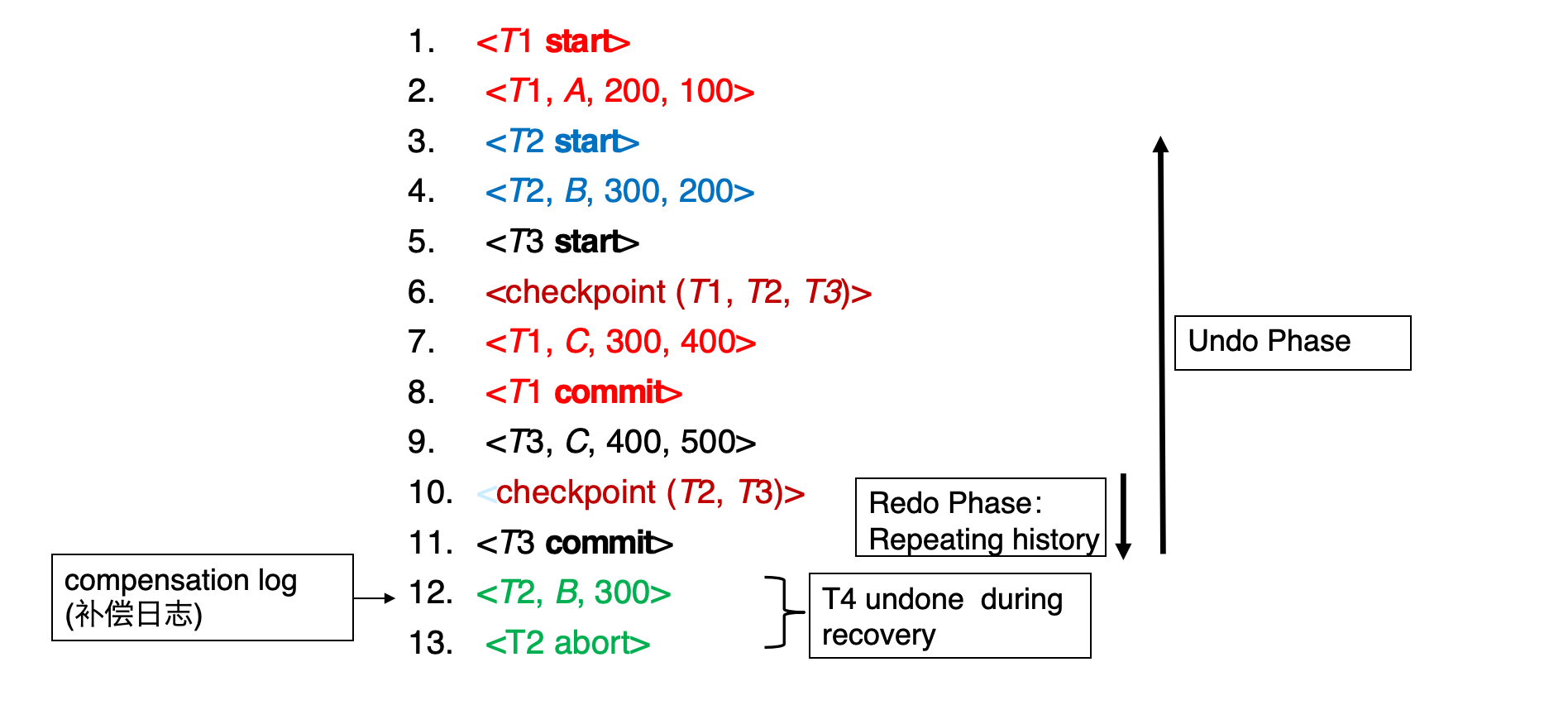
例子:
T1 在 checkpoint 前开始,在 checkpoint 后提交T2 在 checkpoint 前开始,失败时仍未完成T3 在 checkpoint 后开始并提交T4 在 checkpoint 后开始,失败时仍未完成恢复动作:
T1可以忽略:更新已经因 checkpoint 写入磁盘T2和T3redoT4undo
Recovery Algorithm
基本恢复算法。
正常执行时的 Logging
事务正常运行时:
事务开始: 写 <Ti start>每次更新 Xj: 写 <Ti, Xj, V1, V2>事务提交: 写 <Ti commit>其中 update log 必须在数据库 item 被写入前写出。
正常执行时的 Transaction Rollback
如果事务 Ti 在正常执行过程中需要 rollback:
1. 从 log 末尾开始向前扫描2. 对每条属于 Ti 的 <Ti, Xj, V1, V2>: - 把 Xj 写回 V1 - 写补偿日志 <Ti, Xj, V1>3. 扫到 <Ti start> 后停止4. 写 <Ti abort>补偿日志是 redo-only 的:
- 它表示“撤销动作本身已经做过”
- 崩溃后 redo 它即可
- 不应该再 undo 它
系统崩溃后的 Recovery
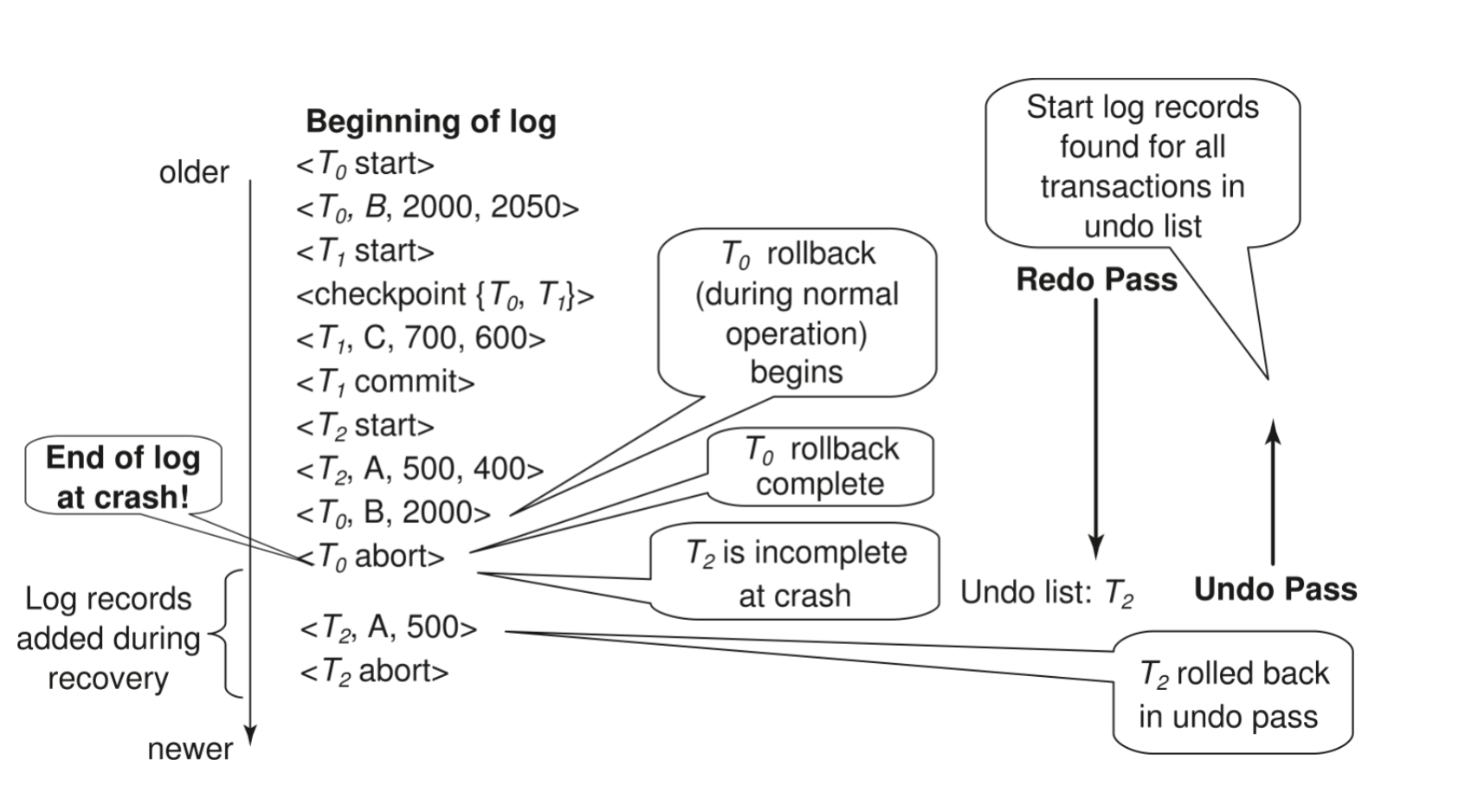
系统崩溃后的 recovery 分两个阶段:
- Redo phase:重复历史
- Undo phase:撤销未完成事务
Redo phase
步骤:
1. 找到最后一条 <checkpoint L>2. undo-list = L3. 从该 checkpoint 开始向前扫描到 log 末尾: - 遇到 <Ti, Xj, V1, V2>:写 Xj = V2 - 遇到补偿日志 <Ti, Xj, V>:写 Xj = V - 遇到 <Ti start>:把 Ti 加入 undo-list - 遇到 <Ti commit> 或 <Ti abort>:从 undo-list 删除 Tiredo phase 结束后:
数据库被恢复到 crash 发生时的状态,包括已提交事务、已回滚事务、未完成事务的影响。
此时 undo-list 中剩下的就是 crash 时未完成的事务。
Undo phase
步骤:
1. 从 log 末尾开始向前扫描2. 遇到属于 undo-list 中事务 Ti 的 <Ti, Xj, V1, V2>: - 写 Xj = V1 - 写补偿日志 <Ti, Xj, V1>3. 遇到 undo-list 中事务 Ti 的 <Ti start>: - 写 <Ti abort> - 从 undo-list 删除 Ti4. undo-list 为空时停止undo phase 完成后,可以恢复正常事务处理。
recovery 练习 log:
<T1 start><T1, A, 100, 200><T2 start><T2, B, 100, 200><T3 start><T3, C, 100, 200><checkpoint (T1, T2, T3)><T3, C, 200, 300><T3 commit><T4 start><T4, C, 300, 400><checkpoint (T1, T2, T4)><T1 commit><T4, C, 300><T4 abort><T2, C, 300, 400><T2, C, 300>从最后一个 checkpoint 开始:
- 初始
undo-list = {T1, T2, T4} - 遇到
<T1 commit>,删除T1 - 遇到
<T4, C, 300>和<T4 abort>,删除T4 T2没有 commit / abort,最终需要 undo
最终:
redo phase: 重做 checkpoint 后的历史undo phase: 撤销 T2,并写 <T2 abort>Buffer Management
恢复算法要高效,不能每条 log 都直接写磁盘,也不能每次 commit 都强制写所有数据页。
结构:
- main memory 中有 database buffer 和 log buffer
- log file 和 database 都在 disk 上
- Log Writer 负责把 log buffer 写到 log file
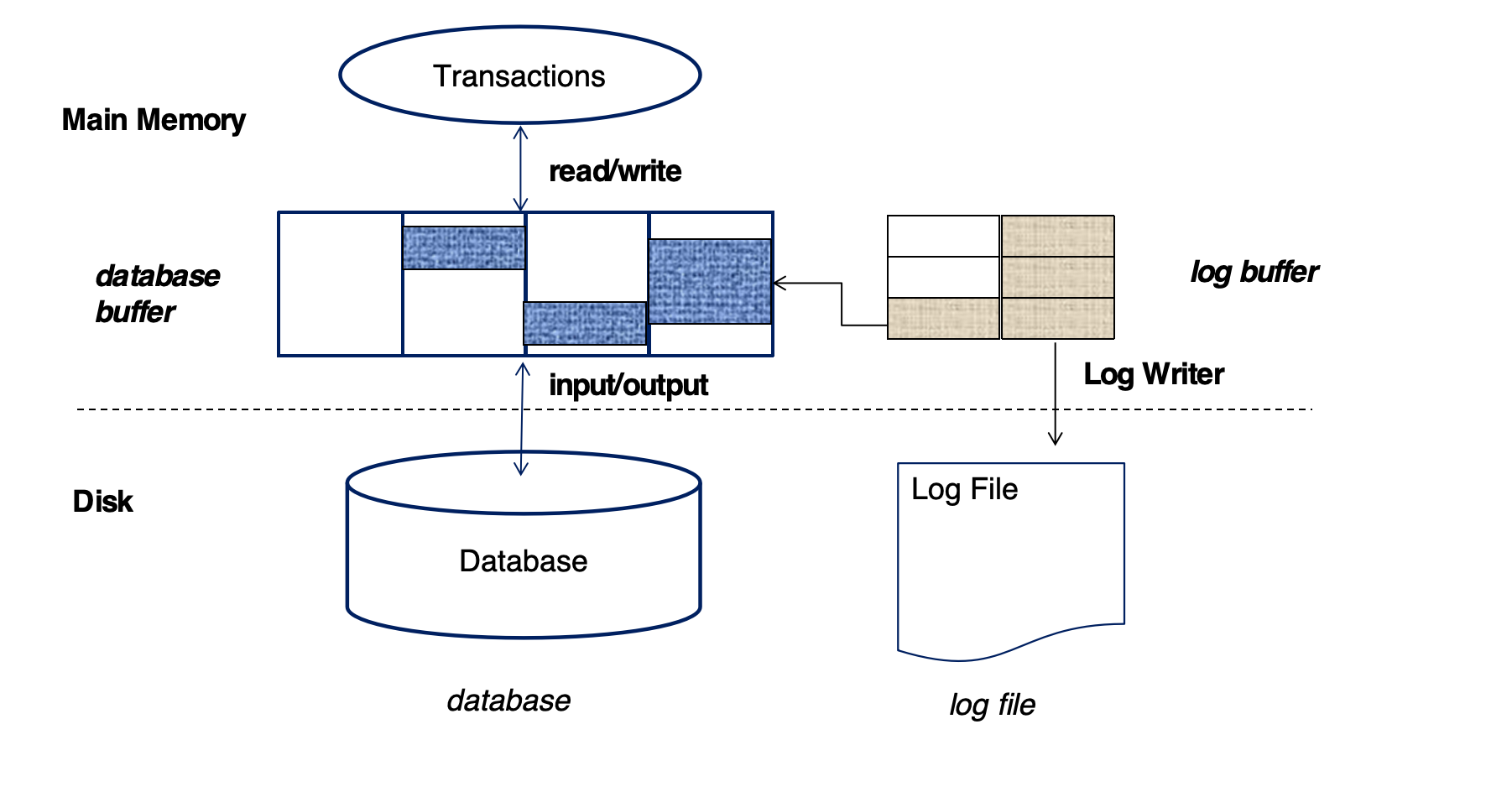
Log Record Buffering
实际系统不会每生成一条 log 就立刻写 stable storage。
做法:
- log records 先放在内存中的 log buffer
- 当 log buffer 满,或执行 log force 时,再写到 stable storage
Log force:强制把 log buffer 中必要的 log records 写到 stable storage。
事务 commit 时必须执行 log force:
<Ti commit> 以及 Ti 的所有先前 log records 必须落到 stable storageGroup Commit
Group commit 把多个事务的 commit log 一次性写出。
好处:
- 多个 log records 共享一次 I/O
- 降低每个事务的 commit I/O 成本
- 高并发事务系统中非常重要
代价:
- 单个事务 commit 可能稍微等待
- 但高负载下整体吞吐量更高,平均延迟可能更低
WAL Rules with Log Buffering
使用 log buffer 时必须满足三条规则:
- log records 按创建顺序写到 stable storage
- 事务
Ti只有在<Ti commit>写到 stable storage 后,才进入 commit state - 内存中的 data block 写回数据库前,和该 block 有关的所有 log records 必须先写到 stable storage
第三条就是 WAL。
严格来说,WAL 至少要求 undo information 先写出;如果 undo 和 redo 分开记录,redo information 可以稍后写。
No-force 与 Steal
Force / No-force
Force policy:事务 commit 时,必须把它修改过的所有 data blocks 写回磁盘。
缺点:
- commit 很慢
- 频繁写热页,I/O 成本高
No-force policy:事务 commit 时,不要求立即写回 data blocks。
优点:
- commit 更快
- 多次更新可以合并后再写
缺点:
- 崩溃后需要 redo 已提交但未落盘的更新
现代数据库通常使用 no-force。
如果 commit 时已经把数据页全部刷盘,当然不需要 redo;但这样 commit 代价太高。实际数据库通常选择 no-force,只要求 commit log 落盘,数据页之后由 buffer manager 自己调度写出。
Steal / No-steal
No-steal policy:未提交事务修改过的 block 不能写到磁盘。
问题:
- 大事务可能占满 buffer
- 脏页不能淘汰,系统难以继续运行
Steal policy:允许包含未提交更新的 block 被写到磁盘。
优点:
- buffer 管理更灵活
- 支持大事务
缺点:
- 崩溃后需要 undo 未提交但已落盘的更新
现代数据库通常使用:
steal + no-force含义:
- commit 时不强制写数据页,所以需要 redo
- 未提交页可以被写出,所以需要 undo
因此 log 必须同时保存 old value 和 new value。
Latch
如果一个含有未提交更新的 block 要写回磁盘,必须先保证 WAL。
输出一个 block 的步骤:
1. 获取该 block 的 exclusive latch2. flush 与该 block 有关的 log records3. output 该 block 到磁盘4. 释放 latchLatch(闩锁) 和事务锁不同:
- latch 是短期的内部锁
- 用来保护内存数据结构或 buffer block
- 不用于保证事务 serializability
- 可以很快释放,不遵循 2PL
OS Buffer 与 Dual Paging
数据库 buffer 可以有两种实现方式。
Reserved main memory
数据库系统自己保留一块真实主存作为 buffer。
问题:
- 内存预先固定分配
- 数据库和其他应用之间无法灵活调整
Virtual memory
数据库 buffer 放在 OS virtual memory 中。
问题:
- OS 可能把修改过的 buffer page 换出到 swap space
- 数据库写 page 到 database file 时,OS 可能又要先从 swap space 读回
这会造成额外 I/O,叫:
dual paging problem
理想做法:
OS 想淘汰数据库 buffer page 时,通知 DBMSDBMS 先按 WAL 写 log,再把 page 写到 database file然后释放内存给 OS但通用操作系统通常不支持这种接口。
Fuzzy Checkpointing
基本 checkpoint 会暂停更新,开销太大。
Fuzzy checkpointing 允许 checkpoint 过程中事务继续执行。
步骤:
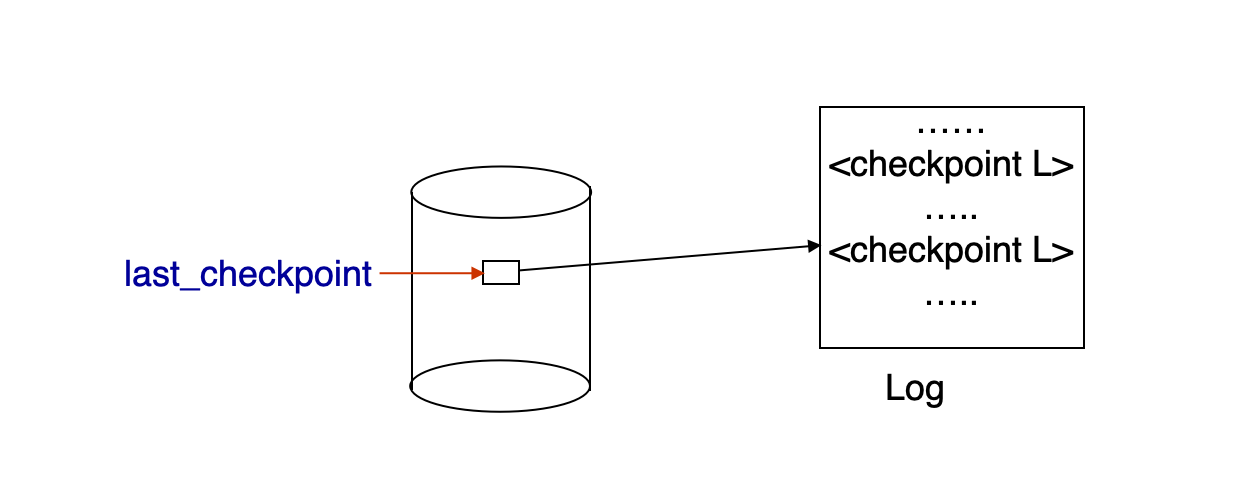
1. 暂停所有事务更新2. 写 <checkpoint L> 并 force log 到 stable storage3. 记录当前 modified buffer blocks 列表 M4. 允许事务继续执行5. 把 M 中的 modified blocks 写到磁盘 - 写出每个 block 前要满足 WAL - 写出时不能被更新6. 在磁盘固定位置 last_checkpoint 存放该 checkpoint record 的指针恢复时:
- 从
last_checkpoint指向的 checkpoint record 开始扫描 - 如果系统在 checkpoint 中途崩溃,
last_checkpoint还没更新,恢复时仍使用前一个完整 checkpoint
这保证 fuzzy checkpoint 是安全的。
要点是 last_checkpoint 指针:
- 写出
<checkpoint L>并不立刻说明这个 checkpoint 已经“算数” - 只有 checkpoint 开始时记录下来的脏页都陆续写出后,系统才能把
last_checkpoint指向它 - recovery 从
last_checkpoint指向的 checkpoint 开始,而不一定从 log 中最后出现的 checkpoint 记录开始
因此 fuzzy checkpoint 的“模糊”体现在:checkpoint 记录先出现,脏页在后台慢慢写出,checkpoint 完成状态由额外指针确认。
Failure with Loss of Nonvolatile Storage
前面默认 nonvolatile storage 不会丢失。若磁盘损坏,单靠 log 不够,因为 database pages 本身可能没了。
处理方法类似 checkpoint,但更重:
周期性把整个数据库 dump 到 stable storage。
基本 dump 过程:
1. 不允许事务 active2. 把内存中的所有 log records 写到 stable storage3. 把所有 buffer blocks 写到 disk4. 把 database 内容复制到 stable storage5. 向 log 写 <dump>磁盘失败后的恢复:
1. 从最近一次 dump 恢复 database2. 查 log3. redo dump 后已经 committed 的所有事务也可以允许 dump 期间有事务运行,这叫:
fuzzy dump / online dump
思想类似 fuzzy checkpointing。
普通文件会定期手动保存,数据库也要定期备份。但数据库不能只靠昨天晚上的备份,因为从备份到故障之间已经有大量提交事务。恢复时必须“备份 + 备份之后的提交日志 redo”配合使用。
Remote Backup Systems
Remote backup systems 用于高可用。
目标:
即使 primary site 被破坏,backup site 也能继续处理事务。
银行系统举例:深圳、上海、北京等多个异地节点保存账户数据和日志。某个 site 故障时,系统需要快速切换到备份 site,减少甚至避免对用户可见的不可用时间。
Failure Detection
Backup site 必须检测 primary site 是否失败。
难点:
primary site failure 和 communication link failure 要区分做法:
- 多条通信链路
- heart-beat messages
如果 backup 收不到 heartbeat,需要判断是 primary 坏了还是网络断了。
Transfer of Control
当 backup 接管时:
1. backup 使用自己的 database copy 和从 primary 收到的 log 执行 recovery2. redo completed transactions3. rollback incomplete transactions4. backup 成为新的 primary旧 primary 恢复后,如果要重新接管:
1. 旧 primary 从当前 primary 接收 redo logs2. 应用所有更新3. 追上当前状态后才能重新成为 primaryHot-Spare
为了减少 takeover delay,可以使用 Hot-Spare(热备份)。
特点:
- backup 持续处理 primary 发来的 redo log
- 本地持续应用更新
- primary 失败后,只需要 rollback incomplete transactions
- 接管速度非常快
Hot-spare 的本质是把 recovery 工作提前做:backup 不是等 primary 坏了才开始读 log,而是在日志到达时持续 redo。故障发生时剩下的主要工作是检测故障、回滚未完成事务、切换入口。
One-safe / Two-very-safe / Two-safe
Remote backup 中有一个核心权衡:
commit 要不要等 backup 也收到 commit log?
One-safe
primary 写入 commit log 后,事务立即 commit优点:
- commit 快
- primary 单点性能好
缺点:
- commit log 可能还没到 backup,primary 就坏了
- backup 接管后可能丢失已经向用户报告 commit 的事务
Two-very-safe
commit log 同时写到 primary 和 backup 后,事务才 commit优点:
- 持久性最强
- backup 接管不会丢失已提交事务
缺点:
- primary 或 backup 任一不可用,事务都无法 commit
- availability 下降
Two-safe
如果 primary 和 backup 都 active:按 two-very-safe如果只有 primary active:按 one-safe优点:
- 比 two-very-safe 可用性更好
- 正常情况下避免 one-safe 的 lost transaction 问题
Early Lock Release and Logical Undo
为什么需要 Logical Undo
高并发结构,例如 B+-tree,并发控制通常会提前释放底层锁。
例子:
- B+-tree insertion
- B+-tree deletion
- tuple insertion / deletion
- space allocation
- bank balance 上的 deposit / subtract 操作
问题:
一旦底层锁提前释放,其他事务可能已经修改同一数据结构。此时不能简单恢复 old value,否则会覆盖其他事务的正确更新。
因此需要 logical undo。
Physical undo
把数据项恢复为 old value适合:
- 没有 early lock release
- 没有其他事务在中间修改该数据项
Logical undo
用一个反向操作撤销原操作例子:
- undo insert:执行 delete
- undo delete:执行 insert
- undo deposit:执行 subtract
这类操作被称为 logical operations。
B+-tree:如果插入或删除时一直持有树上底层节点的锁直到事务结束,并发度会很差。early lock release 允许提前释放这些热点结构上的锁,但代价是恢复时不能简单把 page 或 record 恢复成 old value。
Redo 仍然使用 Physical Redo
即使 undo 使用 logical undo,redo 通常仍然使用 physical redo。
原因:
崩溃恢复刚开始时,磁盘上的数据库状态可能缺少 operation consistency,可能只包含某个操作的一部分影响。此时执行 logical redo 很复杂。
所以:
- undo 可以 logical
- redo 仍然 physical
这不会影响 early lock release。
直觉:redo 要把系统带回 crash 发生时的历史状态,必须重演当时已经发生过的物理变化;undo 是把未完成事务的语义效果取消,所以可以用反向逻辑操作实现。
Operation Logging
逻辑操作的日志记录方式:
1. 操作开始: <Ti, Oj, operation-begin>
2. 操作执行过程中: 正常写 physical redo + physical undo log records
3. 操作完成: <Ti, Oj, operation-end, U>其中:
Oj是操作实例的唯一标识U是逻辑撤销所需的信息
向索引 I9 插入 (K5, RID7):
<T1, O1, operation-begin>...<T1, X, 10, K5><T1, Y, 45, RID7><T1, O1, operation-end, (delete I9, K5, RID7)>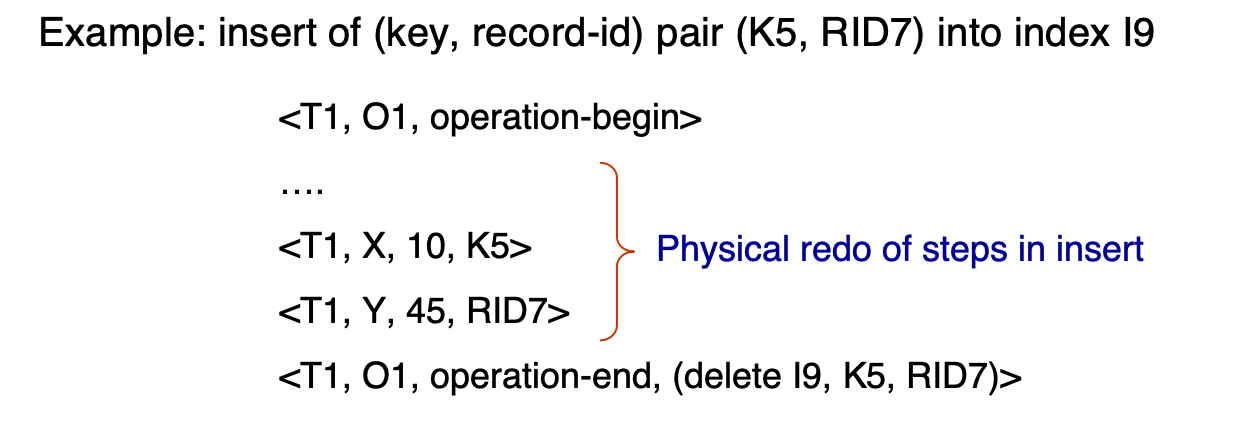
解释:
- 中间的
<T1, X, 10, K5>、<T1, Y, 45, RID7>是 physical logs - 如果操作没完成就 rollback,用 physical undo
- 如果操作完成后 rollback,用 operation-end 里的
(delete I9, K5, RID7)做 logical undo
Rollback with Logical Undo
事务 Ti rollback 时,逆序扫描 log。
遇到普通 physical log
<Ti, X, V1, V2>执行:
X = V1写 <Ti, X, V1>遇到 operation-end
<Ti, Oj, operation-end, U>说明操作已经完成,不能再用 physical undo。
执行:
1. 用 U 执行 logical undo2. logical undo 过程中产生的更新正常记录 log3. 完成后写 <Ti, Oj, operation-abort>4. 跳过该操作之前的所有 physical log,直到 <Ti, Oj, operation-begin>遇到 redo-only record
直接忽略。
遇到 operation-abort
说明该操作以前已经被撤销过。
跳过前面属于该操作的 log,直到 <Ti, Oj, operation-begin>这样可以避免同一个 logical operation 被重复 rollback。
遇到 Ti start
写 <Ti abort>rollback 完成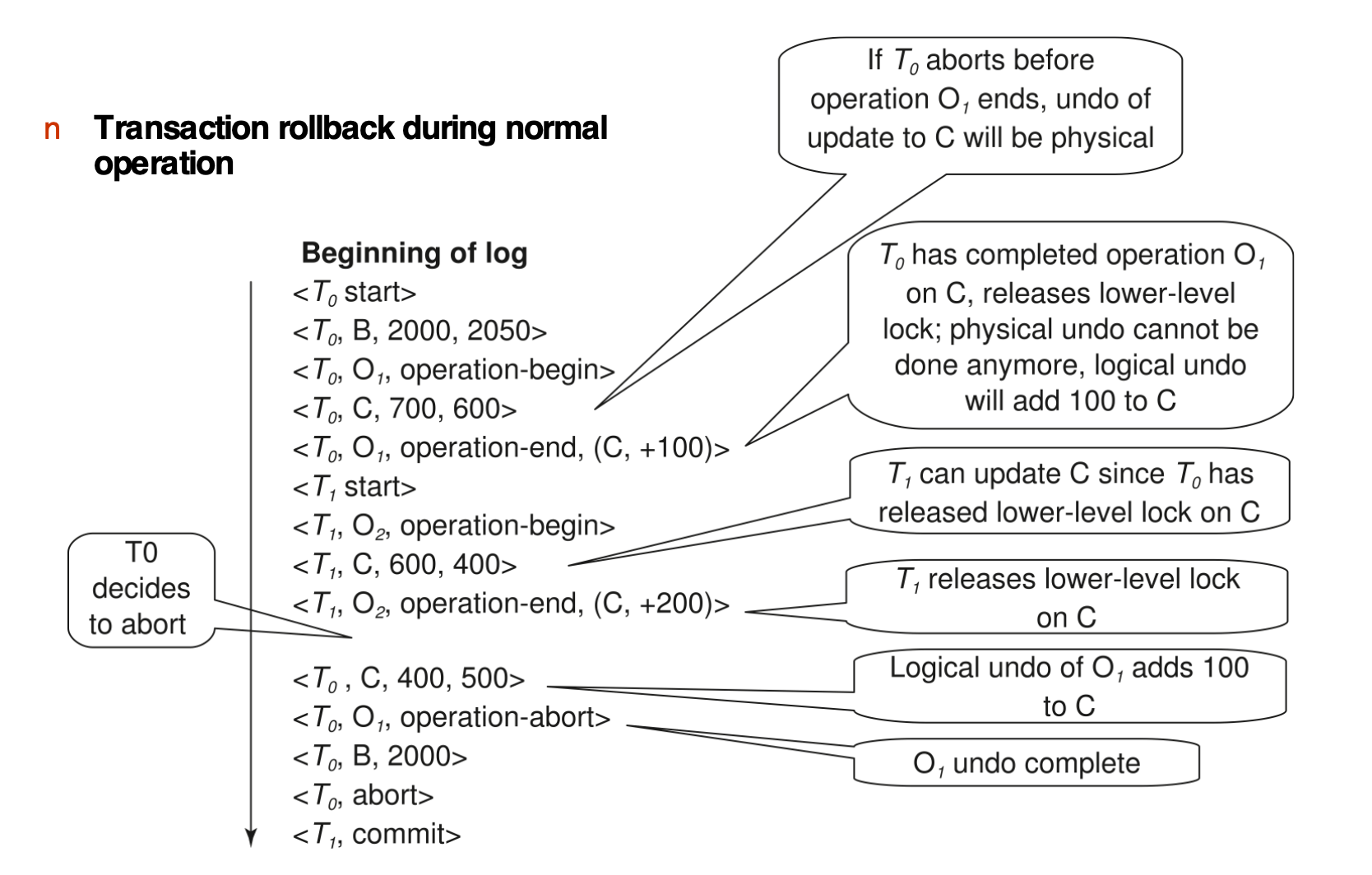
Failure Recovery with Logical Undo
整体仍然是两阶段:
- Redo phase:从最后一个 checkpoint 后开始,物理重做所有更新,重复历史
- Undo phase:对 undo-list 中未完成事务执行 rollback
区别在于 undo phase 处理 log 时,要按 logical undo 的规则:
- 完成的 operation 用
Ulogical undo - 未完成的 operation 用 physical undo
- 已经有 operation-abort 的 operation 不再重复撤销
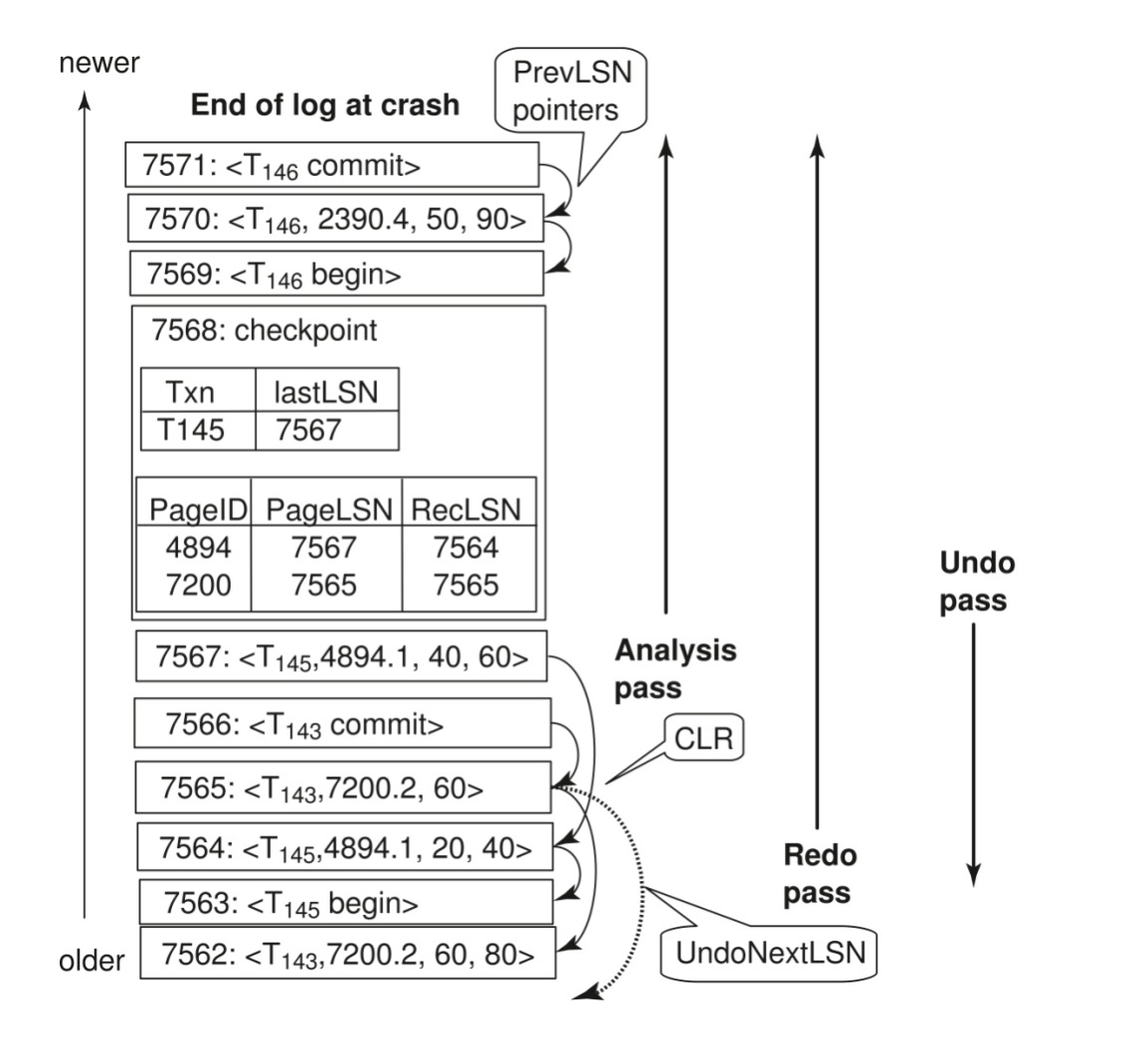
课件中的完整 / 不完整 operation 例子:
<T1 start><T1, O1, operation-begin>...<T1, X, 10, K5><T1, Y, 45, RID7><T1, O1, operation-end, (delete I9, K5, RID7)><T1, O2, operation-begin><T1, Z, 45, 70>
-- T1 Rollback begins here --
<T1, Z, 45> -- 对未完成 O2 做 physical undo,redo-only log<T1, Y, ..., ...> -- 对已完成 O1 做 logical undo 时产生的正常 redo records...<T1, O1, operation-abort><T1 abort>关键点:
O2没有 operation-end,所以用 physical undoO1已经 operation-end,所以用 logical undo- 如果刚写完
<T1, O1, operation-abort>就崩溃,恢复时不能重复撤销O1
ARIES
ARIES 是经典的工业级恢复算法。
它仍然基于:
Repeating history + Undo incomplete transactions但加入了大量优化,用来:
- 降低正常执行开销
- 减少 checkpoint 成本
- 加快 recovery
- 支持 fine-grained locking 和 partial rollback
ARIES 可以理解为前面基本恢复算法的工程化增强版。
ARIES 的核心改进
相比前面的简化算法,ARIES 的主要改进包括:
- 使用 LSN(Log Sequence Number) 标识每条 log record
- 在 page 中保存 PageLSN,判断哪些更新已经反映到该 page
- 支持 physiological redo
- 使用 Dirty Page Table 避免不必要的 redo
- 使用低开销 fuzzy checkpointing,checkpoint 时不强制写出所有 dirty pages
Physiological Redo
Physiological redo 的含义:
物理定位 page,但 page 内部的动作可以是逻辑操作。
例子:删除 page 中一条 record。
如果用纯 physical redo:
- 删除后可能需要移动很多 records 填补空洞
- 需要记录 page 中大量字节的 old/new values
如果用 physiological redo:
- log 只需记录“在这个 page 中删除某条 record”
- redo 时在指定 page 内执行删除动作
优点:
- log 更小
- 恢复效率更高
要求:
- page output 必须是 atomic 的
- incomplete page output 要能通过 checksum 检测
- 如果 page 半写,需要按 media failure 处理
LSN 与 PageLSN
LSN
LSN(Log Sequence Number) 唯一标识每条 log record。
特点:
- 单调递增
- 通常可以设计成 log file 中的 offset,方便快速定位
- 多个 log files 时可以扩展成 file number + offset
PageLSN
每个 page 保存一个 PageLSN:
该 page 已经反映的最后一条 log record 的 LSN。
更新 page 的过程:
1. X-latch page2. 写 log record3. 更新 page4. 把该 log record 的 LSN 写入 PageLSN5. unlock pageflush page 到磁盘前:
必须先 S-latch page这样可以保证 page 写出时处于 operation-consistent 状态。
PageLSN 的作用:
如果 PageLSN >= 某 log record 的 LSN说明该 log record 的影响已经在 page 上redo 时跳过这使 redo 幂等,避免重复执行 physiological redo。
CLR
ARIES 使用 CLR(Compensation Log Record) 记录 recovery / rollback 期间执行的 undo 动作。
CLR 是 redo-only:
CLR 记录的动作永远不需要再 undo。
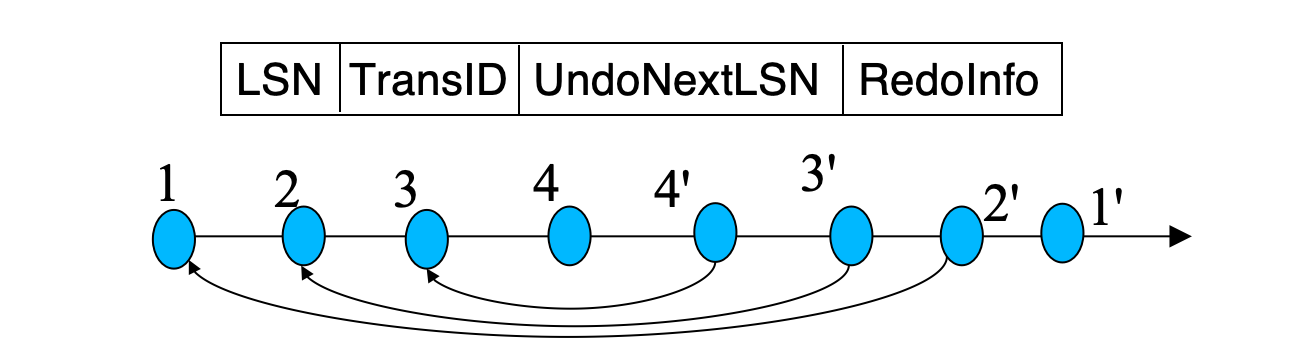
普通 log record 包含:
LSN, TransID, PrevLSN, RedoInfo, UndoInfoCLR 包含:
LSN, TransID, UndoNextLSN, RedoInfo其中:
PrevLSN:同一事务上一条 log record 的 LSNUndoNextLSN:下一条需要被 undo 的更早 log record
UndoNextLSN 的作用:
如果 recovery 期间再次崩溃,重启后可以跳过已经 undo 过的 log records,避免重复 undo。

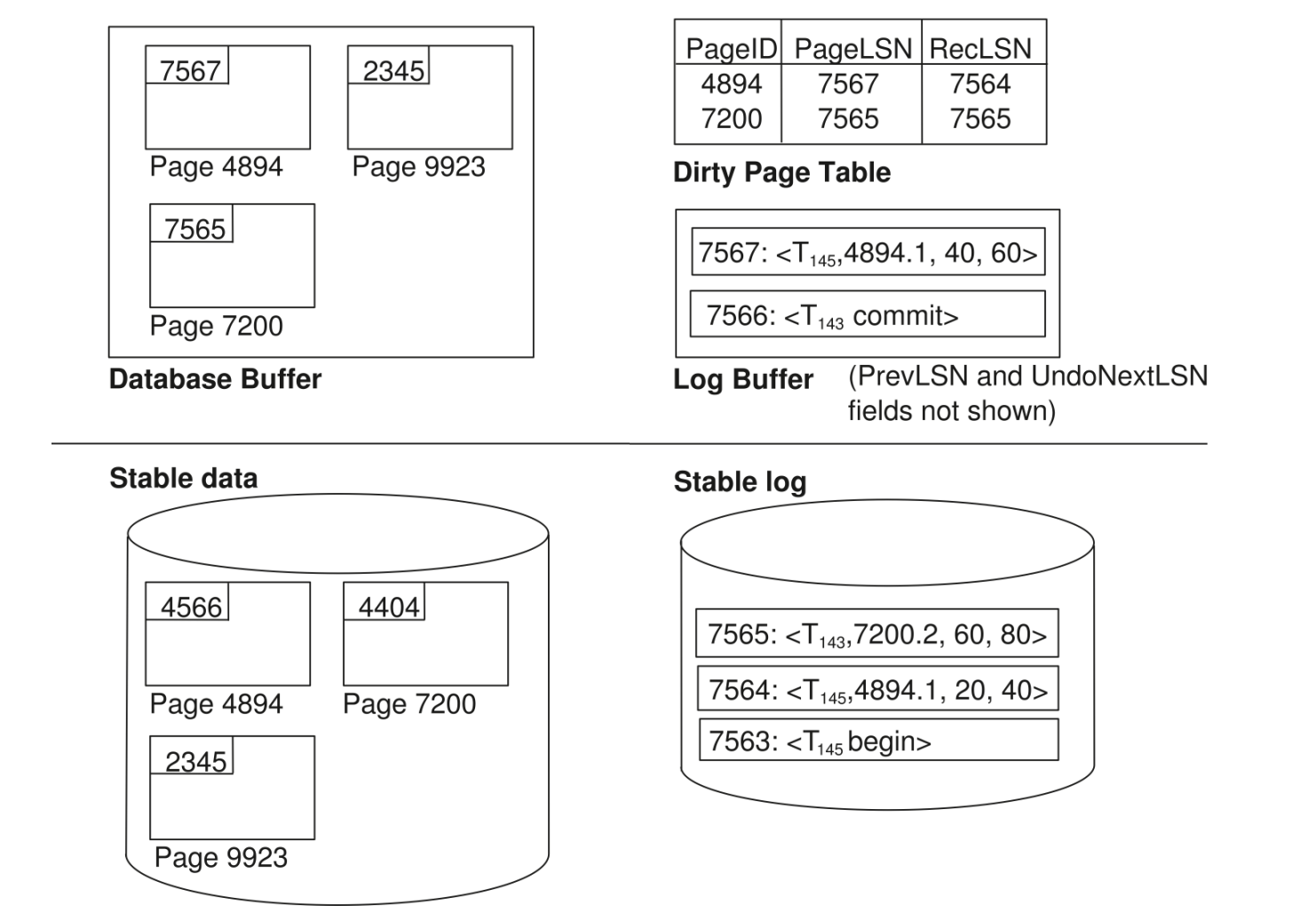
Dirty Page Table
DirtyPageTable 记录 buffer 中已经被更新但磁盘版本未必最新的 pages。
每个 dirty page 记录:
PageLSNRecLSN
其中:
RecLSN是该 page 变 dirty 后第一条可能还没反映到磁盘的 log record 的 LSN。
设置方式:
当 page 第一次进入 DirtyPageTable 时,RecLSN = 当前 update log record 的 LSN作用:
- recovery 时不必从更早的 log 开始 redo
- 对某个 page 来说,早于
RecLSN的 log 一定不需要 redo
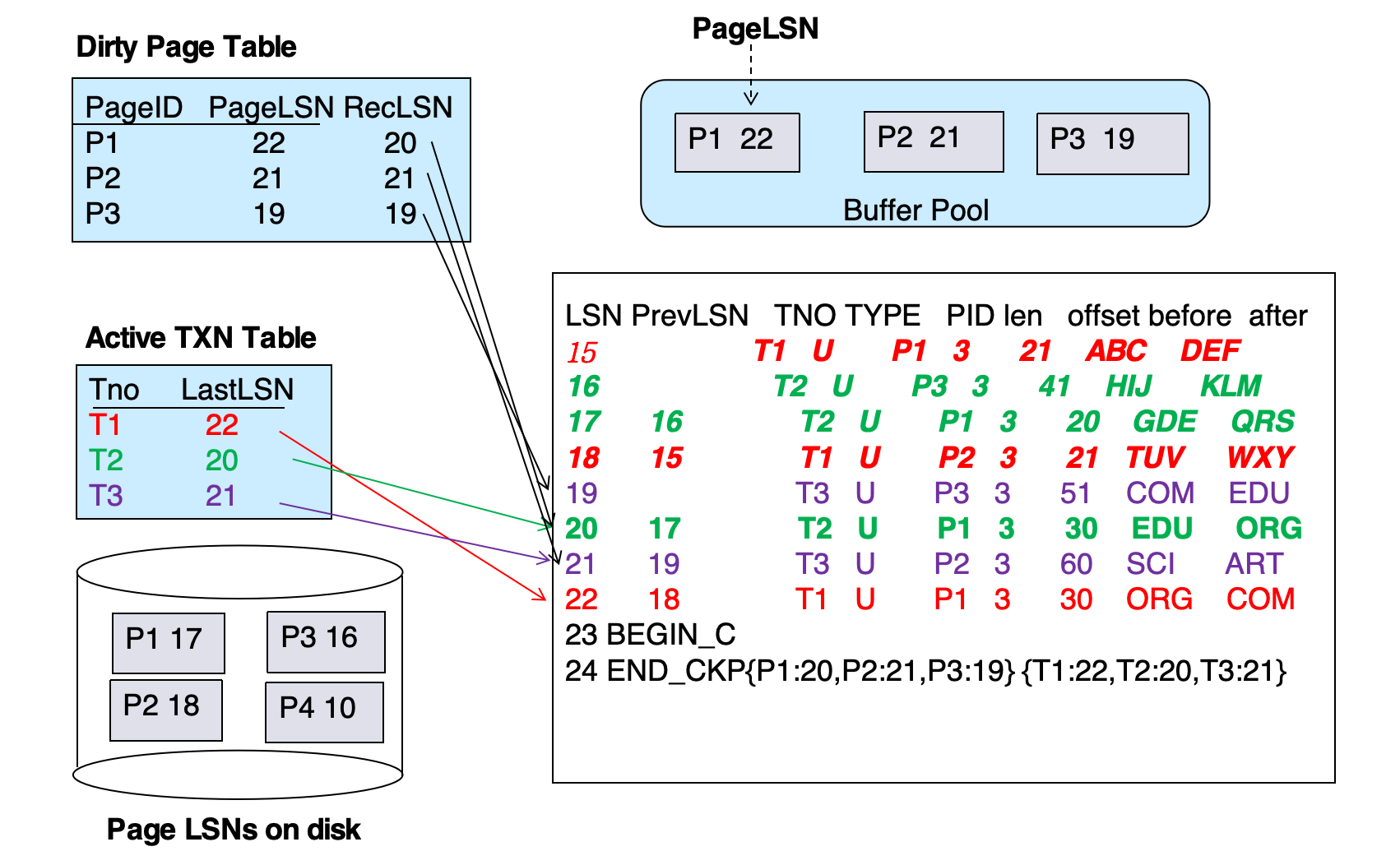
ARIES Checkpoint
ARIES checkpoint record 包含:
- DirtyPageTable
- active transaction list
- 每个 active transaction 的
LastLSN
同时,磁盘固定位置保存:
last completed checkpoint log record 的 LSNARIES 的 checkpoint 特点:
checkpoint 时不强制写出 dirty pages。
dirty pages 在后台持续写出。
因此 ARIES checkpoint 开销很低,可以频繁执行。
这里和基本 checkpoint 的差别必须分清:
- 基本 checkpoint:checkpoint 时强制刷出 dirty pages
- ARIES checkpoint:只把 DirtyPageTable 和 active transaction list 写进 checkpoint log,dirty pages 后台持续写出
所以 ARIES 中 RedoLSN 可能早于 checkpoint log record 的 LSN,因为 checkpoint 时 dirty page 并没有被强制写盘。
ARIES Recovery
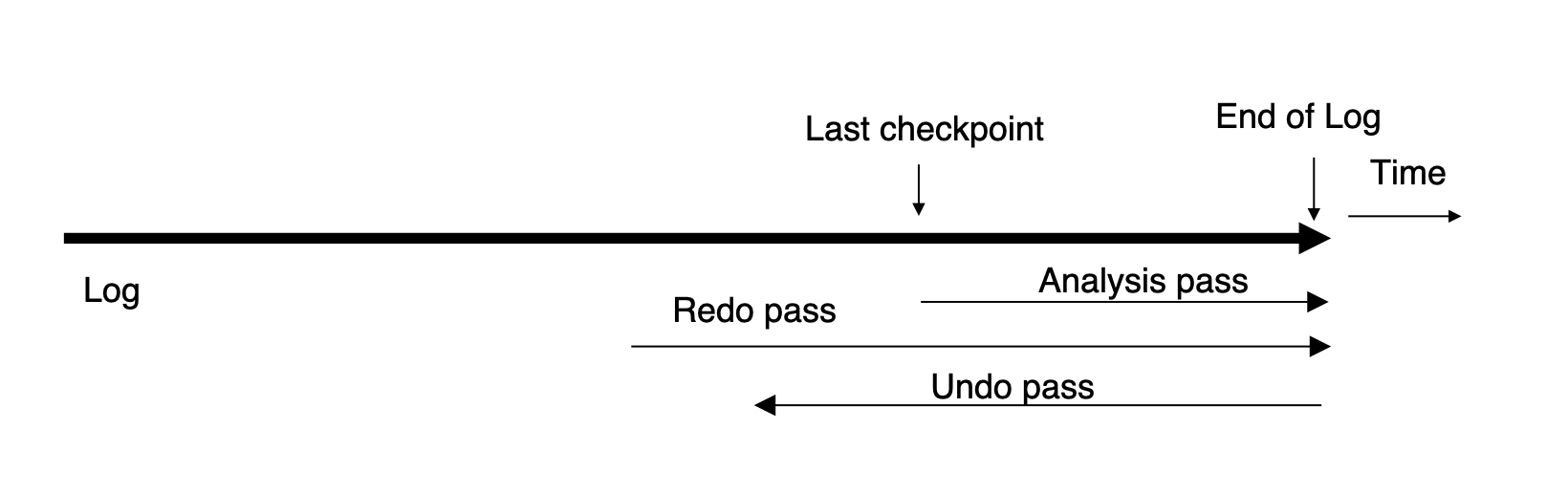
ARIES recovery 分三遍:
- Analysis pass
- Redo pass
- Undo pass
Analysis pass
目标:确定 recovery 需要做什么。
Analysis pass 需要确定:
- 哪些事务需要 undo
- crash 时哪些 pages 是 dirty 的
- redo 应该从哪里开始,即
RedoLSN
步骤:
1. 从最后一个完整 checkpoint 开始2. 读取 checkpoint 中的 DirtyPageTable3. RedoLSN = DirtyPageTable 中所有 RecLSN 的最小值 - 如果没有 dirty pages,则 RedoLSN = checkpoint record 的 LSN4. undo-list = checkpoint 中的 active transaction list5. 读取这些事务的 LastLSN6. 从 checkpoint 向前扫描到 log 末尾: - 发现新事务 log,加入 undo-list - 发现 update log,若 page 不在 DirtyPageTable 中,加入并设置 RecLSN - 发现 transaction end log,删除该事务 - 持续更新每个事务的 LastLSNAnalysis pass 结束后:
RedoLSN决定 redo pass 从哪里开始- DirtyPageTable 决定哪些 page 可能需要 redo
- undo-list 中的事务必须 rollback
记忆方式:analysis pass 是“恢复现场”,恢复出 crash 时的两个表:
DirtyPageTable:哪些页的磁盘版本可能不是最新Active transaction list / undo-list:哪些事务 crash 时还没结束同时由 DirtyPageTable 中最小的 RecLSN 得到 RedoLSN。
Redo pass
Redo pass 从 RedoLSN 开始向前扫描。
遇到 update log record 时:
1. 如果 page 不在 DirtyPageTable 中:跳过2. 如果 log record 的 LSN < page 的 RecLSN:跳过3. 否则 fetch page4. 如果 page.PageLSN < log record.LSN:redo5. 否则跳过关键优化:
- 前两个判断可以避免读 page
PageLSN可以避免重复 redo
Redo pass 的本质仍然是:
repeating history但 ARIES 用 RecLSN + PageLSN 跳过已经反映在磁盘上的动作。
两个 skip 判断的作用不同:
- page 不在 DirtyPageTable,或者 log.LSN < page.RecLSN:连 page 都不用读,直接跳过
- 通过前一关后才 fetch page,再用 PageLSN 判断是否真的需要 redo
这样可以减少恢复时的随机 I/O。
Undo pass
Undo pass 对 analysis 得到的 undo-list 中事务做 rollback。
优化方式:
1. 每个事务维护 next LSN to undo2. 初始值为该事务 LastLSN3. 每次选择最大的 LSN 进行 undo4. 如果是普通 log record: - 执行 undo - 写 CLR - next = PrevLSN5. 如果是 CLR: - next = UndoNextLSN - 跳过中间已经 undo 过的 records6. 所有事务都到达 start 后,写 end / abort,undo 完成CLR 保证:
- rollback 过程中崩溃也没关系
- 重启后不会重复 undo 已经 undo 过的动作

ARIES 的其他特性
Recovery Independence
ARIES 支持 page-level recovery independence:
某些 disk pages 损坏时,可以单独从 backup 恢复这些 pages,同时其他 pages 仍可使用。
Savepoints
事务可以设置 savepoint,之后 rollback 到某个 savepoint。
用途:
- 复杂事务的局部回滚
- 死锁时只回滚一部分操作,释放所需锁
Fine-grained locking
ARIES 支持细粒度锁,例如 index 上的 tuple-level locking。
这通常要求:
- logical undo
- early lock release
- 更复杂的恢复逻辑
Recovery optimizations
常见优化:
- 利用 DirtyPageTable 在 redo 阶段预取 pages
- 支持 out-of-order redo
- 某个 page 正在 fetch 时,可以先处理其他 log records
- page 到达后再执行对应 redo
Recovery in Main-Memory Databases
主存数据库中,查询和更新很快,但 main memory 在系统崩溃或关机后会丢失内容。
因此仍然需要:
- 把 log records 写到 stable storage
- checkpoint 到持久存储
- recovery 时从 disk 重新加载数据库,并应用 log
主存数据库可以做一些优化。
Index redo 可以省略
主存数据库恢复 relation 后,index 往往可以很快重建。
因此很多系统:
- 不为 index updates 做 redo logging
- 仍然需要 undo logging 支持事务 abort
- 这些 undo logs 可以只保存在内存中,不一定写入 stable log
只做 redo logging
一些主存数据库通过以下方式减少 logging:
- 周期性 checkpoint
- 确保未提交数据不写入 disk
- 或使用多版本记录,避免 in-place updates
恢复时:
1. 加载 checkpoint2. redo checkpoint 后的提交更新3. 清理未提交版本并行恢复
主存数据库恢复时,整个数据库需要重新载入,恢复速度非常关键。
优化方式:
- 将数据分区
- log records 也按分区组织
- 多个 CPU cores 并行恢复不同分区
NVRAM 补充
Non-volatile RAM / Storage Class Memory 支持类似 RAM 的随机访问,同时断电后不丢失内容。
对恢复的影响:
- 可以减少甚至避免 redo logging
- 仍可能需要 undo logging 处理事务 abort
- 需要考虑 NVRAM 上原子更新的问题
Shadow Copying 与 Shadow Paging
另一类恢复思想:shadow copying。
基本思想:
1. 更新前复制一份数据库2. 所有更新写到新副本3. 如果事务 abort,删除新副本4. 如果事务 commit,原子地把 db-pointer 指向新副本优点:
- abort 很简单
- 原副本始终保持不变
缺点:
- 复制整个数据库代价巨大
- 不适合大数据库
- 不适合并发事务
Shadow paging 是优化版:
- 不复制整个数据库
- 复制 page table 和被更新的 pages
- 未更新 pages 共享旧副本
- commit 时原子更新 page table pointer
但 shadow paging 在并发事务下表现不好,所以现代数据库主要使用 log-based recovery。