

概述
向量数据库 的本质,是把文本、图像、音频、视频等非结构化数据先变成可计算的 向量,再围绕这些向量做 存储、索引、相似度检索与组合查询。
- 非结构化数据的数据库化表示
- 语义检索(semantic retrieval)的底层思路
- 向量检索系统的核心工程权衡
目录
- 概述
- 目录
- 从数据对象到向量
- 向量数据库
- 从精确匹配到语义理解
- 距离度量方式
- 核心挑战与 ANN
- HNSW
- IVF(倒排文件索引)
- PQ(乘积量化)
- IVF-PQ 的结合应用
- 查询增强能力
- 主流向量数据库概览
- 多模态向量数据库
从数据对象到向量
向量嵌入
向量嵌入(Vector Embedding),就是把真实世界中复杂、高维、非结构化的数据对象,转换成数学上更容易处理的低维、稠密、连续数值向量。
这里有三个角色:
- 数据对象(data object)
- Embedding 模型(embedding model)
- 输出向量(output vector)
例如:
- 一段文本:
helloworld - 一张图片:一只猫
- 一段音频 / 一个视频片段
都会被送进一个 embedding 模型,最后变成类似:
[0.16, 0.29, -0.88, ...]这样的固定长度一维数组。
- 输入是现实中的对象
- 中间是模型做特征压缩与表示学习
- 输出是可以计算距离 / 相似度的向量
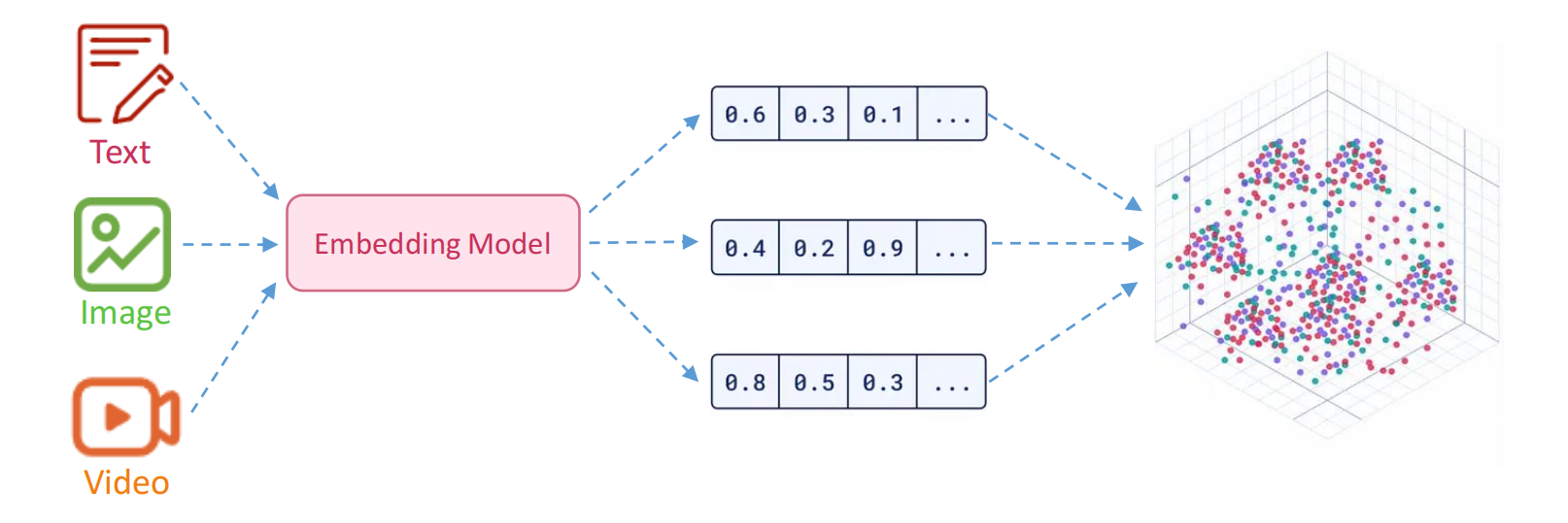
TIP向量真正的意义在于:
- 把原本不好直接比较的对象
- 变成可以做“距离计算”的数学对象
于是系统才有可能回答:
- 哪段文本和这段文本语义最接近?
- 哪张图片和这张图片最像?
- 哪张图最符合一句文本描述?
主流 Embedding 模型
embedding 模型分成三类:
文本模型
- OpenAI text-embedding-3:闭源行业标杆
- BAAI BGE 系列:开源代表
它们主要负责把自然语言文本映射成向量。
图像与视觉模型
- ResNet:工业界图像特征提取的重要基础模型
- Vision Transformer(ViT):利用全局注意力机制捕捉图像细节
它们主要负责从图像中提取视觉特征。
多模态模型
- CLIP:可以同时“读文本、看图像”,并把两者映射到同一个向量空间
这类模型特别重要,因为它直接关系到后面多模态向量数据库的发展。
向量数据库
向量数据库(Vector Database) 是:专门用于高效存储、索引和查询高维向量数据的系统。
包含三层意思:
- 存储(storage)
- 存的不是传统结构化字段为主的数据,而是向量表示
- 索引(indexing)
- 必须为高维向量设计特殊索引,否则检索会非常慢
- 查询(querying)
- 查询重点不再只是精确匹配,还包括相似度搜索、语义搜索、带过滤条件的组合查询
向量数据库强调三件事:
- 适配非结构化数据
- 文本、图像、视频等都能以向量形式统一表示
- 支持近似最近邻搜索
- 在大规模数据中快速找“最像”的对象
- 支持多样化查询
- 不只是相似度,还能叠加筛选、范围、排序等条件
所以向量数据库是:
- 以向量为核心数据对象
- 以相似度检索为核心操作
- 以 ANN 索引为核心性能基础
从精确匹配到语义理解
传统数据库(SQL / NoSQL)很擅长:
- 精确过滤
- 条件匹配
- 聚合统计
- 结构化字段查询
但它们在面对以下对象时会明显吃力:
- 图片
- 音频
- 长文本
- 视频
- 跨模态内容
原因很直接:
- 传统数据库擅长匹配“值”
- 向量数据库擅长匹配“意思”
关键词搜索 vs 向量搜索
搜索词:“手机”
-
关键词搜索
- 找不到只写了“移动电话”的文章
-
向量搜索
- 能知道“手机”和
iPhoneAndroid通信设备
在语义空间里距离很近
- 能知道“手机”和
所以本质差异是:
- 关键词搜索看 字面是否相同
- 向量搜索看 语义是否接近
NOTE
- 传统检索更像在做“字符串过滤”
- 向量检索更像在做“语义邻域搜索”
因此,向量数据库的价值,并不能替代所有传统数据库功能,可但是以补上 语义理解能力。
距离度量方式
点积(Dot Product)
点积衡量的是:
- 对应维度乘积之和
- 同时综合了 方向 和 大小
公式:
- 越同向、且模长也合适,点积通常越大
余弦相似度(Cosine Similarity)
余弦相似度只关心两个向量夹角,不太关心绝对长度。
公式:
- 常用于文本
因为很多文本场景里,重点是方向上的语义一致性,而不是长度本身。
欧氏距离(L2 Distance)
欧氏距离衡量的是两个向量在空间中的绝对距离。
公式:
- 常用于机器学习聚类
因为它更直接反映空间中的几何距离。
核心挑战与 ANN
暴力 KNN
如果完全不建索引,而是对数据库里每一条向量都和查询向量做一次比较,这就是最直接的 KNN(k-Nearest Neighbors)暴力检索。
它的问题在于:
- 数据量很大
- 向量维度很高
- 每次查询都要扫描全库
因此在海量高维数据下,计算成本会变得非常高。
于是就出现了一个核心问题:
我们能不能不查所有向量,只查“最有希望的那一小部分”?
这就是 ANN(Approximate Nearest Neighbor,近似最近邻) 的出发点。
ANN 的目标是:
- 用更快的速度
- 更低的内存 / 计算代价
- 找到“足够接近”的近邻
准确度 / 速度 / 内存的权衡
- 准确度(Accuracy):KNN 最强
- 查询速度(Speed):HNSW 很突出
- 内存效率(Memory):IVF / PQ 更有优势
当前三类主流索引就是:
- HNSW:基于图
- IVF:基于倒排文件 / 聚类
- PQ:基于量化压缩
WARNINGANN 的关键词是 Approximate。
- 它追求的是“高概率找到足够好的邻居”
- 它默认接受一定程度的近似误差
这是性能提升的代价,也是它的本质。
HNSW
HNSW(Hierarchical Navigable Small World) 是一种基于图的索引方法。
- 检索速度强
- 需要较高内存开销
- 因为要维护分层图结构
它的理解可以拆成三步:
- 先理解 Skip List
- 再理解 NSW
- 最后把二者拼起来得到 HNSW
Skip List
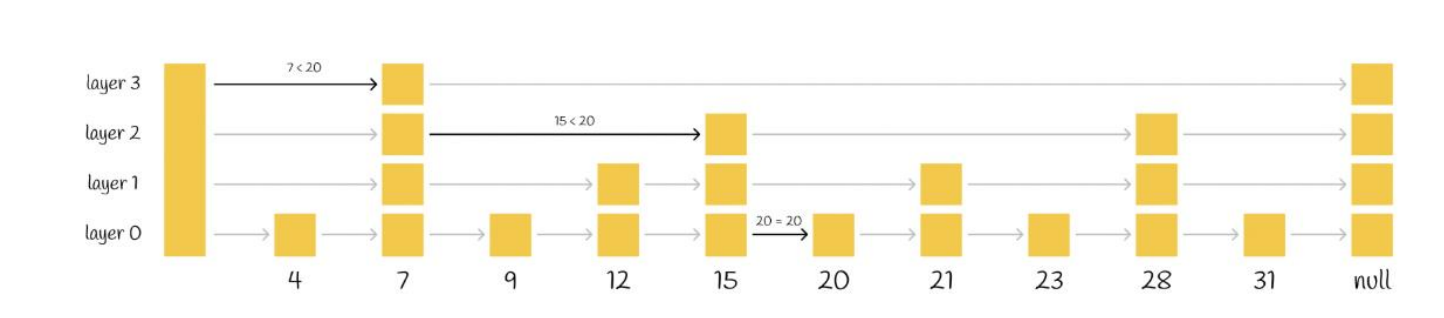
跳表(Skip List) 解决的问题是:在有序链表里找元素,如果每次都从头一个个走,太慢。
做多层索引:
- 底层(Layer 0):包含所有元素
- 高层(Layer 1, Layer 2, …):只保留少量元素,像“高速公路”
查找时:
- 先从最高层开始做粗定位
- 确定大概范围后
- 再逐层下降做细查
这是一种:
- 先粗后细
- 逐层缩小范围
的典型结构。
NSW
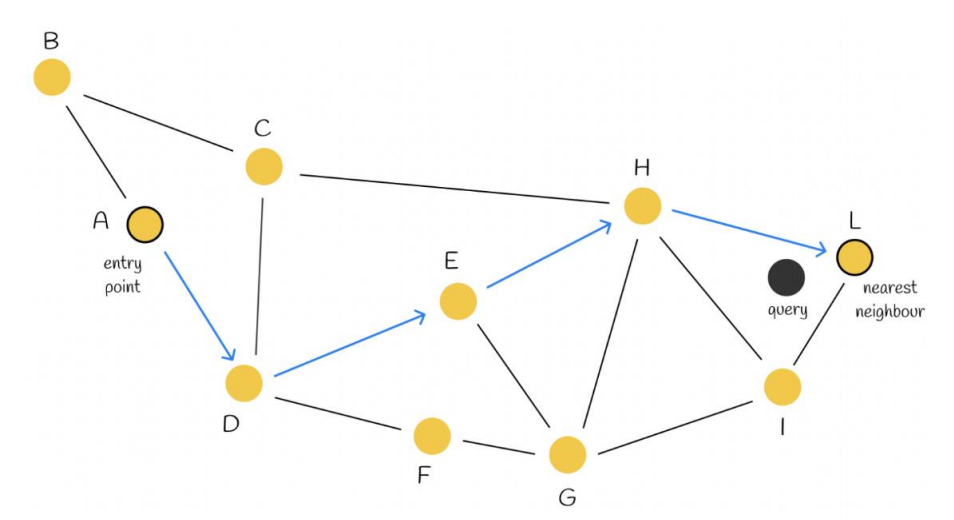
NSW(Navigable Small World) 可以理解成一种“可导航的小世界图”。
它背后的直觉来自:
- 六度分隔理论
在向量空间中:
- 每个向量是一个节点
- 距离相近的节点之间连边
搜索时使用 贪心搜索(greedy search):
- 随机选一个起点
- 看它所有邻居
- 如果某个邻居离目标更近,就跳过去
- 不断重复
- 直到当前节点已经比它所有邻居都更接近目标
关键优点是:
- 不需要遍历全体节点
- 可以顺着“越来越近”的边快速逼近目标
HNSW 的工作原理
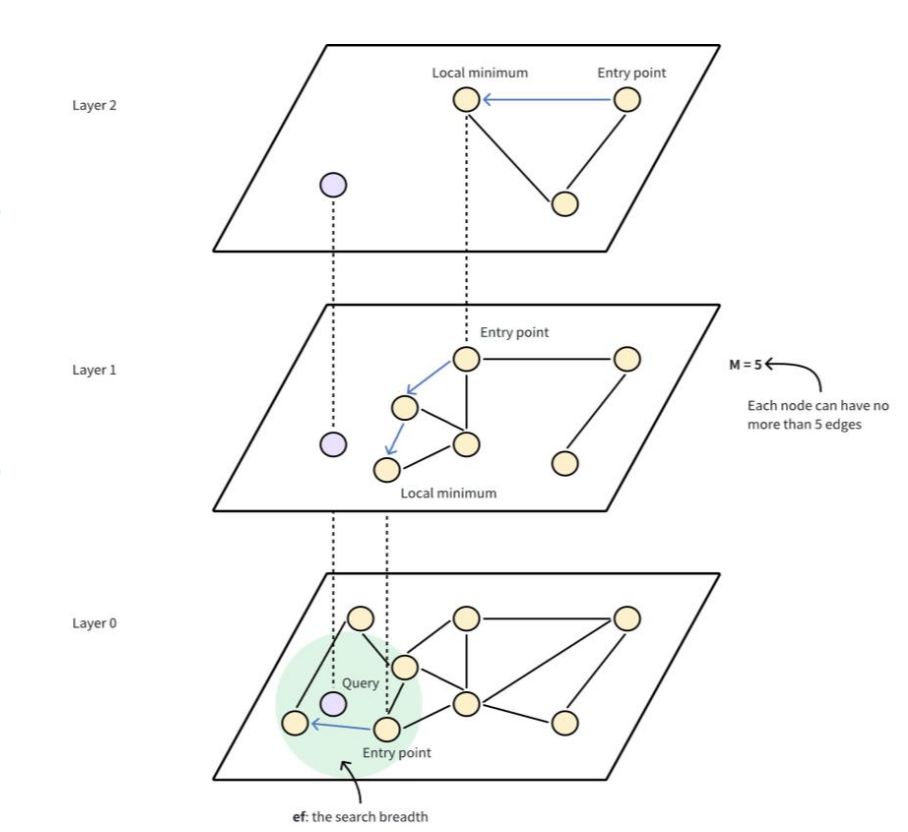
HNSW 把 NSW 图做成了 跳表式的多层结构。
它是很多层图叠在一起:
- 高层:节点少、边长、更适合粗定位
- 低层:节点多、边密、更适合精细搜索
工作原理:
- 入口点(entry point)
- 从顶层一个固定入口节点开始
- 贪婪搜索(greedy search)
- 在当前层持续移动到更靠近查询向量的邻居
- 层层下降(layer-by-layer descent)
- 当前层到达局部最优后,跳到下一层继续搜
- 底层精搜
- 越往下图越密,搜索范围越来越小,结果越来越精细
IVF(倒排文件索引)
IVF(Inverted File Index) 的核心思想是:
先聚类,把搜索范围缩到少数几个簇里,而不是全库都查。
过程:
- 聚类
- 用
k-means等方法把向量数据划分成多个簇 - 每个簇有一个中心点
- 用
- 分配
- 每个向量被分到离自己最近的中心所属簇中
- 反向索引
- 记录“某个聚类中心 -> 它下面有哪些向量”
- 搜索
- 查询向量先和各中心比较
- 只选择最有希望的若干簇
- 再在这些簇内部继续搜索
它的本质是:
- 先做粗筛
- 再做局部检索
因此它能显著减少候选集合大小。
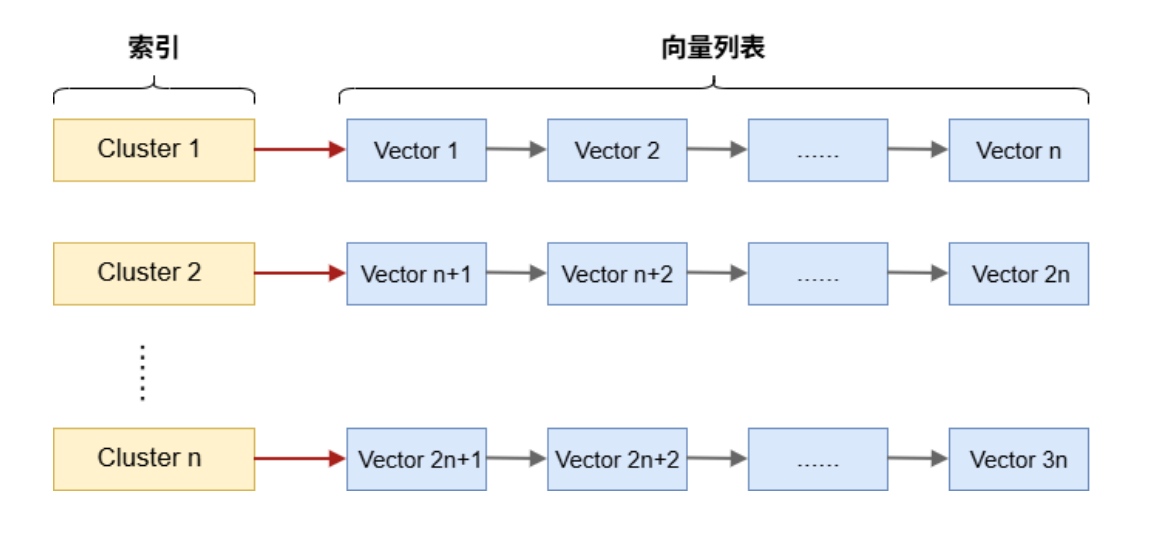
TIPIVF 的思路和很多数据库 / 检索系统里的“先缩小搜索空间”是一致的。
只不过这里缩小的依据不是布尔条件, 而是“查询向量更可能落在哪些聚类里”。
PQ(乘积量化)
PQ(Product Quantization,乘积量化) 的核心思想是:
把高维向量切成多段,在每段里分别做量化压缩。
这会让向量存储成本大幅下降,也让距离计算可以被近似为查表求和。
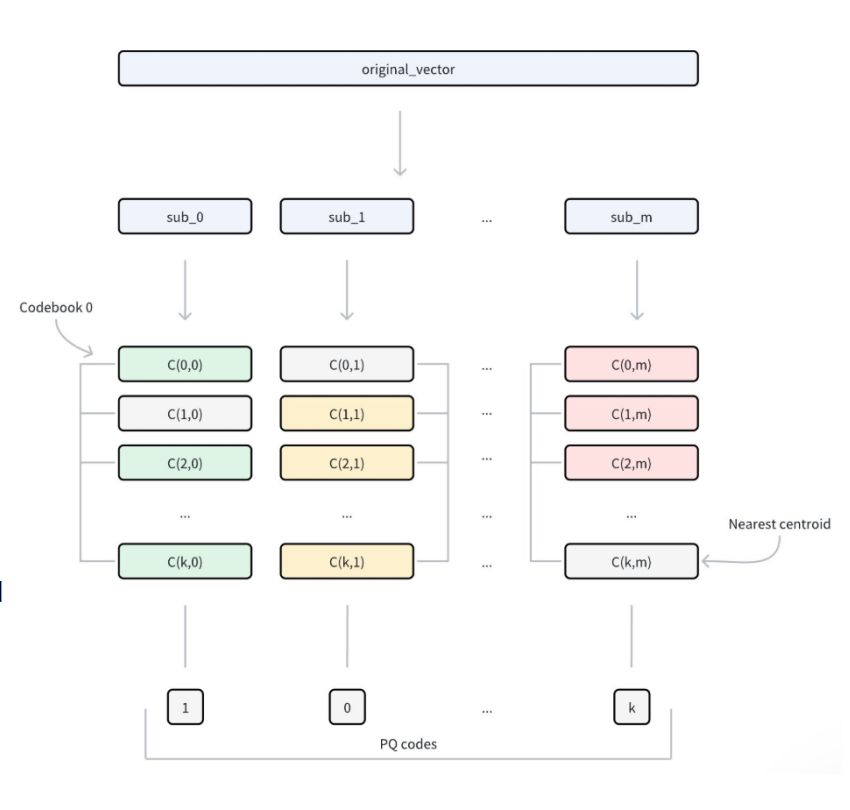
构建流程:
- 向量切分
- 把一个
D维向量平均切分成m个子段
- 把一个
- 子空间聚类
- 在每个子空间里分别聚类
- 每个子空间得到一个包含
k个中心的“密码本(codebook)”
- 编码替换
- 对数据库中的每条向量,查看每个子段最接近该子空间密码本中的哪个中心
- 不再存原始子段
- 只存“中心编号(ID)”
所以 PQ 存下来的不是原向量,而是:
- 每个子段对应哪个中心的编号
这就是压缩的来源。
搜索过程
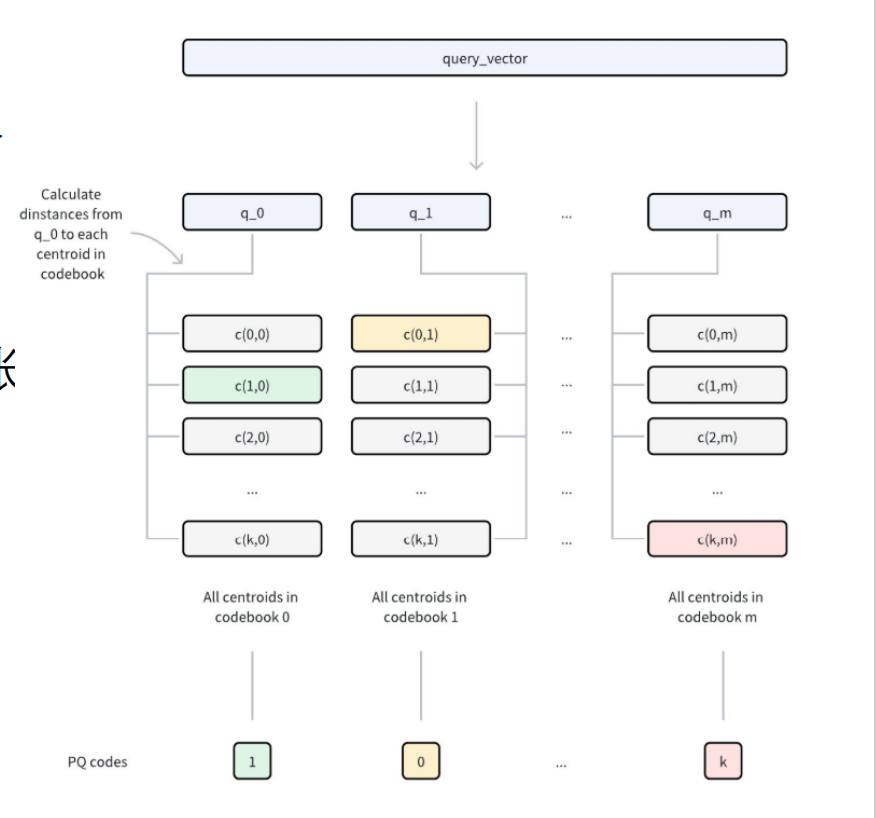
查询时,slides 给出的流程是:
- 查询向量
Q到来 - 也把
Q切成m个子段 - 对每个子段,计算它到对应子空间
k个中心的距离 - 提前生成一张距离表
- 对数据库中的被量化向量,只需把各子段对应中心的距离查表后相加
- 得到一个近似距离
- 不再和原始高维浮点向量逐维计算
- 而是把大量计算替换成“查表 + 求和”
这会非常快。
NOTEPQ 的核心收益是:
- 压缩存储
- 加速距离估算
它牺牲的是一部分精度,因为距离不再是原向量上的精确距离, 而是量化后的近似距离。
IVF-PQ 的结合应用
IVF_PQ 结合了 IVF 和 PQ 的优势。
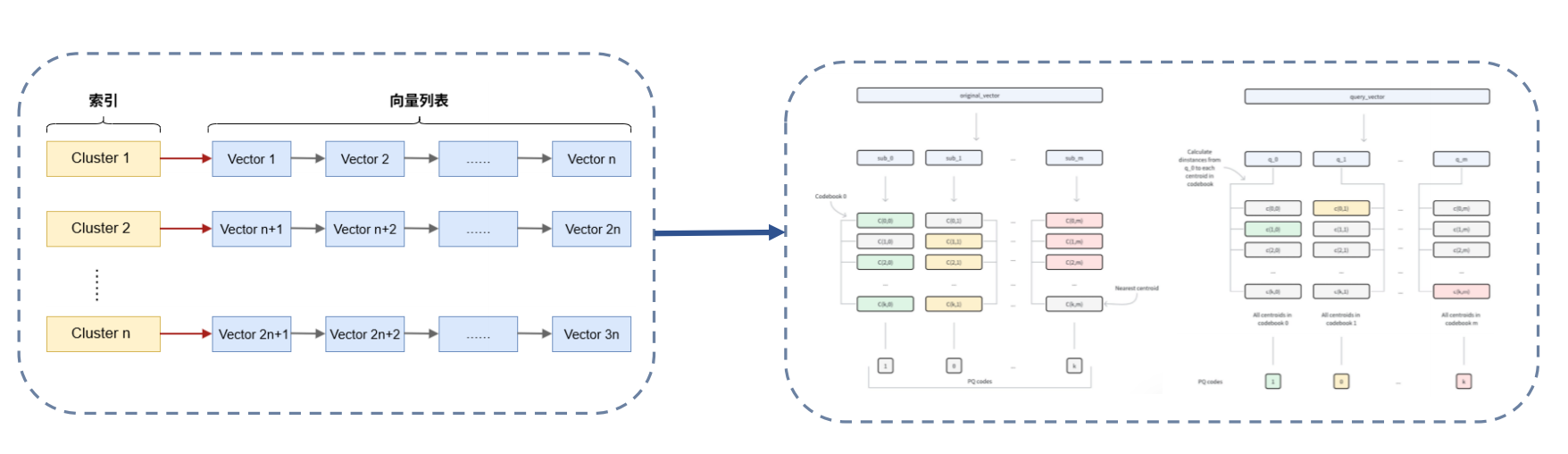
可以概括成两层结构:
第一层:IVF 粗量化
- 用高精度向量训练出
N个聚类中心 - 查询时先定位“最可能相关”的若干簇
- 过滤掉绝大多数无关数据
可以过滤掉 99% 以上的数据
第二层:PQ 细量化
- 簇内向量不再完整存储
- 而是统一做 PQ 编码压缩
- 检索时在簇内直接做 PQ 查表求和
IVF 负责先找大致区域 PQ 负责在区域内部做压缩后的快速搜索
这类组合索引很典型,因为工程上常常不是单一思路能解决所有问题,而是:
- 先做候选过滤
- 再做快速近似排序
查询增强能力
只会做“向量最近邻搜索”还不够。
一个真正能落地的向量数据库,还要支持更复杂的查询组织方式。
混合搜索(Hybrid Search)
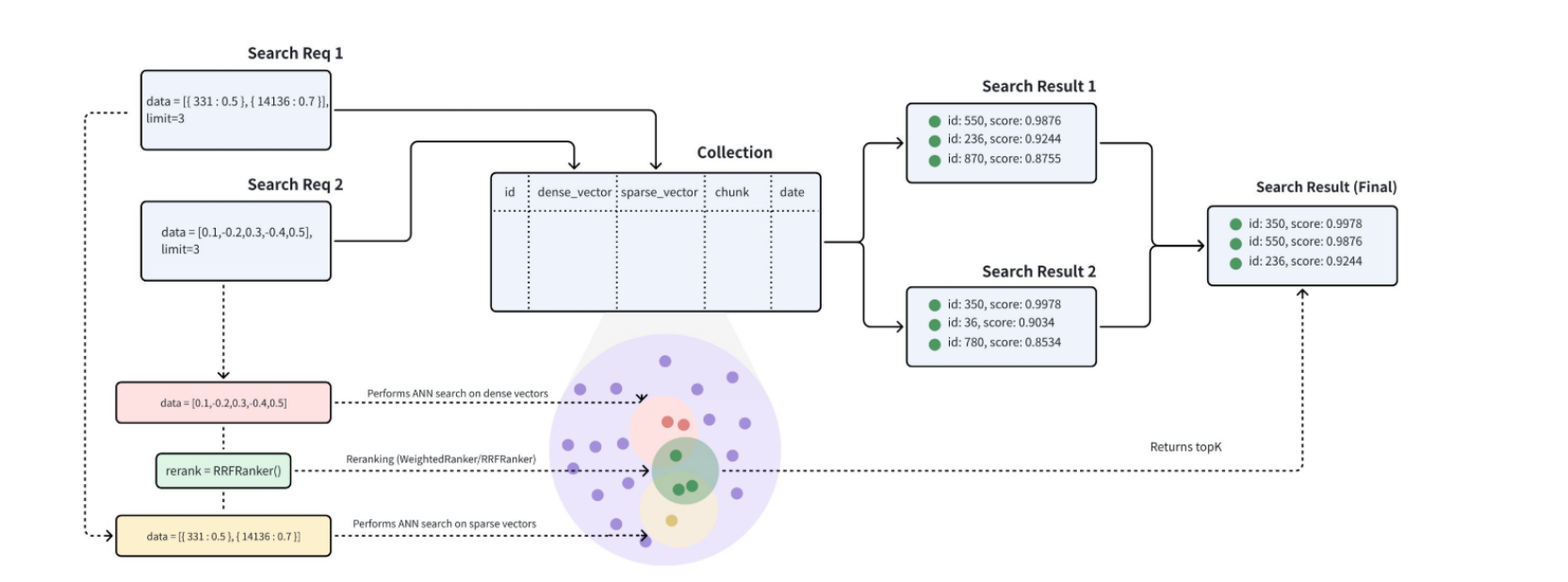
两类向量:
稀疏向量(sparse vector)
- 维度很高
- 大多数位置都是 0
- 只有极少数位置有值
这类表示通常擅长:
- 关键词匹配
- 精确术语命中
密集向量(dense vector)
- 大部分位置都是非零实数
- 由深度学习模型压缩得到
这类表示通常擅长:
- 语义关系建模
- 概念层面的相似性
因此:
- 稀疏向量 更适合“字面上的准”
- 密集向量 更适合“语义上的像”
混合搜索的意义就在于把两者结合起来:
既保留密集向量带来的语义理解能力,
也保留稀疏向量带来的关键词精确相关性。
这会让搜索结果更稳。
例如:
- 用户搜一个专业术语
- 系统既不能只看语义而把术语约束放丢
- 也不能只看关键词而完全看不懂上下文
这时 hybrid search 就非常有价值。
过滤搜索(Filtered Search)
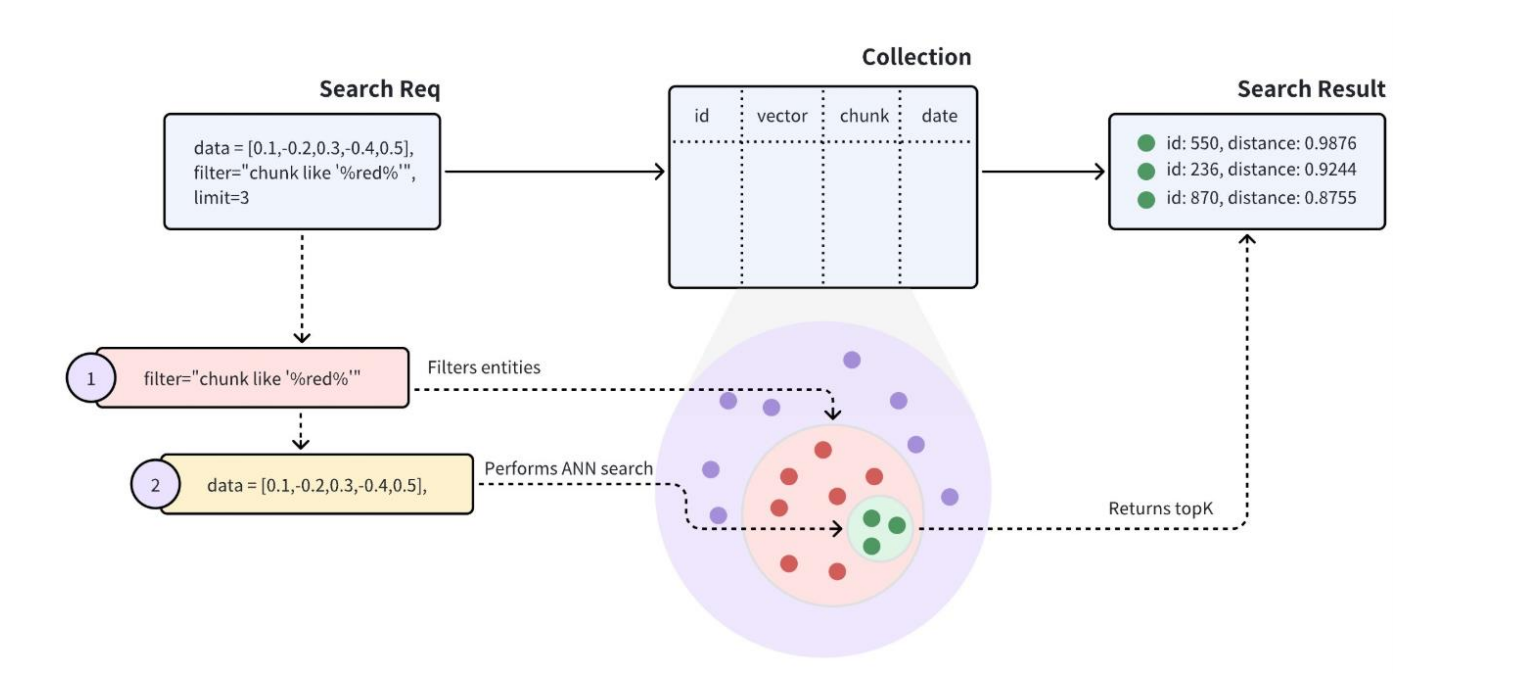
过滤搜索 指的是:
在相似度向量检索之外,再叠加传统精确条件。
也就是:
- 先有“像不像”
- 再有“符不符合结构化条件”
带元数据(metadata)的搜索
- 先找语义上最接近的内容
- 但只保留满足某些 metadata 条件的对象
例如可以是:
- 只看某个时间范围
- 只看某个类别
- 只看某个作者 / 某个来源
- 只看某个租户 / 某个用户可见范围
所以过滤搜索其实是在说:
- 向量数据库不能只有“向量”
- 它还必须和“结构化元数据”协同工作
主流向量数据库概览
当前系统大致分成两类:
独立向量数据库
- Milvus
- Pinecone
- Qdrant
- Chroma
这类系统通常以向量检索为核心能力来设计。
传统数据库的向量化扩展
- PostgreSQL
- RedisVL
- Elasticsearch
这类系统原本不是纯向量数据库,但逐步加入了向量能力。
因此实际工程里常见两种路线:
- 从零选一个“纯向量数据库”
- 或者在已有数据库 / 检索系统上增加向量支持
多模态向量数据库
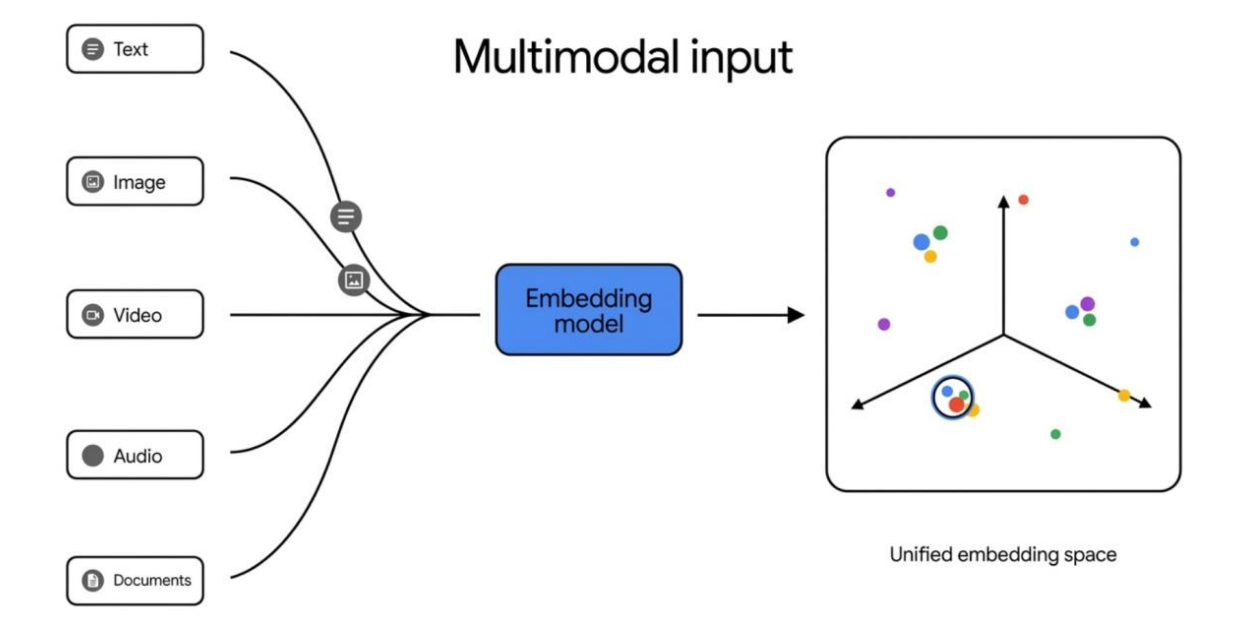
多模态向量数据库 的核心就是:
把文本、图像、音频、视频等不同模态的数据,尽量放进同一个统一特征空间中进行存储和检索。
传统割裂式检索的痛点
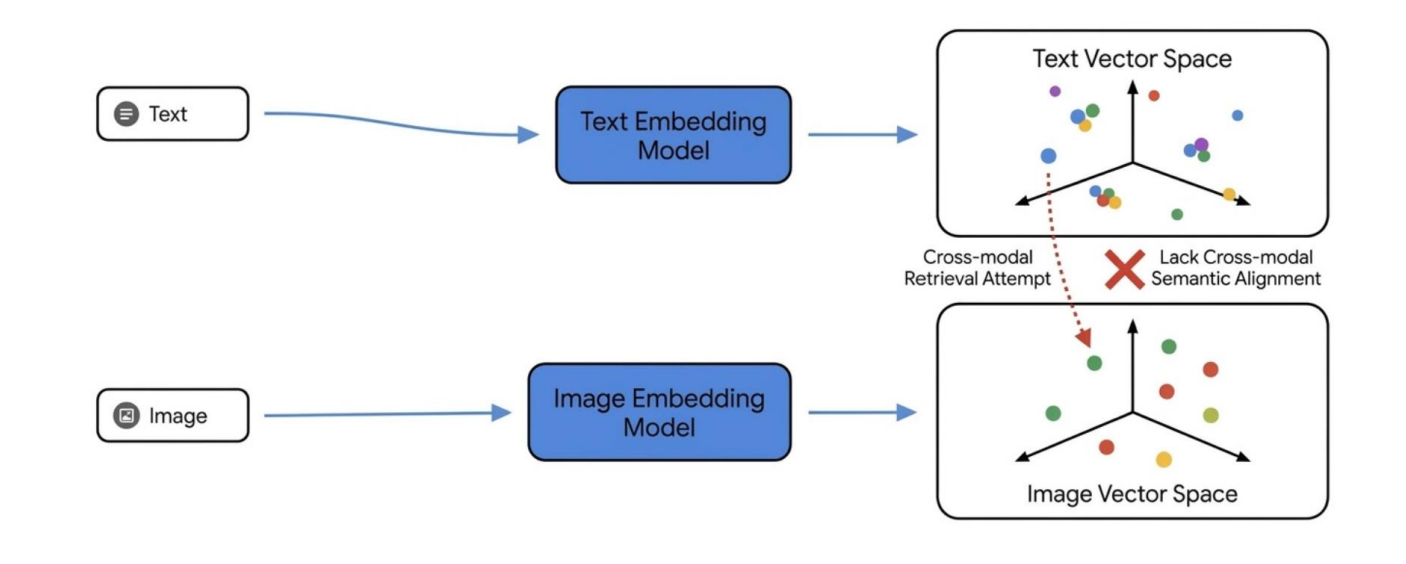
旧架构的问题:
- 文本特征(例如 LLM 提取)
- 图像特征(例如 ResNet / ViT 提取)
经常被放在 完全独立的向量空间 中。
这会导致两个问题:
- 跨模态检索困难
- 你无法自然地拿一句文本去找图片
- 也无法自然地拿一张图去找文本
- 语义对齐差
- 不同模态之间来回切换空间,容易丢上下文
- 效率低
多模态向量数据库的核心能力
统一的特征空间
支持将:
- 文本
- 图像
- 音频
- 视频
的特征向量统一放到同一个高维空间中。
多模态对齐模型
关键支撑是:
- CLIP 这类强对齐模型
它可以学到这样的语义关系:
- 图片里的猫
- 文本里的“一只猫”
应该在向量空间里彼此接近。
所以多模态向量数据库追求的是:
- 跨模态可比
- 跨模态可搜
- 跨模态统一建模
这会把向量数据库从“文本向量库”或“图像向量库”进一步推进到更通用的统一语义基础设施。