

概述
这一章的核心是:
数据库允许多个事务并发执行,但并发执行的结果必须保持正确。Concurrency Control 要做的事情,就是设计事务访问数据的规则,使实际产生的调度满足隔离性,通常目标是 conflict serializability。
第 17 章已经给出理论工具:
- 事务、调度、冲突操作
- serial schedule / serializable schedule
- precedence graph
- conflict serializability
- isolation levels
第 18 章回答实现层问题:
DBMS 具体用什么协议,让实际并发调度保持正确?
本章主要内容:
- Lock-Based Protocols:基于锁的并发控制,重点是 Two-Phase Locking
- Deadlock Handling:死锁预防、检测、恢复
- Graph-Based Protocols:基于数据项偏序的协议
- Multiple Granularity:多粒度封锁
- Insert / Delete / Phantom:插入、删除与幽灵现象
- Index Concurrency:索引结构上的并发控制
- Multiversion Schemes:多版本并发控制
- Timestamp-Based Protocols:时间戳排序协议
- Validation-Based Protocols:验证协议 / 乐观并发控制
- Snapshot Isolation:快照隔离
- Weak Levels of Consistency:实践中的弱一致性级别
- Transactions across User Interaction:跨用户交互的事务处理
目录
- 概述
- Lock-Based Protocols
- Two-Phase Locking
- Two-Phase Locking 的证明
- 2PL 的变种
- Lock Manager
- Deadlock Handling
- Graph-Based Protocols
- Multiple Granularity
- Insert、Delete 与 Phantom
- Index Concurrency
- Multiversion Schemes
- Timestamp-Based Protocols
- Validation-Based Protocols
- Snapshot Isolation
- Weak Levels of Consistency
- Transactions across User Interaction
- 总结
Lock-Based Protocols
Lock 的基本思想
Lock 是控制并发事务访问同一数据项的机制。
事务访问数据项前,需要先向 concurrency-control manager 请求锁。只有锁被授予之后,事务才能继续执行。
数据项常见锁模式:
| 锁模式 | 英文 | 允许操作 | 请求指令 |
|---|---|---|---|
| Shared Lock | S-lock | 只读 | lock-S(Q) |
| Exclusive Lock | X-lock | 读 + 写 | lock-X(Q) |
直观理解:
- 读数据:申请
S锁 - 写数据:申请
X锁 - 多个事务可以同时读同一个数据项
- 某事务持有
X锁时,其他事务不能在该数据项上持有任何锁
锁相容矩阵
| 已持有 \ 请求 | S | X |
|---|---|---|
| S | true | false |
| X | false | false |
含义:
S和S相容:多个事务可以同时读S和X不相容:有人读时,别人不能写X和任何锁都不相容:有人写时,别人不能读写
如果请求锁无法立即授予,请求事务必须等待,直到所有不相容锁被释放。
只加锁还不够
考虑事务:
T2:lock-S(A);read(A);unlock(A);lock-S(B);read(B);unlock(B);display(A+B);这个事务每次访问前都加锁,但仍然不能保证可串行化。
问题在于:
T2读完A后立刻释放A的锁- 在
T2读B前,其他事务可能修改A或B - 最后显示的
A+B可能对应一个数据库中从未真实存在过的状态
所以关键不只是“访问前加锁”,还包括:
什么时候申请锁?什么时候释放锁?所有事务遵循什么共同规则?
Locking protocol 就是一组事务申请和释放锁的规则。
锁协议通过限制可能产生的调度来保证 serializability。
Lock-Based Protocols 的陷阱
基于锁的协议容易产生 deadlock。
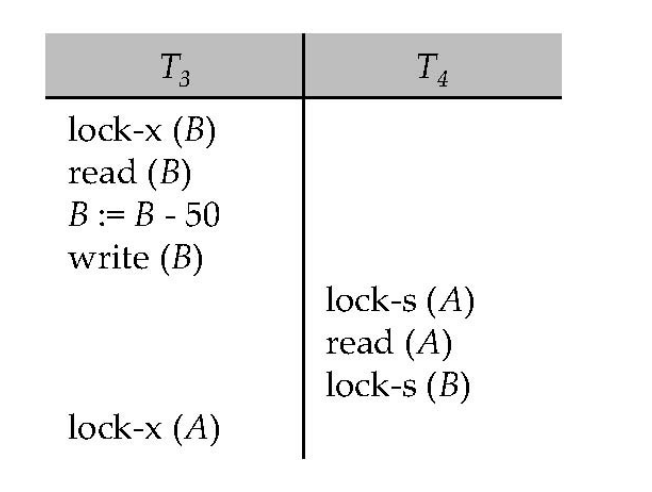
例子:
T3:lock-X(B);read(B);B := B - 50;write(B);...lock-X(A); // 需要等待 T4 释放 A
T4:lock-S(A);read(A);lock-S(B); // 需要等待 T3 释放 B此时:
T3持有B的X锁,等待AT4持有A的S锁,等待B- 二者都无法继续
这就是死锁。处理死锁时,需要回滚其中一个事务,并释放它持有的锁。
另一个问题是 starvation:
- 某事务一直等待某数据项的
X锁,但不断有其他事务获得该数据项的S锁 - 某事务在死锁恢复中反复被选为 victim 并回滚
并发控制管理器需要设计公平的等待队列和 victim 选择策略,避免 starvation。
Two-Phase Locking
Two-Phase Locking Protocol,2PL,两阶段封锁协议 是本章最重要的锁协议。
它保证产生的调度是 conflict-serializable。
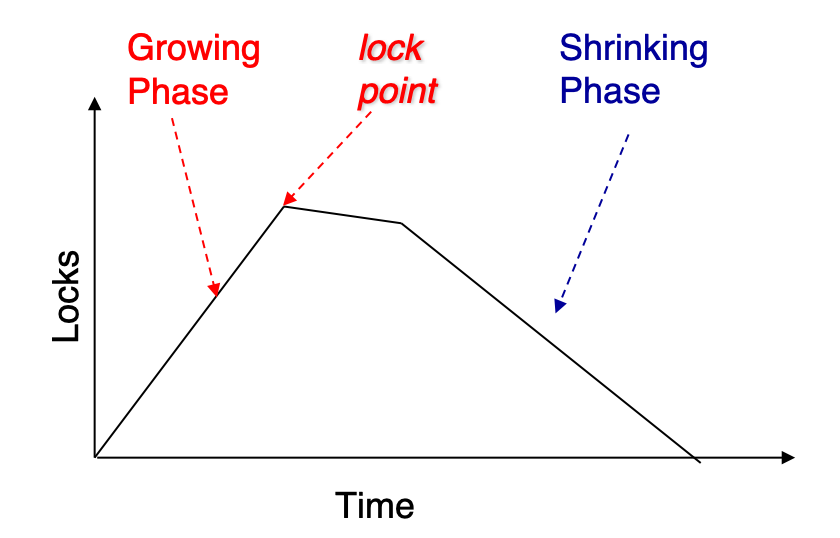
两个阶段
2PL 将事务的加锁 / 解锁过程分成两个阶段:
| 阶段 | 英文 | 允许行为 | 禁止行为 |
|---|---|---|---|
| 增长阶段 | Growing Phase | 获得锁 | 释放锁 |
| 收缩阶段 | Shrinking Phase | 释放锁 | 获得锁 |
核心规则:
一旦事务释放了任何一个锁,就不能再获得新的锁。
例子:
lock-S(A);read(A);lock-S(B);read(B);unlock(A);unlock(B);display(A+B);这个事务符合 2PL:
lock-S(A)、lock-S(B)属于 growing phaseunlock(A)、unlock(B)属于 shrinking phase- 释放
A之后没有再申请新锁
Lock Point
Lock Point,LP 是事务获得最后一个锁的时间点。
它是 2PL 证明中的关键概念:
LP(Ti)之前,Ti仍可能继续获得新锁LP(Ti)之后,Ti只能释放锁- 所有事务可以按照 lock point 的先后顺序串行化
Two-Phase Locking 的证明
要证明:
如果所有事务都遵循 2PL,则任意产生的调度都是 conflict-serializable,并且可以按照事务 lock point 的先后顺序串行化。
证明使用 precedence graph。
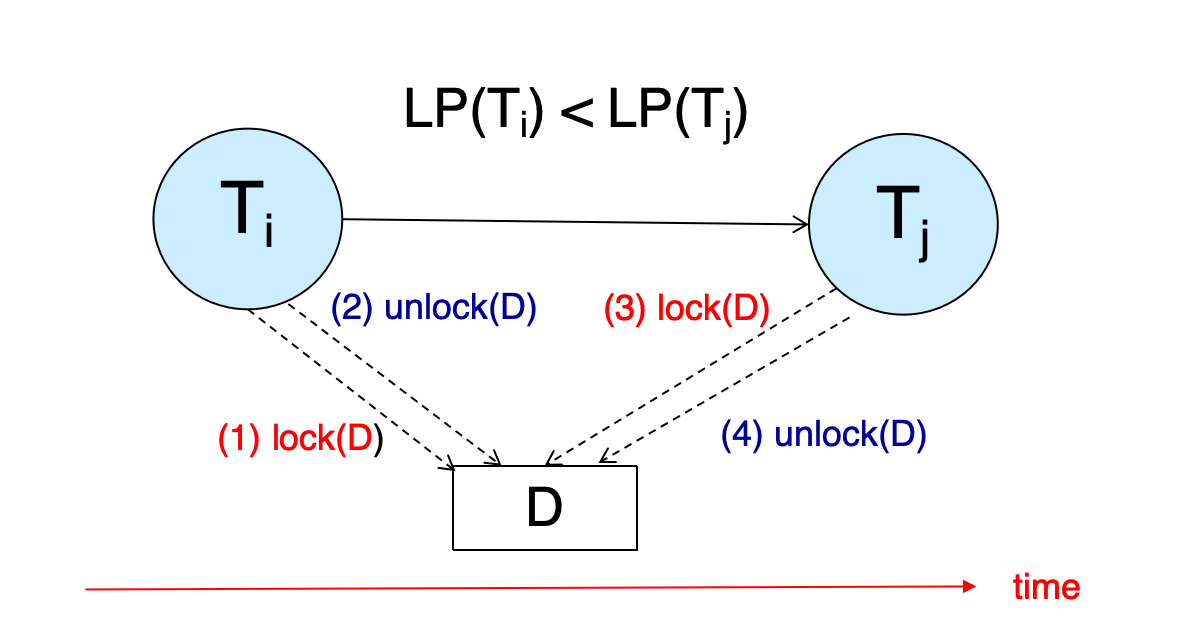
关键引理
设某个调度的 precedence graph 中存在边:
Ti -> Tj说明:
Ti和Tj在某个数据项D上有冲突操作Ti的冲突操作先于Tj的冲突操作
因为冲突操作至少有一个是写操作,所以二者在 D 上需要不相容的锁。
实际执行顺序必然类似:
Ti: lock(D)Ti: OPi(D)Ti: unlock(D)Tj: lock(D)Tj: OPj(D)Tj 能获得 D 上的锁,说明 Ti 已经释放了 D 上的不相容锁。
根据 2PL:
Ti已经执行unlock(D),说明Ti已进入 shrinking phase- 因此
LP(Ti)必然早于Ti的unlock(D) Tj正在执行lock(D),说明Tj还处于 growing phase- 因此
LP(Tj)不早于Tj的lock(D)
于是:
LP(Ti) < LP(Tj)结论:
precedence graph 中只要有边
Ti -> Tj,就必然有LP(Ti) < LP(Tj)。
 。
。
推出 precedence graph 无环
如果 precedence graph 中存在环:
T1 -> T2 -> ... -> Tk -> T1由关键引理可得:
LP(T1) < LP(T2) < ... < LP(Tk) < LP(T1)这要求一个时间点小于自身,矛盾。
所以 precedence graph 无环,调度是 conflict-serializable。
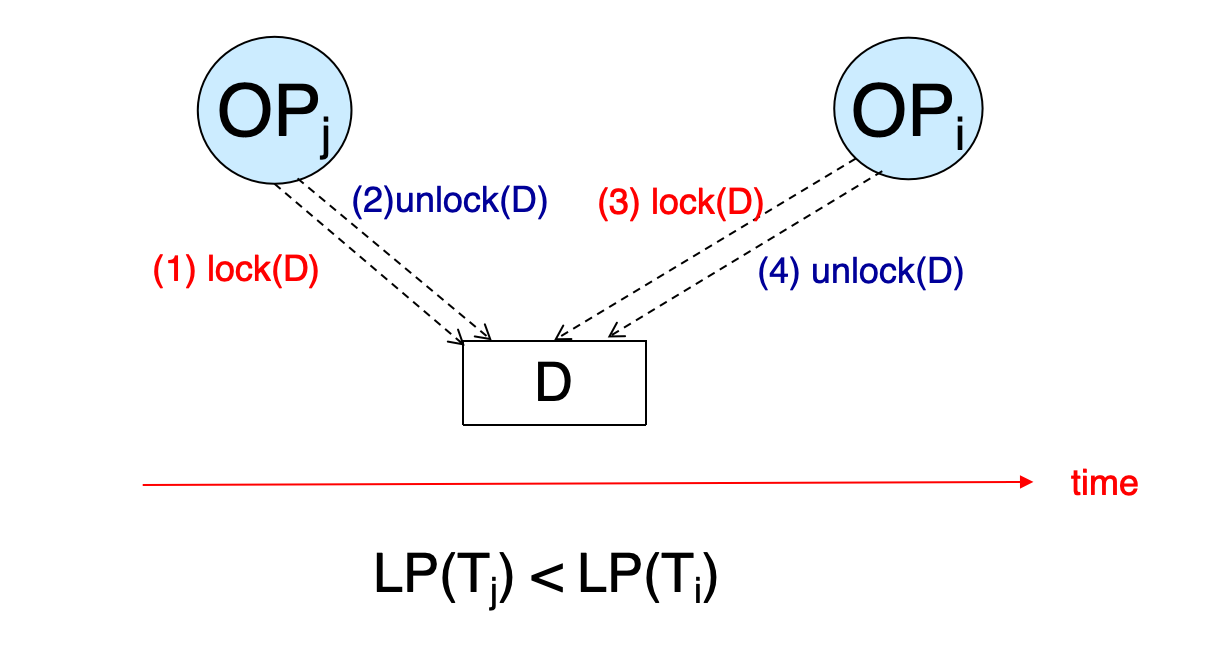
另一种证明角度:最小 Lock Point
也可以取所有事务中 lock point 最小的事务 Ti。
如果存在其他事务 Tj 的操作阻塞了 Ti 的操作,则必须有:
LP(Tj) < LP(Ti)这与 Ti 是最小 lock point 矛盾。
因此最小 lock point 的事务可以排在串行顺序的最前面。递归删除它后,对剩余事务重复这个过程,就得到一个按 lock point 排序的串行顺序。
2PL 的变种
Basic 2PL
Basic 2PL,基本两阶段封锁 只要求事务遵循两个阶段:
- 释放锁前可以不断申请锁
- 一旦释放锁,就不能再申请新锁
它保证 conflict serializability,但对恢复性要求不足:
- 可能产生不可恢复调度
- 可能导致 cascading rollback
Strict Two-Phase Locking
Strict 2PL,严格两阶段封锁:
事务必须一直持有所有
X锁,直到 commit 或 abort。
作用:
- 保证 recoverability
- 避免 cascading rollback
原因:
- 其他事务无法读到未提交事务写过的数据
- 如果写事务最后 abort,不会导致已经读到脏数据的事务跟着回滚
Rigorous Two-Phase Locking
Rigorous 2PL,强两阶段封锁:
事务必须一直持有所有锁,包括
S锁和X锁,直到 commit 或 abort。
特点:
- 更强,更简单
- 事务可以按照 commit 顺序串行化
- 很多数据库实现的“2PL”实际更接近 rigorous 2PL
2PL 是充分条件,非必要条件
2PL 保证冲突可串行化,但存在 conflict-serializable 调度无法由 2PL 产生。
例子:
T1: write(C)T2: write(C)T3: write(A)T1: write(A)冲突边:
T1 -> T2 // 二者都写 C,T1 在前T3 -> T1 // 二者都写 A,T3 在前precedence graph 无环,等价串行顺序可以是:
T3 -> T1 -> T2所以该调度是 conflict-serializable。
但它无法由 2PL 产生。对应 lock / unlock 调度为:
T1:lock-X(C);write(C);unlock(C);
T2:lock-X(C);write(C);unlock(C);
T3:lock-X(A);write(A);unlock(A);
T1:lock-X(A);write(A);unlock(A);T1 释放 C 后又申请 A,违反 2PL 的“释放锁后不能再加锁”。
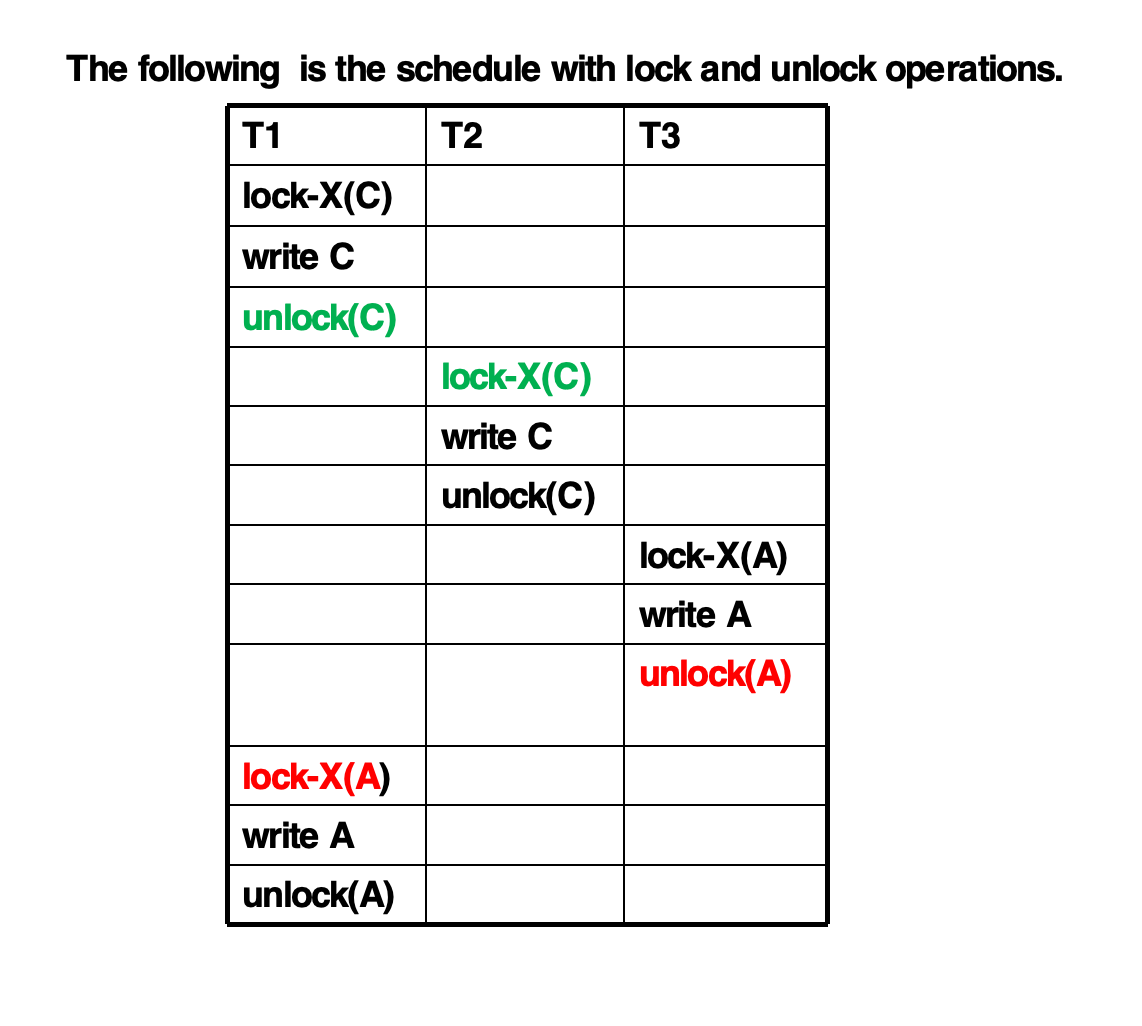
Lock Conversion
2PL 可以允许锁转换。
在 growing phase:
- 可以申请
S锁或X锁 - 可以把
S锁升级为X锁,称为 lock-upgrade
在 shrinking phase:
- 可以释放
S锁或X锁 - 可以把
X锁降级为S锁,称为 lock-downgrade
规则可以概括为:
- 前半段只能增强锁权限
- 后半段只能削弱锁权限
因此仍然保证 serializability。
Lock Manager
实际系统中,事务一般不会显式写 lock-S、lock-X。
应用程序只执行普通 read(Q)、write(Q),DBMS 内部由 lock manager 自动处理锁请求。
read(D) 的处理
read(D): if Ti already has a lock on D: read(D) else: wait until no other transaction has X-lock on D grant Ti an S-lock on D read(D)含义:
- 如果事务已经持有
D上的某种锁,可以直接读 - 如果没有锁,需要等待其他事务释放
D上的X锁 - 然后授予
S锁并执行读
write(D) 的处理
write(D): if Ti already has X-lock on D: write(D) else: wait until no other transaction has any lock on D if Ti has S-lock on D: upgrade lock on D to X-lock else: grant Ti an X-lock on D write(D)含义:
- 写操作需要
X锁 - 如果事务已有
S锁,需要做 lock upgrade - 如果其他事务在
D上持有任何锁,当前事务都要等待
在严格 / 强 2PL 中,所有锁通常在 commit 或 abort 后统一释放。
Lock Table
lock manager 维护 lock table,通常是内存中的 hash table:
- key:被锁定的数据项名
- value:该数据项上的请求队列
队列中记录:
- 已授予的锁
- 等待中的锁请求
- 锁模式
- 对应事务
处理规则:
- 新请求加入该数据项请求队列尾部
- 如果它与所有早于它的已授予锁相容,则授予
unlock会删除对应请求,并检查后续等待请求是否可以授予- 事务 abort 时,删除该事务所有已授予和等待中的锁请求
为了高效释放锁,系统通常还维护:
transaction -> list of locks held by transaction这样事务 commit / abort 时,可以快速找到并释放所有已持有锁。
Deadlock Handling
死锁定义
如果存在一组事务,使得集合中的每个事务都在等待集合中另一个事务释放锁,则系统进入 deadlock。
2PL 能保证 conflict serializability,但不能保证无死锁。
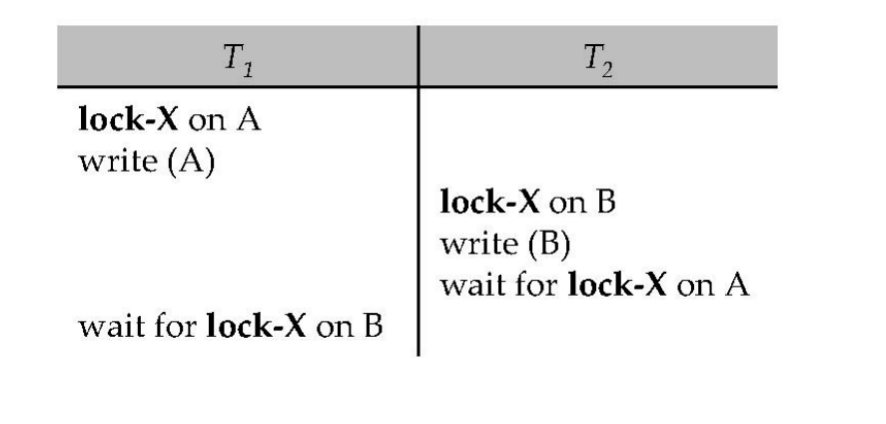
课件例子:
T1: write(X); write(Y)T2: write(Y); write(X)可能执行为:
T1: lock-X(A)T1: write(A)
T2: lock-X(B)T2: write(B)
T1: wait for lock-X(B)T2: wait for lock-X(A)此时:
T1持有A,等待BT2持有B,等待A- 二者都无法继续
Deadlock Prevention
死锁预防的目标是让系统永远不会进入死锁状态。
常见方法:
Predeclaration
事务开始前一次性锁住所有需要的数据项。
优点:
- 简单
- 可以避免循环等待
缺点:
- 事务必须提前知道所有访问对象
- 锁持有时间可能过长
- 并发度较低
数据项偏序
对所有数据项规定一个偏序。事务只能按照该顺序请求锁。
如果所有事务都按照同一偏序加锁,就不会形成循环等待。
这类方法与后面的 graph-based protocol 相关。
Timeout-Based Schemes
事务等待锁超过一定时间后自动回滚。
优点:
- 实现简单
- 可以避免长期死锁
缺点:
- 可能回滚并未死锁的事务
- timeout 阈值难设
- starvation 仍可能出现
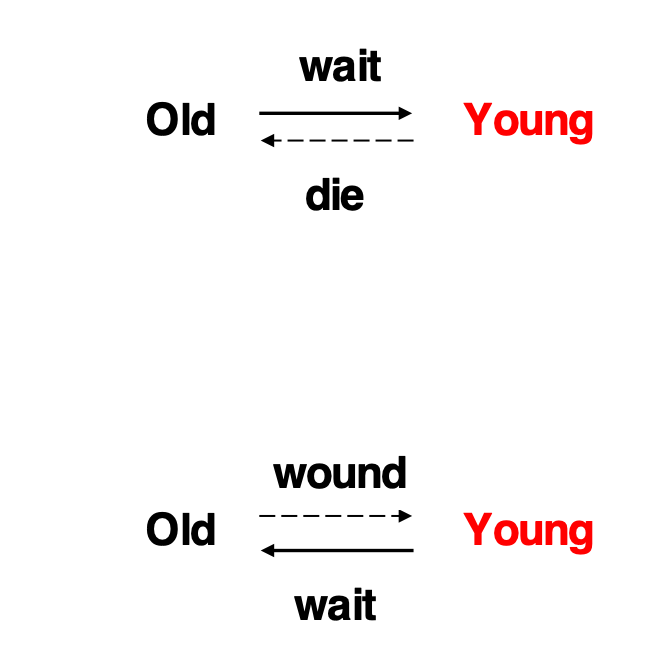
Wait-Die 与 Wound-Wait
这两种协议只用时间戳做死锁预防。
设:
- older transaction:时间戳更小
- younger transaction:时间戳更大
Wait-Die
wait-die 是 non-preemptive 方法。
规则:
- 老事务可以等待新事务释放数据项
- 新事务请求老事务持有的数据项时,新事务回滚
- 回滚后重启事务仍使用原来的时间戳
表格:
| 请求者 | 持有者 | 结果 |
|---|---|---|
| old | young | old waits |
| young | old | young dies |
Wound-Wait
wound-wait 是 preemptive 方法。
规则:
- 老事务请求新事务持有的数据项时,强制新事务回滚
- 新事务请求老事务持有的数据项时,新事务等待
- 回滚后重启事务仍使用原来的时间戳
表格:
| 请求者 | 持有者 | 结果 |
|---|---|---|
| old | young | old wounds young |
| young | old | young waits |
二者共同点:
被回滚事务重启时保留原时间戳,所以事务变老后优先级升高,可以避免 starvation。
Deadlock Detection
死锁也可以不预防,改为检测。
使用 wait-for graph:
G = (V, E)其中:
V:系统中的事务Ti -> Tj:Ti正在等待Tj释放某个数据项
当 Ti 请求的数据项正在被 Tj 持有时,加入边:
Ti -> Tj当 Tj 不再持有 Ti 所需数据项时,删除这条边。
关键结论:
wait-for graph 中存在有向环,当且仅当系统存在死锁。
系统需要周期性运行 cycle detection 算法。
[插图占位|slides p.24] 截取整页图:wait-for graph 的定义。建议在图旁边标注
Ti -> Tj表示Ti等待Tj。
Deadlock Recovery
检测到死锁后,需要选择某个事务作为 victim 回滚。
选择 victim 时通常考虑:
- 事务已经执行了多久
- 已经持有多少锁
- 已经修改多少数据
- 回滚代价
- 过去被回滚次数
回滚方式:
| 方式 | 含义 |
|---|---|
| Total rollback | 整个事务 abort,然后重启 |
| Partial rollback | 只回滚到足以打破死锁的位置 |
为了避免 starvation,需要把“事务已经被回滚的次数”加入 victim 选择成本。
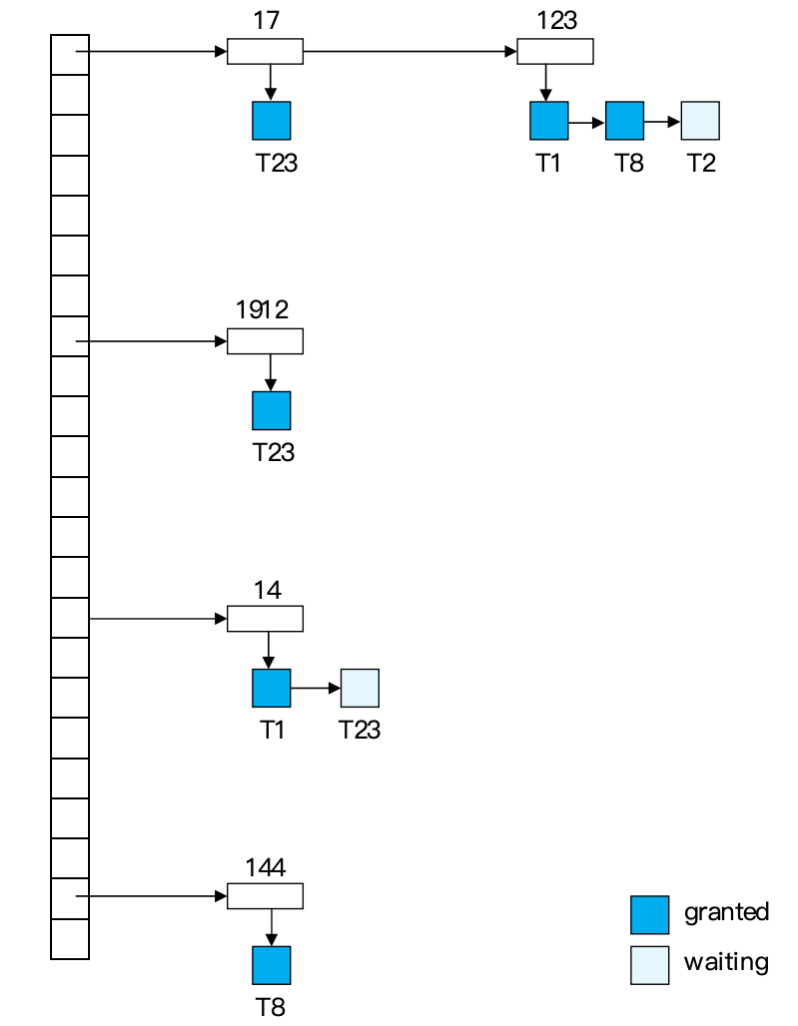
例题:根据 lock table 判断死锁
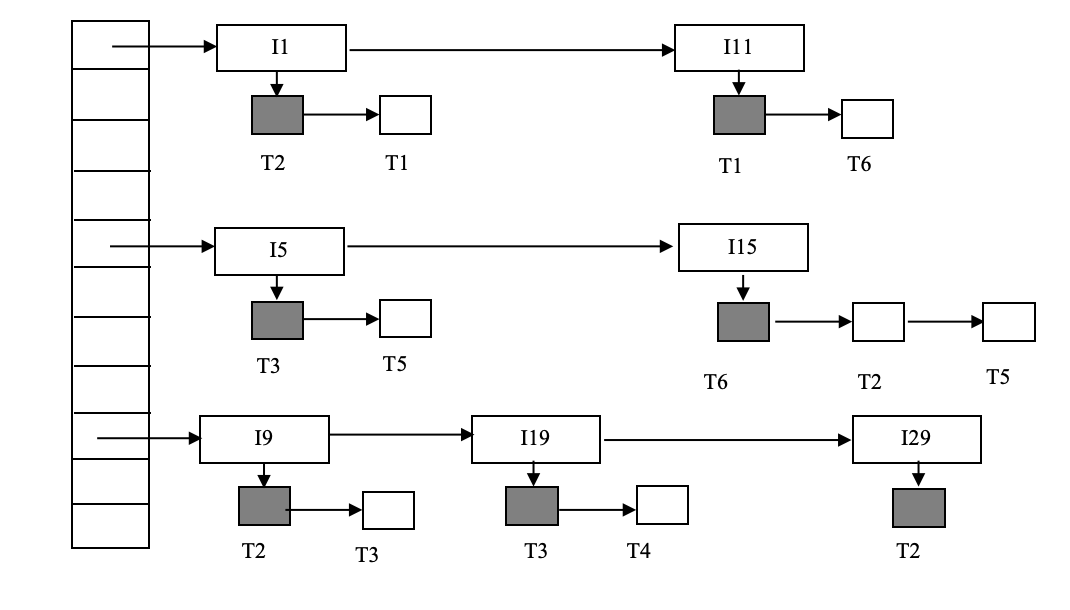
给定一个 lock table:
- 6 个事务:
T1到T6 - 数据项:
I1, I11, I5, I15, I9, I19, I29 - 黑色方块表示 granted lock
- 空方块表示 waiting request
从图中读出关键等待关系:
I1: T2 granted, T1 waiting => T1 -> T2I11: T1 granted, T6 waiting => T6 -> T1I15: T6 granted, T2 waiting => T2 -> T6于是得到环:
T1 -> T2 -> T6 -> T1所以发生死锁的事务是:
T1, T2, T6打破死锁时,回滚环中的任意一个事务都可以。若题目没有给出回滚代价,可以说明:
T2持有锁较多,回滚代价可能较高T1和T6持有锁较少- 选择
T6或T1都能打破环;若按“锁少、影响小”粗略判断,T6是合理 victim
第三问的数据结构:
transaction -> list of locks held by transaction这样事务 commit / abort 时,可以快速释放它持有的全部锁。
Graph-Based Protocols
Graph-based protocols 是 2PL 的替代方案。
基本思想:
- 对所有数据项集合
D = {d1, d2, ..., dh}定义一个偏序-> - 如果
di -> dj,任何同时访问di和dj的事务都必须先访问di,再访问dj - 数据项集合可以看作一个有向无环图,称为 database graph
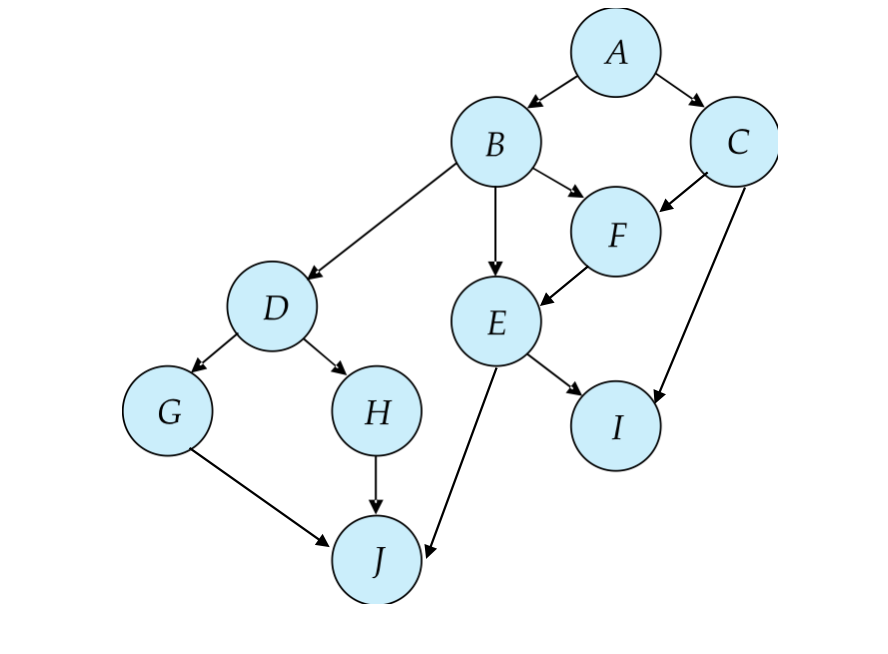 。
。
Tree Protocol
Tree protocol 是一种简单的 graph protocol。
规则:
- 只允许
X锁 - 事务的第一个锁可以加在任意数据项上
- 后续事务只有在持有父节点锁时,才能锁子节点
- 数据项可以在任意时间解锁
- 一个事务释放过某个数据项后,不能再次锁该数据项
它保证:
- conflict serializability
- deadlock freedom
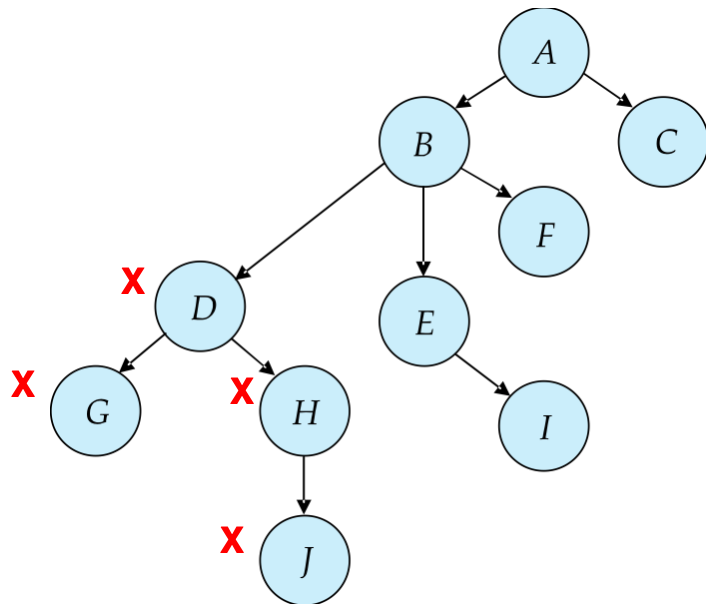
Tree Protocol 的优缺点
优点:
- 可以比 2PL 更早释放锁
- 等待时间可能更短
- 协议无死锁,不需要 deadlock rollback
缺点:
- 不保证 recoverability
- 不保证 cascade freedom
- 需要额外引入 commit dependency 来保证 recoverability
- 事务可能为了访问某个节点而锁住一些并不真正需要的数据项
- 锁开销和等待时间可能增加
补充:
- 有些调度可以由 tree protocol 产生,但不能由 2PL 产生
- 有些调度可以由 2PL 产生,但不能由 tree protocol 产生
Multiple Granularity
为什么需要多粒度封锁
如果所有锁都加在 record 级别:
- 并发度高
- 锁数量多
- lock manager 开销大
如果所有锁都加在 table / database 级别:
- 锁数量少
- 并发度低
Multiple Granularity 允许数据项有不同大小,形成层次结构:
database area file / table record当事务显式锁住某个节点时,会隐式锁住该节点的所有后代节点。
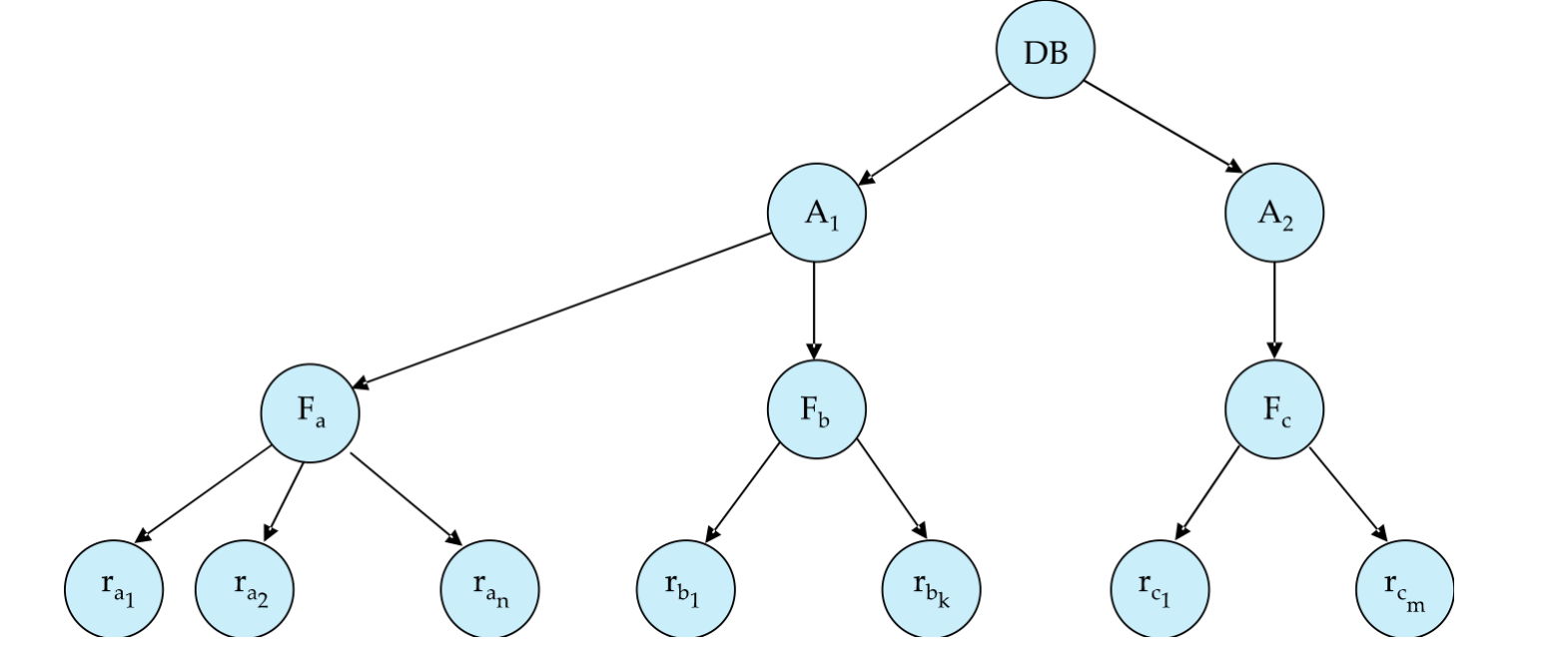
粒度选择
| 粒度 | 位置 | 优点 | 缺点 |
|---|---|---|---|
| fine granularity | 层次树较低处 | 并发度高 | 锁开销大 |
| coarse granularity | 层次树较高处 | 锁开销小 | 并发度低 |
Intention Locks
只用 S 和 X 不够,因为高层节点需要知道低层是否已经被锁。
多粒度封锁引入三种意向锁:
| 锁模式 | 含义 |
|---|---|
IS | intention-shared,表示事务将在更低层显式加 S 锁 |
IX | intention-exclusive,表示事务将在更低层显式加 X 或 S 锁 |
SIX | shared and intention-exclusive,当前子树被显式 S 锁住,同时事务还会在更低层加 X 锁 |
意向锁的作用:
让系统在高层节点判断能否加
S或X锁时,不必扫描所有后代节点。
例如:
T1想读整张表,可以在 table 节点申请S- 如果有事务正在表内某些 record 上写,需要在 table 或其祖先上持有
IX S与IX不相容,系统在 table 层就能发现冲突
多粒度锁相容矩阵
| 已持有 \ 请求 | IS | IX | S | SIX | X |
|---|---|---|---|---|---|
| IS | true | true | true | true | false |
| IX | true | true | false | false | false |
| S | true | false | true | false | false |
| SIX | true | false | false | false | false |
| X | false | false | false | false | false |
关键理解:
IS很弱,大多相容IX与S不相容,因为一个要在下面写,一个要读整个子树SIX很强,只与IS相容X与任何锁都不相容
多粒度封锁协议
事务 Ti 给节点 Q 加锁时必须遵守:
- 遵守锁相容矩阵
- 必须先锁 root,root 可以用任意模式
- 如果要对
Q加S或IS,则Q的父节点必须已由Ti持有IS或IX - 如果要对
Q加X、IX或SIX,则Q的父节点必须已由Ti持有IX或SIX Ti必须遵循 2PL:释放过任何节点后,不能再获得新锁- 只有当
Ti不再持有Q的任何子节点锁时,才能释放Q
所以:
加锁顺序:root -> leaf解锁顺序:leaf -> root多粒度封锁例子
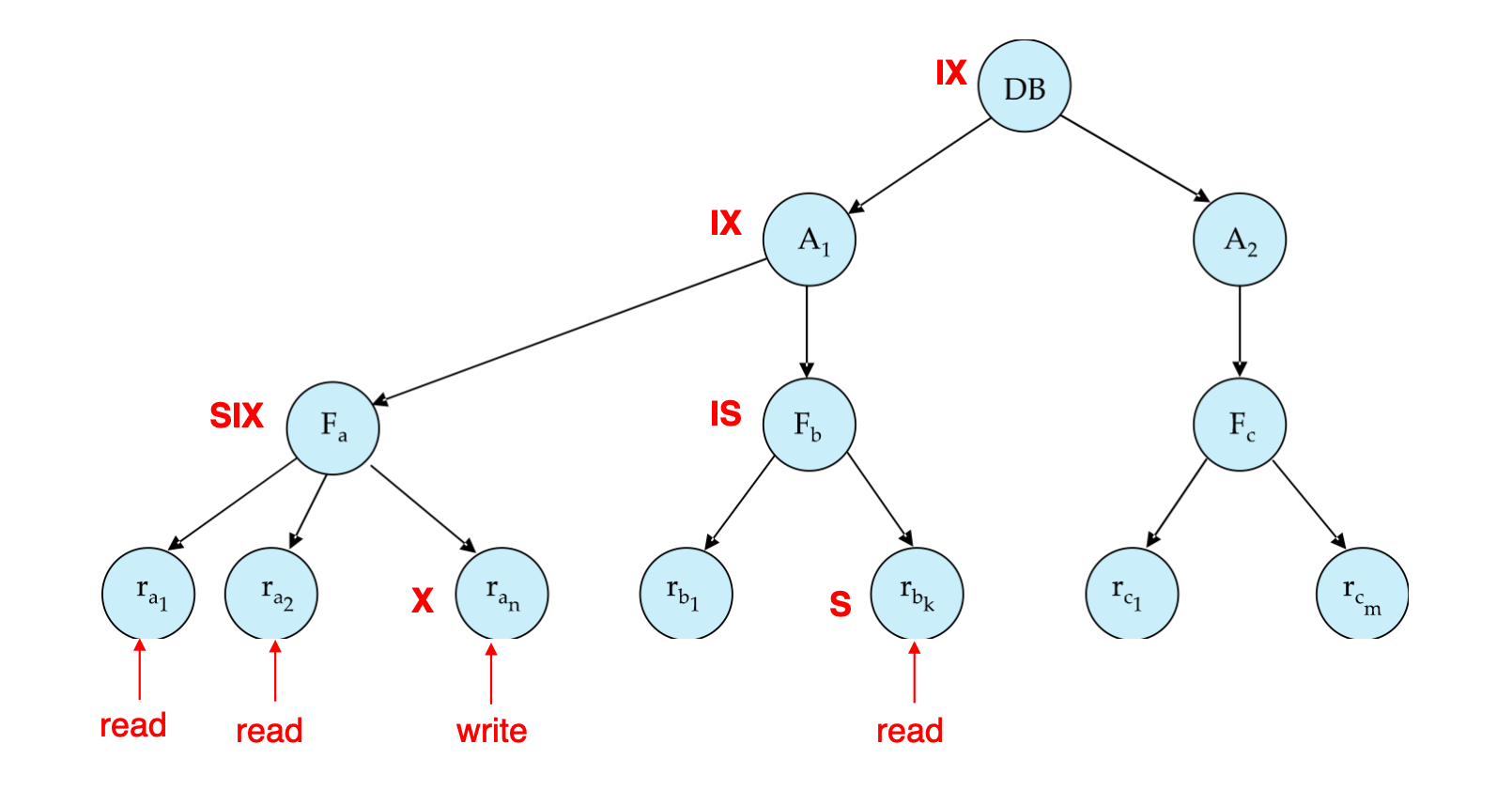
对应锁模式:
DB上加IX:表示整棵数据库树下面会有写操作A1上加IX:表示A1子树下面会有写操作Fa上加SIX:表示读Fa子树,同时还会对其中某些 record 写ran上加X:写某个 recordFb上加IS,rbk上加S:读某个 record
这个例子说明:
- 要写底层 record,需要在路径祖先上放
IX - 要读底层 record,需要在路径祖先上放
IS - 如果一边读整个文件,一边写其中少数 record,可用
SIX
Lock Granularity Escalation
如果某事务在某一层持有过多低层锁,系统可以进行 lock escalation:
许多 record-level S locks -> 一个 table-level S lock许多 record-level X locks -> 一个 table-level X lock作用:
- 减少锁数量
- 降低 lock manager 开销
代价:
- 提高锁粒度
- 降低并发度
Insert、Delete 与 Phantom
Insert / Delete 的基本规则
在 2PL 下:
- 删除 tuple:事务必须持有该 tuple 的
X锁 - 插入 tuple:事务会获得新 tuple 的
X锁
但只锁 tuple 仍会导致一个特殊问题:phantom phenomenon。
Phantom Phenomenon
课件例子:
T1: find sum of balances of all accounts in PerryridgeT2: insert a new account at PerryridgeT1 扫描已有 tuple,T2 插入一个新 tuple。
二者可能没有访问任何共同 tuple,但语义上冲突:
T1读取的是“满足条件的 tuple 集合”T2改变了这个集合本身
如果只对已有 tuple 加锁,T1 无法阻止 T2 插入新的满足条件的 tuple。
这就是幽灵现象。
直观例子:
同一事务中第一次查询 age = 18 的学生得到 100 人另一个事务插入一个 age = 18 的学生并提交第二次查询得到 101 人新增的第 101 条记录像“幽灵”一样出现。
锁 relation membership 信息
一种简单解决方案:
- 给 relation 额外关联一个数据项,用来表示“这个 relation 当前包含哪些 tuple”
- 扫描 relation 的事务对该数据项加
S锁 - 插入 / 删除 tuple 的事务对该数据项加
X锁
这样可以让 scan 与 insert/delete 冲突。
问题:
- 并发度很低
- 所有 insert/delete 都会与 relation scan 冲突
Index Locking Protocol
更高并发的方案是 index locking。
规则:
- 每个 relation 至少有一个 index
- 事务只能通过 index 找 tuple
- 事务执行 lookup 时,必须对访问过的 index leaf nodes 加
S锁 - 即使 leaf node 中没有满足条件的 tuple,只要范围查询访问到它,也要加锁
- 插入 / 更新 / 删除 tuple 时,必须更新该 relation 上所有 index
- 插入 / 更新 / 删除必须对受影响的 index leaf nodes 加
X锁 - 仍然遵守 2PL
这样:
- 范围查询锁住相关 leaf nodes
- 插入 / 删除要修改 leaf nodes
- 二者会产生冲突
- phantom 得到避免
Next-Key Locking
锁整个 index leaf 可能并发度较差。
更细的替代方法是:
- 锁住所有满足 index lookup 的 key values
- 再锁住范围后的 next key value
- lookup 使用
S锁 - insert / delete / update 使用
X锁
这样能保证:
范围查询与会改变该范围结果的插入 / 删除 / 更新事务发生冲突。
这类思想常称为 key-range locking 或 next-key locking。
例子:
查询条件:10 <= key <= 20已有 key:10, 12, 17, 25需要锁:
10, 12, 17, 25其中 25 是 next key。
如果另一个事务想插入 18,它会与这个范围锁冲突,从而避免 phantom。
Index Concurrency
索引并发的特殊性
Index 与普通数据项不同。
普通数据项是用户关心的数据内容;index 的作用是帮助定位数据。
索引结构访问频率极高,尤其是 B+-tree 的根节点和内部节点。如果对索引节点严格使用 2PL,会导致很低的并发度。
课件强调:
只要索引结构保持正确,并且能把访问引导到正确 leaf node,索引内部节点上的并发访问本身不必满足严格 serializability。
Crabbing Protocol
B+-tree 常用思想是 crabbing,也叫 latch coupling。
搜索 / 插入 / 删除时:
- 先以 shared mode 锁住 root
- 锁住当前节点的 child 后,释放 parent
- 沿树向下重复这个过程
- 到 leaf 后执行实际访问
- 插入 / 删除时,将 leaf lock 升级为 exclusive mode
- 如果 split 或 coalesce 需要修改 parent,再对 parent 加 exclusive lock
这个过程提前释放 parent lock,因此不严格遵循 2PL。
但它对索引是可以接受的,因为:
- 内部节点读到的具体值并非最终业务结果
- 只要算法能到达正确 leaf,索引访问就是正确的
- 数据项本身的隔离性仍由数据锁保证
问题:
- 搜索向下走,更新可能向上修改 parent
- 二者可能形成死锁
- 可以 abort 并重启 search,不必 abort 整个事务
更好的协议包括 B-link tree protocol,其直观思路是:
- 在获得 child lock 前释放 parent lock
- 通过额外链接处理释放和重新获得锁之间发生的结构变化
Multiversion Schemes
基本思想
多版本协议保留数据项的旧版本。
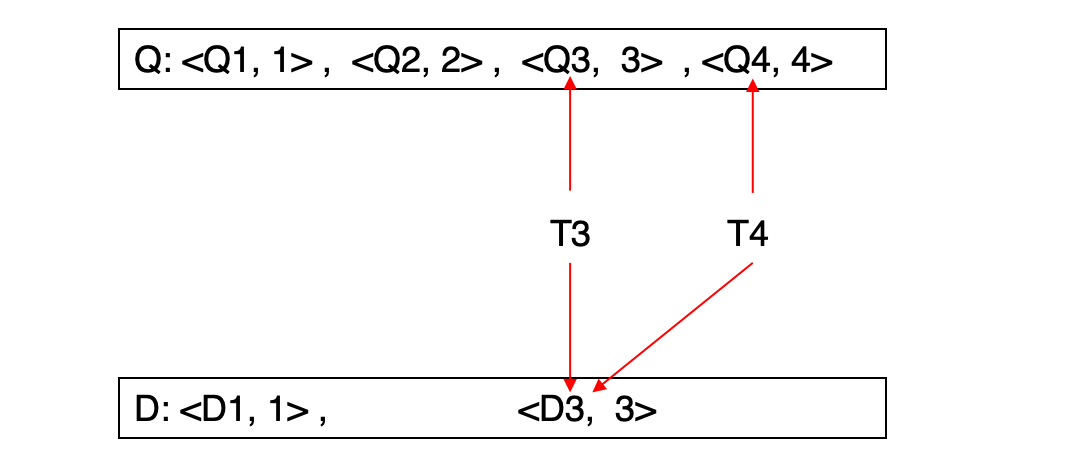
每次成功写入都会创建新版本:
Q: <Q1, 1>, <Q2, 2>, <Q3, 3>其中第二个字段通常是版本时间戳。
事务执行 read(Q) 时,系统根据事务时间戳选择合适版本。
好处:
读操作通常不需要等待写操作,因为系统可以返回一个合适的旧版本。
代价:
- 保存多个版本带来额外 tuple
- tuple 中需要保存版本元数据
- 旧版本需要 garbage collection
Multiversion Two-Phase Locking
多版本 2PL 区分两类事务:
SET TRANSACTION READ ONLY;SET TRANSACTION READ WRITE;Update Transactions
更新事务:
- 获取读锁和写锁
- 持有所有锁直到事务结束
- 遵循 rigorous 2PL
- 每次成功写入创建新版本
- 每个版本有一个时间戳,来自全局计数器
ts-counter
更新事务读数据项时:
1. 获得 S lock2. 读取最新版本更新事务写数据项时:
1. 获得 X lock2. 创建新版本3. 将新版本时间戳临时设为 ∞提交时:
1. 将本事务创建的版本时间戳设为 ts-counter + 12. ts-counter = ts-counter + 13. 释放所有锁例子:
写前:Q: <Q1, 1>, <Q2, 2>, <Q3, 3>
写时:Q: <Q1, 1>, <Q2, 2>, <Q3, 3>, <Q4, ∞>
提交后:Q: <Q1, 1>, <Q2, 2>, <Q3, 3>, <Q4, 4>
Read-Only Transactions
只读事务:
- 开始前读取当前
ts-counter作为TS(Ti) - 执行
read(Q)时,返回时间戳不超过TS(Ti)的最新版本 - 不需要等待更新事务
例子:
Q: <Q1,1>, <Q2,2>, <Q3,3>, <Q4,4>如果只读事务时间戳为 3,则读 Q 返回 Q3。
如果只读事务时间戳为 4,则读 Q 返回 Q4。
因此:
- 在更新事务提交后启动的只读事务,会看到更新后的版本
- 在更新事务提交前启动的只读事务,会看到更新前的版本
- 只读事务不阻塞写事务,写事务也不阻塞只读事务
- 产生的调度仍然 serializable
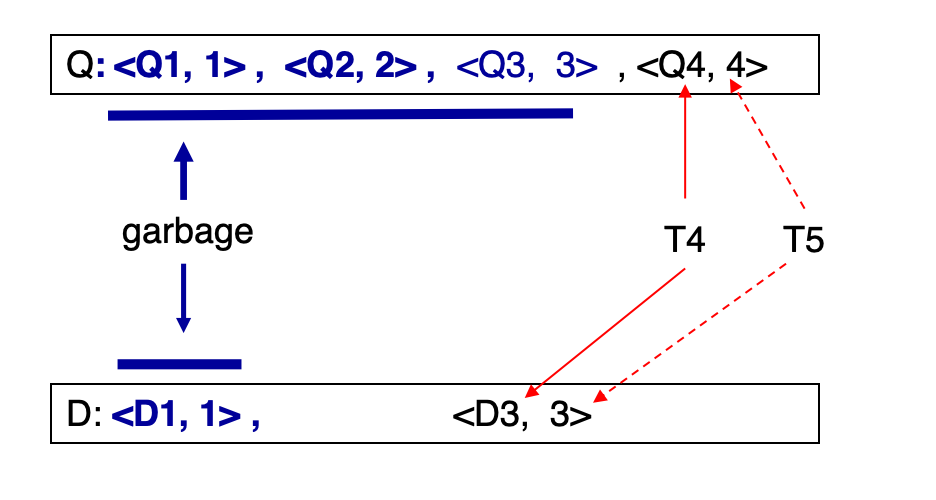
Garbage Collection
多版本会产生过期版本,需要回收。
规则:
找到系统中最老 active read-only transaction 的时间戳
Told。对每个数据项,保留所有版本中时间戳<= Told的最新版本,以及所有更新版本;更老版本可以删除。
例子:
Q: <Q1,1>, <Q2,2>, <Q3,3>, <Q4,4>如果当前最老活跃只读事务时间戳为 3,那么:
Q3仍可能被该事务读取Q4是更新版本,需要保留Q1、Q2已无用,可以回收
Multiversion Timestamp Ordering
每个数据项 Q 有一组版本:
<Q1, Q2, ..., Qm>每个版本 Qk 包含三类信息:
| 字段 | 含义 |
|---|---|
| content | 该版本的值 |
W-timestamp(Qk) | 创建该版本的事务时间戳 |
R-timestamp(Qk) | 成功读过该版本的最大事务时间戳 |
当事务 Ti 创建新版本 Qk 时:
W-timestamp(Qk) = TS(Ti)R-timestamp(Qk) = TS(Ti)当事务 Tj 读版本 Qk 且:
TS(Tj) > R-timestamp(Qk)则更新:
R-timestamp(Qk) = TS(Tj)读规则
事务 Ti 执行 read(Q) 时,找到版本 Qk:
Qk = W-timestamp <= TS(Ti) 的最新版本然后返回 Qk 的 content。
读操作总能成功。
写规则
事务 Ti 执行 write(Q) 时,也先找到:
Qk = W-timestamp <= TS(Ti) 的最新版本然后:
- 如果
TS(Ti) < R-timestamp(Qk),则Ti回滚 - 如果
TS(Ti) = W-timestamp(Qk),则覆盖Qk - 否则,创建
Q的新版本
解释:
- 如果某个更年轻事务已经读过
Qk - 按时间戳顺序,它本应看到
Ti写出的版本 - 但它已经读了旧版本
- 所以
Ti的写不能再接受
该协议保证 serializability。
Timestamp-Based Protocols
基本思想
每个事务进入系统时获得一个时间戳 TS(Ti)。
如果 Ti 比 Tj 更早进入系统,则:
TS(Ti) < TS(Tj)Timestamp-ordering protocol 要求:
并发执行效果等价于按照事务时间戳顺序串行执行。
对每个数据项 Q,系统维护两个时间戳:
| 字段 | 含义 |
|---|---|
W-timestamp(Q) | 成功执行 write(Q) 的事务中的最大时间戳 |
R-timestamp(Q) | 成功执行 read(Q) 的事务中的最大时间戳 |
Read Rule
事务 Ti 执行 read(Q):
- 如果:
TS(Ti) < W-timestamp(Q)说明 Q 已经被更年轻事务写过,Ti 需要读的旧值已经被覆盖。
该读操作被拒绝,Ti 回滚。
- 否则执行读,并更新:
R-timestamp(Q) = max(R-timestamp(Q), TS(Ti))Write Rule
事务 Ti 执行 write(Q):
- 如果:
TS(Ti) < R-timestamp(Q)说明已有更年轻事务读过旧值。若现在允许 Ti 写入,会破坏时间戳顺序。
所以 Ti 回滚。
- 如果:
TS(Ti) < W-timestamp(Q)说明已有更年轻事务写过 Q。Ti 现在写的是 obsolete value。
普通 timestamp-ordering protocol 会回滚 Ti。
- 否则执行写,并更新:
W-timestamp(Q) = TS(Ti)例子
设事务时间戳:
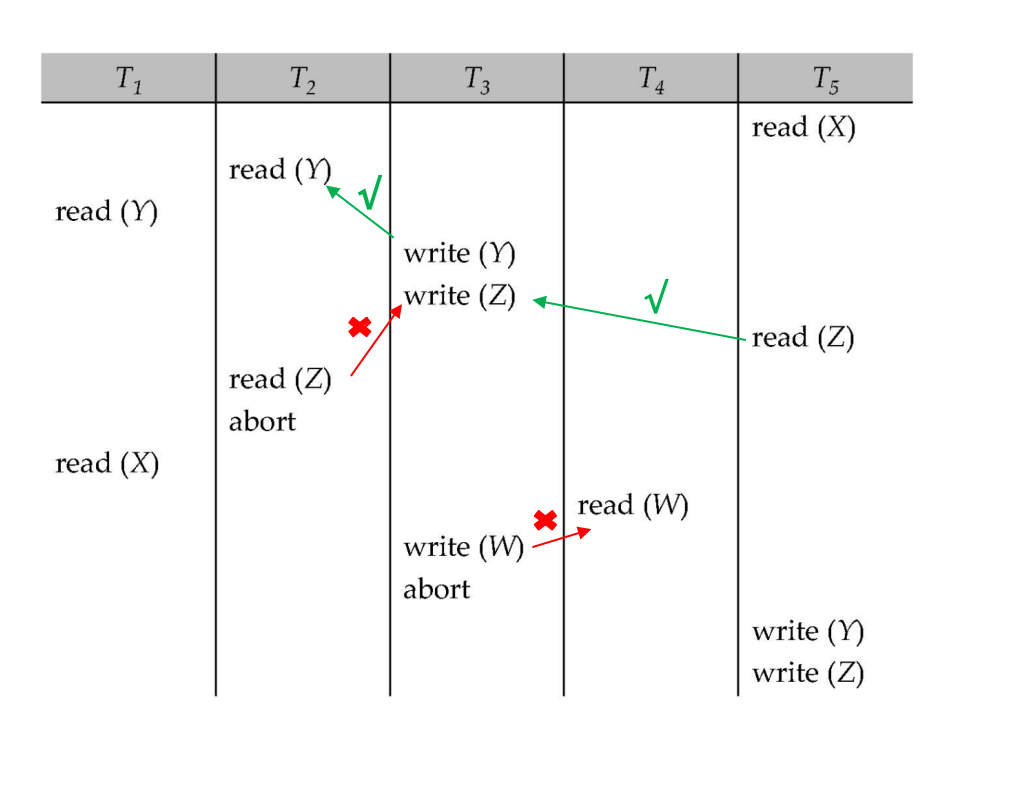
TS(T1)=1, TS(T2)=2, TS(T3)=3, TS(T4)=4, TS(T5)=5部分调度中:
T2: read(Y)T1: read(Y)T3: write(Y) // 可以,TS(T3)=3 >= R-timestamp(Y)=2
T3: write(Z)T4: read(Z) // 可以,TS(T4)=4 >= W-timestamp(Z)=3T2: read(Z) // 不可以,TS(T2)=2 < W-timestamp(Z)=3,T2 abort
T4: read(W)T3: write(W) // 不可以,TS(T3)=3 < R-timestamp(W)=4,T3 abort
T5: write(Y)T5: write(Z) // T5 时间戳最大,一般可以继续写这个例子展示了两类 abort:
- 旧事务读一个已被新事务写过的数据项
- 旧事务写一个已被新事务读过的数据项
正确性
Timestamp-ordering protocol 保证 serializability。
原因:
所有冲突边都从较小时间戳事务指向较大时间戳事务。
因此 precedence graph 不可能有环。
它也保证 deadlock freedom,因为事务不会等待锁;冲突时直接回滚。
问题:
- 可能产生 cascading rollback
- 甚至可能产生不可恢复调度

Recoverability 问题
如果:
Tj 读了 Ti 写过的数据Ti 后来 abort那么 Tj 也必须 abort。
如果 Tj 已经 commit,则调度不可恢复。
这会导致 cascading rollback:
Ti abort=> Tj abort=> 读过 Tj 数据的其他事务继续 abort解决方案:
- 事务把所有写操作放在处理末尾,并以原子方式执行
- 使用有限形式的 locking:读数据前等待写事务提交
- 使用 commit dependencies 保证可恢复性
Thomas’ Write Rule
Thomas’ Write Rule 修改 timestamp-ordering 的写规则。
当 Ti 执行 write(Q) 且:
TS(Ti) < W-timestamp(Q)普通协议会回滚 Ti。
Thomas’ Write Rule 认为:
这是一个 obsolete write,可以直接忽略本次写操作。
其余规则与 timestamp-ordering protocol 相同。
好处:
- 提高并发度
- 允许一些 view-serializable 但非 conflict-serializable 的调度
Validation-Based Protocols
基本思想
Validation-based protocol 也称 optimistic concurrency control。
适合冲突概率低的场景。
核心思想:
先让事务自由执行,提交前再检查是否会破坏 serializability。
三个阶段
事务 Ti 执行分成三阶段:
| 阶段 | 含义 |
|---|---|
| Read and Execution Phase | 读取数据库,计算结果;写入临时局部变量 |
| Validation Phase | 检查本事务能否安全提交 |
| Write Phase | 如果验证通过,将临时结果写回数据库;否则回滚 |
并发事务的三个阶段可以交错,但每个事务内部必须按上述顺序执行。
为简化讨论,通常假设:
validation phase 和 write phase 原子地、串行地执行,即同一时刻只有一个事务在验证 / 写回。
三个时间戳
每个事务 Ti 有三个时间:
| 时间 | 含义 |
|---|---|
Start(Ti) | 事务开始执行时间 |
Validation(Ti) | 事务进入 validation phase 的时间 |
Finish(Ti) | 事务完成 write phase 的时间 |
串行化顺序按 validation time 决定:
TS(Ti) = Validation(Ti)这样比事务一开始就固定串行顺序更灵活,冲突少时回滚更少。
Validation Test
对正在验证的事务 Tj,对所有满足:
TS(Ti) < TS(Tj)的事务 Ti,如果满足以下任一条件,则 Tj 验证通过。
条件一
Finish(Ti) < Start(Tj)含义:
Ti在Tj开始前已经结束- 二者没有重叠执行
- 不会冲突
条件二
Start(Tj) < Finish(Ti) < Validation(Tj)write_set(Ti) ∩ read_set(Tj) = ∅含义:
Ti和Tj有重叠执行- 但
Ti写过的数据没有被Tj读过 - 因此
Tj的读结果不受Ti影响
若检查失败,Tj abort。
例子
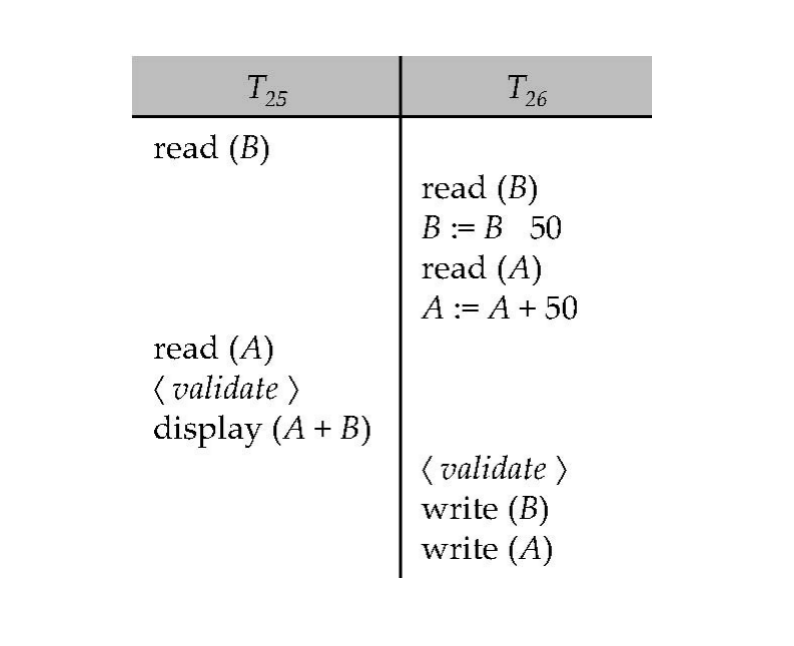
两个事务:
T25:read(B)read(A)<validate>display(A+B)
T26:read(B)B := B - 50read(A)A := A + 50<validate>write(B)write(A)理解:
T25只读A、B并显示总和T26执行从B到A的转账- 写操作在 validation 通过后才真正写回
- 若
T25先完成 validation,则可把串行顺序看作T25 -> T26
这体现了 optimistic concurrency control 的特点:读执行阶段不加锁,最后统一验证。
适用场景
适合:
- 读多写少
- 冲突概率低
- 不希望长时间持锁
不适合:
- 热点数据频繁更新
- 冲突概率高
- 事务执行很久后才在 validation 阶段失败,回滚代价大
Snapshot Isolation
动机
决策支持查询经常读取大量数据,而 OLTP 事务通常只更新少量行。
如果二者都使用普通锁,容易互相阻塞:
- 大查询读很多行,会持有大量读锁
- 小更新需要写锁,会被阻塞
- 更新事务也可能阻塞长查询
多版本思想可以给事务一个逻辑快照,让读操作不阻塞写操作。
两类方案
方案一:
只给 read-only transactions 快照read-write transactions 使用普通 locking这就是 multiversion 2PL 的思路。
问题:
- 系统需要知道事务是否只读
方案二:
给每个事务一个 snapshot只有更新操作使用 2PL 防止并发写冲突这就是 snapshot isolation 的基本思路。
问题:
- 可能出现 lost update 等异常
- snapshot isolation 使用 first-committer-wins 作为部分补救
Snapshot Isolation 的规则
事务 T1 在 snapshot isolation 下:
- 启动时获得一个 committed data 的 snapshot
- 后续读操作都从自己的 snapshot 中读
- 自己写入的数据对自己可见
- 并发事务的更新对自己不可见
- 写入在 commit 时生效
- 提交时使用 first-committer-wins 规则
first-committer-wins:
如果另一个与当前事务并发的事务已经提交,并写过当前事务也想写的数据项,则当前事务 abort。
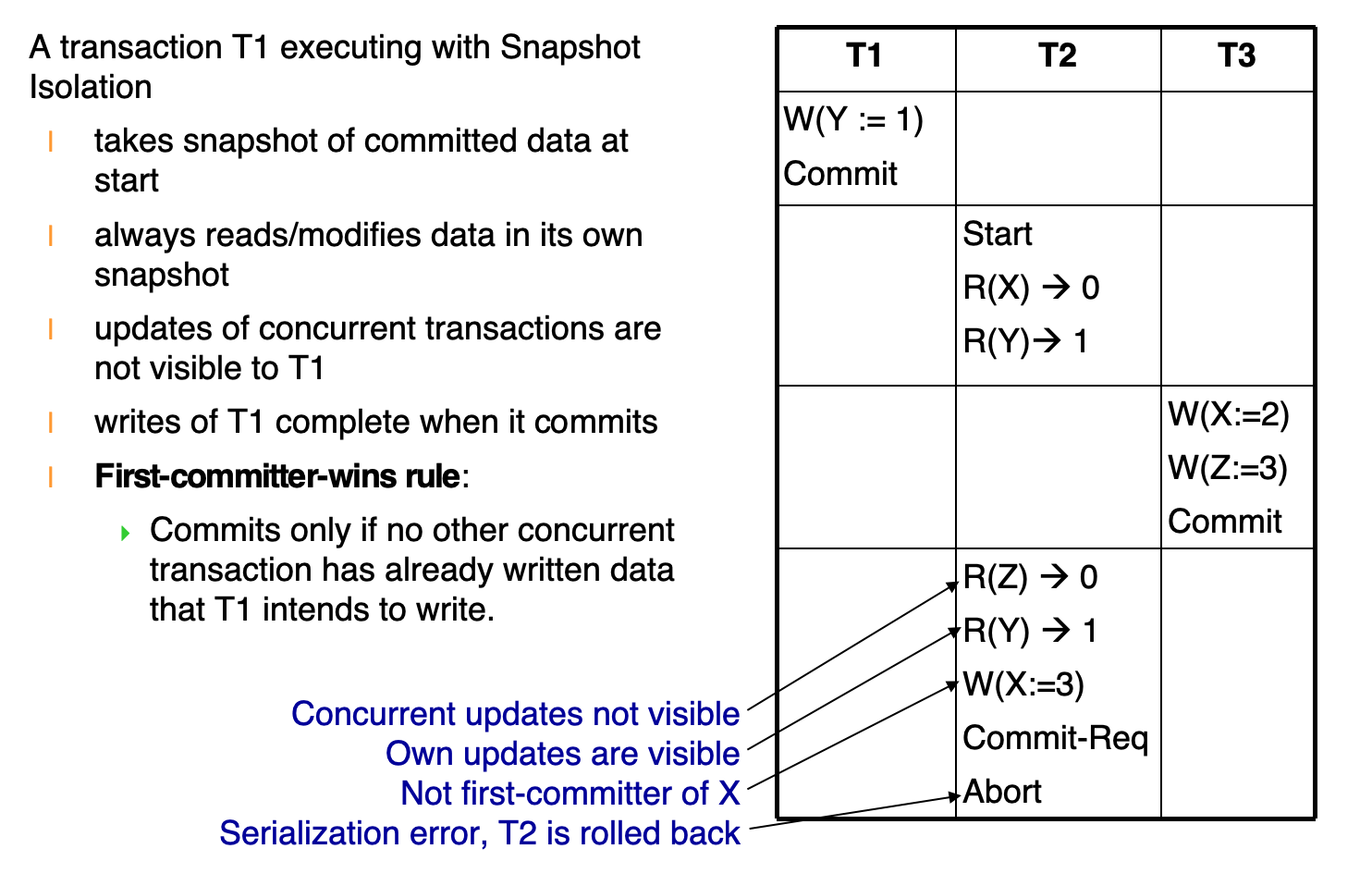
Snapshot Isolation 例子:提交冲突
例子:
T1: W(Y := 1); Commit
T2: StartT2: R(X) -> 0T2: R(Y) -> 1
T3: W(X := 2)T3: W(Z := 3)T3: Commit
T2: R(Z) -> 0T2: R(Y) -> 1T2: W(X := 3)T2: Commit-ReqT2: Abort理解:
T2启动时形成 snapshotT3在T2运行期间提交,所以T2看不到T3对Z的更新T2自己写X- 但
T3已经并发写过并提交了X T2并非X的 first committer,所以提交失败并回滚
Snapshot Read 例子
例子:
Initial:X0 = 100, Y0 = 0T1 往 Y 存 50:
T1:r1(X0, 100)r1(Y0, 0)w1(Y1, 50)r1(X0, 100) // 看不到 T2 对 X 的更新r1(Y1, 50) // 看得到自己的更新T2 从 X 取 50:
T2:r2(Y0, 0)r2(X0, 100)w2(X2, 50)r2(Y0, 0) // 看不到 T1 对 Y 的更新最终数据库中可以有:
X2 = 50, Y1 = 50这个例子说明:
- snapshot read 看不到并发事务更新
- 每个事务能看到自己的写入

Snapshot Write:First Committer Wins
课件例子:
Initial:X0 = 100
T1:r1(X0, 100)w1(X1, 150)commit1
T2:r2(X0, 100)w2(X2, 50)commit2T1 和 T2 都写 X。
T1 先提交,成为 X 的 first committer。
T2 提交时发现:
并发事务 T1 已经写过 X 并提交所以 T2 发生 serialization error 并回滚。

First-Updater-Wins
first-updater-wins 是 first-committer-wins 的变体。
规则:
- 在执行写操作时检查并发更新
- 如果发现冲突,提前 abort
- 为了正确,需要锁住被写数据项,直到所有并发事务结束
区别:
- first-committer-wins 在 commit 时发现冲突
- first-updater-wins 在 write 时更早发现冲突
Oracle 使用 first-updater-wins 及一些额外机制。
Snapshot Isolation 的优点
Snapshot Isolation 的读操作:
- 不被写操作阻塞
- 也不阻塞其他事务活动
- 性能接近 Read Committed
它可以避免常见异常:
- dirty read
- lost update
- non-repeatable read
- predicate-based phantom
Snapshot Isolation 的问题
Snapshot Isolation 并不总能产生 serializable execution。
串行执行中,如果两个事务并发,最终等价串行顺序里总有一个事务应该看到另一个事务的效果。
但 SI 中:
两个并发事务可能都只看到启动时的旧 snapshot所以二者可能互相看不到对方结果,破坏某些完整性约束。
Write Skew
例子:
T1: x := yT2: y := x
Initial:x = 3, y = 17串行执行有两种结果:
T1 -> T2:x = 17, y = 17
T2 -> T1:x = 3, y = 3如果 T1 和 T2 同时开始,使用 snapshot isolation:
T1 看到 x = 3, y = 17,所以写 x = 17T2 看到 x = 3, y = 17,所以写 y = 3最终:
x = 17, y = 3这个结果不等价于任何串行顺序。
这就是 write skew。
插入场景也会出现 skew:
1. find max order number among all orders2. create a new order with order number = previous max + 1两个并发事务可能基于同一个旧最大值生成相同订单号。
SI 的实践注意点
SI 破坏 serializability 的典型模式:
两个事务修改不同数据项,但各自基于对方所修改数据项的旧状态做决定。
这种情况在实践中不一定常见。例如 TPC-C 在 SI 下通常能正确运行,因为如果两个事务因不同数据项冲突,常常还会共同修改某个共享数据项,SI 会回滚其中一个。
但 write skew 真实存在,应用开发者需要注意。
另外:
- read-only transaction anomaly 也可能发生
- 使用 snapshot 检查 primary key / foreign key 可能导致不一致
- 完整性约束检查通常需要在 snapshot 外部处理
数据库实现提示
- Oracle 的
serializable隔离级别使用 SI 变体 - PostgreSQL 9.1 之前的
serializable也接近 SI - Oracle 使用 first-updater-wins
- PostgreSQL 9.1 引入 Serializable Snapshot Isolation, SSI
- SSI 能保证真正 serializability,包括 predicate reads
Select For Update
某些查询可以用 select ... for update 绕开 SI 的问题。
例子:
select max(orderno)from ordersfor update;后续:
1. 将 max(orderno) 读入局部变量 maxorder2. insert into orders values (maxorder + 1, ...)select for update 会把读到的数据当作也要更新,从而阻止并发更新。
局限:
- 不能总是保证 serializability
- phantom phenomenon 仍可能出现
- 对范围 / 谓词查询仍需要 key-range locking 或 predicate locking
[插图占位|slid
Weak Levels of Consistency
实践中并不总是要求 serializability。
有些场景更重视吞吐量和响应时间,只需要较弱一致性。
Degree-Two Consistency
Degree-two consistency 与 2PL 的区别:
S锁可以随时释放- 后续仍可以继续获得新锁
X锁必须持有到事务结束
结果:
- 不保证 serializability
- 程序员需要保证不会产生错误数据库状态
Cursor Stability
Cursor stability 是 degree-two consistency 的特例。
读 tuple 时:
lock tupleread tupleunlock tuple immediately写锁仍然持有到事务结束。
它可以避免部分 lost update,但隔离性弱于 serializable。
SQL Isolation Levels
SQL 允许非串行化执行。
| 隔离级别 | 含义 |
|---|---|
| Serializable | 最强,目标是串行化执行 |
| Repeatable Read | 只能读已提交记录;重复读同一记录应返回相同值;phantom 可以不防止 |
| Read Committed | 只读已提交数据;很多系统用 cursor stability 实现 |
| Read Uncommitted | 允许读未提交数据,可能发生 dirty read |
很多数据库默认使用 Read Committed。
需要更强隔离时,显式设置:
set isolation level serializable;Transactions across User Interaction
很多应用需要跨用户交互保持事务语义。
例如:
- 用户打开页面查看账户余额
- 用户思考一段时间
- 用户点击提交转账
此时不能简单地一直持有数据库锁:
- 用户交互时间不可控
- 长时间持锁会严重阻塞其他事务
- 不希望每个用户长期占用一个数据库连接
应用层并发控制
常见做法:给 tuple 增加 version number。
读取时记录版本:
select r.balance, r.versioninto :A, :versionfrom rwhere acctId = 23;写入时检查版本是否仍然相同:
update rset r.balance = r.balance + :deposit, r.version = r.version + 1where acctId = 23 and r.version = :version;如果更新影响行数为 0,说明该 tuple 在用户交互期间被别人修改过,当前操作应失败或重试。
这个方法等价于:
- optimistic concurrency control
- 但不验证完整 read set
它常见于 Hibernate ORM 等系统,也常由应用开发者手动实现。
version numbering 也可用于支持 snapshot isolation 的 first-committer-wins 检查。
但与 SI 相比,这种应用层方法不保证所有读取都来自同一个 snapshot。