

概述
这一章的核心是:
事务(transaction)把一组数据库读写操作包装成一个逻辑工作单元,并要求它在故障和并发环境下仍然表现得“正确”。
事务管理要解决两个主要问题:
- Failures:硬件故障、系统崩溃、软件错误可能让事务只执行一半
- Concurrent execution:多个事务同时执行可能相互干扰,产生错误结果
因此数据库系统要提供:
- Atomicity:要么全做,要么全不做
- Consistency:事务从一致状态出发,成功结束后仍回到一致状态
- Isolation:并发执行的效果应像某种串行执行
- Durability:提交后的结果即使系统故障也要保留
这一章的脉络可以概括为:
事务概念 -> ACID -> 简单 read/write 模型 -> 并发异常 -> 调度 schedule -> 可串行化 serializability -> 可恢复性 recoverability -> 隔离级别 isolation levels -> SQL 中如何定义事务边界目录
- 概述
- 目录
- Transaction Concept
- ACID Properties
- A Simple Transaction Model
- Transaction State
- Concurrent Executions
- Lost Update
- Dirty Read
- Unrepeatable Read
- Phantom Problem
- Schedules
- Serializability
- Conflict Serializability
- Testing for Conflict Serializability
- View Serializability
- Other Notions of Serializability
- Recoverability
- Concurrency Control Protocols
- Weak Levels of Consistency
- Transaction Isolation Levels
- Transaction Definition in SQL
- Transaction Boundaries
Transaction Concept
事务的定义
事务是数据库应用中的一个逻辑工作单元。
形式上:
A transaction is a unit of program execution that accesses and possibly updates various data items.
也就是说,一个事务可以:
- 读取数据库中的数据项
- 修改数据库中的数据项
- 执行多个 SQL 语句
- 最后以
commit或rollback结束
事务的关键不取决于语句数量,关键在于业务语义上的完整性。
例如:
- 转账:从 A 扣钱,同时给 B 加钱
- 订票:锁定座位,同时生成订单
- 支付:扣减余额,同时修改订单状态
这些操作如果只执行一部分,数据库就会进入错误状态。
转账例子
从账户 A 向账户 B 转账 50 元:
update accountset balance = balance - 50where account_number = A;
update accountset balance = balance + 50where account_number = B;
commit;把它抽象成 read/write 模型:
1. read(A)2. A := A - 503. write(A)4. read(B)5. B := B + 506. write(B)如果 A = 100, B = 100,事务成功完成后应为:
A = 50, B = 150A + B = 200总余额没有变化,只是钱从 A 转移到了 B。
事务管理要解决的问题
事务系统主要处理两类风险。
故障风险:
如果事务在第 3 步后、第 6 步前崩溃:
A 已经扣 50B 还没有加 50数据库中表现为钱“消失”了。
并发风险:
如果另一个事务在第 3 步和第 6 步之间读取 A 和 B:
read(A), read(B), print(A + B)它可能看到 A + B < 200 的中间状态。
这就是事务管理的出发点:
- 发生故障时,不能留下半个事务
- 并发执行时,不能让其他事务看到危险的中间结果
ACID Properties
ACID 是事务正确性的四个核心性质。
Atomicity
原子性要求:
Either all operations of the transaction are reflected in the database or none are.
也就是:
- 事务所有操作都成功,数据库保留全部修改
- 事务中途失败,数据库撤销已经做过的修改
以转账为例:
A := A - 50B := B + 50这两个操作必须作为一个整体处理。
不能只扣 A,不加 B。
Consistency
一致性要求:
Execution of a transaction in isolation preserves the consistency of the database.
意思是:
- 事务开始前数据库是一致的
- 事务单独执行并成功提交后,数据库仍然一致
转账例子中的一致性约束:
A + B 的总和不变更一般地,一致性约束分为两类。
显式完整性约束:
- primary key
- foreign key
- check constraint
- not null
隐式业务约束:
例如银行系统中:
所有账户余额之和 - 所有贷款金额之和 = 银行现金持有量这类约束通常无法完全靠 SQL 声明表达,需要应用逻辑保证。
NOTE事务执行过程中,数据库可以短暂不一致。
例如转账时,先扣 A 再加 B,中间时刻
A + B会变小。关键要求是:
- 中间状态不能被不该看到的事务看到
- 成功提交后必须恢复到一致状态
Isolation
隔离性要求:
Although multiple transactions may execute concurrently, each transaction must be unaware of other concurrently executing transactions.
直观理解:
- 多个事务可以同时运行
- 但每个事务看到的效果应像其他事务要么已经执行完,要么还没有开始
- 事务的中间结果应该被隐藏
最简单的隔离方式是串行执行:
T1 完全执行完T2 再开始执行这样一定安全,但性能差。
数据库系统的目标是:
允许并发执行,同时保证效果等价于某个串行执行Durability
持久性要求:
After a transaction completes successfully, its changes persist even if there are system failures.
也就是说:
- 用户收到“事务成功”的通知后
- 数据库必须保证修改已经可靠保存
- 即使之后系统崩溃,也不能丢失已经提交的结果
实现上通常依赖:
- log
- stable storage
- recovery system
具体机制会在恢复系统章节展开。
ACID 中系统和程序员的分工
| 性质 | 主要责任方 | 说明 |
|---|---|---|
| Atomicity | DBMS recovery system | 失败时 undo 未完成事务 |
| Consistency | 程序员 + DBMS | 程序逻辑要正确,DBMS 检查显式约束 |
| Isolation | DBMS concurrency-control system | 控制并发事务的交错执行 |
| Durability | DBMS recovery system + storage | 提交后结果必须可恢复 |
关键点:
- DBMS 可以保证原子性、隔离性、持久性
- 一致性需要事务逻辑本身正确
- 错误的业务逻辑即使被完整提交,也可能破坏数据库语义
A Simple Transaction Model
这一章先用一个简单模型研究事务。
模型只保留两类操作:
read(X)write(X)这样可以先分析事务并发的本质。
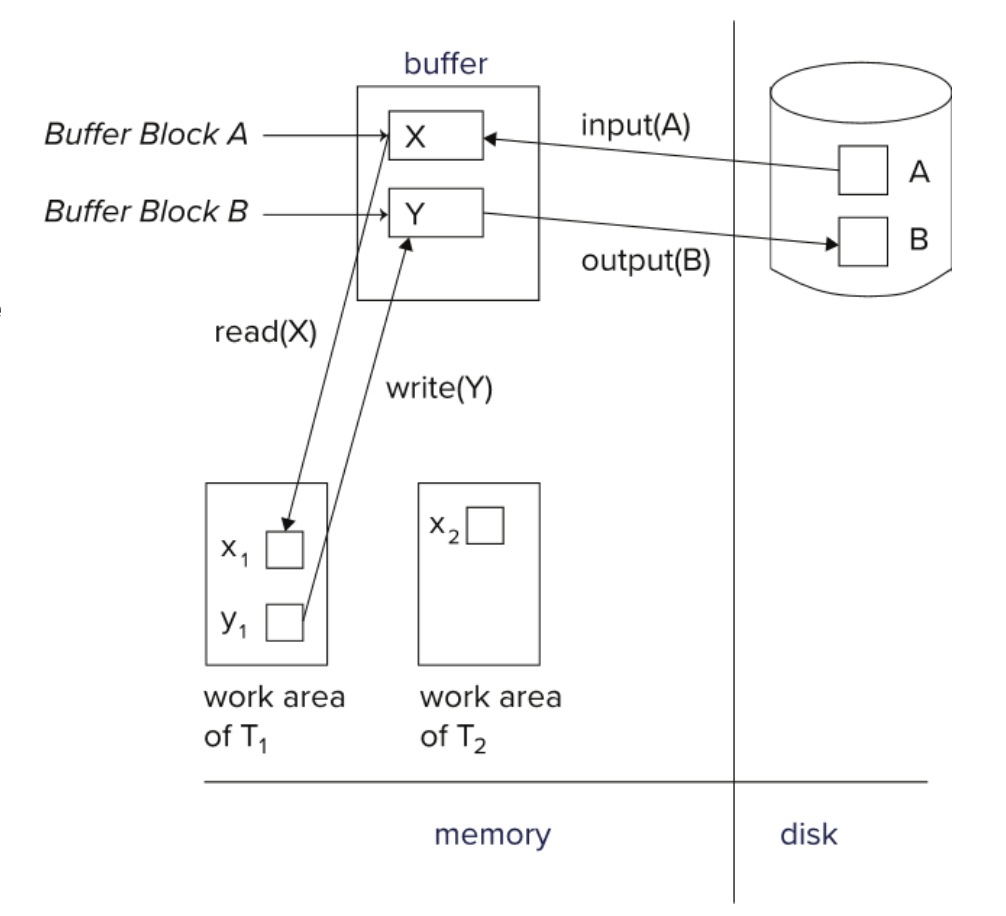
read 和 write
read(X):
把数据库中的数据项 X 读入事务自己的主存工作区变量 Xwrite(X):
把事务工作区变量 X 的值写回数据库中的数据项 X每个事务有自己的 work area。
数据库中的数据项可能在磁盘上,也可能在缓冲区中;事务看到的是读入自己工作区后的变量。
存储结构与故障语义
事务恢复相关的三类存储。
Volatile storage(易失存储):
- 断电或系统崩溃后内容丢失
- 例如 CPU cache、main memory
Non-volatile storage(非易失存储):
- 系统崩溃后通常保留
- 设备自身仍可能故障
- 例如 disk、SSD
Stable storage(稳定存储):
- 理想模型:数据永不丢失
- 现实中用冗余技术近似实现
- 例如 RAID、镜像磁盘、多副本归档
事务的 durability 本质上依赖稳定存储思想。
数据库在通知用户 commit 成功前,必须确保提交结果或恢复所需日志已经足够可靠。
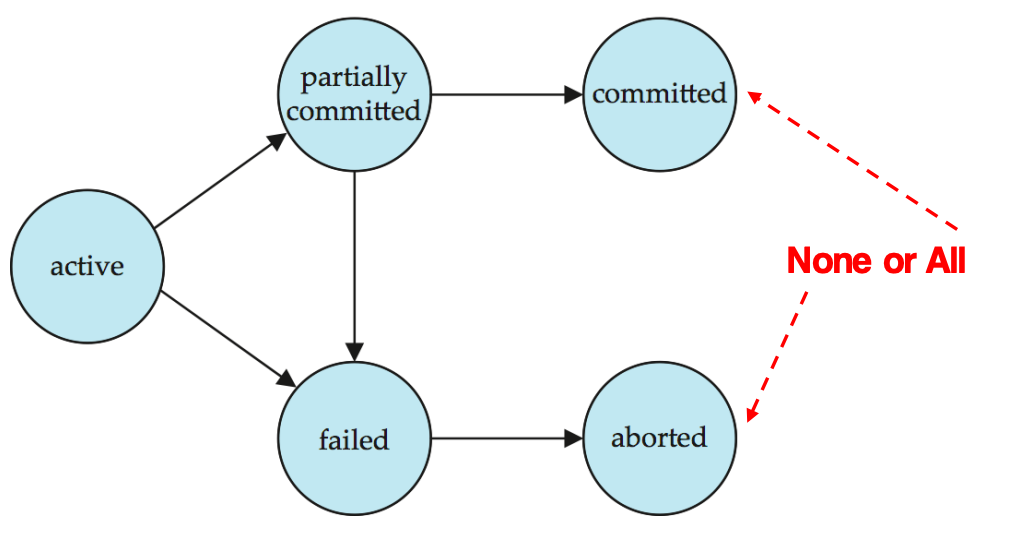
Transaction State
一个事务在执行过程中会处于以下状态。
| 状态 | 含义 |
|---|---|
| Active | 初始状态,事务正在执行 |
| Partially committed | 最后一条语句已经执行完,但还没有最终确认提交安全 |
| Failed | 发现事务无法继续正常执行 |
| Aborted | 事务已经回滚,数据库恢复到事务开始前状态 |
| Committed | 事务成功完成,修改被持久保存 |
状态流转可以理解为:
Active -> Partially committed -> Committed
Active -> Failed -> Aborted -> restart 或 kill
Partially committed -> Failed -> Aborted事务失败后有两种处理方式:
- restart transaction:重新执行事务
- kill transaction:终止事务,不再重试
这一部分对应事务的核心原则:
None or All即:
- 要么完全提交
- 要么完全回滚
Partially committed 和 Committed 的区别
Partially committed 只是说明事务的最后一条语句已经执行完,事务还没有真正完成提交确认。
此时如果系统发现日志没有安全落盘、约束检查失败,或者恢复所需信息还不完整,事务仍可能进入 Failed,再被回滚为 Aborted。
Committed 表示提交已经被系统确认。用户一旦收到成功提交的通知,之后即使发生系统故障,数据库也必须能通过恢复机制保留这次提交的结果。
Concurrent Executions
为什么要并发执行
数据库允许多个事务并发执行,主要有两个好处。
提高系统吞吐量:
一个事务等待磁盘 I/O 时,另一个事务可以使用 CPU。
T1: waiting for diskT2: using CPU这样能提高 processor 和 disk 的利用率。
降低平均响应时间:
短事务不用一直排在长事务后面。
例如:
长事务:统计所有账户总余额短事务:查询某个账户余额如果完全串行,短事务可能等待很久。
并发执行的收益很明显,但代价是需要处理并发异常。
并发执行的异常
四类典型异常:
- Lost Update(丢失修改)
- Dirty Read(读脏数据)
- Unrepeatable Read(不可重复读)
- Phantom Problem(幽灵问题)
这些异常都来自一个共同原因:
多个事务的 read/write 操作交错执行,并且没有足够的隔离控制。
Lost Update
丢失修改指:两个事务基于同一个旧值进行修改,后写入的结果覆盖了先写入的结果。
例子:
初始 A = 100
T1 T2read(A) = 100 read(A) = 100A := A - 1 = 99 A := A - 1 = 99write(A) = 99 write(A) = 99正确结果应该是:
A = 98实际结果是:
A = 99原因:
- T1 的
A := A - 1被 T2 的写入覆盖 - 两次扣减只体现了一次
这个异常本质上是 read-modify-write 操作没有被当作一个整体保护。
Dirty Read
脏读指:一个事务读取了另一个尚未提交事务写出的值。
课件例子:
初始 A = 100
T1 T2read(A) = 100A := A - 1 = 99write(A) = 99 read(A) = 99 A := A - 1 = 98rollback write(A) = 98 commit问题在于:
- T2 读取了 T1 写出的
99 - 但 T1 最后 rollback
- 于是 T2 的计算基于一个本不应该存在的值
这会导致数据库保留一个由无效数据推导出来的结果。
脏读通常会破坏 recoverability。
Unrepeatable Read
不可重复读指:同一个事务内,两次读取同一个数据项,得到不同结果。
课件例子:
初始 A = 100
T1 T2read(A) = 100 read(A) = 100 A := A - 1 = 99 write(A) = 99read(A) = 99T1 在同一个事务中第一次看到:
A = 100第二次看到:
A = 99如果 T1 的业务逻辑依赖“同一事务内重复读取结果稳定”,这个交错执行就会出错。
Phantom Problem
幽灵问题指:一个事务按某个谓词条件查询一批记录,另一个事务插入或删除满足该条件的记录,导致前后两次查询结果集合变化。
课件例子:
-- T1 第一次查询select *from studentwhere age = 18;-- 返回 100 条记录并发事务 T2 插入:
insert into student(id, gender, age)values ('008', 'M', 18);T1 再次查询:
select *from studentwhere age = 18;-- 返回 101 条记录新出现的那条记录像“幽灵”一样出现在第二次查询中。
幽灵问题和不可重复读相似,但关注点不同:
- 不可重复读:同一条记录的值变了
- 幽灵问题:满足条件的记录集合变了
在简单 read/write 模型中,幽灵问题不容易表达,因为它涉及谓词读取 predicate read。
Schedules
Schedule 的定义
调度(schedule)描述多个事务并发执行时,各条指令的实际时间顺序。
定义:
A schedule is a sequence of instructions that specifies the chronological order in which instructions of concurrent transactions are executed.
一个合法的 schedule 必须满足:
- 包含相关事务的所有指令
- 保留每个事务内部原本的指令顺序
也就是说,事务之间可以交错,但事务内部不能乱序。
例如事务内部顺序是:
read(A)A := A - 50write(A)schedule 中也必须保持这个顺序。
commit 和 abort
如果事务成功完成:
commit 是最后一步如果事务失败:
abort 是最后一步通常默认事务在成功执行完最后一条语句后会提交。
Serial Schedule
串行调度指事务一个接一个执行,中间没有交错。
设:
T1: 从 A 转 50 到 BT2: 从 A 转出 A 余额的 10% 到 BSchedule 1:T1 后跟 T2
初始:A = 100, B = 100
T1:read(A) -> 100A := A - 50 -> 50write(A) -> A = 50read(B) -> 100B := B + 50 -> 150write(B) -> B = 150commit
T2:read(A) -> 50temp := A*0.1 -> 5A := A - temp -> 45write(A) -> A = 45read(B) -> 150B := B + temp -> 155write(B) -> B = 155commit最终:
A = 45, B = 155, A + B = 200Schedule 2:T2 后跟 T1
初始:A = 100, B = 100
T2:read(A) -> 100temp := A*0.1 -> 10A := A - temp -> 90write(A) -> A = 90read(B) -> 100B := B + temp -> 110write(B) -> B = 110commit
T1:read(A) -> 90A := A - 50 -> 40write(A) -> A = 40read(B) -> 110B := B + 50 -> 160write(B) -> B = 160commit最终:
A = 40, B = 160, A + B = 200两个串行调度的最终结果可以不同,但都满足一致性约束。
这说明:
串行执行不要求所有串行顺序结果完全相同,只要求每个串行顺序都是一致的。
Concurrent Schedule
并发调度允许事务交错执行。
Schedule 3:并发但正确
Schedule 3:
初始:A = 100, B = 100
T1: read(A) -> 100T1: A := A - 50 -> 50T1: write(A) -> A = 50
T2: read(A) -> 50T2: temp := A*0.1 -> 5T2: A := A - temp -> 45T2: write(A) -> A = 45
T1: read(B) -> 100T1: B := B + 50 -> 150T1: write(B) -> B = 150T1: commit
T2: read(B) -> 150T2: B := B + temp -> 155T2: write(B) -> B = 155T2: commit最终:
A = 45, B = 155, A + B = 200它和 Schedule 1 的效果相同,所以这个并发调度是正确的。
Schedule 4:并发且错误
初始:A = 100, B = 100
T1: read(A) -> 100T1: A := A - 50 -> 50
T2: read(A) -> 100T2: temp := A*0.1 -> 10T2: A := A - temp -> 90T2: write(A) -> A = 90T2: read(B) -> 100
T1: write(A) -> A = 50 -- 覆盖 T2 对 A 的写入T1: read(B) -> 100T1: B := B + 50 -> 150T1: write(B) -> B = 150T1: commit
T2: B := B + temp -> 110T2: write(B) -> B = 110 -- 覆盖 T1 对 B 的写入T2: commit最终:
A = 50, B = 110, A + B = 160A + B 没有保持不变,因此 Schedule 4 是错误调度。
Serializability
基本假设
可串行化分析建立在一个基本假设上:
每个事务单独执行时,都能保持数据库一致性。
因此:
事务串行执行 -> 一定保持一致性如果某个并发调度的效果等价于某个串行调度,那么这个并发调度也应该是正确的。
可串行化的含义
定义:
A schedule is serializable if it is equivalent to a serial schedule.
也就是说:
并发 schedule S只要能找到某个串行 schedule S’,使得二者效果等价,那么 S 就是可串行化的。
不同的“等价”定义会产生不同的可串行化概念:
- Conflict Serializability(冲突可串行化)
- View Serializability(视图可串行化)
可以把两者的核心要求概括为:
- 冲突可串行化:所有冲突操作对的相对顺序保持一致。
- 视图可串行化:对应读操作读到的值一致,且每个数据项的最终写入者一致。
以 Schedule 1 和 Schedule 3 为例:
- T1 读取到 A、B 的初始值。
- T2 读取到由 T1 写出的 A、B。
- 最终写 A、B 的事务都是 T2。
因此 Schedule 3 与 Schedule 1 在视图上等价。
Conflict Serializability
冲突可串行化只关注 read/write 操作之间的冲突关系。
Conflict 的定义
设 li 是事务 Ti 的一条指令,lj 是事务 Tj 的一条指令。
如果它们满足:
- 来自不同事务
- 访问同一个数据项
Q - 至少有一个是
write(Q)
那么它们冲突。
四种情况:
| 操作对 | 是否冲突 | 原因 |
|---|---|---|
read(Q) vs read(Q) | 不冲突 | 两个读不会改变值 |
read(Q) vs write(Q) | 冲突 | 先后顺序影响读到的值 |
write(Q) vs read(Q) | 冲突 | 先后顺序影响读到的值 |
write(Q) vs write(Q) | 冲突 | 先后顺序影响最终值 |
直观理解:
冲突操作之间的相对顺序不能随便交换。
如果两个相邻操作不冲突,交换它们不会改变最终效果。
Conflict Equivalent
如果一个 schedule S 可以通过一系列非冲突相邻操作交换变成另一个 schedule S',则:
S 和 S' conflict equivalent注意:
- 只能交换非冲突操作
- 不能打乱单个事务内部顺序
- 不能交换会影响读写结果的操作
Conflict Serializable
如果 schedule S conflict equivalent 于某个串行 schedule,则:
S 是 conflict serializableSchedule 3 可以通过交换非冲突操作,变成串行调度:
T1 -> T2所以 Schedule 3 是 conflict serializable。
反例
不可冲突可串行化调度:
T3 T4read(Q) write(Q)write(Q)冲突关系:
T3 read(Q)在T4 write(Q)前,所以需要T3 -> T4T4 write(Q)在T3 write(Q)前,所以需要T4 -> T3
形成环:
T3 -> T4 -> T3因此无法交换成:
<T3, T4>也无法交换成:
<T4, T3>所以它不是 conflict serializable。
Testing for Conflict Serializability
Precedence Graph
前驱图(precedence graph)用于判定一个 schedule 是否 conflict serializable。
构造方式:
- 每个事务是一个顶点
- 如果
Ti和Tj在某个数据项上发生冲突 - 且
Ti的冲突操作先出现 - 就画一条边:
Ti -> Tj可以在边上标注冲突的数据项。
判定规则
核心定理:
A schedule is conflict serializable if and only if its precedence graph is acyclic.
也就是说:
前驱图无环 <=> conflict serializable前驱图有环 <=> not conflict serializable如果前驱图无环,可以对图做拓扑排序。
拓扑排序得到的事务顺序,就是等价的串行顺序。
复杂度:
- 普通 cycle detection 可以做到
O(n^2) - 更好的图算法可以做到
O(n + e)
其中:
n是事务数量e是边数量
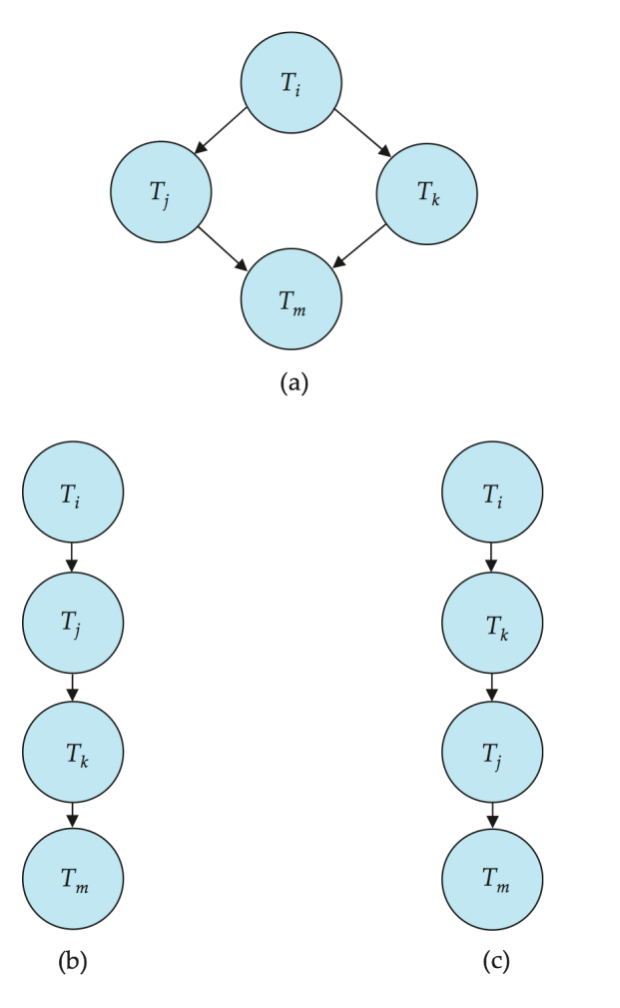
例子
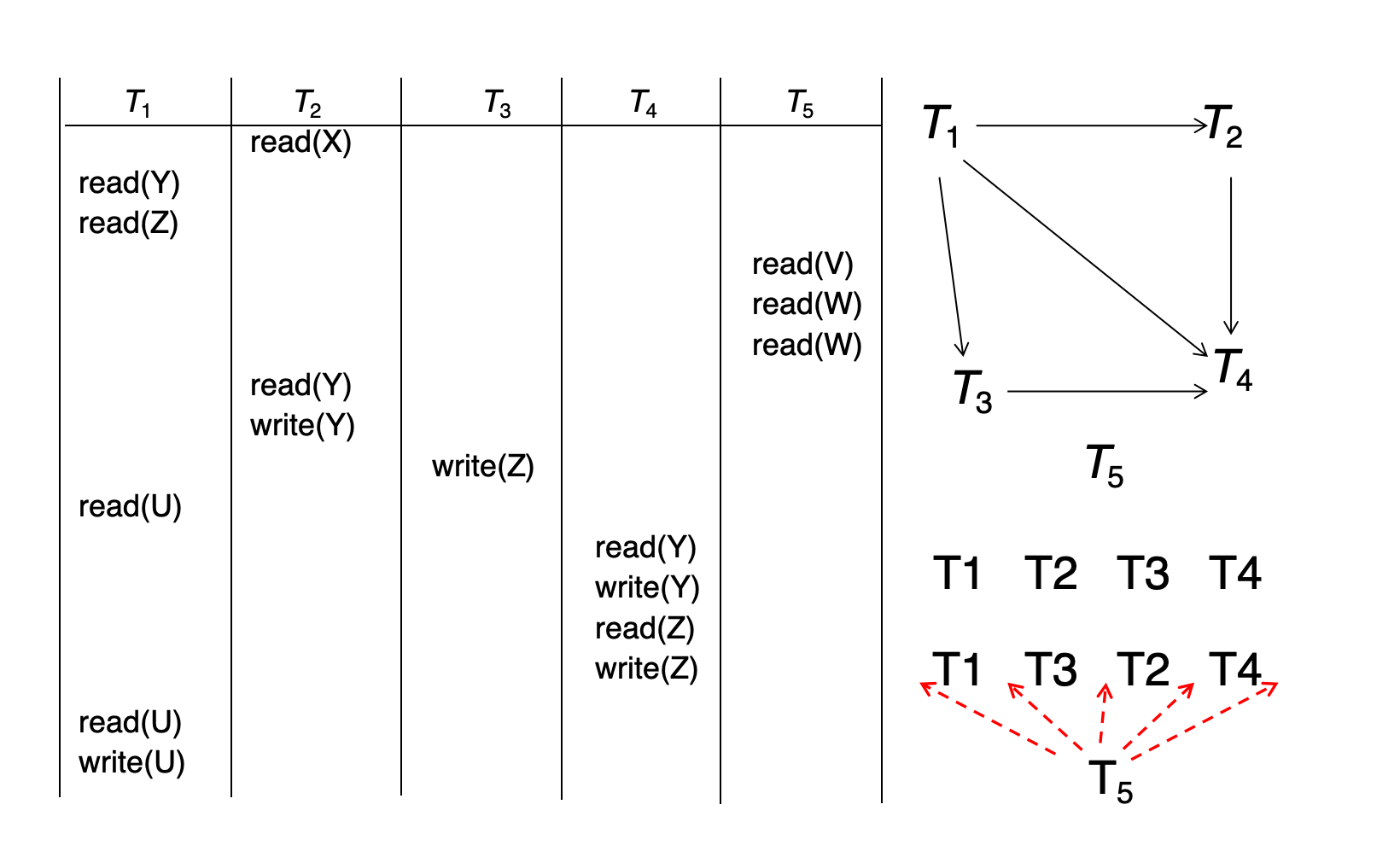
Schedule A 涉及事务:
T1, T2, T3, T4, T5图中的主要前驱关系包括:
T1 -> T2T1 -> T3T1 -> T4T2 -> T4T3 -> T4T5 只执行读操作,不和其他事务形成写冲突,因此可以放在多个位置。
一个合法的拓扑序是:
T1, T2, T3, T4另一个合法的拓扑序是:
T1, T3, T2, T4如果把 T5 放进去,它可以在不违反依赖的任意位置出现。
View Serializability
冲突可串行化较强,很多正确的调度会被排除。
视图可串行化使用更宽松的等价关系:只要求每个读操作“看到”的值一致,并且最终写入者一致。
View Equivalent
两个 schedule S 和 S' view equivalent,需要对每个数据项 Q 满足三条规则。
初值读取一致:
如果在 S 中,事务 Ti 读取的是 Q 的初始值,那么在 S' 中,Ti 也必须读取 Q 的初始值。
读到的写入来源一致:
如果在 S 中,Ti 的 read(Q) 读到的是 Tj 某次 write(Q) 产生的值,那么在 S' 中,Ti 也必须读到同一个 Tj 写出的值。
最终写入者一致:
如果在 S 中,最后写 Q 的事务是 Tk,那么在 S' 中,最后写 Q 的事务也必须是 Tk。
View Serializable
如果 schedule S view equivalent 于某个串行 schedule,则 S 是 view serializable。
和 Conflict Serializability 的关系
关系是:
Conflict serializable ⊆ View serializable即:
- 每个 conflict serializable schedule 都是 view serializable
- 有些 view serializable schedule 不是 conflict serializable
例子:
T27 T28 T29read(Q) write(Q)write(Q) write(Q)这个调度:
- 是 view serializable
- 等价于串行顺序:
T27 -> T28 -> T29但它不是 conflict serializable。
原因在于其中存在 blind write 相关情况,使得冲突图可能出现环,但从“读到什么值”和“最终谁写入”的角度看,它仍能对应一个串行执行。
Other Notions of Serializability
有些调度最终结果和某个串行调度相同,但这种等价性无法只靠 read/write 冲突或 view equivalence 判断。
例子中,两个操作满足数学上的交换律:
(B - 10) + 50 = (B + 50) - 10因此最终结果可能和串行调度 <T1, T5> 一样。
但要证明这种等价,需要理解事务内部计算逻辑:
- SQL 语句语义
- Java/JDBC 程序逻辑
- 算术表达式是否可交换
- 条件分支是否影响写入
这远远超出了简单 read/write 模型。
所以数据库系统通常不会直接分析这种“语义等价”。
实际系统采用的做法是:
用并发控制协议施加约束,保证产生的调度属于某类可证明正确的调度Recoverability
可串行化主要解决隔离性。
但即使一个调度在并发结果上看起来正确,也可能在事务失败时无法恢复。
所以还需要 recoverability。
Recoverable Schedule
定义:
如果事务
Tj读取了事务Ti先前写过的数据项,那么Ti的 commit 必须出现在Tj的 commit 之前。
形式化:
Tj reads value written by Ti=> commit(Ti) must appear before commit(Tj)原因:
- 如果
Tj依赖了Ti的写入 Tj却先 commit- 之后
Tiabort - 那么
Tj已经提交了基于无效数据的结果
不可恢复例子:
T8 T9write(A) read(A) commitabort如果 T9 在 T8 提交前就提交,而 T8 后来 abort,则系统无法正确恢复。
Cascading Rollback
级联回滚指:一个事务失败,导致多个依赖它的事务也必须回滚。
例子:
T10 writes AT11 reads A written by T10, then writes AT12 reads A written by T11如果:
T10 fails那么:
T11 必须回滚T12 也必须回滚这会撤销大量已经做过的工作,代价很高。
Cascadeless Schedule
无级联调度要求:
如果
Tj要读取Ti写过的数据项,那么Ti必须在Tj读取之前已经 commit。
形式化:
Tj reads value written by Ti=> commit(Ti) appears before read(Tj)这比 recoverable 更强。
关系是:
Cascadeless schedule => Recoverable schedule优点:
- 不会发生级联回滚
- 一个事务失败不会拖垮一串事务
- 更容易恢复
实际系统通常更希望限制调度为 cascadeless。
Concurrency Control Protocols
数据库系统必须保证所有可能出现的调度满足:
serializablerecoverablepreferably cascadeless具体来说,应保证:
- 调度是 conflict serializable 或 view serializable
- 调度是 recoverable
- 最好是 cascadeless
关键点:
事务执行完以后再检测 schedule 是否可串行化已经太晚了。
原因:
- 如果已经输出了错误结果,检查没有意义
- 如果已经提交了不可恢复事务,系统可能无法修正
所以数据库需要在事务运行过程中使用并发控制协议。
并发控制协议的作用是:
限制事务操作的执行顺序,使系统永远不会产生不安全调度它通常不会实时构造完整的 precedence graph,而是直接施加纪律。
例如:
- 先加锁再读写
- 按时间戳顺序访问
- 提交前做验证
不同协议之间有权衡:
| 目标 | 代价 |
|---|---|
| 允许更多并发 | 协议更复杂,开销更高 |
| 降低协议开销 | 可能限制更多并发 |
| 强隔离 | 性能下降 |
| 弱隔离 | 程序员要承担更多一致性风险 |
前驱图不是运行时检查机制
前驱图、冲突边和拓扑排序主要是用来理解与证明调度正确性的数学工具。实际 DBMS 通常不会等一个 schedule 形成后再检查它有没有环,因为那时错误读写、错误输出或不可恢复提交可能已经发生。
更实际的做法是:设计并发控制协议,让事务在运行过程中就遵守某些访问规则,从源头避免不可串行化、不可恢复或级联回滚的调度。
三类并发控制协议预告
只给出协议类型的概览,具体机制在后续并发控制章节展开。
Lock-Based Protocols(基于锁的协议):
- 访问数据前先申请锁
- 锁粒度可以很粗,也可以很细,例如 whole database lock 或 data item lock
- 读通常申请 shared lock,写通常申请 exclusive lock
- 核心问题是:锁什么时候申请,持有多久,什么时候释放
Timestamp-Based Protocols(基于时间戳的协议):
- 事务开始时分配时间戳
- 数据项维护读时间戳和写时间戳
- 系统用时间戳判断访问是否违反事务的逻辑先后顺序
Validation-Based Protocols(基于验证的协议):
- 属于 optimistic concurrency control
- 适合冲突率较低的场景
- 事务分为三个阶段:
Read phase -> Validation phase -> Write phase如果验证阶段发现冲突,再回滚或重启事务。
Weak Levels of Consistency
有些应用可以接受弱一致性。
典型例子:
- 只读事务想估算所有账户总余额
- 查询优化器统计数据库数据分布
- 监控系统计算近似指标
这些任务不一定需要严格可串行化。
因为它们更看重:
性能 / 低延迟 / 少阻塞可以牺牲一定准确性。
只读事务与多版本思想
对只读事务,数据库可以采用多版本思想减少阻塞:写事务生成数据的新版本,已经开始的只读事务继续读取旧的一致版本。这样读事务可以在较强的一致性要求下尽量不阻塞写事务。
这种方法提高读并发,但系统需要维护多个版本,并在合适时机回收旧版本。如果事务既读又写,或者要求严格可串行化,仍然需要额外的并发控制机制。
这就是隔离级别存在的原因。
核心权衡:
accuracy <-> performanceTransaction Isolation Levels
SQL 标准定义了多个事务隔离级别。
从强到弱大致为:
SerializableRepeatable ReadRead CommittedRead UncommittedSerializable
最强隔离级别。
要求事务并发执行的效果等价于某个串行执行。
特点:
- 理论上最安全
- 并发度最低
- 实现开销最高
课件中把它标为 default,但要注意:
某些数据库系统默认级别并不是真正 serializable。
例如教材和课件都提醒:Oracle、PostgreSQL 等系统默认支持或常用的并发行为可能是 snapshot isolation 或 read committed,而 snapshot isolation 不属于 SQL 标准隔离级别。
Repeatable Read
要求:
- 只能读取已经提交的数据
- 同一事务内重复读取同一条记录,必须返回同样的值
因此它能避免:
- dirty read
- unrepeatable read
但它仍可能出现某些非串行化情况,尤其是谓词查询相关问题。
课件描述:
A transaction may not be serializable — it may find some records inserted by a transaction but not find others.
也就是可能仍然受 phantom 类问题影响。
Read Committed
要求:
- 只能读取已经提交的数据
但不保证重复读取结果相同。
也就是说:
同一事务第一次 read(A) 得到 100另一个事务提交更新 A=99同一事务第二次 read(A) 得到 99Read committed 可以避免 dirty read,但可能出现:
- unrepeatable read
- phantom problem
- lost update 的某些变体
许多数据库系统默认使用 read committed。
Read Uncommitted
最低隔离级别。
允许读取未提交数据。
因此可能出现:
- dirty read
- unrepeatable read
- phantom problem
它适合对精度要求低、性能要求高的近似读取场景。
隔离级别对比
| 隔离级别 | 是否可读未提交数据 | 重复读是否稳定 | 是否保证可串行化 | 典型风险 |
|---|---|---|---|---|
| Serializable | 否 | 是 | 是 | 性能开销高 |
| Repeatable Read | 否 | 是,针对已读记录 | 不一定 | phantom / 非串行化 |
| Read Committed | 否 | 否 | 否 | 不可重复读、phantom |
| Read Uncommitted | 是 | 否 | 否 | 脏读 |
还要注意:
SQL 标准的这些隔离级别都禁止 dirty write。
Dirty write 指:
一个事务写入了另一个尚未提交或回滚事务已经写过的数据项Transaction Definition in SQL
SQL 中的事务开始和结束
在 SQL 中,事务通常是隐式开始的。
事务结束方式:
commit work;含义:
提交当前事务,并开始一个新事务rollback work;含义:
中止当前事务,撤销当前事务已做修改很多系统也支持简写:
commit;rollback;自动提交
大多数数据库系统默认开启自动提交。
含义:
每条 SQL 语句成功执行后,系统自动提交一次这对单语句事务方便,但对多语句事务危险。
例如转账需要两条更新语句:
update account set balance = balance - 50 where account_number = A;update account set balance = balance + 50 where account_number = B;如果自动提交开启:
- 第一条 SQL 成功后可能已经提交
- 第二条 SQL 失败时无法把第一条自然合并回滚
因此应用程序中处理多语句事务时,通常要关闭自动提交。
JDBC 中:
connection.setAutoCommit(false);
try { // execute multiple SQL statements connection.commit();} catch (Exception e) { connection.rollback();}恢复自动提交:
connection.setAutoCommit(true);设置隔离级别
SQL 中可以在事务开始时设置隔离级别。
例如:
set transaction isolation level serializable;JDBC 中:
connection.setTransactionIsolation( Connection.TRANSACTION_SERIALIZABLE);隔离级别也可以在数据库级别配置。
注意:
- 设置隔离级别通常必须在事务开始时完成
- 不同 DBMS 的默认隔离级别可能不同
- 不同 DBMS 对同名隔离级别的实现细节也可能不同
Transaction Boundaries
事务边界指:
哪些操作应该被放进同一个事务里。
这不是纯技术问题,也涉及业务语义。
例子:订一张票 vs 订多张票
如果用户只订一张票:
锁定座位生成订单提交事务事务边界比较自然。
如果用户一次订多张票,就要明确业务规则。
方案 A:多张票作为一个事务
所有座位都订成功 -> commit只要一个座位失败 -> rollback适合:
- 多人同行必须坐同一班次
- 订单要求整体成功
方案 B:每张票单独事务
能订到几张算几张失败的票单独提示适合:
- 用户接受部分成功
- 系统希望减少锁持有时间
例子:订票和支付是否放在同一事务
如果把订票和支付放在一个事务:
优点:
- 强原子性
- 订单和支付状态不会分离
缺点:
- 外部支付接口可能很慢
- 数据库锁持有时间长
- 支付系统不一定支持和本地数据库同一个事务
实际系统常采用拆分设计:
事务 1:创建订单 + 临时锁座外部支付:调用支付系统事务 2:支付成功后确认订单 / 支付失败后释放座位这时需要额外机制:
- 订单状态机
- 座位锁超时
- 幂等支付回调
- 补偿事务
- 定时清理未支付订单
所以事务边界的判断标准是:
业务上必须共同成功或共同失败的操作,才适合放入同一个短事务如果操作涉及外部系统或长时间等待,通常应拆成多个事务,并通过状态和补偿逻辑保证最终一致。