

概述
这一章的核心是:
同一个 SQL 查询,可以有大量结果相同但执行代价差异极大的方案。查询优化器(query optimizer)的任务,就是在可行的执行计划中选出代价尽可能低的方案。
第十五章解决的是:
- selection、sort、join 等操作可以怎么执行
- 每种算法大致需要多少 I/O
这一章继续解决:
- 一个查询应该先做哪些操作
- join 应该按什么顺序进行
- 每一步应该选择哪种物理算法
- 如何依据统计信息估计中间结果规模和总代价
优化链条:
SQL query ↓Parsing and Translation ↓Relational Algebra Expression ↓Equivalent Expression Transformation ↓Cardinality / Cost Estimation ↓Cheapest Evaluation Plan ↓Execution其中最关键的两层选择是:
- 逻辑优化(logical optimization):选择等价但更便宜的关系代数表达式,例如 selection pushdown、projection pushdown、join reorder。
- 物理优化(physical optimization):为每个操作选择具体算法,例如 index scan、hash join、merge join、external sort。
也就是说:
查询优化既要决定“先算什么”,也要决定“怎么计算”。
目录
- n_{\sigma_{A=v}(r)} - Range Selection
- n_{\text{result}} - Disjunction
- n_{\text{result}} - Negation
- n_{\sigma_{\neg \theta}(r)}
- \frac{4 \times 6}{V(A,s)}
- \frac{24}{4}
- \frac{4 \times 6}{V(A,r)}
- \frac{24}{3}
-
student ⋈ takes示例 - r_{new} \bowtie s
- (r_{old} \cup i_r) \bowtie s - Selection - Projection - Aggregation - Set Operations - Outer Join - 复合表达式
Introduction
查询处理的基本步骤
数据库接收到 SQL 后,大体经历三个阶段。
- Parsing and Translation
- 语法检查
- 检查查询中引用的 relation / attribute 是否存在
- 把 SQL 翻译成内部表示,再转成关系代数表达式
- Optimization
- 生成与原表达式等价的其他表达式
- 为每种表达式考虑不同物理执行方法
- 估计每种执行计划的代价
- 选择估计代价最低的计划
- Evaluation
- query-execution engine 接收最终计划
- 实际执行该计划
- 返回查询结果
SQL 只描述“我要什么结果”;执行计划决定“系统如何拿到这些结果”。
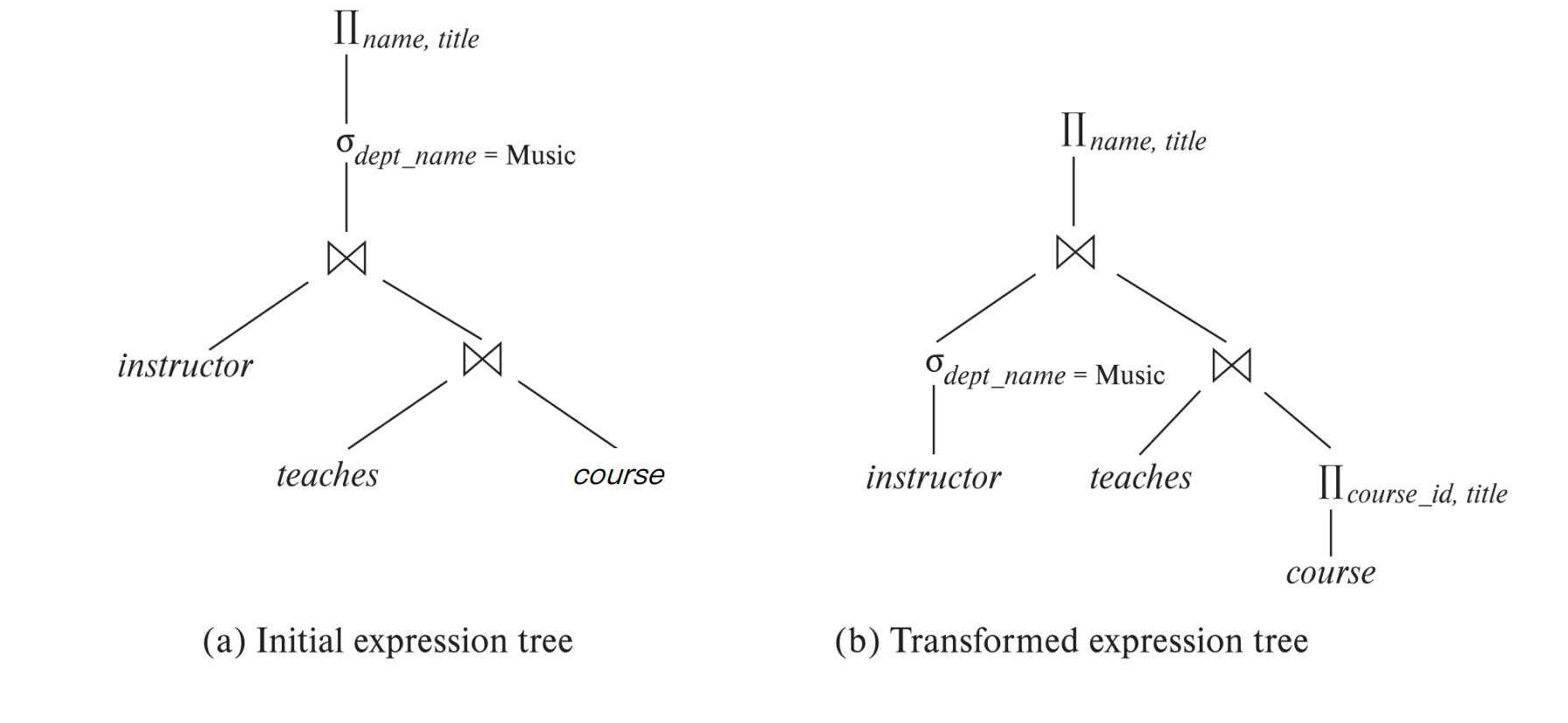
表达式与执行计划
考虑查询:
select name, titlefrom instructor natural join (teaches natural join course)where dept_name = 'Music';直接转换得到的关系代数表达式可以写成:
这个表达式的语义没有问题,但未必高效。
可以先把只涉及 instructor 的选择条件下推:
还可以只保留后续 join 和最终输出需要的属性:
这些仍然只是逻辑表达式。
一个完整的 evaluation plan(执行计划) 还需要明确:
dept_name='Music'是否使用索引- 两次 join 分别选择 hash join、merge join 还是 nested-loop join
- 是否需要排序
- projection 去重采用什么算法
- 操作之间使用 materialization 还是 pipelining
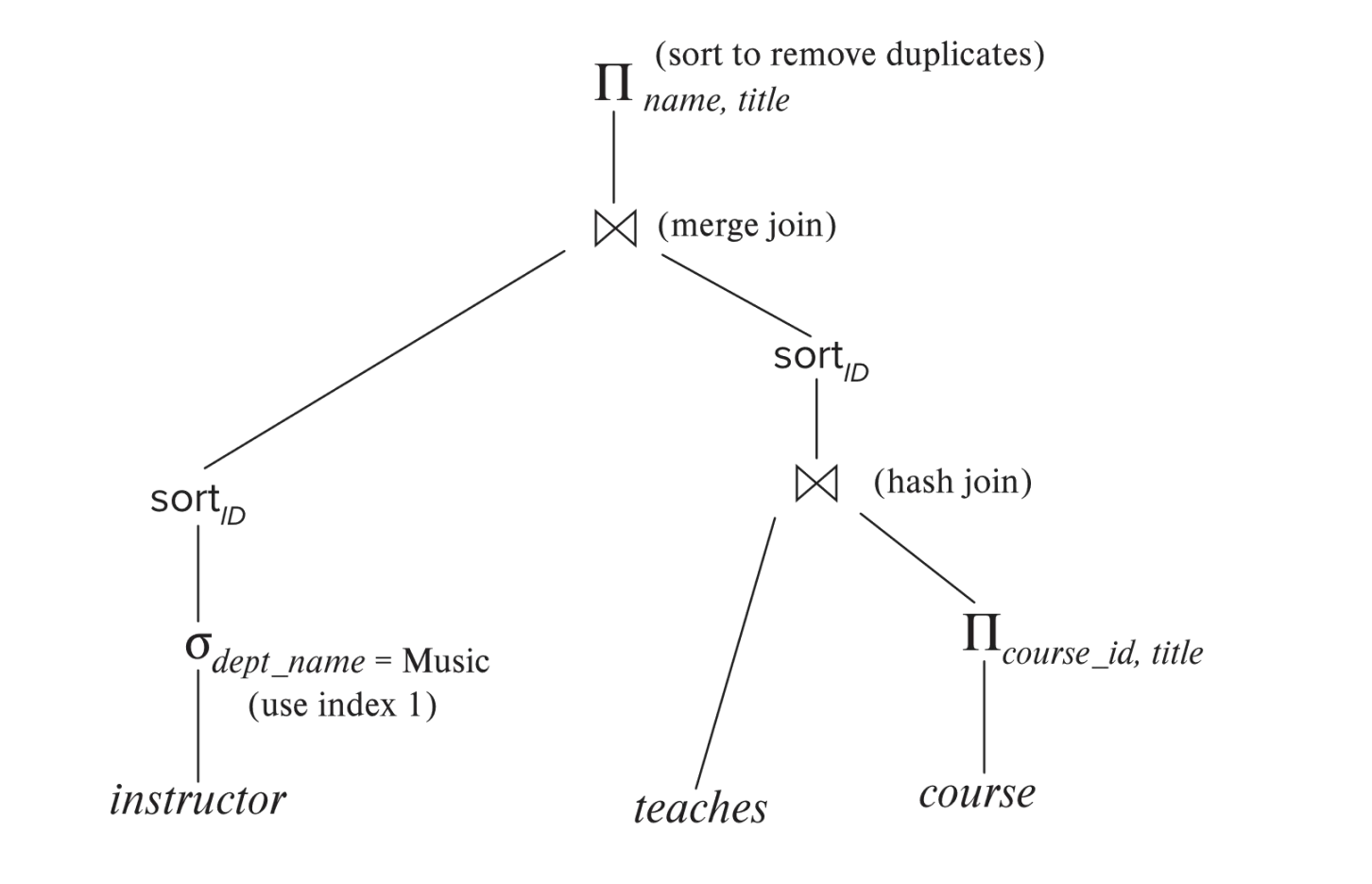
例如一个计划可能是:
- 用
dept_name上的索引筛选instructor - 将筛选后的结果按
ID排序 - 对
teaches和course做 hash join - 对两个输入做 merge join
- 最终排序去重并输出
name, title
关系代数树只说明操作结构;执行计划还为节点标注了实际算法与执行协调方式。
基于代价的查询优化
同一查询的不同计划,代价差异可能达到:
- 几秒
- 几分钟
- 甚至几天
Cost-based query optimization 通常分为三步:
- 使用等价规则生成逻辑等价表达式。
- 给每个表达式配置不同算法,得到候选 evaluation plans。
- 根据估计代价选择最便宜的计划。
代价估计依赖三类信息:
- 基本关系统计信息
- tuple 数量
- block 数量
- 属性 distinct value 数量
- 中间结果规模估计
- selection 后剩多少 tuple
- join 后产生多少 tuple
- 物理算法代价公式
- index scan / sequential scan
- nested-loop / merge join / hash join
- sort 的 I/O 代价
这一章最重要的闭环是:
statistics ↓cardinality estimation ↓operator cost estimation ↓plan comparison ↓chosen plan查看执行计划
多数数据库都允许查看 optimizer 选择的计划。
-- PostgreSQLEXPLAIN <query>;
-- PostgreSQL:同时实际执行,显示真实运行统计EXPLAIN ANALYZE <query>;其他系统的典型形式:
-- OracleEXPLAIN PLAN FOR <query>;SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
-- SQL ServerSET SHOWPLAN_TEXT ON;在 PostgreSQL 中,常见的成本显示形式是:
cost = f .. l其中:
f:产生第一条结果 tuple 的估计代价l:产生全部结果 tuple 的估计总代价
TIP
EXPLAIN和EXPLAIN ANALYZE的区别:
EXPLAIN:只展示估计计划,不真正执行查询EXPLAIN ANALYZE:执行查询,再把实际 tuple 数、实际耗时等信息与估计值一起展示因此,分析 cardinality estimation 是否失准时,
EXPLAIN ANALYZE更有价值。
Transformation of Relational Expressions
等价表达式
两个关系代数表达式 和 等价,指的是:
对每一个合法数据库实例,它们都产生相同的结果。
传统关系代数把 relation 当作集合。
SQL 的输入输出一般采用 multiset / bag semantics(多重集语义),所以优化器必须保证:
- 结果中的 tuple 值相同
- 每个 tuple 出现的次数也相同
一个 equivalence rule(等价规则) 给出两种可互换的表达式形式。
优化器可以用它把当前表达式改写为其他候选表达式。
Selection 与 Projection 规则
设 、、 为关系代数表达式, 为选择条件, 为属性集合。
Conjunctive Selection 的分解
含义:
- 多个
and连接的过滤条件可以拆开 - 拆开后,优化器可以把不同条件分别下推到不同输入上
Selection 的交换律
选择顺序不改变结果,但会影响执行代价:
- 更有选择性的条件先执行,通常能更早缩小中间结果
- 有索引的条件可能更适合优先执行
Projection 的合并
如果最终只需要属性集合 ,那么中间重复的投影可以省去:
前提是:
- 后续投影保留了最终需要的全部属性
Selection 与 Cartesian Product / Theta Join
也就是说:
- 笛卡尔积加连接条件可以直接表示为 join
- join 后再筛选的跨表条件可以合并进 join predicate
Join 规则
Join 的交换律
对于 theta join 和 natural join:
交换输入后,结果属性顺序可能不同;若属性顺序重要,可再加 projection 调整。
Natural Join 的结合律
它允许优化器改变 join order。
例如:
- 若 很小
- 而 很大
则应优先计算:
从而避免产生过大的中间关系。
Theta Join 的结合变换
若 只涉及 和 的属性,则:
这里本质是在保证谓词涉及关系不变的前提下,重新组织 join tree。
Selection 下推到 Join 输入
如果 只涉及 的属性:
如果 只涉及 , 只涉及 :
这就是 selection pushdown。
它通常有利,因为:
- join 前就减少 tuple 数
- 后续 join、sort、materialization 的代价都可能下降
Projection 下推到 Join 输入
若 join 条件 只涉及 中的属性:
更一般地,若:
- 是 join predicate 使用但 中未保留的 属性
- 是 join predicate 使用但 中未保留的 属性
则:
这是 projection pushdown。
核心要求:
可以尽早丢弃不需要的属性,但 join predicate 和最终输出仍需要的属性不能被提前删掉。
Set Operation、Aggregation 与 Outer Join 规则
Union 与 Intersection
交换律:
结合律:
注意:
- set difference
-不满足交换律
Selection 与集合操作
对于 和 也有类似分配规则。
此外:
但相同形式对 不成立。
Projection 与 Union
Selection 与 Aggregation
使用 表示:
- 按属性集合 分组
- 计算聚合表达式
若选择谓词 只涉及 grouping attributes ,则:
这意味着:
- 只按分组键过滤时,可以在聚合前先过滤
- 聚合输入变小,执行代价通常下降
若 predicate 涉及聚合值,例如 sum(salary) > 100000,就不能按此规则直接下推。
Outer Join 的基本规则
Full outer join 满足交换律:
Left outer join 与 right outer join 可互相转换:
若 只涉及保留侧 的属性,则 selection 可以下推:
若谓词 对右侧 的 null 扩展 tuple 会返回 false 或 unknown,即 是 null-rejecting predicate,则:
原因:
- left outer join 中没有匹配的 tuple 会在 属性上补
null - null-rejecting selection 最终会把它们全部删除
- 因此外连接可以改为内连接
Outer Join 的限制
内连接上的很多等价规则,不能机械地套到 outer join 上。
例如:
除非能证明 selection 对 teaches 的空值扩展 tuple 是 null-rejecting,且语义确实允许消去外连接。
Outer join 通常也不满足结合律:
WARNING优化时遇到 outer join,应先确认:
- 哪一侧需要保留未匹配 tuple
- selection 是否引用 null-supplying side
- selection 是否是 null-rejecting
- join reorder 是否会改变补
null的位置直接把内连接的下推、重排规则照搬到 outer join,会改变查询语义。
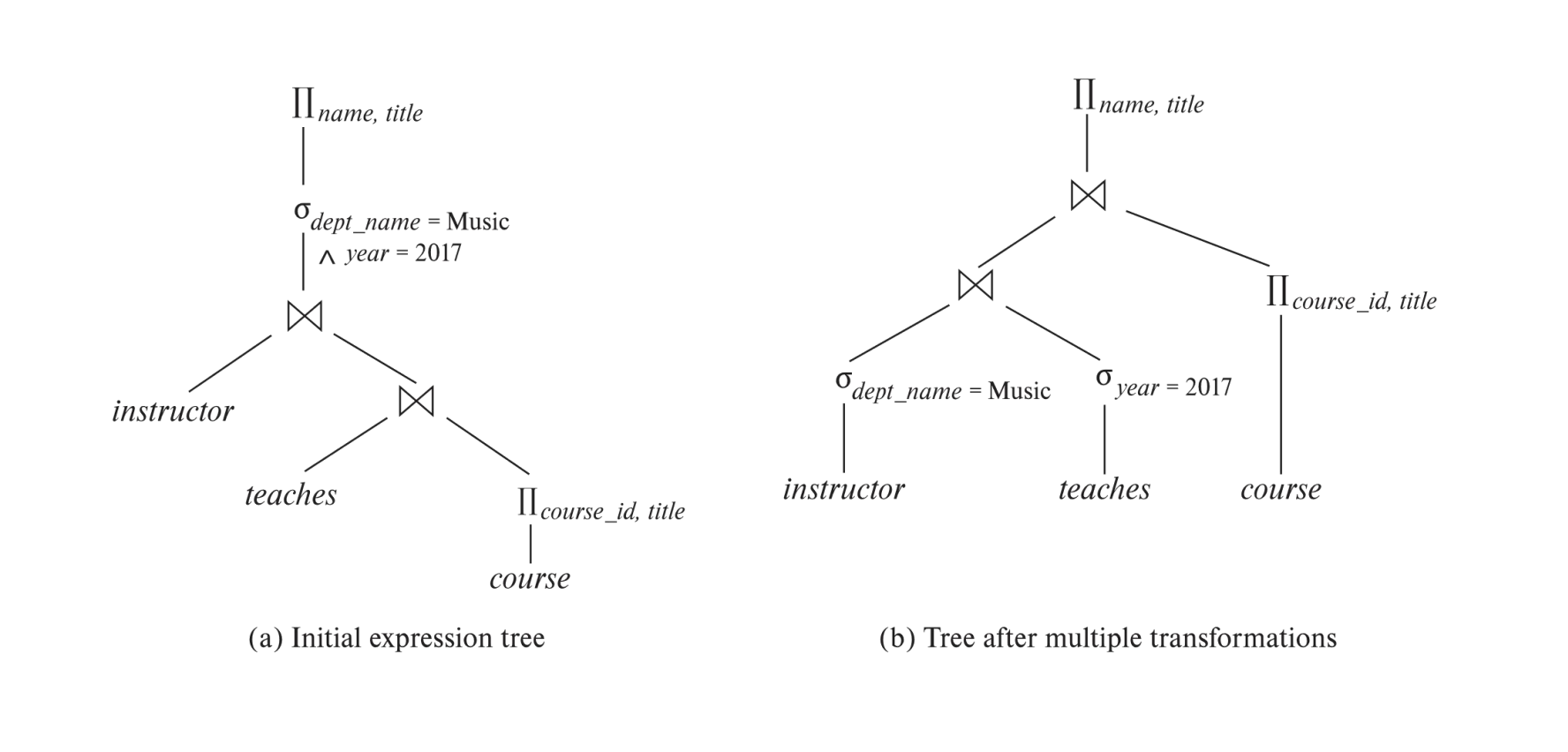
Multiple Transformations Example
查询目标:
找出 Music 系教师在 2017 年教授过的课程名称,并输出教师名与课程标题。
原始表达式:
优化过程可以分成三步。
Selection pushdown
两个 predicate 分别只依赖一个基本关系:
dept_name='Music'只涉及instructoryear=2017只涉及teaches
所以可以先筛选:
Join reorder
Music 系教师通常只占全部教师的一小部分,2017 年授课记录也只占所有 teaches 的一部分。
因此先做:
通常比先计算:
更容易得到较小的中间结果。
Projection pushdown
在 join 过程中,只保留必要属性:
instructor侧保留ID, nameteaches侧保留ID, course_idcourse侧保留course_id, title
于是最终树中,大量不参与后续计算的属性不会进入中间结果。
优化后的结构可以概括为:
等价表达式的生成
最直接的方法是:
- 从原表达式开始。
- 对当前已找到的每个表达式及其所有子表达式,尝试应用每条等价规则。
- 把新表达式加入候选集合。
- 重复直到不能产生新表达式。
伪代码思想:
EQ = {initial expression}
repeat 对 EQ 中每个表达式的每个子表达式应用全部可用规则 将新得到的等价表达式加入 EQuntil 不再出现新表达式问题是:
- 候选表达式数量可能极大
- 同一子表达式会被反复生成
- 时间和空间消耗都难以接受
优化方式:
- 共享公共子表达式:表达式用 DAG 而非大量重复的树表示。
- 检测重复表达式:同样的子表达式只保存一份。
- Dynamic Programming / Memoization:一个子问题的最优计划只计算一次。
- Cost-based pruning:明显不可能胜出的计划尽早剪枝。
- Heuristics:只搜索更有希望的结构,例如 left-deep join tree。
Statistical Information for Cost Estimation
为什么需要统计信息
执行一个 operator 的成本,依赖它输入关系的大小。
但在复杂查询中:
- operator 的输入通常不是基本表
- 输入是上一个操作产生的中间结果
因此 optimizer 必须估计:
- 中间关系有多少 tuple
- 每个 tuple 多大
- 需要多少 block
- 属性值分布如何
- 是否会产生大量重复值
这类估计称为:
Cardinality Estimation(基数估计):估计每个关系代数子表达式会产生多少 tuple。
Cardinality estimation 一旦严重失准,可能导致:
- 错误的 join order
- 错误的 join algorithm
- 错误的 index / scan 选择
- 实际执行代价远高于估计代价
Catalog 中的基本统计量
对于 relation ,系统 catalog 常保存:
| 记号 | 含义 |
|---|---|
| relation 中 tuple 的数量 | |
| 存储 的 block 数量 | |
| 一个 tuple 的大小 | |
| blocking factor:一个 block 可以容纳的 tuple 数 | |
| 属性集合 在 中出现的 distinct value 数,即 $ |
如果 tuple 紧密存放在文件中:
其中:
- 决定逻辑规模
- 更直接决定磁盘 I/O
- 是估计 selection 和 join 结果规模的关键统计量
Histogram
只有 min、max 和 distinct value 数,往往不足以描述数据分布。
例如:
- 年龄可能集中在
18–22 - 工资可能高度偏斜
- 某些 department 的 tuple 数可能远大于其他 department
数据库系统通常使用 histogram(直方图) 保存值分布信息。
常见形式:
- Equi-width histogram:每个桶覆盖相同的值域区间
- Equi-depth histogram:每个桶尽量包含相近数量的 tuple
用途:
- 更准确估计范围选择
- 更准确估计偏斜属性上的 join
- 降低 uniform distribution 假设带来的误差
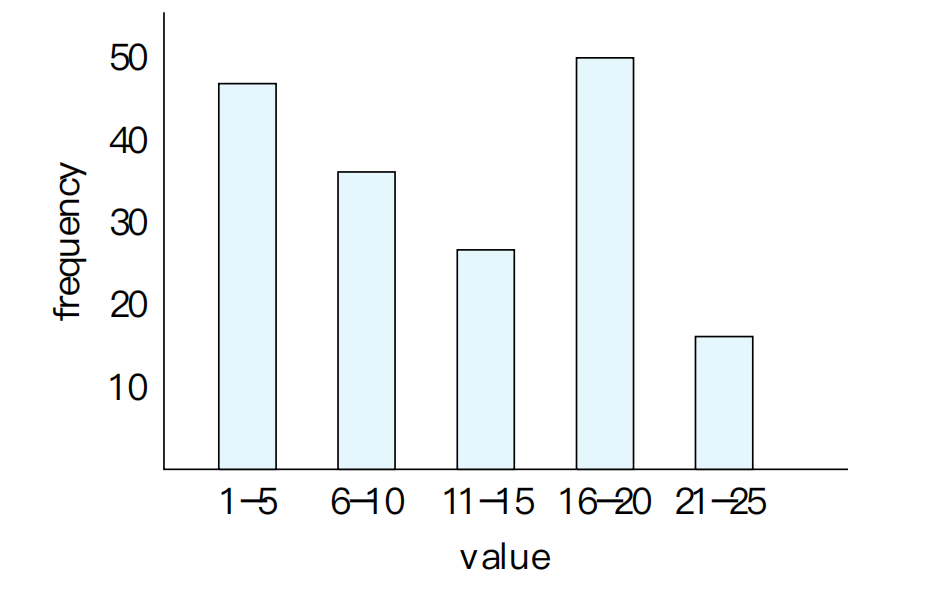
Selection 结果大小估计
Equality Selection
对于:
如果假设属性 的各个值均匀分布,则:
如果 是 key:
若查询值确实存在,通常估计为 1。
Range Selection
对于:
若 catalog 中有 与 ,并假设值均匀分布:
对于 的估计方式对称。
如果有 histogram:
- 应优先按桶统计结果数量
- 通常比单纯的
min / max + uniform distribution更准确
若完全没有有用统计信息, 6采用的粗略估计为:
复杂选择条件的 Selectivity
选择条件 的 selectivity(中选率) 定义为:
也就是:
- 一个随机 tuple 满足该条件的概率估计
Conjunction
对:
若假设各条件相互独立:
Disjunction
对:
若假设各条件独立:
Negation
WARNING独立性假设很容易失效。
例如:
dept_name='Comp. Sci.'salary > 100000可能高度相关。若 optimizer 把它们当作独立条件相乘,可能明显低估或高估结果规模。
Histogram、多列统计信息与执行期自适应机制,都是为了缓解这类误差。
Join 结果大小估计
设:
- 与 为两个关系
- natural join 的共同属性为
Cartesian Product
每个结果 tuple 的长度约为:
若 ,natural join 等同于 Cartesian product。
共同属性是某一侧的 Key
如果 是 的 key,则:
- 中每个 tuple 至多匹配 中一个 tuple
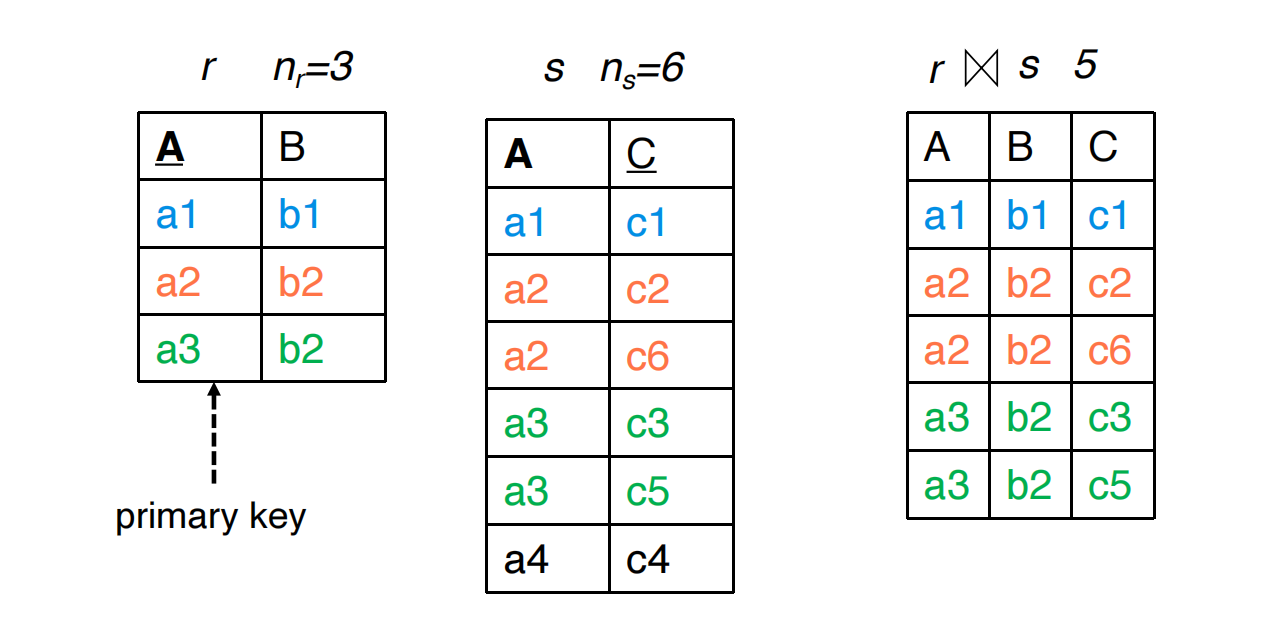
因此:
如果共同属性还是 中引用 的 foreign key,并且外键值均有效,则:
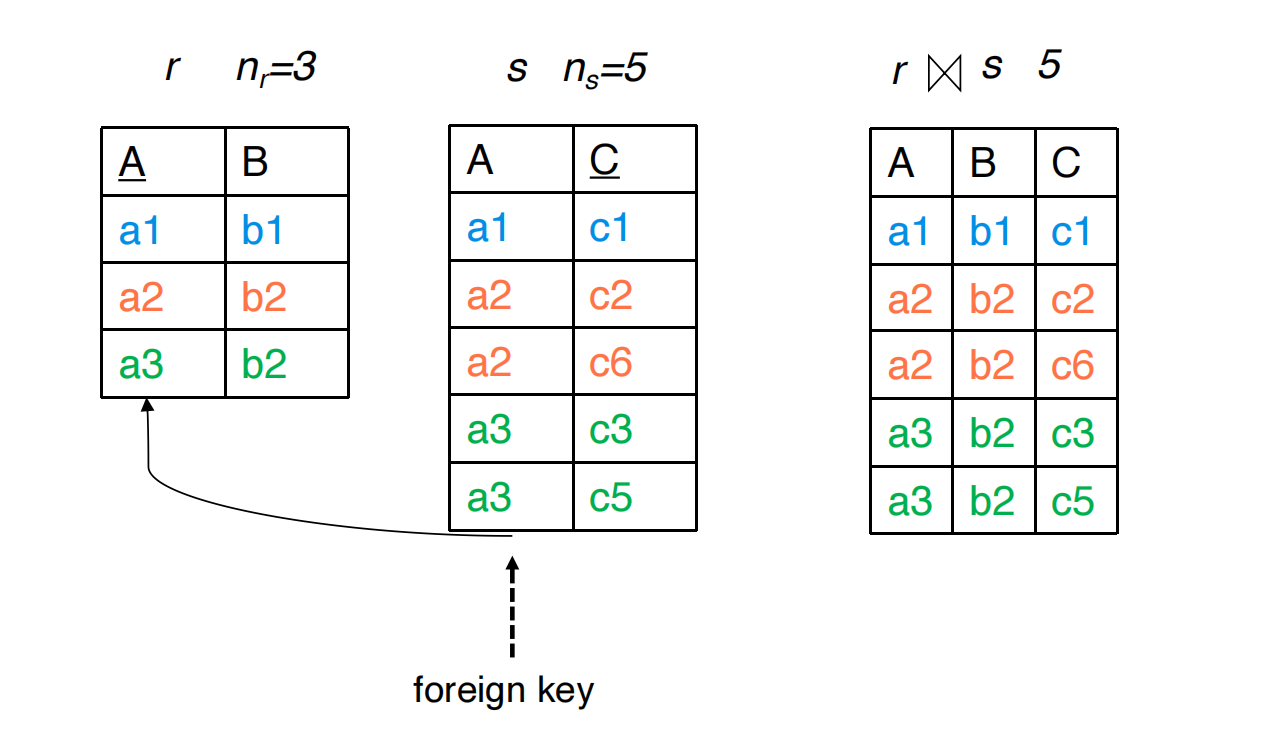
即:
外键侧每一行都恰好 join 到被引用表中的一行。
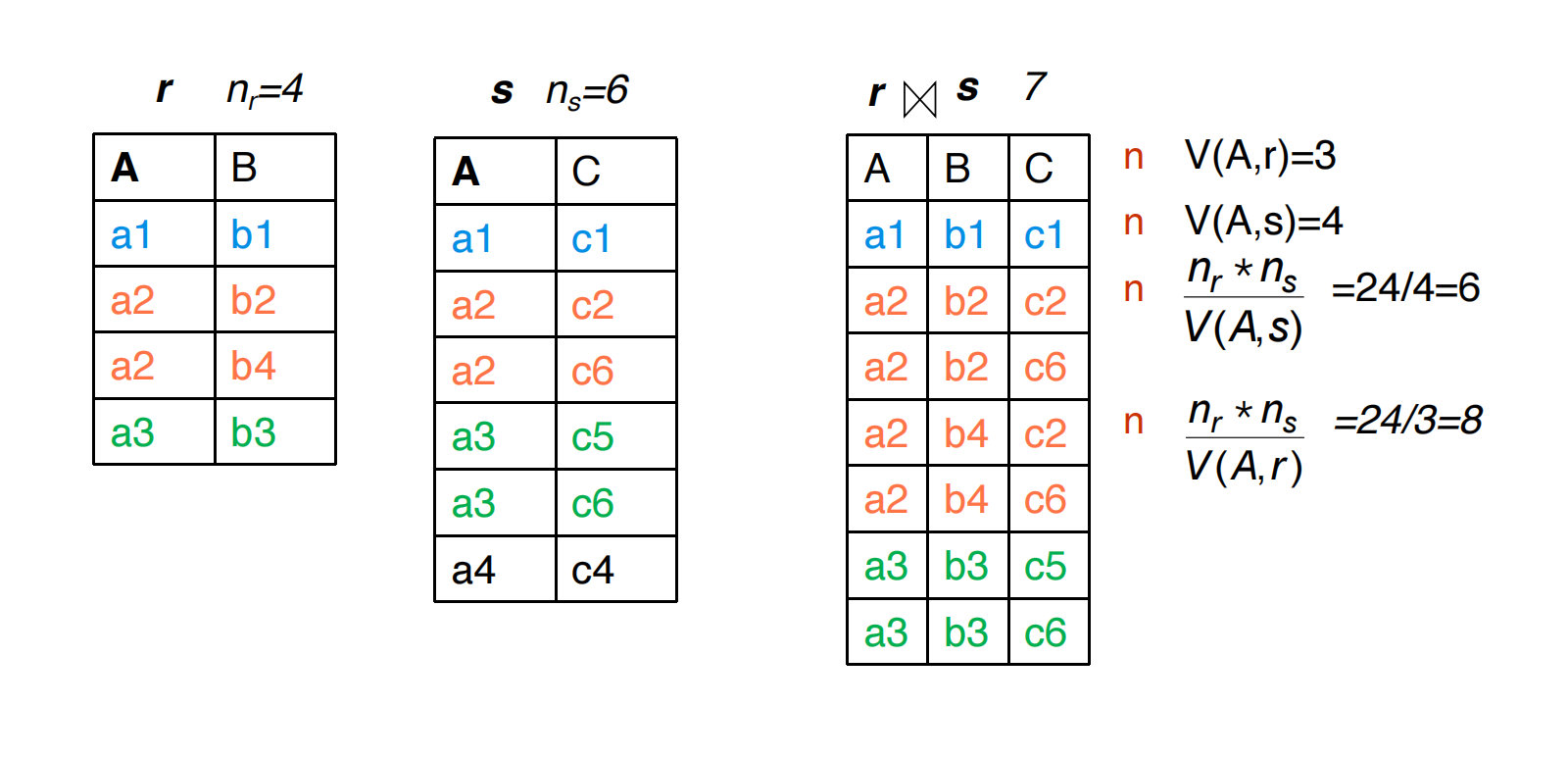
一般单属性 Join
若共同属性为 ,且 在两侧都不是 key,两种估计:
通常取较小者,即:
直观理解:
- distinct value 越多,同值碰撞越少
- join 结果规模通常越小
如果有 histogram,可以对每个相应桶分别估计后求和,从而处理数据偏斜。
表格示例
设:
| 关系 | tuple 数 | |
|---|---|---|
则两个方向的估计为:
取较小值:
实际 join 结果包含 7 个 tuple。
这个例子说明:
- 公式只是在分布假设下的估计
- 不保证等于真实结果
- 其价值在于为计划选择提供数量级判断
student ⋈ takes 示例
Catalog 给定:
| 统计量 | 数值 |
|---|---|
含义:
student.ID是主键takes.ID是引用student.ID的外键takes中出现了2500个不同学生- 这些学生平均每人选过:
门课程。
因为 takes.ID 是引用 student.ID 的外键:
即使不知道 foreign key,只使用 distinct value 估计:
取较小者,也会得到:
TIP这个例子要记住:
- 约束信息,例如 primary key / foreign key,可以直接给出更可靠的 cardinality。
- 统计估计是在不知道更强语义约束时的退而求其次。
其他操作的结果大小估计
Projection
对于单个属性集合 :
因为 projection 去重后,结果中每个 tuple 对应一个 distinct value。
Aggregation
按属性集合 分组:
因为每个不同 group 产生一条结果 tuple。
Set Operations
如果是在同一关系上的 selection 结果之间做集合操作,应 优先重写成复杂 selection:
再使用 selection 的 cardinality 估计公式。
如果两个输入来自不同关系,可采用粗略上界:
直接用这些上界作为粗略估计。它们可能不精确,但安全且计算便宜。
Outer Join
粗略估计为:
右外连接对称。
对于 full outer join:
这里实质上是偏保守的估计:
- 未精细扣除已经匹配的 tuple
- 适合作为简单代价估计的近似量
中间结果的 Distinct Value 估计
很多更上层的 cardinality estimate 又依赖 。
因此不仅要估计 tuple 数,还要估计中间结果上的 distinct value 数。
Selection
对 :
- 若 强制
A = constant:
- 若 限定 只能取给定集合中的若干个值:
- 若 是范围条件
A op v,设其 selectivity 为 :
- 其他情况使用近似:
Join
对 :
若属性集合 全部来自 :
若 包含来自两侧的属性,令:
- :来自 的部分
- :来自 的部分
近似:
Projection 与 Aggregation
- 投影后的属性 distinct value 与原关系中相同:
- aggregation 的 grouping attributes 也保留原 distinct value 情况。
- 对
min(A)、max(A)这类聚合结果,按分组属性 分组时:
- 对其他聚合结果,课件采用:
即粗略假设每个 group 的聚合结果不同。
Choice of Evaluation Plans
操作之间会相互影响
不能对每个 operator 各自选择局部最便宜的算法,然后期待整体计划最优。
例如:
- 对 ,hash join 的当前代价可能低于 merge join
- 但 merge join 会输出按 join attribute 排序的结果
- 这个有序结果可以直接用于接下来的 merge join、
order by或group by - 总体计划反而可能更便宜
因此 plan selection 必须考虑:
- 中间结果 cardinality
- 中间结果 physical property,例如排序顺序
- 后续 operator 对这些性质的利用
Join Order 的搜索空间
对于:
不同 join 顺序的数量非常大。
示例:
| Join Order 数量 | |
|---|---|
| 3 | 12 |
| 4 | 120 |
| 5 | 1680 |
| 7 | 665280 |
| 10 | 17643225600 |
直观例子():
子集 的 join order 有 12 种。若先求出该子集的最优顺序,再与 、 逐步合并,原本需要比较的 种组合可以理解为拆成 的两步选择。
因此不必生成全部 join order:动态规划把每个子集的最优顺序只计算一次并复用。
这说明:
- 枚举全部 join trees 在关系数稍大时就不可行
- 必须用动态规划、限制树形或启发式方法压缩搜索空间
Dynamic Programming 选择 Join Plan
动态规划的关键观察是:
如果已经知道某个 relation 子集的最优计划,就应复用它,而不应在更大 join 中重复求解。
令 bestplan[S] 表示:
- 计算 relation 集合 的最佳计划
- 以及该计划的估计代价
基本情况
当 只包含一个 relation 时:
- 应用只涉及 的 selection
- 考虑 sequential scan 与可用 index scan
- 保存成本最低的 access plan
递归情况
当 包含多个 relation 时:
- 枚举非空真子集
- 将 分成 与
- 分别取得这两个子集的最佳计划
- 尝试不同 join algorithm
- 保存总代价最小的组合
伪代码:
procedure FindBestPlan(S): if bestplan[S] has been computed: return bestplan[S]
if S contains only one relation: bestplan[S] = cheapest access plan for S using selections and available indices return bestplan[S]
for each non-empty proper subset S1 of S: P1 = FindBestPlan(S1) P2 = FindBestPlan(S - S1)
for each applicable join algorithm A: P = join P1 and P2 using A cost(P) = cost(P1) + cost(P2) + joinCost(A)
if cost(P) < bestplan[S].cost: bestplan[S] = P
return bestplan[S]需要额外注意:
- indexed nested-loop join 的 inner input 必须具有可利用的索引,且通常需要对应到一个基本关系。
- hash join 要考虑哪一侧作为 build relation。
- merge join 要考虑输入是否已排序,以及额外 sort 的成本。
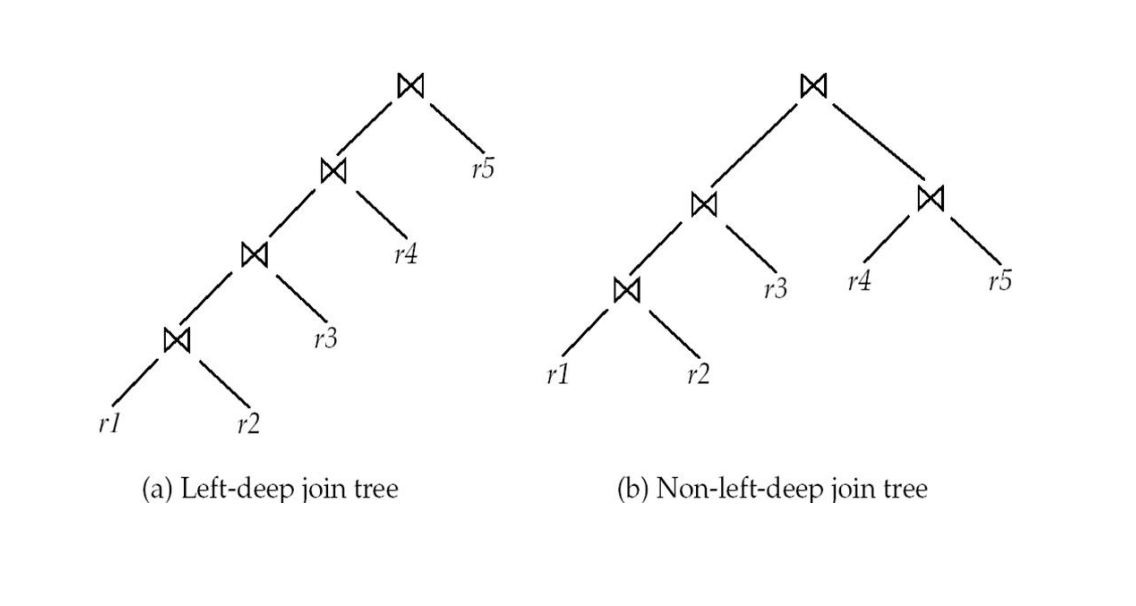
Left-Deep Join Tree
Left-deep join tree 的限制是:
每次 join 的右输入必须是一个基本关系,而不能是一个由 join 得到的中间结果。
例如 left-deep:
(((r1 ⋈ r2) ⋈ r3) ⋈ r4) ⋈ r5而下面是 bushy / non-left-deep 结构:
(r1 ⋈ r2) ⋈ (r3 ⋈ (r4 ⋈ r5))Left-deep 的优势:
- 搜索空间更小
- 适合 pipelined evaluation
- 每一层只需要把左侧中间流继续向上管道传递
- 右侧通常是可以直接扫描或使用索引访问的基本关系
复杂度:
| 搜索范围 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 允许 bushy trees 的 DP | ||
| 只考虑 left-deep trees 的 DP |
- 当 时,全 join order 规模约为
176亿 - bushy-tree 动态规划只需数量级约
59000的子组合计算
Interesting Sort Order
考虑:
三个关系通过共同属性 join。
对于第一个 join:
- hash join 也许成本最低
- merge join 也许成本更高,但会输出按 排序的结果
若接下来仍要按 做 merge join,则:
- 前一个 merge join 的排序结果可被复用
- 总成本可能低于“前一步局部最便宜”的选择
这种以后可能有价值的排序属性称为:
Interesting sort order:对后续 join、
order by或group by可能有用的中间结果排序顺序。
因此动态规划不能只保存:
- 每个 relation subset 的唯一最便宜计划
还要保存:
- 每个 subset 在不同 interesting sort order 下的最佳计划
通常 interesting order 的种类不多,所以不会显著改变复杂度数量级。
基于等价规则的 Cost-Based Optimization
仅处理 join order 还不够。更通用的 optimizer 需要同时处理:
- selection
- projection
- join
- aggregation
- outer join
- nested query rewrite
- physical operator selection
Physical equivalence rules 可以把逻辑节点转换成具体物理算法,例如:
- logical join → hash join
- logical join → merge join
- logical selection → table scan
- logical selection → index scan
高效实现通常需要:
- 用共享结构表示表达式,避免复制相同子树
- 快速检测重复 derivation
- 用 memoization 存储某个子表达式的最优物理计划
- 用 cost-based pruning 避免枚举所有计划
Heuristic Optimization
Cost-based optimization 很有价值,但优化本身也消耗时间。
常见 heuristic rules:
- 尽早执行 selection
- 尽早执行 projection
- 优先执行结果规模最小的 selection / join
- 避免不必要的 Cartesian product
- 优先考虑 left-deep join order
这些规则通常有效,因为它们倾向于压缩中间结果。
WARNING“Selection 越早越好”是一条 heuristic,不是绝对规律。
例如:
- 非常小
- 非常大
- 的 join attribute 上有索引
- selection predicate 涉及 的另一个没有索引的属性
此时先扫描整个 做 selection 可能很贵。
更好的计划可能是:
- 以小关系 为外表
- 利用 的 join 索引做 indexed nested-loop join
- join 后再过滤 selection 条件
所以最终仍应由 cost estimation 决定。
现实系统常采用混合策略:
- 对 nested block structure 与 aggregation 先用 heuristic rewrite
- 对各查询块内部的 join order 做 cost-based search
- 为优化器设定 optimization cost budget
- 超过预算时返回当前找到的最好计划
- 缓存已经求得的计划,供重复查询复用
对于很便宜的查询:
- 优化开销可能高于执行收益
- 系统可能只进行简单 heuristic optimization
对于高代价查询:
- 更充分的枚举和成本比较通常是值得的
Nested Subqueries
Correlated Evaluation
考虑查询:
select namefrom instructorwhere exists ( select * from teaches where instructor.ID = teaches.ID and teaches.year = 2022);内层查询引用了外层 relation 的属性:
instructor.ID这个属性叫做 correlation variable(相关变量)。
SQL 语义上,可以把内层 subquery 理解为一个依赖外层当前 tuple 的函数:
- 对外层
instructor的每一条 tuple - 带入其
ID - 执行一次内层查询
- 判断是否存在匹配的
teachestuple
这种执行方式称为:
Correlated evaluation(相关执行)。
问题:
- 外层有多少 tuple,内层可能就执行多少次
- 可能产生大量随机 I/O
- 对大表极其昂贵
Semijoin 与重复元组问题
上面的 exists 查询不能直接粗暴改写成普通 join:
select namefrom instructor, teacheswhere instructor.ID = teaches.ID and teaches.year = 2022;原因:
- 一名教师在 2022 年可能教授多门课程
- 普通 join 会为每条匹配
teachestuple 输出一份教师 tuple exists只要求“至少存在一条”,不会因为多次匹配而增加外层 tuple 的出现次数
为保持 SQL multiset 语义,应使用 semijoin(半连接)。
定义:
- 若 中 tuple 出现 次
- 且 中至少存在一条 tuple 与其满足 join condition
- 则 在 中仍出现 次
- 的属性不进入输出结果
因此查询可写为:
等价 SQL 还可以通过先去重再 join 实现:
with t1 as ( select distinct ID from teaches where year = 2022)select namefrom instructor, t1where t1.ID = instructor.ID;Anti-Semijoin
对于 not exists:
select namefrom instructorwhere not exists ( select * from teaches where instructor.ID = teaches.ID and teaches.year = 2022);可使用 anti-semijoin(反半连接):
含义:
- 保留
instructor中找不到任何匹配teachestuple 的那些 tuple
Decorrelation
一般形式:
select Afrom r1, r2, ..., rnwhere P1 and exists ( select * from s1, s2, ..., sm where P21 and P22 );其中:
- 不涉及 correlation variables
- 涉及 correlation variables
可转换为:
把 nested query 转换为 join / semijoin / anti-semijoin 的过程称为:
Decorrelation(去相关)。
收益:
- 不必对外层每条 tuple 重复执行 inner query
- 可以使用高效 join algorithm
- optimizer 可以统一考虑 join order 和索引
Scalar Aggregate Subquery
聚合子查询的 decorrelation 更复杂。
例子:
select namefrom instructorwhere 1 < ( select count(*) from teaches where instructor.ID = teaches.ID and teaches.year = 2022);含义:
- 找出 2022 年教授课程数超过 1 门的教师
可以先对 teaches 分组聚合:
然后与 instructor 做带条件的 semijoin:
但并非所有 scalar subquery 都能这样安全转换:
- 标量子查询返回多行时,原 SQL 可能产生 runtime exception
- 聚合、
null与重复语义会增加转换难度 - decorrelation 是否值得做,也应经过成本比较
因此现实优化器对复杂 nested subquery 的 decorrelation 支持通常有限。
Materialized Views
物化视图的作用
普通 view 通常只保存定义查询。
Materialized view(物化视图) 会把查询结果实际计算并存储下来。
例子:
create view department_total_salary(dept_name, total_salary) asselect dept_name, sum(salary)from instructorgroup by dept_name;如果系统频繁查询:
- 每个系的教师工资总额
那么物化该视图可以避免每次都:
- 扫描
instructor - 按
dept_name分组 - 重新计算
sum(salary)
查询时直接读物化结果即可。
代价是:
- 数据存在冗余
- 基表更新后,物化视图也必须同步更新
View Maintenance
保持物化视图与基表一致的任务称为:
Materialized View Maintenance(物化视图维护)。
可选方式:
- 每次基表更新后完整重算视图
- 使用触发器维护
- 在应用程序更新基表时同步维护
- 周期性重算,例如每天夜间刷新
- 使用数据库系统直接提供的 materialized view refresh 机制
完整重算逻辑简单,但通常代价大。
更常用的思想是:
只根据基表发生的变化,计算视图中应新增或删除的部分。
这叫 Incremental View Maintenance(增量视图维护)。
Differential 与 Incremental Maintenance
设 relation 发生变化:
- :插入到 的 tuple 集合
- :从 删除的 tuple 集合
这两个变化集合称为 relation 的 differential(差分)。
更新操作可等价看成:
- 先删除旧 tuple
- 再插入新 tuple
因此只讨论 insert / delete 即可覆盖 update 的核心逻辑。
常见关系操作的增量维护
Join
设物化视图:
若向 中插入 :
因为:
所以:
若从 中删除 :
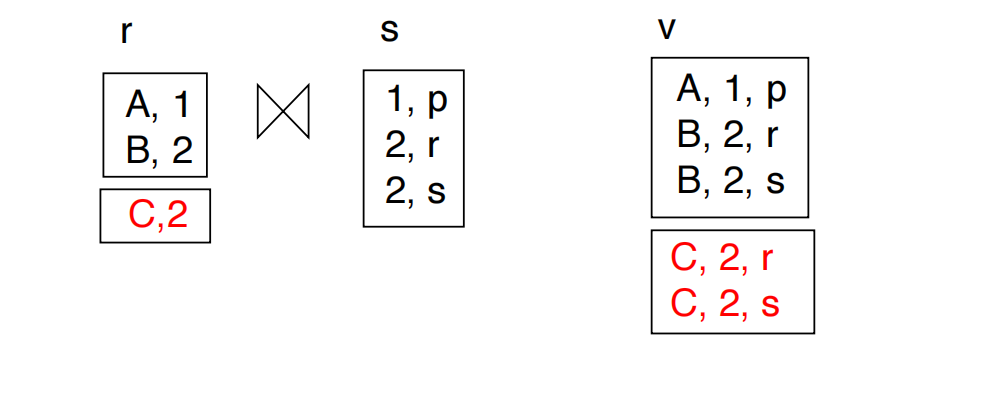
关键点:
- 不重新计算整个
- 只 join 发生变化的少量 tuple
Selection
设:
插入:
删除:
Projection
设:
projection 会去重,因此删除维护不能简单地删掉投影后的 tuple。
例如:
r(A, B) = {(a, 2), (a, 3)}ΠA(r) = {(a)}若只删除 (a,2):
(a)仍由(a,3)支持- 不能从物化结果中删除
(a)
解决方式:
- 对投影结果中的每条 tuple 维护一个 derivation count
- 插入导致该 tuple 再次出现时,计数加一
- 删除对应基表 tuple 时,计数减一
- 只有计数变为
0时,才真正删除投影结果 tuple
Aggregation
设按属性 分组。
count
- 插入 tuple:对应 group 的 count 加一;若 group 不存在则新建
- 删除 tuple:对应 group 的 count 减一;变为
0时删除 group
sum
- 插入 tuple:对应 group 的 sum 加上
B - 删除 tuple:对应 group 的 sum 减去
B - 还必须维护 count,以判断该 group 是否已没有 tuple
不能仅凭 sum = 0 判断 group 是否为空,因为:
- 仍存在若干 tuple,其值之和也可能恰好为
0
avg
不能仅凭旧平均值和新增 / 删除值直接可靠维护。
通常维护:
sumcount
最后计算:
min / max
- 插入时容易维护:与当前最小 / 最大值比较即可
- 删除时更复杂:若删除的是当前最小 / 最大值,需要在同组其他 tuple 中重新查找新值
为此可以在 (G, B) 上建立有序索引。
Set Operations
对:
- 向 插入 tuple 时:检查其是否存在于 ;存在则加入
- 从 删除 tuple 时:若其在交集中,则从 删除
- 的变化对称处理
union 与 set difference 也可类似维护。
Outer Join
Outer join 的维护与 join 类似,但更复杂:
- 删除一侧 tuple 后,另一侧某些 tuple 可能从“已有匹配”变为“需要补 null 的未匹配 tuple”
- 插入一侧 tuple 后,另一侧某些原先补 null 的 tuple 可能重新变为匹配结果
复合表达式
对于复杂视图表达式:
- 从最小子表达式开始
- 逐层计算每个子表达式的 differential
- 再向上传递变化
例如若:
且已经算出 的新增部分为 ,则由这一变化导致的新增 view tuple 为:
使用物化视图优化查询
物化视图不仅要被维护,还可以被 optimizer 用于 query rewrite。
将查询改写为使用物化视图
若已有:
用户查询:
可改写为:
是否采用该改写,仍应取决于成本估计:
v是否已建索引v是否足够小- 读取
v是否比重新计算r ⋈ s更便宜
展开物化视图反而更便宜
假设:
用户查询:
如果:
v上没有合适索引r.A上有索引s的 join attribute 上有索引
那么直接扫描 v 可能很贵,反而应该展开定义:
有物化视图,不代表每次都应该读取物化视图;它只是 optimizer 的一个额外候选 access path。
Materialized View Selection 与 Index Selection
系统需要决定:
- 哪些 view 值得物化
- 哪些 index 值得建立
二者共同特点:
- 都属于派生数据
- 都会加快某些查询
- 都会增加存储空间
- 都会增加更新维护成本
选择依据通常是 workload:
- 经常执行哪些查询
- 经常进行哪些更新
- 哪些查询有严格响应时间要求
- 可用存储空间和维护预算是多少
典型目标:
在空间限制和关键查询 / 更新约束下,使总体 workload 执行时间最小。
许多商业数据库提供 tuning assistant / wizard,协助 DBA 选择索引和物化视图。
Advanced Topics in Query Optimization
Top-K Queries
很多查询只需要排序结果中的前 条:
select *from r, swhere r.B = s.Border by r.A ascendinglimit 10;若系统先生成完整 join 结果,再排序并只保留 10 条:
- 大量中间结果最终被丢弃
- 当 很小时极其浪费
优化思路:
有序流水执行
如果能利用 r.A 上的索引按升序扫描 r,并以 r 作为 indexed nested-loop join 的外表:
- 可以较早地产生较小
A值对应的 join 输出 - 得到前 10 条后可能提前停止
估计阈值并加入过滤条件
估计 top-10 结果中最大的 r.A 值为 ,将查询加上:
and r.A <= H如果结果少于 10 条:
- 增大
- 重新执行
如果多于 10 条:
- 只保留排序后的前
10条
Optimization of Updates 与 Halloween Problem
考虑:
update Rset A = 5 * Awhere A > 10;假设:
- 属性
A上有索引 - 系统使用该索引扫描所有
A > 10的 tuple - 找到 tuple 后立即修改
A与索引项
那么同一条 tuple 更新后,新的索引项可能再次落到尚未扫描的位置。
该 tuple 可能被再次发现并重复更新。
这称为:
Halloween Problem:更新改变了用于定位待更新 tuple 的查询执行过程,使同一 tuple 被错误地反复处理。
解决方式:
总是延迟更新
- 第一遍只收集所有需要更新的 tuple 及新值。
- 第二遍统一修改 relation 与 index。
优点:
- 一定安全
缺点:
- 即使更新完全不会影响扫描路径,也承担额外存储与执行代价
仅在必要时延迟更新
如果 update 不影响:
where中涉及的属性- 当前扫描所依赖的 index 属性
则可以立即更新。
否则:
- 先收集
- 再统一执行
教材还指出:
- 即使更新影响索引属性,如果扫描方向保证更新后的索引项不会再次被遇到,也可能安全地即时更新。
- 对大量更新,可先批量收集,再按每个 index 的顺序排序后更新,从而减少随机 I/O。
Join Minimization
有时查询来自 view 展开,包含了其实不需要的 join。
例子:
select r.A, r.Bfrom r, swhere r.B = s.B;若满足:
r.B是引用s.B的 foreign keyr.B声明为not null- 查询不需要
s的任何属性 - 查询也不对
s施加额外 filtering condition
则与 s 的 join 不会:
- 删除
r中任何 tuple - 产生
rtuple 的额外副本
因此可删除该 join:
select r.A, r.Bfrom r;课件还给出含重复别名的例子:
select r.A, s2.Bfrom r, s as s1, s as s2where r.B = s1.B and r.B = s2.B and s1.A < 20 and s2.A < 10;由于 s2.A < 10 已蕴含 s1.A < 20 的筛选作用,在适当约束成立时,与 s1 的 join 可能是冗余的,可以删除。
Multiquery Optimization 与 Shared Scan
考虑两个查询:
-- Q1select *from (r natural join t) natural join s;
-- Q2select *from (r natural join u) natural join s;两个查询可能共享子表达式:
可以尝试:
- 只计算一次
- 在两个查询中复用
但不能盲目复用:
- 也许
r ⋈ s本身非常大 - 分别按原查询结构执行反而更便宜
Multiquery optimization 的目标是:
面向一组查询选择总体代价最低的联合执行方式,并在确实有收益时共享公共子表达式。
一种便宜但不一定最优的 heuristic:
- 分别优化每条查询。
- 在各自最佳计划中寻找相同子表达式。
- 若有利,则共享其计算结果。
Shared scan 是常见特例:
- 多条查询都要扫描同一个很大的 relation
- 系统只从磁盘读一次
- 将扫描产生的数据流同时供给多条查询
物化视图维护中,多个 view 的更新计划也可能共享子表达式,因此同样可利用 multiquery optimization。
Parametric Query Optimization
考虑参数化查询:
select *from r natural join swhere r.a < $1;在编译 / 准备计划时:
- 参数
$1的实际值还未知
不同参数值可能导致不同最优计划:
- 阈值很小:index scan + indexed join 可能好
- 阈值很大:full scan + hash join 可能好
三种处理方式:
每次执行时重新优化
- 能针对实际参数生成计划
- 但优化开销可能过大
Parametric Query Optimization
- 预先生成一组计划
- 每个计划在某一段参数取值范围内最优
- 运行时知道
$1后,从该集合中快速选择计划
课件指出:
- 当参数数目约为
1–3时,所需保存的最优计划集合通常较小
Query Plan Caching
- 若 optimizer 判断不同参数值下同一计划都足够好
- 则缓存计划并重复使用
- 否则重新优化
计划缓存实践中很常见,但在数据偏斜明显时可能选择到很差的计划。
Adaptive Query Processing
前面的优化都依赖统计估计,而统计估计可能失准。
Adaptive query processing 允许系统在运行时修正选择。
两类方法:
Adaptive Operator
operator 在执行过程中根据真实输入大小决定算法。
例如:
- 外表很小:选择 indexed nested-loop join
- 外表变大:切换为 hash join
Runtime Re-optimization
系统在执行过程中监控:
- 实际 tuple 数
- 实际中间结果大小
- 与 optimizer 估计值的偏差
若偏差大到说明原计划严重不合适:
- 停止当前执行。
- 使用已观测到的真实统计信息重新优化。
- 以新计划重新启动执行。
风险:
- 重启本身有代价
- 必须避免反复 abort / restart