

概述
Chapter 3 解决的是:
- SQL 的基本查询怎么写
- 聚合、子查询、增删改怎么表达
- 单条 SQL 怎样完成常见数据操作
Chapter 4 进一步解决:
- join、view、完整性约束、事务、权限这些 数据库内部能力
- 也就是:数据库自己如何更规范地组织和保护数据
Chapter 5 再往前走一步,讨论的是:
- SQL 怎样和通用编程语言协作
- 为什么业务逻辑有时会被放进数据库内部执行
- trigger、递归查询、窗口函数、OLAP 这些 更高级的 SQL 能力 到底在干什么
所以这一章的核心是:
数据库不只是被动存数据。 它还可以和程序联动、主动执行逻辑、表达递归关系、直接支持分析型查询。
目录
- 概述
- 目录
- Accessing SQL from a Programming Language
- Functions and Procedures
- Triggers
- Recursive Queries
- Advanced Aggregation Features
- Ranking
rank()与dense_rank()- 低效但直观的 基础 SQL 排名写法
- 分组内排名
partition by - 其他排名函数
- Windowing
- 移动窗口
- 常见窗口边界
- 分区内累计和
- OLAP
- 什么是 OLAP
- 维度属性与度量属性
- 交叉表
cross-tab/pivot-table - Data Cube
- Hierarchy、roll up、drill down、slice、dice、pivot
- 把交叉表表示成关系
cubegrouping()与把null还原成allrollup- 多个
rollup/cube组合 grouping sets:更精细地指定分组集合- MOLAP / ROLAP / HOLAP
- 预计算与优化
merge
Accessing SQL from a Programming Language
为什么单靠 SQL 不够
- SQL 不是通用编程语言
- 它没有通用语言那样完整的表达能力
- 像 打印报表、和用户交互、把结果发给 GUI、走网络请求 这些操作,SQL 本身做不了
所以数据库程序员必须把 SQL 和 宿主语言(Java、C、C++、Python 等)结合起来。
- SQL 擅长描述要什么数据
- 通用语言擅长控制流程、组织交互、处理外部资源
这就是 数据库应用程序 存在的意义。
两条路线:API vs Embedded SQL
从通用编程语言访问数据库,主要有两种做法:
1. API 方式
程序通过一组库函数去:
- 建立连接
- 发送 SQL
- 逐行取回结果
典型代表:
JDBC:Java 用ODBC:C / C++ / C# 常用
2. Embedded SQL 方式
把 SQL 直接嵌进宿主语言源码里。
-
编译时先由预处理器把嵌入式 SQL 翻译成函数调用
-
运行时再通过底层 API 连库并执行
-
API:你自己显式写 调用数据库接口 的代码
-
Embedded SQL:你把 SQL 写在程序里,编译器/预处理器帮你翻译
JDBC
JDBC 的基本流程
JDBC 是 Java 访问 SQL 数据库的标准 API。
它的基本模型非常经典:
- 打开连接
Connection - 创建语句对象
Statement - 执行查询或更新
- 读取
ResultSet - 处理异常
- 关闭资源
一个极简骨架是:
Connection conn = DriverManager.getConnection(url, user, passwd);Statement stmt = conn.createStatement();// do actual workstmt.close();conn.close();这一套流程背后的意思很像:
Connection:我先和数据库服务器建立会话Statement:我拿到一个 发 SQL 命令的工具ResultSet:数据库把查询结果封装成一个可迭代结果集
JDBC 查询与更新示例
slides 给了两个最基础的例子。
更新:插入一条教师记录
stmt.executeUpdate( "insert into instructor values('77987', 'Kim', 'Physics', 98000)");这里用的是 executeUpdate(),适合:
insertupdatedelete- DDL 之类不返回结果表的语句
查询:按院系统计平均工资
ResultSet rset = stmt.executeQuery( "select dept_name, avg(salary) from instructor group by dept_name");while (rset.next()) { System.out.println(rset.getString("dept_name") + " " + rset.getFloat(2));}这里体现出几个关键点:
executeQuery()用于返回结果表的查询rset.next()把游标推进到下一行- 取列值可以按 列名,也可以按 列号
例如:
rset.getString("dept_name")rset.getString(1)
如果 dept_name 正好是 select 结果的第一列,这两个就等价。
PreparedStatement 与 SQL 注入
只要 SQL 中要拼接用户输入,就应该优先使用
PreparedStatement。
例如:
PreparedStatement pStmt = conn.prepareStatement( "insert into instructor values(?,?,?,?)");pStmt.setString(1, "88877");pStmt.setString(2, "Perry");pStmt.setString(3, "Finance");pStmt.setInt(4, 125000);pStmt.executeUpdate();这里的核心思想是:
- SQL 模板先固定下来
- 用户输入只作为 参数值 绑定进去
- 数据和 SQL 结构分离
这比字符串拼接安全得多。
WARNING比如你如果写:
那当用户输入:
最后就会变成:
where条件恒真,整张表都会被返回。更恶意一点,还可能输入:
这就是 SQL injection(SQL 注入)。
所以经验规则非常简单:
- 不要把用户输入直接拼成 SQL 字符串
- 要用 prepared statement / 参数绑定
它不仅能防攻击,也能避免名字里带引号这种正常输入把 SQL 搞坏。比如 D'Souza。
元数据 metadata
JDBC 不只是 查数据 ,它还能 查数据库自己的结构信息 。
这类信息叫 metadata(元数据),也就是 关于数据的数据 。
1. ResultSetMetaData
用于查看某个查询结果有哪些列、每列类型是什么。
ResultSetMetaData rsmd = rs.getMetaData();for (int i = 1; i <= rsmd.getColumnCount(); i++) { System.out.println(rsmd.getColumnName(i)); System.out.println(rsmd.getColumnTypeName(i));}这很适合写 通用查询结果打印器。
2. DatabaseMetaData
用于查看数据库里存在哪些表、某张表有哪些列。
DatabaseMetaData dbmd = conn.getMetaData();ResultSet rs = dbmd.getColumns(null, "univdb", "department", "%");这里四个参数大致对应:
- catalog
- schema pattern
- table pattern
- column pattern
所以这个查询的意思就是:
找
univdb.department里所有列,并返回列名、类型等信息。
JDBC 中的事务控制
默认情况下,JDBC 每执行一条 SQL 就自动提交一次。
这叫 auto commit。
conn.setAutoCommit(false);// 多条更新conn.commit();// 或者 conn.rollback();为什么默认自动提交有时不好?
因为很多业务操作不是 一条 SQL 就结束的,而是多步更新必须一起成功。
例如转账:
- A 扣钱
- B 加钱
如果只执行完第一步就自动提交,而第二步失败,就会把数据库留在不一致状态。
所以:
- 单条独立语句,自动提交问题不大
- 多步逻辑更新,通常要关闭自动提交,自己控制
commit/rollback
调用函数 / 过程与大对象
JDBC 还能调用数据库里的函数和存储过程,用 CallableStatement:
CallableStatement cStmt1 = conn.prepareCall("{? = call some_function(?)}");CallableStatement cStmt2 = conn.prepareCall("{call some_procedure(?,?)}");这说明:
- 数据库内部不只有表
- 还可以有 可调用逻辑单元
另外,JDBC 对大对象也有支持:
Blob:二进制大对象Clob:字符大对象
可以通过:
getBlob()getClob()
取出来,也可以把输入流绑定进去更新。
这类数据常见于:
- 图片
- 文档
- 大段文本
- 音视频片段等
SQLJ
slides 提到:JDBC 很灵活,但 太动态 了。
- 很多 SQL 错误只有运行时才能发现
- 编译器很难提前帮你检查
于是出现了 SQLJ,可以把 SQL 更紧密地嵌入 Java:
#sql iterator deptInfoIter (String dept_name, int avgSal);#sql iter = { select dept_name, avg(salary) as avgSal from instructor group by dept_name};它的优点是:
- 更接近 嵌入式 SQL 的感觉
- 编译阶段能做更多检查
但从现代工程角度看,JDBC / ORM 框架更常见。
ODBC
ODBC 的思想
ODBC 是一种更通用的数据库接口标准。
你可以把它理解成:
- 应用程序面对统一接口
- 不同数据库厂商各自提供 driver
- 应用通过 driver 去和具体 DBMS 通信
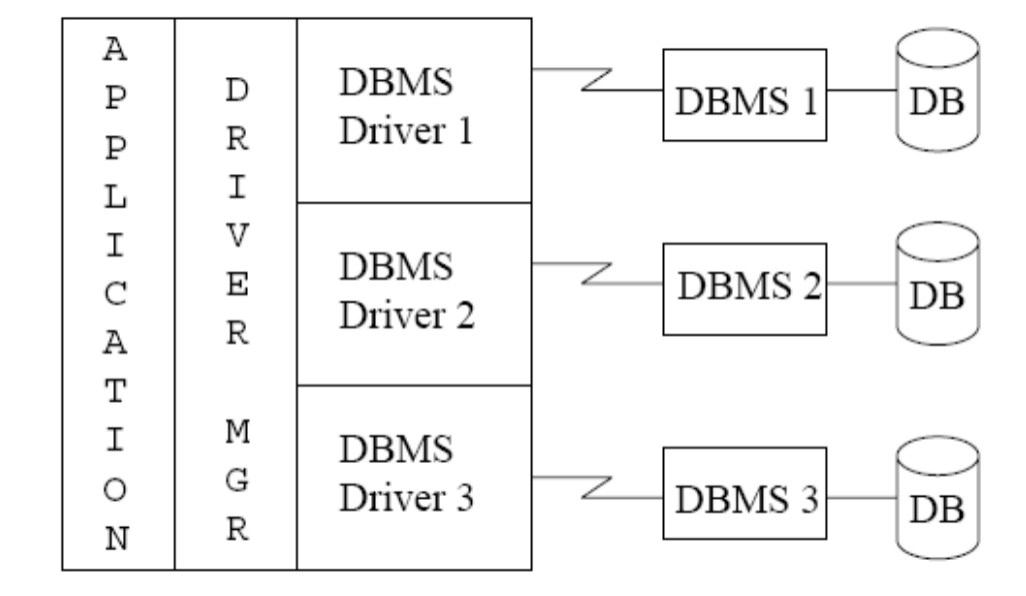
应用程序不用为每个数据库重写一套完全不同的接口代码, 而是通过 ODBC 驱动层去适配不同 DBMS。
- Embedded SQL 往往绑定某个特定 DBMS
- 因而可移植性差
- 也不方便同时访问多个数据库并做互操作
于是 ODBC 试图提供一种 像打印机驱动那样 的统一访问模式:
- 应用程序只面对 ODBC API
- 中间由 Driver Manager 负责装载、管理驱动
- 再由具体 ODBC Driver 去和某个 DBMS 通信
从体系结构上看,ODBC 至少包含三层:
- Application
- Driver Manager
- 具体 Driver + Data Source
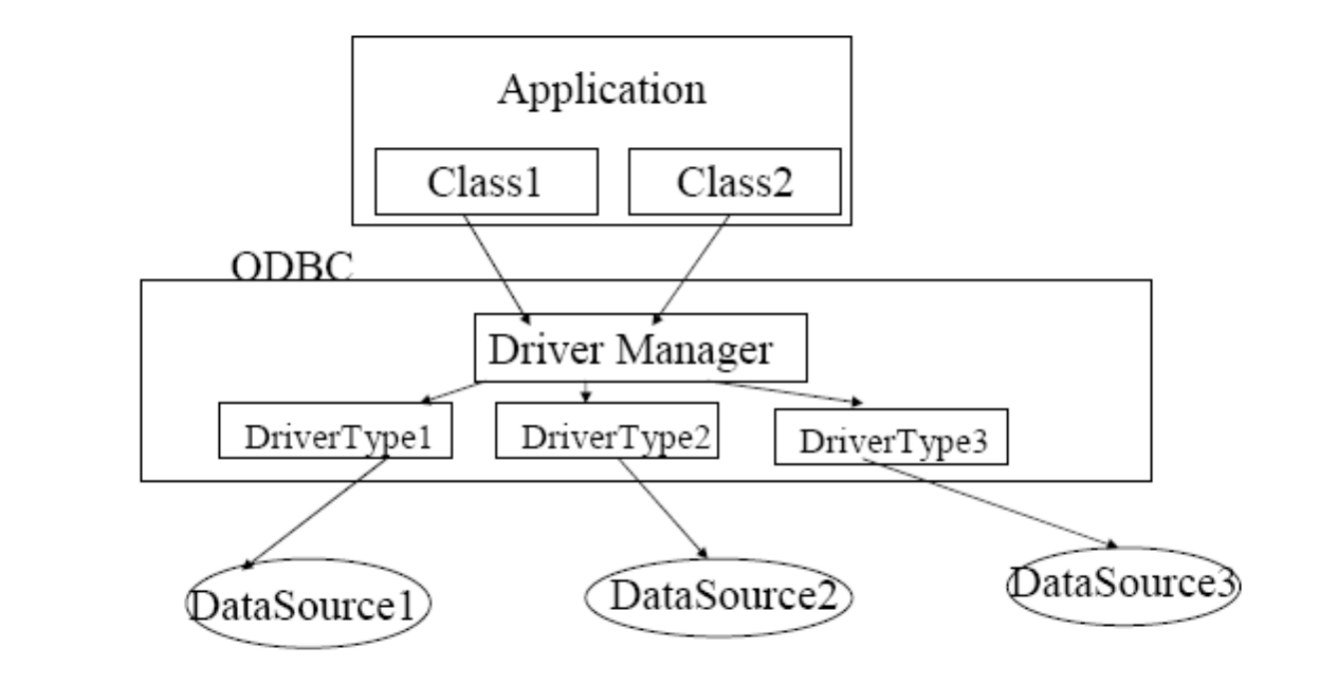 其中:
其中:- Driver Manager 负责管理应用与驱动之间的通信、装载驱动、配置数据源
- Driver 负责把 ODBC 标准调用翻译成某个数据库能理解的调用
- Data Source Name(DSN) 则把一个具体连接包装成名字,里面通常包含服务器名、驱动、数据库名等信息
所以 ODBC 的真正价值不只是 多一个 API ,而是:
它把 应用如何访问数据库 与 底层到底是哪家数据库 进一步解耦了。
ODBC 的执行流程
ODBC 的程序结构,和 JDBC 的逻辑其实很像,只是它更底层、更 C 风格。
常见步骤:
- 分配环境句柄
- 分配连接句柄
SQLConnect()建立连接- 分配语句句柄
SQLExecDirect()执行 SQLSQLBindCol()绑定输出列SQLFetch()逐行取结果- 释放语句 / 断开连接 / 释放句柄
例如:
SQLAllocEnv(&env);SQLAllocConnect(env, &conn);SQLConnect(conn, "db.yale.edu", SQL_NTS, "avi", SQL_NTS, "avipasswd", SQL_NTS);其中:
SQL_NTS表示 这是一个以\0结尾的字符串
查询示例:
char *sqlquery = "select dept_name, sum(salary) from instructor group by dept_name";error = SQLExecDirect(stmt, sqlquery, SQL_NTS);接着绑定结果列:
SQLBindCol(stmt, 1, SQL_C_CHAR, deptname, 80, &lenOut1);SQLBindCol(stmt, 2, SQL_C_FLOAT, &salary, 0, &lenOut2);while (SQLFetch(stmt) == SQL_SUCCESS) { printf("%s %g\n", deptname, salary);}这里的直觉是:
- 查询结果的第 1 列自动放进
deptname - 第 2 列自动放进
salary - 每次
fetch就填一行
如果长度字段返回负值,往往表示该列是 null。
ODBC :句柄、数据类型与一致性
1. 句柄(handle)是 ODBC 的核心组织方式
ODBC 程序通常会维护多层句柄:
- 环境句柄:整个 ODBC 运行环境
- 连接句柄:某个具体数据源连接
- 语句句柄:某条 SQL 语句的执行上下文
- 描述符句柄:参数/结果集元数据描述
它们是分层的:
- 一个环境下可以开多个连接
- 一个连接下可以开多个语句
所以 ODBC 代码看起来会很 句柄化 。
例如:
SQLAllocHandle(SQL_HANDLE_ENV, NULL, &hEnv);SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (SQLPOINTER) SQL_OV_ODBC3, SQL_IS_INTEGER);SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDBC);SQLAllocHandle(SQL_HANDLE_STMT, hDBC, &hSTMT);这里先设置 ODBC 版本,再逐层申请环境、连接、语句句柄。
2. ODBC 有自己的标准数据类型
例如:
SQL_CHARSQL_INTEGERSQL_FLOATSQL_VARCHAR
而具体 DBMS 自己的类型,需要由驱动负责映射到这些 ODBC 标准类型。
也就是说,ODBC 的 统一接口 并不意味着底层数据库类型真的完全一样,而是:
由驱动把各家数据库的差异尽量折叠到一套共同接口里。
3. 统一 也不是绝对统一
ODBC 的一致性级别(conformance levels):
- API 一致性
- SQL 语法一致性
这说明:
- 理论上 ODBC 想给统一访问方式
- 但不同 DBMS、不同驱动仍可能只支持其中一部分能力
所以工程上不能想当然地认为:
只要用了 ODBC,一切数据库差异都会自动消失。
ODBC 的结果读取:SQLBindCol vs SQLGetData
ODBC 查询结果通常会配合 SQLFetch() 使用,两种常见读取方式:
1. SQLBindCol
先把结果列绑定到 C 变量,再 fetch:
SQLBindCol(hSTMT, 1, SQL_C_CHAR, deptname, 80, &lenOut1);SQLBindCol(hSTMT, 2, SQL_C_FLOAT, &salary, 0, &lenOut2);
while (SQLFetch(hSTMT) == SQL_SUCCESS) { printf("%s %g\n", deptname, salary);}它的特点是:
- 一次绑定,后续每次
fetch自动填充变量 - 很适合结构固定的结果集
2. SQLGetData
是在已经定位到当前记录后,再显式取某列数据。
所以它和 SQLBindCol 的差别可以粗略记成:
SQLBindCol:提前绑定,后面自动填SQLGetData:每到一行再主动取值
如果你把 JDBC 类比进来:
SQLBindCol + SQLFetch有点像提前告诉系统 把列填到这些变量里SQLGetData更像每次对当前行再调用getXXX()
ODBC 的结束阶段
ODBC 的资源释放顺序也很重要,通常是:
- 释放语句句柄
- 断开连接
- 释放连接句柄
- 释放环境句柄
例如:
SQLFreeHandle(SQL_HANDLE_STMT, hSTMT);SQLDisconnect(hDBC);SQLFreeHandle(SQL_HANDLE_DBC, hDBC);SQLFreeHandle(SQL_HANDLE_ENV, hEnv);这个顺序背后的逻辑很自然:
- 先清理最里层 语句
- 再关闭 连接
- 最后释放整个 ODBC 环境
ODBC 的预处理语句
ODBC 也支持 prepared statement:
SQLPrepare():先准备 SQL 模板SQLBindParameter():再绑定参数SQLExecute():最后执行
这和 JDBC 的 PreparedStatement 是同一类思想。
它适合:
- SQL 要反复执行很多次
- SQL 里有参数占位符
- 需要防 SQL 注入
slides 也专门用 ODBC 再次强调了 SQL injection 的风险,所以要记住:
- prepared statement 不是 Java 特有技巧
- 它是数据库编程里的通用安全原则
Embedded SQL
Embedded SQL 是另一条非常经典的路线:不是在程序里手工调用一堆 API,而是把 SQL 直接嵌入宿主语言源码中。
- SQL 是 computation incomplete(计算不完备)
- SQL 是 resource incomplete(资源不完备)
也就是:
- 它不擅长表达一般性的控制流程与复杂算法
- 它也不擅长直接管理输入输出、文件、界面、系统资源
所以需要 宿主语言 + SQL 联合工作。
宿主语言与宿主变量
嵌入式 SQL 的核心是:
- 在宿主语言里直接写 SQL
- 用专门语法标出 这里是 SQL
例如:
EXEC SQL <embedded SQL statement>;更准确地说,SQL 标准会把 SQL 嵌入到多种语言里,比如:
- C
- Java
- Cobol
这些语言就叫 host language(宿主语言)。
不同语言的标记方式略有差异:
- C 风格常写成
EXEC SQL ... ; - Java 的某些嵌入形式会写成
#sql { ... }
SQL 用到宿主语言里的变量时,要在变量名前加冒号 :。
例如:
EXEC SQL BEGIN DECLARE SECTION;int credit_amount;EXEC SQL END DECLARE SECTION;然后在 SQL 中写:
where tot_cred > :credit_amount这里 :credit_amount 不是 SQL 变量,而是宿主语言变量。
嵌入式 SQL 真正难的地方,不只是 语法怎么写 ,而是三类接口问题:
- 如何标记 SQL 片段的起止
- 数据库和宿主语言如何通信
- SQL 类型系统与宿主语言类型系统如何对接
SQLCA 与 SQLDA:程序和数据库怎么交换状态
两个经典结构:
SQLCASQLDA
1. SQLCA
SQLCA 可以理解为 SQL Communication Area,它保存最近一次 SQL 执行后的状态信息。
最常见的是看:
sqlcode
如果执行成功,通常可以继续走;如果失败,就根据 sqlcode 判断错误。
所以像下面这种代码:
EXEC SQL INCLUDE SQLCA;...EXEC SQL insert into account values (:account_no, :branch_name, :balance);if (SQLCA.sqlcode != 0) printf("Error!\n");else printf("Success!\n");本质上就是:
SQL 执行完以后,程序到
SQLCA里查看执行状态。
2. SQLDA
SQLDA 可以理解为 SQL Descriptor Area。
它更偏 描述信息 ,主要用于管理:
- 变量地址
- 长度
- 类型
- 指示变量
- 名字等元数据
直觉上可以把它理解成:
当 SQL 的输入输出结构比较动态时,程序需要一个 描述器 来说明这些数据长什么样。
所以:
SQLCA更像 状态区SQLDA更像 描述区
Embedded SQL 的基本例子:单条记录的增删改查
无游标 的基本操作:
insert
EXEC SQL BEGIN DECLARE SECTION;char account_no[11];char branch_name[16];int balance;EXEC SQL END DECLARE SECTION;
EXEC SQL CONNECT TO bank_db USER Adam Using Eve;EXEC SQL insert into account values (:account_no, :branch_name, :balance);意思就是:
- 在声明段里先声明宿主变量
- 连到数据库
- 把宿主变量里的值插入到表里
delete
EXEC SQL delete from accountwhere account_number = :account_no;就是用宿主变量给删除条件赋值。
update
EXEC SQL update accountset balance = balance + :balancewhere account_number = :account_no;这里的 :balance 还是宿主变量,不是列名。
select ... into
EXEC SQL select balance into :balancefrom accountwhere account_number = :account_no;这说明在 Embedded SQL 里:
- 单行查询常用
select ... into - 查询结果直接装入宿主变量
不过这类写法通常要求查询结果是单行或至少逻辑上应当只有一行。
指示变量(indicator variable)
null 怎么传到宿主语言里?
因为像 C 里的 int balance; 本身没有 SQL null 这个概念,所以通常要再配一个 indicator variable:
int balance;int mask;EXEC SQL select balance into :balance:maskfrom accountwhere account_number = :account_no;这里的含义大致是:
mask = 0:正常取到值mask < 0:该列为nullmask > 0:可能发生截断之类情况
所以 indicator variable 的本质作用是:
补上 宿主语言原生类型无法直接表达 SQL null / 截断状态 的那部分语义。
为什么需要 cursor
如果查询结果可能有多行,就不能只靠简单的 select ... into 一次装完。
这时要用 cursor(游标)。
你可以把它理解成:
结果集上的一个 读头 ,每次取一行。
例如:
EXEC SQLdeclare c cursor forselect ID, namefrom studentwhere tot_cred > :credit_amount;这个语句只是 定义查询 ,还没真正执行。
open / fetch / close
游标的生命周期通常是:
1. open c
EXEC SQL open c;此时数据库真正执行查询,并把结果保存在临时结果关系里。
2. fetch c into ...
EXEC SQL fetch c into :si, :sn;每次 fetch:
- 取一行
- 把该行列值放到宿主变量里
多次 fetch 就会依次取后面的行。
3. close c
EXEC SQL close c;临时结果被释放。
当结果取完时,SQLCA 中的 SQLSTATE 会变成 '02000',表示 no more data。
完整流程:
EXEC SQL DECLARE account_cursor CURSOR FORselect account_number, balancefrom depositor natural join accountwhere depositor.customer_name = :customer_name;
EXEC SQL open account_cursor;for (;;) { EXEC SQL fetch account_cursor into :account_no, :balance; if (SQLCA.sqlcode != 0) break; printf("%s %d\n", account_no, balance);}EXEC SQL close account_cursor;这个例子比抽象语法更直观:
declare cursor只是定义查询模板open才真正执行- 每次
fetch只拿一行 - 用循环不断取,直到
sqlcode表示无更多数据
因此游标和 JDBC 的 ResultSet 很像,只是写法更 嵌入式 SQL 风格。
for update 与 where current of
embedded SQL 还支持 边扫描边更新 。
先定义:
EXEC SQLdeclare c cursor forselect *from instructorwhere dept_name = 'Music'for update;然后每次 fetch 之后,可以写:
update instructorset salary = salary + 1000where current of c;这句话的意思是:
更新 游标当前指向的那一行 。
它很适合写逐行处理逻辑。
example:
if (balance < 1000) EXEC SQL update account set balance = balance * 1.05 where current of account_cursor;else EXEC SQL update account set balance = balance * 1.06 where current of account_cursor;它体现出 where current of 的最大价值:
- 不需要再写一遍主键条件
- 直接更新 刚刚 fetch 到的当前行 即可
对于逐行扫描 + 条件更新,这种写法非常自然。
Dynamic SQL:运行时再构造 SQL
静态嵌入式 SQL 的特点是:
- 关系名、属性名、SQL 结构大多写死在程序里
- 编译时就能确定
而动态 SQL 是:
- SQL 语句在运行时构造
- 再由程序提交给数据库执行
这在下面两类场景尤其常见:
- 表名、列名、条件要由用户输入决定
- SQL 模板固定,但参数值会反复变化
常见有两种执行方式。
EXECUTE IMMEDIATE
适合一次性执行临时拼出来的 SQL:
sprintf(statement, "delete from %s where %s", table_name, condition);EXEC SQL EXECUTE IMMEDIATE :statement;这个模式简单直接,但也要特别警惕注入风险。
PREPARE / EXECUTE
适合带参数占位符、且会多次执行的语句:
char *sqlprog = "update account set balance = balance * 1.05 where account_number = ?";
EXEC SQL prepare dynprog from :sqlprog;EXEC SQL execute dynprog using :account;这里的 ? 就是占位符。
这个模式和 JDBC/ODBC 里的 prepared statement 是同一个思想:
- SQL 结构先准备好
- 运行时再绑定参数值
所以回头看会发现:
- JDBC 的
PreparedStatement - ODBC 的
SQLPrepare + SQLBindParameter + SQLExecute - Embedded SQL 的
PREPARE / EXECUTE
本质上都是同一类设计原则,只是外层语法不同。
Functions and Procedures
为什么要把逻辑放进数据库
到这里,Chapter 5 开始把重点从 程序如何访问数据库 转向 数据库内部自己执行逻辑 。
把业务逻辑放进数据库,有几个典型理由:
- 外部应用不需要了解太多内部表结构细节
- 多个应用可以共享同一套数据库内部逻辑
- 一些约束和操作更靠近数据本身,更容易保持一致
也就是说,函数、过程、触发器,本质上都在回答一个问题:
某些逻辑,是不是应该 挪到数据库内部 来做?
函数 function
最简单的例子是一个标量函数:给定院系名,返回该院系教师人数。
create function dept_count(dept_name varchar(20))returns integerbegin declare d_count integer; select count(*) into d_count from instructor where instructor.dept_name = dept_name; return d_count;end然后就可以在 SQL 里直接调用:
select dept_name, budgetfrom departmentwhere dept_count(dept_name) > 1;它说明:
- 函数可以把一段重复逻辑封装起来
- 以后别的 SQL 直接调用函数即可
- SQL 变得更像 用已有组件拼装业务语义
表值函数 returns table
SQL:2003 还支持返回一张关系表的函数。
例如:
create function instructors_of(dept_name char(20))returns table ( ID varchar(5), name varchar(20), dept_name varchar(20), salary numeric(8,2))return table ( select ID, name, dept_name, salary from instructor where instructor.dept_name = instructors_of.dept_name)使用时:
select *from table(instructors_of('Music'));这个思想很重要:
- 普通函数返回一个值
- 表值函数返回 一整张结果表
它相当于 带参数的 view 。
普通 view 没参数,而表值函数可以吃参数,所以更灵活。
存储过程 procedure
前面的 dept_count 也可以写成过程:
create procedure dept_count_proc( in dept_name varchar(20), out d_count integer)begin select count(*) into d_count from instructor where instructor.dept_name = dept_count_proc.dept_name;end调用方式:
declare d_count integer;call dept_count_proc('Physics', d_count);函数和过程的直观区别可以这样理解:
- function:更像 表达式 ,常常直接写进查询里
- procedure:更像 执行一个动作
当然不同 DBMS 的具体限制不完全一样,但这个直觉通常成立。
过程化控制结构
slides 这里讲的是 SQL 的procedural extension。
也就是说,SQL 不只是查表语言,它还加入了:
- 变量
- 分支
- 循环
- 复合语句
这样数据库内部就可以写更复杂的程序。
PL/SQL :
PL/SQL = Procedural Language Extension to SQL
它允许在 SQL 的基础上加入更完整的程序设计工具,例如:
- loops
- conditions
- functions
也就是说,前面我们在 Functions and Procedures 里讲的很多想法,在 Oracle 里往往会具体落成 PL/SQL block 的形式。
PL/SQL block 的结构
DECLARE -- 可选:声明变量、类型、游标BEGIN -- 必选:执行语句EXCEPTION -- 可选:异常处理END; -- 必选/这里的直觉可以记成:
DECLARE:准备阶段,我要用什么变量BEGIN ... END:执行阶段,我到底做什么EXCEPTION:出错了怎么办
其中最后单独一行 /,在很多 Oracle 工具里表示 现在执行这个 block 。
此外,PL/SQL 里还有两类 block:
- anonymous block:匿名块,没有名字,写完立即执行
- named block:有名字的块,例如 procedure、function
所以从课程视角看:
- 匿名块更像 临时脚本
- 命名块更像 可复用的数据库程序单元
变量声明:不仅有 SQL 类型,还有 %TYPE
在过程化 SQL 里,最先出现的通常就是变量声明。
基本写法类似:
declare birthday DATE; age NUMBER(2) NOT NULL := 27; name VARCHAR2(13) := 'Levi'; magic CONSTANT NUMBER := 77; valid BOOLEAN NOT NULL := TRUE;begin ...end;/这说明数据库内部的过程语言已经非常接近普通编程语言:
- 可以声明变量
- 可以指定默认值
- 可以要求
NOT NULL - 还可以声明常量
另一个特别实用的机制是 %TYPE:
declare sname Sailors.sname%TYPE; fav_boat VARCHAR2(30); my_fav_boat fav_boat%TYPE := 'Pinta';begin ...end;/它的意思是:
sname的类型直接继承自Sailors.snamemy_fav_boat的类型继承自变量fav_boat
这个机制很有用,因为:
当表字段类型以后发生变化时,过程里的变量类型也能自动跟着同步,不容易失配。
%ROWTYPE 与 record:把 一整行 当对象用
如果 %TYPE 是 拿一个列的类型 ,那么 %ROWTYPE 就是 拿一整行的结构 。
例如:
declare reserves_record Reserves%ROWTYPE;begin reserves_record.sid := 9; reserves_record.bid := 877;end;/这里 reserves_record 的结构就和 Reserves 表的一整行一致。
这很像:
- C 里的
struct - Java 里的对象字段集合
record 类型的写法:
declare type sailor_record_type is record ( sname VARCHAR2(10), sid VARCHAR2(9), age NUMBER(3), rating NUMBER(3) ); sailor_record sailor_record_type;begin sailor_record.sname := 'peter'; sailor_record.age := 45;end;/所以可以把它理解成两条路:
%ROWTYPE:直接复用表的一行结构record:自己定义一个复合结构
复合语句 begin ... end
begin -- 多条 SQLend它的作用和大多数编程语言里的代码块类似。
特点:
- 可以放多条 SQL 语句
- 可以在块内声明局部变量
while / repeat
declare n integer default 0;while n < 10 do set n = n + 1;end while;
repeat set n = n - 1;until n = 0end repeat;区别大致是:
while:先判条件,再执行repeat:先执行,再判条件,直到满足until
for
SQL 的 for 很常见的一种用法是:遍历查询结果。
declare n integer default 0;for r as select budget from department where dept_name = 'Music'do set n = n - r.budget;end for;这和很多语言里的 for each row in query result 一个意思。
if-then-else
if boolean_expression then statementelseif boolean_expression then statementelse statementend if;本质上就是数据库版条件分支。
SQL:1999 支持 case 风格语句,思路和 C 的 switch/case 接近。
PL/SQL 版本更像普通程序设计里的条件语句:
if rating > 7 then v_message := 'You are great';elsif rating >= 5 then v_message := 'Not bad';else v_message := 'Pretty bad';end if;所以要建立一个统一认识:
if-then-elsewhile / repeat / for- 变量与 record
- cursor
这些都说明数据库过程语言已经不只是 写 SQL ,而是在数据库内部写程序。
select ... into:把单行查询直接装进变量
PL/SQL 里还有一个很常见的形式:
declare v_sname VARCHAR2(10); v_rating NUMBER(3);begin select sname, rating into v_sname, v_rating from Sailors where sid = '112';end;/这里的含义是:
- 查询必须返回恰好一行
INTO子句是必需的- 返回列值直接放入变量
如果查不到,或者返回多于一行,通常会抛出异常,例如:
NO_DATA_FOUNDTOO_MANY_ROWS
所以它更适合:
- 根据主键查单行
- 明确知道结果只应有一行的场景
这和 Embedded SQL 里的 select ... into :host_var 在思想上是一致的,只是这里变量已经在数据库过程语言内部。
显式游标与游标属性
除了 单行查出放进变量 ,PL/SQL 也大量使用 cursor 处理多行结果。
declare cursor c is select * from sailors; sailorData sailors%ROWTYPE;begin open c; fetch c into sailorData; close c;end;/它和前面 Embedded SQL 的 open / fetch / close 逻辑完全一致,只不过这里变量直接是数据库内部变量。
此外,PL/SQL 还给了若干 显式游标属性:
c%ISOPEN:游标是否打开c%FOUND:最近一次fetch是否成功返回一行c%NOTFOUND:最近一次fetch是否没有返回行c%ROWCOUNT:到目前为止已经取回多少行
这组属性非常实用,因为它们让 循环读结果集 这件事更像普通程序控制流。
例如你可以写出更清晰的循环逻辑,而不是完全依赖外部状态码。
隐式 SQL 游标属性:看最近一条 SQL 影响了几行
除了显式 cursor,PL/SQL 还有一个经常出现在工程代码里的东西:隐式 SQL cursor 属性。
每次执行完一条 SQL 语句后,系统其实都自动维护了一个隐式游标,可以通过下面这些属性查看:
SQL%ROWCOUNTSQL%FOUNDSQL%NOTFOUNDSQL%ISOPEN
其中最常用的是 SQL%ROWCOUNT。
一个很好的例子:维护用户登录统计表 mylog。
一种直观写法是先 select 再判断更新还是插入;但更简洁的写法是:
begin update mylog set logon_num = logon_num + 1 where who = user;
if SQL%ROWCOUNT = 0 then insert into mylog values (user, 1); end if;
commit;end;/这里的逻辑特别值得记:
- 先尝试更新
- 如果更新影响行数是 0,说明该用户还不存在
- 再执行插入
这比 先查再改 更紧凑。
Example:registerStudent
- 输入学生、课程、班级、学期、年份等信息
- 先查当前已选人数
currEnrol - 再查教室容量
limit - 如果人数还没满,就插入
takes - 如果已经满员,就返回错误信息
设计思路:
选课 不是简单插一条 takes 记录 。 它其实是一个带业务检查的原子过程。
create function registerStudent( in s_id varchar(5), in s_courseid varchar(8), in s_secid varchar(8), in s_semester varchar(6), in s_year numeric(4,0), out errorMsg varchar(100))returns integerbegin declare currEnrol int; select count(*) into currEnrol from takes where course_id = s_courseid and sec_id = s_secid and semester = s_semester and year = s_year;
declare limit int; select capacity into limit from classroom natural join section where course_id = s_courseid and sec_id = s_secid and semester = s_semester and year = s_year;
if (currEnrol < limit) then begin insert into takes values (s_id, s_courseid, s_secid, s_semester, s_year, null); return(0); end; end if;
-- Otherwise, section capacity limit already reached set errorMsg = 'Enrollment limit reached for course ' || s_courseid || ' section ' || s_secid; return(-1);end;数据库内部做这件事的好处是:
- 容量检查和插入动作绑定在一起
- 外部应用不必自己重复实现
- 业务约束更靠近数据,更统一
也就是说,存储过程/函数的真正价值,不只是 省几行代码 ,而是把业务规则封装成数据库服务接口。
外部语言函数 / 过程
SQL:1999 允许函数和过程用其他语言写,比如 C/C++。
声明时大概像:
create procedure dept_count_proc(in dept_name varchar(20), out count integer)language Cexternal name '/usr/avi/bin/dept_count_proc';这说明数据库其实允许这样一种模式:
- SQL 只声明接口
- 真正实现交给外部语言
好处:
- 表达能力更强
- 某些计算更高效
但问题也随之而来。
安全问题与 sandbox
把外部代码直接丢进数据库系统运行,风险很大:
- 可能误伤数据库内部结构
- 可能越权访问不该看的数据
- 可能把数据库进程本身搞崩
两种缓解思路:
1. sandbox
也就是 沙箱执行 。
- 用更安全的语言,比如 Java
- 限制它随意访问系统或数据库内部内存
2. 单独进程执行
- 外部函数不直接跑在数据库地址空间里
- 而是在另一个进程里执行
- 数据库和它通过进程间通信传参、拿结果
代价就是性能开销更大。
所以这里有一个很典型的权衡:
- 性能
- 安全隔离
通常不能同时取到极致。
Triggers
什么是 trigger
trigger 是:
当数据库发生某类修改时,系统自动执行的一段语句。
也就是说,它不是你显式 call 的。
它是 某事件发生时,被动触发 的。
所以 trigger 很适合做:
- 审计日志
- 自动维护派生数据
- 补充完整性检查
- 自动修正输入
ECA 规则
trigger 常被概括成 ECA:
- E = Event:什么事件触发?
insert / delete / update - C = Condition:满足什么条件才执行?
- A = Action:满足条件后做什么?
所以一个 trigger 设计,本质上要回答三件事:
- 什么时候触发
- 触发时检查什么
- 真正执行什么动作
Example1:大额余额变动记日志
create trigger account_trigger after update of balance on accountreferencing new row as nrowreferencing old row as orowfor each rowwhen nrow.balance - orow.balance >= 200000 or orow.balance - nrow.balance >= 50000begin insert into account_log values( nrow.account_number, nrow.balance - orow.balance, current_time() );end;这个 trigger 的意思是:
- 当
account.balance被更新后 - 如果变动金额太大
- 就往
account_log写一条日志
这里很值得注意的是:
old row表示更新前的元组new row表示更新后的元组
所以 trigger 天然很适合做 比较新旧状态 的工作。
Example2:用 trigger 补足外键约束表达不了的完整性
一个很有代表性的例子。
time_slot_id 不是 time_slot 的主键,因此没法直接从 section 建一个标准外键过去。
这时就用 trigger 做约束补充。
插入 section 时检查:
create trigger timeslot_check1 after insert on sectionreferencing new row as nrowfor each rowwhen (nrow.time_slot_id not in ( select time_slot_id from time_slot))begin rollback;end;意思是:
- 插入新
section后 - 如果它引用了一个根本不存在的
time_slot_id - 整个事务回滚
删除 time_slot 时检查:
create trigger timeslot_check2 after delete on time_slotreferencing old row as orowfor each rowwhen ( orow.time_slot_id not in (select time_slot_id from time_slot) and orow.time_slot_id in (select time_slot_id from section))begin rollback;end;意思是:
- 某个
time_slot_id的最后一条记录被删掉了 - 但
section里还有记录引用它 - 那就不允许删,直接回滚
这说明 trigger 可以补足这样一类问题:
标准外键语法表达不了, 但业务上又必须保证的数据一致性。
Example3:before update 纠正数据
trigger 不一定只在事后记日志,也可以在事前修正输入。
例如:
create trigger setnull_trigger before update of grade on takesreferencing new row as nrowfor each rowwhen (nrow.grade = ' ')begin atomic set nrow.grade = null;end;意思是:
- 更新成绩前
- 如果有人把成绩写成空白字符串
- 系统自动把它改成
null
这是一个典型的数据清洗/标准化用法。
Example4:成绩更新后自动累计学分
create trigger credits_earned after update of grade on takesreferencing new row as nrowreferencing old row as orowfor each rowwhen nrow.grade <> 'F' and nrow.grade is not null and (orow.grade = 'F' or orow.grade is null)begin atomic update student set tot_cred = tot_cred + ( select credits from course where course.course_id = nrow.course_id ) where student.id = nrow.id;end;它的业务语义是:
- 某学生某门课原来没通过 / 还没成绩
- 现在成绩更新成了 通过
- 那么自动给
student.tot_cred加上该课程学分
这个例子特别能体现 trigger 的优势:
takes.grade改了student.tot_cred自动跟着更新
也就是:把派生数据维护自动化。
for each row vs for each statement
trigger 有两种重要粒度:
1. for each row
- 每影响一行就执行一次
- 更细
- 适合逐行逻辑
2. for each statement
- 整条 SQL 语句只执行一次
- 适合批量更新后的整体检查
- 通常效率更高
一个 statement-level 的例子:
create trigger grade_trigger after update of grade on takesreferencing new table as new_tablefor each statementwhen exists ( select avg(grade) from new_table group by course_id, sec_id, semester, year having avg(grade) < 60)begin rollback;end;这里 new_table 是 transition table,保存这条语句影响到的所有新行。
这个 trigger 的意思是:
- 一次批量更新成绩后
- 如果某个班级的平均分低于 60
- 那么整个操作回滚
这种 整体检查 如果按 for each row 做,反而不自然。
trigger 的风险与替代方案
trigger 很强,但有明显风险。
风险 1:容易 悄悄执行
比如:
- 从备份恢复数据
- 远程复制更新
- 批量导入数据
这时 trigger 可能被意外触发。
风险 2:可能拖垮关键事务
trigger 里只要有 bug,就可能让本来重要的更新失败。
风险 3:级联触发
一个 trigger 改了表,可能又引发别的 trigger,最后非常难追踪。
所以一些旧时代常拿 trigger 做的事,现在有更好的专门机制:
- 维护汇总数据:现在可用 materialized view
- 复制:现在数据库往往有内建 replication
另外,很多业务逻辑也可以通过封装方法/存储过程来做,而不是直接放 trigger 里。
所以经验上:
- trigger 很适合小而清晰的自动反应逻辑
- 不适合堆太复杂、太隐蔽的业务流程
Recursive Queries
为什么需要递归查询
有一类问题,天然带 传递性 或 层级性 :
- A 的先修课是 B,B 的先修课是 C,那 C 也是 A 的间接先修课
- 员工的经理的经理,仍然是他的上级
- 组织树、类别树、祖先后代关系
这类问题的共同特点是:
不是固定连一次、两次表就结束, 而是要一直 沿关系往上/往下追 。
这时就需要递归查询。
先修课的传递闭包
with recursive rec_prereq(course_id, prereq_id) as ( select course_id, prereq_id from prereq
union
select rec_prereq.course_id, prereq.prereq_id from rec_prereq, prereq where rec_prereq.prereq_id = prereq.course_id)select *from rec_prereq;这个查询的含义是:
第一部分(base query)
select course_id, prereq_id from prereq先取出所有 直接先修 关系。
第二部分(recursive step)
select rec_prereq.course_id, prereq.prereq_idfrom rec_prereq, prereqwhere rec_prereq.prereq_id = prereq.course_id如果:
X <- YY <- Z
那么就推出:
X <- Z
不断重复,直到不再产生新元组为止。
这个结果就叫 transitive closure(传递闭包)。
为什么非递归 SQL 做不好这类问题
如果你不用递归,只靠普通 SQL,那么你最多只能写出:
- 连一次
prereq - 连两次
prereq - 连三次
prereq
也就是说,连接层数是写死的。
但真实数据库里:
- 先修链可能 2 层
- 可能 5 层
- 也可能 20 层
只要层数超过你事先写死的 join 次数,查询就失效。
所以递归查询的本质价值在于:
不是预先写死 追几层 , 而是一直推到固定点为止。
递归的迭代版思路
一个 非递归 SQL + 过程化控制 的版本,即 findAllPrereqs 思想。
- 建临时表存当前已知先修课集合
- 再建临时表存 上一轮新增的课程
- 根据上一轮新增项继续往外扩展
- 把新找到但之前没见过的课程加入集合
- 若这一轮没有新课程,停止
这说明:
- 递归 SQL 和 迭代过程 在逻辑上是等价的
- 递归 SQL 更声明式、更紧凑
- 过程化写法更接近算法实现
层级关系:员工-经理传递关系
with recursive empl(employee_name, manager_name) as ( select employee_name, manager_name from manager
union
select manager.employee_name, empl.manager_name from manager, empl where manager.manager_name = empl.employee_name)select *from empl;这里求出的就是:
- 员工对直接经理
- 员工对经理的经理
- 员工对更高层经理
本质上仍然是传递闭包。
所以要建立一个统一直觉:
- 先修关系 是有向图边
- 经理关系 也是有向图边
- 递归查询就是在算图上的可达关系
Advanced Aggregation Features
Ranking
rank() 与 dense_rank()
如果有关系:
student_grades(ID, GPA)想按照 GPA 排名,可以写:
select ID, rank() over (order by GPA desc) as s_rankfrom student_grades;如果还想按排名顺序输出:
select ID, rank() over (order by GPA desc) as s_rankfrom student_gradesorder by s_rank;这里的关键是:
over (...)定义的是 窗口- 排名函数不会把多行压成一行
- 它是给结果中的每一行额外算一个排名值
rank() 的特点是:
- 并列名次会跳号
例如前两名并列第一,那么下一名是第三。
dense_rank() 则不跳号,下一名是第二。
低效但直观的 基础 SQL 排名写法
不用窗口函数的排名写法:
select ID, (1 + (select count(*) from student_grades B where B.GPA > A.GPA)) as s_rankfrom student_grades Aorder by s_rank;这个思路很直观:
- 一个人前面有多少人比他 GPA 高
- 他的排名就是那个数量加 1
但它很低效,因为每一行都要再做一次子查询统计。
这正好说明窗口函数的价值:
- 表达更自然
- 执行通常更高效
分组内排名 partition by
排名还可以在分组内部做。
例如 按院系分别排名 :
select ID, dept_name, rank() over (partition by dept_name order by GPA desc) as dept_rankfrom dept_gradesorder by dept_name, dept_rank;这里:
partition by dept_name先把数据按院系分区- 每个分区内部再按 GPA 排名
这就是很多 Top-N within each group 问题的标准解法。
比单纯 limit n 更强,因为:
limit n只能取全局前 npartition + rank可以取 每组前 n
其他排名函数
percent_rank():百分位排名cume_dist():累计分布row_number():顺序编号ntile(n):把排序结果切成 n 个桶
例如:
select ID, ntile(4) over (order by GPA desc) as quartilefrom student_grades;这就是把学生按 GPA 分成四个分位组。
此外,SQL 还允许显式指定 nulls first 或 nulls last:
select ID, rank() over (order by GPA desc nulls last) as s_rankfrom student_grades;这能避免空值在排序中的位置含糊不清。
Windowing
移动窗口
窗口函数不只做排名,也能做 滑动聚合 。
经典例子是移动平均。
给定:
sales(date, value)要算 当天、前一天、后一天 三天的总和/平均,可以写:
select date, sum(value) over ( order by date rows between 1 preceding and 1 following )from sales;这个窗口的意思是:
- 以当前行为中心
- 往前取 1 行
- 往后取 1 行
所以它天然适合时间序列平滑。
常见窗口边界
几类常见窗口框架:
between rows unbounded preceding and current rowrows unbounded precedingrange between 10 preceding and current rowrange interval 10 day preceding
要区分:
rows:按 物理行数 取窗口range:按 排序键值范围 取窗口
比如:
rows 1 preceding是前一行range 10 preceding是所有排序值在当前值减 10 到当前值之间的行
分区内累计和
另一个特别实用的例子是 账户余额流水 。
给定:
transaction(account_number, date_time, value)其中:
- 存款是正数
- 取款是负数
想求 每个账户在每笔交易后的余额 :
select account_number, date_time, sum(value) over ( partition by account_number order by date_time rows unbounded preceding ) as balancefrom transactionorder by account_number, date_time;这里的含义是:
- 每个账户单独分区
- 在该账户内部按时间排序
- 从第一笔到当前笔全部累加
这就是 running total(累计和)。
OLAP
什么是 OLAP
OLAP = Online Analytical Processing。
核心不是事务处理,而是:
- 交互式分析数据
- 从不同角度汇总数据
- 快速切换观察视角
也就是:
不是 改一条记录 , 而是 从海量数据里快速看规律 。
维度属性与度量属性
分析型数据分成两类:
1. 度量属性(measure)
- 用来度量某个值
- 可以聚合
- 例如销量
quantity
2. 维度属性(dimension)
- 用来决定 从哪个角度看
- 例如:
item_name、color、clothes_size
简单的理解:
quantity回答 有多少item_name/color/size回答 按什么分类看
交叉表 cross-tab / pivot-table
销售关系:
sales(item_name, color, clothes_size, quantity)交叉表的特征是:
- 一个维度做行头
- 一个维度做列头
- 其他维度作为过滤条件或更上层标题
- 表格单元格里放聚合结果
例如 按商品和颜色看销量汇总 的表,就是一个典型 cross-tab / pivot-table。
Data Cube
交叉表其实只是多维数据立方体的一个二维视图。
Data Cube 可以理解为:
- 对多个维度同时做聚合
- 得到多种不同粒度的汇总结果
2D 的交叉表只是 cube 的一个切面。
Hierarchy、roll up、drill down、slice、dice、pivot
分析型查询里常见的几个词
Hierarchy(层级)
例如时间维度可以按:
- hour
- date
- month
- quarter
- year
地区维度可以按:
- city
- state
- country
- region
Roll up
- 从细粒度汇总到粗粒度
- 例如日 -> 月 -> 年
Drill down
- 从粗粒度展开到细粒度
- 年 -> 月 -> 日
Slice / Dice
slice:固定某个维度值,切出一个切片dice:固定多个维度值,切出一个子块
Pivot
- 改变交叉表的观察维度
- 例如原来按 商品 × 颜色 ,改成 商品 × 尺码
把交叉表表示成关系
交叉表可以重新表示成普通关系。
为了表示 汇总 ,有时会引入一个像 all 这样的值。
例如:
(item_name, color, clothes_size, quantity)其中某些列取 all,表示 这一维已经被汇总掉了 。
但 SQL 标准里通常不是用 all 这个字面量,而是用 null 来表示这种 汇总占位 。
这就会带来一个问题:
- 普通
null表示 值未知 / 不存在 - 汇总用
null表示 all
二者语义会冲突
这也是后面 grouping() 函数存在的原因。
cube
cube 会对指定属性的每个子集都做分组聚合。
例如:
select item_name, color, clothes_size, sum(quantity)from salesgroup by cube(item_name, color, clothes_size);它等价于把这些 group by 的结果做并集:
(item_name, color, clothes_size)(item_name, color)(item_name, clothes_size)(color, clothes_size)(item_name)(color)(clothes_size)()
如果有 3 个维度,就一共是 2^3 = 8 种分组。
这说明:
cube很强- 但结果规模也会迅速膨胀
grouping() 与把 null 还原成 all
由于 cube/rollup 会用 null 表示 这一维被汇总掉 ,所以要区分:
- 这个
null是原始数据里的真空值 - 还是聚合产生的 all 占位
grouping(attr) 就是干这个的。
- 若
attr的null是聚合产生的,返回 1 - 否则返回 0
例如:
select item_name, color, clothes_size, sum(quantity), grouping(item_name) as item_name_flag, grouping(color) as color_flag, grouping(clothes_size) as size_flagfrom salesgroup by cube(item_name, color, clothes_size);进一步,还可以用 case / decode 把这类 null 显示成 all:
select case when grouping(item_name) = 1 then 'all' else item_name end as item_name, case when grouping(color) = 1 then 'all' else color end as color, sum(quantity) as quantityfrom salesgroup by rollup(item_name, color);这里不能简单用 coalesce(item_name, 'all'),因为那会把原始数据里真正的空值也误改成 all。
rollup
rollup 和 cube 类似,但只对前缀分组做聚合。
例如:
select item_name, color, clothes_size, sum(quantity)from salesgroup by rollup(item_name, color, clothes_size);它产生的只是:
(item_name, color, clothes_size)(item_name, color)(item_name)()
所以:
cube:所有子集rollup:只有前缀链
因此 rollup 特别适合层级结构。
例如:
select category, item_name, sum(quantity)from sales, itemcategorywhere sales.item_name = itemcategory.item_namegroup by rollup(category, item_name);这里就会自然得到:
- 每个商品小计
- 每个类别小计
- 总计
多个 rollup/cube 组合
还可以在一个 group by 中组合多个 rollup/cube。
例如:
select item_name, color, clothes_size, sum(quantity)from salesgroup by rollup(item_name), rollup(color, clothes_size);它的本质是:
- 第一个
rollup(item_name)生成{(item_name), ()} - 第二个
rollup(color, clothes_size)生成{(color, clothes_size), (color), ()} - 两者做笛卡尔积
最终得到多个组合层级。
这个思想和关系代数其实是连得上的:
每个 rollup 都在生成一组 group-by 列表, 多个 rollup/cube 组合时,本质上就是这些分组集合的组合。
grouping sets:更精细地指定分组集合
它的作用是:
cube太多rollup太少- 我就手工指定 只要这几种分组
例如只想要:
(color, clothes_size)(clothes_size, item_name)
那么可以写:
select item_name, color, clothes_size, sum(quantity)from salesgroup by grouping sets ( (color, clothes_size), (clothes_size, item_name));这比 cube 更可控。
MOLAP / ROLAP / HOLAP
OLAP 系统实现上也分路线:
MOLAP
- 用多维数组等专门结构直接存 data cube
- 响应快
- 但实现更专门化
ROLAP
- 基于关系数据库实现 OLAP
- 靠 SQL、聚合、索引、物化视图等能力做分析
HOLAP
- 混合模式
- 一部分汇总放内存
- 明细数据和其他汇总放关系数据库
预计算与优化
早期 OLAP 系统常常尝试 把所有可能汇总都预先算好 。
问题是:
- 若有
n个维度 - 可能的 group by 组合就有
2^n个
空间和时间代价都很夸张。
所以更合理的做法通常是:
- 只预计算一部分关键汇总
- 其他汇总按需从更细粒度结果再聚合出来
例如:
(item_name, color)的汇总- 可以从
(item_name, color, size)的汇总再聚出来
这对像 sum/count 这样的可分解聚合尤其适用。
而像 median 这种 非可分解聚合 ,就没这么方便。
merge
它适合做批量更新合并。
例如有一张:
funds_received(account_number, amount)表示一批待入账资金。
那么:
merge into account as Ausing (select * from funds_received as F)on (A.account_number = F.account_number)when matched then update set balance = balance + F.amount;它的意思是:
- 逐条匹配账户
- 匹配上就更新余额
merge 本质上是把 匹配 + 更新 / 插入 打包成一条批处理语句。
在工程里很常见。