概述
这一章讨论的是 Pipelining(流水线)。Chapter 1 主要研究性能该如何定量分析,这一章更关注:在处理器实现层面,怎样通过重叠不同指令的执行过程来提升吞吐率。
本章内容大致沿着一条很自然的主线展开:
- 先从顺序执行、一次重叠、二次重叠过渡到真正的流水线;
- 再讨论流水线有哪些分类、怎样评价它的性能;
- 然后进入最核心也最容易出题的部分:pipeline hazards(流水线冒险);
- 最后补上 branch prediction(分支预测) 与 nonlinear pipelining scheduling(非线性流水调度)。
需要特别注意的是:
- 流水线提升的核心是吞吐率(throughput),不是单条指令的执行延迟(latency);
- 理想流水线很漂亮,但真实机器会受到 stage 不均衡、资源冲突、数据相关、控制相关等因素影响;
- 因此这一章既有概念题,也有大量图示题、时序题、计算题。
目录
- What is Pipelining
- 从顺序执行到重叠执行
- 流水线的定义与基本直觉
- 指令/数据访存冲突与 advance control
- Classes of Pipelining
- stage / segment / depth / pipeline register
- 单功能 / 多功能,静态 / 动态
- 线性 / 非线性,有序 / 乱序,标量 / 向量
- Performance Evaluation of Pipelining
- Throughput / Speedup / Efficiency
- bottleneck segment 与改进方法
- 双功能流水线点积例子
- Hazards of Pipelining
- dependence 与 hazard 的区别
- structural / data / control hazards
- forwarding / bubble / code scheduling
- Data Hazards: Forwarding vs. Stalling
- forwarding 的检测条件
- double data hazard
- load-use hazard 与 stall 插入
- Control Hazards and Dynamic Branch Prediction
- stall on branch / predict not taken / delayed branch
- branch operand 的数据相关
- BHT / 1-bit predictor / 2-bit predictor / BTB
- Schedule of Nonlinear Pipelining
- reservation table
- initial conflict vector / current conflict vector
- state transition graph
What is Pipelining
如果一个人从头到尾把一个任务的所有步骤都做完,那么系统是严格串行的;如果把一个任务拆成若干阶段,让不同的人分别负责不同阶段,那么多个任务就可以像接力一样前后错开地推进。
这正是流水线最核心的直觉:
- 不是把一条指令“瞬间做完”;
- 而是把多条指令在不同阶段同时推进。
从顺序执行到重叠执行
为了说明流水线是怎么来的,slides 先把一条指令粗略分成 3 个阶段:
- IF(Instruction Fetch):取指
- ID(Instruction Decode):译码
- EX(Execution):执行
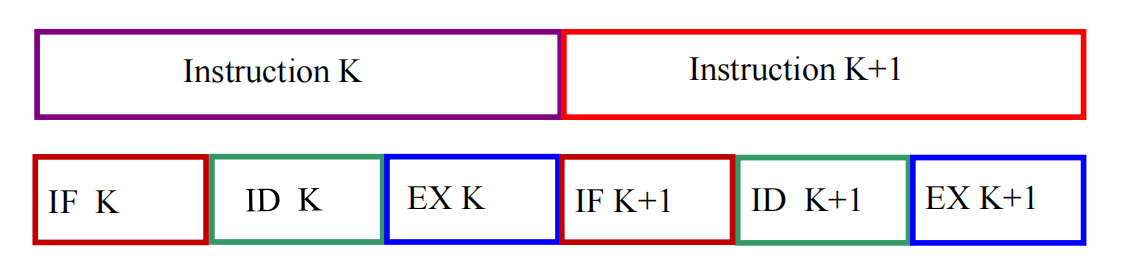
如果完全顺序执行,那么第 条指令必须完整经过 IF、ID、EX 之后,第 条指令才能开始。
假设三个阶段长度都近似为 ,则执行 条指令的总时间是:
这种方式的优点是:
- 控制简单;
- 硬件利用关系直观;
- 不容易出现复杂的时序冲突。
但缺点也很明显:
- 功能部件利用率低;
- 当前阶段工作时,其他阶段对应的硬件经常在空闲。
Single Overlapping Execution
接下来是 single overlapping execution(一次重叠执行)。
它的思想是:当第 条指令进入 EX 时,可以同时去取第 条指令。
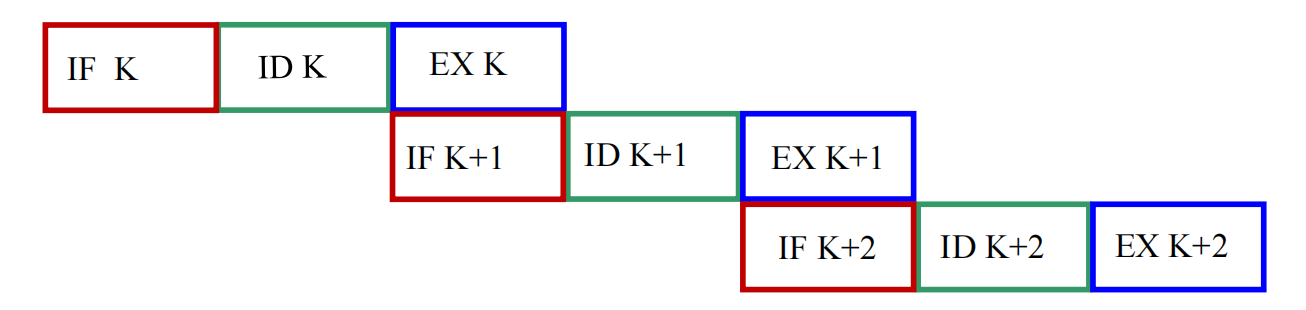
直观上就是:
- 前一条指令在“后半段”执行;
- 下一条指令在“前半段”开始准备。
在 3 段模型且每段时间相等时,执行 条指令的总时间变为:
和顺序执行相比,它把总时间从 压缩到了 ,因此:
- 时间明显下降;
- 功能部件利用率更高;
- 但控制逻辑已经开始复杂起来。
Twice Overlapping Execution
进一步再做一次重叠,就得到 twice overlapping execution(二次重叠执行)。
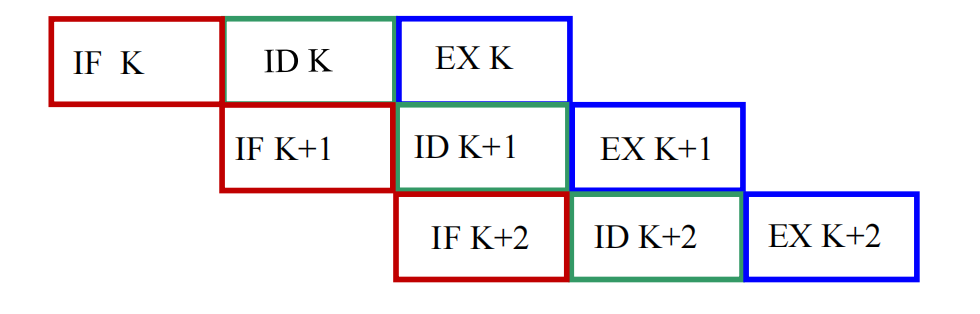
这时可以做到:
- 第 条指令执行;
- 第 条指令译码;
- 第 条指令取指。
于是 3 个阶段真正形成了“并排前进”的关系。
在同样的 3 段等长模型下:
它的优点比一次重叠更明显:
- 执行时间进一步下降;
- 功能部件利用率更高。
对应代价也更大:
- 需要把 IF、ID、EX 的部件真正分离;
- 控制更加复杂;
- 如果阶段长度不平衡,容易出现资源浪费或新的冲突。
TIP一个细节:
如果取指阶段本身非常短,那么有时可以把 IF 的工作部分并入译码阶段,这样原本的 twice overlapping 在实现上就会退化成一种更接近 single overlapping 的形式。
这说明“重叠几次”并不是固定不变的标签,它和具体的 stage 划分方式密切相关。
重叠执行不等于成熟流水线
如果各阶段耗时不一样,简单重叠会很快遇到问题。
例如:
- 若 ,那么后面的 EX 阶段会经常等前面的阶段,造成资源浪费;
- 若 ,则后续阶段可能来不及消化前面送来的任务,容易形成堆积;
- 若取指和数据访问共用同一块存储器,还会发生访问冲突。
所以,“把多条指令摆在一起”只是第一步。
真正意义上的流水线,还需要:
- 更合理的阶段划分;
- 相邻阶段之间的缓冲;
- 更系统的控制机制。
Pipelining 的定义
Pipelining 是一种实现技术,它把一条指令的处理过程分成若干个时间大致相等的子过程,并让多条相邻指令在这些子过程上错开、重叠地执行。
这里有几个关键词:
-
implementation technique
- 流水线首先是“实现技术”,不是 ISA 本身;
- 同一套 ISA,可以有流水线实现,也可以没有。
-
overlapped execution
- 真正的收益来自多个阶段并行工作;
- 因而流水线的主要提升体现在吞吐率上。
-
equal time as much as possible
- 阶段时间越均衡,流水线越接近理想状态;
- 最长阶段会成为瓶颈。
如果把一个过程划分成 个阶段,每个阶段长度都近似为 ,那么执行 个任务所需总时间可写成:
这个公式很重要,因为它把流水线执行时间拆成了两部分:
- 建立阶段(fill):前 左右,流水线还在逐步填满;
- 稳态阶段(steady state):之后每经过一个 ,就能完成一个新任务;
- 排空阶段(drain):最后几条任务还需要走完剩余阶段。
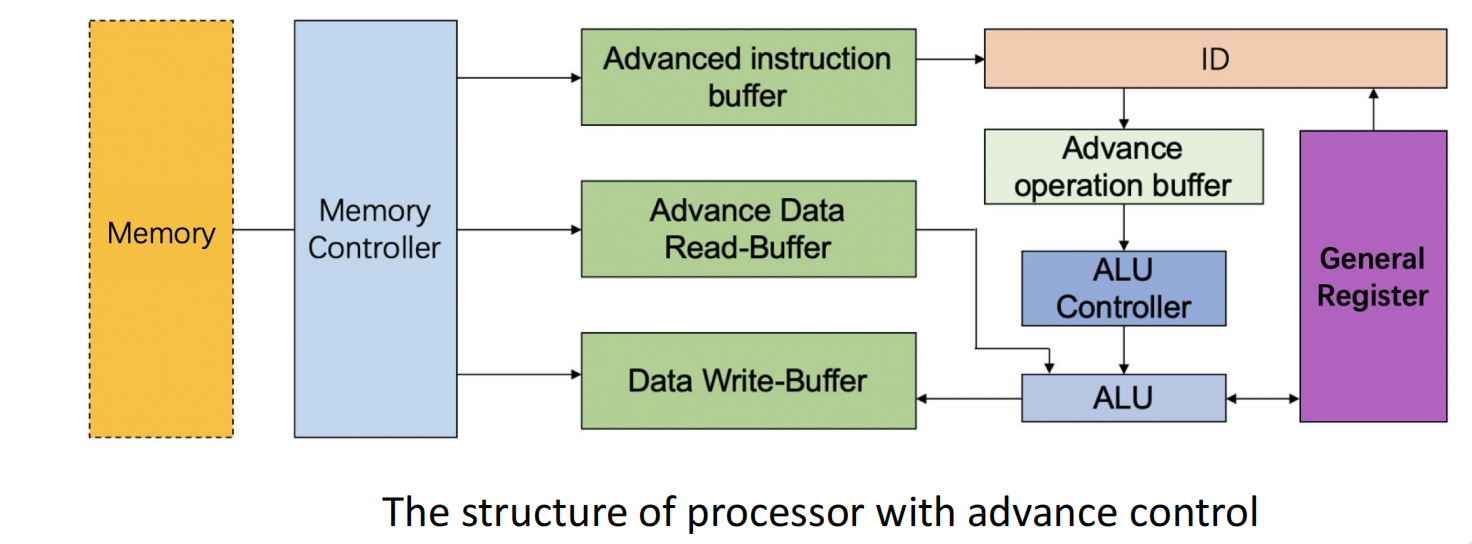
访存冲突与 Instruction Buffer
memory access conflict(存储器访问冲突)。
典型场景是:
- 取指阶段要访问 instruction memory;
- load/store 又要访问 data memory;
- 如果它们共用同一个存储体,就会互相争资源。
常见处理方法有:
- instruction memory 与 data memory 分离
- 使用 Harvard structure
- 指令 cache 和数据 cache 分离
- 使用多体交叉存储结构
- 在 memory 和 decode unit 之间增加 instruction buffer
instruction buffer 的作用可以理解为:
- 在取指和后续译码之间加一个“缓冲区”;
- 让前端能提前取一些指令;
- 即使后面一拍暂时忙,前端也不至于完全停住。
slides 后面提到的 advance control 本质上也是这个思路:
当阶段长度不完全相等时,用 FIFO 式缓冲和更复杂的控制来减少阻塞。
Classes of Pipelining
基本术语
- stage / segment
流水线中的每一个子过程叫一个 stage,也常叫 segment。
例如 IF、ID、EX、MEM、WB 都可以看成不同的 stage。
- depth of pipeline
流水线的阶段数叫 depth。
例如 5-stage pipeline 的 depth 就是 5。
- pipeline register
相邻阶段之间必须有寄存器或锁存器把数据隔开,这就是 pipeline register。
它的作用有两个:
- 保存本阶段产生、供下一阶段使用的数据;
- 把不同阶段在时间上隔离开,使各阶段能并行工作。
- pass time / empty time
- pass time:第一个任务从进入流水线到第一次输出结果所需时间;
- empty time:停止送入新任务后,最后一个任务从进入到完全流出所需时间。
它们反映的就是流水线的建立和排空开销。
流水线的一般特征
流水线通常具有以下共同特点:
- 一个复杂过程被拆成多个子过程;
- 每个子过程由专门的功能部件负责;
- 各阶段时间应尽量平衡;
- 最长阶段会成为 bottleneck(瓶颈段);
- 只有输入端持续有任务时,流水线效率才能充分发挥。
这也解释了为什么流水线特别适合:
- 大量重复任务;
- 顺序稳定、模式相似的处理过程;
- 可以持续“喂饱”流水线的工作负载。
单功能流水线与多功能流水线
- Single-function pipelining
只实现一种固定功能的流水线。
例如某条流水线只做某一类固定运算,那么它的阶段连接方式不会改变。
优点:
- 结构简单;
- 控制容易;
- 容易做到高频和稳定。
缺点:
- 功能单一;
- 应用范围较窄。
- Multi-function pipelining
各阶段可以按照不同连接方式组成若干种功能。
slides 里举的是浮点运算相关例子:同一组 segment 可以按不同路径完成加法或乘法。
优点:
- 硬件复用率更高;
- 一条流水线可以支持多类运算。
缺点:
- 调度和控制明显更复杂;
- 不同功能间切换时容易产生空闲和冲突。
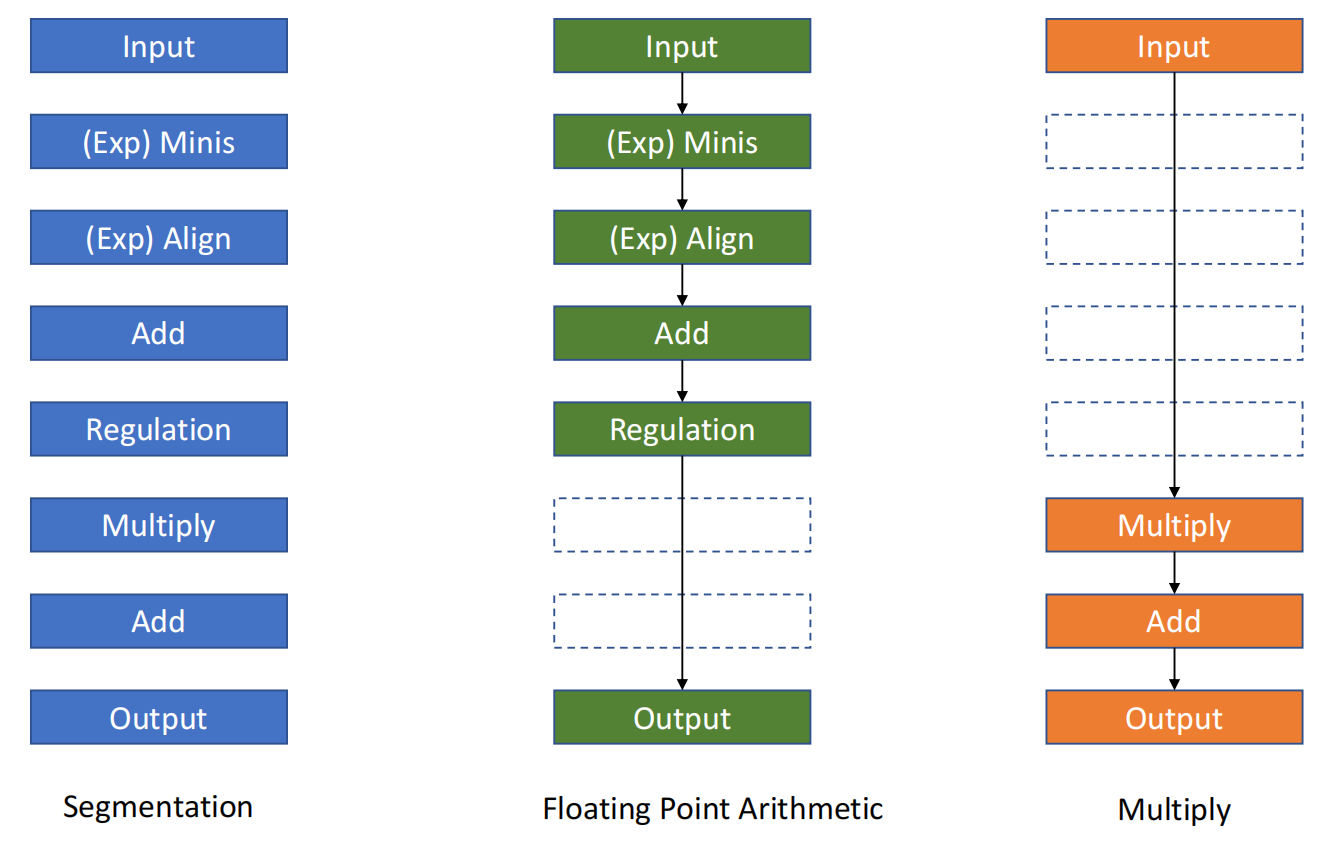
Static 与 Dynamic Multi-function Pipelining
对于多功能流水线,还可以继续分成:
- Static pipelining
在同一时刻,各阶段只能按照同一种功能连接方式工作。
也就是说,如果当前流水线在按“加法模式”连接,那么此时就不能同时再按“乘法模式”服务另一批任务。
特点:
- 适合同类任务连续输入;
- 控制相对容易;
- 灵活性较弱。
- Dynamic pipelining
在同一时刻,各阶段可以按不同连接方式服务不同功能。
这意味着同一条多功能流水线能同时支持多类任务穿行。
特点:
- 灵活;
- 功能部件利用率更高;
- 但控制逻辑复杂得多。

按层次分类
按流水线作用的层次来分。
-
Component level pipelining
- 又可理解为 operation pipelining
- 在算术逻辑运算部件内部做分段
- 例如把某个复杂运算器拆成多个小段连续流动
-
Processor level pipelining
- 也就是最常见的 instruction pipelining
- 把一条指令的解释与执行过程拆成多个阶段
- IF / ID / EX / MEM / WB 就是这一类
-
Inter-processor pipelining
- 又叫 macro pipelining
- 多个处理机串接处理同一数据流
- 每个处理机负责大任务中的一个阶段
这三个层次对应的是:
- 部件内部的流水;
- 单处理器内部的指令流水;
- 多处理器之间的宏观流水。
Linear 与 Nonlinear Pipelining
- Linear pipelining
线性流水线中,各阶段严格串联,没有反馈环。
一个任务进入后,最多经过每个阶段一次。
- Nonlinear pipelining
非线性流水线中除了串联,还存在反馈路径。
因此同一个任务可能会再次回到某个已经经过的阶段。
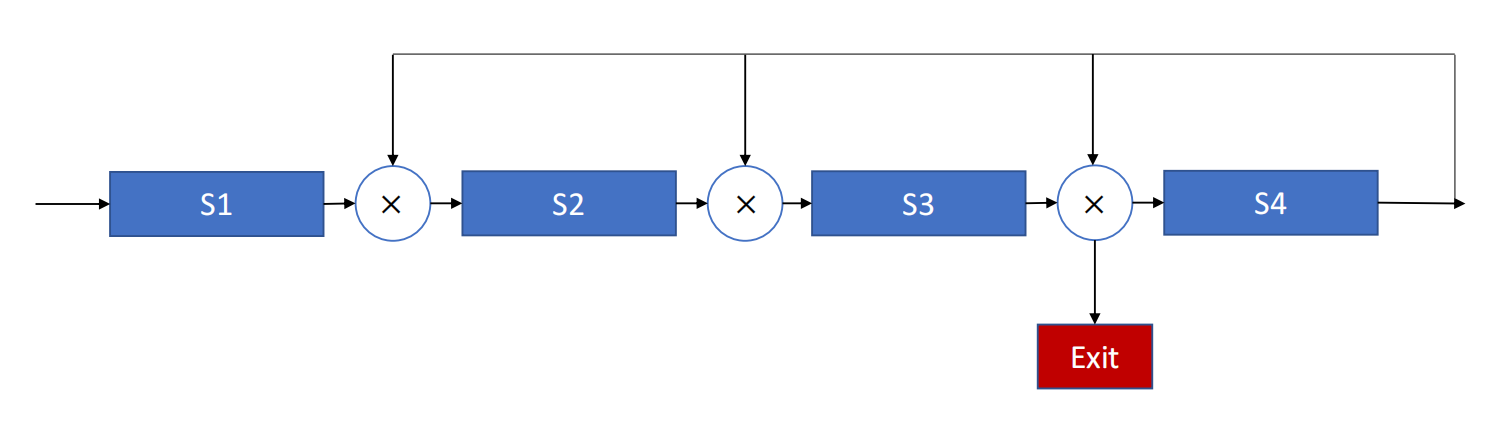
典型路径是:
一旦出现这种反馈,就会产生新的问题:
- 新任务什么时候可以进入?
- 会不会和已经在流水线中的旧任务撞在同一个 stage 上?
- 如何安排启动间隔,才能既无冲突又尽可能快?
这就是后面 nonlinear pipeline scheduling 要解决的问题。
Ordered 与 Disordered Pipelining
- Ordered pipelining
任务流出顺序与流入顺序一致。
也就是说,先进入的任务一定先离开。
- Disordered pipelining
任务流出顺序不一定和流入顺序一致。
后进入的任务可能先完成。
它反映的是流水线内部是否允许更灵活的调度和完成顺序。
Scalar 与 Vector Pipelining
- Scalar processor
只处理标量数据,没有专门的向量表示和向量指令。
- Vector pipelining processor
具有向量数据表示和向量指令,把流水线技术与向量处理结合起来。
对于大量同构数据运算,向量流水线往往更能发挥硬件吞吐率优势。
Performance Evaluation of Pipelining
一个最基本的时钟周期例子
一个 5 阶段 datapath 的时延表:
| 指令类型 | IF | Register Read | ALU | Memory | Register Write | Total |
|---|---|---|---|---|---|---|
lw | 200ps | 100ps | 200ps | 200ps | 100ps | 800ps |
sw | 200ps | 100ps | 200ps | 200ps | - | 700ps |
| R-type | 200ps | 100ps | 200ps | - | 100ps | 600ps |
beq | 200ps | 100ps | 200ps | - | - | 500ps |
从这个表可以马上得到两个结论:
- Single-cycle datapath
单周期处理器的时钟周期必须覆盖最慢指令,因此时钟周期至少是:
- Pipelined datapath
如果做成流水线,那么时钟周期主要由最慢 stage 决定。
在这里最长 stage 是 200ps,所以理想情况下:
这说明:
- 单周期处理器被最慢指令“绑死”;
- 流水线则把一条长路径拆散,让时钟周期向最慢阶段靠齐。
Throughput
对于 段、段长均为 的理想流水线,执行 个任务需要:
因此 throughput(吞吐率) 为:
当 很大时,流水线进入稳态,吞吐率趋近于最大值:
也就是说,在理想稳态下:
- 每经过一个时钟周期;
- 就能完成一个任务。
Speedup
如果不用流水线,执行 个任务需要:
于是流水线的加速比为:
当 时:
这说明在理想情况下,流水线的最大加速比接近阶段数。
Efficiency
流水线效率定义为:
当 时:
效率接近 1 的含义是:
- 大部分 stage 在大部分时间都处于工作状态;
- 管线建立和排空的损失相对可以忽略。
当 stage 不均衡时:Bottleneck Segment
真实流水线往往并不完美平衡。
如果各段时延分别是 ,则时钟周期必须至少取最大值:
执行 个任务的大致时间可写成:
其中最长的那一段就叫 bottleneck segment(瓶颈段)。

- 的时间都是
- 的时间是
这时显然:
也就是说,虽然大多数阶段都很快,但整个流水线节拍只能跟着最慢的 走。
解决瓶颈段的两种常见办法
- Subdivision
把慢段继续细分。
例如把 拆成 ,让每个小段都尽量接近 。

优点:
- 降低单段时延;
- 提高总体时钟频率。
缺点:
- stage 数变多;
- latch 数量增加;
- 控制更复杂。
- Repetition
直接复制瓶颈段,做多个并行副本,再用 data distributor / collector 分配与收集数据。

优点:
- 不改变其他段结构;
- 能缓解热点段排队问题。
缺点:
- 硬件代价更高;
- 数据分发和回收也要控制好。
Example 1:静态双功能流水线上的向量点积
- 向量
- 向量
- 在 static dual-function pipeline 上计算点积
其中两条功能路径分别是:
- 加法流水线:
1 → 2 → 3 → 5 - 乘法流水线:
1 → 4 → 5

计算点积一共需要:
- 4 次乘法
- 3 次加法
若顺序执行:
- 每次乘法占 3 段,耗时
- 每次加法占 4 段,耗时
于是总顺序时间为:
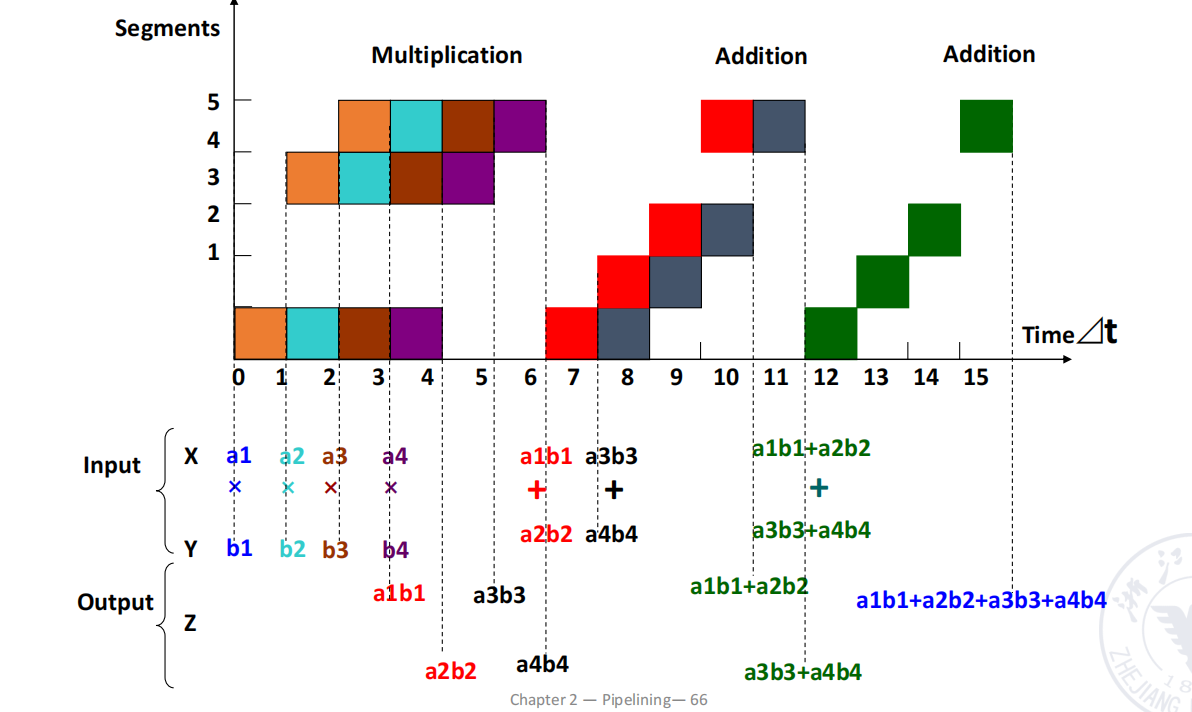
流水线总时间是:
因此:
这个例子很能说明多功能流水线的现实问题:
- 虽然有 5 个 segment;
- 但不同功能路径长度不同;
- 各段并不能始终满负荷工作;
- 所以实际效率会明显低于理想值。
Example 2:动态双功能流水线上的向量点积
一个 dynamic dual-function pipeline 的点积例子。
这次两条功能路径是:
- 加法流水线:
1 → 3 → 4 → 5 - 乘法流水线:
1 → 2 → 5

而且其中某些段时长不再均匀,例如乘法路径里的某段需要 。
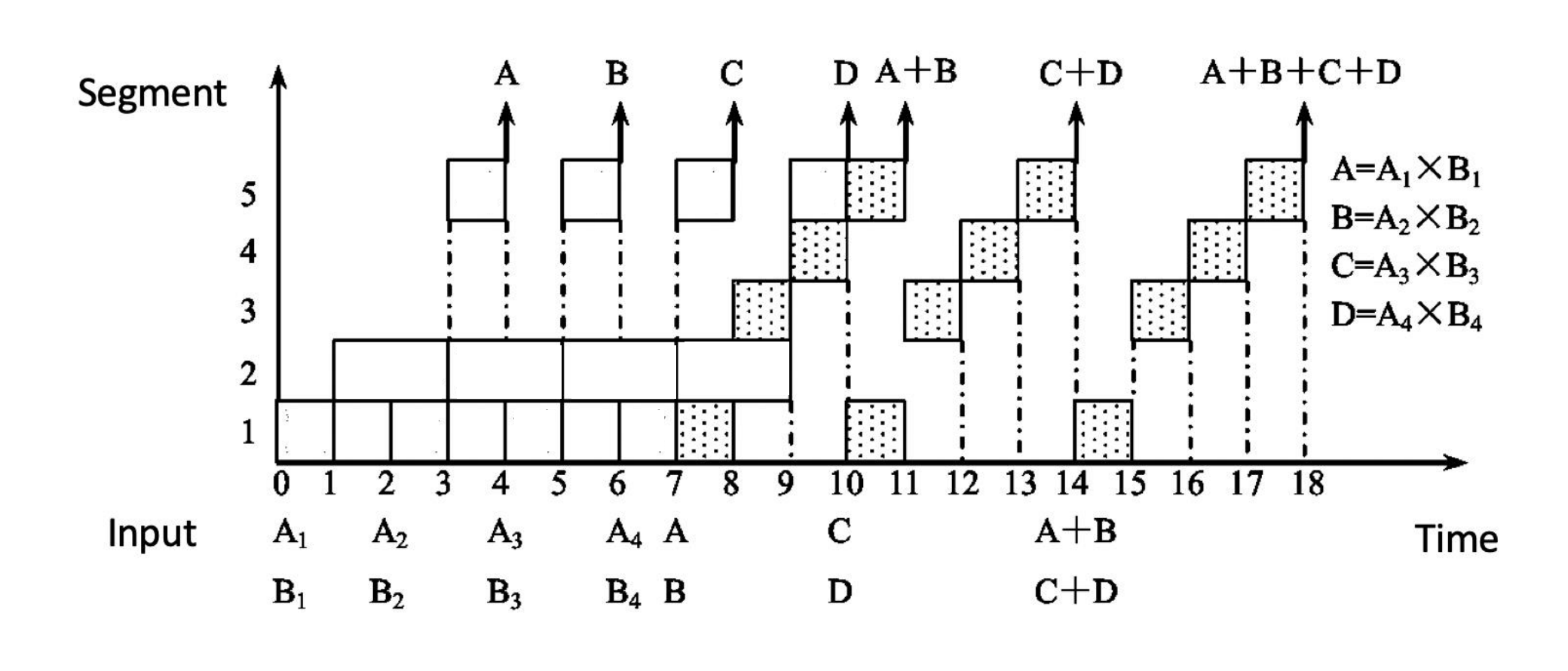
slides 直接给出的结果是:
这里的 28Δt 来自:
- 4 次乘法,每次约 4Δt;
- 3 次加法,每次约 4Δt;
- 总顺序时间约为 28Δt。
虽然 dynamic pipelining 更灵活,但:
- 功能切换会产生额外开销;
- 某些段仍然会空闲;
- 乘加之间还存在前后依赖。
因此最终加速比并没有显著超过前一个静态例子。
对流水线性能的几点讨论
- 为什么流水线能提速
本质不是把单条指令做得更“短”,而是把很多条指令重叠起来,从而提高吞吐率。
- 理想加速比为什么接近 stage 数
因为在完全平衡、无冲突、无额外开销时,稳态下每拍完成一个任务,而非流水线需要每个任务独占 个阶段。
- slides 里的一个直观吞吐例子
一个非常直接的数字对比来强调 throughput 的差别:
- 非流水结构每 100ns 才能启动一次新计算;
- 流水结构每 20ns 就能启动一次新计算。
因此单位时间可完成的计算数会从:
提升到:
这个例子再次说明,流水线最显著的收益是“发射频率变高”,而不是单条任务的首个结果突然缩短很多。
- 为什么不能一味加深流水线
- stage 太多,控制会非常复杂;
- 需要处理更多 in-flight instructions 之间的依赖;
- latch 本身也有延迟和面积开销;
- clock skew 不可忽略;
- 深流水线的 branch penalty 更重。
TIP理想流水线常用来帮助推公式,但真实处理器里必须把以下开销一起算进去:
- pipeline register delay
- latch overhead
- clock skew
- stage 不均衡
- 多功能切换的空拍
- 数据相关和控制相关造成的 stall
Hazards of Pipelining
Dependence 不等于 Hazard
区分两个容易混淆的词:
- Dependence(相关)
它描述的是程序语义上的约束。
也就是说,就算没有流水线,这种先后关系本身也存在。
- Hazard(冒险)
它描述的是实现层面的困难:
由于流水线并行推进,导致下一条指令不能在下一个周期开始。
所以:
- dependence 是“语义必须如此”;
- hazard 是“硬件实现因此受阻”。
真正的 data hazard,通常来自某种 dependence 在流水线中暴露成时序冲突。
三类 Hazard
-
Structural hazard
- 某个需要的硬件资源正在被占用
-
Data hazard
- 后一条指令需要等待前一条指令的数据读写完成
-
Control hazard
- 下一条该取谁,取决于前面分支的结果
这三类几乎覆盖了基础流水线里最重要的时序问题。
Data Dependence
最基本的真相关(true dependence)例子是:
FLD F0, 0(R1)FADD.D F4, F0, F2这里第二条指令依赖第一条指令写回的 F0。
如果 FLD 还没有把数据准备好,FADD.D 就不能安全使用这个操作数。
这类相关是真正的数据流关系,因此不能靠简单改名消除。
Name Dependence
name dependence 不是“值被依赖”,而是“名字撞上了”。
slides 给了两个典型例子。
- Anti-dependence(WAR)
FDIV.D F2, F6, F4FADD.D F6, F0, F12FSUB.D F8, F6, F14这里前面的指令先读 F6,后面的指令又要写 F6。
如果把第二条指令的目的寄存器改名为 S:
FDIV.D F2, F6, F4FADD.D S, F0, F12FSUB.D F8, S, F14那么这类 name dependence 就被消除了。
- Output-dependence(WAW)
FDIV.D F2, F6, F4FADD.D F6, F0, F12FSUB.D F2, F6, F14这里第一条和第三条都写 F2,于是发生 output dependence。
如果把其中一个写回目标改名为 S,就能消除这类“名字冲突”。
要点是:
- WAR / WAW 不反映真实数据流;
- 它们反映的是“同名寄存器造成的约束”;
- register renaming 可以消除 name dependence。
Control Dependence
if p1 { Statement 1}Statementif p2 { Statement 2}这里后续语句到底该不该执行,依赖于前面条件判断的结果。
这类依赖不会直接体现为“某个寄存器值还没写回”,但会影响:
- 下一条该取哪条指令;
- 已经取来的指令是不是其实走错了路径。
Structural Hazards
结构冒险的本质是:两个阶段想用同一个资源,但资源只有一个。
最典型的例子就是单存储器结构:
load/store需要访问 data memory;- 同时 IF 阶段又要访问 instruction memory;
- 如果两者实际上共用一个 memory,那么这一拍就只能选一个。
结果就是:
- 取指必须停一下;
- 流水线中间会插入一个 bubble(气泡)。
对应的解决办法也很直接:
- instruction memory 与 data memory 分离;
- 指令 cache 与数据 cache 分离;
- 或者至少在前端增加合适缓冲。
Data Hazards
最常见的数据冒险是 RAW(Read After Write)。
例如:
add x5, x28, x29sub x30, x5, x31第二条 sub 要读 x5,但 x5 是上一条 add 刚写出来的结果。
如果 sub 在结果就绪前就进入执行阶段,就会读到旧值。
slides 还给了一个更长的时间表示例:
DADD R1, R2, R3DSUB R4, R1, R5XOR R6, R1, R7AND R8, R1, R9OR R10, R1, R11这组指令都依赖 R1。
如果没有特殊处理,后续多条指令都会不同程度地被 DADD 的写回时间限制住。
slides 中把 data hazards 又分成三种经典形式:
- RAW(Read After Write)
FADD.D F6, F0, F12FSUB.D F8, F6, F14- WAR(Write After Read)
FDIV.D F2, F6, F4FADD.D F6, F0, F12- WAW(Write After Write)
FDIV.D F2, F0, F4FSUB.D F2, F6, F14在基础、顺序发射的整数流水线里,真正最常见的是 RAW;
WAR 和 WAW 更容易在乱序执行、多周期功能部件里变得显著。
Forwarding:最常见的数据冒险缓解方法
forwarding 也叫 bypassing。
它的思想非常直接:
- 结果一算出来就直接旁路给后面的消费者;
- 不必非等到它先写回寄存器堆。
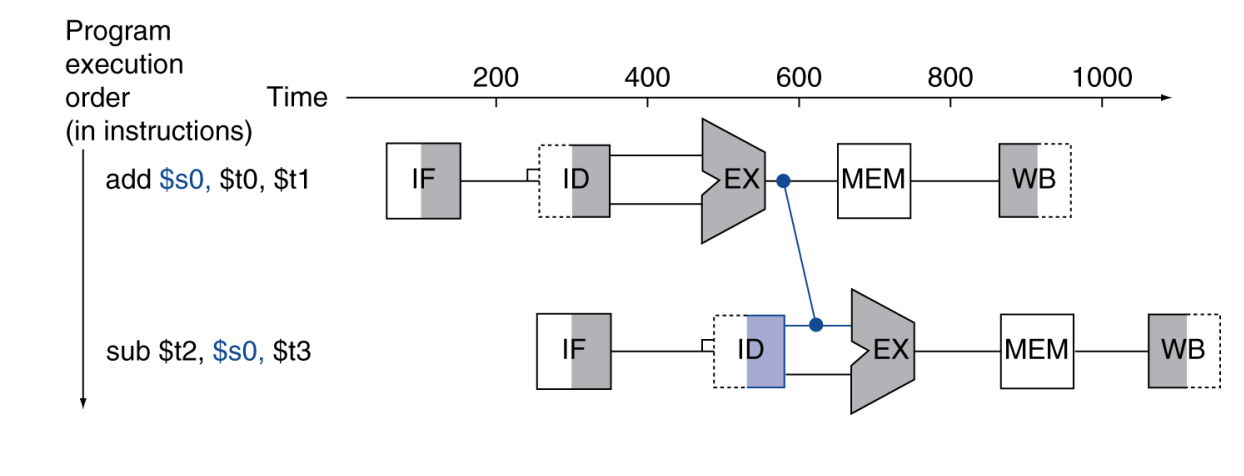
也就是说,forwarding 缩短的是“生产者计算完成”与“消费者拿到结果”之间的路径。
这在 ALU-ALU 依赖中尤其有效。
但要注意,forwarding 不是万能的。
Can’t forward backward in time.
也就是说,如果消费者需要值的时刻早于生产者真正产生值的时刻,那么单纯 forwarding 仍然不够,还是得 stall。
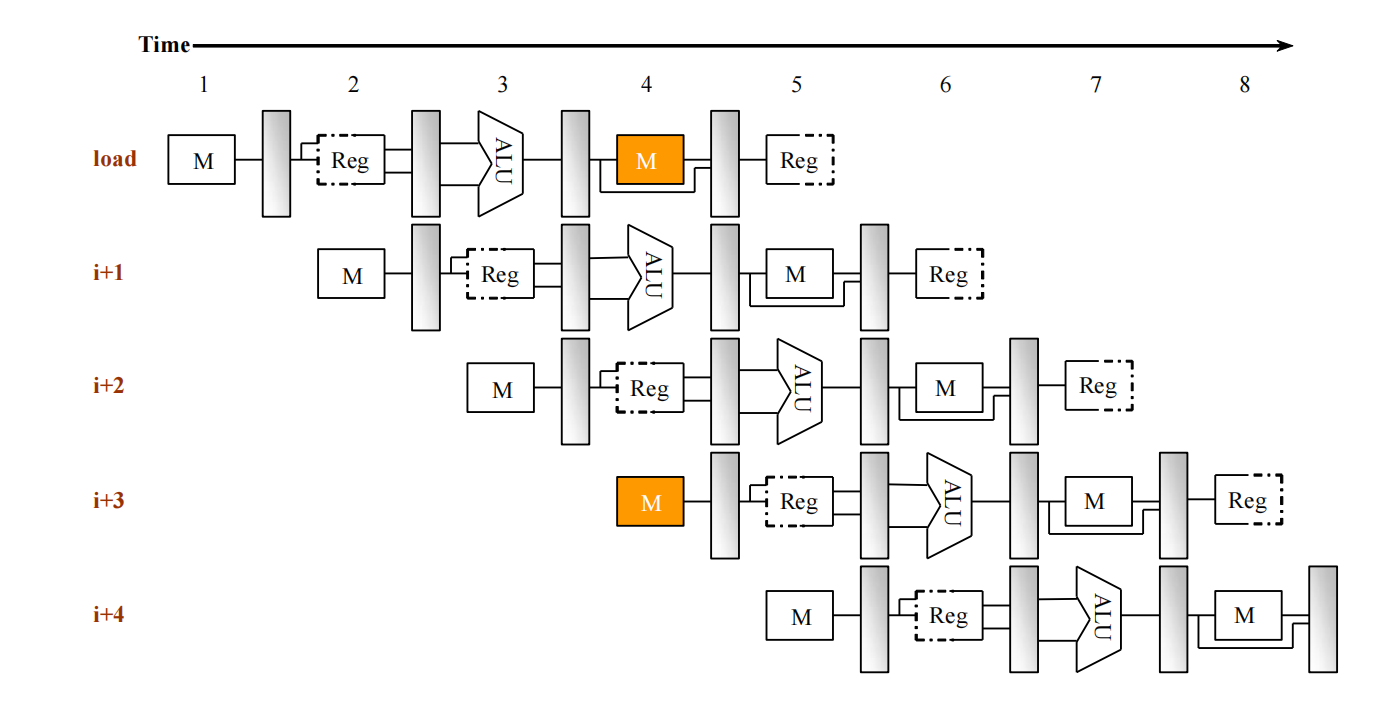
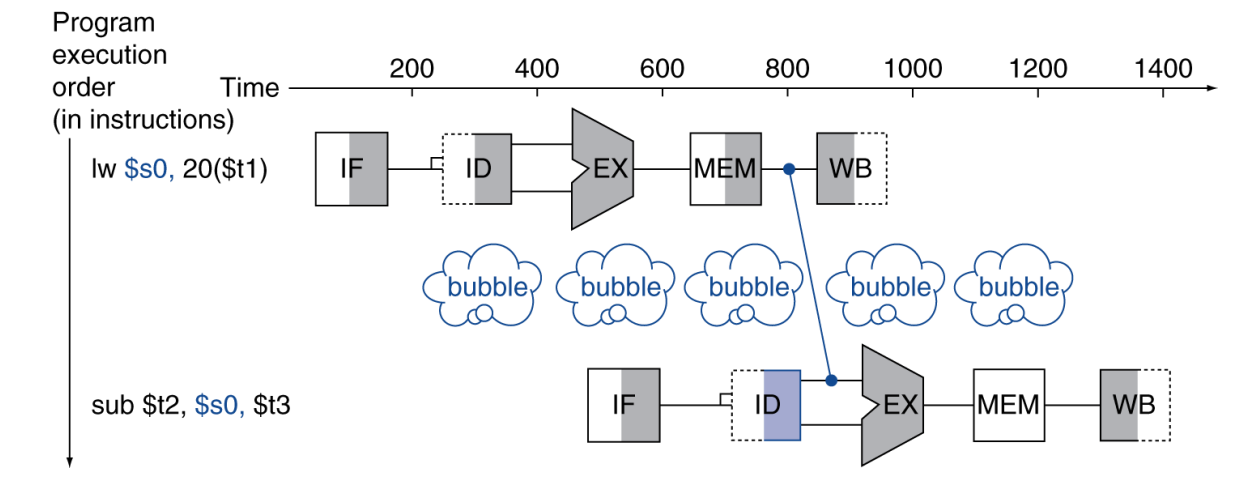
Load-Use Hazard
最典型的 forwarding 也救不了的例子是 load-use hazard:
LD R1, 0(R2)DADD R4, R1, R5AND R6, R1, R7XOR R8, R1, R9问题在于:
LD的数据要等到 MEM 阶段末尾才真正读出来;- 紧跟在后面的
DADD太早就想在 EX 阶段使用它。
因此这时通常要:
- 插入 1 个 bubble;
- 等
LD的数据到位后,再 forward 给后面的 EX。
不过这里有一个 slides 里也单独举出来的特殊情况:
LD R5, 0(R1)SD R5, 12(R1)如果 Load 后面紧跟的是 Store,而相关寄存器只是作为 store data 被后一条指令使用,那么很多实现可以把 LD 读出的结果直接 forwarding 到 store 的数据通路上。
也就是说,这一类 load -> store 相关不一定需要额外停顿,不必机械地把它和普通的 load-use hazard 归为同一种情况。
Code Scheduling:用编译器重排来隐藏 Stall
除了硬件旁路,还有compiler scheduling / code scheduling。
思路很简单:
- 不要让“马上要用 load 结果的指令”紧跟在 load 后面;
- 尽量插入一些彼此独立的指令,把空拍隐藏掉。
Example 1
A = B + CD = E - F重排前:
LD Rb, BLD Rc, CDADD Ra, Rb, RcSD Ra, ALD Re, ELD Rf, FDSUB Rd, Re, RfSD Rd, D重排后:
LD Rb, BLD Rc, CLD Re, EDADD Ra, Rb, RcLD Rf, FSD Ra, ADSUB Rd, Re, RfSD Rd, D这里把与前一个结果无关的 LD Re, E 往前提,就能让 DADD 的等待时间更少。
Example 2
A = B + EC = B + F重排前:
lw $t1, 0($t0)lw $t2, 4($t0)add $t3, $t1, $t2sw $t3, 12($t0)lw $t4, 8($t0)add $t5, $t1, $t4sw $t5, 16($t0)重排后:
lw $t1, 0($t0)lw $t2, 4($t0)lw $t4, 8($t0)add $t3, $t1, $t2sw $t3, 12($t0)add $t5, $t1, $t4sw $t5, 16($t0)- 重排前:13 cycles
- 重排后:11 cycles
重点在于:
- 哪些指令之间有真正依赖;
- 哪些独立指令可以前移填补 bubble。
Data Hazards: Forwarding vs. Stalling
这里则进一步讨论:
- 什么时候需要 forwarding
- forward 从哪里来
- 什么时候必须 stall
一个基础序列
下面这组 ALU 指令来引出 forwarding 检测:
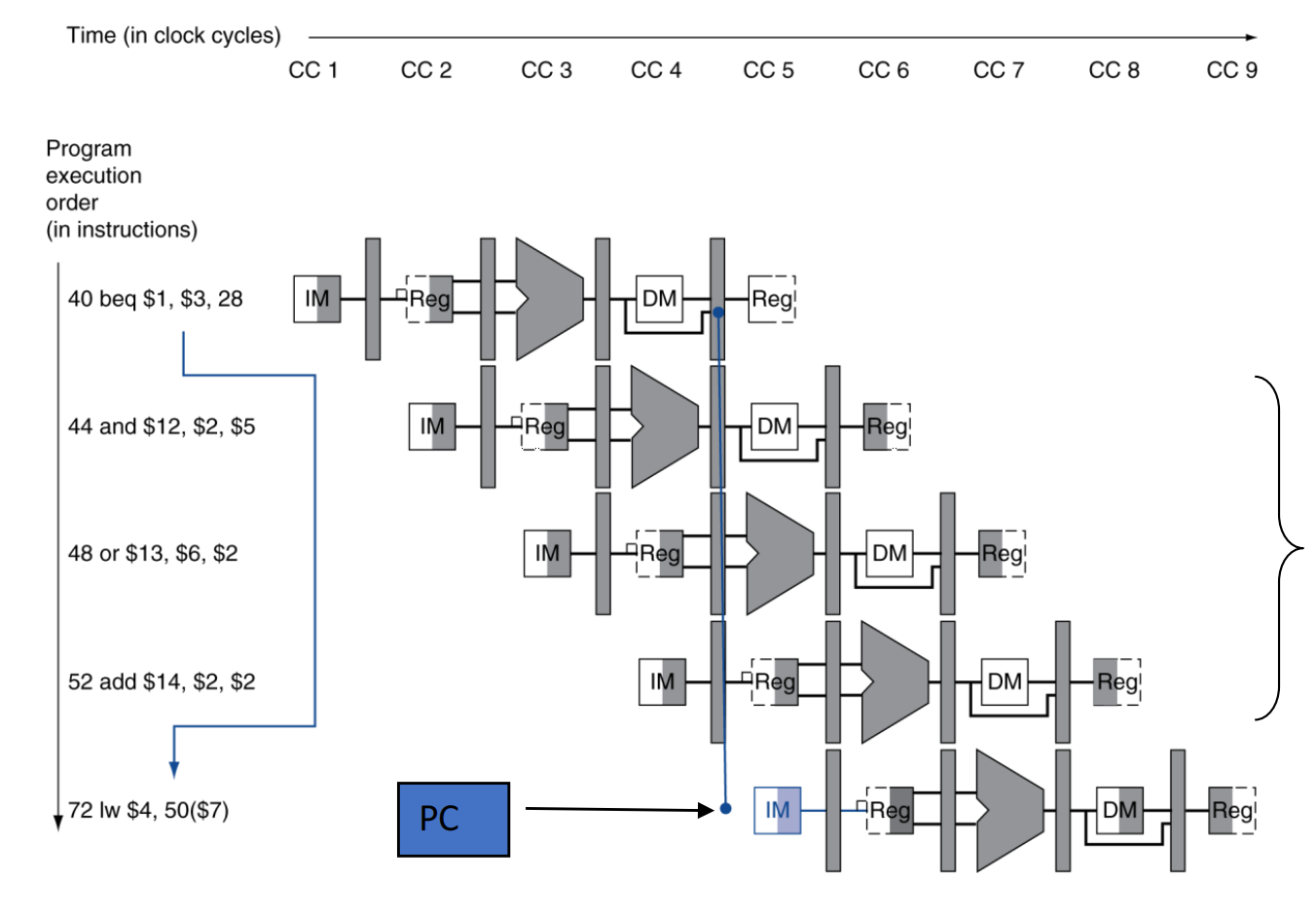
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)核心问题是:
- 后续多条指令都在用
$2 - 这个
$2来自最前面的sub - 那么消费者在各自进入 EX 时,应该从哪一级拿到最新值?
为了回答这个问题,必须把寄存器号沿着 pipeline 一起传下去。
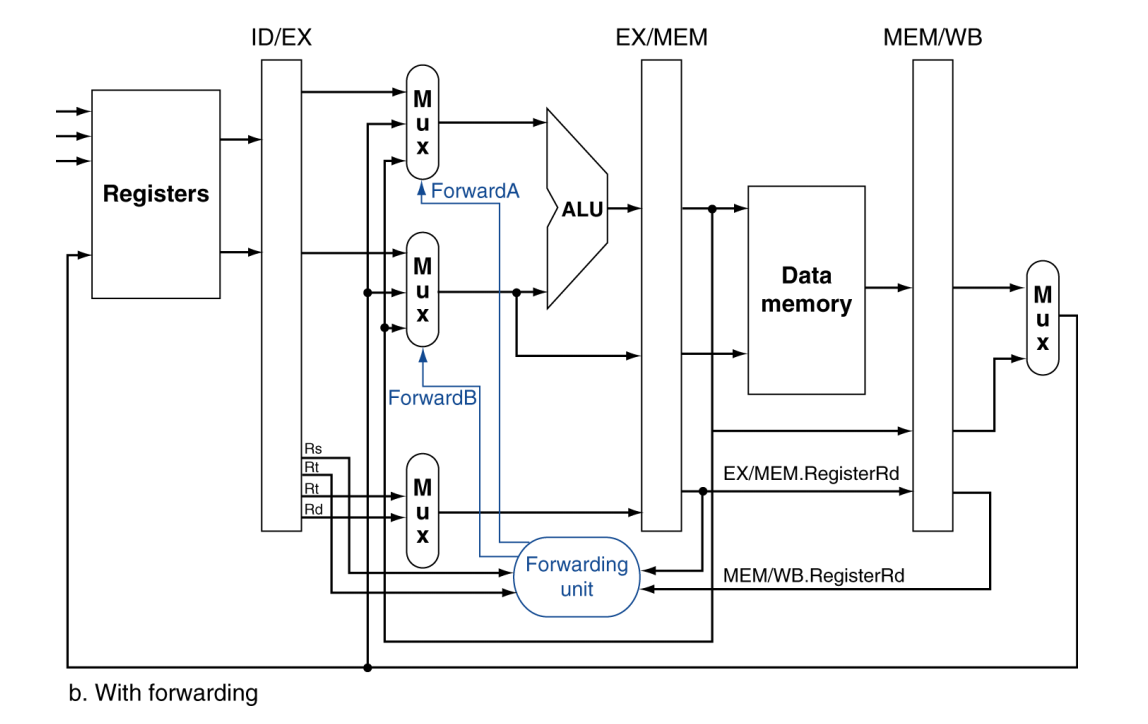
需要比较哪些寄存器号
关键信号是:
ID/EX.RegisterRsID/EX.RegisterRtEX/MEM.RegisterRdMEM/WB.RegisterRd
在 EX 阶段,ALU 的两个源操作数来自:
ID/EX.RegisterRsID/EX.RegisterRt
因此只要比较:
EX/MEM.RegisterRd == ID/EX.RegisterRsEX/MEM.RegisterRd == ID/EX.RegisterRtMEM/WB.RegisterRd == ID/EX.RegisterRsMEM/WB.RegisterRd == ID/EX.RegisterRt
就能知道是否存在需要前递的依赖。
Forwarding 的基本条件
但仅仅寄存器号相等还不够,slides 还强调了两个额外限制:
-
这条前面的指令真的会写寄存器
EX/MEM.RegWriteMEM/WB.RegWrite
-
写回目标不能是
$zeroEX/MEM.RegisterRd != 0MEM/WB.RegisterRd != 0
于是常见 forwarding 条件写成:
EX hazard
若 EX/MEM 中的结果正好是当前 EX 阶段要用的源寄存器,则:
if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10
if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10MEM hazard
若 MEM/WB 中的结果匹配当前 EX 源寄存器,则:
if (MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01
if (MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01这里的 ForwardA / ForwardB 本质上是在控制 ALU 输入前的多路选择器。
Data Path With Forwarding
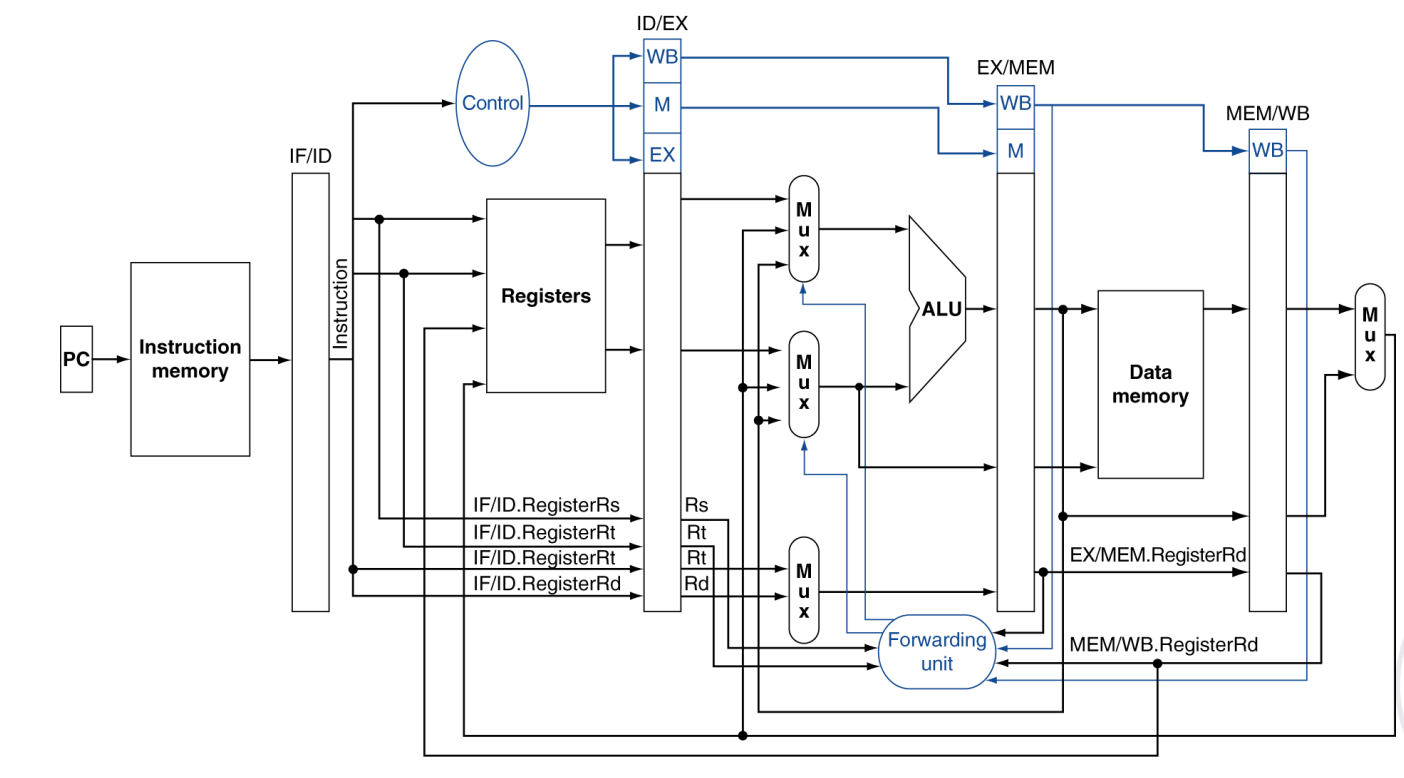
Double Data Hazard:要选“最近的那个值”
一个经典例子:
add $1, $1, $2add $1, $1, $3add $1, $1, $4这时第三条指令读 $1 时,可能同时满足:
- EX/MEM 有一个较新的
$1 - MEM/WB 也有一个较旧的
$1
也就是说,两个 hazard 条件会同时出现。
此时必须优先选最近产生的那个值,也就是 EX/MEM 中的结果。
所以对 MEM hazard 条件做了修正:
只有在 EX hazard 不成立时,才允许使用 MEM/WB 的结果做 forwarding这一步非常关键,因为它体现了 forwarding 并不是“有匹配就转发”,而是要保证拿到的是最新版本。
Load-Use Hazard 的检测条件
当上一条是 lw 时,问题就不一样了。
这时消费者在 ID 阶段就应该被识别出来,因为再晚就来不及阻止错误推进。
判定条件是:
if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)))含义是:
- ID/EX 里的那条指令是一个要读内存的 load;
- 它将写回的目标寄存器,正是下一条正在 ID 阶段译码指令要用的源寄存器。
这里同样要注意一个实现层面的特例:
如果下一条指令是 store,并且相关寄存器只是用作待写回内存的数据,那么可以单独为 store data path 增加 forwarding,把 load 的结果直接送过去。
因此 load -> store 不一定都要按“普通 load-use hazard”处理成 1 个 stall。
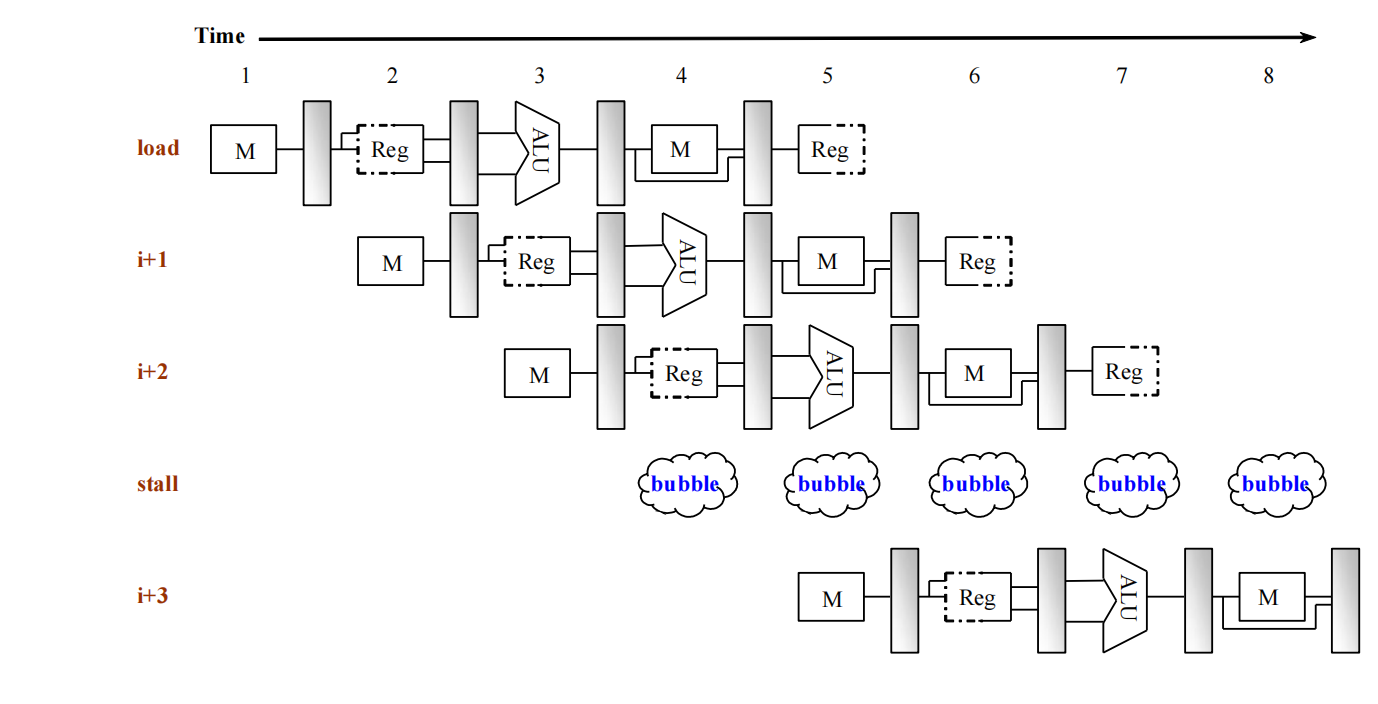
一旦检测到这种情况,就必须 stall 并插入 bubble。
How to Stall the Pipeline
stall 的实现:
-
冻结 PC 和 IF/ID
- 也就是不让取指继续前进
- 当前正在 ID 的指令下一拍还会继续待在 ID
-
把 ID/EX 中的控制信号清零
- 让 EX、MEM、WB 看起来像在执行一个
nop - 这就相当于插入了一个 bubble
- 让 EX、MEM、WB 看起来像在执行一个
-
等待 1 个周期
- 让 load 在 MEM 阶段把数据真正读出来
- 下一拍再把它 forward 给 EX
因此,bubble 的本质并不是“整条流水线全停住”,而是:
- 前半段冻结;
- 中间插一个空操作;
- 后半段继续流动。
Datapath with Hazard Detection:
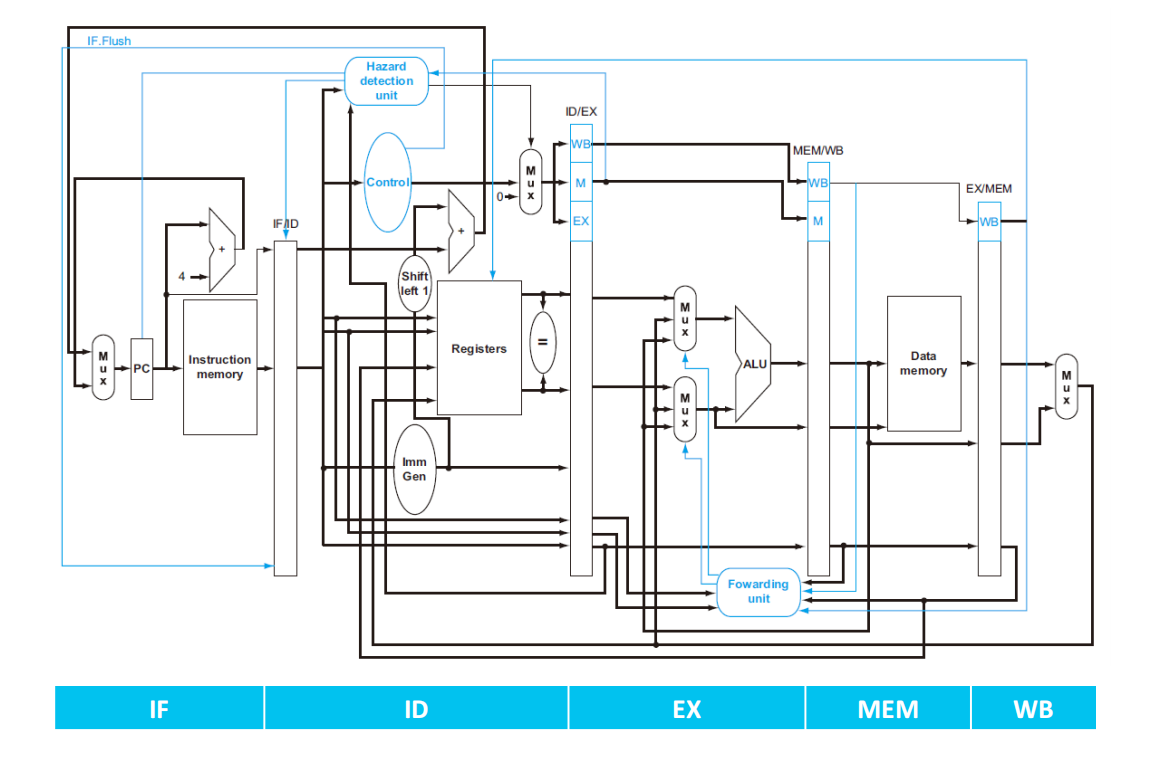
Control Hazards and Dynamic Branch Prediction
为什么 branch 会破坏流水线
control hazard 的根源是:
- 分支会改变控制流;
- 但下一条该取哪条指令,要等 branch outcome 决定后才能知道。
如果处理器在结果未确定前就继续往下取指,那么可能取错。
一旦取错,就要把这些错误路径上的指令 flush(冲刷) 掉。
在 RISC-V 的流水线实现里,希望尽量把:
- 寄存器比较
- 分支目标地址计算
提前到 ID stage,这样可以缩短 branch penalty。
基本分支类型
控制转移包括:
-
Unconditional Jump
jaljalr
-
Conditional Branch
- 只有条件满足才跳转
其中真正让流水线头疼的是 conditional branch,因为它的方向在执行前不确定。
Stall on Branch
最保守的方法是:
- branch 结果没出来之前;
- 暂时不要继续取后续指令。
这就是 stall on branch。
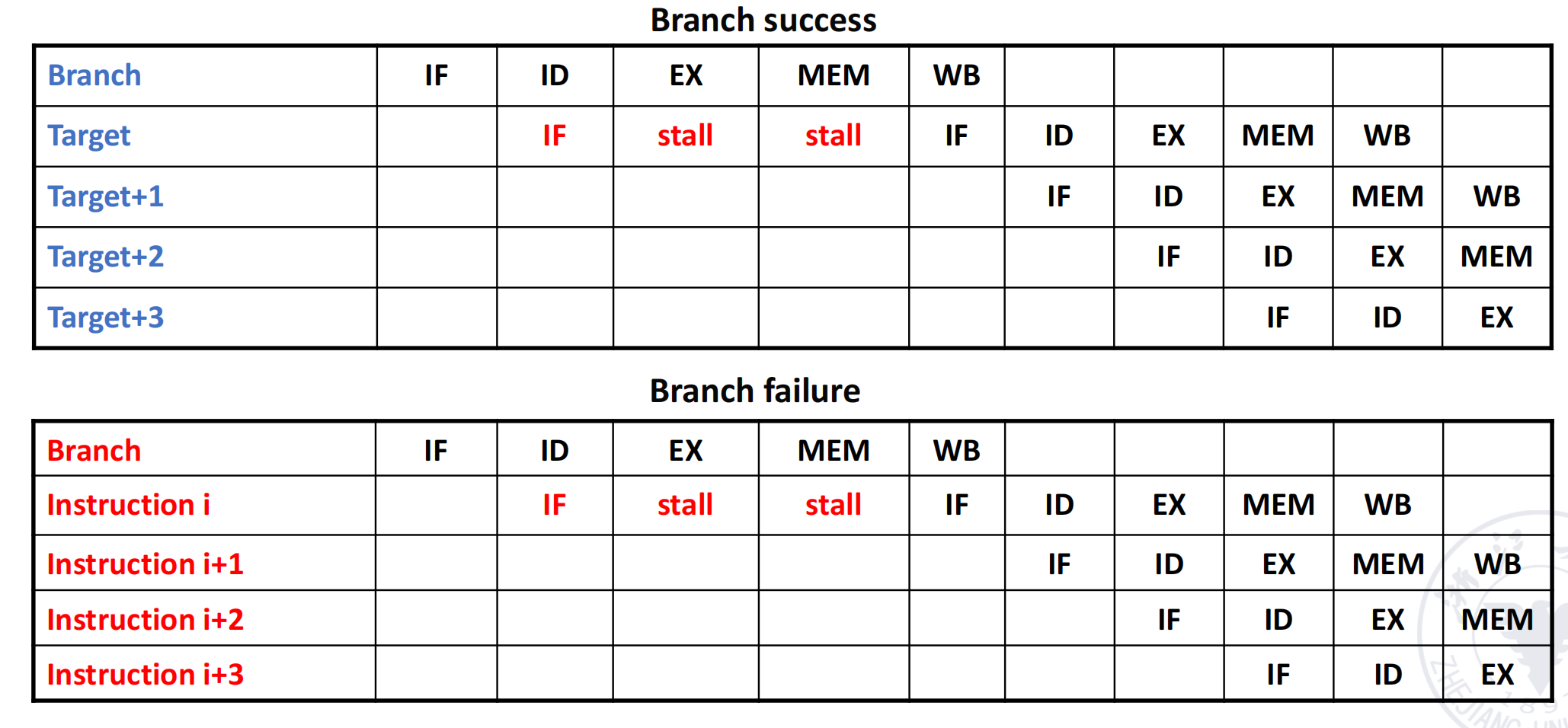
它的优点是简单、正确。
缺点是显而易见的:
- 每遇到 branch 就停;
- 流水线吞吐率会明显下降。
所以这种办法通常只适合作为最基础的正确性方案,而不是高性能方案。
Predict Not Taken
比完全等待更积极的办法是 predict not taken(预测不跳转)。
做法是:
- 先按顺序继续取下一条;
- 如果最后 branch 真的不跳,那么没有损失;
- 如果 branch 实际跳转,就把错取的指令冲掉,再改去目标地址。
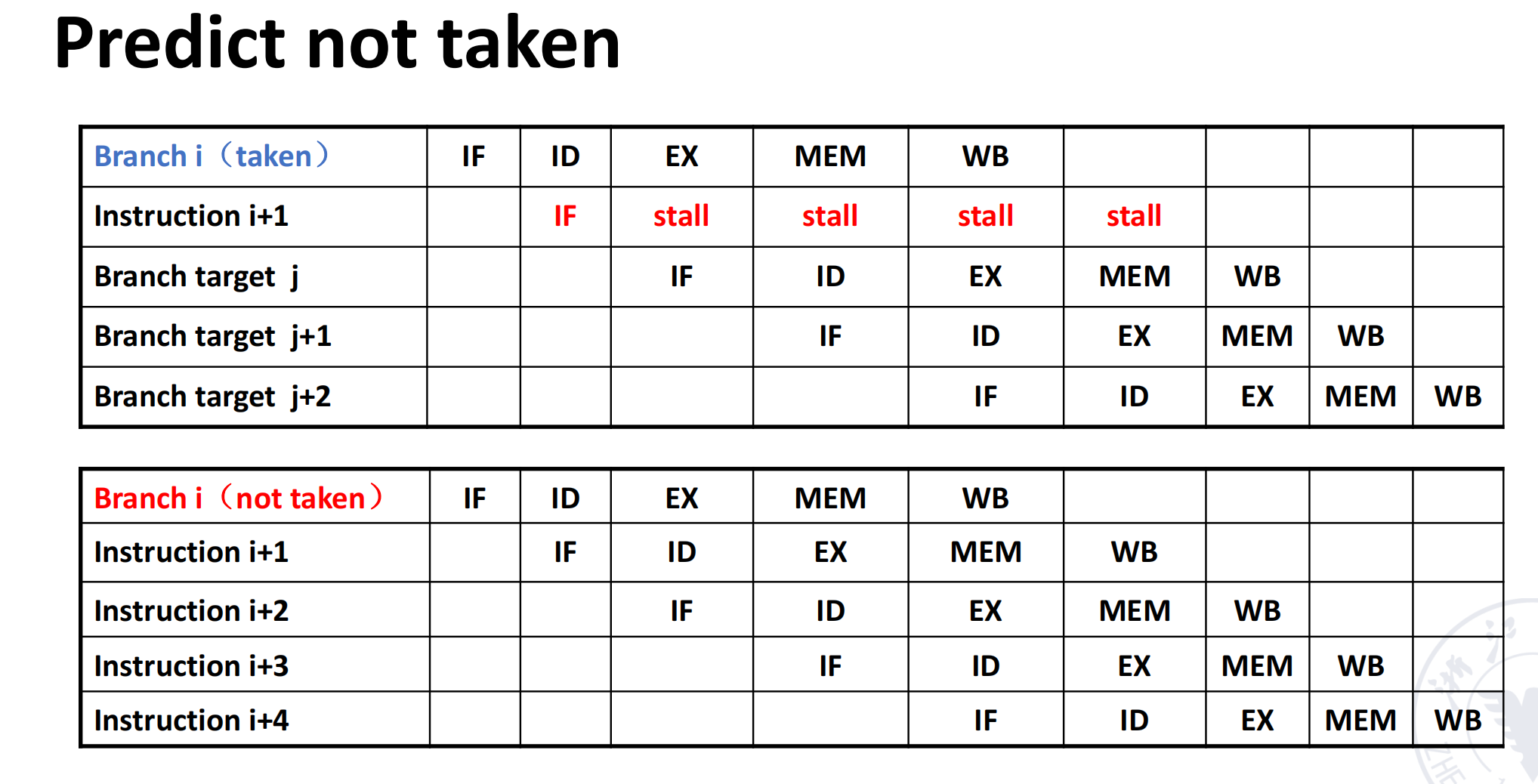
这种策略的特点是:
- 对“not taken” 分支几乎没有额外代价;
- 对“taken” 分支要承担 flush penalty。
Static Branch Prediction
在真正进入动态预测前,slides 还先提了一种更朴素的思路:static branch prediction(静态分支预测)。
它不是根据运行历史来猜,而是根据“这类 branch 通常长什么样”来猜。
slides 给出的经验规则是:
- backward branches predicted taken
- forward branches predicted not taken
原因很直观:
- 向后跳的分支往往对应 loop,通常多数时候都会继续 taken;
- 向前跳的分支往往对应 if/else,很多场景下 fall-through 更常见。
这类规则虽然粗糙,但实现简单,在没有复杂预测器时也能带来一定收益。
Delayed Branch
另一种经典思路是 delayed branch(延迟分支)。
其核心语义是:
分支后的那一条 delay slot 指令,无论 branch 最终是否跳转,都会执行。
这样做的好处是:
- 把原本的一个 branch penalty slot 暴露给编译器;
- 编译器可以尝试放入一条有用指令,而不是让它空着。
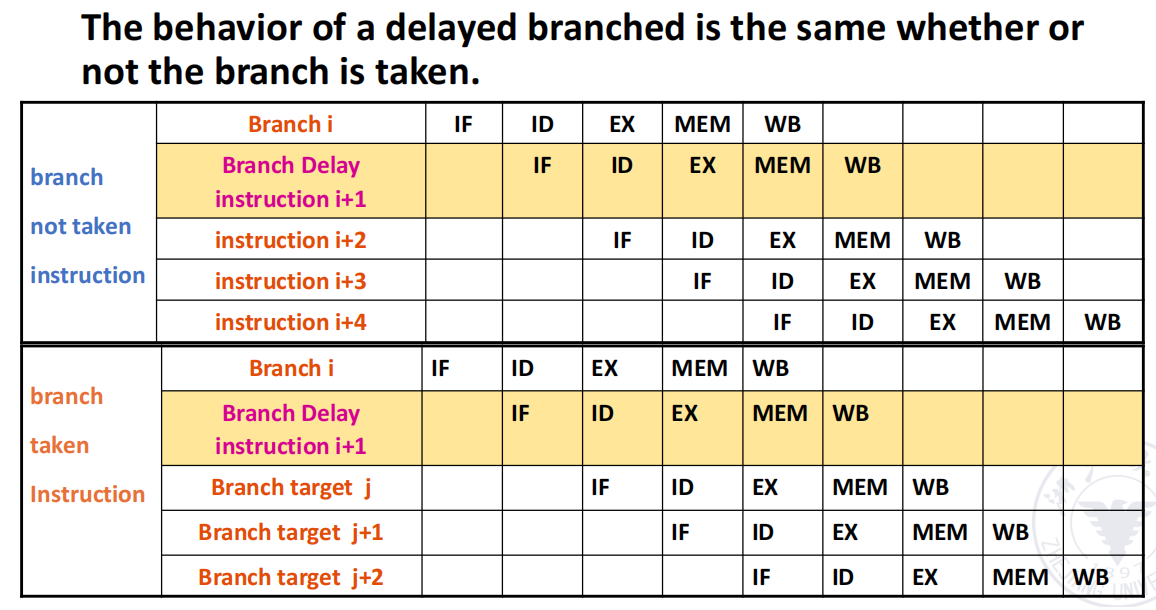
但缺点也很明显:
- ISA 语义变复杂;
- 编译器负担加重;
- 对深流水线和复杂实现并不友好。
slides 后面借 RISC-V 手册专门提醒:
RISC-V base ISA 不采用 branch delay slot。
NOTE延迟分支是理解经典 RISC 流水线非常重要的概念,但现代 ISA 未必继续保留它。
这一点在考试中常用来比较 “经典 MIPS 风格” 与 “现代 RISC-V 风格”。
Branch Operand 的数据相关
分支本身还会受到数据相关影响。
因为 branch 需要比较寄存器,如果这些寄存器恰好是前面指令刚写出来的,那么 branch 也可能要等。
三种情况:
-
若比较寄存器来自前面第 2 或第 3 条 ALU 指令
- 可通过 forwarding 解决
-
若比较寄存器来自紧前一条 ALU 指令,或前面第 2 条 load 指令
- 需要 1 个 stall cycle
-
若比较寄存器来自紧前一条 load 指令
- 需要 2 个 stall cycles
这说明:
- branch hazard 不只是“跳不跳”的问题;
- branch 自己使用的操作数,也可能触发 data hazard。
Dynamic Branch Prediction
随着流水线变深、甚至进入 superscalar 场景,branch penalty 会越来越不能接受。
于是就需要 dynamic branch prediction(动态分支预测)。
它的基本思路是:
- 硬件记录历史行为;
- 下次遇到同一个 branch 时,猜它会延续之前的趋势;
- 如果猜错,就 flush 并更新历史。
首先给出的是 BHT(Branch History Table),也叫 branch prediction buffer。
它通常:
- 由 branch instruction address 索引;
- 存储该分支最近的 taken / not taken 历史;
- 供前端在取指时快速做预测。
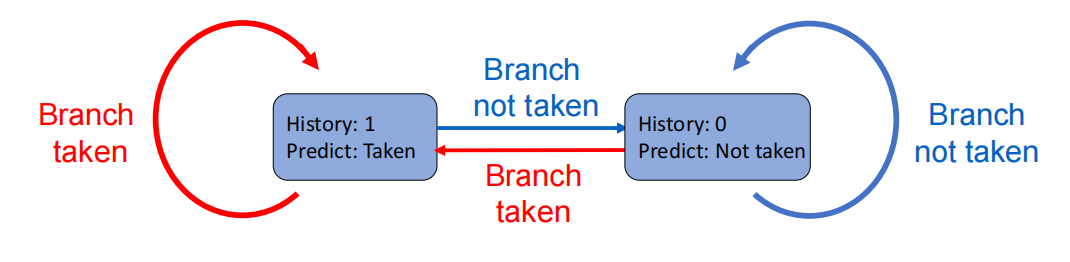
1-Bit Predictor 的缺点
- 内层循环在最后一次迭代时会从 taken 变成 not taken;
- 这一拍会误判一次;
- 下一次重新进入内层循环时,它又会在第一次迭代上误判一次。
也就是说,一个 loop branch 往往会被错两次。
这就是为什么 1-bit predictor 过于敏感:
一次偶然变化就会把状态完全翻转。
2-Bit Predictor
为了解决 1-bit predictor 过于脆弱的问题,常用的是 2-bit saturating predictor。
它通常有 4 个状态:
- Strongly Taken
- Weakly Taken
- Weakly Not Taken
- Strongly Not Taken
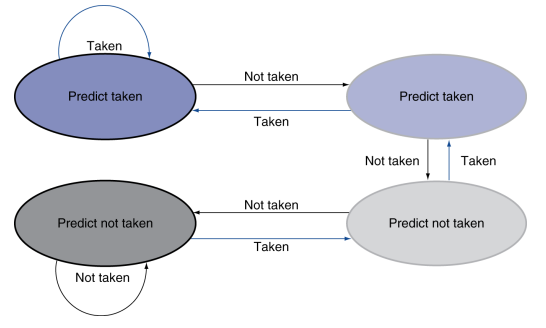
它的关键思想是:
- 一次反常结果不会立刻把预测方向翻转;
- 要连续两次朝相反方向发展,状态才会真正越过“taken / not taken”的分界。
因此:
- 对 loop 这种大多数时候 taken、仅最后一次 not taken 的分支更稳健;
- 平均误判率比 1-bit predictor 更低。
BTB:不仅要猜方向,还要更快拿到目标地址
即使预测器猜对了“会跳”,处理器仍然还要计算 branch target。
如果这一步还得再花 1 个周期,那么 taken branch 仍然会有额外代价。
这时就需要 BTB(Branch-Target Buffer),也叫 branch-target cache。
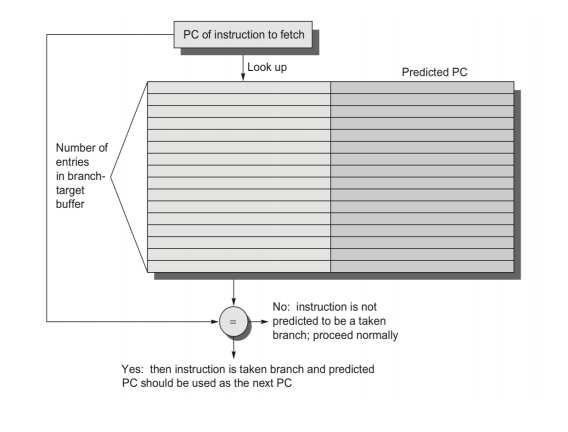
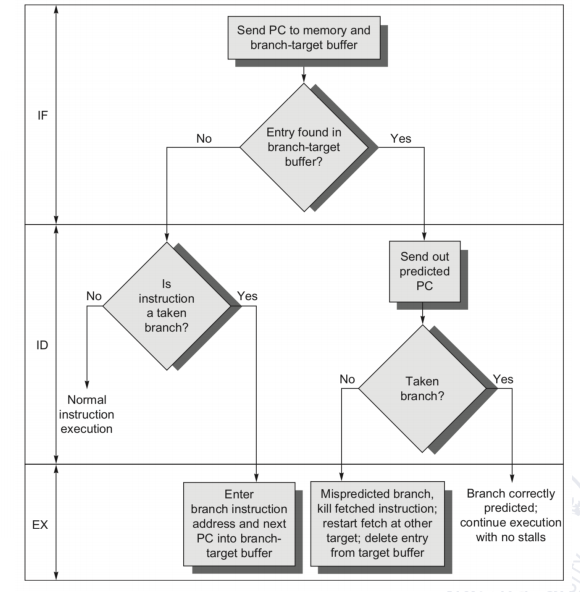
它缓存的是:
- 某条 branch 的目标地址;
- 让前端在预测 taken 时可以直接去目标处取指。
一个非常好记的表:
| BTB 中有无该项 | 预测 | 实际 | Delay cycle |
|---|---|---|---|
| Yes | Taken | Taken | 0 |
| Yes | Taken | Not taken | 2 |
| No | Not taken | Taken | 2 |
| No | Not taken | Not taken | 0 |
这个表反映出 BTB 的核心收益:
- 猜对且命中时,taken branch 可以做到 0 额外延迟;
- 猜错时仍要付出 flush 代价。
BTB 的进一步好处:
- 更快获得 target instructions;
- 能一次提供多个 target instructions;
- 支持 branch folding
- 某些无条件跳转甚至可做到几乎无延迟
Integrated Instruction Fetch Unit
随着前端越来越复杂,instruction fetch 也不再只是一个简单 stage。
integrated instruction fetch unit 会把几件事情整合在一起:
- integrated branch prediction
- instruction prefetch
- instruction memory access and buffering
也就是说,现代前端并不是“先取指,再单独预测,再单独访问 cache”,而是把这些功能高度耦合起来共同为高吞吐服务。
Schedule of Nonlinear Pipelining
前面大部分内容都围绕线性指令流水线展开。
这一节讨论的是更抽象也更理论化的内容:非线性流水线的调度。
由于非线性流水线存在反馈路径,同一个任务可能重复占用某个 stage。
于是问题变成:
- 新任务能否在某个时刻进入?
- 如果进入,会不会和已有任务在某个 stage、某个时刻发生冲突?
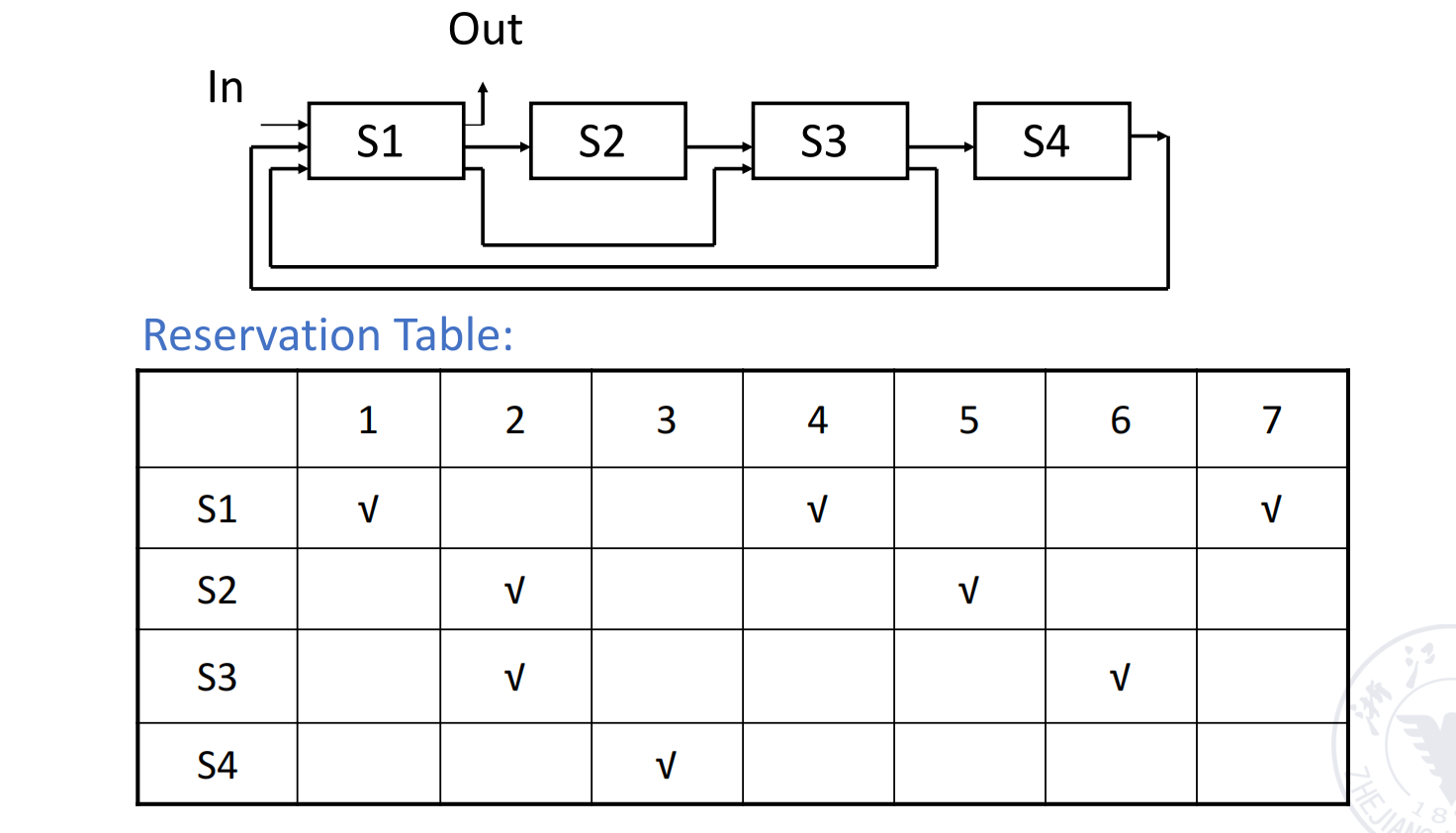
Reservation Table
分析这类问题最常见的工具是 reservation table(预约表)。
它的做法是:
- 行表示 stage,如
S1, S2, S3, S4 - 列表示相对时间槽
- 在某个格子里打勾,表示某个任务在该时刻占用了该 stage
一条任务在不同时间槽里反复使用某些 stage,于是就形成了一个具有反馈特征的预约表。
预约表的作用是:
- 把“一个任务自身怎样走完整条非线性流水线”表示清楚;
- 然后据此分析两个不同任务是否会撞车。
Initial Conflict Vector
从 reservation table 可以推出 prohibit sets(禁止延迟集合)。
slides 给出的样例是:
含义是:
- 如果新任务和旧任务的启动间隔为 1、5、6、8 个时间单位;
- 那么它们一定会在某个 stage 上发生冲突;
- 因此这些间隔是禁止的。
把它写成二进制向量,就是 initial conflict vector:
这里每一位表示对应的启动间隔是否被禁止:
- 1 表示禁止;
- 0 表示允许。
Current Conflict Vector
在真正调度时,我们关心的是当前状态下哪些启动间隔可行。
这就是 CCV(Current Conflict Vector)。
标准更新规则可以概括为:
- 时间前进一个单位,冲突向量右移一位;
- 如果在当前时刻启动一个新任务,则把右移后的结果与 做按位或。
也就是常写成:
其中 是本次选择的启动间隔。
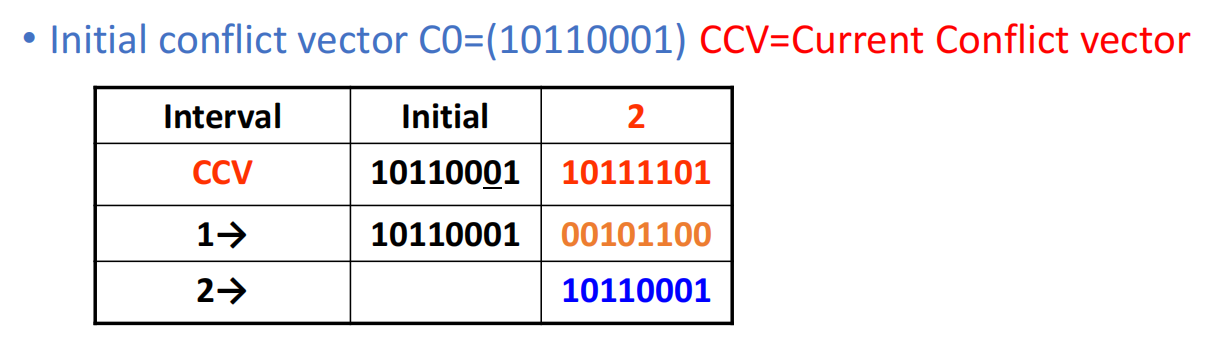
演化过程,例如:
- 初始

- 若选择间隔 2 启动新任务,则进入新状态:
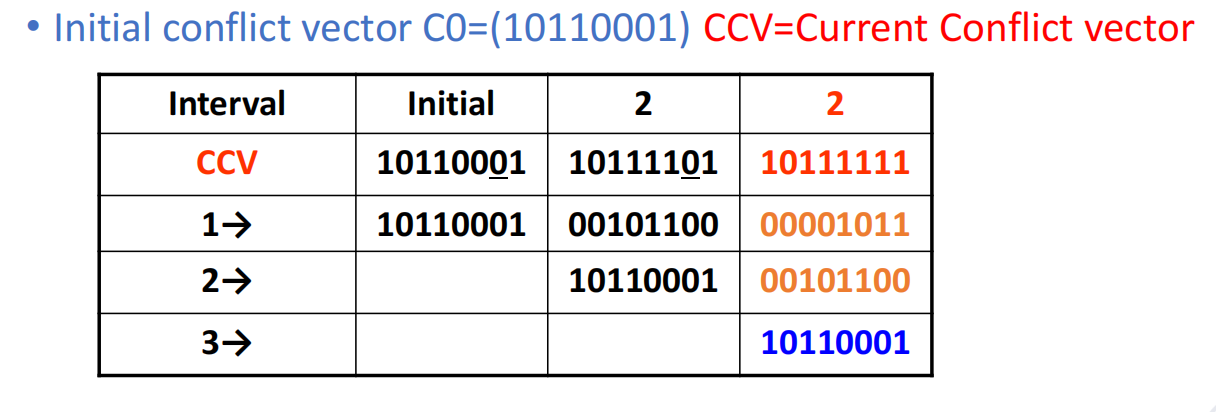
- 再选一次间隔 2,又会得到:
- 接着再选 7,就会回到:
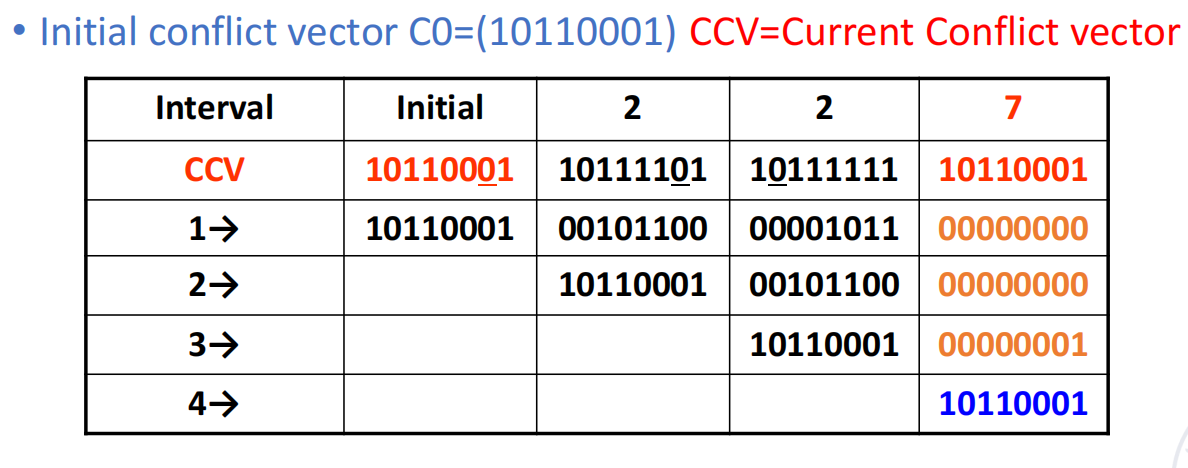
这就对应出一个循环调度串:
其平均启动间隔为:
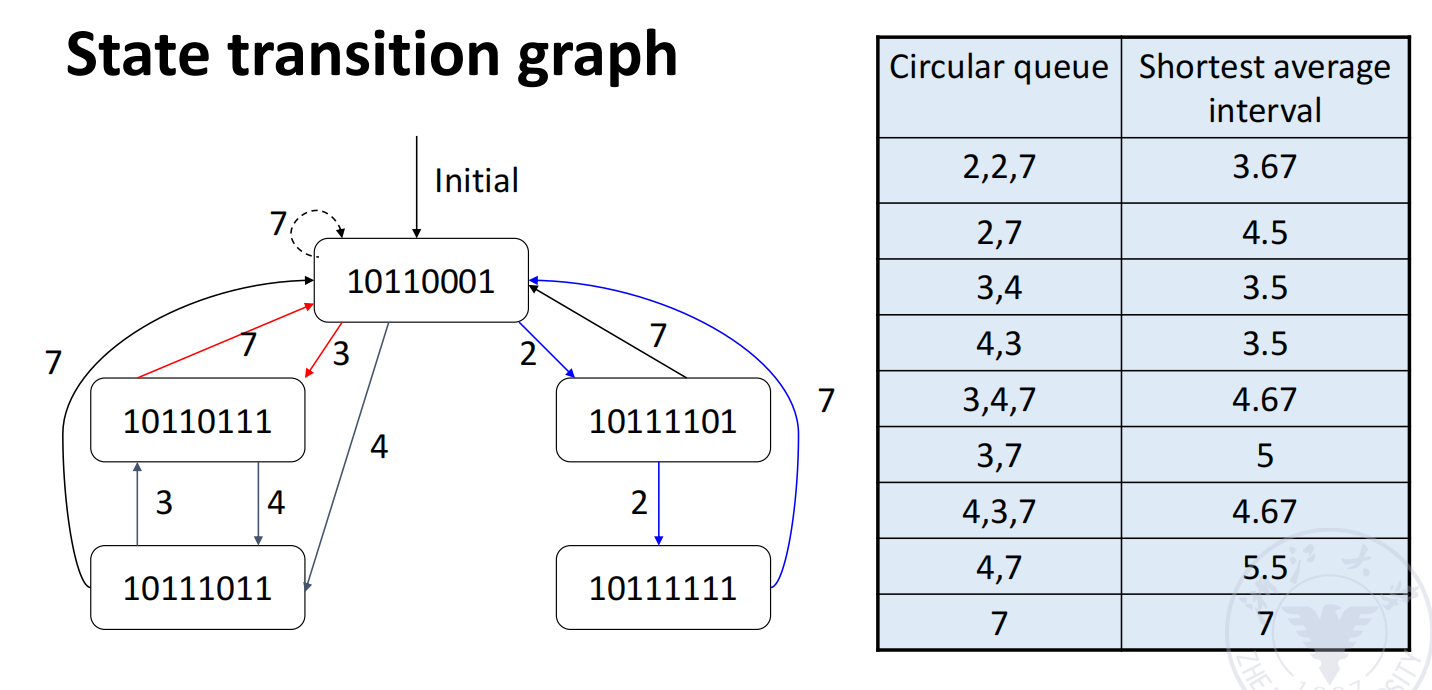
State Transition Graph
为了系统枚举所有可能的合法调度,slides 又引入了 state transition graph(状态转移图)。
图中的:
- 每个节点表示一个 conflict vector 状态;
- 每条边表示选择某个合法启动间隔后转移到的新状态。
这样就能从图里找出所有循环,并比较它们的平均启动间隔。
slides 给出的几个候选循环包括:
2,2,7,平均 3.672,7,平均 4.53,4,平均 3.54,3,平均 3.53,4,7,平均 4.673,7,平均 54,3,7,平均 4.674,7,平均 5.57,平均 7
因此从 slides 这个例子来看,最优循环是:
它们的最短平均启动间隔都是:
平均启动间隔越短,说明:
- 新任务进入得越频繁;
- 整体吞吐率越高。