概述
这一章的核心是:
数据库最终要落到磁盘 / SSD 上。关系表里的 tuple 不能直接“抽象地存在”,它必须被组织成 record,record 再被放进 block,block 再通过 file organization 和 buffer manager 被高效访问。
从上到下可以理解为:
- Relation / tuple:逻辑层看到的表和行
- Record / field:物理层保存的一条记录和记录里的字段
- Block / page:磁盘和内存之间传输的基本单位
- File organization:一批 record 在文件里怎么排列
- Buffer manager:哪些 block 留在内存,哪些 block 被替换出去
这一章本质上回答一个问题:
已经设计好的关系模式,实际在存储介质上应该怎么放,才能减少 I/O?
目录
- 概述
- 目录
- Database Storage Architecture
- File Organization
- Organization of Records in Files
- Data-Dictionary Storage
- Database Buffer
- Buffer Replacement Strategies
- Column-Oriented Storage
- Main-Memory Databases
Database Storage Architecture
数据库里的数据要持久保存,所以最终会放在 non-volatile storage 上,例如:
- magnetic disk
- SSD
- storage class memory
这些设备通常都是 block-structured devices:
数据读写的单位是 block,而数据库逻辑上处理的是 record。
所以数据库必须解决一个映射问题:
relation / tuple ↓record / field ↓block / page ↓file ↓disk / SSD其中:
- record 通常比 block 小
- 一个 block 里通常放多个 records
- I/O 通常以 block 为单位发生
- CPU 只能直接访问内存里的数据
- 磁盘 / SSD 上的数据必须先被读入内存,才能被处理
所以重点放在 SQL 查询背后的物理组织。
File Organization
文件、记录、字段、块
数据库可以看成一组文件:
- 一个 file 是一串 records
- 一个 record 是一串 fields
- 一个 field 对应关系表中的一个 attribute value
- 一个 block / page 是存储分配和数据传输的单位
一种最简单的做法是:
- 假设 record size 固定
- 每个 file 只存一种 record
- 不同 relation 使用不同 file
- record 不跨越 block boundary
这样实现最简单,但真实数据库中经常会出现可变长度字段,所以还需要处理 variable-length records。
Fixed-Length Records
定长记录指每条 record 占用相同字节数。
假设每条 record 长度为 n bytes,那么一个简单存储方式是:
record i starts at byte n × (i - 1)这样访问 record 很直接:知道 record 编号,就能直接算出偏移量。
例如 instructor(ID, name, dept_name, salary):
| record | ID | name | dept_name | salary |
|---|---|---|---|---|
| 0 | 10101 | Srinivasan | Comp. Sci. | 65000 |
| 1 | 12121 | Wu | Finance | 90000 |
| 2 | 15151 | Mozart | Music | 40000 |
| 3 | 22222 | Einstein | Physics | 95000 |
| 4 | 32343 | El Said | History | 60000 |
| 5 | 33456 | Gold | Physics | 87000 |
| 6 | 45565 | Katz | Comp. Sci. | 75000 |
| 7 | 58583 | Califieri | History | 62000 |
| 8 | 76543 | Singh | Finance | 80000 |
| 9 | 76766 | Crick | Biology | 72000 |
| 10 | 83821 | Brandt | Comp. Sci. | 92000 |
| 11 | 98345 | Kim | Elec. Eng. | 80000 |
这个方法的问题:
- 如果 block size 不是 record size 的整数倍,record 可能跨 block。
- record 删除之后,空出来的位置需要处理。
解决第一个问题的常见方法:
一个 record 必须完整放在一个 block 内,不允许跨 block boundary。
这样会浪费 block 末尾的一点空间,但能避免一次访问需要读两个 block。
删除定长记录
删除 record i 有三种策略。
移动后续所有记录
删除 record i 后,将:
record i+1, ..., record n整体前移到:
record i, ..., record n-1优点:
- 文件保持紧凑
- 顺序不变
缺点:
- 移动成本高
- 可能产生大量 block 写入
用最后一条记录填空
删除 record i 后,把最后一条 record n 移到 record i 的位置。
例如 slides 中的例子:
- 删除 record 3,也就是 Einstein
- 用 record 11,也就是 Kim,填到 record 3 的位置
优点:
- 只移动一条记录
- 删除成本低
缺点:
- 破坏原有顺序
- 如果外部有指针指向原 record,可能需要更新
使用 Free List
删除记录后,可以不移动其他记录,直接把空闲位置串成一个链表。
做法:
- file header 指向第一个空闲 record
- 第一个空闲 record 内部存下一个空闲 record 的地址
- 依次形成 free list
插入新记录时:
- 查看 header 指向的空闲位置。
- 把新 record 放进去。
- 更新 header,指向下一个空闲位置。
- 如果没有空闲位置,就追加到文件末尾。
这也是定长记录里最常用、最自然的删除处理方式。
Variable-Length Records
变长记录出现的原因主要有三类:
- 一个 file 里存多种 record type
- record 中有变长字段,例如
varchar - record 中有重复字段,例如数组、集合、multiset
变长记录需要解决两个问题:
- 一条 record 内部怎么表示,才能快速取出各个 attribute?
- 一个 block 内部怎么放多条变长 record,才能方便插入、删除和移动?
常见表示方法:
- fixed-length attributes 直接存在 record 前部
- variable-length attributes 在 record 前部用固定大小的
(offset, length)表示 - 真实的变长数据放在后面
- null 值用 null-value bitmap(空位图) 表示
以 Instructor(id, name, dept_name, salary) 为例:
[offset,length] [offset,length] [offset,length] [salary] [null bitmap] [id] [name] [dept_name]
其中:
id、name、dept_name是变长字符串salary是固定长度数值- null bitmap 中每一位表示一个属性是否为 NULL
例如 null bitmap 为 0000,表示四个属性都不是 NULL。
如果 salary 为 NULL,则对应 bit 置为 1,原本 salary 所在字节可以被忽略。
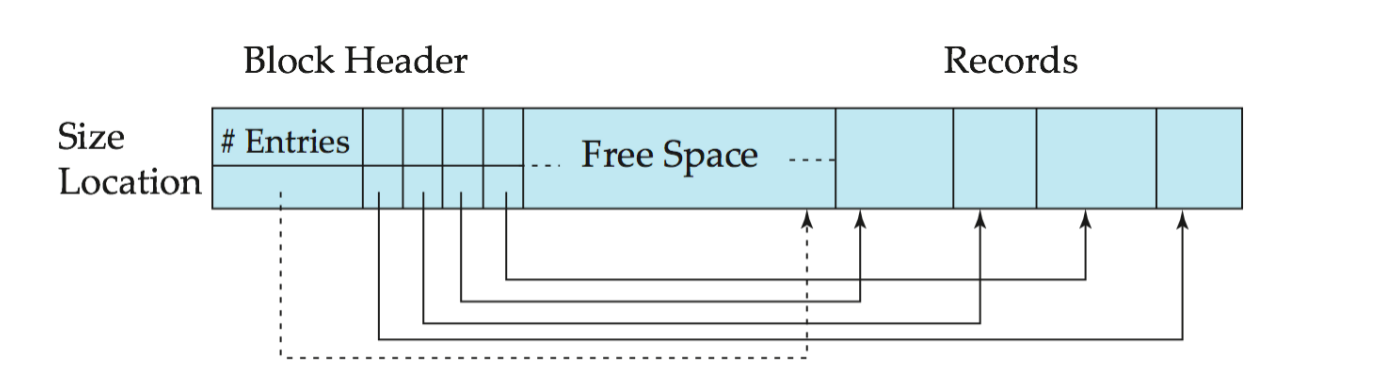
Slotted Page Structure
变长记录真正放进 block 时,常用 slotted page(分槽页)。
一个 slotted page 由两部分组成:
- Block Header
- Records Area
header 中保存:
- record entries 的数量
- free space 的末尾位置
- 每条 record 的 location 和 size
典型布局:
| Block Header | slot array | free space | records |其中:
- header 和 slot array 从 block 前端增长
- records 从 block 后端向前增长
- 中间区域是连续 free space
插入 record:
- 在 free space 末尾给 record 分配空间。
- 在 header 的 slot array 中增加一个 entry。
- entry 记录该 record 的 location 和 size。
删除 record:
- 把对应 slot 标记为 deleted。
- 移动其他 records,让 block 内空闲空间重新连续。
- 更新 header 中的 location / size 信息。
关键规则:
record pointer 不应直接指向 record 的物理位置,而应指向 header 里的 slot entry。
原因:record 在 page 内可能移动。如果外部指针直接指向 record,移动后指针就失效;如果外部指针指向 slot entry,只需要更新 slot entry 里的 location 即可。
Large Objects
有些属性可能远大于一个 block,例如:
- image
- audio
- video
- CAD file
- long text
SQL 中常见类型:
- BLOB:binary large object
- CLOB:character large object
数据库通常采用下面的处理方式:
- 大对象单独存储
- record 中只保存指向大对象的 logical pointer
这样可以避免普通 record 超过 block size。
大对象也可以放在数据库外部文件系统中,只在数据库里保存文件路径。但这样会带来两个问题:
- 文件可能被外部删除,导致数据库中的路径失效
- 数据库自身的权限控制无法直接约束外部文件
所以真实系统要在性能、备份大小、权限控制、一致性之间做权衡。
Organization of Records in Files
几种文件组织方式
record 在 file 里可以有多种组织方式:
| File Organization | 核心思想 | 适合场景 |
|---|---|---|
| Heap | record 可以放在任意有空间的位置 | 插入多、无序访问 |
| Sequential | 按 search key 顺序存放 | 顺序扫描、范围处理 |
| Multitable Clustering | 多个 relation 的相关记录放在一起 | join 很频繁 |
| B+-tree | 用 B+-tree 保持有序并支持高效插删 | 有序访问 + 点查 |
| Hashing | 对 search key 做 hash 决定 block | 等值查找 |
Heap File Organization
Heap file organization 中,record 可以放在文件中任何有空闲空间的位置。
特点:
- record 通常一旦放入就不移动
- 插入时要快速找到有足够空间的 block
- 删除后留下的空间应当被后续插入复用
难点是:
如何不扫描整个 file,就知道哪些 block 有空闲空间?
解决方法是 free-space map。
Free-Space Map
Free-space map 用一个数组记录每个 block 的空闲空间比例。
基本形式:
one entry per block每个 entry 用几 bit 到 1 byte 表示该 block 的空闲比例。
slides 的例子中:
- 每个 block 用 3 bits 表示
- entry value / 8 表示该 block 的 free fraction

例如:
first level:4 2 1 4 7 3 6 5 1 2 0 1 1 0 5 6含义:
- 第 0 个 block 的空闲比例约为
4/8 - 第 4 个 block 的空闲比例约为
7/8 - entry 越大,空闲空间越多
为了加速查找,还可以建立第二层 free-space map。
如果每 4 个 first-level entries 聚合成一个 second-level entry,则 second-level entry 存这 4 个值的最大值:
first level: 4 2 1 4 | 7 3 6 5 | 1 2 0 1 | 1 0 5 6second level: 4 | 7 | 2 | 6查找过程:
- 先查 second-level map,找到可能有足够空间的一组 block。
- 再进入对应 first-level entries 精查。
- 最后读取具体 block 验证。
注意:free-space map 可以周期性写回磁盘,不必每次更新都同步写盘。
这意味着 map 可能有旧值:
- map 说某 block 有空间,但读出来发现没有:继续找别的 block
- map 说某 block 没空间,但实际有空间:可能造成暂时空间浪费
这种错误可以通过后续扫描和重建 map 修正。
Sequential File Organization
Sequential file organization 按某个 search key 的顺序存放 records。
注意:
search key 不一定是 primary key,也不一定是 superkey。
例如 instructor records 可以按 ID 排序:
10101 → 12121 → 15151 → 22222 → ... → 98345优点:
- 适合顺序处理整个文件
- 适合按 search key 做范围扫描
- 对某些排序、连接算法有帮助
为了维持 search-key order,record 通常会带有 pointer,指向逻辑上的下一条 record。
删除
删除可以用 pointer chain 处理。
插入
插入时:
- 找到 search-key order 中前一条 record。
- 如果同一个 block 中有空闲空间,就插入该 block。
- 如果没有空间,就插入 overflow block。
- 更新 pointer chain,让逻辑顺序仍然正确。
Example:
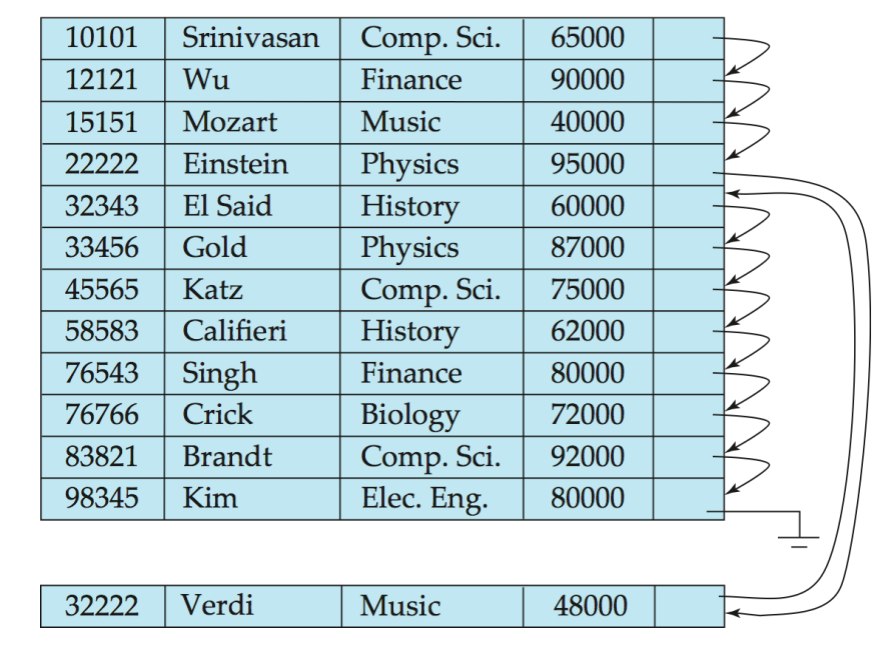
- 原文件按
ID顺序存储 - 插入
(32222, Verdi, Music, 48000) - 逻辑上它应该位于
22222和32343之间 - 如果原 block 没空间,就放到 overflow block
- 通过 pointer chain 连接回正确顺序
代价:
- 插入和删除多了以后,物理顺序会逐渐偏离逻辑顺序
- 顺序扫描效率下降
- 需要定期 reorganize file,恢复物理顺序
Multitable Clustering File Organization
普通情况下,每个 relation 分开存:
department fileinstructor fileMultitable clustering file organization 会把多个 relation 中经常一起访问的 records 放到同一个 file,甚至同一个 block。
动机:
把 join 中会一起访问的数据放近,减少 block I/O。
典型例子:
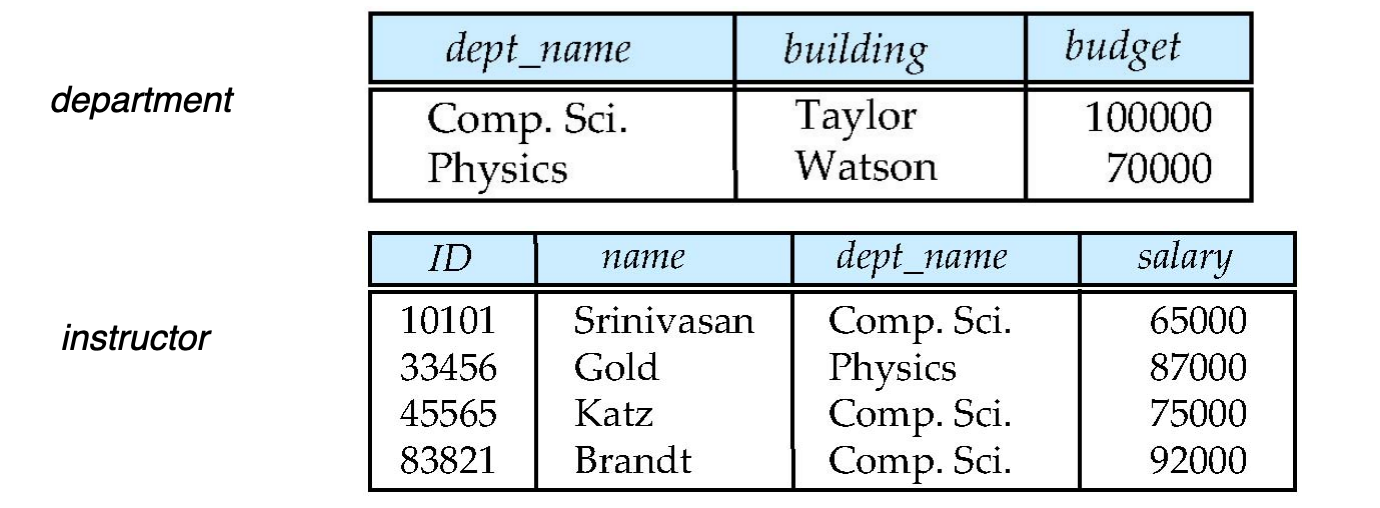
select dept_name, building, budget, ID, name, salaryfrom department natural join instructor;如果 department 和 instructor 经常按照 dept_name 连接,可以把同一个 department 及其 instructors 放在一起:
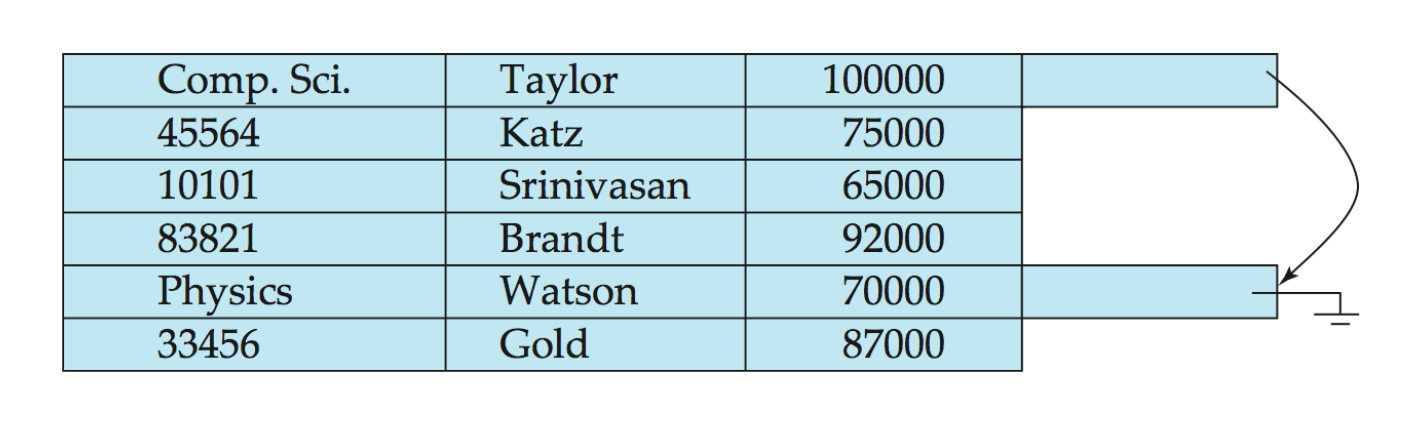
这里的 dept_name 就是 cluster key。
优点:
- 对
department ⋈ instructor这类 join 很友好 - 对“查询某个 department 及其 instructors”很友好
- 相关 records 通常在同一 block 或相邻 block 中
缺点:
- 只查
department时会更慢,因为每个 block 混入了 instructor records - block 中 record 类型不同,导致 variable-size records 问题更明显
- 需要额外 pointer chains 来快速找到某个 relation 的 records
结论:
clustering 适合 join workload 明确、访问模式稳定的场景。
Table Partitioning
Table partitioning 把一个 relation 的 records 拆成多个更小的 relation 分开存储。
例如交易表:
transaction_2018transaction_2019transaction_2020...逻辑上用户仍然查询 transaction:
select *from transactionwhere year = 2019;优化器可以把它改写成只访问:
transaction_2019优点:
- 减少每个 partition 的 free-space 管理成本
- 查询带 partition key 条件时,只访问相关 partition
- 不同 partition 可以放在不同存储设备上
例如:
- 当前年份交易数据放 SSD
- 较老年份交易数据放 magnetic disk
缺点:
- 如果查询没有 partition 条件,仍要访问所有 partitions
- 分区键选得不好,会导致负载不均匀
- 维护复杂度上升
Data-Dictionary Storage
Data dictionary 也叫 system catalog,保存的是 metadata。
metadata 就是:
data about data。
数据库需要保存的 metadata 包括:
Relation 信息
- relation names
- 每个 relation 的 attributes
- attributes 的 types 和 lengths
- views 的 names 和 definitions
- integrity constraints
User 与权限信息
- user names
- encrypted passwords
- default schemas
- authorization information
统计信息
- 每个 relation 的 tuple 数量
- 每个 attribute 的 distinct values 数量
- 这些统计信息会服务于 query optimizer
物理组织信息
- relation 是 heap / sequential / hash / clustered 组织
- relation 的物理位置
- relation 对应的 file names 或 block list
Index 信息
- index name
- indexed relation
- indexed attributes
- index type
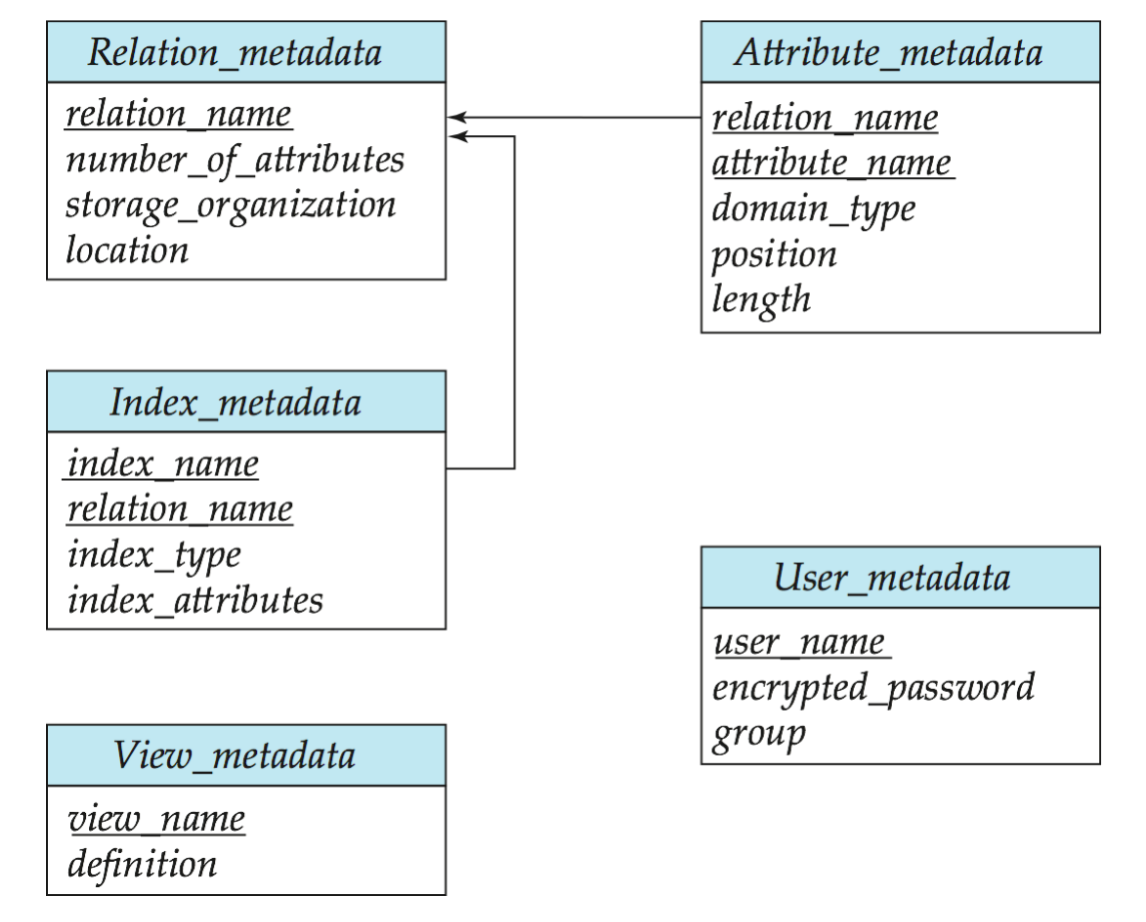
一种简化的 metadata schema 可以写成:
Relation_metadata(relation_name, number_of_attributes, storage_organization, location)Attribute_metadata(relation_name, attribute_name, domain_type, position, length)Index_metadata(index_name, relation_name, index_type, index_attributes)View_metadata(view_name, definition)User_metadata(user_name, encrypted_password, group)关键点:
- data dictionary 本身也可以用 relation 表示
- 它相当于一个“关于数据库的小数据库”
- 真实系统中会保存更多字段
- 为了快速访问,启动数据库时常把 system metadata 读入内存
有一个 bootstrap 问题:
要读取
Relation_metadata,系统必须先知道Relation_metadata自己存在哪里。
所以这部分信息通常写在数据库代码中,或放在数据库文件的固定位置。
Database Buffer
Buffer 与 Buffer Manager
block 是存储分配和数据传输的单位。
数据库要尽量减少 disk ↔ memory 的 block transfer。
因此会在内存中开辟一块区域:
- buffer:main memory 中用于缓存 disk blocks 的区域
- buffer manager:负责分配和管理 buffer space 的子系统
基本思想:
如果要访问的 block 已经在 buffer 中,就不需要磁盘 I/O。
这就是数据库系统性能优化中非常核心的一层。
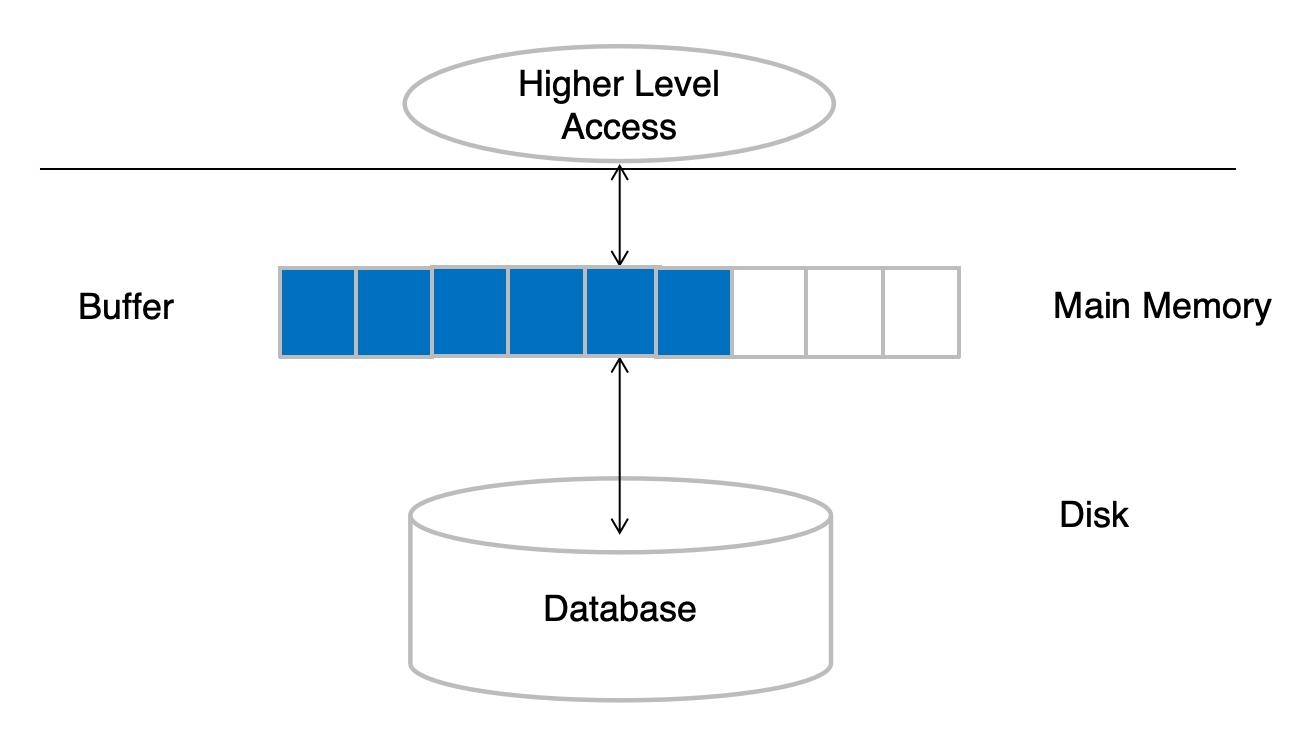
Buffer Manager 的工作流程
当上层程序需要某个 block 时,会向 buffer manager 请求。
情况一:block 已经在 buffer 中
buffer manager 直接返回该 block 在内存中的地址。
request block BB is in bufferreturn memory address of B情况二:block 不在 buffer 中
buffer manager 执行:
- 在 buffer 中分配空间。
- 如果没有空闲 buffer page,就选择某个 block 替换出去。
- 如果被替换的 block 被修改过,需要先写回 disk。
- 从 disk 读取目标 block 到 buffer。
- 返回该 block 的内存地址。
注意:
被替换的 block 只有在 dirty 时才需要写回 disk。
这里的 dirty 指:
buffer 中的版本比 disk 上的版本更新Pinned Block
Pinned block 是当前不能被驱逐的 buffer block。
原因很直接:
- 某个进程正在读 / 写这个 block
- 如果 buffer manager 此时把它替换出去,正在访问它的进程会读到错误内容,甚至写坏新 block
使用方式:
- 读写 block 之前执行 pin
- 读写完成后执行 unpin
多个进程可能同时 pin 同一个 block,因此系统维护 pin count:
pin => pin_count += 1unpin => pin_count -= 1只有当:
pin_count = 0该 buffer block 才允许被 evict。
Shared Lock 与 Exclusive Lock
pin 只能保证 block 不被替换出去。
如果多个进程同时访问同一个 buffer block,还需要锁。
数据库 buffer manager 支持:
- shared lock:读锁
- exclusive lock:写锁
规则:
| 情况 | 是否允许 |
|---|---|
| 多个 shared locks 同时存在 | 允许 |
| 一个 exclusive lock 存在时再加 shared lock | 不允许 |
| 一个 exclusive lock 存在时再加 exclusive lock | 不允许 |
| 已有 shared lock 时加 exclusive lock | 需要等待 |
典型流程:
读数据:
pin blockacquire shared lockreadrelease shared lockunpin block更新数据:
pin blockacquire exclusive lockupdaterelease exclusive lockunpin block锁的目的:
防止一个进程正在重组 page 内容时,另一个进程读到中间状态。
Output 与 Forced Output
buffer 中的 dirty block 可以稍后写回 disk。
这种普通写回称为 output of blocks。
但有些场景必须强制写回 disk,称为 forced output。
原因主要与 recovery 有关:
- memory 中的数据系统崩溃后会丢失
- disk 上的数据通常能保留
- transaction commit 后,系统必须保证足够信息已经落盘
forced output 通常会和 logging 机制配合使用。具体恢复算法会在 Recovery System 一章展开。
Buffer Replacement Strategies
LRU
LRU(Least Recently Used) 策略:
替换最近最久没有被使用的 block。
直觉是:
- 最近访问过的 block 未来可能还会访问
- 很久没访问的 block 未来访问概率较低
操作系统的 page replacement 经常使用类似思想。
但数据库系统比操作系统有更多信息:
- query plan 告诉系统接下来大概率会访问哪些 relation
- sequential scan、nested-loop join 等访问模式很明确
- optimizer 可以向 buffer manager 提供 replacement hints
所以数据库里单纯 LRU 经常不够好。
Example
- 有 4 个 buffer pages
- 初始为空
- access sequence:
1, 4, 8, 1, 5, 2, 3, 2, 4按 LRU 策略:
| Step | Access | Buffer after access | Replacement |
|---|---|---|---|
| 1 | 1 | 1 | no |
| 2 | 4 | 4, 1 | no |
| 3 | 8 | 8, 4, 1 | no |
| 4 | 1 | 1, 8, 4 | no |
| 5 | 5 | 5, 1, 8, 4 | no |
| 6 | 2 | 2, 5, 1, 8 | replace 4 |
| 7 | 3 | 3, 2, 5, 1 | replace 8 |
| 8 | 2 | 2, 3, 5, 1 | no |
| 9 | 4 | 4, 2, 3, 5 | replace 1 |
所以:
replacement occurred 3 times被替换出去的 block 依次是:
4, 8, 1注意区分:
- 第一次把 block 放入空 buffer page 不算 replacement
- buffer 满了以后再换出旧 block,才算 replacement
数据库里 LRU 的问题
考虑 nested-loop join:
for each tuple tr of r do for each tuple ts of s do if tr and ts match then output如果 s 被反复全表扫描,LRU 可能表现很差。
原因:
- 顺序扫描会把大量只用一次的 block 装入 buffer
- 这些 block 可能把更有价值的数据挤出去
- 最近使用并不代表未来马上会用
数据库知道当前查询计划,所以可以采用更贴合访问模式的策略。
Toss-Immediate 与 MRU
Toss-Immediate
Toss-immediate strategy:
一个 block 的最后一个 tuple 处理完后,立即释放它占用的 buffer space。
适合场景:
- 顺序扫描某个 relation
- 处理过的 block 后面不会再用
例如扫描 instructor 时,某个 instructor block 处理完后就可以丢掉。
MRU
MRU(Most Recently Used):
替换最近刚刚使用过的 block。
这个策略听起来反直觉,但在某些循环扫描中是合理的。
例如 nested-loop join 中反复扫描 department:
- 当前刚处理完的 department block
- 下一次再次访问它,要等其他 department blocks 都处理完之后
- 所以它反而是较晚才会再次用到的 block
为了让 MRU 正确工作:
- 正在处理的 block 要 pin
- 处理完后 unpin
- 它成为 most recently used block
- 如果需要替换,就可以优先替换它
Clock Algorithm
Clock algorithm 是 LRU 的近似实现,也叫 second-chance algorithm。
基本结构:
- 把 buffer blocks 排成一个环
- 每个 block 有一个
reference_bit - 有一个指针在环上移动

规则:
When pin_count reduces to 0, set reference_bit = 1reference_bit is the 2nd chance bit替换时:
do for each block in cycle: if reference_bit == 1: set reference_bit = 0 else if reference_bit == 0: choose this block for replacementuntil a page is chosen直观理解:
reference_bit = 1:最近用过,给一次机会,先清零reference_bit = 0:已经给过机会还没再被用,可以替换- pinned block 不能被替换
Clock 的好处:
- 不需要精确维护完整 LRU 链表
- 实现简单
- 开销低
- 能近似表达“最近是否被访问过”
Write Reordering and Recovery
buffer 允许写操作先发生在内存中,稍后再写回 disk。
为了性能,系统可能会重排写入顺序。
问题是:
如果写入顺序被重排,系统又在中间崩溃,磁盘上的数据结构可能不一致。
例子:文件系统用链表记录文件 block:
- 新建一个链表节点。
- 更新前一个节点的 pointer 指向新节点。
- 如果 pointer 先落盘,而新节点内容还没落盘,系统崩溃后 pointer 会指向无效内容。
现代文件系统通常用 journaling 缓解这一问题:
- 先把写操作顺序记录到 log disk / journal
- 实际数据可以稍后写回真实位置
- 崩溃后根据 journal 重做未完成写入
数据库系统也有自己的 logging 和 recovery 机制,后续 Recovery System 会详细讲。
buffer manager 不能随意写回 dirty block,它必须和 recovery subsystem 协调。
Column-Oriented Storage
Row Store 与 Column Store
传统数据库通常使用 row-oriented storage:
tuple1: ID, name, dept_name, salarytuple2: ID, name, dept_name, salarytuple3: ID, name, dept_name, salary也就是一条 tuple 的所有 attributes 放在一起。
Column-oriented storage 也叫 columnar representation:
ID column: 10101, 12121, 15151, ...name column: Srinivasan, Wu, Mozart, ...dept_name column: Comp. Sci., Finance, Music, ...salary column: 65000, 90000, 40000, ...
也就是同一 attribute 的所有值连续存放。
如果要重构第 i 行 tuple,需要从每个 column 的第 i 个位置取值,然后拼回 tuple。
列式存储的优点
Reduced I/O
很多分析查询只访问少数几列。
例如:
select avg(salary)from instructor;只需要读 salary 列,不需要读 ID、name、dept_name。
列式存储可以显著减少 I/O。
Improved CPU Cache Performance
现代 CPU 会按 cache line 读取连续内存。
列式存储中,相邻字节往往属于同一 column。
如果查询正在扫描 salary,cache line 里大多都是有用的 salary values。
行式存储中,相邻字节会混合 ID、name、dept_name、salary,很多字段对当前查询没用,浪费 cache。
Improved Compression
同一列的数据类型相同、分布更相似。
例如:
- dept_name 中有大量重复值
- salary 都是数字
- ID 长度和格式相似
所以列式存储更容易压缩。
压缩的收益:
- 减少磁盘 I/O
- 减少内存占用
- 对数据仓库尤其重要
Vector Processing
现代 CPU 支持 vector processing。
列式存储把同一列连续放置,适合批量执行:
- 比较一列是否满足条件
- 对一列做聚合
- 对一列做向量化计算
例如:
select avg(salary)from instructorwhere salary > 80000;可以对 salary column 做连续扫描和向量化比较。
列式存储的代价
Tuple Reconstruction Cost
如果查询需要完整 tuple:
select *from instructorwhere ID = '10101';列式存储需要从多个 column 中取出同一行位置的值,再重构 tuple。
这会带来额外成本。
Tuple Deletion and Update Cost
列式存储常配合压缩。
如果单独更新或删除一条 tuple,可能需要改写压缩块中的大量数据。
所以列式存储不适合频繁小更新。
Decompression Cost
查询压缩数据时需要解压。
如果只想访问很少几条记录,可能需要解压较大范围的数据,代价不划算。
因此:
| 存储方式 | 更适合 |
|---|---|
| Row-oriented storage | OLTP,事务处理,频繁点查和更新 |
| Column-oriented storage | OLAP,决策支持,数据分析,大量扫描少数列 |
ORC 与 Parquet
两个常见列式文件格式:
- ORC(Optimized Row Columnar)
- Parquet
它们常用于 Hadoop / HDFS / 大数据系统。
共同特点:
- open source
- column-oriented data file format
- 适合高效存储和读取
- 文件内部按列组织数据
- 常配合压缩和统计信息做谓词下推、跳过无关数据块
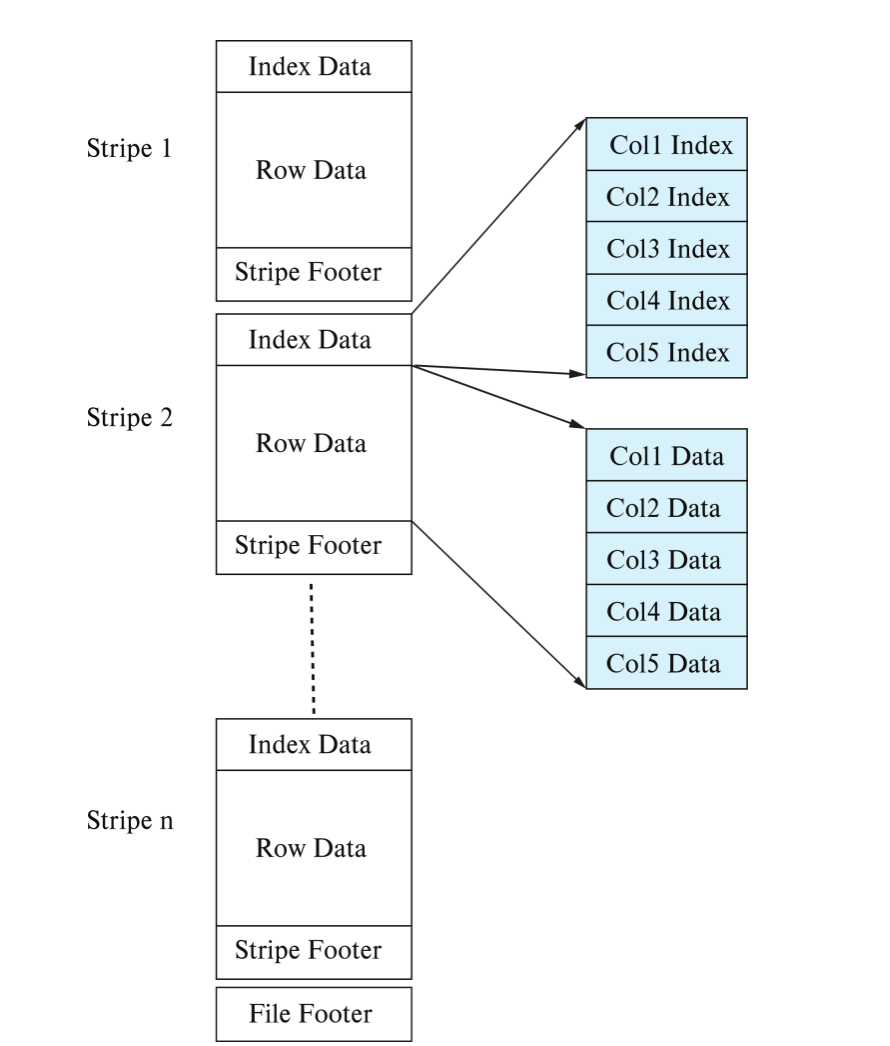
ORC 的典型结构:
ORC File├── Stripe 1│ ├── Index Data│ ├── Row Data / Column Data│ └── Stripe Footer├── Stripe 2│ ├── Index Data│ ├── Row Data / Column Data│ └── Stripe Footer└── File Footer其中:
- 一个 ORC file 由多个 stripes 组成
- 每个 stripe 存一批 tuples 的列式表示
- index data 记录每组 values 的起始位置
- 查询可以跳过不需要的 group,减少 I/O
Hybrid Row/Column Store
有些数据库同时支持 row store 和 column store,称为:
hybrid row/column stores
典型思路:
- 新写入、频繁更新的数据放 row store
- 稳定后、用于分析的数据迁移到 column store
这样可以同时服务:
- 事务处理 workload
- 分析查询 workload
还有一种折中方案:
在一个 disk block 内部使用 column-oriented layout。
这样:
- 一个 block 仍包含一组 tuple 的全部 attributes
- 访问完整 tuple 不需要读多个 block
- block 内部列式排列又能改善 CPU cache 和 vector processing
这介于纯行式和纯列式之间。
Main-Memory Databases
随着内存容量变大,有些数据库可以整体放入 main memory。
Main-memory database 指:
数据常驻内存,并且系统的数据结构和算法专门针对内存访问优化。
它和“传统数据库把 buffer 设得很大”有区别:
- 传统数据库仍以 disk block 为核心组织单位
- main-memory database 可以直接围绕内存指针和内存布局优化
主要特点:
不需要传统 Buffer Manager
如果全部数据都在内存中:
- 不需要反复从 disk fetch block 到 buffer
- 也不需要做普通意义上的 buffer replacement
- record pointer 可以直接是 memory pointer
访问 record 的成本从:
block id → check buffer → locate page → locate slot → record降低为:
memory pointer → recordRecord 不应频繁移动
直接 memory pointer 的前提是 record 地址稳定。
如果使用 slotted page,record 可能因为 page 内重组而移动。
所以 main-memory database 常直接在内存中分配 records,并尽量保证 record 不因其他 record 更新而移动。
问题:
- variable-size records 反复插入删除会造成 memory fragmentation
- 系统需要内存管理策略或周期性 compaction
内存中的列式存储
main-memory database 也可以使用 column-oriented storage。
例如每一列是一个逻辑数组。
如果不断 append,保持一个大数组连续分配成本高。
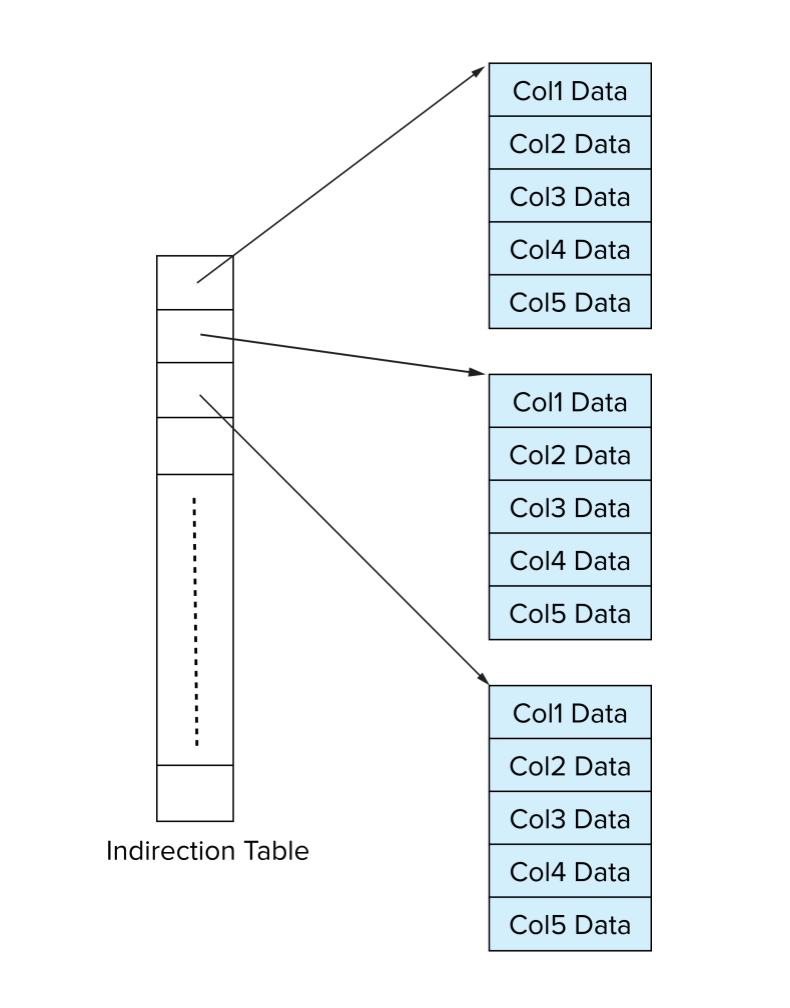
所以可以把一个 logical array 拆成多个 physical arrays,再用 indirection table 连接:
logical column ↓indirection table ↓physical array 1, physical array 2, physical array 3, ...查找第 i 个元素时:
- 通过 indirection table 找到对应 physical array。
- 在 physical array 内计算 offset。
- 读取对应值。
列式内存存储适合 decision support applications。
原因:
- 扫描快
- cache locality 好
- 可压缩,减少内存需求
- 适合 vector processing