

概述
这一章的核心是:
数据库最终要落到 物理存储设备 上。不同设备在 速度、成本、可靠性、访问模式 上差异很大,这些差异会直接影响数据库的文件组织、缓冲管理、索引设计、查询代价和故障恢复。
从数据库系统角度看,物理存储要回答四个问题:
- 数据放在哪一层存储上?
- 一次 I/O 到底要花多久?
- 随机访问和顺序访问差在哪里?
- 如何在磁盘 / SSD / RAID 上提高性能并保证可靠性?
简单说:
- 上层 SQL 看见的是表
- 底层系统处理的是 block / page / disk / SSD / RAID
目录
- 概述
- 目录
- Physical Storage Media
- Storage Hierarchy
- Storage Interfaces
- Magnetic Disks
- Performance Measures of Disks
- Flash Storage and SSD
- Storage Class Memory and NVM
- RAID
- Optimization of Disk-Block Access
Physical Storage Media
数据库系统管理的是数据,但数据最终一定存放在某种 storage media(存储介质) 上。
不同存储介质的差异决定了:
- 一次查询读数据有多慢
- 一次事务提交要等多久
- 索引是否值得建立
- 数据丢失后能不能恢复
- 系统需要多少 buffer / cache
评价存储介质的三个维度
通常从三个方面评价存储介质:
- Speed:访问数据有多快
- Cost per unit of data:单位容量成本有多高
- Reliability:数据在断电、系统崩溃、设备损坏时是否可靠
更快的设备通常更贵,容量也更小。更便宜的设备通常更慢,但能存更多数据。
这就是存储层次存在的原因。
Volatile vs Non-volatile
Volatile storage
易失存储(volatile storage) 的特点是:
- 断电后内容丢失
- 速度通常很快
- 典型例子:cache、main memory
数据库运行时会把数据读入内存处理,但不能只放在 volatile storage 中。
原因很直接:
- 系统崩溃后,内存内容会丢
- 数据库必须保证持久性
- 所以关键数据最终要写入 non-volatile storage
Non-volatile storage
非易失存储(non-volatile storage) 的特点是:
- 断电后内容仍然保留
- 速度通常慢于内存
- 典型例子:flash memory、magnetic disk、optical disk、magnetic tape
数据库的持久数据主要依赖非易失存储。
常见存储介质
| 存储介质 | 特点 | 数据库中的作用 |
|---|---|---|
| Cache | 最快、最贵、容量小、易失 | 由硬件管理,影响查询算法的 cache behavior |
| Main Memory | 快、易失 | 查询执行、buffer pool、临时数据 |
| Flash Memory / SSD | 非易失、随机访问快 | 高性能数据库存储、热点数据层 |
| Magnetic Disk / HDD | 非易失、容量大、便宜、随机访问慢 | 大规模数据长期在线存储 |
| Optical Disk | 非易失、较慢 | 备份、归档,较少用于活跃数据库 |
| Magnetic Tape | 非易失、顺序访问、便宜 | 长期归档、备份、大规模冷数据 |
Storage Hierarchy
存储层次从上到下大致是:
cachemain memoryflash memory / SSDmagnetic diskoptical diskmagnetic tape越往上:
- 速度越快
- 单位容量越贵
- 容量通常越小
越往下:
- 速度越慢
- 单位容量越便宜
- 容量通常越大
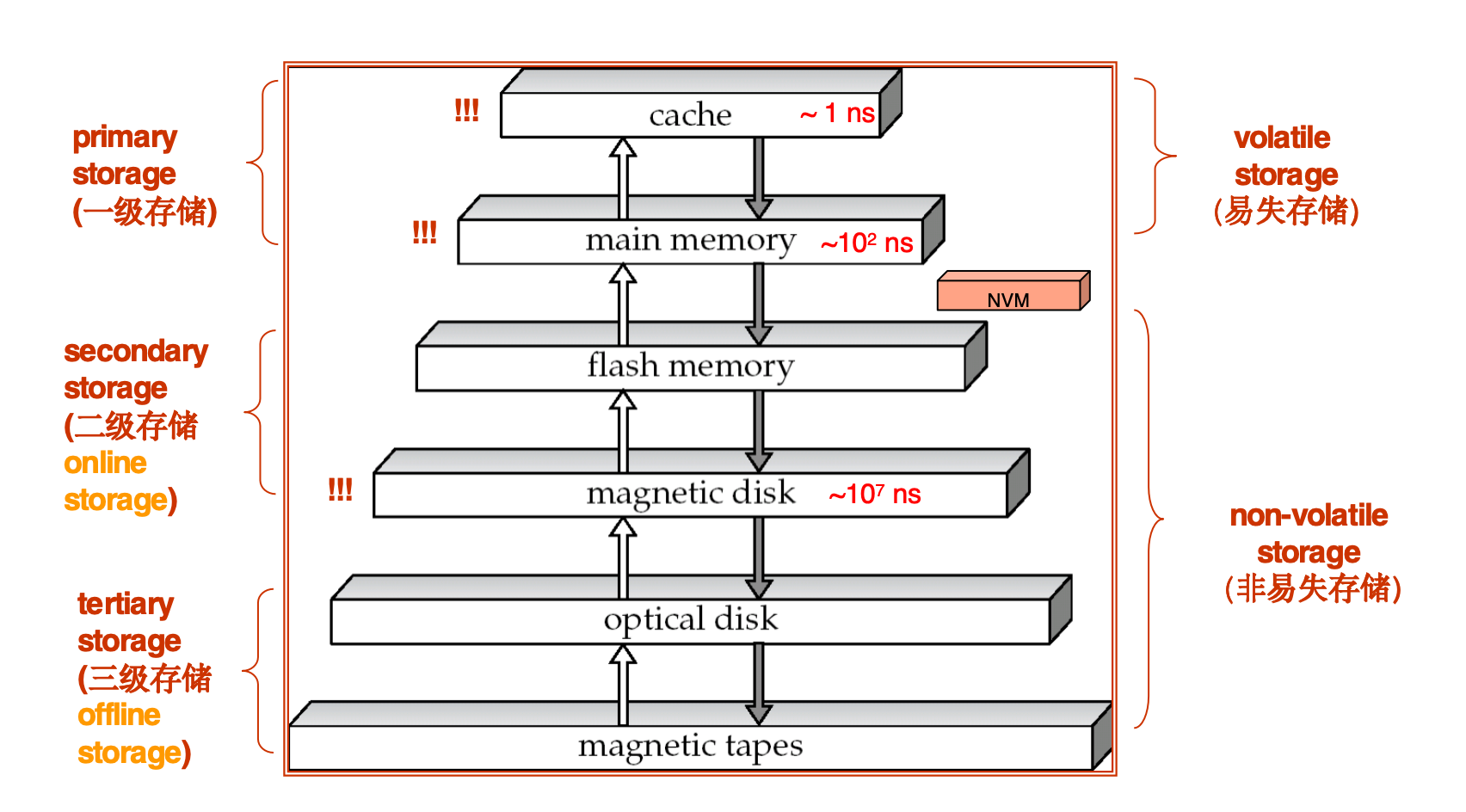
典型数量级:
- cache:约
1 ns - main memory:约
10^2 ns - magnetic disk:约
10^7 ns
这说明:磁盘访问和内存访问之间的差距达到多个数量级。
Primary Storage
Primary storage(一级存储) 包括:
- cache
- main memory
特点:
- 最快
- 通常易失
- 价格高
- 容量有限
数据库系统会尽量把热点数据放在内存 buffer 中,减少访问磁盘的次数。
Secondary Storage
Secondary storage(二级存储 / online storage) 包括:
- flash memory / SSD
- magnetic disk
特点:
- 非易失
- 可以在线访问
- 速度慢于内存,快于磁带
- 是数据库持久数据的主要存储层
数据库系统讨论的很多 I/O 代价,默认就是 secondary storage 上的 block access 代价。
Tertiary Storage
Tertiary storage(三级存储 / offline storage) 包括:
- optical disk
- magnetic tape
特点:
- 非易失
- 成本低
- 访问慢
- 适合备份、归档、冷数据
例如磁带是典型的 sequential-access storage,访问某个位置前往往要从头顺序移动,延迟可以达到几十秒甚至更长。
层次结构的本质
存储层次本质上是在做 trade-off:
- 快速设备负责当前正在处理的数据
- 慢速设备负责大容量、长期保存的数据
- 数据库通过 buffer、prefetch、索引、文件组织等机制,把慢设备的访问次数降下来
Storage Interfaces
存储设备要通过接口连接到计算机系统。接口会影响最大传输率、延迟和并发能力。
Disk Interface Standards
常见接口标准:
| 标准 | 全称 | 典型特点 |
|---|---|---|
| SATA | Serial ATA | 常见于普通磁盘和 SSD,SATA 3 最高约 6 Gbps |
| SAS | Serial Attached SCSI | 常见于服务器,SAS Version 3 约 12 Gbps |
| NVMe | Non-Volatile Memory Express | 面向 SSD,通常配合 PCIe,延迟更低、吞吐更高,课件给出约 24 Gbps |
简单理解:
- HDD 上,机械延迟常常是瓶颈
- SSD 上,设备本身很快,接口就更容易成为瓶颈
- NVMe 的意义在于更适合高并发、低延迟 SSD 访问
SAN 与 NAS
SAN
SAN(Storage Area Network) 的特点是:
- 许多磁盘通过高速网络连接到多个服务器
- 对服务器来说,它更像一个很大的块设备
- 通常会结合 RAID 提供大容量和高可靠性
适合数据库底层存储。
NAS
NAS(Network Attached Storage) 的特点是:
- 通过网络提供文件系统接口
- 使用网络文件系统协议
- 对上层暴露的是文件接口,不是裸磁盘块接口
核心区别:
- SAN 更接近 disk system interface
- NAS 更接近 file system interface
Magnetic Disks
磁盘是传统数据库系统中最重要的二级存储。
它的关键问题是:
磁盘是机械设备,访问数据前需要移动磁头并等待盘片转到正确位置。
所以磁盘随机访问很慢。
磁盘基本结构
一个磁盘通常由以下部分组成:
- platter(盘片):圆形盘片,表面覆盖磁性材料
- spindle(主轴):带动盘片高速旋转
- read-write head(读写磁头):靠近盘片表面,读写磁性编码信息
- disk arm(磁臂):带动磁头移动到不同磁道
- arm assembly(磁臂组件):多个磁头共用的机械组件
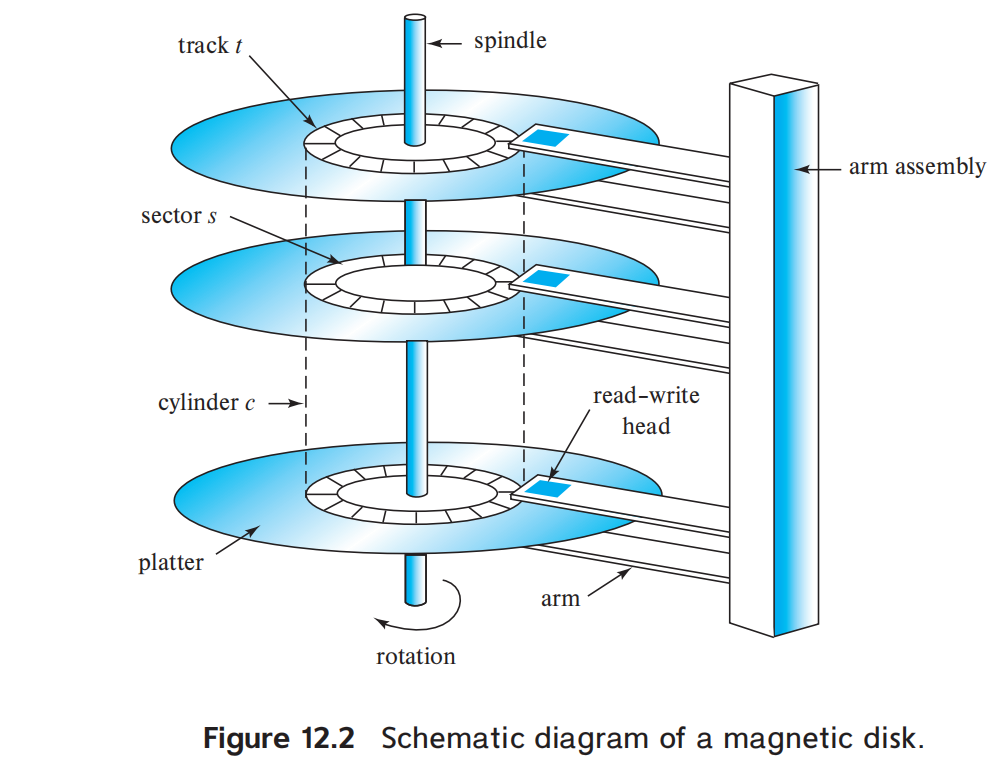
磁盘访问一个 sector 的过程:
- 磁臂移动,让磁头到达正确 track
- 盘片持续旋转
- 等目标 sector 转到磁头下方
- 磁头完成读 / 写
Track / Sector / Cylinder
Track
Track(磁道) 是盘片表面的同心圆。
典型范围:
- 每个 platter 上有
50K ~ 100K条 tracks
Sector
Sector(扇区) 是 track 上的更小单位。
它是磁盘可以读写的最小物理单位。
典型数值:
- sector size 通常是
512 bytes - 内圈每条 track 约
500 ~ 1000sectors - 外圈每条 track 约
1000 ~ 2000sectors
外圈 track 更长,所以能容纳更多 sectors。
Cylinder
Cylinder(柱面) 是所有盘片上第 i 条 track 的集合。
因为多个磁头装在同一个 arm assembly 上,所以当一个磁头移动到第 i 条 track 时,其他盘面的磁头也在各自盘面的第 i 条 track 上。
所以:
cylinder i = all ith tracks of all plattersDisk Controller
Disk controller(磁盘控制器) 是计算机系统和磁盘硬件之间的接口。
它负责:
- 接受上层 read / write sector 命令
- 控制磁臂移动到正确 track
- 触发实际读写
- 为 sector 计算并保存 checksum
- 读回数据时重新计算 checksum,检测数据是否损坏
- 写入后读回验证,确认写入成功
- remapping of bad sectors(坏扇区重映射)
坏扇区重映射的思路:
- 如果某个 sector 损坏
- controller 从预留的 spare sectors 中找一个新位置
- 把逻辑 sector 映射到新的物理 sector
- 上层仍然使用原来的逻辑地址
这说明磁盘暴露给操作系统的是抽象后的逻辑块地址,很多物理细节被 controller 隐藏了。
Performance Measures of Disks
磁盘性能通常看这些指标:
- capacity
- access time
- data-transfer rate
- IOPS
- MTTF
其中数据库最关心的是:
- 一次随机 I/O 多慢
- 顺序读写能有多快
- 设备多久可能失效
Access Time
Access time(访问时间) 指的是:
从发出读 / 写请求,到数据开始传输之间的时间。
它主要由两部分组成:
access time = seek time + rotational latency数据真正开始传输之后,还要再考虑 transfer time。
Seek Time
Seek time(寻道时间) 是磁臂移动到目标 track 所需的时间。
特点:
- 磁头移动距离越远,seek time 通常越长
- average seek time 约为 worst-case seek time 的一半
- 典型平均值:
4 ~ 10 ms
这部分是磁盘随机访问慢的主要来源之一。
Rotational Latency
Rotational latency(旋转延迟) 是等待目标 sector 转到磁头下方的时间。
特点:
- 盘片一直在旋转
- 磁头到达正确 track 后,还要等目标 sector 出现
- average latency 约为 worst-case latency 的一半
- 典型值:
4 ~ 11 ms,对应5400 ~ 15000 rpm
所以一次随机读写经常要花数毫秒到十几毫秒。
Data-transfer Rate
Data-transfer rate(数据传输率) 是数据真正开始传输后,单位时间能读 / 写多少数据。
典型范围:
- 磁盘最大传输率约
25 ~ 100 MB/s - 教材中也给出当前磁盘最大传输率可到约
50 ~ 200 MB/s - 内圈 track 因为 sector 更少,持续传输率低于外圈
需要区分:
- access time:等到数据开始传输之前的时间
- transfer rate:数据开始传输之后的速度
随机访问慢主要慢在前者。
Disk Block
Disk block(磁盘块) 是数据库和操作系统进行存储分配、数据传输的逻辑单位。
典型大小:
4 KB ~ 16 KB
block size 有权衡:
- block 小:一次只传少量数据,可能导致 I/O 次数更多
- block 大:一次读更多数据,但如果只用其中一小部分,会浪费空间和带宽
注意区分:
- sector:磁盘物理读写的最小单位
- block / page:数据库或文件系统视角下的数据传输与管理单位
Sequential Access vs Random Access
Sequential Access
Sequential access pattern(顺序访问模式):
- 连续请求相邻 disk blocks
- 第一个 block 可能需要 seek
- 后续 blocks 很可能在同一 track 或相邻 track
- 平均每个 block 分摊到的 seek / rotational latency 很小
适合:
- 全表扫描
- 顺序日志写入
- 大文件读取
- 批处理分析
Random Access
Random access pattern(随机访问模式):
- 每次请求的位置可能在磁盘任意地方
- 每次访问都可能需要 seek
- 大量时间浪费在磁臂移动和旋转等待上
适合性较差的场景:
- 没有索引的随机查找
- B+ tree 上大量不连续叶子节点访问
- 小事务频繁随机更新
结论很重要:
对 HDD 来说,顺序访问和随机访问的性能差距非常大。
IOPS
IOPS(I/O operations per second) 表示每秒能支持多少次随机 block I/O。
磁盘典型值:
- HDD random read:约
50 ~ 200 IOPS
这意味着:
- 一秒只能做几百次随机小块读写
- 一个查询如果造成大量随机 I/O,性能会迅速下降
这也是为什么数据库系统非常重视:
- buffer pool
- clustering
- index access path
- sequential scan
- prefetch
MTTF
MTTF(Mean Time To Failure,平均故障时间) 表示设备平均能连续运行多久而不发生故障。
- 普通磁盘实际使用寿命常常约
3 ~ 5 years - 新磁盘的理论 MTTF 可达
500,000 ~ 1,200,000 hours 1,200,000 hours不等于一块磁盘可以稳定用 136 年
关键例子:
如果有 1000 块相对新的磁盘,且每块磁盘 MTTF 为
1,200,000 hours,那么平均每1200 hours约有一块磁盘失败,也就是约50 days一块。
这说明:
- 单块磁盘看起来很可靠
- 大规模系统中磁盘故障会变成常态
- 需要 RAID / replication / backup 等机制保证可靠性
Flash Storage and SSD
Flash storage 和 magnetic disk 的核心差异是:
Flash 没有机械移动部件,所以随机访问延迟远低于磁盘。
但 flash 的写入和擦除机制更复杂。
NAND Flash
Flash memory 主要有两类:
- NOR flash
- NAND flash
数据库存储和 SSD 中主要使用 NAND flash。
NAND flash 的特点:
- 读通常以 page 为单位
- page 大小通常为
512 bytes ~ 4 KB - 随机读和顺序读差距比 HDD 小很多
- 一个 page 写入后不能直接覆盖
- 重写前必须先 erase
SSD
SSD(Solid State Disk) 内部使用多个 flash storage devices,但对外提供类似磁盘的 block-oriented interface。
也就是说:
- 上层仍然像访问磁盘一样读写 blocks
- 内部由 SSD controller 管理 flash page、erase block、映射表和磨损均衡
HDD 与 SSD 对比:
| 指标 | Magnetic Disk | Solid State Disk |
|---|---|---|
| Retrieve a page | 5 ~ 10 ms | 20 ~ 100 μs |
| Random access | 50 ~ 200 IOPS | reads: 10,000 IOPS; writes: 40,000 IOPS |
| Data transfer rate | 约 200 MB/s | 500 MB/s SATA,3 GB/s NVMe |
| Power consumption | higher | lower |
| Update mode | in-place | erase → rewrite |
| Reliability | MTTF 500,000 ~ 1,200,000 hours | erase blocks 约 100,000 ~ 1,000,000 次擦除 |
结论:
- SSD 随机访问远快于 HDD
- SSD 对随机读尤其友好
- SSD 写入受 erase 和 wear 限制影响
Flash 的写入问题
Flash 写入的难点来自两个限制:
- page 写入后不能直接覆盖
- erase 必须以 erase block 为单位
典型值:
- erase block 大小:
256 KB ~ 1 MB - 一个 erase block 包含约
128 ~ 256 pages - erase 操作耗时:
2 ~ 5 ms - 擦除次数上限:约
100,000 ~ 1,000,000次
所以不能把 flash 当成普通磁盘简单地原地覆盖。
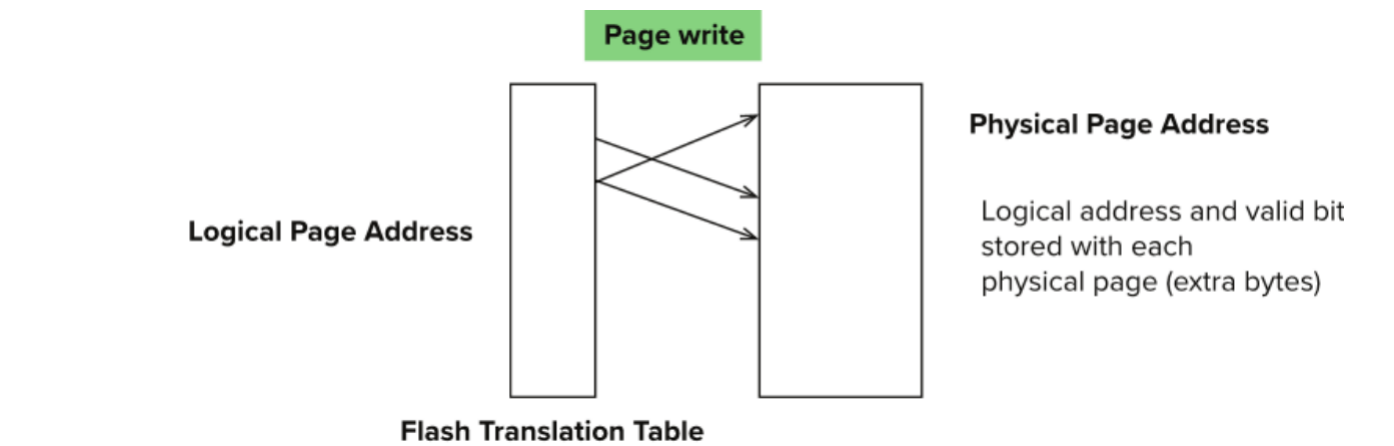
Flash Translation Layer
FTL(Flash Translation Layer) 的作用是:
把上层看到的 logical page address 映射到底层真实的 physical page address。
更新一个 logical page 时,SSD 通常不会直接覆盖原来的物理 page。
过程大致是:
- 找一个已经擦除好的空 physical page
- 把新数据写到这个位置
- 更新 logical → physical 映射
- 把旧 physical page 标记为 deleted / invalid
- 后续垃圾回收时再擦除旧 block
因此:
- 上层以为自己在原地更新
- 底层实际是在重映射
Wear Leveling
Wear leveling(磨损均衡) 的目标是:
让 erase 操作尽量均匀分布到不同 physical blocks 上。
原因是:
- 每个 erase block 的擦除次数有限
- 如果热点数据反复写在同一批 blocks 上,这些 blocks 会很快损坏
基本策略:
- 经常更新的 hot data 放到擦除次数较少的 blocks
- 很少更新的 cold data 可以放到擦除次数较多的 blocks
- controller 透明地移动数据,平衡各 blocks 的磨损
Storage Class Memory and NVM
Storage Class Memory(SCM) 指介于 main memory 和 SSD 之间的一类非易失存储。
它的目标是同时接近:
- 内存的低延迟
- 存储设备的持久性
代表技术:
- 3D-XPoint
- Intel Optane
NVM 的特点:
- non-volatile
- byte-addressable
- 读写粒度可以接近 word / byte
- 延迟远低于 SSD
- 速度可以接近 main memory
相对对比:
| 指标 | DRAM | NVM | SSD | HDD |
|---|---|---|---|---|
| Read Latency | 1x | 2 ~ 4x | 500x | 10^5x |
| Write Latency | 1x | 2 ~ 8x | 5000x | 10^5x |
| Persistence | No | Yes | Yes | Yes |
| Byte-addressable | Yes | Yes | No | No |
NVM 对数据库很重要,因为它会模糊传统界限:
- 内存不一定易失
- 存储不一定只能 block-addressable
- recovery、buffer manager、logging 的设计都可能受到影响
RAID
RAID 在计组已经学过。
为什么需要 RAID
当系统只有一块磁盘时,磁盘失败就可能导致数据丢失。
当系统有很多块磁盘时,问题更严重:
单块磁盘失败概率看起来很低,但只要磁盘数量足够多,系统中“某块磁盘失败”的概率就会变高。
Example:
- 假设一块磁盘 MTTF 为
100,000 hours - 如果系统有
100块磁盘 - 那么某块磁盘失败的平均时间约为
100,000 / 100 = 1000 hours - 也就是约
42 days
所以大规模数据库系统必须考虑磁盘失败。
RAID(Redundant Arrays of Independent Disks) 的目标有两个:
- 通过多磁盘并行提高性能
- 通过冗余信息提高可靠性
Mirroring
Mirroring(镜像) 是最简单的冗余方式。
做法:
- 每份数据写到两块磁盘
- 一个 logical disk 对应两个 physical disks
- 任何写操作都写两份
- 一个盘坏了,可以从另一个盘读
优点:
- 可靠性高
- 读请求可以分散到两个盘上
- 写性能相对好,逻辑简单
缺点:
- 存储成本高
- 需要 2 倍磁盘空间
Example:
- 单盘 MTTF:
100,000 hours - 平均修复时间:
10 hours - 镜像系统的 mean time to data loss 可达到约
500 × 10^6 hours
这说明 mirroring 能显著降低数据丢失概率。
Striping
Striping(条带化) 是把数据分散到多个磁盘上。
目标是利用并行性。
Bit-level striping
把每个 byte 的不同 bit 放到不同磁盘上。
例如 8 块磁盘:
- 第
i位写到第i块磁盘
缺点:
- 每次访问都要所有磁盘参与
- 小访问并发能力差
- 实际系统很少使用
Block-level striping
把不同 blocks 分配到不同磁盘上。
假设有 n 块磁盘,logical block i 放到:
disk = (i mod n) + 1physical block = floor(i / n)例如 8 块磁盘:
- logical block 0 → disk 1 的 physical block 0
- logical block 11 → disk 4 的 physical block 1
优点:
- 大文件读取时可以多个磁盘并行
- 小 block 读取时只占用一块磁盘,其余磁盘还能处理其他请求
- 实际系统中更常用
Parity
Parity(奇偶校验) 用较少的冗余空间提供故障恢复能力。
基本思想:
- 对一组 data blocks 计算 XOR
- 把 XOR 结果作为 parity block 保存
- 任意一个 data block 丢失后,可以用剩余 blocks 和 parity block 通过 XOR 恢复
形式上:
P = B1 XOR B2 XOR ... XOR Bn如果 B2 丢失:
B2 = P XOR B1 XOR B3 XOR ... XOR Bn代价:
- 写入某个 block 后,对应 parity 也要更新
- 小随机写会带来额外读写开销
常见 RAID Levels
| RAID Level | 核心机制 | 冗余 | 特点 | 适用场景 |
|---|---|---|---|---|
| RAID 0 | block striping | 无 | 性能高,但没有容错 | 临时数据、可丢数据、高性能场景 |
| RAID 1 | mirroring + striping | 镜像 | 可靠性高,读性能好,写性能较好,空间成本高 | 数据库日志、关键数据、中等容量高 I/O |
| RAID 5 | block-level striping + distributed parity | 分布式 parity | 空间开销低,读性能好,小随机写开销大 | 读多写少的数据 |
| RAID 6 | 类似 RAID 5,但有 P + Q redundancy | 可容忍两盘失败 | 可靠性更高,空间和写入开销更大 | 数据安全要求高的大容量系统 |
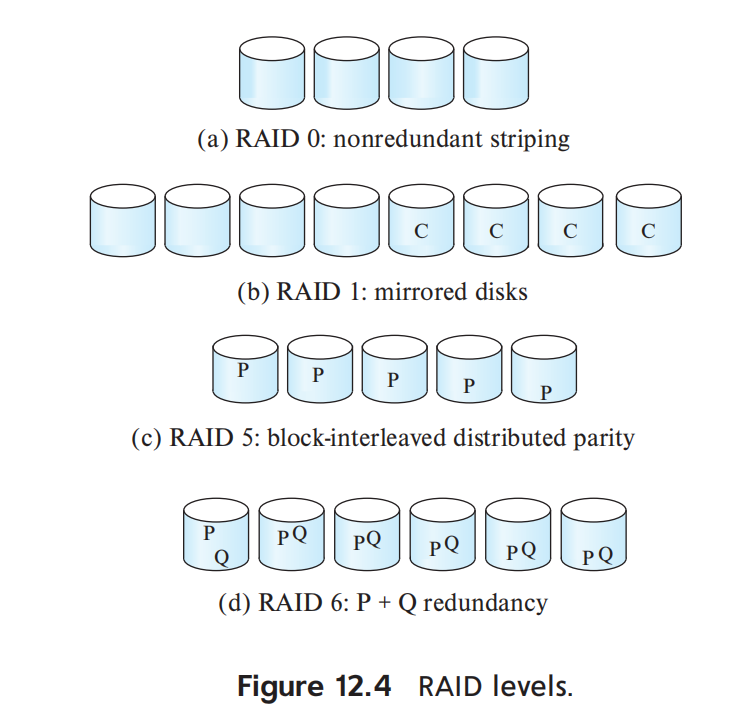
RAID 0
RAID 0 只有 striping,没有冗余。
结果:
- 性能高
- 任意一块磁盘失败都可能造成数据丢失
所以 RAID 0 不适合存关键数据。
RAID 1
RAID 1 使用 mirroring。
结果:
- 任意一个副本损坏,另一个副本仍可使用
- 读可以从两个副本分摊
- 写必须写两个副本
在数据库中,RAID 1 常用于 log files,因为日志写入对可靠性和写延迟很敏感。
RAID 5
RAID 5 使用 distributed parity。
特点:
- parity block 分散在不同磁盘上
- 避免单独 parity disk 成为瓶颈
- 可容忍一块磁盘失败
小随机写代价较高。
一次小 block 更新通常需要:
- 读旧 data block
- 读旧 parity block
- 写新 data block
- 写新 parity block
也就是常说的:
RAID 5 small random write = 2 reads + 2 writes所以 RAID 5 更适合读多写少、顺序写较多的场景。
RAID 6
RAID 6 使用 P + Q redundancy,可以容忍两块磁盘失败。
它适合:
- 大容量磁盘阵列
- 重建时间很长的系统
- 不能接受单盘故障期间再出现 latent sector failure 的场景
RAID 的工程问题
Rebuild
当一块盘坏了,需要用剩余磁盘重建数据。
不同 RAID level 的 rebuild 成本不同:
- RAID 1:从镜像盘复制即可
- RAID 5 / 6:需要读取其他磁盘并重新计算数据
rebuild 时间越长,系统处于降级状态的时间越长,风险越高。
Software RAID vs Hardware RAID
Software RAID:
- 由操作系统 / 软件管理 RAID
- 成本低
- 故障恢复和一致性检查可能更慢
Hardware RAID:
- 专用 RAID controller 管理
- 常有 non-volatile RAM 记录未完成写入
- 可以更好处理断电、重建、重排写入等问题
Scrubbing
Scrubbing 是 RAID controller 在空闲时主动读取所有 sectors,检查是否有 latent failure / bit rot。
如果发现某个 sector 读不出来:
- 用 RAID 冗余信息恢复数据
- 写回到正常 sector
- 必要时触发坏扇区重映射
Hot Swapping
Hot swapping(热插拔) 指:
- 不关机替换故障磁盘
- RAID controller 自动检测新盘
- 自动开始重建旧盘数据
这可以降低 mean time to repair,从而降低数据丢失概率。
Optimization of Disk-Block Access
磁盘优化的核心目标是:
尽量减少随机 I/O,尽量把访问变成顺序 I/O,尽量减少磁臂移动和等待时间。
Buffering
Buffering 指把读入的 disk blocks 暂存在内存 buffer 中。
好处:
- 以后再次访问同一 block 时,不需要重新读磁盘
- 热点数据可以长期留在内存中
- 对数据库性能非常关键
数据库系统通常有自己的 buffer pool,因为数据库比操作系统更清楚哪些 pages 重要。
Read-ahead / Prefetch
Read-ahead(预读)/ Prefetch(预取) 指:
当系统读一个 block 时,顺便把后续连续 blocks 也读入内存。
适合:
- 顺序扫描
- 连续文件读取
- 大范围查询
不适合:
- 完全随机访问
例子:
- 查询执行器准备做 full table scan
- 系统读第一个 block 时预取后续 blocks
- 后面扫描时数据已经在内存中
这可以降低每个 block 分摊到的 seek / rotational latency。
Disk-arm Scheduling
Disk-arm scheduling 的目标是重排多个磁盘请求,让磁臂移动距离更小。
典型算法:elevator algorithm(电梯算法)。
思路类似电梯:
- 当前磁臂沿一个方向移动
- 遇到有请求的 track 就服务
- 直到该方向没有更远请求
- 再反向移动并服务请求
这样避免磁臂在内外圈之间来回乱跳。
File Organization
文件组织的目标是让数据布局符合访问模式。
如果一个文件经常被顺序访问,就应该尽可能让它的 blocks 连续存放。
Extent
Extent(盘区) 是连续 blocks 的一组分配单位。
操作系统常常以 extent 为单位给文件分配一组连续 blocks。
好处:
- 顺序访问时,一个 extent 内部可以连续读取
- 每个 extent 只需要较少 seek
- 比完全随机分配 blocks 高效很多
Fragmentation
Fragmentation(碎片化) 指文件 blocks 分散在磁盘不同位置。
原因:
- 文件多次小规模 append
- 空闲 blocks 本身分散
- 新文件只能被分散分配
后果:
- 顺序访问时也需要频繁 seek
- 性能下降
解决:
- defragmentation(碎片整理)
- backup + restore,使文件重新连续布局
Non-volatile Write Buffers
Non-volatile write buffer(非易失性写缓存) 用来加速磁盘写入。
基本过程:
- 数据库请求写一个 block
- controller 先把 block 写到非易失 buffer
- 立刻通知上层“写入成功”
- 之后 controller 再选择合适时机写入真正磁盘位置
好处:
- 数据已经进入非易失介质,断电也不会丢
- 上层不必等机械磁盘完成实际写入
- controller 可以重排写入顺序,减少 arm movement
常见实现:
- battery-backed RAM
- flash memory
- RAID controller 上的 NVRAM
注意:
- 普通易失内存不能随意用来确认持久写入
- 数据库 recovery 依赖写入顺序和持久性保证
Log Disk
Log disk(日志磁盘) 是专门用于写 block updates sequential log 的磁盘。
它和 non-volatile write buffer 的作用类似:
- 先把更新顺序写入日志磁盘
- 因为是顺序写,所以不需要频繁 seek
- 写入很快
- 不需要特殊 NVRAM 硬件
数据库中的日志写入天然适合顺序 I/O。
这也解释了为什么数据库 recovery 系统非常强调 log:
- 随机更新数据页很慢
- 顺序写日志相对快
- 先保证日志持久,再慢慢把数据页刷回磁盘