

概述
本章围绕指令级并行(ILP)展开,先区分 dependence 与 hazard,说明为什么流水线会被依赖关系限制。随后用 Scoreboard 与 Tomasulo 展示动态调度如何实现乱序执行,并通过保留站与重命名消除 WAR/WAW;再引入 ROB,把“乱序执行 / 顺序提交”串成一条主线,解释精确异常与推测执行的关系。最后讨论进一步提高 ILP 的多发射技术:比较 Superscalar、VLIW 与 Superpipelining,并结合双发射动态调度、VLIW 循环展开和 MIPS R4000 分析它们的性能收益与限制。
目录
- 概述
- 目录
- Review: Dependences and Hazards
- Dynamic Scheduling
- Hardware-Based Speculation
- Exploiting ILP Using Multiple Issue and Static Scheduling
Review: Dependences and Hazards
dependence 和 hazard 的区别
Dependence(相关性 / 依赖关系) 是程序自身的属性。只要程序写出来,指令之间是否有数据传递、是否复用同一个寄存器名称、是否受分支控制,这些关系就已经存在。
Hazard(流水线冒险) 是流水线组织方式的属性。程序中有 dependence,不一定会导致 hazard;是否形成 hazard,取决于流水线是否能通过 forwarding、stall、renaming、prediction 等机制处理它。
Dependences are a property of programs.
Hazards are properties of the pipeline organization.
- dependence 描述“程序中有什么关系”;
- hazard 描述“某种硬件实现会不会被这种关系卡住”。
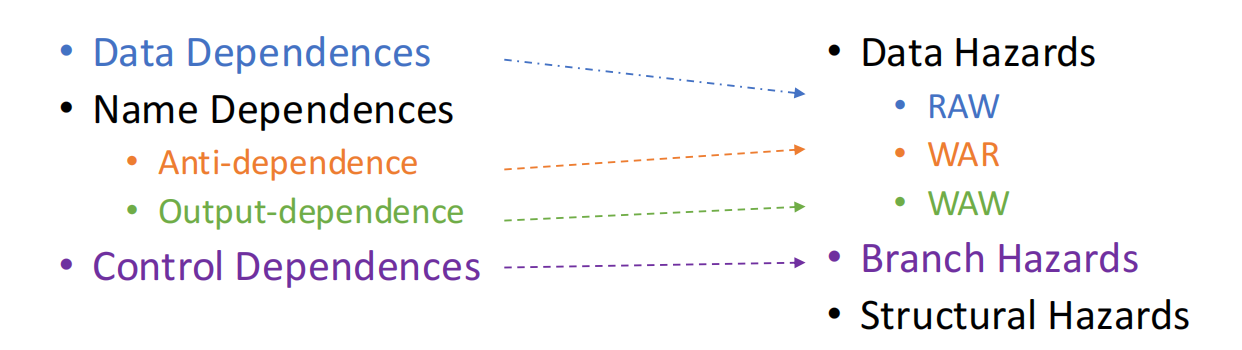
三类主要 dependence
Data Dependence
data dependence(数据相关) 指后面的指令真正需要前面指令产生的数据。
典型形式:
FLD F0, 0(R1)FADD.D F4, F0, F2第二条指令要读取 F0,而 F0 由第一条指令产生。这里存在真实的数据流动。
对应的 hazard 是:
- RAW(Read After Write)
- 后读前写
- 后面的读必须等前面的写产生结果
RAW 是真实数据相关,不能靠简单改寄存器名字消除。常见解决方式是:
- forwarding / bypassing;
- stall / bubble;
- 动态调度中等待操作数 ready。
Name Dependence
name dependence(名相关) 指两条指令复用了同一个寄存器名字,但它们之间没有真实数据传递。
它分成两类。
第一类是 anti-dependence(反相关),对应 WAR(Write After Read):
FDIV.D F2, F6, F4FADD.D F6, F0, F12第一条指令要读 F6,第二条指令要写 F6。如果第二条在第一条读走 F6 前先写了 F6,第一条会读到错误值。
第二类是 output-dependence(输出相关),对应 WAW(Write After Write):
FDIV.D F2, F0, F4FSUB.D F2, F6, F14两条指令都写 F2。如果后写和前写的顺序被打乱,最终 F2 的值可能错误。
name dependence 的本质是“名字冲突”。它可以通过 register renaming(寄存器重命名) 消除。
TIPRAW 代表真实的数据流动,不能随便改名消掉。
WAR / WAW 多数来自寄存器名字复用,可以通过重命名解决。
Control Dependence
control dependence(控制相关) 来自分支指令。
例如:
if (p1) { Statement 1;}Statement;if (p2) { Statement 2;}某些语句是否执行,取决于前面的分支条件。流水线中对应的问题是 branch hazard / control hazard。
三类主要 hazard
流水线中常见 hazard 包括:
-
Structural hazard
- 所需硬件资源正忙;
- 例如两个 load 同时争用同一个访存 / 整数功能部件。
-
Data hazard
- 需要等待前面指令的数据读写;
- 包括 RAW / WAR / WAW。
-
Control hazard
- 下一条取什么指令取决于分支结果;
- 需要分支预测、延迟槽或 stall 等机制处理。
Example
slides 给出的复习例子是:
FADD.D R1, R2, R4FADD.D R2, R1, 1FSUB.D R1, R4, R5记三条指令为 I1 / I2 / I3。
| 指令关系 | hazard 类型 | 涉及寄存器 | 说明 |
|---|---|---|---|
I1 -> I2 | RAW | R1 | I1 写 R1,I2 读 R1 |
I1 -> I2 | WAR | R2 | I1 读 R2,I2 写 R2 |
I2 -> I3 | WAR | R1 | I2 读 R1,I3 写 R1 |
I1 -> I3 | WAW | R1 | I1 和 I3 都写 R1 |
处理思路:
I1 -> I2的 RAW 是真实数据相关,必须保留;R2上的 WAR 可以通过重命名消除;R1上的 WAW / WAR 也可以通过重命名消除。
一种示意性重命名写法是:
FADD.D R1, R2, R4FADD.D R3, R1, 1FSUB.D R6, R4, R5这里保留 I1 -> I2 对 R1 的真实数据传递,同时把无真实数据传递的寄存器名字冲突避开。
TIP这里的重命名只是在说明思想。真实处理器里会维护 architectural register 和 physical register 的映射,保证最终对外表现仍然符合程序原始语义。
Dynamic Scheduling
顺序流水线的限制
简单流水线通常采用:
- in-order issue;
- in-order execution。
也就是说,指令按照程序顺序进入流水线;如果某条指令因为数据相关或结构冲突停住,后面的指令也可能被卡住。
slides 中给出的例子是:
FDIV.D F4, F0, F2FSUB.D F10, F4, F6FADD.D F12, F6, F14分析:
FSUB.D依赖FDIV.D产生的F4;FDIV.D是长延迟指令,FSUB.D必须等待;FADD.D与前两条指令没有真实数据相关;- 但在顺序流水线中,
FADD.D仍然会被前面的FSUB.D挡住。
这就造成了功能部件浪费。后面的短指令本来可以先执行,却因为程序顺序被迫等待。
动态调度的基本思想
dynamic scheduling(动态调度) 的核心思想是:
程序运行过程中,由 CPU 硬件动态判断每条指令是否可以执行;只要操作数 ready 且功能部件可用,就允许它先执行。
对应实现方式是:
- in-order issue:按程序顺序进入调度结构;
- out-of-order execution:进入后,谁先满足执行条件谁先执行;
- out-of-order completion:短指令可能先完成。
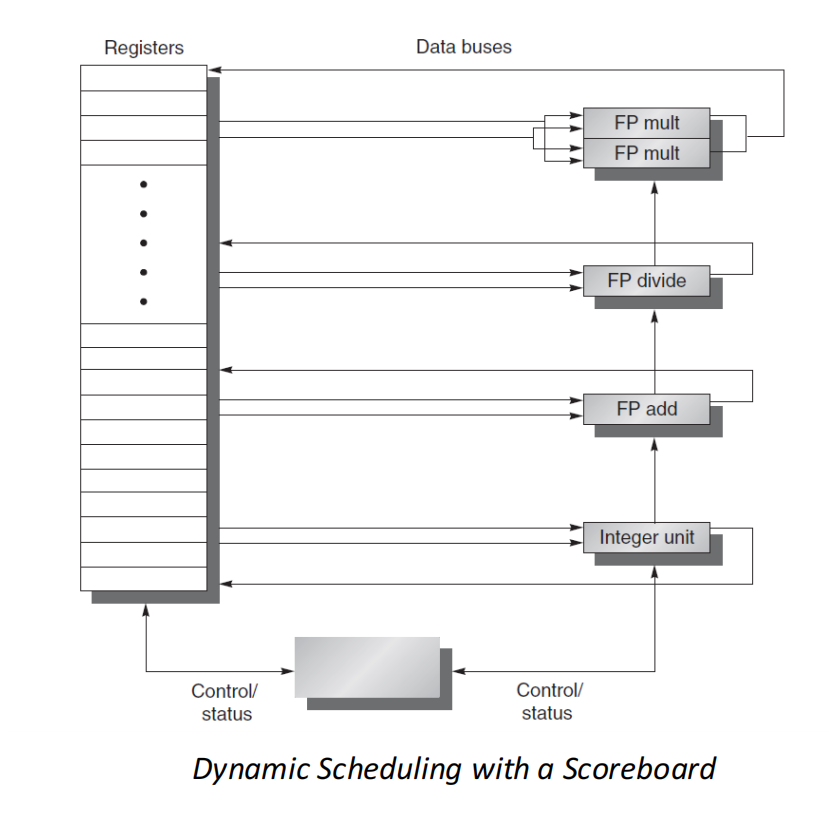
这样可以提升功能部件利用率,减少无谓等待。
乱序执行带来的新问题
在五级整数流水线中,WAR / WAW 通常不会真正形成问题,因为读寄存器和写寄存器的位置固定,且指令顺序推进。
但乱序执行后,后面的指令可能先执行、先写回,因此会出现:
- WAR hazard:后面的写覆盖了前面尚未读取的值;
- WAW hazard:后面的写先于前面的写完成,破坏最终结果顺序。
例如:
FDIV.D F10, F0, F2FSUB.D F10, F4, F6FADD.D F6, F8, F14这里存在:
FDIV.D和FSUB.D对F10的 WAW;FSUB.D与FADD.D对F6的 WAR。
所以乱序执行必须解决两个问题:
- 尽可能让独立指令提前执行;
- 保证执行结果仍然和原程序语义一致。
Scoreboard 和 Tomasulo 都是在解决这个问题。
Scoreboard Algorithm
Example
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F6, F2FDIV.D F10, F0, F6FADD.D F6, F8, F2基本思想
Scoreboard algorithm(记分牌算法) 是早期用于动态调度和乱序执行的经典方法。
它的直觉很简单:
- 用一个中心化的记分牌记录当前所有功能部件、寄存器、指令的状态;
- 每条指令进入时,先检查是否有结构冲突;
- 操作数没有 ready 时先等待;
- 操作数 ready 后就可以执行;
- 写回前还要检查是否会破坏前面指令尚未完成的读操作。
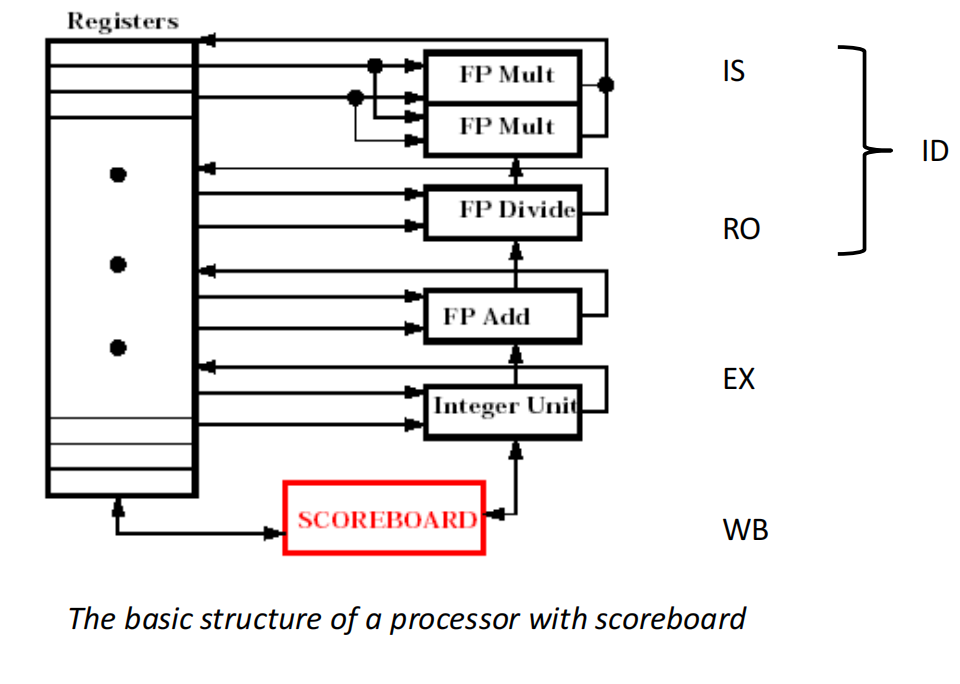
Scoreboard 的目标是:允许部分指令乱序执行,同时由硬件检测 hazard,保证结果正确。
从 ID 拆成 IS 和 RO
在简单五级流水线中,ID 阶段通常同时完成:
- decode;
- structural hazard 检查;
- data hazard 检查;
- register read。
如果所有检查都放在 ID 中,那么前面一条指令卡住时,后面的指令没有机会进入不同功能部件等待。
为了支持乱序执行,需要把 ID 拆成两个阶段:
-
Issue(IS)
- decode instruction;
- 检查 structural hazard;
- 按程序顺序 issue;
- 如果目标功能部件忙,则当前指令不能进入,后续指令也不能跳过它。
-
Read Operands(RO)
- 等待数据 hazard 消失;
- 操作数 ready 后读取操作数;
- 可以乱序发生。
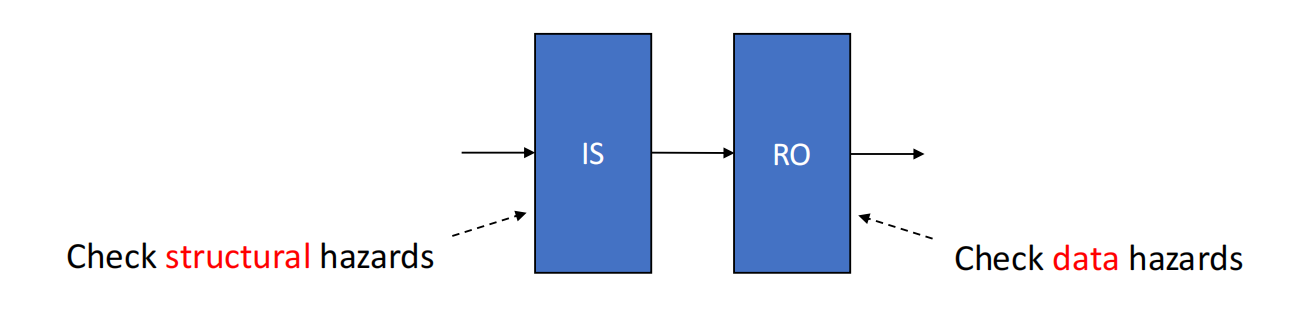
TIPIS 阶段仍然是顺序的。
真正允许乱序的是 RO / EX 之后的推进过程。
Scoreboard 的四个阶段
Scoreboard 中每条指令大致经过四个阶段:
| 阶段 | 含义 | 主要检查 |
|---|---|---|
| IS | Issue | 功能部件是否空闲;是否能占用对应记录项 |
| RO | Read Operands | 源操作数是否 ready;RAW 是否已经消除 |
| EX | Execute | 按功能部件延迟执行 |
| WB | Write Back | 是否存在 WAR;能否安全写回结果 |
IS:检查结构冲突
IS 阶段主要看目标功能部件是否可用。
若两个 FLD 都需要使用 Integer / Load 部件,而该结构里只有一个 Integer 部件。因此第一条 load 占用该部件时,第二条 load 不能在第 2 拍 issue,只能等第一条 load 完成释放后再进入。
RO:等待操作数 ready
RO 阶段主要看源操作数是否已经可用。
例如:
FMUL.D F0, F2, F4它要读 F2。如果 F2 由前面的 FLD F2, 45(R3) 产生,那么它必须等 F2 写回后才能 RO。
EX:执行
EX 阶段按照功能部件所需周期执行。
假设:
- Load:1 cycle;
- Add / Sub:2 cycles;
- Multiply:10 cycles;
- Divide:40 cycles。
不同功能部件可以并行工作,因此短指令可能先于长指令执行完。
WB:写回并检查 WAR
WB 阶段不能只看自己是否执行完,还要检查是否会破坏前面指令尚未读取的源寄存器。
例如:
FDIV.D F10, F0, F6FADD.D F6, F8, F2FDIV.D 需要读取 F6,FADD.D 要写 F6。如果 FADD.D 在 FDIV.D 读取 F6 前写回,就会形成 WAR。Scoreboard 没有做寄存器重命名,只能让 FADD.D 等到 FDIV.D 完成 RO 后再 WB。
三张状态表
Scoreboard 需要维护三类信息。
Instruction Status
记录每条指令到了哪个阶段。
| Instruction | IS | RO | EX | WB |
|---|---|---|---|---|
FLD F6, 34(R2) | √ | √ | √ | √ |
FLD F2, 45(R3) | √ | √ | √ | |
FMUL.D F0, F2, F4 | √ | |||
FSUB.D F8, F6, F2 | √ | |||
FDIV.D F10, F0, F6 | √ | |||
FADD.D F6, F8, F2 |
这张表主要帮助我们理解当前每条指令的进度。
Function Component Status
记录每个功能部件当前是否忙、正在执行什么操作、目标寄存器和源寄存器是谁、操作数是否可读。
字段含义如下:
| 字段 | 含义 |
|---|---|
| Busy | 当前功能部件是否被占用 |
| Op | 当前操作类型,如 Load / MUL / SUB / DIV |
| Fi | 目标寄存器 |
| Fj / Fk | 源寄存器 |
| Qj / Qk | 如果源操作数还没 ready,记录将产生它的功能部件 |
| Rj / Rk | 源操作数是否 ready 且尚未被读取 |
| Name | Busy | Op | Fi | Fj | Fk | Qj | Qk | Rj | Rk |
|---|---|---|---|---|---|---|---|---|---|
| Integer | yes | Load | F2 | R3 | no | ||||
| Mult1 | yes | MUL | F0 | F2 | F4 | Integer | no | yes | |
| Mult2 | no | ||||||||
| Add | yes | SUB | F8 | F6 | F2 | Integer | yes | no | |
| Divide | yes | DIV | F10 | F0 | F6 | Mult1 | no | yes |
Rj / Rk :
yes:operand ready,但还没有读;no且Qj/Qk = null:operand 已经读走;no且Qj/Qk != null:operand 还没有 ready,正在等待某个功能部件产生。
Register Status
记录每个寄存器当前是否有尚未写回的生产者。
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … | F30 |
|---|---|---|---|---|---|---|---|---|
| Qi | Mult1 | Integer | Add | Divide |
含义:
Qi = Mult1:说明F0将由Mult1产生;Qi = Integer:说明F2将由 Integer / Load 部件产生;- 空白:说明当前没有未完成指令要写这个寄存器。
这张表用来判断 RAW 和 WAW,也帮助后续指令知道自己要等谁。
上面的三张表对应第 1 个时刻(第二条 FLD 还没写回)。下面补上另外两个关键时刻,便于对照指令推进。
关键时刻 2:FMUL.D 准备写回
此时 FMUL.D 已完成 EX 但尚未 WB,FDIV.D 仍在等待 F0,FADD.D 因 WAR 暂停写回。
| Instruction | IS | RO | EX | WB |
|---|---|---|---|---|
FLD F6, 34(R2) | √ | √ | √ | √ |
FLD F2, 45(R3) | √ | √ | √ | √ |
FMUL.D F0, F2, F4 | √ | √ | √ | |
FSUB.D F8, F6, F2 | √ | √ | √ | √ |
FDIV.D F10, F0, F6 | √ | |||
FADD.D F6, F8, F2 | √ | √ | √ |
| Name | Busy | Op | Fi | Fj | Fk | Qj | Qk | Rj | Rk |
|---|---|---|---|---|---|---|---|---|---|
| Integer | no | ||||||||
| Mult1 | yes | MUL | F0 | F2 | F4 | no | no | ||
| Mult2 | no | ||||||||
| Add | yes | ADD | F6 | F8 | F2 | no | no | ||
| Divide | yes | DIV | F10 | F0 | F6 | Mult1 | no | yes |
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … | F30 |
|---|---|---|---|---|---|---|---|---|
| Qi | Mult1 | Add | Divide |
关键时刻 3:FDIV.D 准备写回
此时除法部件仍忙,其他功能部件已空闲,寄存器状态只剩 F10 由 Divide 产生。
| Instruction | IS | RO | EX | WB |
|---|---|---|---|---|
FLD F6, 34(R2) | √ | √ | √ | √ |
FLD F2, 45(R3) | √ | √ | √ | √ |
FMUL.D F0, F2, F4 | √ | √ | √ | √ |
FSUB.D F8, F6, F2 | √ | √ | √ | √ |
FDIV.D F10, F0, F6 | √ | √ | √ | |
FADD.D F6, F8, F2 | √ | √ | √ | √ |
| Name | Busy | Op | Fi | Fj | Fk | Qj | Qk | Rj | Rk |
|---|---|---|---|---|---|---|---|---|---|
| Integer | no | ||||||||
| Mult1 | no | ||||||||
| Mult2 | no | ||||||||
| Add | no | ||||||||
| Divide | yes | DIV | F10 | F0 | F6 | no | no |
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … | F30 |
|---|---|---|---|---|---|---|---|---|
| Qi | Divide |
Scoreboard 的局限
Scoreboard 可以实现乱序执行,但它的处理方式偏保守。
它能做到:
- 检测 structural hazard;
- 检测 RAW;
- 检测 WAR / WAW;
- 允许无关指令提前执行。
但它还做不到:
- 通过硬件寄存器重命名消除 WAR / WAW;
- 从根本上解决 name dependence 带来的等待;
- 自然保证精确异常。
因此当它发现 WAR / WAW 时,通常只能等待。
后续 Tomasulo 算法会引入 reservation station、CDB、硬件寄存器重命名,用更主动的方式减少这些等待。
Scoreboard 时序填写
条件
指令序列为:
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F2, F6FDIV.D F10, F0, F6FADD.D F6, F8, F2执行延迟假设为:
| 指令类型 | EX 延迟 |
|---|---|
| LD | 1 cycle |
| ADD / SUB | 2 cycles |
| MUL | 10 cycles |
| DIV | 40 cycles |
要求填写每条指令的:
- IS;
- RO;
- EX;
- WB。
答案
| Instruction | IS | RO | EX | WB |
|---|---|---|---|---|
FLD F6, 34(R2) | 1 | 2 | 3 | 4 |
FLD F2, 45(R3) | 5 | 6 | 7 | 8 |
FMUL.D F0, F2, F4 | 6 | 9 | 10–19 | 20 |
FSUB.D F8, F2, F6 | 7 | 9 | 10–11 | 12 |
FDIV.D F10, F0, F6 | 8 | 21 | 22–61 | 62 |
FADD.D F6, F8, F2 | 13 | 14 | 15–16 | 22 |
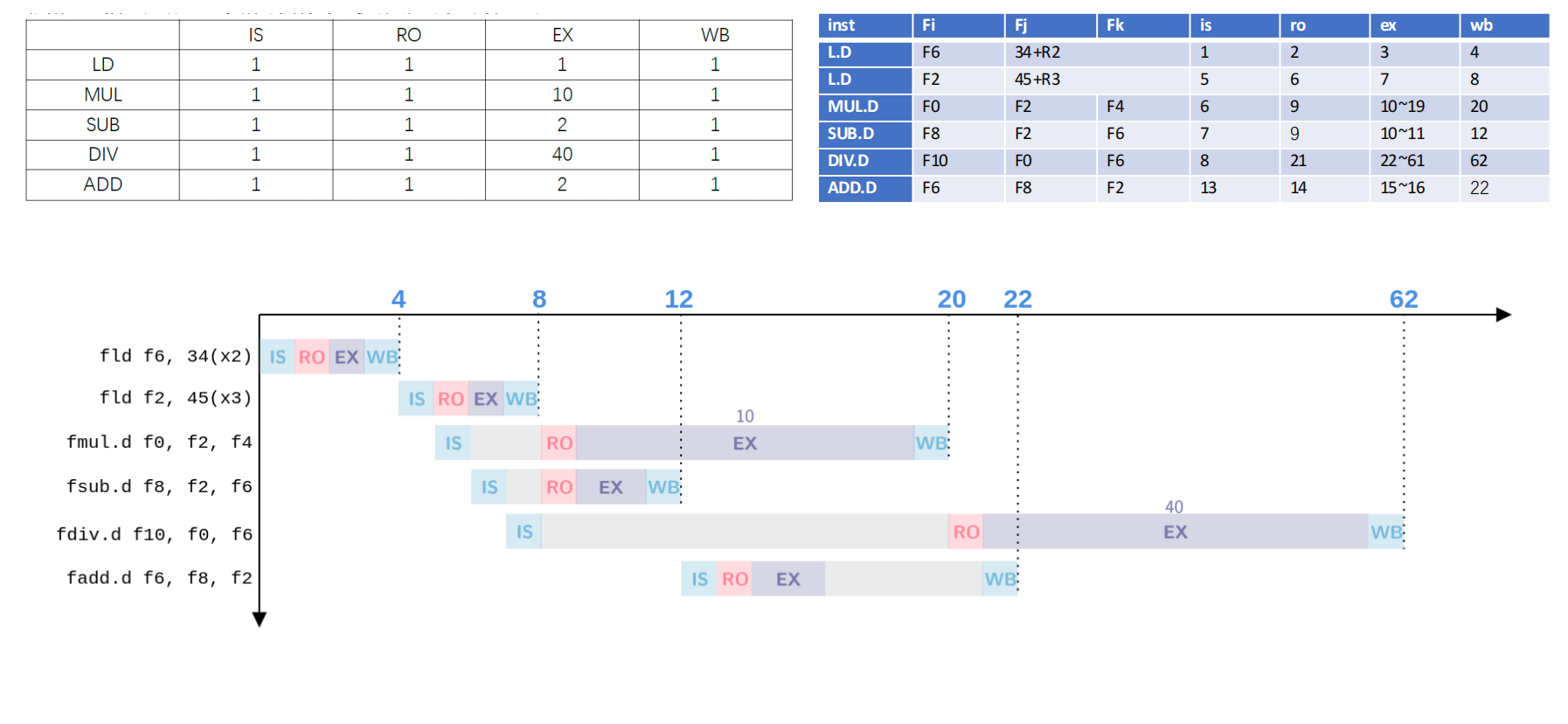
FLD F6, 34(R2)
第一条指令直接进入:
- IS = 1;
- RO = 2;
- EX = 3;
- WB = 4。
它占用 Integer / Load 功能部件,直到第 4 拍写回后释放。
FLD F2, 45(R3)
第二条也是 load,也要使用同一个 Integer / Load 功能部件。
第一条 load 在第 1 到第 4 拍占用该部件,所以第二条不能在第 2 拍 issue。
因此:
- IS = 5;
- RO = 6;
- EX = 7;
- WB = 8。
TIP第二条
FLD不能在第 2 拍 IS。
原因在于 Integer / Load 功能部件仍被第一条FLD占用,和数据 ready 无关。
FMUL.D F0, F2, F4
这条指令使用乘法部件。
- 第 6 拍可以 IS,因为它前面的第二条 load 已经在第 5 拍 issue,且乘法部件空闲;
- 但它要读
F2,而F2由第二条FLD产生; - 第二条
FLD在第 8 拍 WB,因此FMUL.D第 9 拍才能 RO; - 乘法执行 10 拍,即 EX = 10–19;
- 第 20 拍 WB。
因此:
IS = 6, RO = 9, EX = 10–19, WB = 20FSUB.D F8, F2, F6
这条指令使用加法 / 减法部件。
- 第 7 拍可以 IS,因为 Add 部件空闲;
- 它需要
F2和F6; F6已经由第一条 load 在第 4 拍写回;F2由第二条 load 在第 8 拍写回;- 所以第 9 拍可以 RO;
- 减法执行 2 拍,即 EX = 10–11;
- 第 12 拍 WB。
因此:
IS = 7, RO = 9, EX = 10–11, WB = 12注意:它和 FMUL.D 可以同在第 9 拍 RO,因为它们进入了不同功能部件,且操作数都已经 ready。
FDIV.D F10, F0, F6
这条指令使用除法部件。
- 第 8 拍可以 IS,因为 Divide 部件空闲;
- 它需要
F0和F6; F6已经 ready;F0由FMUL.D产生,FMUL.D第 20 拍 WB;- 因此
FDIV.D第 21 拍才能 RO; - 除法执行 40 拍,即 EX = 22–61;
- 第 62 拍 WB。
因此:
IS = 8, RO = 21, EX = 22–61, WB = 62FADD.D F6, F8, F2
这条指令使用 Add 部件。
- Add 部件被
FSUB.D占用到第 12 拍; - 所以它第 13 拍才能 IS;
F8由FSUB.D第 12 拍产生,F2已经 ready;- 因此第 14 拍 RO;
- 加法执行 2 拍,即 EX = 15–16;
- 按执行结果看,第 17 拍之后它已经可以写回。
但它的目标寄存器是 F6,而前面的:
FDIV.D F10, F0, F6还没有读取 F6。FDIV.D 在第 21 拍 RO,读走 F6 后,FADD.D 才能安全写 F6。
因此 FADD.D 的 WB 被推迟到第 22 拍。
IS = 13, RO = 14, EX = 15–16, WB = 22Scoreboard 遇到 WAR 时只能等待。
Tomasulo’s Approach
Scoreboard 可以检测 RAW / WAR / WAW,并让一部分指令乱序执行。它的问题是:
- 对真实数据相关 RAW,只能等前面结果产生,这个必须保留;
- 对 name dependence 引起的 WAR / WAW,也只能检测并等待;
- 它没有真正“消除”这些名字相关带来的冲突。
Tomasulo 算法的核心改进是:在硬件中做 register renaming(寄存器重命名)。
也就是说,当程序中的两个指令只是碰巧用了同一个寄存器名字,但实际上没有真实数据传递时,硬件自动给它们换一个内部名字。这样就可以保留真正的数据依赖,同时消除 WAR / WAW。
从 Scoreboard 到 Tomasulo
回顾一个 name dependence 的例子:
FDIV.D F0, F2, F4FADD.D F6, F0, F8FSD F6, 0(R1)FSUB.D F8, F10, F14FMUL.D F6, F10, F8这里存在两个名字相关:
F6被FADD.D写,又被后面的FMUL.D写,容易形成 WAW;F8被前面的FADD.D读,又被FSUB.D写,容易形成 WAR。
如果手工重命名,可以改成:
FDIV.D F0, F2, F4FADD.D S, F0, F8FSD S, 0(R1)FSUB.D T, F10, F14FMUL.D F6, F10, T其中:
- 原来
FADD.D写的F6改成临时名S; - 原来
FSUB.D写的F8改成临时名T; - 真正的数据流仍然保留,比如
FMUL.D依赖FSUB.D的结果。
TIPTomasulo 要解决的问题就是:这件“看代码后手工改名”的事情,能不能让 CPU 在运行时自动完成。
硬件结构:Reservation Station 与 CDB
Tomasulo 在 Scoreboard 的基础上改变了硬件组织方式。它减少对单一集中式控制表的依赖,在功能部件前面加入多个 reservation stations(保留站)。
整体结构可以理解为:
- 上方是 instruction queue,指令仍然按程序顺序进入;
- load / store 指令进入 load buffer / store buffer;
- 加法、乘法等浮点运算进入对应的 reservation station;
- 结果通过 **CDB(Common Data Bus,公共数据总线)**广播给所有需要它的位置。
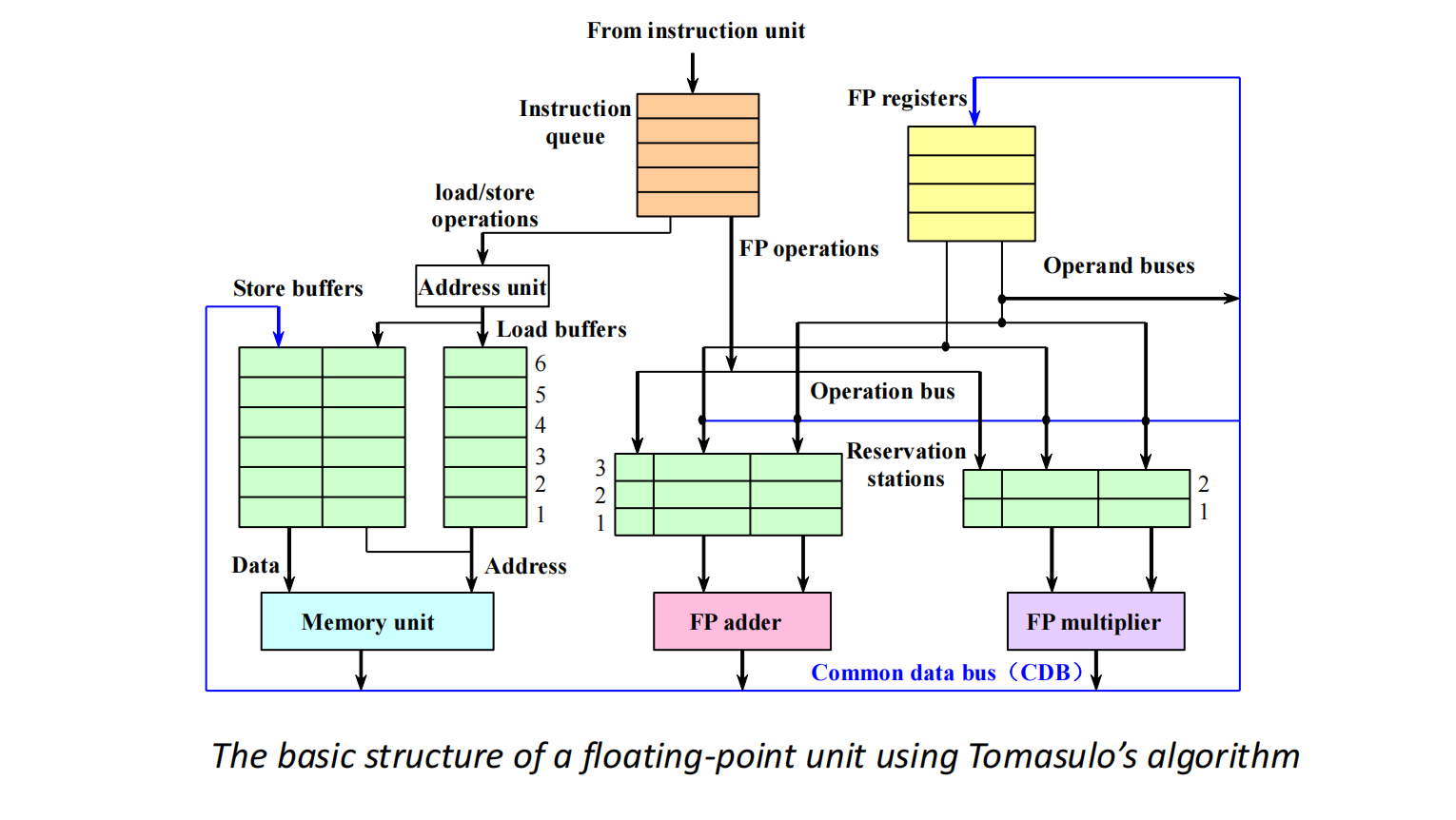
保留站的作用不只是缓存指令。它同时完成三件事:
-
扩展功能部件前的等待空间
例如只有一个加法器,但前面可以有 3 个加法保留站,所以最多可以有 3 条加法类指令先进入流水线等待。 -
保存操作数的值或生产者名字
如果操作数已经 ready,保留站中直接保存值;如果还没有 ready,保留站保存“将来由哪个保留站产生”。 -
完成寄存器重命名
指令进入保留站以后,源操作数和目的操作数不再单纯依赖架构寄存器名,改用保留站名或具体值表示。
和 Scoreboard 相比,Tomasulo 的关键差别是:
| 项目 | Scoreboard | Tomasulo |
|---|---|---|
| 控制方式 | 集中式 scoreboard | 分布式 reservation stations + CDB |
| Issue 时检查 | 功能部件是否空闲 | 对应保留站 / buffer 是否有空位 |
| WAR / WAW | 检测后等待 | 通过 register renaming 消除 |
| RAW | 等待前面结果产生 | 用 tag 记录生产者,结果出现后广播 |
| 写回 | 写寄存器,并释放部件 | 通过 CDB 广播到寄存器和所有等待位置 |
这里要特别注意:
- Tomasulo 的 IS 阶段仍然是 in-order issue;
- 进入保留站之后,谁的操作数 ready、谁的功能部件空闲,谁就可以先执行;
- 因此执行和写回可以乱序。
Tomasulo 的三个阶段
Tomasulo 把指令执行分成三个主要阶段。
Issue
从 instruction queue 的队首取出下一条指令。
如果对应类型的 reservation station 或 load/store buffer 有空位,就把指令发射进去;否则发生结构冲突,指令停在队列中。
Issue 阶段同时做 register renaming:
- 如果源操作数已经在寄存器中,就把值直接读入保留站;
- 如果源操作数还没 ready,就记录将来产生它的保留站名;
- 如果该指令要写某个寄存器,就在 register status table 中记录:这个寄存器将来由哪个保留站产生。
TIPTomasulo 的 Issue 不再检查“功能部件是否忙”。
它先检查保留站是否有空位,让指令先进来;进入之后再等操作数和功能部件。
Execute
当一条指令的所有源操作数都 ready,并且对应功能部件可用时,就可以执行。
load / store 指令有两个动作:
- 先计算 effective address;
- 再把地址放到 load buffer 或 store buffer 中,等待访存。
Write Result
当结果产生后,通过 CDB 广播。
广播目标包括:
- 架构寄存器;
- 所有正在等待这个结果的 reservation stations;
- store buffer 等需要该结果的位置。
同一个结果在一个 clock cycle 中可以被多个等待者同时收到。
store 指令需要特殊处理:只有当 store 的地址和要写入的数据都 ready,并且 memory unit 空闲时,才真正写内存。
Example:硬件如何自动重命名
老师用两条指令说明 Tomasulo 怎样自动消除 WAR,同时保留 RAW。
MUL.D F0, F2, F4ADD.D F2, F0, F6假设初始寄存器中:
F2 = aF4 = bF6 = c这两条指令之间有两种关系:
ADD.D要读F0,而F0由MUL.D产生,这是 RAW,必须保留;MUL.D要读F2,而ADD.D后面要写F2,这是 WAR,只是名字相关,可以消除。
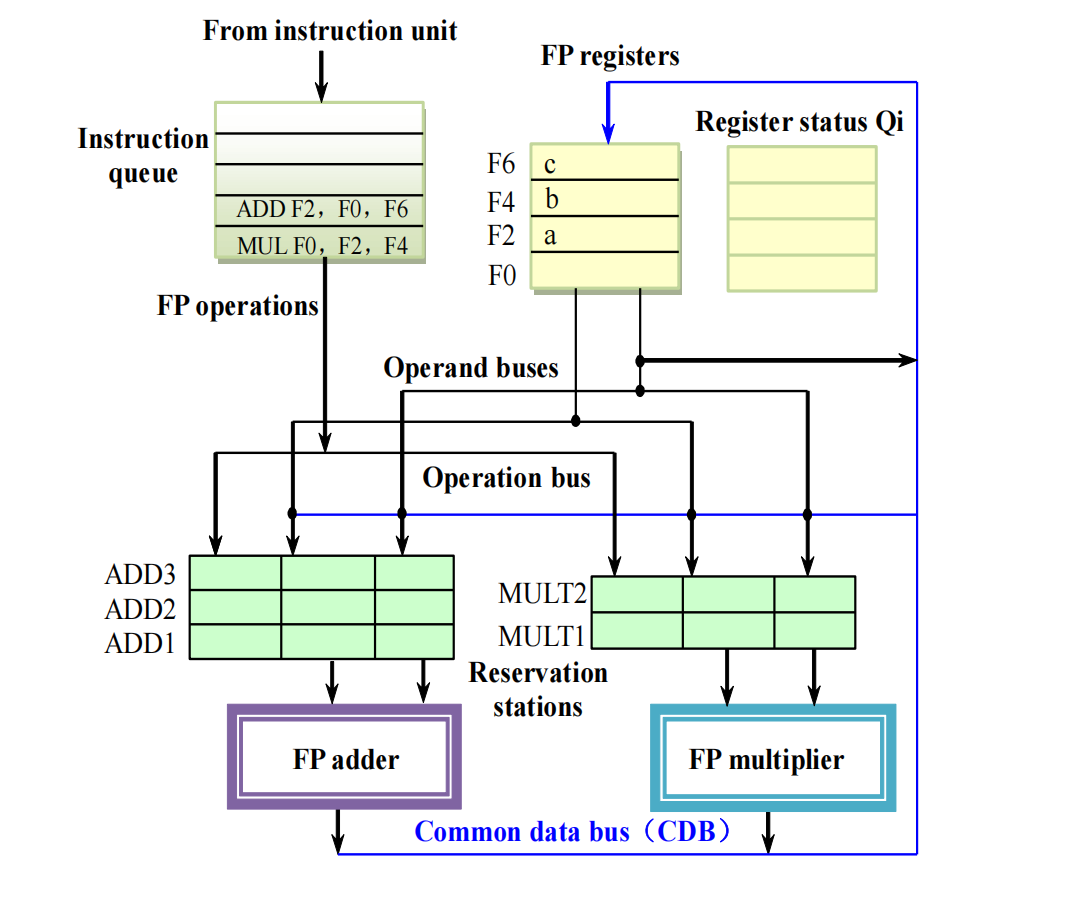
执行过程如下。
MUL.D F0, F2, F4issue 到MULT1
因为 F2 和 F4 都已经有值,所以保留站中直接存:
MULT1: MUL, Vj = a, Vk = b同时 register status table 记录:
Qi[F0] = MULT1意思是:F0 将来由 MULT1 产生。
此时 MUL.D 已经把旧的 F2 = a 读入保留站。后面即使有人写 F2,也不会影响这条乘法指令。
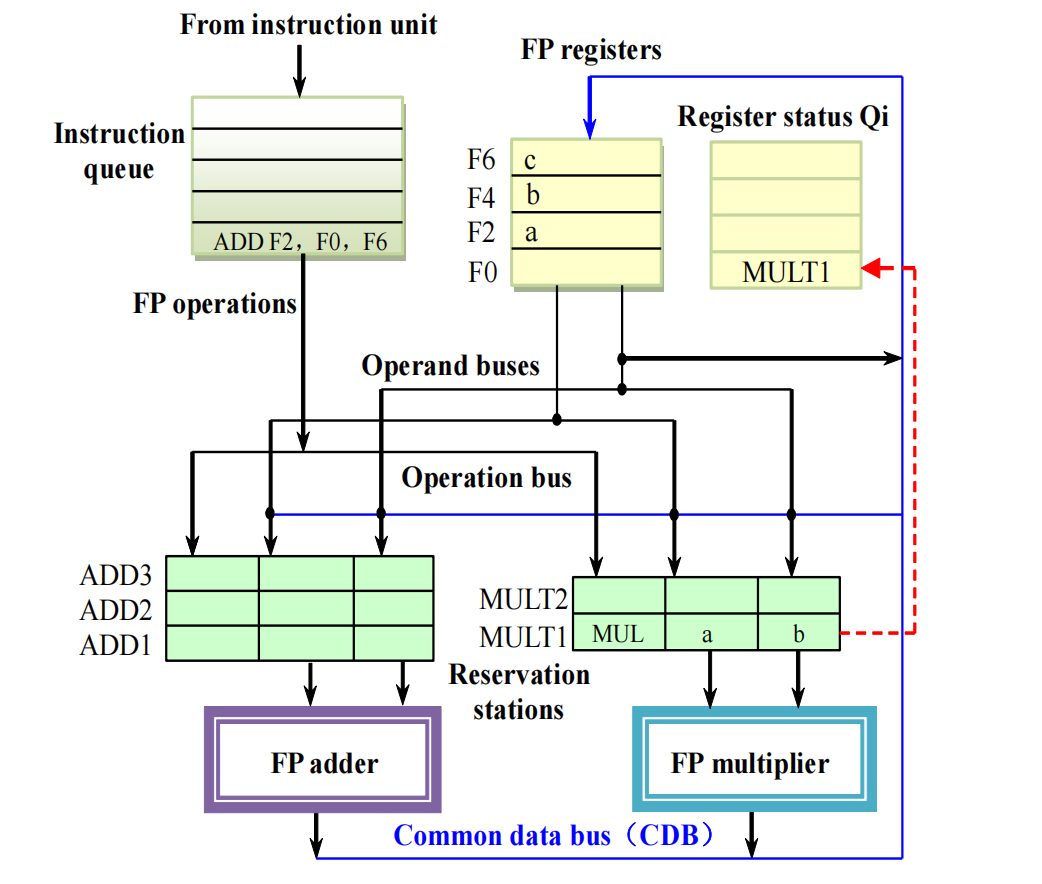
ADD.D F2, F0, F6issue 到ADD1
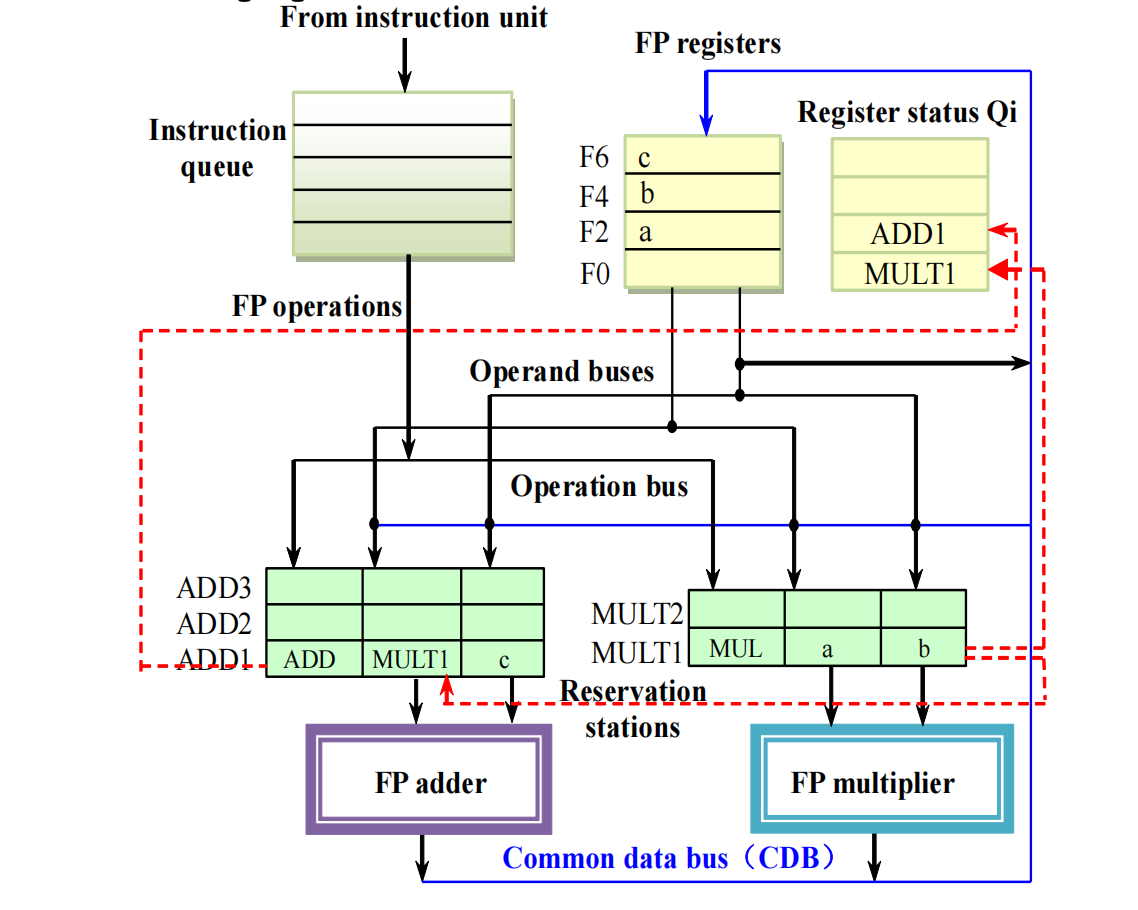
F6 = c 已经 ready,所以直接读入;F0 还没 ready,但 register status table 说明它将来由 MULT1 产生,所以记录:
ADD1: ADD, Qj = MULT1, Vk = c同时这条加法要写 F2,所以:
Qi[F2] = ADD1这里 F2 的 WAR 已经被消除:
MUL.D需要的旧F2已经变成保留站里的值a;ADD.D将来写的F2对应内部名字ADD1;- 两者不再争用同一个“名字”。
MULT1计算完成并 broadcast
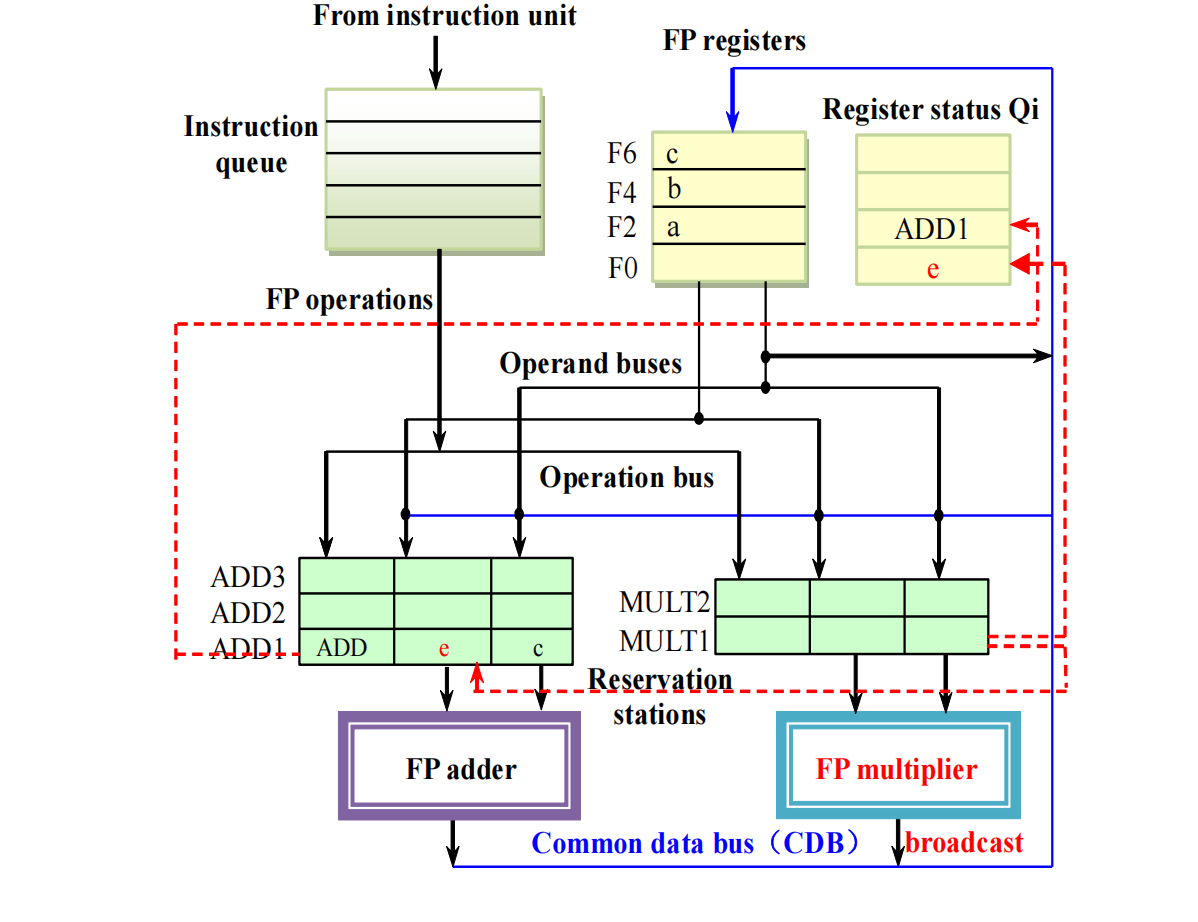
假设:
e = a × bMULT1 通过 CDB 广播 e。
于是:
F0得到e;- 所有等待
MULT1的保留站也得到e; ADD1从Qj = MULT1变成Vj = e。
此后 ADD1 可以执行:
F2 = e + c这个例子的核心是:
- RAW 通过
Qj/Qk保留下来; - WAR / WAW 通过保留站名和
Qi表被消除。
Tomasulo 的三张状态表
Tomasulo 需要记录三类状态。
Instruction Status Table
记录每条指令到了哪个阶段:
- Issue;
- Execute;
- Write Result。
这张表主要用于帮助理解算法,通常不是硬件中的真实结构。
Reservation Station Table
保留站表记录每个保留站当前是否被占用,以及源操作数是否 ready。
常见字段如下:
| 字段 | 含义 |
|---|---|
Busy | 当前保留站是否被占用 |
Op | 要执行的操作 |
Vj, Vk | 已经 ready 的源操作数值 |
Qj, Qk | 将来产生源操作数的保留站名 |
A | load/store 的地址计算相关信息 |
判断一个操作数是否 ready:
- 如果
Qj/Qk为空,说明对应操作数已经在Vj/Vk中; - 如果
Qj/Qk不为空,说明还在等某个保留站通过 CDB 广播结果。
Register Status Table
Register status table 的核心字段是 Qi。
它记录:
某个寄存器将来由哪个保留站产生例如:
Qi[F0] = MULT1表示当前 F0 的最新值还没有真正写入寄存器,它将来由 MULT1 产生。
如果 Qi[F0] 为空,则说明 F0 当前值已经在寄存器堆中,是 ready 的。
Example:状态表变化
沿用六条指令:
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F6, F2FDIV.D F10, F0, F6FADD.D F6, F8, F2关键时刻 1:只有第一条 load 已经写回
此时第一条指令已经完成:
FLD F6, 34(R2)第二条 load 已经 issue 和 execute,但还没有 write result。后面四条指令已经 issue 到对应保留站。
Instruction Status 大致为:
| Instruction | Issue | Execute | Write Result |
|---|---|---|---|
FLD F6, 34(R2) | √ | √ | √ |
FLD F2, 45(R3) | √ | √ | |
FMUL.D F0, F2, F4 | √ | ||
FSUB.D F8, F6, F2 | √ | ||
FDIV.D F10, F0, F6 | √ | ||
FADD.D F6, F8, F2 | √ |
Reservation Station Table 可以概括成:
| Name | Busy | Op | Vj | Vk | Qj | Qk | A |
|---|---|---|---|---|---|---|---|
| Load1 | No | ||||||
| Load2 | Yes | Load | 45 + Regs[R3] | ||||
| Add1 | Yes | SUB | Mem[34 + Regs[R2]] | Load2 | |||
| Add2 | Yes | ADD | Add1 | Load2 | |||
| Add3 | No | ||||||
| Mult1 | Yes | MUL | Reg[F4] | Load2 | |||
| Mult2 | Yes | DIV | Mem[34 + Regs[R2]] | Mult1 |
Register Status Table 为:
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … |
|---|---|---|---|---|---|---|---|
Qi | Mult1 | Load2 | Add2 | Add1 | Mult2 |
这里最值得注意的是 F6:
第一条 load 已经把旧的 F6 写回,后面的 FDIV.D 在 issue 时已经读到了旧 F6 的值;而最后一条 FADD.D 将来要写新的 F6,所以 Qi[F6] = Add2。
这说明 Tomasulo 已经把“旧 F6”和“新 F6”区分开了。Scoreboard 中 FADD.D 因 WAR 不能过早写 F6,但 Tomasulo 不需要这样等待。
关键时刻 2:FMUL.D 准备写回
等第二条 load 写回后,FMUL.D 和 FSUB.D 都拿到了 F2。其中:
FSUB.D执行较短,很快写回;FADD.D等到F8后也可以执行并写回;FMUL.D执行较长,此时准备 write result;FDIV.D仍然等待F0,也就是等待Mult1。
此时 Instruction Status 大致为:
| Instruction | Issue | Execute | Write Result |
|---|---|---|---|
FLD F6, 34(R2) | √ | √ | √ |
FLD F2, 45(R3) | √ | √ | √ |
FMUL.D F0, F2, F4 | √ | √ | |
FSUB.D F8, F6, F2 | √ | √ | √ |
FDIV.D F10, F0, F6 | √ | ||
FADD.D F6, F8, F2 | √ | √ | √ |
Reservation Station Table 只剩下两个乘除相关项:
| Name | Busy | Op | Vj | Vk | Qj | Qk |
|---|---|---|---|---|---|---|
| Mult1 | Yes | MUL | Mem[45 + Regs[R3]] | Reg[F4] | ||
| Mult2 | Yes | DIV | Mem[34 + Regs[R2]] | Mult1 |
Register Status Table 为:
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … |
|---|---|---|---|---|---|---|---|
Qi | Mult1 | Mult2 |
此时 FSUB.D 和 FADD.D 虽然在程序顺序上排在 FMUL.D 和 FDIV.D 后面,但已经写回。这就是 Tomasulo 的乱序执行 / 乱序写回。
Tomasulo 的贡献与局限
Tomasulo 的主要贡献:
- 提供了成熟的动态调度机制;
- 通过硬件 register renaming 消除 WAR / WAW;
- 对 RAW 用 tag 保留真实数据依赖;
- 比 Scoreboard 更适合现代乱序处理器;
- 引入了 load/store disambiguation 的思想。
其中 load/store 指令是否能乱序,要看地址关系:
- 如果 load 和 store 访问不同地址,可以安全乱序;
- 如果 load 在前、store 在后,交换顺序会让 store 先写、load 后读,可能形成 WAR;
- 如果 store 在前、load 在后,交换顺序会让 load 先读、store 后写,可能形成 RAW;
- 如果两个 store 访问同一地址,交换顺序会形成 WAW。
Tomasulo 的局限也很明显:
-
硬件结构复杂
需要保留站、load/store buffer、CDB、register status 等结构。 -
CDB 容易成为瓶颈
所有结果都要通过 CDB 广播。如果多个功能部件同一周期完成,就需要仲裁或多条 CDB。 -
访存相关仍然难处理
load/store 依赖地址计算,只有知道地址后才能判断是否可以安全乱序。 -
不能自然保证 precise exception
Tomasulo 允许乱序执行和乱序写回。这样可能出现:后面的指令已经修改了机器状态,前面的指令却发生异常。此时程序员看到的状态可能不像按顺序执行那样干净。
Tomasulo 时序填写
假设:
- Add / Sub 执行需要 2 个 clock cycles;
- Multiply 执行需要 10 个 clock cycles;
- Division 执行需要 40 个 clock cycles;
- Load 的访存执行需要 1 个 clock cycle;
- 指令按顺序 issue;
- 结果通过 CDB 写回。
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F2, F6FDIV.D F10, F0, F6FADD.D F6, F8, F2时序表为:
| Instruction | IS | EX | WB |
|---|---|---|---|
FLD F6, 34(R2) | 1 | 2-3 | 4 |
FLD F2, 45(R3) | 2 | 3-4 | 5 |
FMUL.D F0, F2, F4 | 3 | 6–15 | 16 |
FSUB.D F8, F2, F6 | 4 | 6–7 | 8 |
FDIV.D F10, F0, F6 | 5 | 17–56 | 57 |
FADD.D F6, F8, F2 | 6 | 9–10 | 11 |
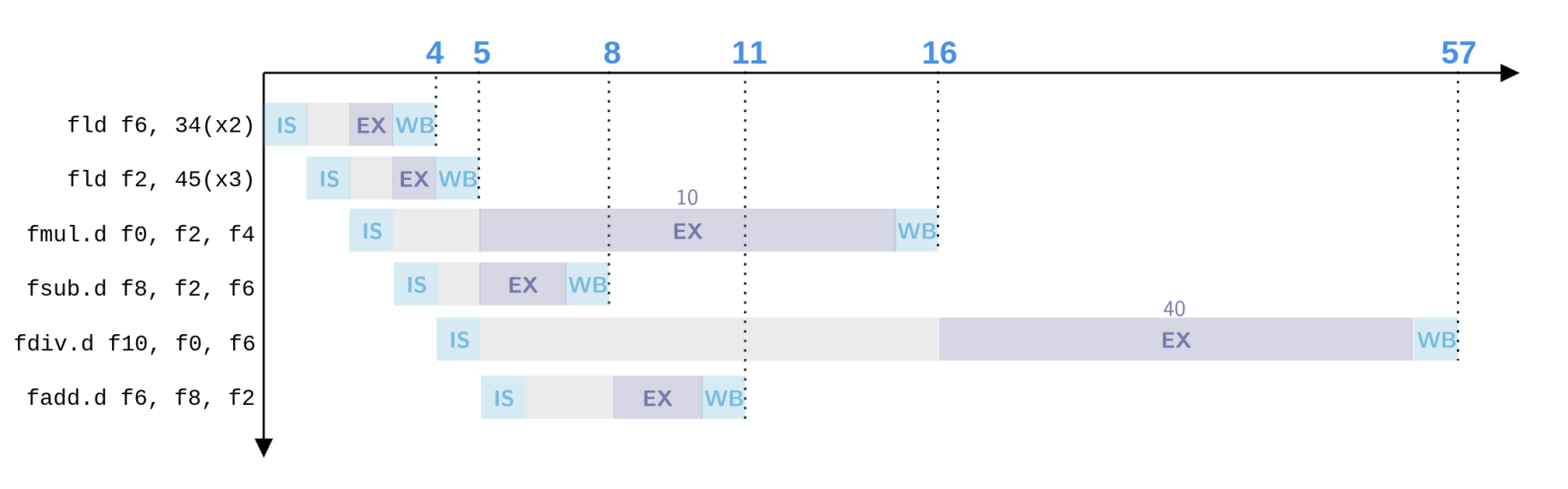
几个关键点:
- 第二条 load 为什么可以第 2 拍 IS ?
和 Scoreboard 不同,Tomasulo 检查的是 load buffer 是否有空位。只要 load buffer 有空,第二条 FLD 就可以进入流水线,不必等第一条 load 完全写回。
FMUL.D和FSUB.D为什么都可以第 6 拍开始 EX ?
第二条 load 在第 5 拍通过 CDB 写回 F2。FMUL.D 和 FSUB.D 都在等待这个结果。
CDB 广播的特点是:一个结果可以在同一拍被多个等待者同时收到。
所以第 6 拍:
FMUL.D拿到F2,可以开始乘法;FSUB.D也拿到F2,可以开始减法。
FADD.D为什么第 11 拍就能 WB ?
FADD.D 需要 F8 和 F2。
F2第 5 拍已经 ready;F8由FSUB.D产生,FSUB.D第 8 拍 WB;- 因此
FADD.D第 9–10 拍执行,第 11 拍写回。
在 Scoreboard 中,FADD.D 写 F6 会因为前面的 FDIV.D 还没读完 F6 而发生 WAR 等待;在 Tomasulo 中,FDIV.D issue 时已经把旧 F6 的值读到保留站,所以 FADD.D 可以直接写回新的 F6。
因此 Tomasulo 的写回顺序是:
1 → 2 → 4 → 6 → 3 → 5这体现了乱序执行和乱序写回。
Hardware-Based Speculation
Tomasulo 能提高功能部件利用率,但它带来一个问题:
Out-of-order execution 是否一定意味着 out-of-order completion?
答案是:可以把二者分开。
我们希望:
- 执行时乱序,提高硬件利用率;
- 对外完成时仍然顺序,保证程序语义和精确异常。
这就需要在 Tomasulo 后面再加一个 buffer:ROB(Reorder Buffer,重排序缓冲区)。
为什么需要 ROB
- 同学按学号 1、2、3、4、5 的顺序进入教室;
- 教室里有多个功能部件,可以让同学乱序完成不同任务;
- 有的人做得快,有的人做得慢;
- 但最后从教室出去时,仍然要求按学号顺序出去。
解决办法是在出口处放一排“沙发”。
- 1 号完成后可以直接出去;
- 2 号如果先完成,要坐在沙发上等 1 号;
- 5 号如果最早完成,也要等 1、2、3、4 都出去之后才能出去。
这个“沙发”就是 ROB。
TIPROB 的本质作用是:允许指令乱序执行,但强制指令按程序顺序 commit。
基于硬件推测的基本结构
Hardware-Based Speculation 在 Tomasulo 基础上加入 ROB。
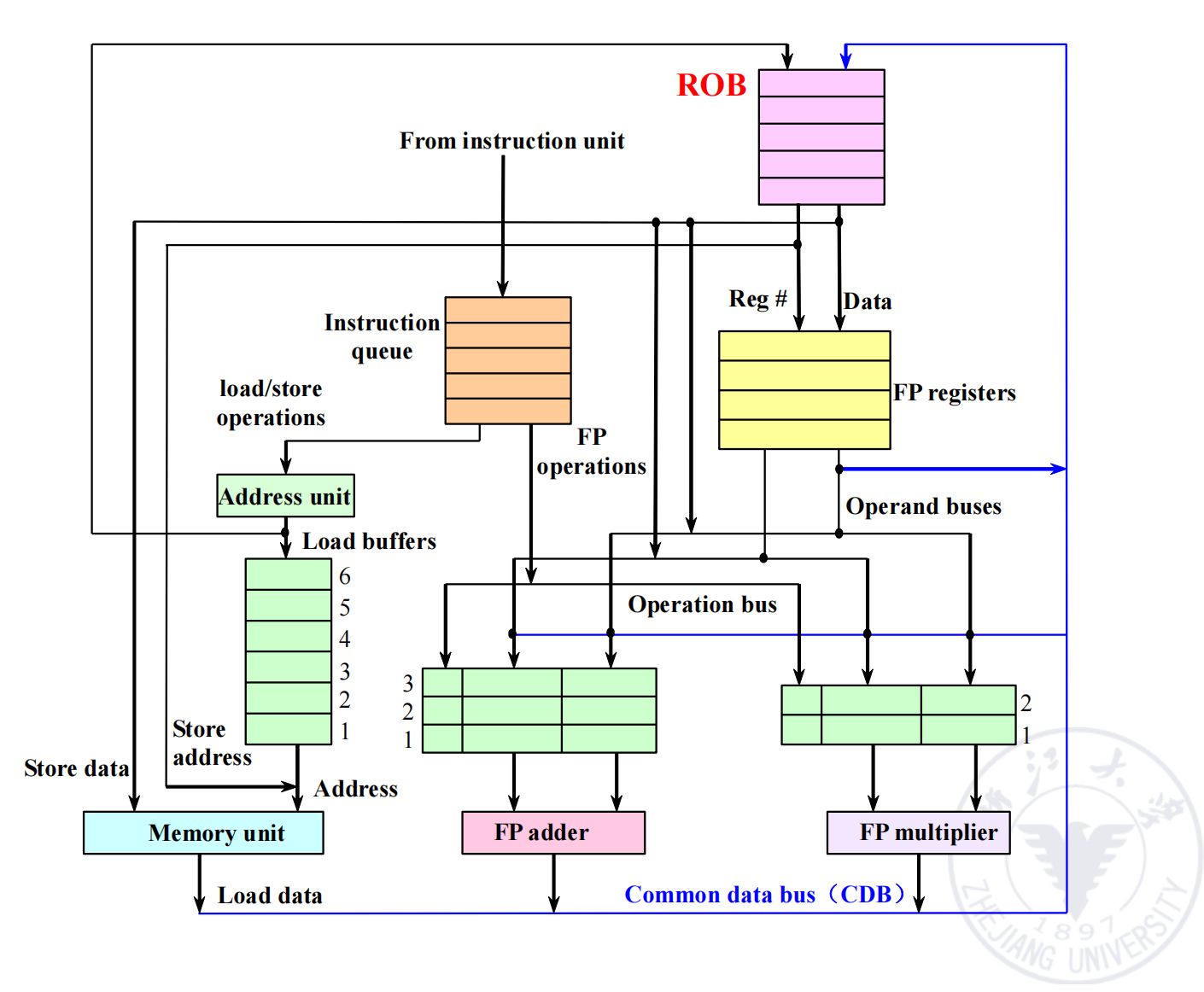
它结合了三个核心思想:
-
dynamic branch prediction
预测后面应该取哪些指令。 -
speculation
在控制相关还没有完全确定之前,先让预测路径上的指令执行。 -
dynamic scheduling
让不同基本块中的指令也能动态调度,尽量提高功能部件利用率。
加入 ROB 后,CDB 不再直接把结果写入最终的架构寄存器。结果先进入 ROB,等到该指令成为 ROB 队首并且前面所有指令都已经完成后,才真正 commit。
四个阶段:IS / EX / WB / Commit
Hardware-Based Speculation 的指令流程变成四个阶段。
Issue
从 instruction queue 中按顺序取指令。
如果对应 reservation station 有空位,并且 ROB 有空位,就可以 issue。
Issue 时会同时分配:
- 一个 reservation station;
- 一个 ROB entry。
register status table 记录的内容从 reservation station 名改为 ROB entry 编号。
Execute
和 Tomasulo 一样:
- 等源操作数 ready;
- 等功能部件可用;
- ready 的指令可以乱序执行。
Writeback
执行完成后,通过 CDB 把结果写到 ROB 对应 entry 中,也会广播给等待该结果的保留站。
区别是:此时还没有真正修改架构寄存器。
Commit
ROB 按程序顺序检查队首指令。
只有当队首指令已经完成,才允许 commit:
- 普通计算指令:把 ROB 中的结果写入架构寄存器;
- store 指令:在 commit 时真正写内存;
- 分支预测错误:从 ROB 中清除错误路径上的结果,并恢复到正确路径;
- 异常:在 commit 时处理,从而保证 precise exception。
TIPWriteback 是“结果算完并写入 ROB”。
Commit 是“这个结果正式成为程序可见状态”。
这两个阶段不能混在一起。
ROB 记录什么
ROB 需要记录每条已经 issue 但尚未 commit 的指令。
常见字段包括:
| 字段 | 含义 |
|---|---|
No. | ROB entry 编号,按照 issue 顺序分配 |
Busy | 该 entry 是否被占用 |
Instruction | 对应指令 |
Status | 当前状态,如 Issue / EX / WB / Commit |
Dest / Object | 最终要写的寄存器或内存位置 |
Value | 已经算出的结果 |
Reservation Station Table 也要增加一个字段:
| 字段 | 含义 |
|---|---|
Dest | 当前指令结果将写入哪个 ROB entry |
Register Status Table 变成记录:
某个架构寄存器的最新值将由哪个 ROB entry 产生例如:
ROB[F0] = #3表示 F0 的最新值将由 ROB 第 3 项产生。
Example
FMUL.D 准备 commit 时的状态
继续使用六条指令:
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F2, F6FDIV.D F10, F0, F6FADD.D F6, F8, F2ROB :
| No. | Busy | Instruction | Status | Dest / Object | Value |
|---|---|---|---|---|---|
| 1 | no | FLD F6, 34(R2) | Commit | F6 | Mem[34 + Regs[R2]] |
| 2 | no | FLD F2, 45(R3) | Commit | F2 | Mem[45 + Regs[R3]] |
| 3 | yes | FMUL.D F0, F2, F4 | WB | F0 | #2 × Regs[F4] |
| 4 | yes | FSUB.D F8, F2, F6 | WB | F8 | #1 - #2 |
| 5 | yes | FDIV.D F10, F0, F6 | EX | F10 | |
| 6 | yes | FADD.D F6, F8, F2 | WB | F6 | #4 + #2 |
Reservation Station Table :
| Name | Busy | Op | Vj | Vk | Qj | Qk | Dest | A |
|---|---|---|---|---|---|---|---|---|
| Add1 | no | |||||||
| Add2 | no | |||||||
| Add3 | no | |||||||
| Mult1 | no | MUL | Mem[45 + Regs[R3]] | Regs[F4] | #3 | |||
| Mult2 | yes | DIV | Mem[34 + Regs[R2]] | #3 | #5 |
register status table :
| Register | F0 | F2 | F4 | F6 | F8 | F10 | … |
|---|---|---|---|---|---|---|---|
| ROB | #3 | #6 | #4 | #5 | |||
| Busy | yes | no | no | yes | yes | yes |
注意这里的关键现象:
- 第 4 条
FSUB.D已经 WB; - 第 6 条
FADD.D也已经 WB; - 但它们都不能 commit,因为第 3 条
FMUL.D还没有 commit。
所以 ROB 把“乱序写回”重新整理成“顺序提交”。
Hardware-Based Speculation 时序填写
同一组执行延迟下,加入 ROB 后,前面的 Issue / Execute / Writeback 和 Tomasulo 基本相同。区别在于多了 Commit 阶段。
最终表格为:
| Instruction | Issue | Exec Comp | Writeback | Commit |
|---|---|---|---|---|
FLD F6, 34(R2) | 1 | 3 | 4 | 5 |
FLD F2, 45(R3) | 2 | 4 | 5 | 6 |
FMUL.D F0, F2, F4 | 3 | 6–15 | 16 | 17 |
FSUB.D F8, F2, F6 | 4 | 6–7 | 8 | 18 |
FDIV.D F10, F0, F6 | 5 | 17–56 | 57 | 58 |
FADD.D F6, F8, F2 | 6 | 9–10 | 11 | 59 |
这个表最重要的结论是:
In-order Issue / Commit,Out-of-Order Execution / Writeback.具体来看:
FSUB.D为什么 WB 很早但 Commit 很晚 ?
FSUB.D 第 8 拍已经写回 ROB。
但它是第 4 条指令,前面的第 3 条 FMUL.D 要到第 17 拍才 commit,所以 FSUB.D 必须等到第 18 拍 commit。
FADD.D为什么第 11 拍 WB,却第 59 拍 Commit ?
FADD.D 是第 6 条指令。它第 11 拍已经算完并写入 ROB。
但前面的第 5 条 FDIV.D 很慢,要到第 58 拍 commit。
因此 FADD.D 只能在第 59 拍 commit。
- 这样做为什么能保证 precise exception ?
假设第 5 条 FDIV.D 发生异常。
虽然第 6 条 FADD.D 早在第 11 拍就已经算完,但它的结果只在 ROB 中,还没有正式写入架构寄存器。因此处理器可以丢弃第 6 条及之后的推测结果,让机器状态停在“第 5 条发生异常之前”的精确位置。
这就是 precise exception 的关键。
三种方法对比
| 方法 | Issue | Execute | Writeback | Commit / 完成 | WAR / WAW | 精确异常 |
|---|---|---|---|---|---|---|
| Scoreboard | 顺序 | 可乱序 | 可能因 WAR 等待 | 写回即完成 | 检测后等待 | 较难保证 |
| Tomasulo | 顺序 | 乱序 | 乱序 | 写回即完成 | 通过重命名消除 | 不能自然保证 |
| Tomasulo + ROB | 顺序 | 乱序 | 乱序 | 顺序 commit | 通过重命名消除 | 可以保证 |
Exploiting ILP Using Multiple Issue and Static Scheduling
前面讨论的动态调度、寄存器重命名和 ROB,重点在于减少依赖造成的等待:只要一条指令的操作数已准备好,就允许它越过阻塞指令先执行。
接下来进一步提高性能的方法是 Multiple Issue(多发射 / 多流出):让处理器在一个 clock cycle 内发射多条指令,从而直接降低理想 CPI、提高 IPC。
理想情况下,若处理器最多每周期发射 条指令,则:
但真实执行速度还受到以下因素限制:
- 程序中可利用的 ILP 是否足够;
- 同周期发射的指令之间是否存在数据依赖或结构冲突;
- 功能部件、寄存器端口、旁路网络和写回通路是否足够;
- 分支判断、Load Delay、Cache Miss 等长延迟事件是否阻塞执行。
从 Single-Issue 到 Multiple-Issue
在普通单发射流水线中,每个 cycle 最多只有一条新指令进入流水线。多发射处理器希望在同一 cycle 发射两条甚至更多指令,例如:
cycle 1: issue I1, I2cycle 2: issue I3, I4cycle 3: issue I5, I6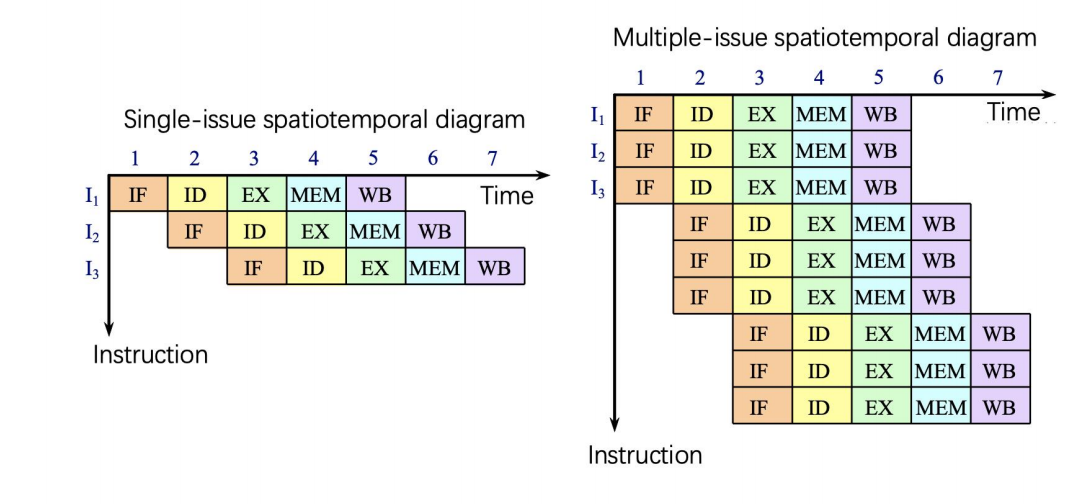

- IF 必须一次取出多条指令;
- ID / Issue 必须同时译码并检测多条指令间的冲突;
- EX 需要多套可以并行工作的功能部件;
- MEM 与 WB 需要更多访问端口、写回端口和旁路路径。
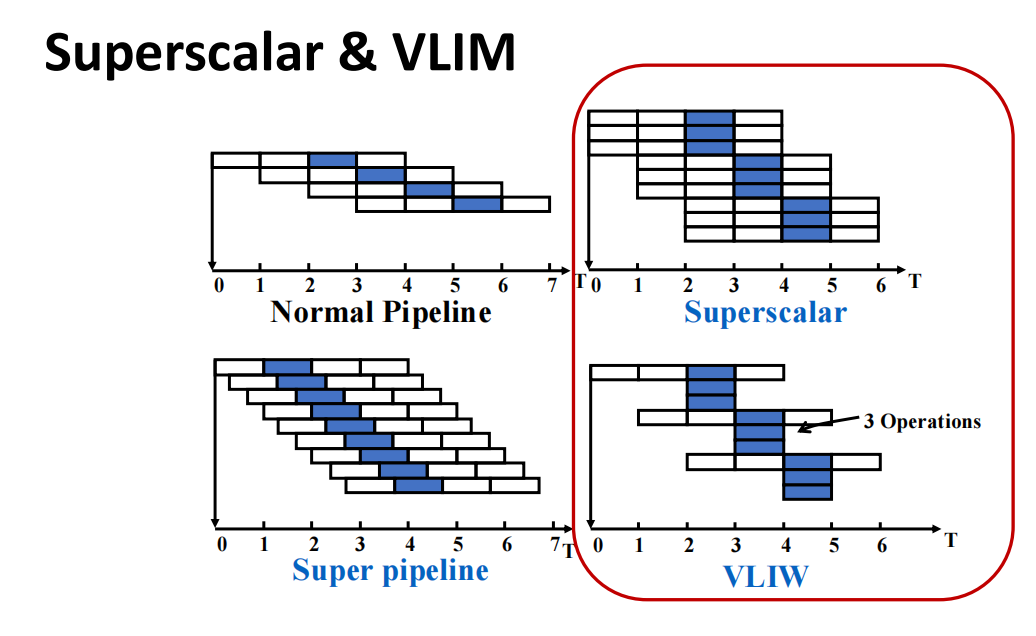
两类 Multiple-Issue Processor
Superscalar
Superscalar(超标量) 处理器每周期可发射的指令数目是不固定的:处理器设定一个发射上限,实际能发射几条取决于当前指令是否独立、资源是否可用。
若一个处理器每周期最多发射 条指令,则称为 -issue superscalar。
其特点是:
- 每个 cycle 的实际发射数量可以从
0到上限变化; - 指令仍以普通标量指令形式存在,处理器在运行时判断哪些指令可以并行发射;
- 可以采用静态调度,也可以结合 Tomasulo、ROB 等机制进行动态调度和推测执行;
- 二进制程序对微结构较透明,旧程序仍可运行,只是未必充分利用更宽的发射能力。
Superscalar 是通用处理器中最成功的多发射实现方式。
VLIW:Very Long Instruction Word
VLIW(Very Long Instruction Word,超长指令字) 把若干个能够并行执行的操作在编译阶段打包成一条很长的指令,通常也称为一个 instruction packet。
其特点是:
- 每条长指令包含固定数目的 operation slots;
- 每个 slot 通常直接控制一个功能部件,例如两个访存槽、两个浮点槽和一个整数/分支槽;
- 指令之间的并行关系由编译器显式决定;
- 硬件不需要在运行时进行同样复杂的动态发射判断;
- 更适合 DSP、多媒体等执行模式规则、并行性容易被编译器识别的应用。
TIPSuperscalar 的核心是:硬件在运行时寻找并行性。
VLIW 的核心是:编译器在编译时把并行性写进指令包。
多发射实现方式对比
常见多发射处理器归纳为以下几类:
| 类型 | Issue Structure | Hazard Detection | Scheduling | 主要特征 | 典型应用 / 处理器 |
|---|---|---|---|---|---|
| Superscalar(静态) | 动态发射 | 硬件检测 | 静态 | 通常顺序执行 | MIPS、ARM 等 |
| Superscalar(动态) | 动态发射 | 硬件检测 | 动态 | 允许一定程度的乱序执行 | 课程中作为算法扩展讨论 |
| Superscalar(推测) | 动态发射 | 硬件检测 | 动态 + 推测 | 乱序执行、顺序提交 | Intel Core、AMD、IBM Power 等 |
| VLIW / LIW | 静态打包 | 主要由软件保证 | 静态 | 危险由编译器分析并隐含解决 | TI C6x 等 DSP |
| EPIC | 主要静态 | 主要由软件保证 | 大多静态 | 编译器显式指出并行与相关信息 | Itanium |
多发射越宽,理想 IPC 越高;同时,依赖检测、寄存器端口、功能部件数量、写回通路和功耗都会迅速增加。
Static-Scheduled Superscalar
静态调度的 Superscalar 仍然由处理器在发射时检查冲突,但指令重排主要依赖编译器完成。
对于一个典型的 4-issue superscalar:
- IF 每周期从 instruction cache 中取出
1 ~ 4条指令,形成 issue packet; - 处理器检查 packet 内部的结构冲突和数据冲突;
- 再检查这些候选指令与流水线中尚未完成指令之间的冲突;
- 最终可能发射整个 packet,也可能只发射其中一部分。
MIPS 式双发射
用一个较简单的静态双发射方案说明硬件需求:
每个 cycle 最多同时发射:1 条 integer instruction + 1 条 floating-point instruction其中:
- load、store、branch 均归入 integer 类;
- IF 需要一次取出 64 bit,即两条 32-bit 指令;
- ID / Issue 需要同时译码两条指令,并判断能否同时进入各自功能部件;
- 浮点加法假设需要两个 EX cycle,整数指令只需要一个 EX cycle。
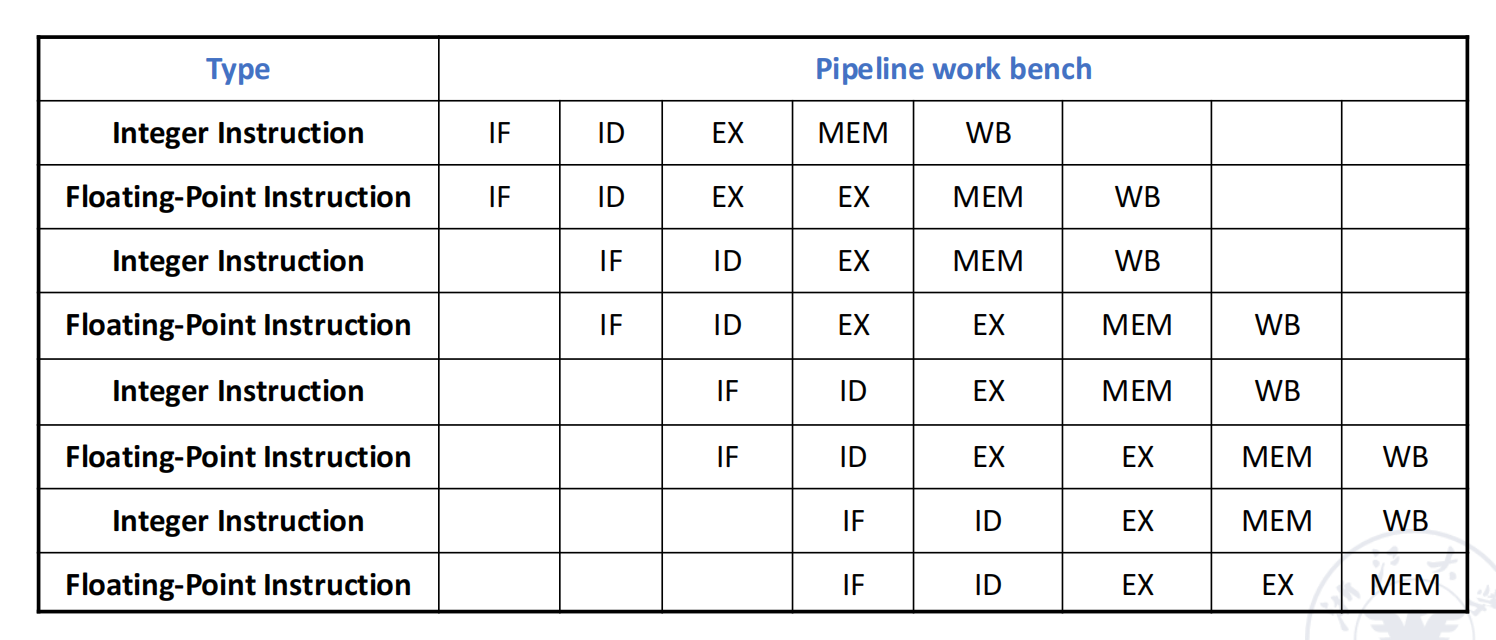
这种“1 integer + 1 floating-point”方案的优点是硬件增长相对可控;但仍然需要付出代价:
- 浮点 load / store 需要使用整数地址计算部件,会增加资源冲突;
- 浮点寄存器文件需要增加读写端口;
- 流水线中同时存在的指令增多,forwarding / bypass 通路必须扩展。
Dynamic-Scheduled Multiple Issue
静态调度很难覆盖运行时才能确定的等待,例如 Cache Miss、分支结果和动态依赖。因此,多发射通常还会与动态调度结合。
Extended Tomasulo:双发射
将 Tomasulo 扩展到双发射处理器时,采用了一个简化模型:
每个 cycle 最多同时 issue:1 条 integer instruction + 1 条 floating-point instruction关键设计原则为:
- 指令仍需按程序顺序进入 reservation station,否则可能破坏程序语义;
- 整数操作与浮点操作可以分别维护表结构,使一条 integer 指令和一条 FP 指令能在同周期进入各自的 reservation station;
- 已经进入保留站的指令,只要操作数 ready 且功能部件可用,就可以乱序执行。
这相当于把两种思想叠加起来:
Multiple Issue:每个 cycle 放入更多候选指令Dynamic Scheduling:从候选指令中动态挑选可执行者Example:向量元素加标量
给出如下循环:把常数 1(标量)加到向量的每个元素上。
Loop: LD X2, 0(X1) // X2 = array element ADDI X2, X2, 1 // increment X2 SD X2, 0(X1) // store result ADDI X1, X1, 8 // increment pointer by 8 BNE X2, X3, Loop // branch if not last分析时采用以下假设:
- 每周期可以 issue 一条 integer 指令和一条 floating-point 指令,即使二者之间存在依赖;
- 有独立的整数 ALU / 地址计算部件,以及独立流水化的浮点功能部件;
- Instruction flow 与 Write Result 各占一个 cycle;
- 有动态分支预测部件,并带独立的分支条件计算部件;
- 不使用延迟分支;分支预测完美;在分支完成前,后续指令只允许取出与 issue,不能执行;
- 由于 Write Result 占一个 cycle,结果生成延迟为:integer operation 1 cycle、load 2 cycles、floating-point addition 3 cycles。
本例只涉及 integer / load / store,因此浮点槽位处于空闲状态。
不带 ROB:分支之后的指令不能提前执行
首先考虑使用 Tomasulo,但不加入 ROB,也不进行推测执行。
此时下一轮循环的 LD 虽然可以被取出和 issue,但必须等待上一轮 BNE 的执行结果确认之后才能真正开始执行。
前三轮执行时序如下(Without speculation):
| Loop | Instruction | IS | EX | MEM | Write CDB | 说明 |
|---|---|---|---|---|---|---|
| 1 | LD X2, 0(X1) | 1 | 2 | 3 | 4 | 第一条指令 |
| 1 | ADDI X2, X2, 1 | 1 | 5 | 6 | 等待 LD | |
| 1 | SD X2, 0(X1) | 2 | 3 | 7 | 等待 ADDI | |
| 1 | ADDI X1, X1, 8 | 2 | 3 | 4 | 可直接执行 | |
| 1 | BNE X2, X3, Loop | 3 | 7 | 等待 ADDI | ||
| 2 | LD X2, 0(X1) | 4 | 8 | 9 | 10 | 等待 BNE |
| 2 | ADDI X2, X2, 1 | 4 | 11 | 12 | 等待 LD | |
| 2 | SD X2, 0(X1) | 5 | 9 | 13 | 等待 ADDI | |
| 2 | ADDI X1, X1, 8 | 5 | 8 | 9 | 等待 BNE | |
| 2 | BNE X2, X3, Loop | 6 | 13 | 等待 ADDI | ||
| 3 | LD X2, 0(X1) | 7 | 14 | 15 | 16 | 等待 BNE |
| 3 | ADDI X2, X2, 1 | 7 | 17 | 18 | 等待 LD | |
| 3 | SD X2, 0(X1) | 8 | 13 | 19 | 等待 ADDI | |
| 3 | ADDI X1, X1, 8 | 8 | 14 | 15 | 等待 BNE | |
| 3 | BNE X2, X3, Loop | 9 | 19 | 等待 ADDI |
可以看出:
- 三轮共 15 条指令在 19 cycles 内完成,平均 。
- 主要瓶颈是数据相关分支与整数 ALU 争用:地址计算与整数运算挤在同一部件上。
- 改进思路是增加一个 adder,把地址计算功能从 ALU 中分离。
带 ROB 与推测执行:跨过分支继续执行
若在双发射 Tomasulo 上进一步加入 ROB 与 branch prediction,则处理器可以在分支尚未最终提交前,对后续循环迭代进行推测执行:
- 下一轮
LD不需要等上一轮BNE完成后才执行; - 执行结果先写入 ROB,不直接改变架构状态;
- 若预测正确,按程序顺序 commit;
- 若预测错误,则丢弃错误路径上的 ROB 项,恢复精确状态。
带硬件推测(With hardware speculation)的前三轮时序如下:
| Loop | Instruction | IS | EX | MEM | Write CDB | Commit | 说明 |
|---|---|---|---|---|---|---|---|
| 1 | LD X2, 0(X1) | 1 | 2 | 3 | 4 | 5 | 第一条指令 |
| 1 | ADDI X2, X2, 1 | 1 | 5 | 6 | 7 | 等待 LD | |
| 1 | SD X2, 0(X1) | 2 | 3 | 7 | 等待 ADDI | ||
| 1 | ADDI X1, X1, 8 | 2 | 3 | 4 | 8 | 顺序提交 | |
| 1 | BNE X2, X3, Loop | 3 | 7 | 8 | 等待 ADDI | ||
| 2 | LD X2, 0(X1) | 4 | 5 | 6 | 7 | 9 | 无执行延迟 |
| 2 | ADDI X2, X2, 1 | 4 | 8 | 9 | 10 | 等待 LD | |
| 2 | SD X2, 0(X1) | 5 | 6 | 10 | 等待 ADDI | ||
| 2 | ADDI X1, X1, 8 | 5 | 6 | 7 | 11 | 顺序提交 | |
| 2 | BNE X2, X3, Loop | 6 | 10 | 11 | 等待 ADDI | ||
| 3 | LD X2, 0(X1) | 7 | 8 | 9 | 10 | 12 | 最早可执行 |
| 3 | ADDI X2, X2, 1 | 7 | 11 | 12 | 13 | 等待 LD | |
| 3 | SD X2, 0(X1) | 8 | 9 | 13 | 等待 ADDI | ||
| 3 | ADDI X1, X1, 8 | 8 | 9 | 10 | 14 | 更早执行 | |
| 3 | BNE X2, X3, Loop | 9 | 13 | 14 | 等待 ADDI |
由表可得:三轮共 15 条指令在 14 cycles 内提交,平均 。
按全部指令完成的口径,推测执行带来的加速比约为:
从这个例子可以看到:
- 分支可能成为关键性能瓶颈,硬件推测可以显著改善。
- 非推测流水线的完成速率很快落后于发射速率,继续发射更多迭代会出现明显停顿。
- 推测执行的收益依赖分支预测准确性;预测错误会降低性能并显著损耗能效。
这里的核心并是:
提前执行分支后的工作,同时用 ROB 保证最终仍按顺序提交。VLIW 的静态调度
VLIW 通过编译器把可以并行执行的操作打包成一条长指令。每个 operation slot 对应一种功能部件,因此一个 VLIW instruction 可以在同一 cycle 内驱动多个部件同时工作。
采用如下五槽 VLIW 结构:
| Operation Slot | 功能 |
|---|---|
L/S Instruction 1 | 第一个访存操作 |
L/S Instruction 2 | 第二个访存操作 |
FP Instruction 1 | 第一个浮点操作 |
FP Instruction 2 | 第二个浮点操作 |
Integer / Branch Instruction | 整数运算或分支 |
Example:循环展开后的 VLIW 打包
以循环展开后的向量加标量程序为例:一次处理 7 个元素。
展开前的原始循环指令序列:
Loop: L.D F0, 0(R1) ADD.D F4, F0, F2 S.D F4, 0(R1) DADDIU R1, R1, #-8 BNE R1, R2, Loop循环展开后的指令序列(按程序顺序):
Loop: L.D F0, 0(R1) L.D F6, -8(R1) L.D F10, -16(R1) L.D F14, -24(R1) L.D F18, -32(R1) L.D F22, -40(R1) L.D F26, -48(R1) ADD.D F4, F0, F2 ADD.D F8, F6, F2 ADD.D F12, F10, F2 ADD.D F16, F14, F2 ADD.D F20, F18, F2 ADD.D F24, F22, F2 ADD.D F28, F26, F24 S.D F4, 0(R1) S.D F8, -8(R1) S.D F12, -16(R1) S.D F16, -24(R1) S.D F20, -32(R1) S.D F24, -40(R1) S.D F28, -48(R1) DADDIU R1, R1, #-56 BNE R1, R2, LoopVLIW 指令包安排如下,每一行代表一个 clock cycle:
| Cycle | L/S Instruction 1 | L/S Instruction 2 | FP Instruction 1 | FP Instruction 2 | Integer / Branch |
|---|---|---|---|---|---|
| 1 | L.D F0, 0(R1) | L.D F6, -8(R1) | |||
| 2 | L.D F10, -16(R1) | L.D F14, -24(R1) | |||
| 3 | L.D F18, -32(R1) | L.D F22, -40(R1) | ADD.D F4, F0, F2 | ADD.D F8, F6, F2 | |
| 4 | L.D F26, -48(R1) | ADD.D F12, F10, F2 | ADD.D F16, F14, F2 | ||
| 5 | ADD.D F20, F18, F2 | ADD.D F24, F22, F2 | |||
| 6 | S.D F4, 0(R1) | S.D F8, -8(R1) | ADD.D F28, F26, F24 | ||
| 7 | S.D F12, -16(R1) | S.D F16, -24(R1) | DADDIU R1, R1, #-56 | ||
| 8 | S.D F20, 24(R1) | S.D F24, 16(R1) | |||
| 9 | S.D F28, 8(R1) | BNE R1, R2, Loop |
第 8~9 行的 S.D F20, 24(R1)、S.D F24, 16(R1)、S.D F28, 8(R1) 需要特别注意:第 7 行已经执行 R1 = R1 - 56,所以相对更新后指针的 24/16/8(R1) 分别对应原始指针的 -32/-40/-48(R1)。
这份安排的性能为:
- 7 个原始循环迭代在 9 cycles 内完成;
- 平均每个元素耗时:
- 共执行 23 个有效操作,平均有效操作数为:
- 总 operation slots 为
9 × 5 = 45,有效槽位利用率为:
VLIW 的局限
VLIW 将调度压力转移给编译器,硬件可以较简单,但也带来明显限制:
- 代码长度增加:为了暴露更多并行性,编译器往往需要大量 loop unrolling;
- 操作槽浪费:程序中并非始终存在足够独立操作,很多 slot 可能为空;
- Lockstep 机制:若某个功能部件因等待而暂停,整个长指令包往往都要暂停;
- 二进制兼容性较差:VLIW 代码依赖功能部件数量和执行延迟,不同微结构之间较难直接复用同一份机器代码;
- 程序本身 ILP 有限:存在真实数据依赖的操作不能简单打包并行执行。
因此,多发射处理器最终都受到三类因素影响:
- 程序本身固有的 instruction-level parallelism;
- 实现多发射、冲突检测和并行通路的硬件复杂度;
- Superscalar 或 VLIW 各自技术路线的固有限制。
Superpipelining Processor
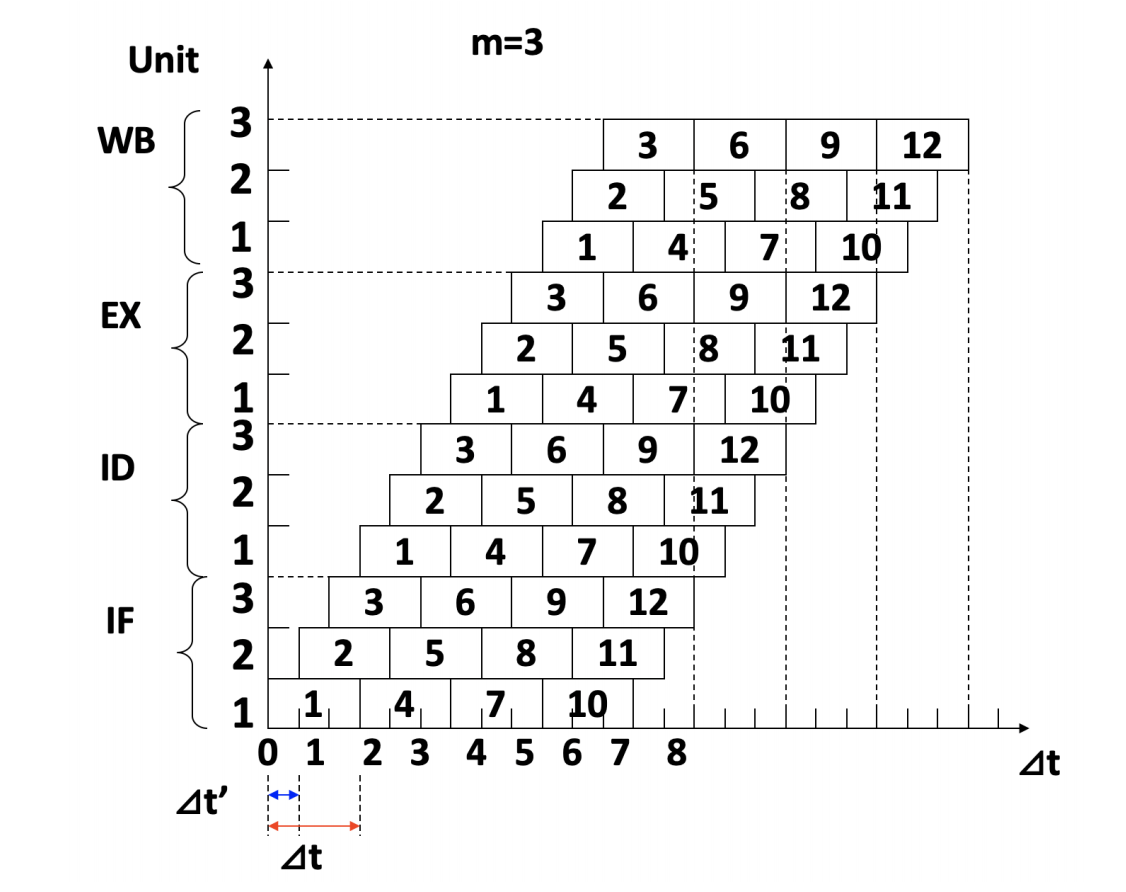
Superpipelining(超流水) 采用另一种提高吞吐率的方法:把原有 pipeline stage 进一步细分,使处理器可以在小于一个原始 clock cycle 的时间间隔内流入下一条指令。
若一个原始 cycle 被细分为 份,则:
- 指令不是在同一时刻同时发射 条;
- 而是每经过 个原始 cycle 流入一条指令;
- 从宏观上看,一个原始 cycle 内同样可以流入约 条指令。
这与 Superscalar 的区别为:
| 技术 | 同一时刻并行发射多条指令 | 主要手段 |
|---|---|---|
| Superscalar | 是 | 增加并行功能部件和发射宽度 |
| Superpipelining | 否 | 细分流水阶段,提高流水节拍频率 |
MIPS R4000:八段 Superpipeline
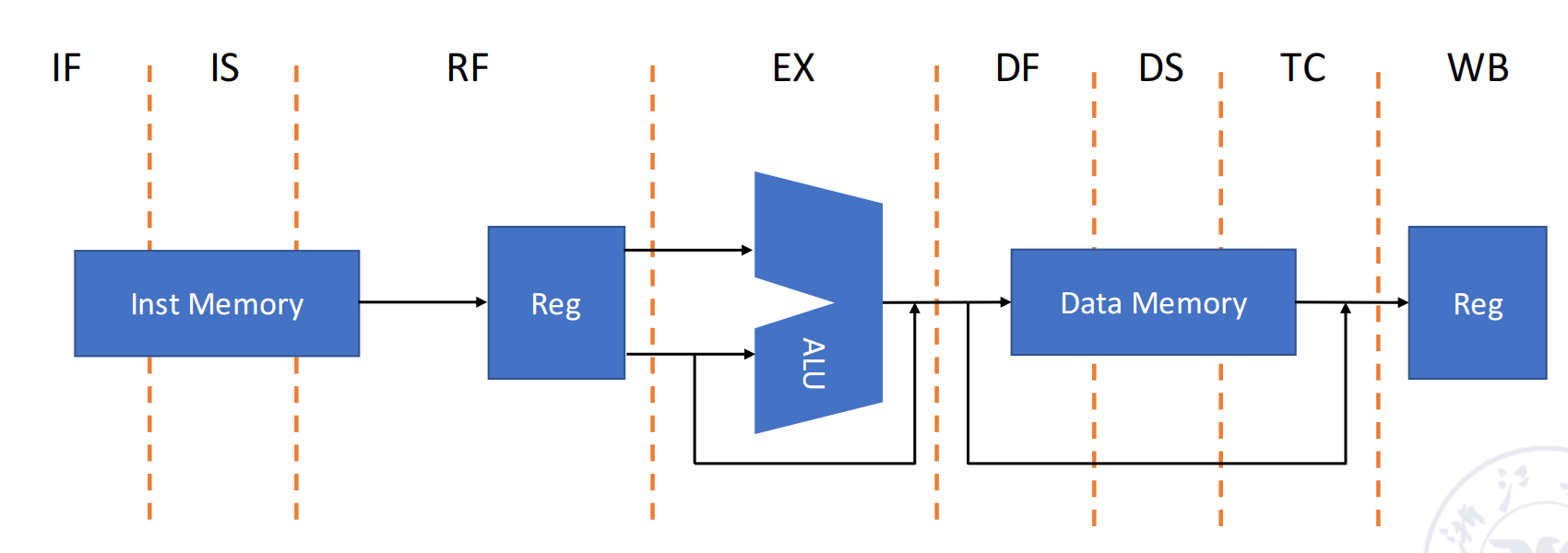
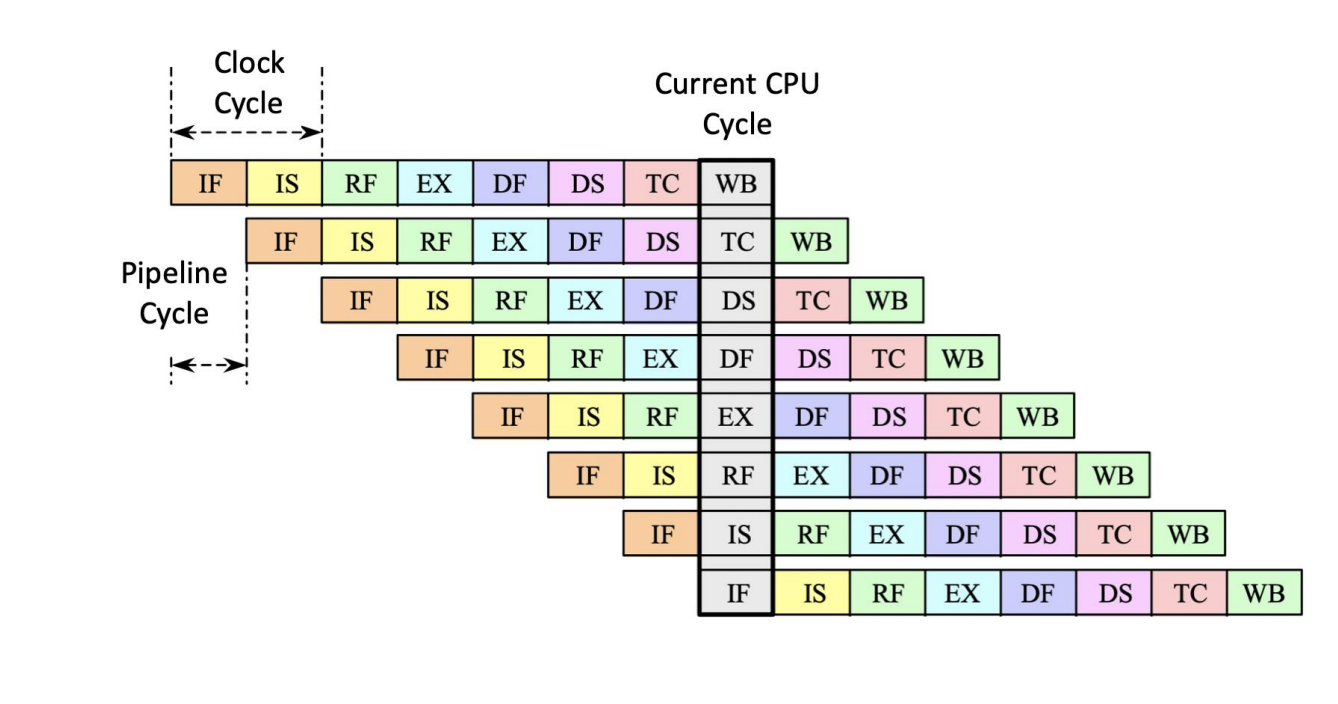
SGI MIPS R4000 作为典型超流水处理器。其整数核心采用 8 段流水:
IF → IS → RF → EX → DF → DS → TC → WB其中各阶段含义如下:
| Stage | 功能 |
|---|---|
IF | 取指前半段:选择 PC,并启动 instruction cache 访问 |
IS | 取指后半段:完成 instruction cache 访问 |
RF | 指令译码、寄存器读取、hazard checking、instruction cache hit detection |
EX | 执行:有效地址计算、ALU 运算、分支目标地址与分支条件计算 |
DF | 数据访问前半段:启动 data cache 访问 |
DS | 数据访问后半段:完成 data cache 访问 |
TC | Tag check:判断 data cache 访问是否命中 |
WB | load 与寄存器-寄存器运算的写回 |
R4000 中与该结构相关的硬件包括:
- 分离的 Instruction Cache 与 Data Cache;
- 两个 Cache 容量均为
8 KB; - 每个 Cache 数据宽度为
64 bit; - 整数核心含
32 × 32-bit通用寄存器组、ALU 和独立乘除法部件。
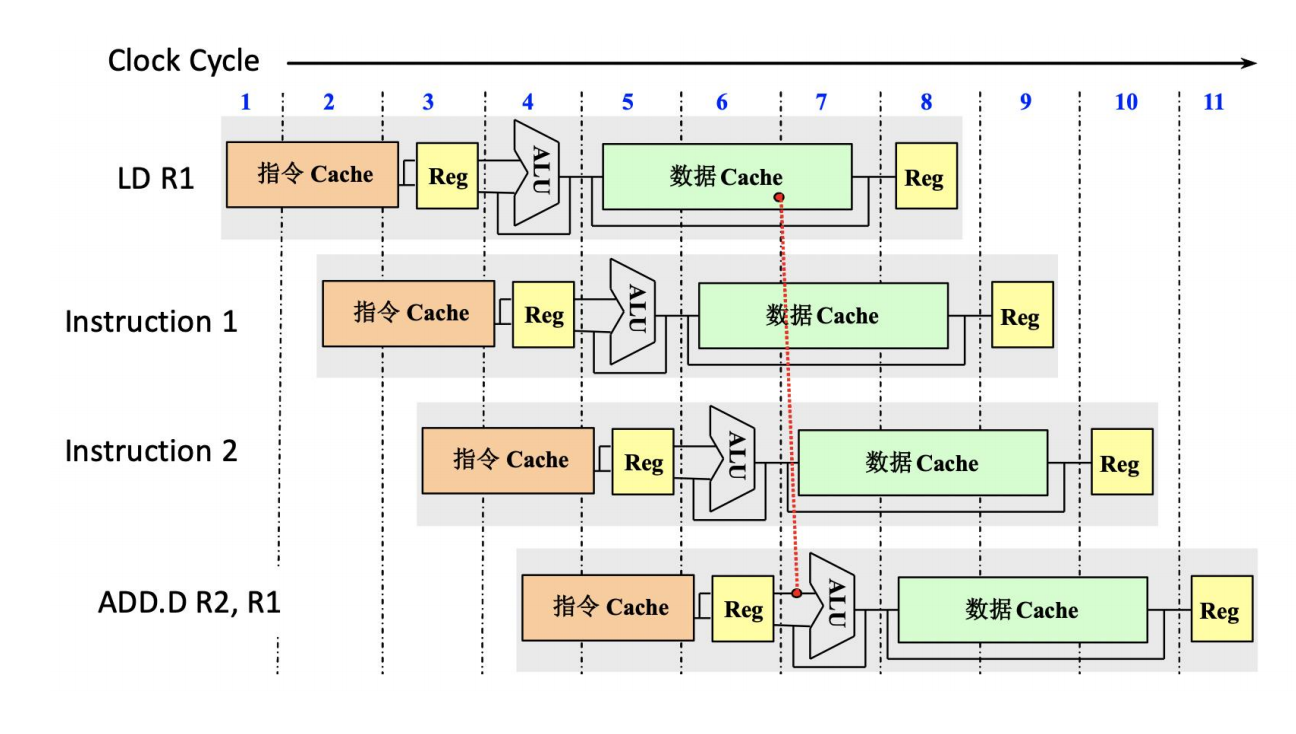
深流水仍然存在 Load Delay
Superpipeline 可以提高流水吞吐率,但不能消除数据依赖。
在 R4000 中,load 结果需要经过:
EX → DF → DS → TC → WB依赖该结果的下一条运算指令,即使已经进入流水线,也必须等待 load 数据真正可用。课件用 LD R1 后紧接 ADD.D R2, R1 的例子展示了 two clock cycles for load delay。
TIP更深的流水线提高的是潜在 throughput;如果依赖关系、分支或 Cache Miss 造成等待,实际 IPC 仍会下降。
因此 Superpipelining、Multiple Issue 与 Dynamic Scheduling 常常需要协同使用。
 方法对比
方法对比
| 方法 | 每周期进入流水线的指令数 | 并行性由谁发现 | 是否支持乱序执行 | 主要优势 | 主要限制 |
|---|---|---|---|---|---|
| Single-Issue Pipeline | 1 | 编译器 / 简单硬件 | 通常否 | 硬件简单 | 理想 IPC 上限低 |
| Superscalar + Static Scheduling | 0 ~ n | 编译器为主,硬件检查发射冲突 | 通常顺序执行 | 兼容普通标量程序 | 编译器受运行时事件限制 |
| Superscalar + Dynamic Scheduling + ROB | 0 ~ n | 硬件动态发现 | 是,顺序提交 | 能处理动态等待与分支推测 | 硬件复杂、功耗高 |
| VLIW | 固定 packet 宽度 | 编译器 | 一般按静态计划执行 | 硬件发射逻辑较简单 | 空槽、代码膨胀、兼容性问题 |
| Superpipelining | 每 cycle 流入一条 | 与调度方案独立 | 取决于实现 | 提高流水节拍 | 深流水放大 hazard 代价 |