

概述
这一章讨论的是 memory hierarchy(存储层次):当 CPU 速度远高于主存,而主存又远小于外存时,系统如何通过多级存储结构,在 速度、容量、成本、功耗 之间取得折中。
本章主线可以分成两部分:
-
Cache
- 利用 temporal locality 和 spatial locality,把近期或相邻的数据保存在更靠近 CPU 的小而快存储中;
- 围绕四个基本问题展开:block 放在哪里、如何查找、miss 时替换谁、write 时如何处理;
- 通过 AMAT、memory stall cycles 等公式分析 cache 对 CPU 性能的影响;
- 进一步讨论降低 hit time、miss rate、miss penalty,以及提高 cache bandwidth 的典型优化方法。
-
Virtual Memory
- 在 OS 和 MMU 的配合下,把程序看到的 virtual address 映射到 physical address;
- 让进程拥有连续、独立的虚拟地址空间,而物理内存可以不连续分配;
- 通过 page table、TLB、page fault、protection bits 等机制,实现内存扩展、进程隔离、共享与保护。
本章的核心是理解:存储系统的设计本质上是在不同层级之间转移访问代价。Cache 试图让大多数访问停留在更快层级;Virtual Memory 则进一步把主存和外存纳入统一的地址空间管理中。两者共同构成现代计算机系统中 CPU、OS 和 memory system 协同工作的基础。
目录
- 概述
- 目录
- Introduction
- Technology Trend and Memory Hierarchy
- Four Questions for Cache Designers
- Memory System Performance
- Improve Cache Performance
- Additional Techniques Often Discussed with Cache Optimization
- GPU Memory and Cache-Related Topics
- How to Compare These Techniques
- A Compact Takeaway Table
- Virtual Memory
- OS、MMU 与 Virtual Memory
- Program Thinks vs Program Uses
- Virtual Memory 的三个核心作用
- Cache vs Virtual Memory
- Virtual Memory Allocation
- Four Questions for Virtual Memory
- Address Translation
- Translation Lookaside Buffer
- Page Size Selection
- Address Translation with Cache
- 现代处理器中的访问路径
- Protection and Sharing among Programs
- Virtual Memory and Virtual Machine
Introduction
从 Load/Store 到 Memory Hierarchy
处理器真正和 memory 打交道,最直接的入口其实就是两类指令:
LoadStore
只要程序在读数据或写数据,它就一定绕不开 memory system(存储系统)。
问题在于:
- 寄存器很快,但太小;
- 主存够大,但太慢;
- 如果每次 load/store 都直接等主存,CPU 就会被严重拖慢。
因此系统自然会沿着下面这条思路演化:
- 先有寄存器,解决最靠近执行单元的临时数据保存;
- 仅靠寄存器仍然不够,因为程序访问的数据规模远大于寄存器容量;
- 于是要在处理器和主存之间放一层更快的临时存储;
- 如果一层不够,就继续分层,形成 memory hierarchy(存储层次)。

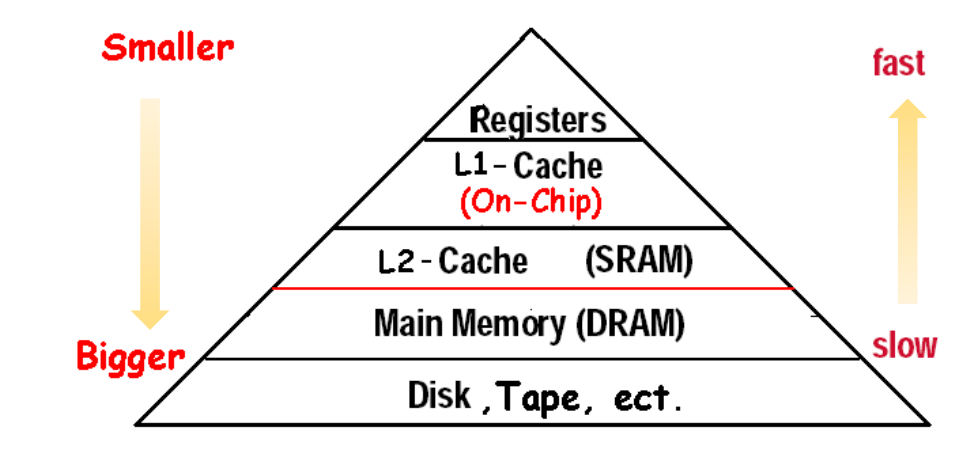
从图里能直接看出 hierarchy 的基本规律:
- 越靠近 CPU,速度越快;
- 越靠近 CPU,容量越小;
- 越往下层,容量越大,但访问代价也越高。
几个典型量级:
- Register:大约
300ps - L1 cache:大约
1ns - L2 cache:大约
5-10ns - Main memory:大约
50-100ns - Storage:已经到
us甚至ms量级
全部都用和寄存器一样快的存储是不现实的:
- 成本太高;
- 功耗太大;
- 容量根本做不起来。
所以 memory hierarchy 的本质是一种系统折中:
- 用少量快存储去吸收大多数高频访问
- 把大容量低成本存储留给不那么频繁的访问
Locality
cache 不是凭空有效的,它依赖的是 principle of locality(局部性原理)。
两种最基本的 locality 是:
-
Temporal locality(时间局部性)
- 如果某个数据刚被访问过,那么它很可能在不久之后再次被访问。
-
Spatial locality(空间局部性)
- 如果某个地址刚被访问过,那么它附近地址的数据也很可能很快会被访问。
NOTE如果一本书刚被你从书柜拿到桌上,你大概率不会看一眼就立刻再也不用它; 如果你刚看完上册、中册,那么接下来去看下册也很自然; 历史访问对未来访问有预测价值。
TIP
- 时间局部性强调刚访问过的对象还会再来;
- 空间局部性强调附近的数据通常会被一起用到。
cache 的两个最基本设计动作,正好就对应这两点:
- 时间局部性 -> 把最近访问过的数据留在更靠近 CPU 的地方;
- 空间局部性 -> 不是只搬一个 word,而是把一整块相邻数据一起搬上来。
Cache
Cache(高速缓存) 是一种小而快的存储,用来降低访问较慢下层存储的平均时间。 In computer architecture, almost everything is a cache.
- Register 可以看成软件和硬件共同管理的最靠近计算的数据缓存;
- L1 是对 L2 / memory 的 cache;
- L2、L3 继续往下缓存;
- 从更大的视角看,memory 甚至还可以看成 disk 上数据的上层缓存。
Cache Hit / Cache Miss
-
cache hit(命中)
- 处理器要的数据已经在 cache 中;
- 这时直接从 cache 返回,处理器几乎感觉不到“下面还有主存”这件事。
-
cache miss(失效)
- 处理器要的数据不在 cache 中;
- 这时就必须继续访问下层存储,把数据取回来。
对处理器来说,hit 和 miss 的差别非常大:
- hit 时,控制逻辑很简单;
- miss 时,不仅要访问下层 memory,还可能要 replacement、write-back,甚至让整个处理器 stall。
Block / Line
cache 和 memory 之间传输数据时,基本单位不是单个 word,而是:
- block(块)
- 也常叫 cache line(缓存行)
它表示的是:
一组固定大小的数据,其中包含了当前请求的那个 word。
NOTE为什么不只搬一个 word?
- 空间局部性说明:既然访问了这个地址,附近地址的数据很可能也快要用了;
- 所以一次 miss 时顺手把整个 block 一起搬上来,通常更划算。
对应而生的参数:
byte offset决定 block 内具体取哪个字节;index决定这个 block 去 cache 的哪一行/哪一组;tag决定当前这行里放的是不是我要的那个 block。
Technology Trend and Memory Hierarchy
Processor-Memory Gap
processor-memory performance gap(处理器与主存的性能鸿沟)
- CPU 核心的速度提升得很快;
- 主存并不是完全不提升,但提升速度明显慢得多;
- 结果就是:处理器越来越像在等内存。
既然主存不可能又大又快,那就只能靠多级 hierarchy 来把快和大拆开实现。
memory hierarchy 的目标:
- 尽量给用户呈现出便宜技术所能提供的大容量
- 同时尽量提供接近最快技术的访问速度
这正是 locality 能带来的收益:
- 高频访问的数据,被上层快存储命中;
- 低频访问的数据,仍然待在下层大容量存储里。
SRAM / DRAM / Storage
-
SRAM(Static RAM,静态随机存取存储器)
- 快,但贵、面积大;
- 适合做 cache。
-
DRAM(Dynamic RAM,动态随机存取存储器)
- 比 SRAM 慢,但容量更大、成本更低;
- 适合做 main memory。
-
Storage(外存)
- 如 SSD / Flash / HDD;
- 更慢,但容量更大、单比特成本更低。
cache 主要靠 SRAM 主存主要靠 DRAM 更往下的层次则是 SSD / Flash / Disk 等存储设备
Memory Hierarchy
从 hierarchy 角度看,一个现代系统常见的层次关系大致是:
- Register
- L1 cache
- L2 cache
- L3 cache
- Main memory
- Storage
接近真实机器的多级 cache 组织图:
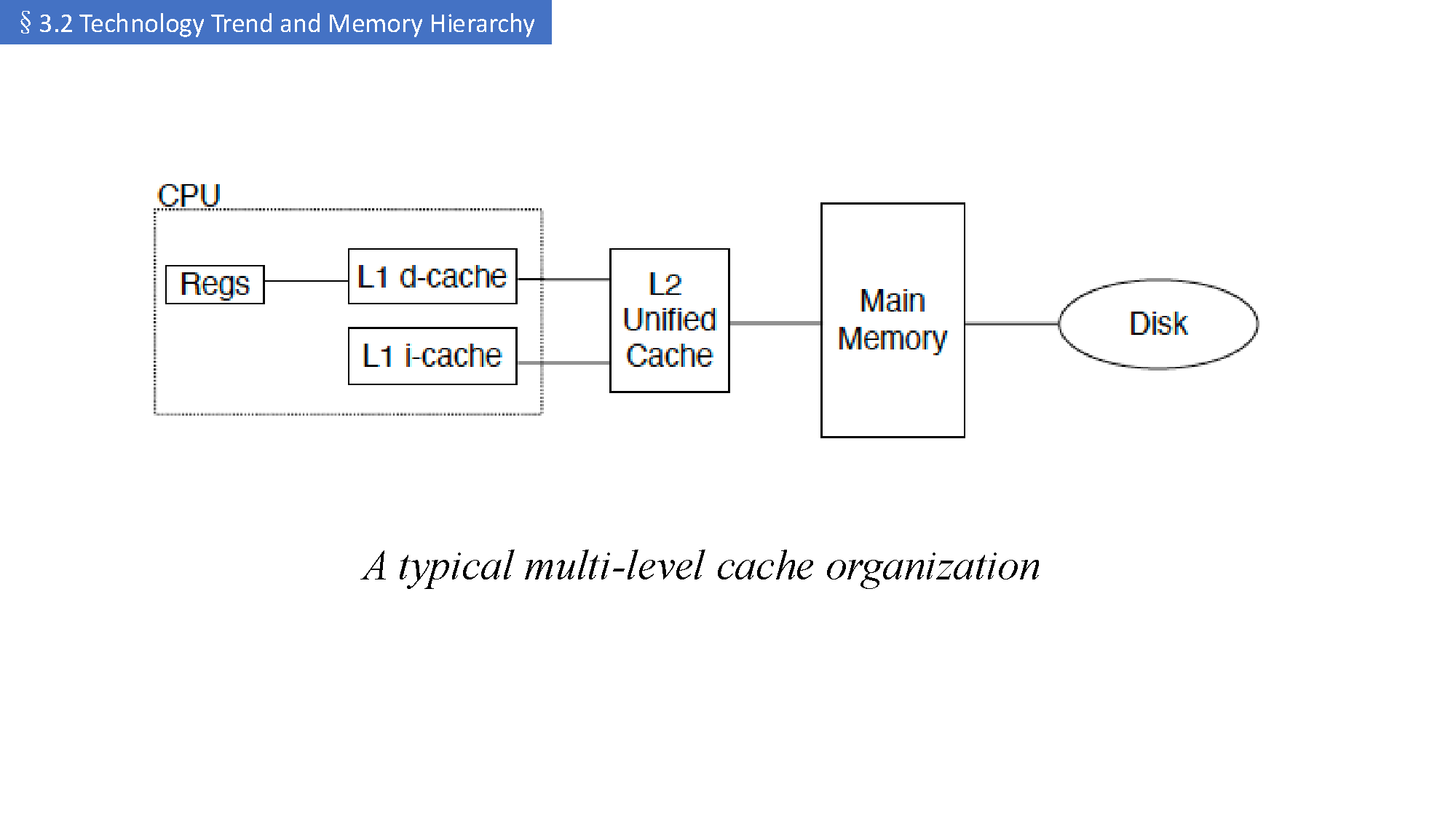
-
cache 往往不是单级的,而是多级的
- L1 最小最快;
- L2 更大但更慢;
- 再往下才到 main memory。
-
I-cache / D-cache 可能是分开的
- instruction cache(指令 cache)
- data cache(数据 cache)
这就引出了后面常见的 split vs unified。
Cache Miss
miss 发生以后,miss 所需时间主要有两部分:
-
latency(延迟)
- 取回 block 的第一个 word 所需要的时间。
-
bandwidth(带宽相关时间)
- 在第一个 word 到达之后,把这个 block 其余部分传完所需要的时间。
miss penalty(失效代价):
- 第一个字到来的等待;
- 整个 block 传输完成的等待。
这也是为什么 block size 不是越大越好的原因:
- block 大,空间局部性利用得更充分;
- 但一次 miss 时要搬的数据更多,miss penalty 也会变大。
3C Misses
Compulsory / Capacity / Conflict
cache miss 常见地分成三类,也就是经典的 3C model:
-
Compulsory miss(强制失效)
- 第一次访问某个 block;
- cache 之前从来没见过它,所以必 miss。
-
Capacity miss(容量失效)
- cache 容量不够;
- 某个 block 被挤掉了,之后又要重新取回来。
-
Conflict miss(冲突失效)
- cache 不是 fully associative;
- 不同 block 因为映射到同一位置/同一组,互相挤掉。
这三类 miss 后面会反复影响设计选择:
- 增大 block size 往往主要影响 compulsory miss;
- 增大 cache size 通常主要缓解 capacity miss;
- 提高 associativity 通常主要缓解 conflict miss。
Split Cache vs Unified Cache
split cache(分离式 cache) unified cache(统一 cache)
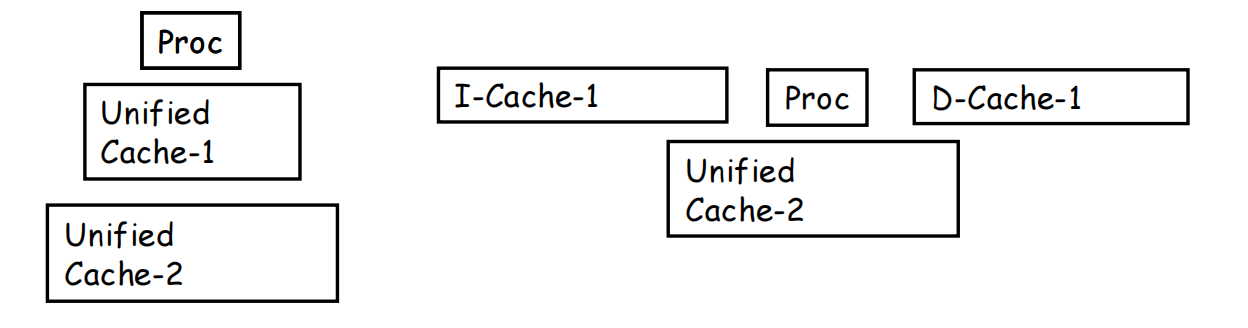
-
Unified cache
- 所有 memory request 都经过同一个 cache;
- 硬件更省;
- 但容易产生指令和数据的竞争。
-
Split I-cache / D-cache
- 指令和数据分别走不同的 cache;
- 硬件更多;
- 但前端取指和数据访问的并行性更好。
L1 一般是 split
- 因为最靠近 CPU,需要尽量高带宽;
- I-cache 只读,逻辑也更简单。
更低层如 L2/L3 一般是 unified
- 因为这一级更关注容量共享和整体利用率。
Three classes of computers with different concerns in memory hierarchy
-
Desktop computers
- 通常以单用户、单应用体验为主;
- 更关注 average latency(平均延迟)。
-
Server computers
- 同时服务很多用户和应用;
- 更关注 bandwidth(带宽)。
-
Embedded computers
- 常是实时场景;
- 更关注 worst-case performance、功耗和电池寿命;
- 保护需求有时没那么强,主存也可能很小,甚至没有 disk。
- cache 设计没有唯一最优;
- 同样的 hierarchy,在不同系统目标下会选出不同折中。
Four Questions for Cache Designers
对于 cache / memory hierarchy 设计者来说,最基本的就是四个问题。
- Where can a block be placed?
- How is a block found if it is there?
- Which block should be replaced on a miss?
- What happens on a write?
Q1:Block Placement
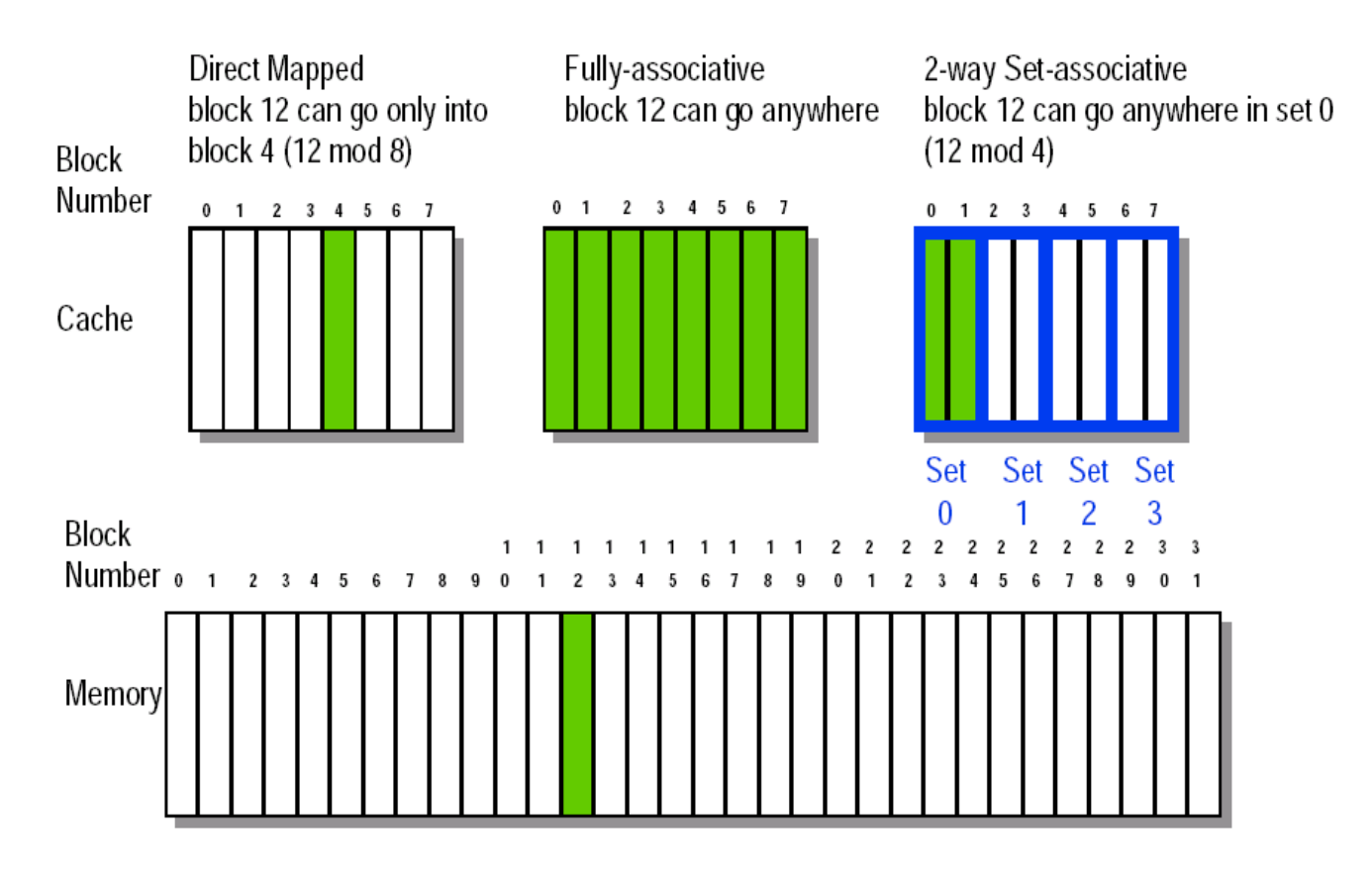
Direct Mapped
direct mapped cache(直接映射) :
一个 memory block 只能去 cache 里的一个固定位置。
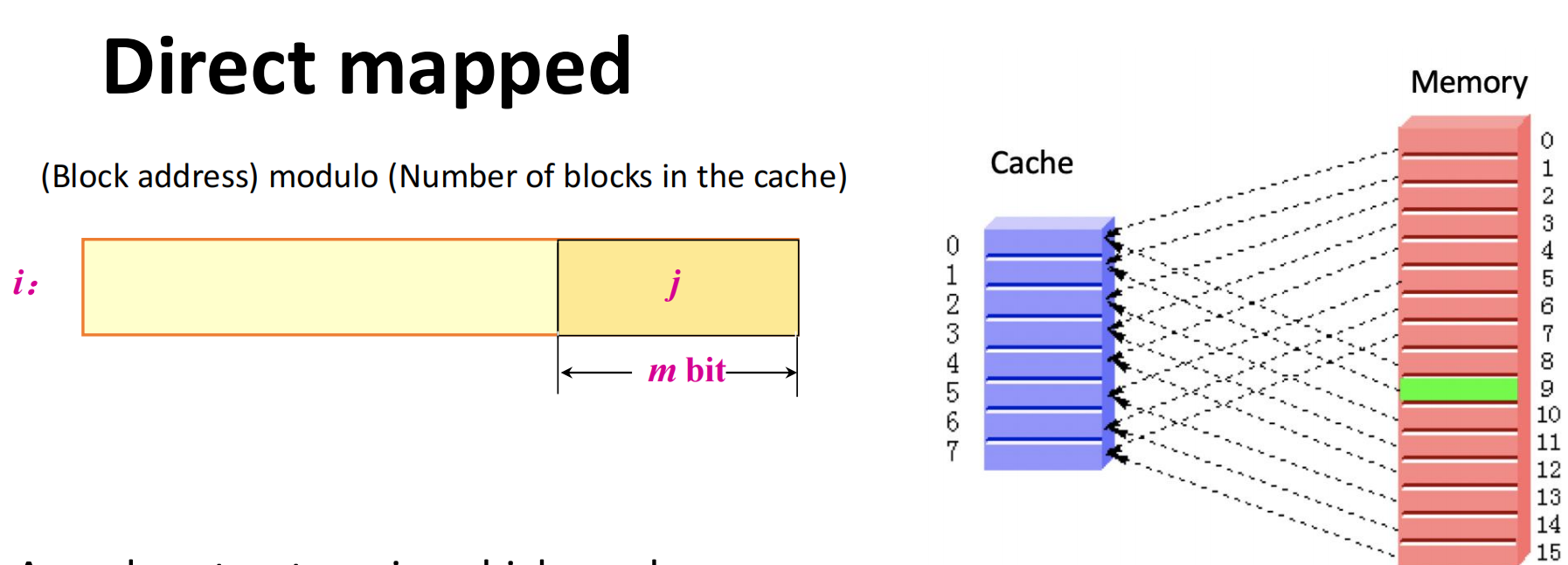

优点:
- 实现最简单;
- 查找快;
- hit time 往往较小。
缺点:
- 灵活性最差;
- 很容易出现 conflict miss。
Fully Associative
fully associative cache(全相联) : 一个 memory block 可以放到 cache 中任意位置。
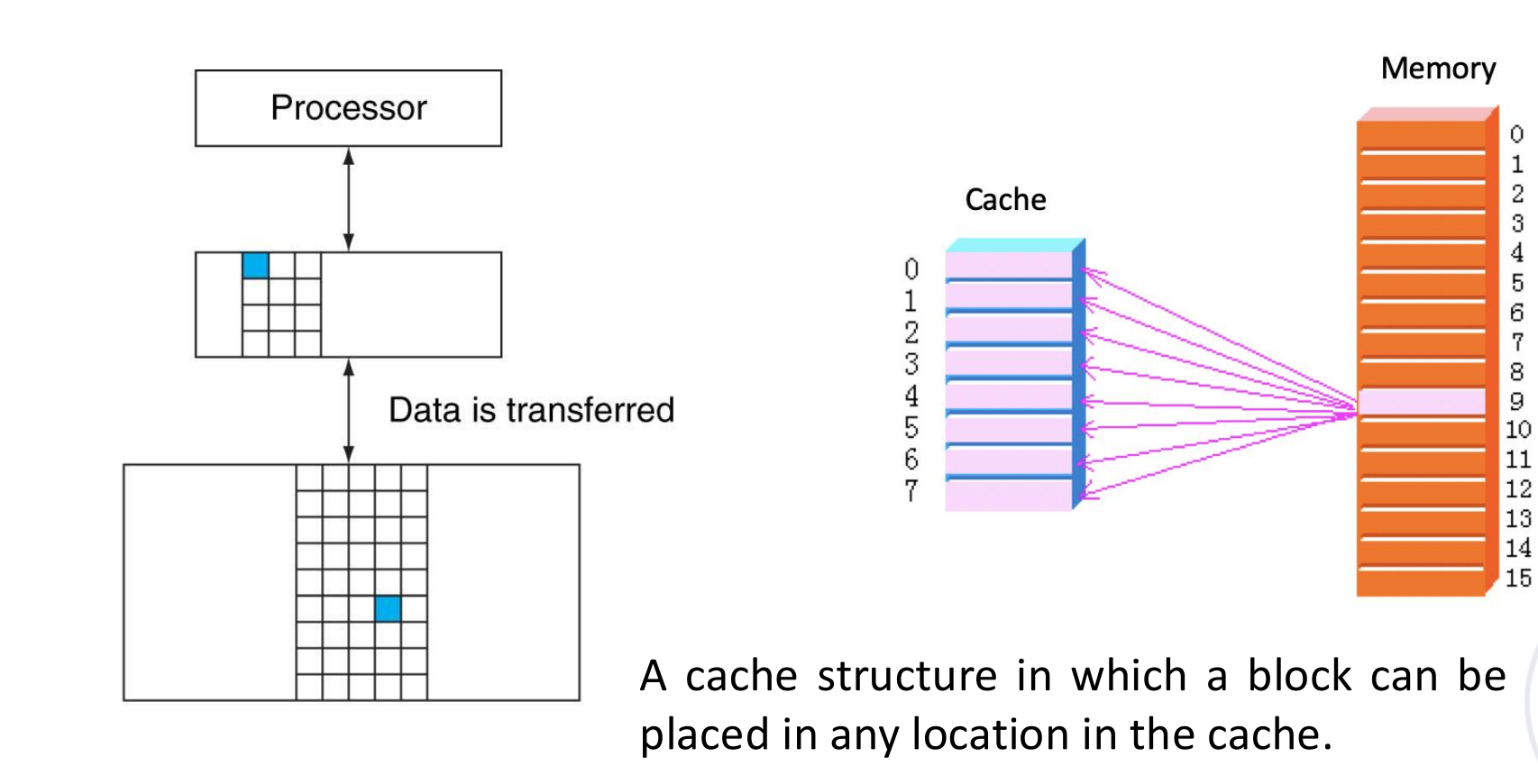
优点:
- 放置最灵活;
- conflict miss 最少。
缺点:
- 查找最贵;
- 需要比较所有 tag;
- 硬件开销大。
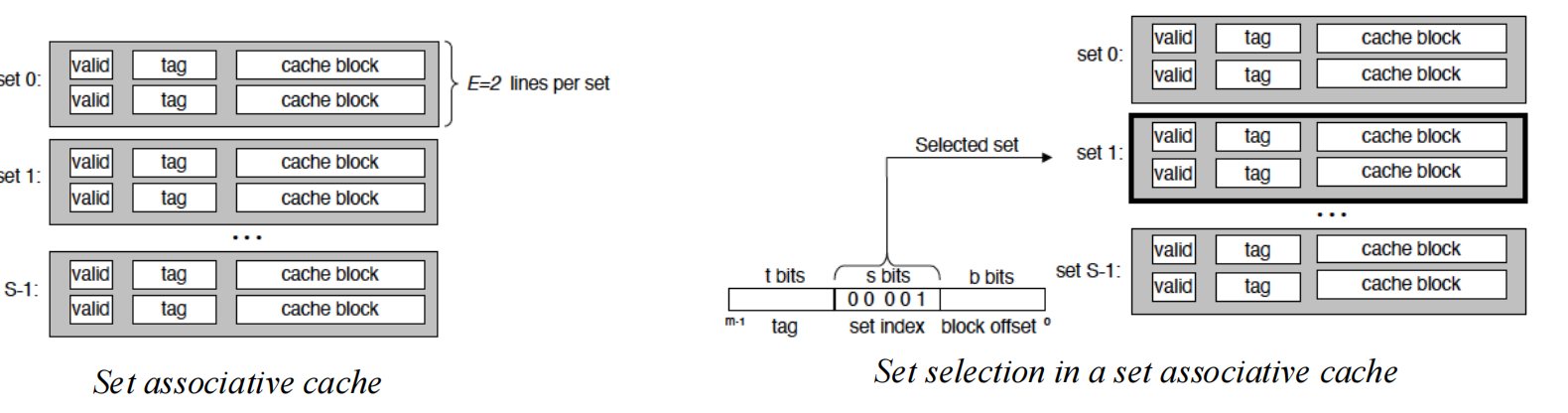
Set Associative
set associative cache(组相联) 处于两者之间。
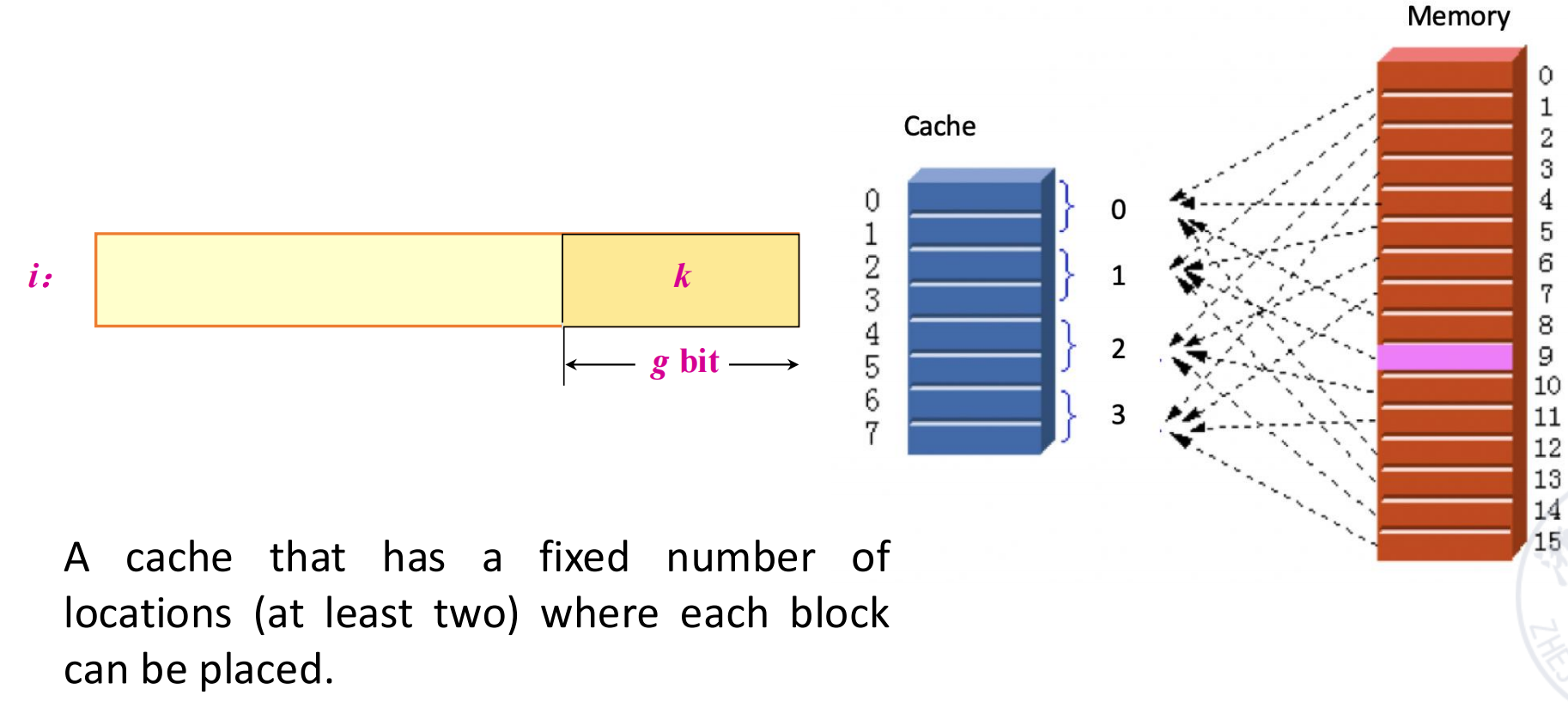
如果是 n-way set associative,表示:
- cache 被分成若干 set(组);
- 每个 set 里有
n个 block; - 一个 memory block 先确定自己属于哪一组;
- 进入该组后,再从这组里的
n个位置中挑一个。
三者其实可以都看作 Set Associative:
- direct mapped =
1-way set associative - fully associative = 整个 cache 只有一组
TIP
- associativity 不是越大越好;
- associativity 越高,冲突越少,但查找和 replacement 逻辑也越复杂;
- 实际系统里,很多 cache 的 associativity 常见是
n ≤ 4。
NOTEwhy index with the middle bits。
核心原因是:
- 低位已经被 block offset 占掉,不能再用来选 set;
- 如果直接拿高位做 index,那么很多连续地址会扎堆映射到同一个 set;
- 这会破坏空间局部性本来带来的好处。
所以更常见的做法是:
- 保留最低位给 offset
- 用中间若干位做 index
- 把更高位留给 tag
这样连续地址更容易分散到相邻 set,局部性利用会更自然。

Example
设:
- :Cache 总块数
- :每组中的块数,即相联度(associativity)
- :组数(number of sets)
则有:
-
全相联(full-associative)
- 整个 Cache 只有一组,主存块可放入任意 Cache 块中
-
直接映射(direct mapped)
- 每组只有一个块,主存块只能映射到唯一位置
-
组相联(set-associative)
- 主存块先映射到某一组,再放入该组内任意一个块中
相联度 越大,优点:
- Cache 空间利用更充分
- 块冲突(block collision) 更少
- 冲突失效(conflict miss) 降低
- 整体 miss rate 往往下降
缺点:
- 命中判断更复杂,需要比较更多 tag
- 硬件成本更高
- 功耗增加
- 命中时间(hit time)可能变长
- 替换策略(如 LRU)实现更复杂
实际设计中,大多数 Cache 的相联度不会太高,常见为:
即通常采用 2-way 或 4-way set-associative cache。
Q2:Block Identification
Q1 解决的是能放哪;Q2 解决的是放进去以后怎么找到它。
这就引出 cache address format(地址格式):
- Tag
- Index
- Byte Offset

其中:
-
Index
- direct mapped 时选中某一行;
- set associative 时选中某一组。
-
Byte Offset
- 选中 block 内具体哪个字节;
- 如果 block 有多个 word,还可以再细分 word offset。
-
Tag
- 用来确认“这一行/这一组里放的到底是不是我要的 block”。
此外每个 cache line 通常还带有:
- valid bit(有效位)
它表示:
valid = 0:这行目前无效,没有可用数据;valid = 1:这行里确实放了某个有效 block。
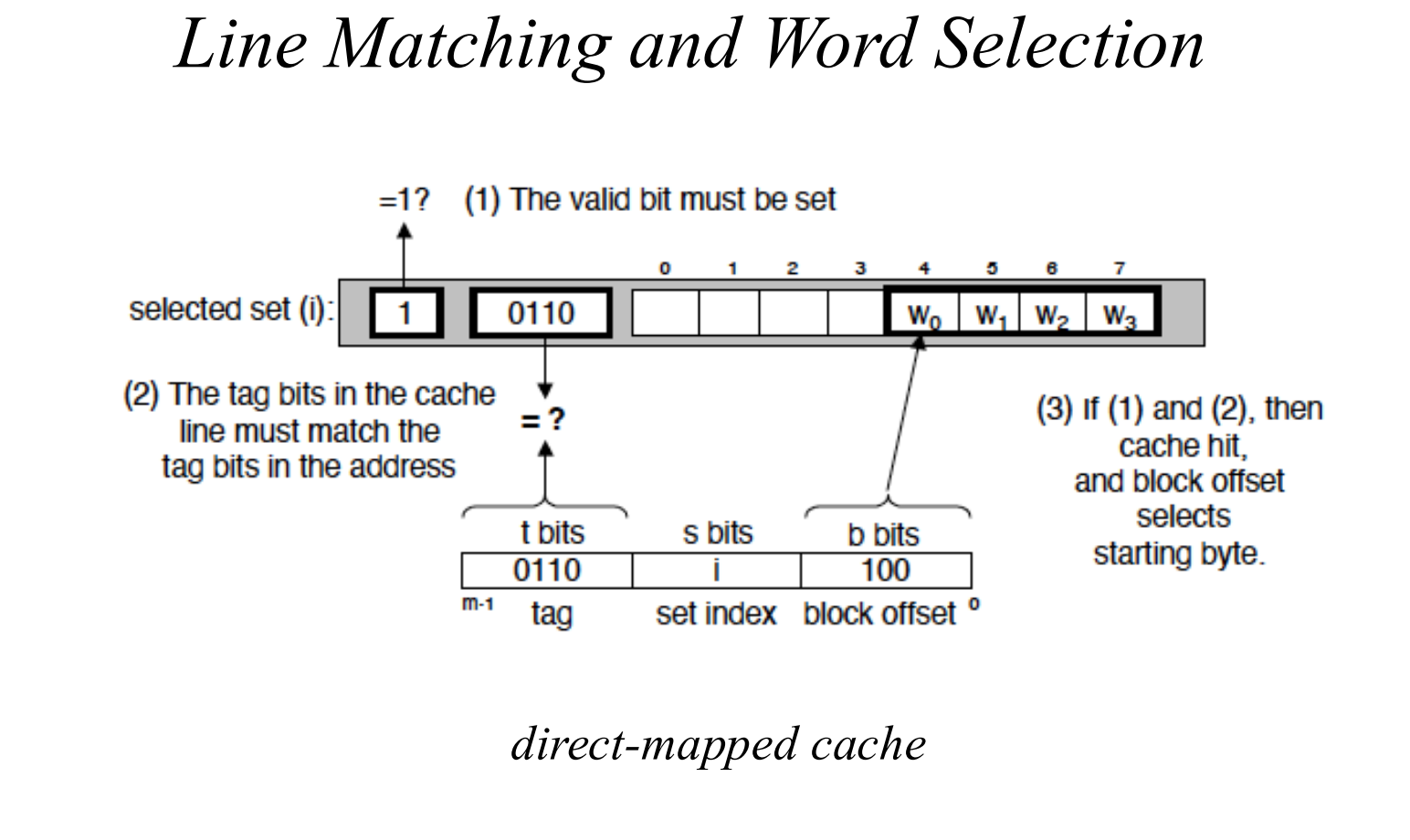
一次访问的判断顺序:
- 根据 index 找到对应行/对应组;
- 先看 valid bit;
- 再比较 tag;
- 若命中,再根据 offset 取出具体数据。
- 先看 valid
- 再看 tag
- 最后才是 offset 取值
查找方式
Direct Mapped
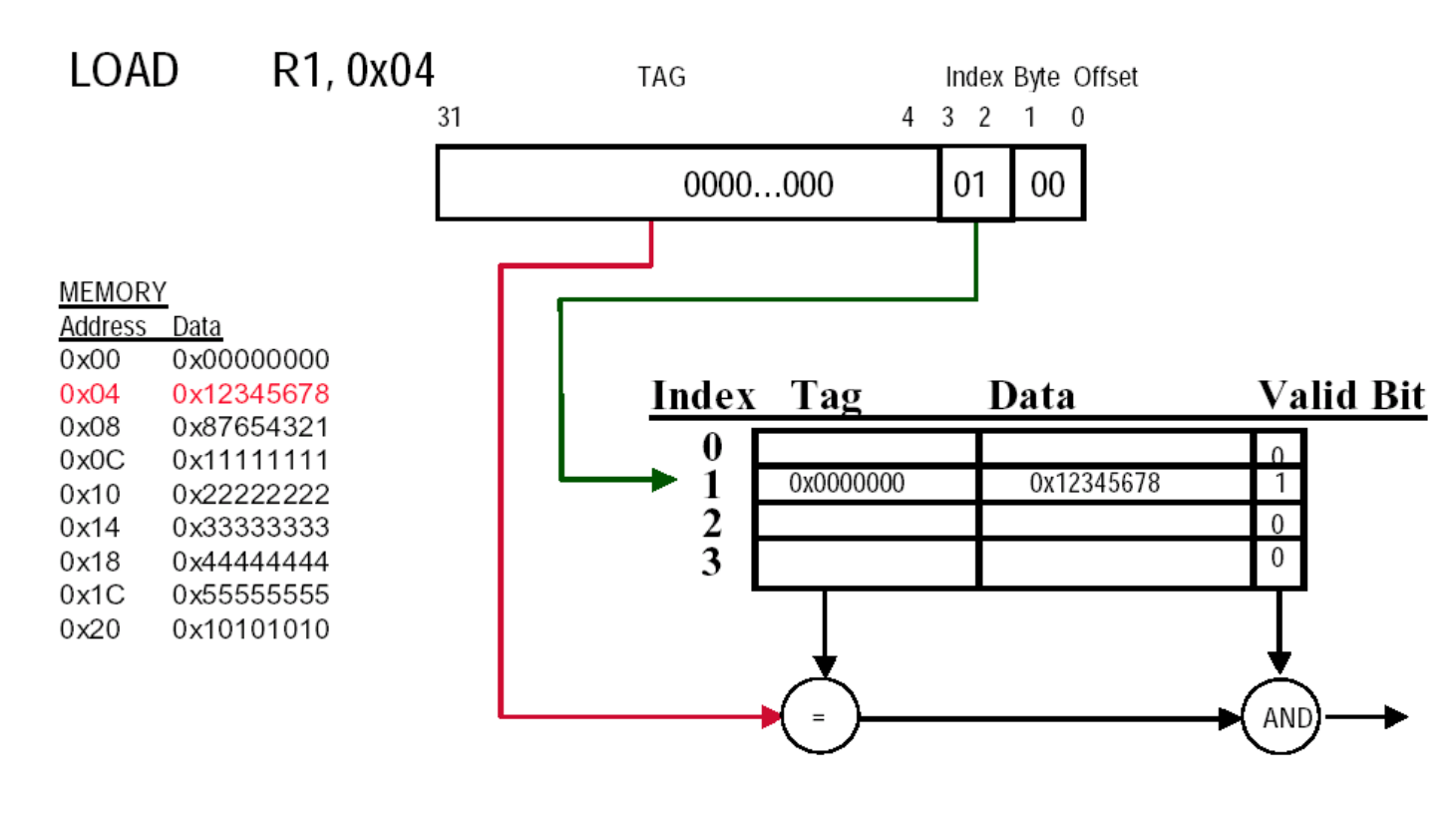

- index 选中唯一一行;
- 看这一行的 valid;
- 再把请求地址的 tag 和该行的 tag 比较;
- 相等则 hit,否则 miss。
特点:
- 查找路径最短;
- 但如果别的 block 映射到同一行,就一定会冲突。
Fully Associative
Assume cache has 4 blocks
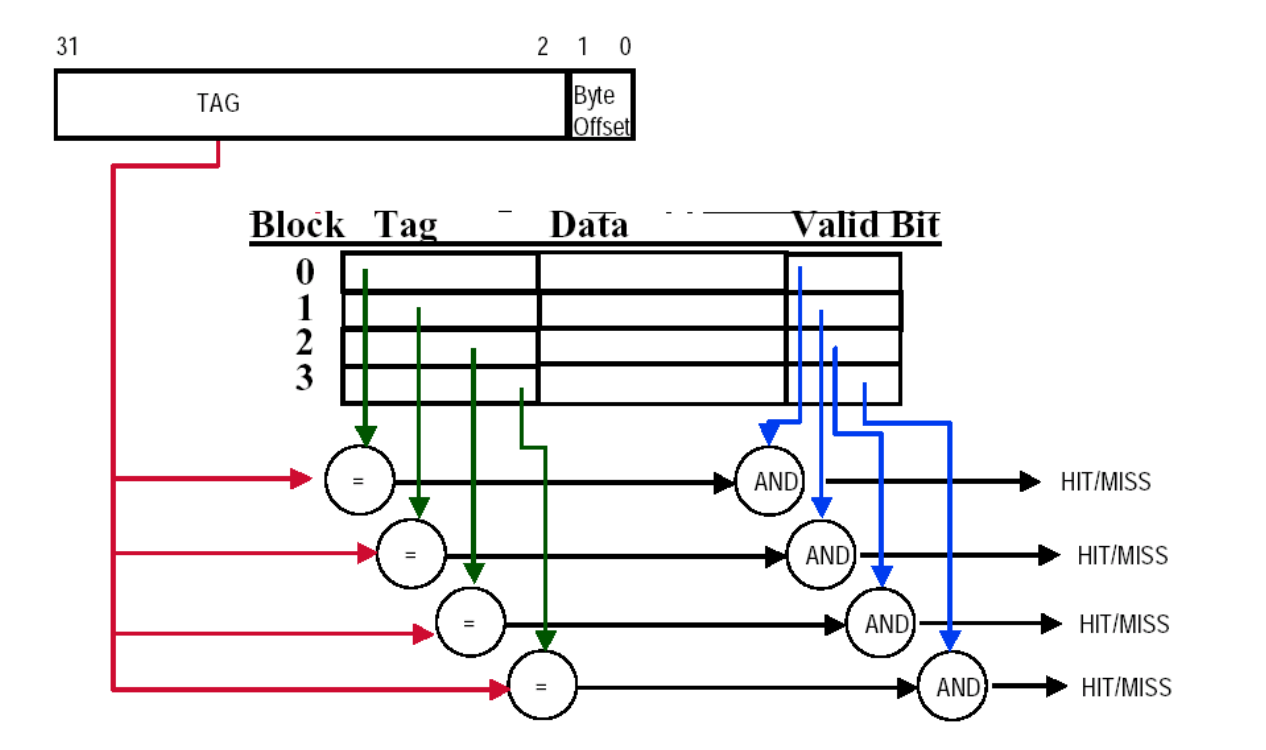

fully associative 最灵活,也最贵:
- 没有传统意义上的 index;
- 访问时必须对所有行的 tag 做比较;
- 任意一行匹配就算 hit。
因此它通常只在规模较小、对灵活性要求很高的结构里更适合。
Set Associative
- Assume cache has 4 blocks and each block is 1 word
- 2 blocks per set, hence 2 sets per cache
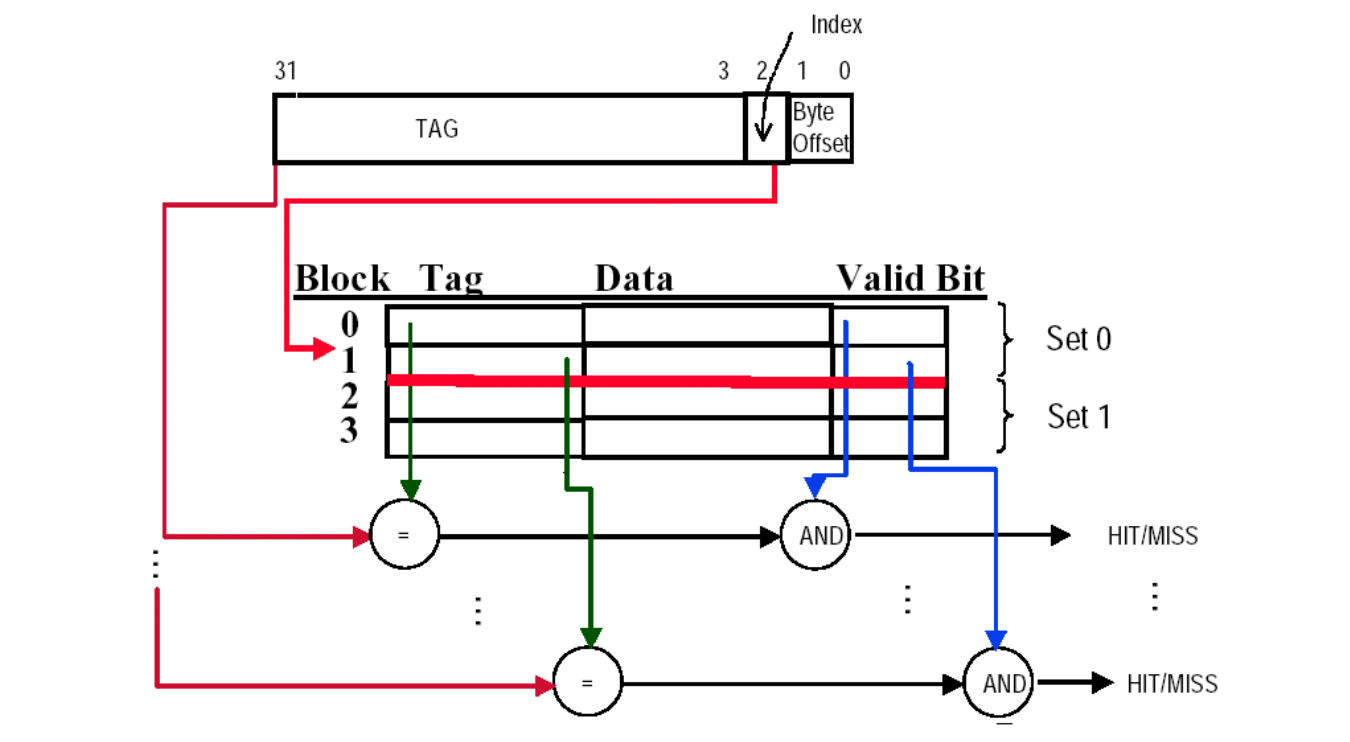
- index 先选中一组;
- 组内每一行都要看 valid,并比较 tag;
- 只要组内某一行匹配,就 hit。
因此它比 direct mapped 多出来的,是:
- 组内并行比较多个 tag;
- 以及 miss 时还得在组内决定替换谁。
FSM Control Simple Cache
Cache 的行为是一个时序过程。
一次访存请求到来后,控制器可能需要依次完成:
- 接收 CPU 请求
- 比较 Tag
- 判断命中 / 失效
- 判断被替换块是否为脏块(dirty)
- 若脏,则先写回主存(write-back)
- 再从主存读入新块(allocate)
- 最后通知 CPU Cache 已准备好
Cache Controller 适合建模成一个 有限状态机。
FSM
一个有限状态机通常包括三部分:
- 当前状态(current state)
- 输入(inputs)
- 输出(outputs)
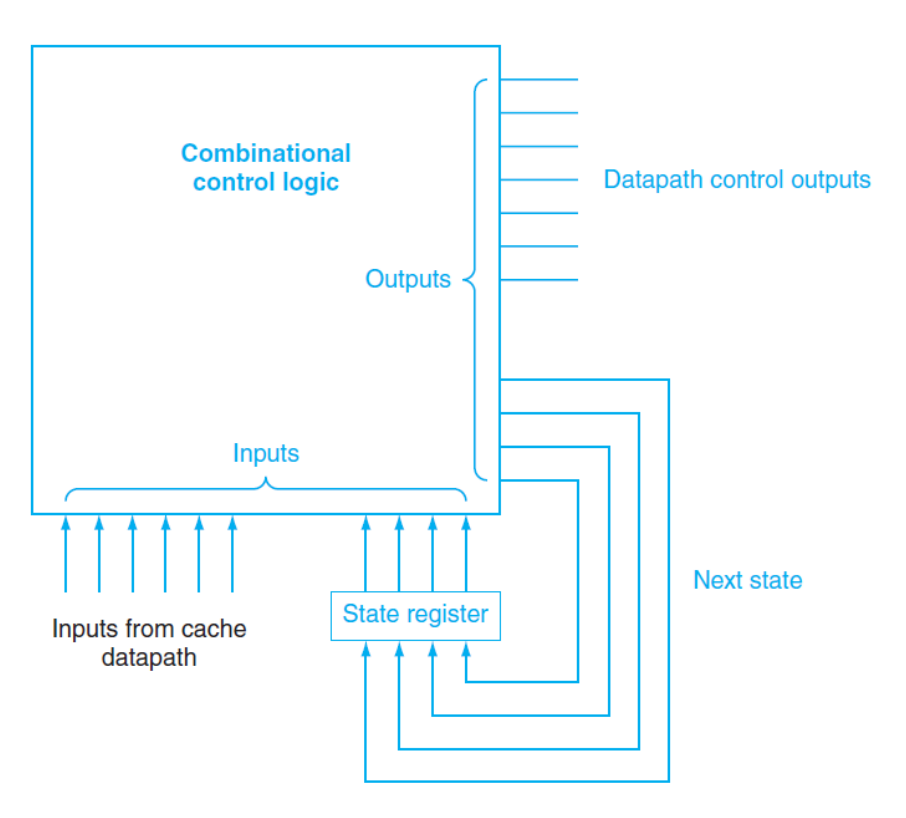
并由两类逻辑决定行为:
- 下一状态函数 根据:当前状态、当前输入,决定:下一拍进入哪个状态
- 输出函数
根据:当前状态、有时还包括输入,产生:对数据通路(datapath)的控制信号
例如:是否读主存、是否写主存、是否更新 valid/tag/dirty、是否通知 CPU ready 等。
State Machine
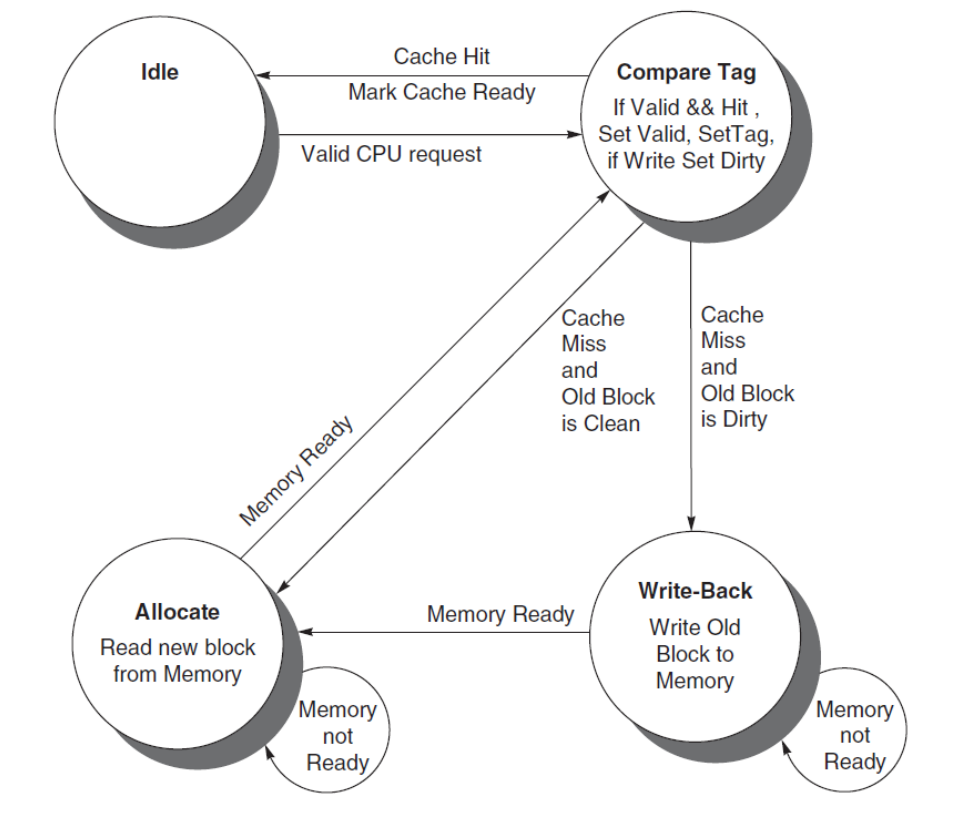
Idle
空闲状态,表示当前没有正在处理的 Cache 请求。
- 如果收到 valid CPU request
- 则进入 Compare Tag
Compare Tag
比较 Tag,判断当前访问是 cache hit 还是 cache miss。
- 检查对应块是否 valid
- 比较 tag 是否匹配
- 若命中:
- 读请求:直接返回数据
- 写请求:更新 cache 内容,并把 dirty 位置 1
- 然后返回 Idle
- 同时向 CPU 发出 cache ready
若失效(miss),则还要进一步判断被替换的旧块是否为脏块:
- 旧块干净(clean) → 进入 Allocate
- 旧块是脏块(dirty) → 进入 Write-Back
Write-Back
写回状态,把被替换的旧脏块写回主存。
- 如果 memory ready
- 写回完成后进入 Allocate
- 如果 memory not ready
- 停留在当前状态等待
只有在替换脏块时,才需要真正写主存。
Allocate
分配状态,从主存中读取新块到 Cache。
- 如果 memory ready
- 新块装入 Cache
- 然后回到 Compare Tag
- 如果 memory not ready
- 停留在当前状态等待
Compare Tag :新块装入后,还要重新完成一次当前 CPU 请求的命中访问。
- exception 处理往往要保存大量架构状态;
- cache miss 更像是 stall / freeze 当前机器状态,等数据回来后再继续。
Cache 容量计算
- 地址长度: bits
(例如 64 位地址时,) - Cache 数据区共有 个 cache line(或 block)
- 每个 block 大小为 words
- 每个 word = 4 bytes = 32 bits
- 相联度(associativity)为
- direct-mapped:
- -way set-associative:
- full-associative:
- 组数为
则有:
地址划分
一个地址通常划分为:
其中:
- Byte offset:2 bits
(因为 1 word = 4 bytes) - Block offset: bits
(因为每块有 words) - Set index: bits
- Tag:剩余高位
所以:
行存储内容
每个 cache line 至少包含:
- Data
- Tag
- Valid bit
若考虑 write-back cache,还常常需要:
- Dirty bit
因此每一行总位数可写成:
- 不考虑 dirty 位
- 考虑 dirty 位
完整 Cache 容量的一般公式
完整 Cache 容量 = 行数 × 每行位数
- 不考虑 dirty 位
- 考虑 dirty 位
Direct-Mapped Cache
direct-mapped 时:
- 相联度
- 每组 1 行
- 所以:
因此:
- tag 位数
- 完整容量 不计 dirty
计 dirty
-way Set-Associative Cache
-路组相联时:
- 每组 行
- 组数:
所以:
- tag 位数
- 完整容量 不计 dirty
计 dirty
Full-Associative Cache
full-associative 时:
- 相联度
- 整个 Cache 只有 1 组
- 所以:
因此:
- tag 位数
- 完整容量
不计 dirty
计 dirty
数据容量:
Example
Example 1
一个 16 KiB data 的 direct-mapped cache,block size 是 4 words,地址长度 64 bit。问这个 cache 一共需要多少 bit?
16 KiB = 2^14 bytes = 2^12 words- block size =
4 words = 2^2 words
因此:
- block 内 word offset 需要
- cache block 数量为
所以:
- block 内一共有
4 words = 16 bytes,因此 block 内总 offset 为:
2 bit选 word2 bit选 byte
- tag 位数为:
每个 block 里保存的内容包括:
- data:
4 × 32 = 128 bit - tag:
50 bit - valid:
1 bit
因此每个 block 总位数:
总块数是 1024,所以 cache 总位数为:
换成字节就是:
cache 的总实现开销并不只是 data 本身,还要把 tag 和控制位一起算进去。
Example 2
一个 cache 有
64 blocks,每个 block 大小是16 bytes。问 byte address1200会映射到哪个 cache block number?
先算 block address:
再对 cache block 数取模:
所以地址 1200 对应的 cache block number 是:
而且不仅 1200,地址 1200 到 1215 都属于同一个 16-byte block。
- cache 搬运的基本单位是整个 block
- 不是某个单独的 byte,也不是某个单独的 bit
Example 3
direct-mapped 访问过程
-
data cache 大小:
16KB -
direct-mapped
-
block size:
4 words -
依次读取 4 个地址:
0x000000140x0000001C0x000000340x00008014
-
主存
这里 block size 是 4 words = 16 bytes,因此:
- byte offset 一共
4 bit - cache block 数量
= 16KB / 16B = 1024 - index 一共
10 bit
四个地址的核心信息:
| 地址 | block address | index | tag | offset |
|---|---|---|---|---|
0x00000014 | 1 | 1 | 0 | 0x4 |
0x0000001C | 1 | 1 | 0 | 0xC |
0x00000034 | 3 | 3 | 0 | 0x4 |
0x00008014 | 2049 | 1 | 2 | 0x4 |
1. Read 0x00000014
index = 1,此时假设机器刚上电,cache 全空:对应行 valid = 0
- 没有有效数据;
- 发生 cache miss(失效)。
下一步:
- 到 memory 中把对应 block
[0x10, 0x14, 0x18, 0x1C]取回来; - 把 tag 写入该行;
- 把 valid 置 1;
- 再根据 offset 取值。
因为 0x14 在这个 block 中的 offset 是 0100,对应的就是第二个 word,因此返回:
2. Read 0x0000001C
index = 1这次和上一步一样,还是同一行。此时:
valid = 1- tag 也匹配
这是一次 cache hit(命中)。
然后根据 offset:
0x1C对应该 block 中最后一个 word
所以返回:
这刚好说明 spatial locality:
- 虽然第一次只想读
0x14; - 但因为整个 block 已经被搬上来;
- 所以随后访问同一个 block 内的
0x1C直接 hit。
3. Read 0x00000034
- block address =
3 - index =
3
对应行一开始无效,所以:
valid = 0- 发生 miss
于是把 [0x30, 0x34, 0x38, 0x3C] 这一整块数据装入对应 cache line。
再看 offset:
0x34对应第二个 word
因此返回:
4. Read 0x00008014
wrong data miss
先看 index:
0x00008014 / 16 = 0x801 = 20492049 mod 1024 = 1
所以它还是落在 index = 1 这行。
但现在这行里原本放的是:tag = 0
而当前请求地址需要的是:tag = 2
- valid 是 1;
- 但 tag 不匹配;
- 这不是空,而是这行已经放了“别的 block”。
于是发生:
- cache miss
- 且必须 replacement(替换)
因为是 direct mapped,能替换的只有这一行本身。
新 block [0x8010, 0x8014, 0x8018, 0x801C] 进入该行后,再按 offset 取值,得到:
可以把四次访问汇总成表:
| 访问地址 | 状态 | 关键原因 | 返回值 |
|---|---|---|---|
0x00000014 | miss | 对应行无效 | b |
0x0000001C | hit | valid 且 tag match | d |
0x00000034 | miss | 对应行无效 | f |
0x00008014 | miss + replacement | valid 但 tag mismatch | j |
5. Read 0x00000030
- block address =
3 - index =
3 - 当前该行 valid = 1
- tag 仍然匹配
因此:
- hit
- offset =
0 - 返回该 block 的第一个 word
6. Read 0x0000001C
第二次访问 0x0000001C 时它 hit 过;
但第四次访问 0x00008014 时,同一个 index = 1 的那一行已经被替换掉了。
因此现在再来读 0x0000001C:
- index 仍然是
1 - valid 仍然是
1 - 但 tag 已经不再是
0,而是2
所以这次:
- miss
- 且是 tag mismatch 导致的 replacement miss
把原来的 [0x10, 0x14, 0x18, 0x1C] 再装回来后,根据 offset 取到:
Q3:Block Replacement
Q3 解决的是:
miss 之后,如果可以放的位置不止一个,或者目标位置已经被占了,到底替换谁?
direct mapped 也会发生 replacement,只是它没有 replacement policy 的选择空间
需要选择策略的的,是:
- set associative
- fully associative
替换策略
常见的替换策略有:Random / FIFO / LRU / OPT
Random
- 随便选一个 block 替换;
- 实现成本低;
- 硬件上甚至只需要一个随机数发生器。
优点:
- 不跟踪复杂历史;
- 平均意义上也未必很差。
缺点:
- 可能刚好把马上又要用的数据替换掉。
FIFO
FIFO(First In, First Out)
- 谁先进入这组;
- 谁就先被替换掉。
优点:
- 比 LRU 简单;
- 容易实现。
缺点:
- 可能把虽然进来较早、但其实还在频繁使用的数据赶走。
LRU
LRU(Least Recently Used,最近最少使用) 是最经典也最符合 locality 直觉的策略之一:
- 认为最近刚访问过的 block,更可能很快又被访问;
- 因此优先淘汰最久没被访问过的 block。
既然无法预测未来,那就让已经发生的访问历史来帮助猜测未来。
优点:
- 和 temporal locality 很契合;
- 通常表现优于纯随机和 FIFO。
缺点:
- 需要额外记录访问顺序;
- associativity 一大,硬件代价就会上升得很快。
OPT
OPT(Optimal replacement) :
- 如果真的知道未来;
- 那就淘汰未来最晚才会再被访问,甚至根本不再访问的那个 block。
它当然性能最好,但基本不能真实实现,因为:
- 它需要已知未来访问序列。
OPT 的意义更多是作为理论最优上界;
Example
2, 3, 2, 1, 5, 2, 4, 5, 3, 4
- cache block 数量:
3 - 访问序列:
2, 3, 2, 1, 5, 2, 4, 5, 3, 4hit 次数:
| 策略 | 命中次数 | 评论 |
|---|---|---|
| FIFO | 3 | 只看进入顺序,容易换错对象 |
| LRU | 4 | 更符合 temporal locality |
| OPT | 5 | 理论最优,因为“知道未来” |
- replacement policy 确实会直接影响 hit rate;
- 而 hit rate 的变化,最终又会传导到
miss rate和AMAT。
Thrashing and Belady Anomaly
Thrashing
如果工作集比 cache 能承受的更大,并且访问序列不断在几组数据之间来回切换,就会出现 thrashing(抖动)。
典型序列:
1, 2, 3, 4, 1, 2, 3, 4当 cache 太小、映射又不友好时:
- 刚装进来的数据很快又被挤掉;
- hit 非常少;
- 系统大部分时间都花在 miss 和 replacement 上。
thrashing 的本质就是:
- 工作集大于有效 cache 容量
- 映射冲突太严重
Belady Anomaly
Belady anomaly(Belady 异常) :
某些替换算法下,cache block 数量增加,hit rate 反而可能下降。
也就是说,block 数变多并不自动保证命中率一定提升。
这件事最常见于 FIFO 这类不具备 stack property 的算法。
而对 LRU 来说:
- hit ratio 会随着 block 数增加而单调不减;
- 这正是它作为 stack replacement algorithm(栈型替换算法) 的重要性质。
Stack Property
含义是:
- 在时间
t,容量为n的 cache 中保存的 block 集合; - 一定是容量为
n+1的 cache 中 block 集合的子集。
这个性质说明:
- cache 容量增加时,LRU 不会丢掉原本更小 cache 能保住的数据;
- 所以其 hit rate 不会因为 block 数增加而下降。
所以 LRU 在 n 增加时,hit rate 不会下降;而 FIFO 就没有这个保证,可能出现 hit rate 反而下降的情况。
Comparison Pair
如果想精确实现 LRU,可以使用 comparison pair method(成对比较法)。
基本思想是:
- 对组内每两个 block 记录谁比谁更新近;
- 然后用这些 pairwise 状态推导出谁是最久未使用者。
例如 3 个 block A, B, C 时,可以维护:
T_ABT_ACT_BC
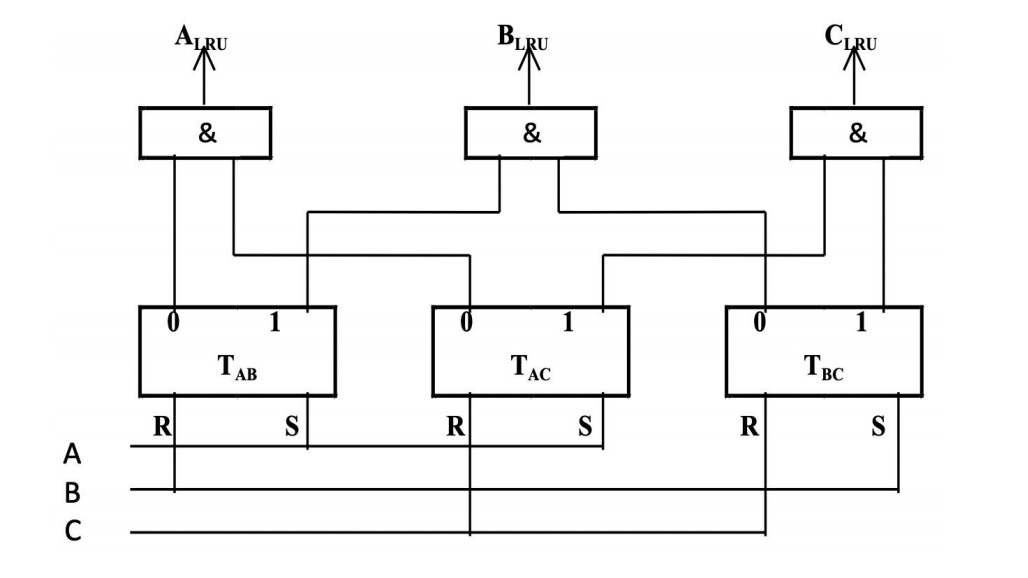
但这个方法的代价增长非常快。
- 3 个 block:需要
3个 flip-flop - 4 个 block:需要
6个 flip-flop - 8 个 block:需要
28个 flip-flop - 64 个 block:需要
2016个 flip-flop
所以:
- 精确 LRU 在 associativity 较高时硬件代价非常大
- 这也是为什么实际处理器里经常用 pseudo-LRU(近似 LRU),而不是严格 LRU
Q4:Write Strategy
Q4 讨论的是:
如果这次访问是 write,会发生什么?
- write hit 时怎么写
- write miss 时怎么写
而这两层组合起来,才构成完整的 write policy。
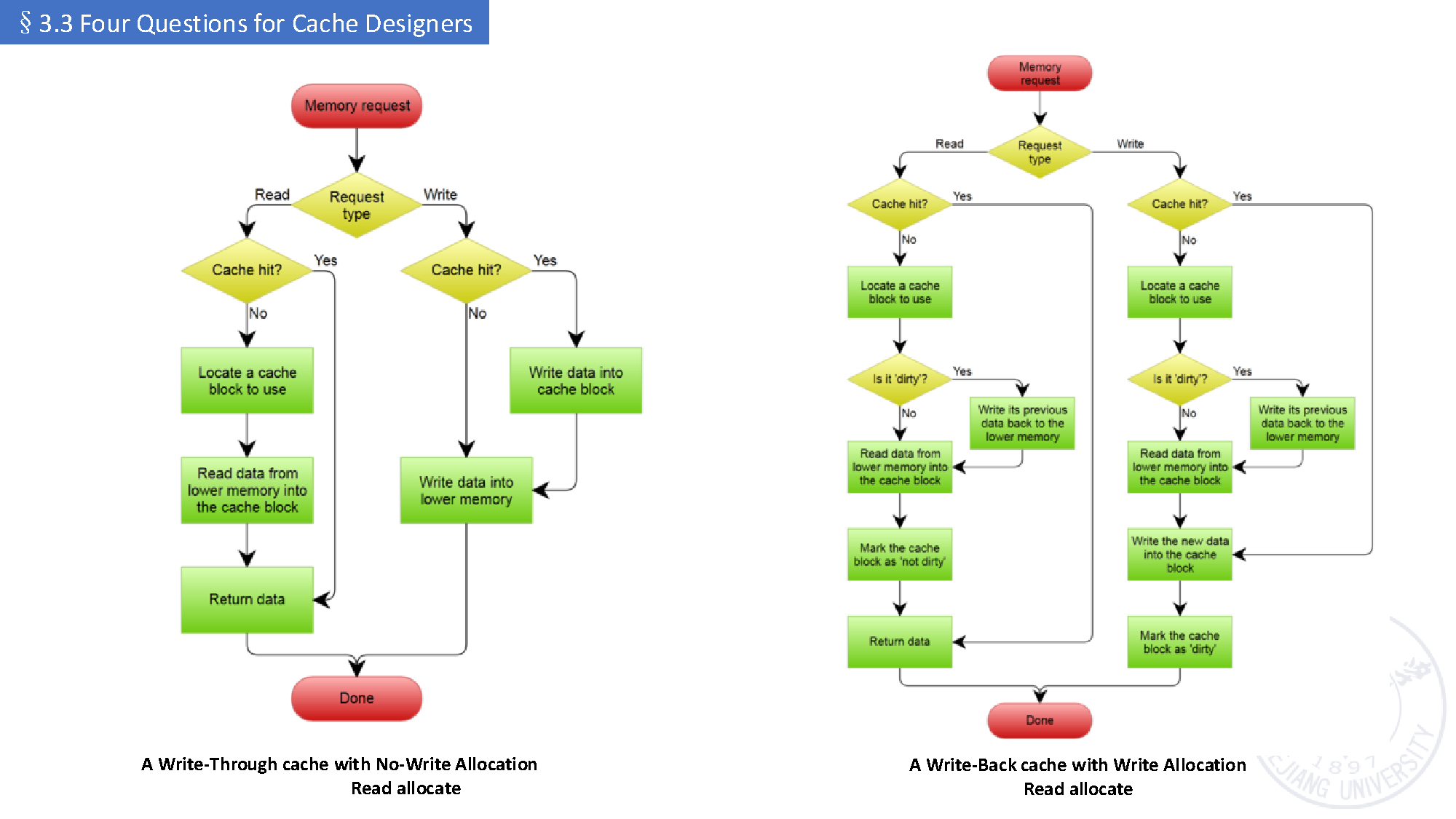
-
write-through + no-write-allocation
- 结构简单;
- 写 miss 直接往下写;
- 不在 cache 中留副本。
-
write-back + write-allocation
- 流程更长;
- replacement 时要检查 dirty;
- miss 时可能要先回写旧块,再装入新块,再更新数据。
Write Hit
Write-Through vs Write-Back
Write-Through
write-through(写直达) 的:
- 一次 write hit 时;
- 同时把数据写到 cache 和 main memory。
特点:
- 一致性强;
- main memory 永远保存最新值;
- 控制位通常只需要
valid bit。
优点:
- 语义直观;
- memory 中总是最新数据;
- 出现系统故障时,丢失尚未回写数据的风险更小。
缺点:
- 每次写都要碰 memory;
- memory bandwidth 压力大;
- 容易产生 write stall。
real-time systems(实时系统)、flight control(飞控)这些场景往往更在意:
- 数据一致性;
- 可预测性;
- 而不是单纯追求写性能。
所以会采用 write-through。
Write-Back
write-back(写回) 的规则是:
- write hit 时只改 cache;
- 先不立刻写 main memory;
- 等这个 block 之后被替换出去时,再把它写回下层。
这时就需要一个额外控制位:
- dirty bit(脏位)
它表示:
dirty = 1:cache 中这份数据已经被改过,但 main memory 还没同步;dirty = 0:cache 与 memory 中对应块内容一致。
优点:
- 大幅减少对 memory 的直接写入;
- 对局部反复写同一块数据的程序更友好;
- 性能通常更高。
缺点:
- 控制更复杂;
- replacement 时如果 block 是 dirty,还得先 write-back;
- 系统异常掉电时,cache 中尚未写回的数据可能丢失。
general-purpose processors(通用处理器)、desktop CPU系统通常更看重 average performance,一般会采用 write-back;
Write Miss
Write Allocate vs No-Write-Allocate
write miss 时,策略分歧主要在:
要不要先把目标 block 装进 cache?
Write Allocate
write allocate(写分配) :
- write miss 时;
- 先把对应 block 从 main memory 调到 cache;
- 再在 cache 中执行写操作。
它的思想体现:
- temporal locality:既然现在要写,后面可能还要读或继续写;
- spatial locality:同一 block 中的其他数据可能也很快用到。
因此 write allocate 常和 write-back 搭配,因为:
- 既然块已经进 cache 了;
- 后续对这个块的多次写就都能在 cache 中完成。
No-Write-Allocate
no-write-allocate(写不分配),也常叫 write around:
- write miss 时;
- 直接把数据写到 main memory;
- 不把该 block 拉进 cache。
优点:
- 避免把一次性写、以后很少再访问的数据塞进 cache;
- 防止 cache pollution(cache 污染)。
所以它更适合这类访问:
- 日志写入
- streaming data
- 很少被重新读取的写操作
常见组合
理论上 write hit 和 write miss 策略可以自由组合,但有两种最常见组合:
-
write-back + write-allocate
- 写 miss 时先把 block 调上来;
- 后续读写都更可能 hit;
- 真正回 memory 等 replacement 再说。
-
write-through + no-write-allocate
- 写 miss 时直接写 main memory;
- 不把数据引入 cache;
- 简单、直观,也避免无意义占用 cache。
性能优先 -> 更偏 write-back + write-allocate
一致性 / 可预测性优先 -> 更偏 write-through + no-write-allocate
Write Stall and Write Buffer
write-through 的一个直接问题是:
- 每次写都可能要等 main memory;
- CPU 很容易被迫停下来。
这就是 write stall(写停顿)。
一种非常常见的优化是:
- write buffer(写缓冲)
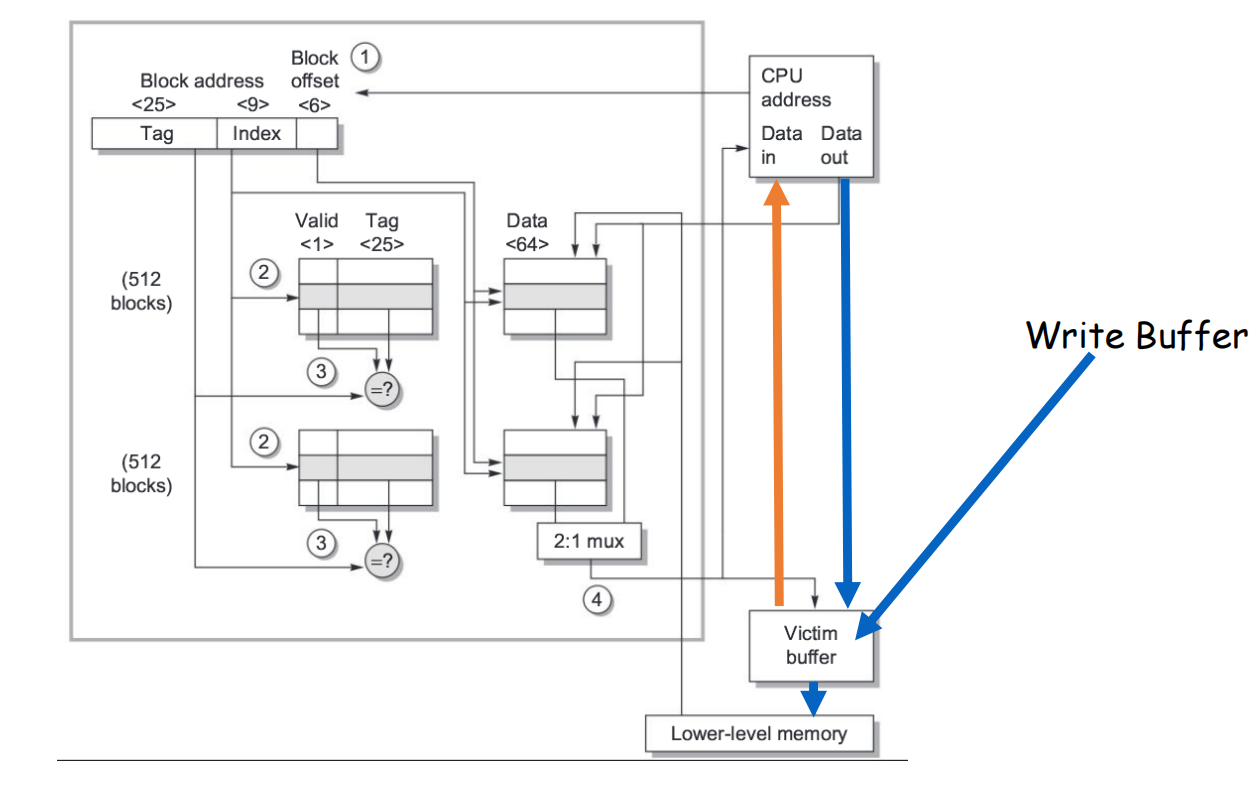
它的思路是:
- CPU 先把要直写的数据放入一个小 buffer;
- 然后继续执行后续指令;
- 由 buffer 在后台慢慢把数据推到 memory。
这样可以明显减轻 write-through 的性能损失。
但它也不是万能的,因为:
- 如果短时间内写太密集;
- buffer 还是可能被写满;
- 写满后 CPU 仍然要 stall。
Example
No-Write-Allocate vs Write-Allocate
条件:
- fully associative
- write-back
- cache 很大,不考虑 replacement
- 初始为空
- 访问序列如下:
1. write Mem[100]2. write Mem[100]3. read Mem[200]4. write Mem[200]5. write Mem[100]比较:
no-write-allocatewrite-allocate
Case 1:No-Write-Allocate
-
write Mem[100]- write miss
- 直接写 memory,不装入 cache
miss
-
write Mem[100]- cache 中仍没有这个 block
- 还是
miss
-
read Mem[200]- 读 miss
- 把 block 200 调入 cache
miss
-
write Mem[200]- 此时 block 200 已在 cache 中
hit
-
write Mem[100]- 100 对应 block 仍不在 cache 中
miss
因此结果是:
| 操作 | no-write-allocate |
|---|---|
write Mem[100] | miss |
write Mem[100] | miss |
read Mem[200] | miss |
write Mem[200] | hit |
write Mem[100] | miss |
总计:
1 hit4 misses
Case 2:Write-Allocate
-
write Mem[100]- write miss
- 但因为采用 write allocate,要先把 100 所在 block 调到 cache
- 再写入 cache
miss
-
write Mem[100]- 100 所在 block 已经在 cache 中
hit
-
read Mem[200]- 第一次访问 200
miss- 并把 200 所在 block 调入 cache
-
write Mem[200]- 200 所在 block 刚才已经调入
hit
-
write Mem[100]- 100 所在 block 也还在 cache 中
hit
所以结果是:
| 操作 | write-allocate |
|---|---|
write Mem[100] | miss |
write Mem[100] | hit |
read Mem[200] | miss |
write Mem[200] | hit |
write Mem[100] | hit |
总计:
3 hits2 misses
如果后续确实还要继续访问这个 block;那么 write allocate 往往更合适。也就是说,write allocate 的效果本质上还是靠 locality 在支撑。
Memory System Performance
Cache 的性能:
真正影响系统性能的,不只是有没有 cache,而是 cache 的三个关键量:
- hit time(命中时间)
- miss rate(失效率)
- miss penalty(失效代价)
所有后面的优化,几乎都可以看成是在想办法改善这三者中的一个或多个。
CPU Execution Time and Memory Stall Cycles
- 即使处理器本身执行逻辑很快;
- 只要 memory stall cycles 很多;
- 总执行时间还是会被拉长。
对 cache 而言,一个很重要的展开式是:
IC:instruction countMemAccess / Inst:平均每条指令有多少次 memory accessMissRate:这些访问里有多少比例会 missMissPenalty:每次 miss 要额外付出多少周期
把它代回去,就得到:
如果把 MissRate × MemAccess / Inst 进一步合并成 MemMisses / Inst,也可以写成:
这两个写法本质一样,只是视角不同:
- 一个从 miss rate 出发;
- 一个从每条指令平均 miss 次数出发。
AMAT
AMAT
-
Hit time
- cache 命中时,从发起访问到拿到数据所需时间;
- 包括 tag 比较、选择 line、读取 data 等。
-
Miss rate
- 访问中 miss 的比例;
- 也可以转换成
misses per instruction来写。
-
Miss penalty
- miss 以后,多出来的额外等待时间;
- 往往包括访问下层 memory、搬运 block、必要时做 replacement / write-back 等开销。
其实就是把所有 memory access 分成两类:
-
命中
- 花
hit time
- 花
-
失效
- 先付出 hit 检查代价;
- 再额外付出
miss penalty
TIP
hit time不是“整个访存时间”;miss penalty也不是“从头到尾全部时间”,而是 相对 hit 多出来的那部分代价。
Example
假设:
- 基础执行
CPI = 1.0(先忽略 memory stalls) - cache miss penalty =
200clock cycles - miss rate =
2% - 平均每条指令有
1.5次 memory reference - 平均每
1000条指令有30次 cache miss
问:把 cache 行为算进来后,对性能有什么影响?
Case 1:用Miss Rate 来算
每条指令带来的 memory stall cycles 为:
所以总 CPI 变成:
Case 2: 用 Misses Per Instruction 来算
题目还给了另一个等价条件:
于是:
因此同样得到:
如果完全没有 cache,那么可以粗略理解为:
- 每次 memory reference 都要直接付出主存代价
这时:
- 有 cache 时:
CPI = 7 - 没有 cache 时:
CPI = 301
如果只看这个简化模型下的比值,则 cache 带来的改善大约是:
- 哪怕 miss rate 只有 2%,只要 miss penalty 足够大,cache 仍然会深刻影响整体性能
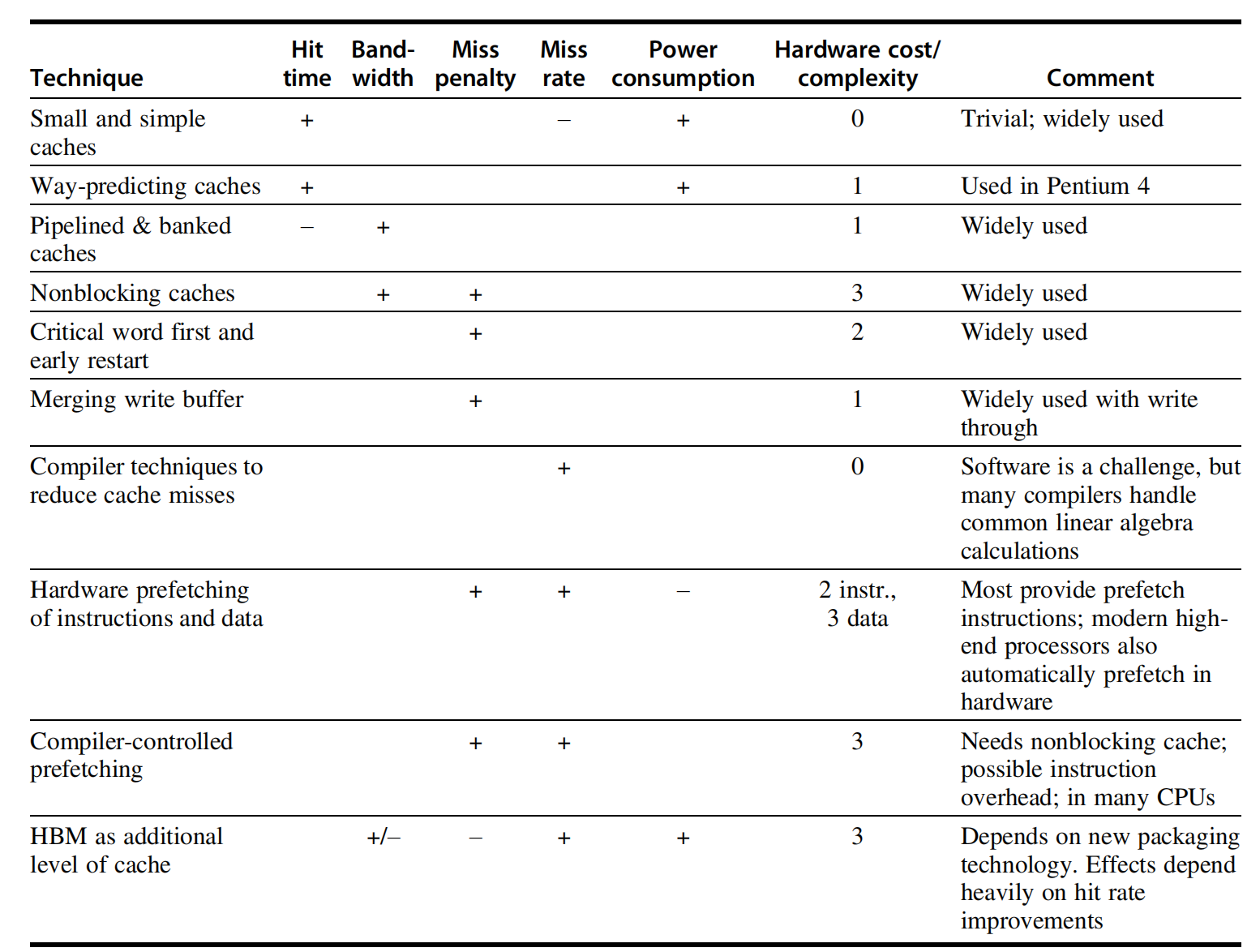
Improve Cache Performance
衡量 cache 优化,最核心的还是三件事:
但在现代处理器里,只看这个式子还不够。因为很多优化还会影响:
- cache bandwidth(缓存带宽)
- power / area(功耗与面积)
- clock cycle time(时钟周期)
- complexity(实现复杂度)
所以判断一种方法是否“值得”,不能只看 miss rate 是否下降,还要看它会不会拖慢 hit path、增加功耗,或者让控制逻辑复杂很多。
TIP一个很重要的判断原则是:
- hit path 上付代价:每次访问都要承担;
- miss path 上付代价:只有 miss 时才承担。
很多方法的设计思想,本质上就是在这两种代价之间做折中。
Reducing the Hit Time
Small and Simple First-Level Caches
L1 cache 几乎每次访存都会经过,所以 L1 的 hit time 往往比它的 miss rate 更敏感。
核心思路:
- L1 不做得太大;
- associativity 不做得太高;
- 让 tag compare、data access、way select 这条关键路径尽量短。
优点:
- hit 更快;
- 往往也更省电。
代价:
- 容量小、相联度低时,可能增加 miss rate;
- 需要依赖更大的 L2 / L3 来兜底。
所以经典设计通常是:
- 小而快的 L1
- 大而慢的 L2 / L3
Way Prediction
组相联 cache 的问题在于:
为了知道哪一 way 命中,通常要比较多个 tag,再做数据选择,这会拉长 hit time。
way prediction 的做法是:
- 先预测“这次大概率命中哪一 way”;
- 先按这个预测去访问;
- 如果预测正确,就接近 direct-mapped 的 hit path;
- 如果预测错误,再补查其他 way,付出额外延迟。
本质上它是在做这样的折中:
- 用少量预测状态
- 换取 平均 hit time 的下降
适合场景:
- 组相联 cache;
- 对 hit time 很敏感的前端 / L1。
代价:
- 预测错时会有额外 penalty;
- 数据 cache 上做 way prediction 一般比 I-cache 更麻烦,因为误判更容易影响后续流水线。
Increasing Cache Bandwidth
这一类方法的目标,不是直接减少单次访问延迟,而是让 cache 在单位时间内能接更多请求。
Pipelined Caches
把一次 cache access 拆成多个 pipeline stage,例如:
- 地址/index 处理
- tag compare
- data array access
- 返回结果
这样做的好处是:
- 可以提高时钟频率;
- cache 本身吞吐更高。
但要注意:
- 带宽上升,不代表单次访问 latency 下降
- 有时 latency 反而更高了
影响:
- I-cache pipeline 更深,会放大 branch misprediction 的代价;
- D-cache pipeline 更深,会增加 load-use latency。
所以 pipelined cache 更像是在用 更长的访问流水,换 更高的频率和吞吐。
Multibanked Caches
把一个 cache 分成多个独立 bank,让不同访问可以并行落到不同 bank:
- 若两个请求去不同 bank,可以同周期并行;
- 若两个请求撞到同一个 bank,就会出现 bank conflict。
优点:
- 提高并发访问能力;
- 对 superscalar、多发射、多 load/store 系统尤其重要。
代价:
- bank 映射和仲裁逻辑更复杂;
- 存在 bank conflict;
- 程序访问模式会直接影响收益。
所以它本质上是在做:
- 把一个大缓存拆成多个可并行的小通道
Nonblocking Caches
传统 blocking cache 在 miss 时会卡住后续访问。
nonblocking cache 则允许:
- hit under miss:一个 miss 正在处理时,后续 hit 还能继续;
- miss under miss:甚至允许多个 miss 并行在途。
直观理解:
- miss 不再把整个 cache 前端“封死”;
- 处理器能把部分等待隐藏掉。
关键实现点:
- 要记录多个 outstanding misses;
- 常见做法是用 MSHR(Miss Status Handling Register) 跟踪每个 miss 的去向、返回数据该填到哪里、唤醒哪条 load/store。
优点:
- 显著降低 effective miss penalty;
- 对 memory-level parallelism 较高的程序很有效。
代价:
- 控制逻辑明显更复杂;
- 需要处理返回乱序、命中/失效碰撞、coherence 等问题。
Reducing the Miss Penalty
Multilevel Caches
这是最基本也最常见的方法:
- L1 miss 后先查 L2;
- L2 miss 后再查 L3;
- 最后才去 main memory。
作用:
- 把“直接掉到主存”的昂贵 miss,改成“更低一级 cache hit”的相对便宜 miss;
- 从而降低 effective miss penalty。
代价:
- hierarchy 更复杂;
- inclusive / exclusive / non-inclusive 等策略会影响设计;
- 多级之间的一致性和替换关系更复杂。
Critical Word First / Early Restart
一次 miss 往往是按 block 为单位搬运的。
但处理器真正急需的,常常只是其中一个 word。
因此可以:
- Critical Word First:先取当前最需要的那个 word;
- Early Restart:只要关键 word 到了,就先让处理器继续执行,剩余部分稍后补齐。
作用:
- 不一定减少总传输量;
- 但可以减少处理器真正“卡住”的时间。
适合场景:
- block 较大;
- miss penalty 中“首字返回延迟”占比较高。
Read Miss Priority Over Write Miss
读 miss 往往直接阻塞程序继续执行;
写请求很多时候可以先暂存在 write buffer 里。
所以常见策略是:
- 读优先于写
- 尤其是 read miss priority over write miss
这样做可以:
- 让关键路径上的 stall 更少;
- 避免写流量把读请求拖住。
Merging Write Buffers
如果 write buffer 中有多次写,目标恰好落在同一 cache line 或相邻区域,就可以合并:
- 减少总线事务数;
- 减少下层存储压力;
- 降低写流量对读 miss 的干扰。
优点:
- 对 write-through cache 特别常见;
- 硬件代价通常不算太夸张。
代价:
- 需要检测可合并性;
- buffer 管理更复杂。
Victim Cache
victim cache 是一个很小的、通常是 fully-associative 的缓冲区,
专门保存 刚从主 cache 被替换出去的 block。
工作方式:
- L1 hit:直接返回;
- L1 miss 且 victim cache hit:通常执行 swap,把 victim cache 中的目标块和 L1 中冲突块交换;
- L1 miss 且 victim cache miss:再访问下层存储。
它针对的核心问题是:
- conflict miss
- 且通常是 被替换后很快又重用 的那类 conflict miss
优点:
- 不把额外复杂度放到 L1 正常 hit path 上;
- 对 direct-mapped cache 很有吸引力;
- 常能以很小硬件代价显著缓解“ABAB 式冲突抖动”。
局限:
- 对 capacity miss 帮助有限;
- 对长 reuse distance、流式访问帮助也有限;
- 它不是一个“正常的额外 cache level”,而是一个 专门接住 victim line 的小旁路结构。
Reducing the Miss Rate
Larger Block Size
block 变大以后,一次 miss 会顺带把附近更多数据带上来,因此:
- spatial locality 利用更充分;
- compulsory miss 往往下降。
但副作用也很明显:
- miss penalty 变大;
- 同样 cache 容量下,block 数变少;
- 可能加重 conflict miss / capacity miss。
所以 block size 永远是 locality 和 penalty 的折中。
Larger Cache Size
cache 更大时,能留下更多 block,因此:
- capacity miss 一般下降。
但代价是:
- 成本和面积增加;
- 功耗上升;
- hit time 可能变长。
因此:
- L1 通常不会做得很大;
- 更大的容量往往放到 L2 / L3 / LLC。
Higher Associativity
提高 associativity 的核心作用是:
- 把“只能放一个位置”变成“能在同组多个位置中选一个”
- 从而减少 conflict miss
优点:
- 对冲突敏感的工作负载常常有效。
代价:
- tag compare 更多;
- replacement 逻辑更复杂;
- hit time 往往更长;
- 功耗也会增加。
所以常见的理解就是:
- direct-mapped:快,但脆弱
- higher associativity:稳,但贵
Compiler Optimizations
有些 miss 不是硬件“命不好”,而是程序访问顺序本身写得不友好。
编译器常见优化包括:
Loop Interchange
通过交换嵌套循环次序,让数组访问更接近其内存布局顺序。
作用:
- 提高 spatial locality;
- 让一个 cache block 中的数据尽可能被连续用完。
Blocking / Tiling
把大问题切成能留在 cache 里的小块,再对子块反复运算。
作用:
- 提高 temporal locality;
- 在数据被替换前多用几次。
这一类优化说明一个关键事实:
- locality 不只是硬件属性,也是程序组织属性
Reducing Miss Penalty or Miss Rate via Parallelism
Hardware Prefetching
核心思想:
- 在处理器真正发出 demand access 之前,
- 预测它很快会用到哪些数据,
- 然后提前取回来。
常见形式:
- next-line prefetch
- stream buffer
- stride prefetch
- 更复杂的相关性预取
优点:
- 若预取及时,可把后续 miss 变成 hit;
- 若不够及时,也能降低 miss penalty。
代价:
- 预取错会浪费带宽;
- 还可能污染 cache;
- 对功耗也可能有负面影响。
所以 prefetch 的本质是:
- 用多做一点“可能没必要的工作”
- 去换 关键时刻少等一点
Compiler-Controlled Prefetching
这类方法由编译器显式插入 prefetch 指令:
- 在真正用到数据之前若干迭代,先发预取;
- 目标通常是让访问和计算重叠。
优点:
- 编译器更了解循环结构和访问模式;
- 对规则数组访问特别有效。
前提:
- 必须给预取留出足够“提前量”;
- cache 通常需要是 nonblocking 的,否则预取本身又会把执行卡住。
代价:
- 会增加指令数;
- 预取距离不好选;
- 程序行为稍变,效果可能就明显波动。
Extending the Memory Hierarchy
这一类方法关注的已经不只是“传统 cache 怎么做更好”,而是:
- 如何把更大容量、更高带宽、更多设备的内存也纳入同一 hierarchy
Using HBM to Extend the Memory Hierarchy
HBM(High Bandwidth Memory) 是把 DRAM 堆叠起来,放得更靠近处理器/加速器的一种近存储方案。
特点:
- 总线非常宽;
- 带宽很高;
- 容量通常不如外部大容量 DRAM;
- 成本和封装要求更高。
在 hierarchy 中,HBM 常见角色是:
- 作为高带宽近内存;
- 作为比 DDR 更快但更贵的一层;
- 有时也可视作 L4 / near-memory cache。
它解决的主要矛盾是:
- 传统 DDR 容量够,但带宽不够
- HBM 带宽很强,但容量和成本受限
Using CXL to Extend the Memory Hierarchy
CXL(Compute Express Link) 可以把外部内存设备、加速器和主机以 cache-coherent 的方式连起来。
从 memory hierarchy 视角看,它的重要价值是:
- 支持 memory expansion(内存扩展)
- 支持 memory pooling(内存池化)
- 支持 memory sharing(内存共享)
- 让部分“原本不在本机板上的内存”也能进入层次结构
可以把它理解成:
- 在本地 DDR / HBM 之下,
- 引入一层 更远、通常更慢、但更灵活、更大 的扩展内存层。
优点:
- 提升容量弹性;
- 资源利用率更高;
- 对数据中心和大规模异构系统很重要。
代价:
- 延迟通常高于本地 DRAM;
- QoS、coherence、资源管理都更复杂;
- 更适合作为“较远的一层内存”,不适合作为最靠近核心的高速层。
Using UnifiedBus to Extend the Memory Hierarchy
这里把 UnifiedBus 理解为近年来“统一互连 / memory-semantic fabric / 资源池化总线”这一类方案。
它的目标通常是:
- 把 CPU、GPU、NPU、内存和 I/O 设备放到更统一的互连语义下;
- 让远端内存、池化内存、异构设备内存更容易被系统按层次结构使用;
- 支持更大范围的资源共享与扩展。
直观理解:
- 传统 memory hierarchy 多是在单机板内分层;
- UnifiedBus 这类方案是在 更大系统范围 上继续分层。
优点:
- 容量扩展强;
- 资源池化能力强;
- 对大规模 AI / 数据中心系统有吸引力。
代价:
- 延迟一定高于本地 cache / DRAM;
- 流控、QoS、容错、隔离、安全都更难;
- 软件栈和资源调度复杂度明显上升。
Additional Techniques Often Discussed with Cache Optimization
Skewed-Associative Cache
普通组相联 cache 中,同一个 block 先确定 set,再在该 set 里挑 way。
skewed-associative cache 的特殊点在于:
- 不同的 way 使用不同的索引/哈希函数
- 因此两个在某一 way 中冲突的 block,可能在另一 way 中并不冲突
作用:
- 进一步降低 conflict miss;
- 尤其适合那些“普通组相联里仍然老撞同一组”的模式。
优点:
- 比直接增加 associativity 更有针对性;
- 有时能以较低 way 数取得不错效果。
代价:
- 索引和替换逻辑更复杂;
- 查找路径也更难实现得非常规整。
Pseudo-Associative Cache
它想同时保住两件事:
- direct-mapped 的快 hit time;
- set-associative 的较低 conflict miss
基本思路:
- 先按 direct-mapped 的主位置查一次;
- 如果主位置没命中,再去查一个“备用位置”;
- 若备用位置命中,这种命中叫 pseudo-hit
因此它的访问特征是:
- 正常 hit 很快;
- pseudo-hit 比正常 hit 慢;
- miss rate 介于 direct-mapped 和 set-associative 之间。
本质上它是在做:
- 把部分 associativity 延迟到第二次检查
Cache Coloring
cache coloring 更多是 OS / allocator 级别的方法,也常叫 page coloring。
核心想法:
- 物理页号会影响它映射到 LLC 的哪些 set;
- OS 可以控制不同页面分配到哪些“颜色”;
- 从而减少热点数据在 LLC 中互相冲突。
用途:
- 减少 cache conflicts;
- 做 cache partition / isolation;
- 提高多程序系统中的可预测性。
这类方法说明:
- cache 行为并不完全由硬件决定;
- 内存分配策略也能改变 cache 冲突模式
System-Level Cache
system-level cache(系统级缓存) 常见于 SoC:
- 它不只服务 CPU;
- 还可能同时服务 GPU、NPU、DSP、ISP、媒体单元等。
作用:
- 降低多个 IP 对外部 DRAM 的访问压力;
- 减少跨设备数据搬运;
- 提高整个 SoC 的能效。
优点:
- 对异构 SoC 很重要;
- 能显著减少 off-chip traffic。
代价:
- coherence 更复杂;
- 多主设备竞争更激烈;
- QoS / priority / partitioning 都更关键。
GPU Memory and Cache-Related Topics
GPU 的优化重点和 CPU 不完全一样。
CPU 通常更依赖 cache 去降低延迟;
GPU 除了使用 cache,还大量依赖:
- multithreading
- coalescing
- shared memory / scratchpad
- 高带宽显存
GPU Shared Memory
GPU shared memory 本质上是:
- 每个 SM / 线程块附近的一块 on-chip scratchpad
- 延迟低、带宽高
- 由程序员显式管理
作用:
- 保存会被线程块内多次复用的数据;
- 减少反复访问全局显存;
- 让局部数据交换不经过更慢的 global memory。
优点:
- 非常快;
- 可控性强;
- 对 tile-based 算法尤其有效。
代价:
- 容量小;
- 需要程序员显式管理;
- 会有 bank conflict 问题。
GPU Memory Hierarchy
GPU 常见的 memory hierarchy 可以粗略理解为:
- registers
- shared memory / scratchpad
- L1 / texture cache
- L2 cache
- HBM / GDDR global memory
- host memory
和 CPU 相比,GPU 的几个特点是:
- 更强调 高带宽;
- 更依赖 大量线程隐藏延迟;
- cache 往往没有 CPU 那么“全能”,shared memory 反而很关键;
- 访存模式是否能 coalescing(合并访存) 非常重要。
所以 GPU memory hierarchy 的优化重点通常是:
- 提高带宽利用率;
- 减少 global memory traffic;
- 增强 locality;
- 降低线程间资源争用。
Unified Memory Architecture
GPU 的 unified memory 指的是:
- CPU 和 GPU 共享一个统一虚拟地址空间;
- 数据页可以在 CPU 与 GPU 之间按需迁移;
- 程序员不必总是手写显式 memcpy。
优点:
- 编程简单很多;
- CPU/GPU 协同更自然;
- 适合复杂数据结构和快速原型开发。
代价:
- 页迁移和 page fault 会带来额外开销;
- 若访问模式不好,可能频繁来回迁移,性能下降很明显。
所以 unified memory 更像是:
- 用更强的软件透明性
- 换取 对访问模式更高的要求
How to Compare These Techniques
更稳妥的比较维度是:
-
它主要针对哪一类问题?
- hit time
- bandwidth
- miss penalty
- miss rate
- system-level capacity / sharing
-
它把代价放在 hit path 还是 miss path?
-
它最擅长处理哪种 miss?
- conflict
- capacity
- compulsory
- streaming / predictable access
-
它的代价是什么?
- latency
- power
- area
- complexity
- programmability
A Compact Takeaway Table
| Technique | Main Goal | Best For | Main Cost |
|---|---|---|---|
| Small/simple L1 | Reduce hit time | latency-sensitive L1 | higher miss rate |
| Way prediction | Reduce average hit time | set-associative L1 | misprediction penalty |
| Pipelined cache | Increase bandwidth / freq | high-frequency cores | higher access latency |
| Multibanked cache | Increase bandwidth | multiple accesses per cycle | bank conflicts |
| Nonblocking cache | Hide miss latency | MLP-rich workloads | high control complexity |
| Critical word first / early restart | Reduce miss penalty | large block refill | refill control complexity |
| Merging write buffer | Reduce write-related penalty | write-through / heavy write traffic | merge logic |
| Compiler optimization | Reduce miss rate | regular loop kernels | compile dependence |
| Hardware prefetch | Reduce miss penalty / rate | predictable streams | bandwidth waste / pollution |
| Compiler prefetch | Reduce miss penalty / rate | regular loops with lookahead | instruction overhead |
| Victim cache | Reduce conflict miss | short-reuse conflicts | small extra buffer |
| Skewed-associative | Reduce conflict miss | stubborn conflict patterns | hashing/replacement complexity |
| Pseudo-associative | Reduce conflict miss with fast first hit | between DM and SA | pseudo-hit latency |
| Cache coloring | Reduce LLC conflicts | OS-level placement / isolation | allocator complexity |
| System-level cache | Reduce off-chip traffic | heterogeneous SoC | coherence/QoS complexity |
| HBM | Extend bandwidth-rich memory layer | bandwidth-bound systems | cost / packaging |
| CXL | Extend/pool memory hierarchy | servers / composable systems | higher latency, management complexity |
| UnifiedBus | Extend system-scale memory hierarchy | large heterogeneous systems | software+fabric complexity |
| GPU shared memory | programmer-managed fast reuse | tiled GPU kernels | small capacity, bank conflicts |
| Unified memory | simplify CPU-GPU memory use | heterogeneous programming | migration overhead |
Virtual Memory
Virtual memory 放在 memory hierarchy 的最后一层来理解。它看起来像是在扩容 memory,实际更关键的是:
- 给每个进程提供连续、独立的虚拟地址空间;
- 把虚拟地址映射到不连续的物理内存,必要时再映射到 secondary storage;
- 通过 page table 做进程隔离、共享和权限保护。
OS、MMU 与 Virtual Memory
从系统角度看,CPU 设计的最终目标是支持软件运行。离硬件最近的软件层就是 OS(operating system)。
OS 负责管理:
- process management;
- file system;
- device management;
- memory management;
- protection 与 isolation。
Virtual memory 是 OS memory management 中最重要的机制之一。它让用户程序不需要直接关心:
- 真实物理内存有多大;
- 数据现在在 cache、main memory 还是 disk;
- 物理内存是否连续;
- 其他进程的地址空间在哪里。
程序看到的是一套由 OS 提供的虚拟地址空间。硬件中的 MMU(Memory Management Unit) 负责把虚拟地址翻译成物理地址,并配合权限位检查访问是否合法。
TIP可以把 virtual memory 看成 OS 做的一层“抽象”:
- 程序使用 virtual address;
- OS 维护 virtual address 到 physical address 的映射;
- MMU 在硬件路径上快速完成地址翻译;
- 出现找不到映射或权限错误时,触发 page fault,由 OS 接管。
Program Thinks vs Program Uses
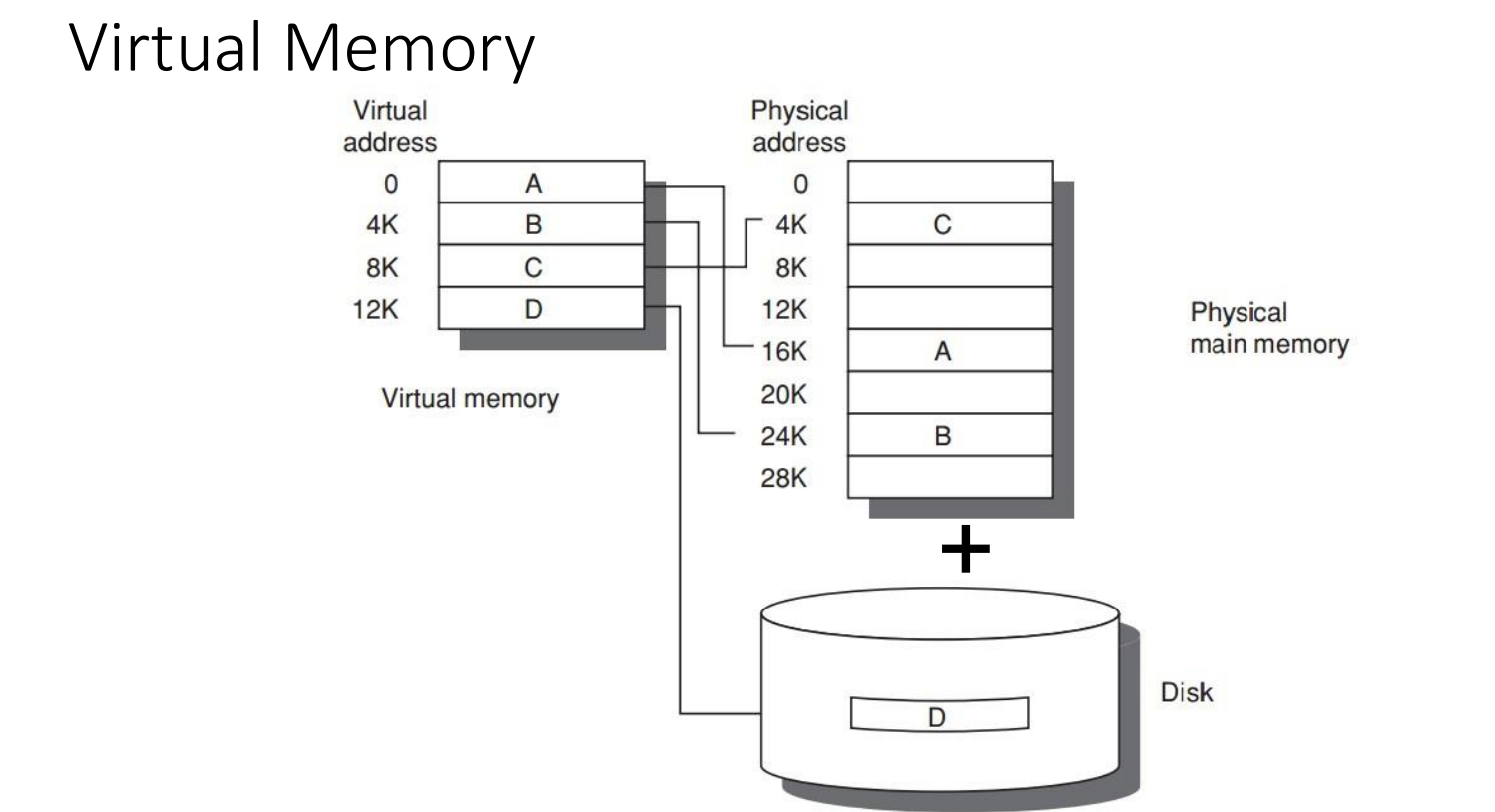
Virtual memory 的核心现象是:
- Program thinks:自己拥有一段连续、很大的地址空间;
- Program uses:底层可能使用不连续的物理内存,甚至一部分数据暂时在 secondary storage 上。
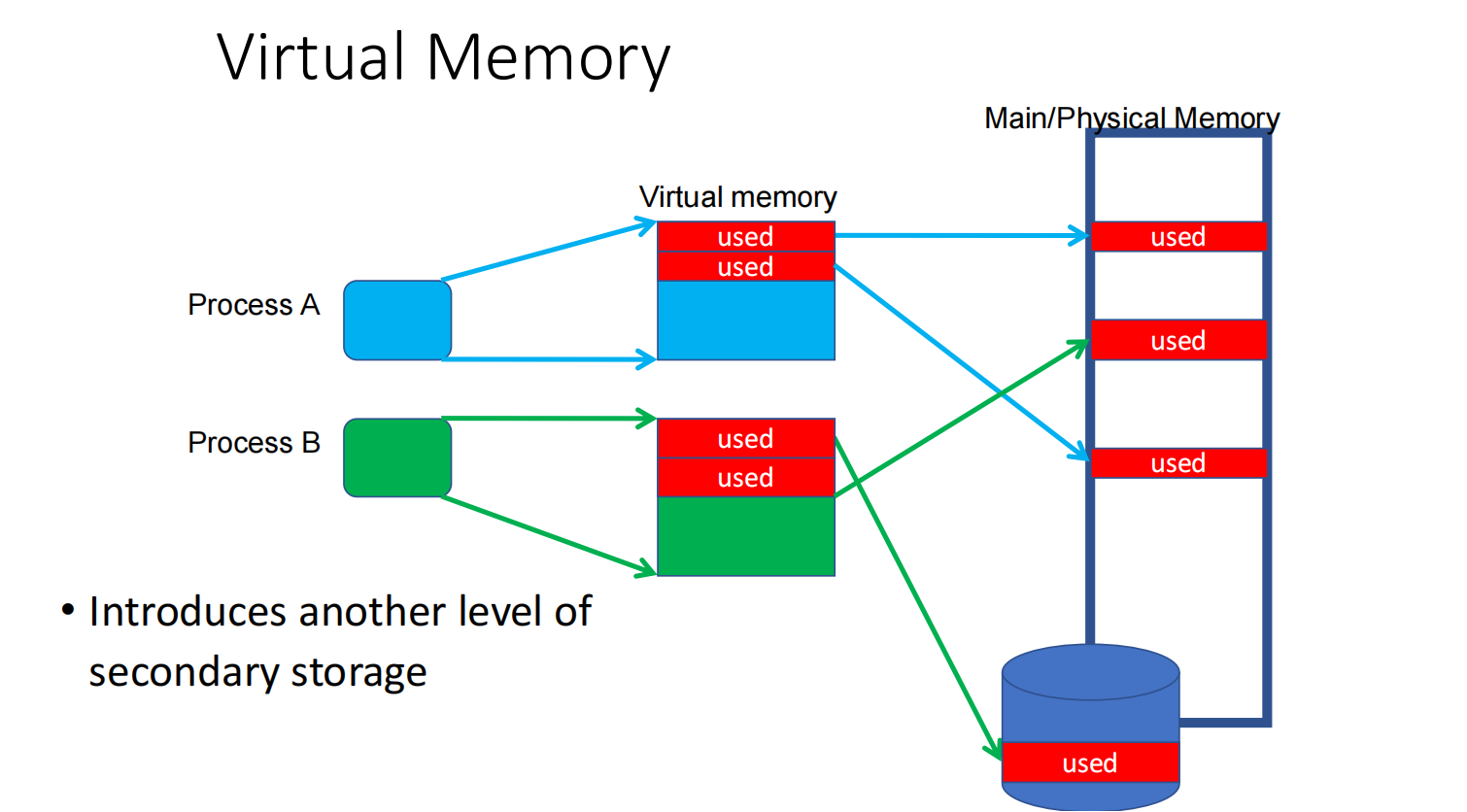
也就是说,虚拟地址空间可以是连续的:
Virtual address space:0 4K 8K 12K| A | B | C | D |对应到物理空间时可能是非连续的:
Physical memory:| C | | A | | B |
Disk / secondary storage:| D |程序只需要按照连续的 virtual address 访问 A/B/C/D,它不需要知道这些块在物理内存中具体放在哪里。
这带来两个直接好处:
-
更大的逻辑空间
- 程序可以认为自己有很大的地址空间;
- 不常用的数据可以暂时放在 disk 上,需要时再调入 memory。
-
更灵活的物理分配
- 物理内存不要求连续;
- OS 只要维护好 page table,就可以把不同虚拟页映射到任意可用物理页。
Virtual Memory 的三个核心作用
扩容:Main Memory + Secondary Storage
Virtual Memory = Main Memory + Secondary Storage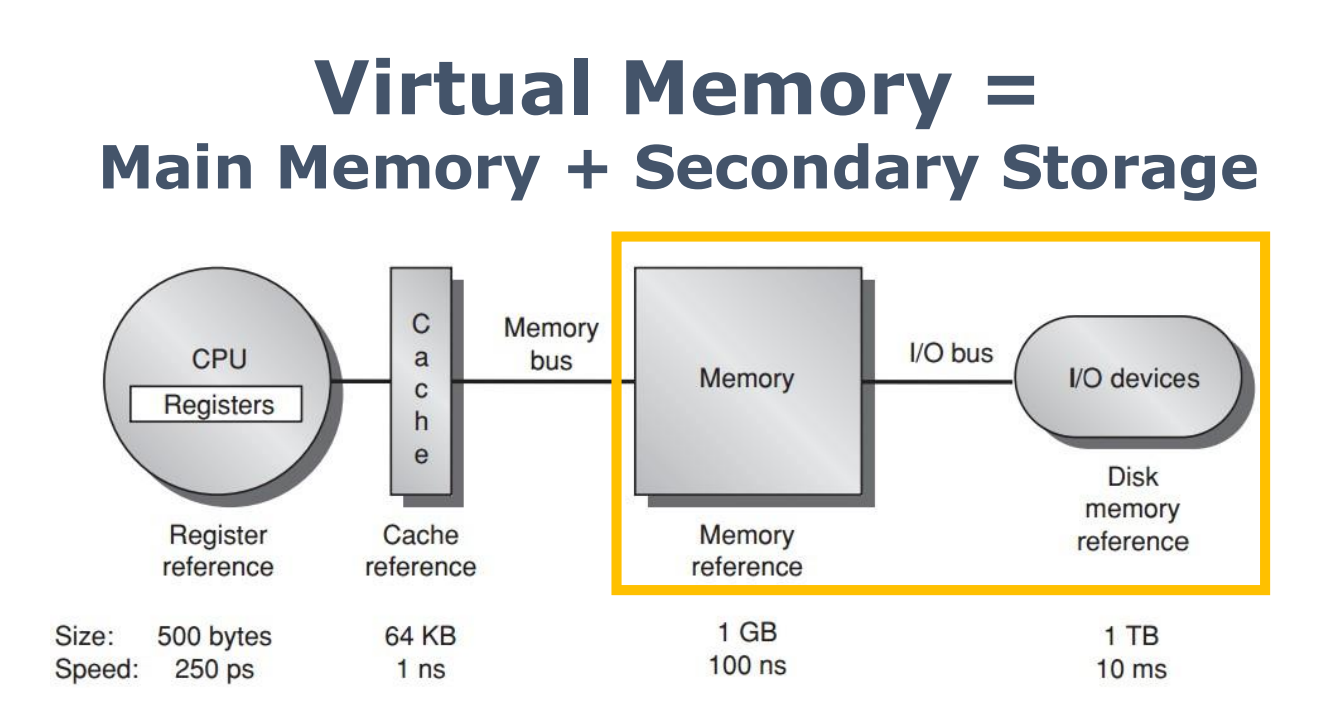
也就是:
- main memory 保存当前活跃的数据和指令;
- secondary storage 保存暂时不在内存中的页;
- OS 通过 page fault / page replacement 在两者之间调入调出。
这和 cache hierarchy 的思想是一致的:
- CPU 希望大多数访问都在快层级命中;
- 访问不到时,再去慢层级取。
区别是:virtual memory 的下一级可能是 disk / SSD,miss penalty 极大,因此设计上会尽量降低 virtual memory miss 的概率。
灵活管理:物理地址可以不连续
没有 virtual memory 时,程序如果直接使用 physical address,就必须面对真实物理内存的布局。多个进程运行、换入换出之后,物理内存容易出现碎片。
有 virtual memory 后:
- 进程看到的是连续 virtual address;
- OS 可以把它映射到不连续 physical frames;
- 页表记录这种映射关系。
这让物理内存分配更灵活,也方便 OS 在多进程场景下管理空间。
隔离与保护:每个进程有自己的地址空间
Virtual memory 的另一个关键作用是 process isolation。
每个进程都有自己的 page table:
Process A virtual address ── Page Table A ──> Physical pages for AProcess B virtual address ── Page Table B ──> Physical pages for B即使两个进程使用了相同的 virtual address,例如都访问 0x4000,它们也可以通过不同的 page table 映射到不同的 physical page。
这样可以做到:
- A 访问不到 B 的私有物理页;
- B 访问不到 A 的私有物理页;
- OS 可以显式决定哪些页允许共享;
- 用户程序不能随便修改 page table。
WARNINGVirtual memory 提供的是机制上的隔离基础,不代表系统绝对安全。攻击和防护都可能围绕 page table、权限位、地址空间隔离、进程上下文展开。
Cache vs Virtual Memory
Cache 和 virtual memory 都属于 memory hierarchy,但它们的管理粒度、代价和目标不同。
| 对比项 | First-level cache | Virtual memory |
|---|---|---|
| 管理单位 | block / cache line | page |
| 典型大小 | 16-128 bytes | 4KB-64KB,现代系统也支持 huge page |
| Hit time | 约 1-3 cycles | 约 100-200 cycles |
| Miss penalty | 几个到几十个 cycles | 可达到百万级 cycles |
| Miss rate | 相对更高,可接受 | 必须极低 |
| 地址映射 | physical address 到 cache address | virtual address 到 physical address |
| 管理主体 | 主要由硬件管理 | OS + hardware 协同 |
关键差别在 miss penalty:
- cache miss 通常访问下一级 cache 或 main memory;
- virtual memory miss 可能需要访问 secondary storage;
- 代价差几个数量级。
所以在 cache 里,direct mapped 带来的 conflict miss 有时可以接受;在 virtual memory 里,页放置通常采用更接近 fully associative 的策略,尽量避免因为放置限制导致 miss。
Virtual Memory Allocation
Virtual memory 的分配主要有两类思想:
- Paged virtual memory(分页)
- Segmented virtual memory(分段)
Paged Virtual Memory
分页把虚拟地址空间切成固定大小的 page。
地址形式:
page address = page number || page offset例如 4KB page:
- page size = bytes;
- page offset = 12 bits;
- 剩下的高位作为 page number。
优点:
- 每个 page 大小相同;
- 替换和分配简单;
- 适合用 page table 建立索引。
缺点:
- 会产生 internal fragmentation(内部碎片);
- 如果程序只用了一个 page 的一部分,剩余空间仍然被这个 page 占用。
Segmented Virtual Memory
分段按逻辑模块或程序结构划分,每个 segment 可以有不同大小。
地址形式:
segment address = segment number + offset优点:
- 更贴近程序逻辑结构;
- 不同 segment 可以按实际需要分配不同大小。
缺点:
- segment 大小不固定;
- 替换、分配、压缩更复杂;
- 容易产生 external fragmentation(外部碎片)。
Paging vs Segmentation
| 机制 | 管理单位 | 地址形式 | 主要优点 | 主要问题 |
|---|---|---|---|---|
| Paging | 固定大小 page | page # + offset | 替换简单,页表索引清晰 | 内部碎片 |
| Segmentation | 可变大小 segment | segment # + offset | 符合程序逻辑结构 | 外部碎片,管理复杂 |
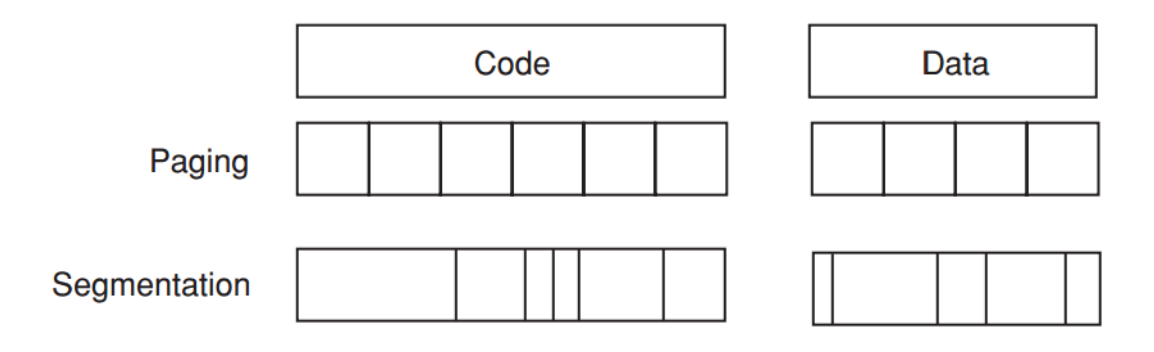
现代系统通常会组合使用分段与分页的思想
Four Questions for Virtual Memory
Q1:Where can a block be placed in main memory?
fully associative strategy。
在 virtual memory 层级中,一个 virtual page 可以放到 main memory 中几乎任意一个可用 physical frame。
原因:
- virtual memory miss penalty 极大;
- 如果因为“固定映射位置”导致冲突 miss,代价无法接受;
- 因此 OS 通常允许 page 放在任意可用 frame 中。
这和 cache 的 direct mapped 形成对比:
- cache 追求 hit path 简单、速度快;
- virtual memory 更重视降低 miss rate。
Q2:How is a block found if it is in main memory?
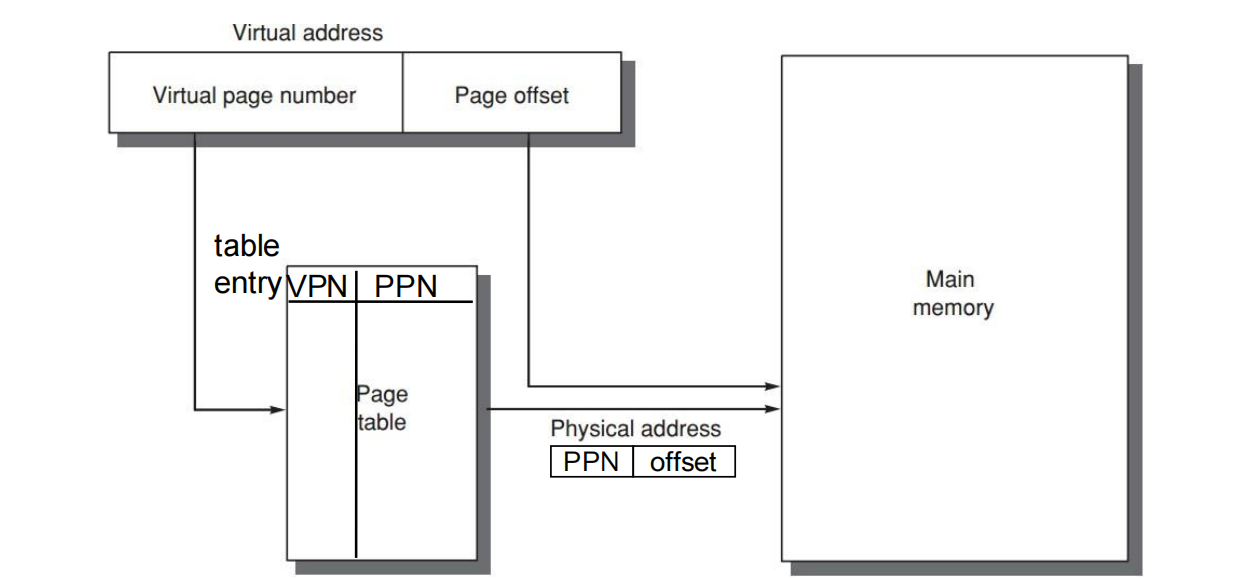
通过 page table。
Virtual address 可以拆成:
Virtual Address = VPN || page offsetPhysical address 可以拆成:
Physical Address = PPN || page offset其中:
VPN:Virtual Page Number;PPN:Physical Page Number / Physical Page Frame Number;page offset:页内偏移,翻译前后保持不变。
地址翻译的核心就是:
VPN ──查 Page Table──> PPNPPN || page offset ──> Physical AddressNOTEPage table 记录的是 page-level 的映射,所以它只需要翻译页号部分;页内偏移不需要改变。
Q3:Which block should be replaced on a virtual memory miss?
通常希望替换 least recently used page,实际 OS 会用近似算法。
LRU 在 virtual memory 中通常通过 use bit / reference bit 近似实现:
- page 被访问时,硬件或 OS 逻辑设置 use bit;
- OS 周期性清除 use bit;
- 之后再观察哪些 page 被重新访问;
- 长时间未被访问的 page 更可能被替换。
完全精确的 LRU 维护成本很高,因此 OS 通常采用 Clock / Second Chance 等近似策略。
Q4:What happens on a write?
采用 write-back strategy。
原因:
- virtual memory 的下一级可能是 disk / SSD;
- 每次写都同步写回 secondary storage 成本太高;
- 只有 page 被替换且内容被修改过时,才需要写回。
这需要 dirty bit:
- dirty = 0:page 内容没有被修改,替换时可以直接丢弃;
- dirty = 1:page 内容已经修改,替换前必须写回 secondary storage。
Address Translation
Page Table 的基本作用
Page table 的作用是保存 virtual page 到 physical page 的映射关系。
virtual address = VPN || page offset | v Page Table | vphysical address = PPN || page offset一次地址翻译可以写成:
VPN = virtual_address[high bits]offset = virtual_address[page-offset bits]PPN = page_table[VPN]physical_address = PPN || offsetPage Table Size Example
假设:
- virtual address = 32 bits;
- page size = 4KB = bytes;
- PTE(page table entry)大小 = 4 bytes = bytes。
则虚拟页数量为:
page table 总大小为:
所以即使只是 32-bit virtual address,单级页表也可能很大。
TIPpage table size 和两个因素直接相关:
- virtual address space 越大,VPN 数量越多,page table 越大;
- page size 越大,VPN 数量越少,page table 越小。
为什么需要 TLB?
Page table 通常存放在 main memory 中。
如果没有 TLB,一次 data access 逻辑上需要两次 memory access:
- 访问 page table,得到 PPN;
- 用 physical address 访问真正的数据。
这会让访存时间近似翻倍。
解决方法是增加一个专门缓存地址翻译结果的小 cache:
TLB = Translation Lookaside BufferTLB 保存最近用过的 virtual page 到 physical page 的翻译关系。
Translation Lookaside Buffer
TLB 可以理解成专门服务于地址翻译的 cache。
TLB entry 通常包含:
- tag:virtual address 的一部分,通常来自 VPN;
- data:physical page frame number / PPN;
- valid bit;
- protection field;
- use / reference bit;
- dirty bit。
TLB Hit
TLB hit 时:
VA = VPN || offsetTLB[VPN] -> PPNPA = PPN || offset此时不需要访问 page table,地址翻译非常快。
TLB Miss
TLB miss 时:
- 需要通过 page table walker 查询 page table;
- 找到 PTE 后得到 PPN 和权限信息;
- 把新的翻译结果填入 TLB;
- 再次访问时即可 TLB hit。
如果 page table 中没有有效映射,或者权限不满足,就会触发 page fault。
TLB Access Steps
-
发送虚拟地址到所有 tag
- TLB 中的多个 entry 同时比较;
- 只有 valid entry 才参与匹配。
-
检查访问类型和权限
- load / store / instruction fetch 对权限要求不同;
- protection field 决定当前访问是否合法。
-
匹配 tag 并选择 PPN
- 命中的 entry 通过 mux 输出对应的 physical page frame number。
-
拼接 page offset
PPN || page offset形成最终 physical address。
NOTETLB 和 cache 的思想相同:把近期常用信息保存在小而快的结构中。区别在于 cache 缓存数据,TLB 缓存地址翻译结果。
Page Size Selection
Page size 会影响 page table、TLB、page fault penalty 和空间浪费。
Larger Page Size 的优点
更大的 page size 会带来:
- page table 更小;
- 同样数量的 TLB entry 可以覆盖更大的地址范围;
- TLB miss 次数可能减少;
- 从 secondary storage 调入调出时,较大块传输更高效。
这类似 cache 中较大 block size 对 spatial locality 的利用。
Larger Page Size 的代价
更大的 page 也有明显代价:
- 内部碎片更严重;
- page fault 时一次调入更多数据,单次 miss penalty 更高;
- 如果程序局部性不好,会搬入很多用不到的数据。
Smaller Page Size 的优点
更小的 page size 可以:
- 减少内部碎片;
- 更精细地管理内存;
- 对小对象和稀疏访问更友好。
Multiple Page Sizes
现代处理器常支持 multiple page sizes,例如常规页和 huge page。
原因:
- 小页适合细粒度管理;
- 大页适合大连续内存区域;
- 大页能减少 TLB miss;
- 某些程序中,TLB miss 对 CPI 的影响可以接近 cache miss。
Address Translation with Cache
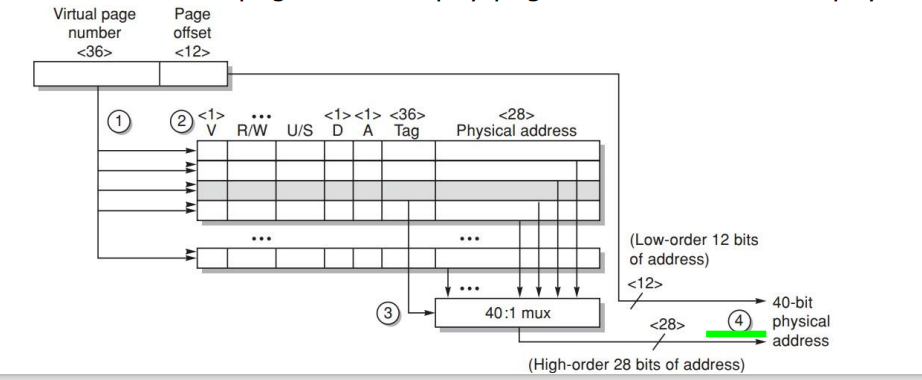
一个完整的地址翻译例子:
- virtual address:64-bit;
- physical address:41-bit;
- page size:8KB;
- two-level direct-mapped caches;
- block size:64B;
- L1:8KB;
- L2:4MB;
- TLB:256 entries。
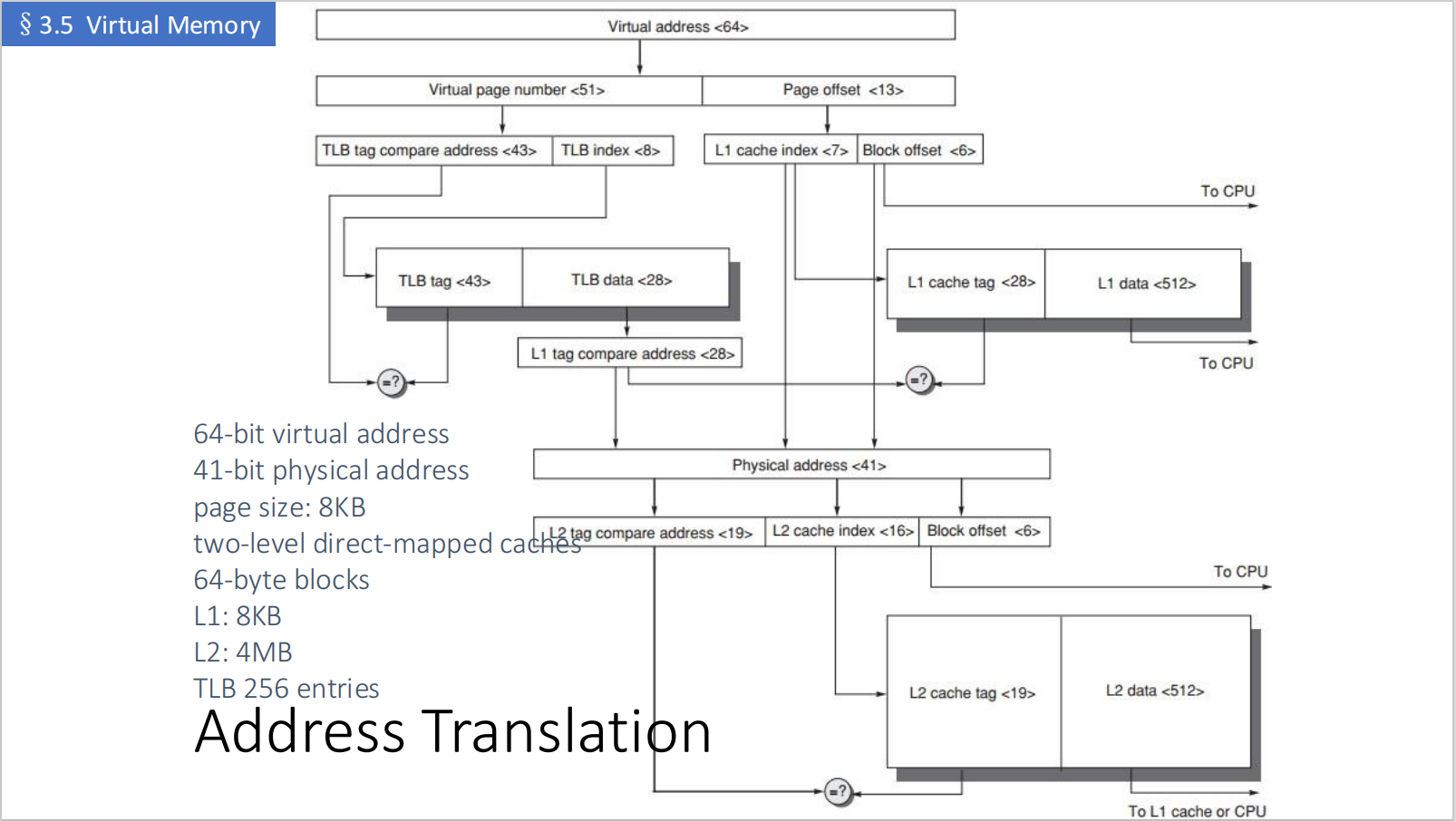
基本位宽
page size = 8KB:
所以:
page offset = 13 bitsVPN = 64 - 13 = 51 bitsPPN = 41 - 13 = 28 bitsphysical address:
Physical Address = PPN || page offset = 28 bits || 13 bits = 41 bitsTLB 位宽
TLB 有 256 entries:
在这个例子中,可以理解为:
TLB index = 8 bitsTLB tag = VPN - TLB index = 51 - 8 = 43 bitsTLB 命中后输出 PPN = 28 bits,再与 13-bit page offset 拼接成 41-bit physical address。
L1 Cache 位宽
L1 cache = 8KB = bytes,block size = 64B = bytes。
因此 L1 line 数为:
所以:
L1 block offset = 6 bitsL1 index = 7 bitsL1 tag = 41 - 7 - 6 = 28 bits注意这里:
L1 index + block offset = 7 + 6 = 13 bits = page offsetpage offset 在地址翻译前后不变,因此 L1 的 index 可以直接从 virtual address 的低 13 位中取出;同时,真正的 tag 比较仍然依赖翻译得到的 physical address 高位。
TIP这就是很多处理器中常见的思路:
- 用 page offset 中的位先索引 L1;
- TLB 并行翻译得到 physical tag;
- 再用 physical tag 做最终比较。
这样可以把 TLB lookup 和 L1 access 尽量并行化。
L2 Cache 位宽
L2 cache = 4MB = bytes,block size = 64B = bytes。
L2 line 数为:
因此:
L2 block offset = 6 bitsL2 index = 16 bitsL2 tag = 41 - 16 - 6 = 19 bits访问过程可以概括为:
1. CPU 产生 virtual address2. TLB 查询 VPN -> PPN3. 同时用 page offset 中的一部分索引 L14. TLB 输出 physical tag 后,与 L1 tag 比较5. L1 hit:返回数据6. L1 miss:用 physical address 继续查 L27. L2 miss:访问 main memory地址翻译伪代码
function access(virtual_address): vpn = virtual_address[63:13] offset = virtual_address[12:0]
if TLB.hit(vpn): ppn = TLB[vpn].ppn else: pte = page_table_walk(vpn) if !pte.valid or !pte.permission_ok: raise page_fault ppn = pte.ppn TLB.insert(vpn, ppn, pte.permission)
physical_address = ppn || offset
if L1.hit(physical_address): return L1.data else if L2.hit(physical_address): fill_L1_from_L2() return L2.data else: fetch_from_memory() fill_L2_and_L1() return data现代处理器中的访问路径
两个实际处理器的 memory hierarchy:
- ARM Cortex-A53
- 区分 instruction access path 和 data access path;
- 常见结构是 I-side / D-side 分开,再汇合到更低层级 cache / memory。
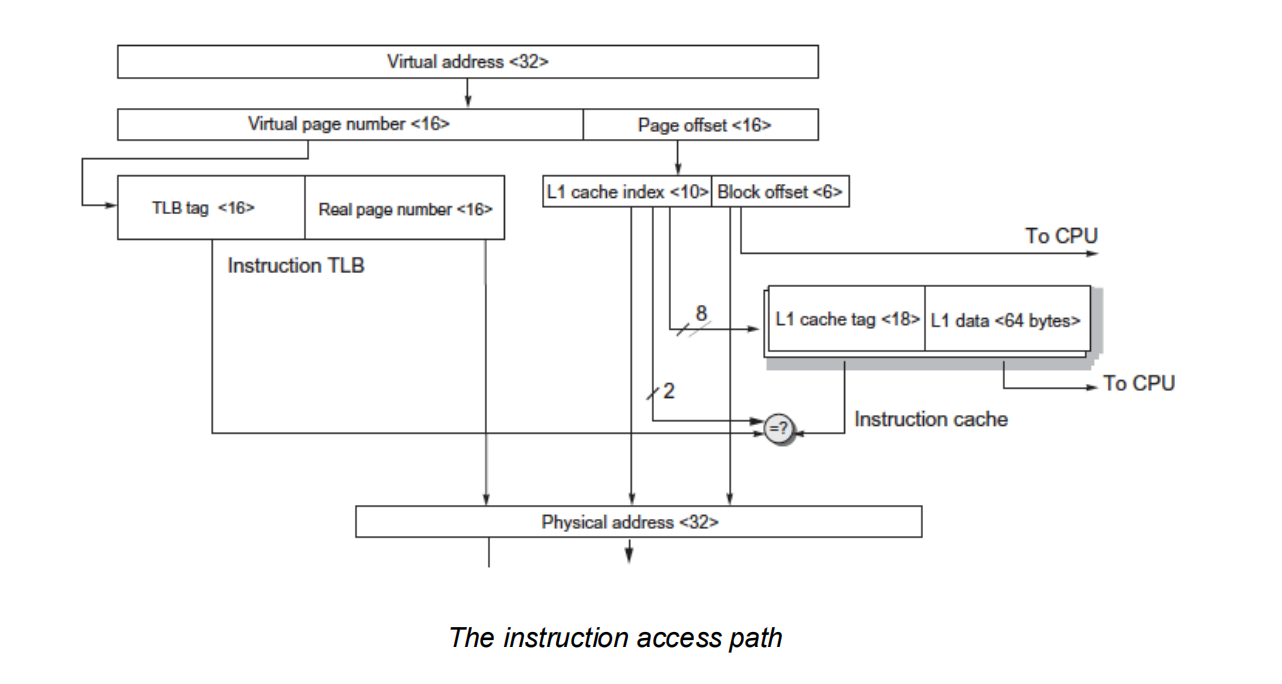
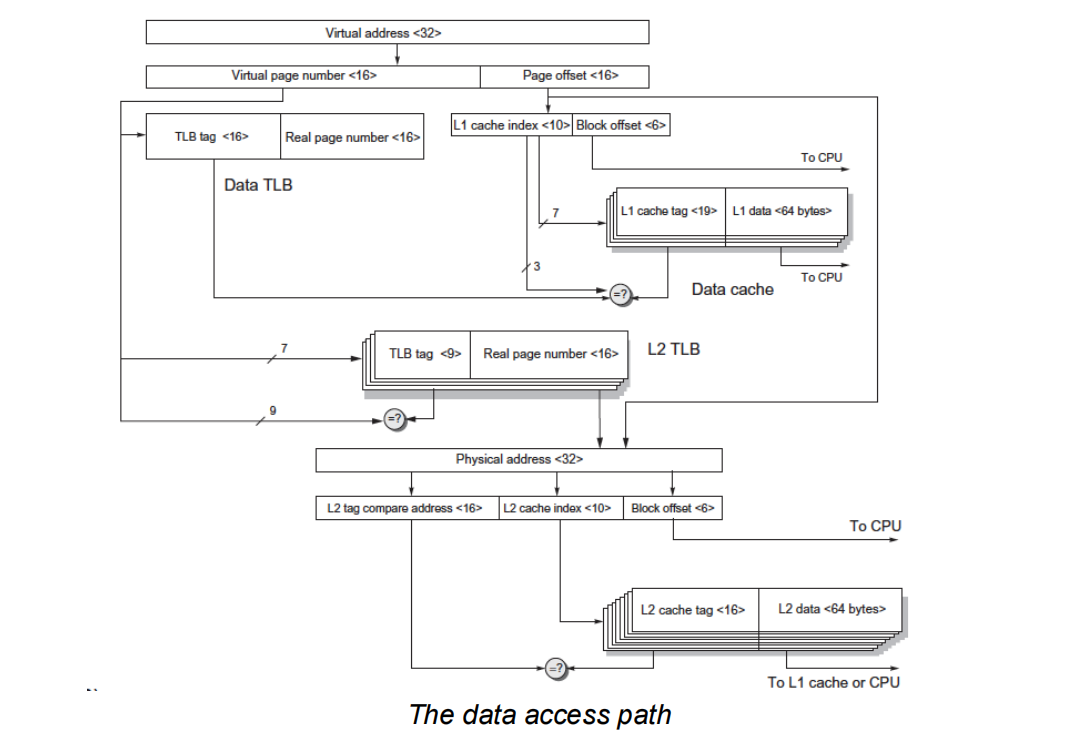
- Intel Core i7 6700
- 具有多级 cache;
- L1、L2、L3 与 TLB 共同组成访存路径;
- 地址翻译和 cache access 在硬件中被尽可能并行化。
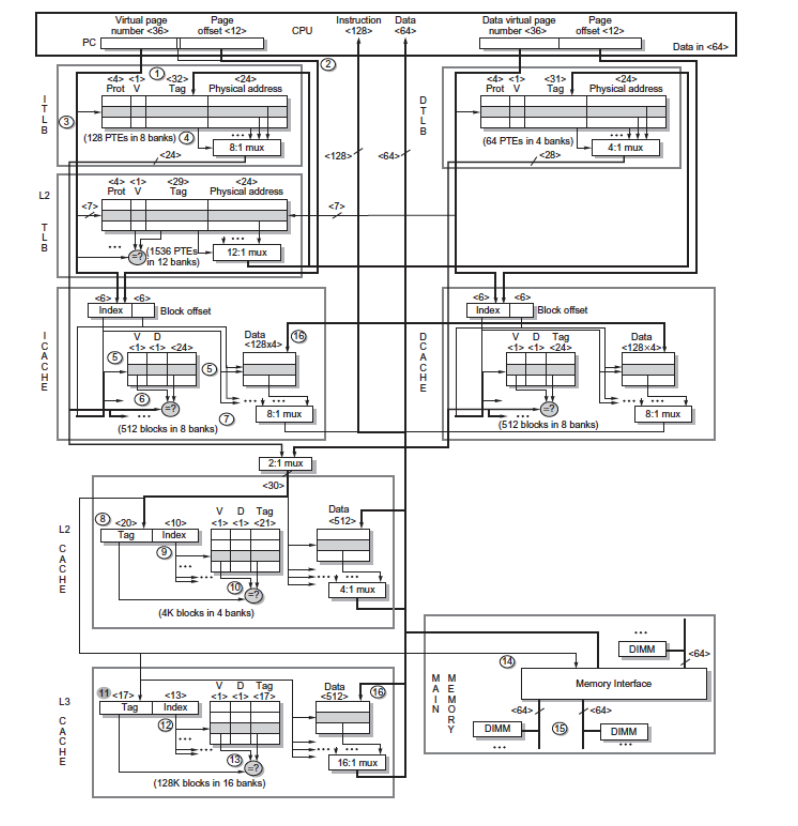
这说明 virtual memory 不是 OS 的纯软件概念,它直接影响处理器取指、访存、cache lookup、异常处理的硬件路径。
Protection and Sharing among Programs
Multiprogramming
Multiprogramming 允许多个程序并发运行,共享同一台机器。
因此系统需要同时解决:
- protection:一个程序不能随便破坏另一个程序;
- sharing:某些资源又需要被多个程序共享。
Process
一个 process 可以理解为:
一个正在运行的程序,加上它继续运行所需的全部状态。
Process state 包括:
- PC;
- registers;
- stack;
- heap;
- page table;
- OS 维护的进程控制信息。
Time-sharing 让多个用户或多个程序共享 CPU 和 memory,并给每个程序一种“自己独占机器”的假象。
当 OS 从一个 process 切换到另一个 process 时,需要进行 context switch:
- 保存旧进程的处理器状态;
- 加载新进程的处理器状态;
- 切换地址空间相关信息,例如 page table base。
Process Protection
进程保护依赖体系结构和操作系统共同完成。
硬件设计者需要保证:
- 处理器状态可以被保存和恢复;
- 用户态不能随便执行高权限操作;
- 地址翻译与权限检查不能被用户程序绕过。
OS 设计者需要保证:
- 不同进程的 page table 指向正确的 physical pages;
- 用户程序不能修改自己的 page table;
- 共享页必须由 OS 显式建立。
Proprietary Page Tables
最基本的隔离方式是每个进程拥有自己的 page table。
Process A page table -> A 的 physical pagesProcess B page table -> B 的 physical pages如果需要共享内存,OS 可以让两个 page table 的某些 entry 指向同一个 physical page:
Process A page table entry ─┐ ├── shared physical pageProcess B page table entry ─┘这样既能隔离私有空间,又能支持共享库、共享内存、copy-on-write 等机制。
Rings
Rings 是一种多级权限保护结构。
大致思想:
- 最内层权限最高,可以访问所有资源;
- 外层权限逐渐降低;
- 普通用户程序在最低权限层,只能访问受限资源。
在 RISC-V 中,类似思想体现为 privilege levels:
- M-mode:Machine mode,最高权限;
- S-mode:Supervisor mode,通常运行 OS kernel;
- U-mode:User mode,运行用户程序。
Keys and Locks
Keys and locks 是另一类保护思想:
- 数据像被 lock 保护;
- 程序必须持有对应 key / capability 才能访问。
关键点是:
- key 不能由普通程序伪造;
- 硬件和 OS 必须能安全地传递 key;
- 权限本身必须受到保护。
Virtual Memory and Virtual Machine
Virtual memory 和 virtual machine 容易混淆,但层次不同。
Virtual Memory
Virtual memory 主要虚拟的是 memory:
virtual address space -> physical memory / secondary storage它解决的是:
- 地址空间抽象;
- 地址翻译;
- 内存扩容;
- 进程隔离;
- 页级保护与共享。
Virtual Machine
Virtual machine 虚拟的是整台机器。
在 CPU 和 OS 之间有一层:
Hardware / CPU |VMM / Hypervisor |Guest OS |ApplicationsVMM / hypervisor 向 guest OS 提供一个“像真实硬件一样”的抽象,让多个 OS 可以共享同一台物理机器。
因此:
- virtual memory 是 OS + MMU 提供的地址空间机制;
- virtual machine 是 hypervisor 提供的机器级虚拟化机制;
- 两者都会涉及地址翻译、权限保护和资源隔离。