概述
本章围绕数据级并行(DLP)与线程级并行(TLP)展开:先介绍 Flynn 分类与 SIMD/MIMD 的基本概念,再讲向量与阵列处理器(含向量流水、向量链、分段与 CRAY/RV64V 示例)及 GPU 的 SIMT 编程模型;接着讨论阵列的内存组织与互联网络、循环并行化策略,以及多处理器的内存模型与一致性协议(UMA/NUMA/COMA、MSI/MESI/目录协议);最后概览大规模并行系统与领域专用加速器(如 TPU)的设计要点与权衡,帮助读者在不同并行粒度上理解性能来源与瓶颈。
目录
- 概述
- 目录
- From ILP to DLP and TLP
- Flynn Classification
- SIMD: Vector Processor
- Vector Processing Methods
- Register-Register Vector Processor: CRAY-1
- Improving Vector Processor Performance
- Modern Vector Architecture: RV64V
- SIMD: Array Processor
- Memory Organization of Array Processors
- Interconnection Network
- Single-Stage Interconnection Network
- Static Network Topologies
- Dynamic Interconnection Network
- SIMD
- DLP in GPU
- Loop-Level Parallelism
- MIMD: Thread-Level Parallelism
- Cache Coherence
- Memory Consistency
- MIMD: MPP / COW / WSC
- Domain-Specific Architectures
From ILP to DLP and TLP
脉络
- pipelining:通过重叠不同指令的执行过程提高吞吐率;
- pipeline hazards:结构冲突、数据相关与控制相关如何限制流水;
- memory hierarchy:存储系统对整体性能的影响;
- ILP:通过动态调度、乱序执行等手段挖掘指令级并行。
这些技术主要仍然围绕单个处理器内部的执行效率展开。而并行层次:
- DLP(Data-Level Parallelism):对大量数据元素执行相同或相似的运算;
- TLP(Thread-Level Parallelism):让多个线程或任务并行执行。
DLP 与 TLP
- Data-Level Parallelism
同一操作可以作用于大量彼此独立的数据。例如:
其中每个元素的加法都可以独立进行,因此天然适合并行执行。
- Thread-Level Parallelism
程序能够划分为多个相对独立的线程或任务,每个执行实体运行自己的指令流,并在需要时通信或同步。
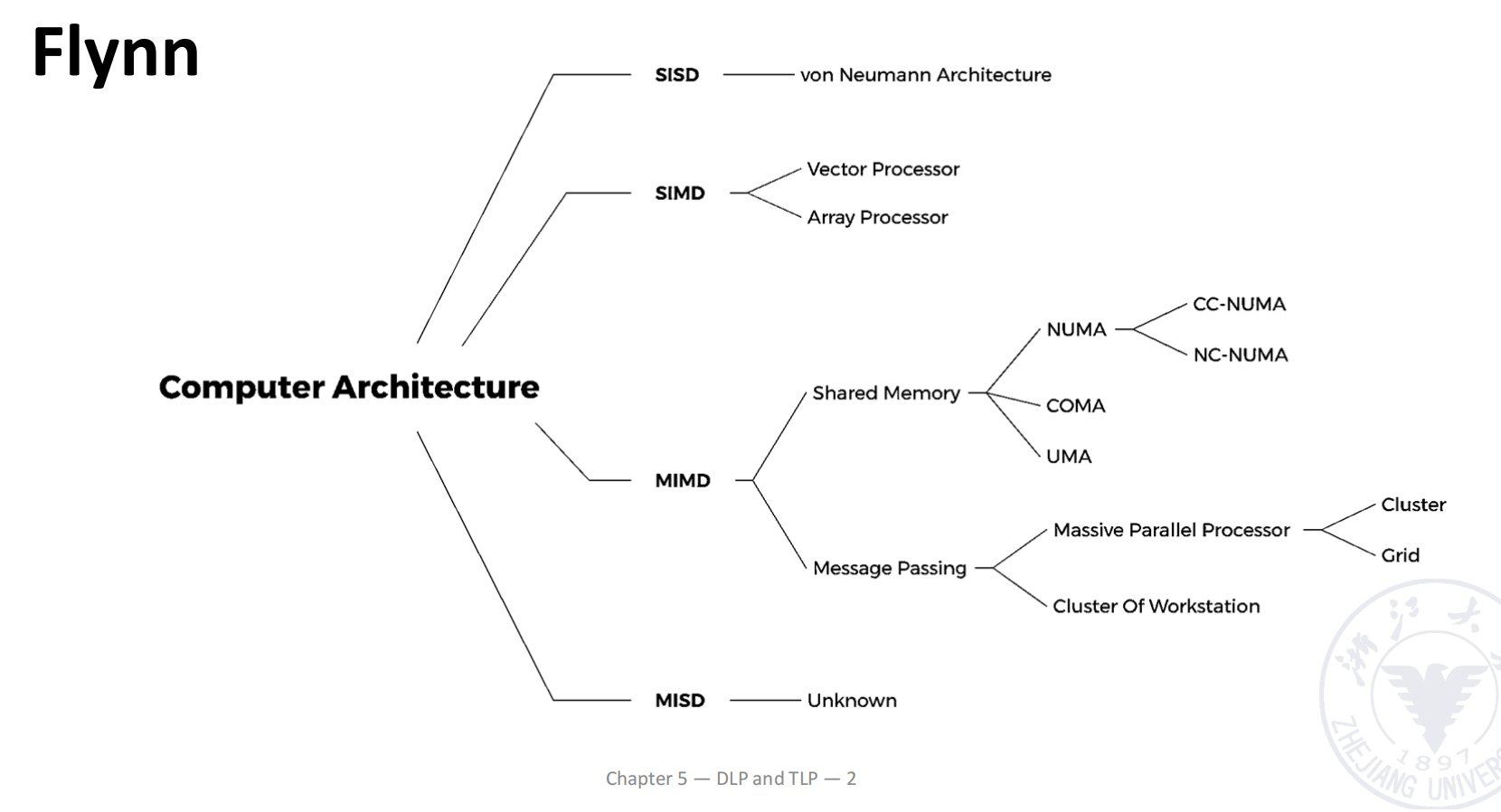
Flynn Classification
Flynn 分类法按照 instruction stream(指令流) 与 data stream(数据流) 的数量,将计算机体系结构划分为四类:
| 类型 | 全称 | 基本含义 | 本课程对应内容 |
|---|---|---|---|
| SISD | Single Instruction Stream, Single Data Stream | 单指令流、单数据流 | 普通标量处理器、流水线、ILP |
| SIMD | Single Instruction Stream, Multiple Data Streams | 单指令流、多数据流 | 向量处理机、阵列处理机 |
| MISD | Multiple Instruction Streams, Single Data Stream | 多指令流、单数据流 | 实际较少使用 |
| MIMD | Multiple Instruction Streams, Multiple Data Streams | 多指令流、多数据流 | shared memory、message passing 等多处理器结构 |
SIMD 的核心特点是:
- 只有一条控制指令流;
- 同一条指令作用于多个数据元素;
- 特别适合规则的数据并行任务。
 ---
---SIMD: Vector Processor
Vector Processor 与 Scalar Processor
- Vector processor(向量处理机)
具有向量数据表示与对应向量指令的流水处理器。它可以用一条向量指令处理一整个向量中的多个元素。
- Scalar processor(标量处理器)
没有专门的向量数据表示与向量指令,只能把各个元素的运算展开为标量指令逐项处理。
例如,对两个向量求和:
向量处理机可以从结构上把它视为一次向量运算;标量处理器通常需要通过循环逐项执行:
C[0] = A[0] + B[0]C[1] = A[1] + B[1]...C[N-1] = A[N-1] + B[N-1]为什么向量特别适合流水线
向量运算的重要特点是:同一向量运算中的不同元素之间通常没有数据相关性。
例如:
其中:
- 的计算不依赖 ;
- 的计算不依赖 ;
- 所有元素都执行相同类型的运算。
这恰好符合流水线最理想的工作负载:
- 功能一致;
- 数据不断流入;
- 相邻任务之间没有 RAW 依赖阻塞;
- 流水线一旦装满,就可以持续输出结果。
但如果向量处理方式选择不当,仍然可能引入:
- 数据相关;
- 频繁的功能切换;
- 向量寄存器或功能部件冲突。
因此,向量处理机设计的核心问题是:怎样组织向量运算,使流水线真正保持高吞吐率。
Vector Processing Methods
如下运算作为贯穿例子:
其中 都是长度为 的向量,乘法表示逐元素相乘:
Horizontal Processing Method
**Horizontal processing(横向处理)**按元素从左到右完成整个表达式:
D1 = A1 × (B1 + C1)D2 = A2 × (B2 + C2)...DN = AN × (BN + CN)等价于循环中的两步计算:
Ki = Bi + CiDi = Ai × Ki对于每一个元素,都必须先做加法,再做乘法。因此:
| 指标 | 次数 |
|---|---|
| 数据相关 | 次 |
| 功能切换 | 次 |
问题在于:
- 每个元素内部都存在 RAW 相关:
- 若使用静态多功能流水线,每处理一个元素都要在加法与乘法功能之间切换,甚至需要先排空已有流水;
- 流水线不断被相关和切换打断,吞吐率很低,性能可能接近顺序执行。
因此:横向处理不适合向量处理机。
Vertical Processing Method
**Vertical processing(纵向处理)**先对整个向量执行一种运算,再切换到下一种运算:
执行过程是:
K1 = B1 + C1K2 = B2 + C2...KN = BN + CN
D1 = A1 × K1D2 = A2 × K2...DN = AN × KN此时:
| 指标 | 次数 |
|---|---|
| 向量指令之间的数据相关 | 1 次 |
| 功能切换 | 2 次 |
优点非常明显:
- 做 时,加法流水线持续工作;
- 做 时,乘法流水线持续工作;
- 功能切换从每个元素都发生,下降到每个向量运算阶段才发生。
但它要求保存完整的中间向量 。早期纵向处理常使用 memory-memory structure:
- 源向量和目标向量都存放在 memory 中;
- 中间结果 也需要写回 memory;
- 后续乘法再从 memory 取出 。
典型机器包括:
- STAR-100;
- CYBER-205。
Vertical and Horizontal Processing Method
如果向量长度 很大,硬件无法一次容纳整个向量,就需要使用 vertical and horizontal processing(纵横处理 / 分组处理)。
设:
其中:
- :完整向量长度;
- :一个向量寄存器组一次能够容纳的元素数;
- :完整长度分组数;
- :剩余元素数。
当 时,剩余元素也构成一组,因此共处理 组。
处理原则是:
- 组内纵向处理:一组内部先完成 ,再完成 ;
- 组间横向推进:第一组处理完后,再处理第二组,直到最后一组。
在 的情况下:
| 指标 | 次数 |
|---|---|
| 数据相关 | 次 |
| 功能切换 | 次 |
这种方式对应于 register-register structure:
- 设置可以快速访问的向量寄存器;
- 源向量、目标向量和中间结果尽可能保存在向量寄存器中;
- 运算部件直接与向量寄存器相连;
- 避免每个中间向量都来回访问 memory。
典型寄存器型向量机包括:
- CRAY-1;
- 银河一号(YH-1);
- GRAP-3;
- Earth Simulator 中的 SX-8 vector processor。
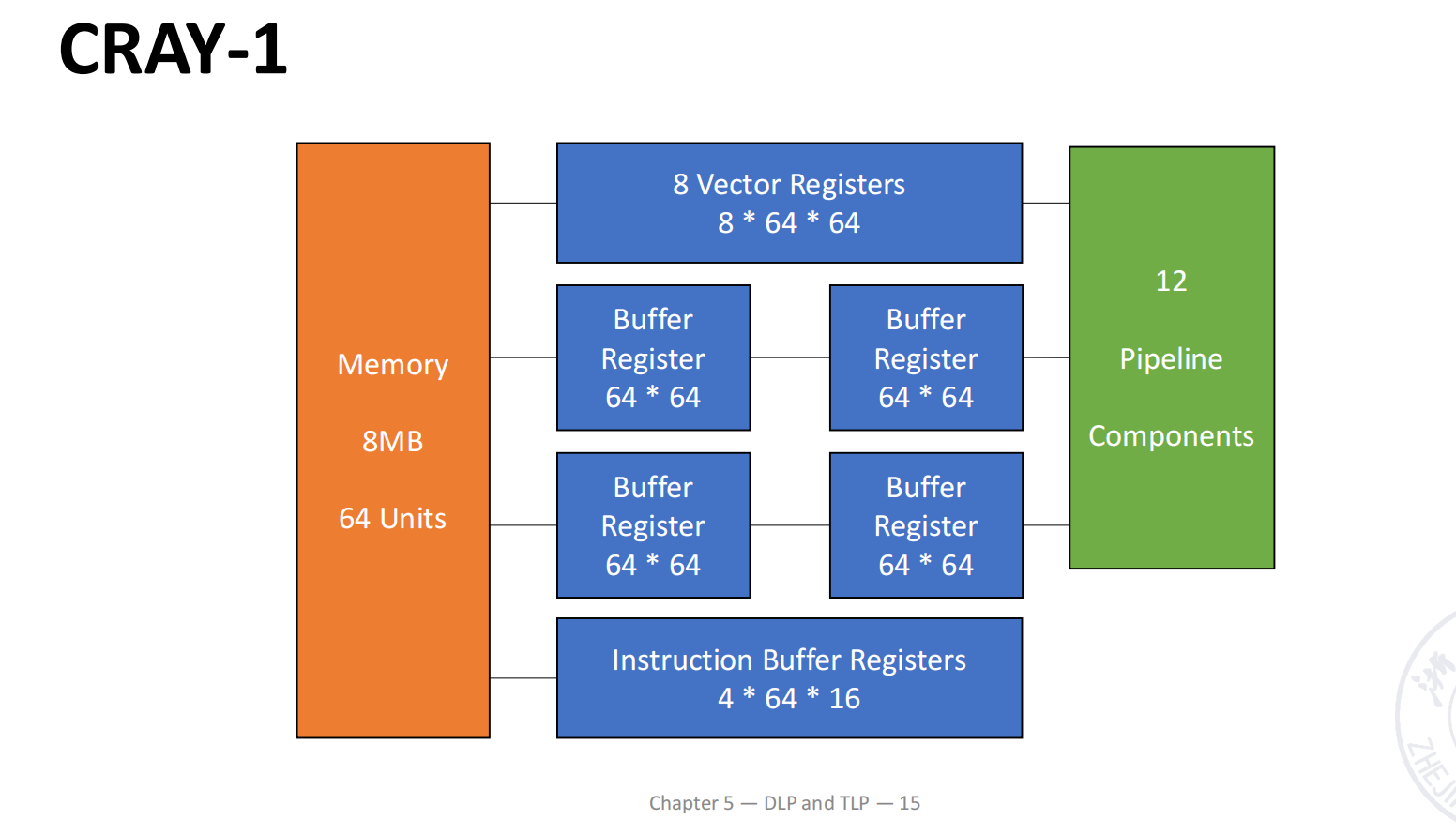
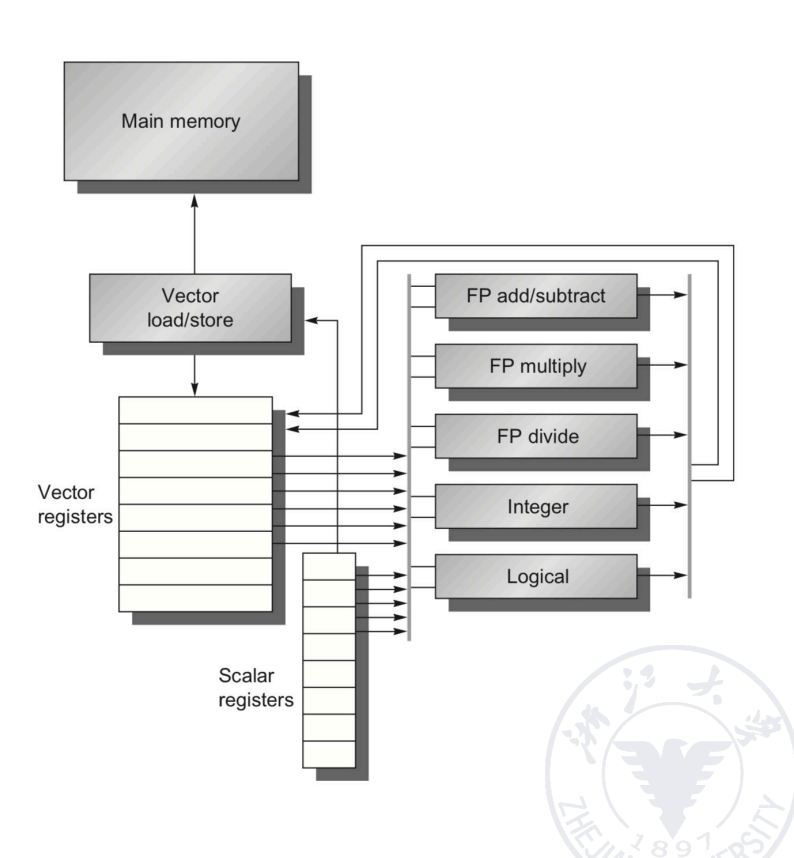
Register-Register Vector Processor: CRAY-1
CRAY-1 的基本结构
CRAY-1 是经典的寄存器型向量处理机,也是课堂用于说明向量流水结构的主要例子。
结构特征包括:
- 采用 register-register 的向量运算方式;
- 具有 12 条能够并行工作的单功能流水线,可分别支持地址、标量和向量运算;
- 具有向量寄存器组,用于保存源向量、目标向量与中间结果;
- 向量寄存器规模可表示为 8 个向量寄存器,每个寄存器含 64 个元素,每个元素为 64 bit;
- 典型性能描述为 100 MFLOPS,clock period 为 12.5 ns。
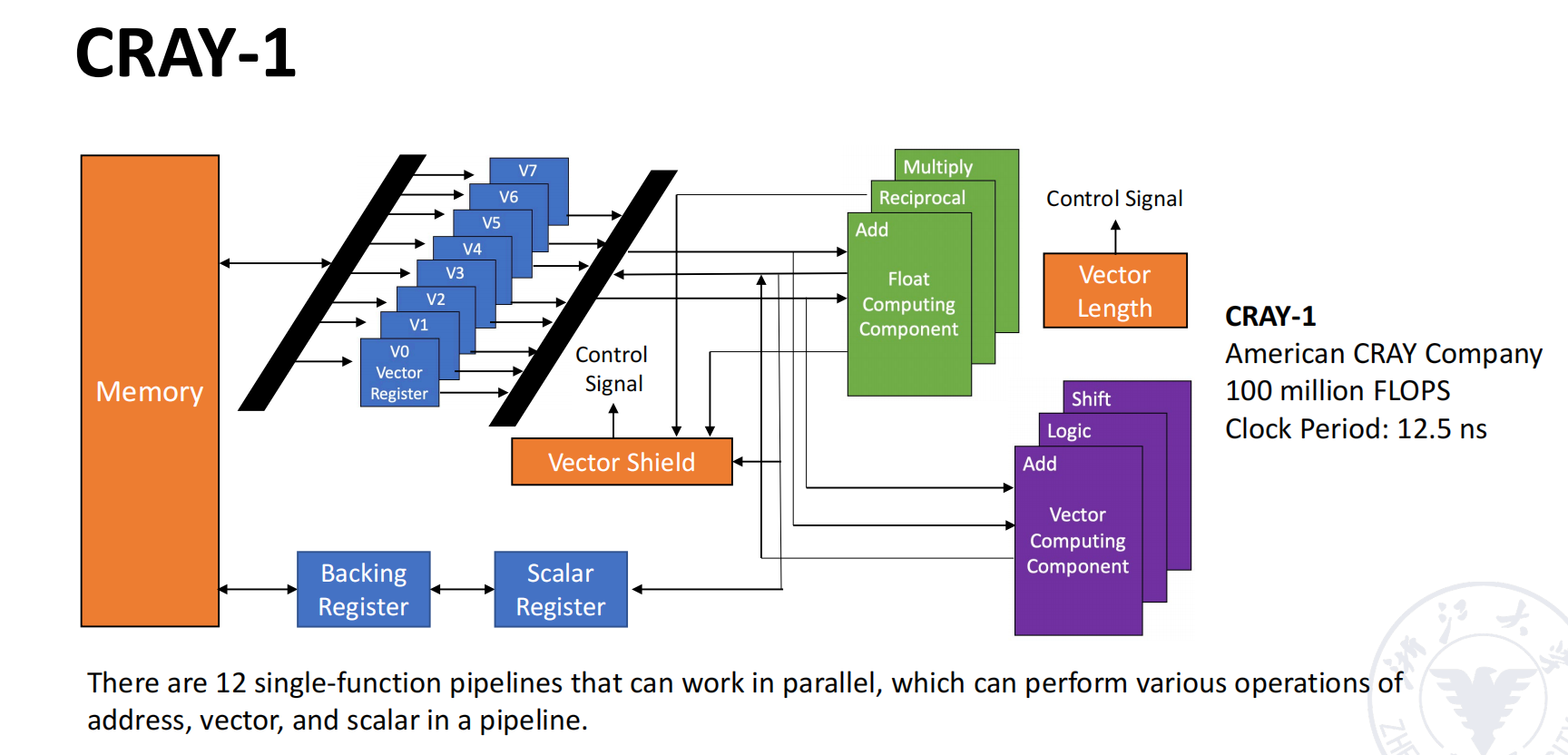
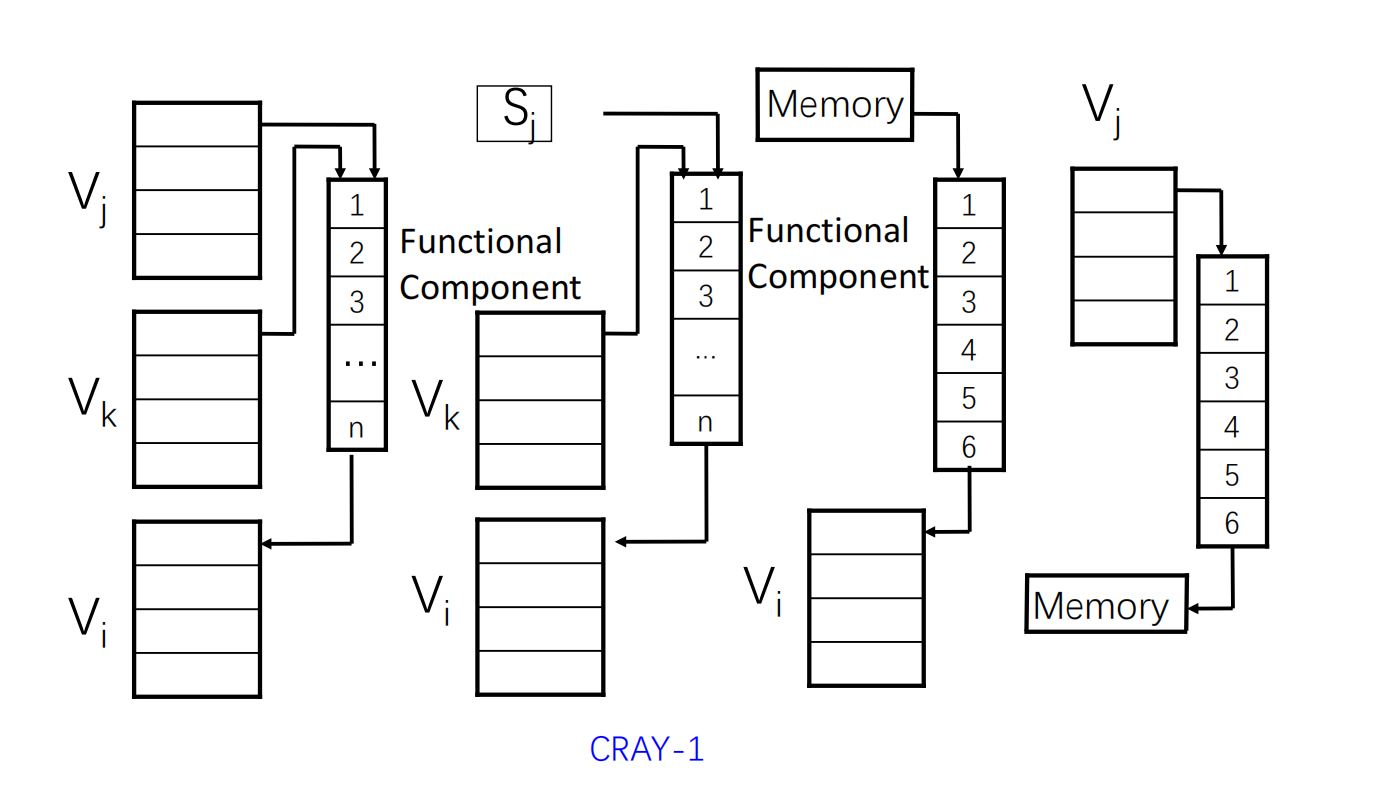
向量寄存器与功能部件连接
CRAY-1 中:
- 每个向量寄存器 都通过独立总线连接到多个向量功能部件;
- 每个向量功能部件也具有将结果送回向量寄存器的结果通路;
- 当指令之间没有寄存器冲突和功能部件冲突时,不同向量指令可以并行工作。
这类结构的优势在于:
- 中间结果不必频繁写回 memory;
- 多条独立向量指令可以同时占用不同流水线;
- 能够进一步支持后面的 chaining 技术。
Vi Conflict
Vi conflict 指并行工作的向量指令使用了同一个向量寄存器作为源或目标,从而出现相关或通路争用。
- 写后读相关:
V0 ← V1 + V2V3 ← V0 × V4第二条指令需要读取第一条指令写出的 ,存在 RAW 相关。
- 共同读取同一向量寄存器:
V0 ← V1 + V2V3 ← V1 × V4两条指令都需要读取 。是否能并行执行取决于寄存器与通路是否支持并行读出。
Functional Conflict
Functional conflict 指多条同时希望执行的向量指令需要使用同一个功能部件,而硬件中对应部件数量不足。
例如,两条向量乘法指令同时需要使用唯一的 vector multiply pipeline,就会发生功能部件争用。
因此,向量机器虽然适合流水线,也仍然要检查:
- 向量寄存器之间的相关或端口冲突;
- 功能部件是否足够;
- 是否存在能够支持并行/链接的数据通路。
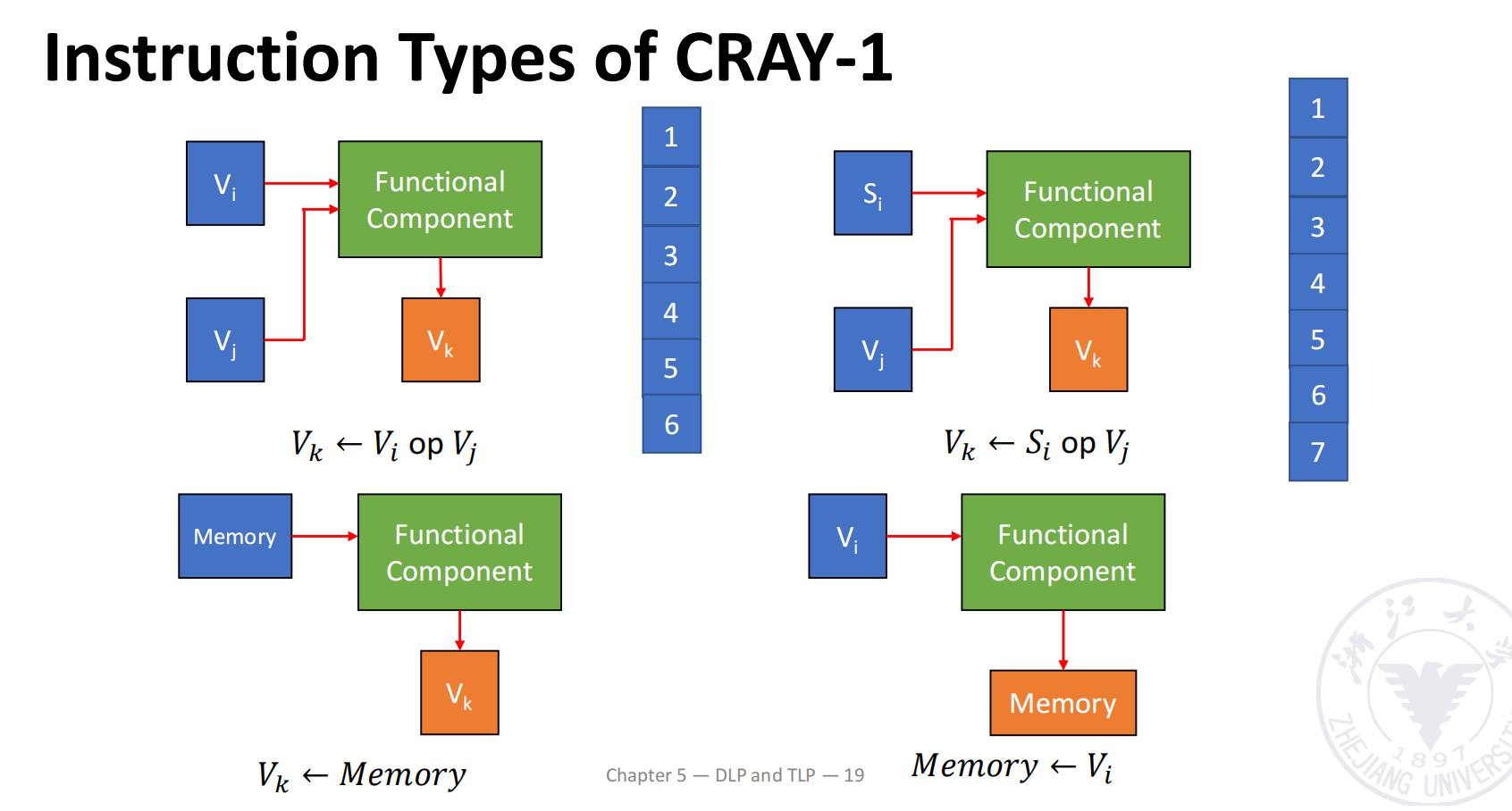
CRAY-1 中的向量指令类型
CRAY-1 中的主要向量操作分为四类:
| 类型 | 形式 | 含义 |
|---|---|---|
| Vector-Vector | 两个向量逐元素运算,结果写入向量寄存器 | |
| Scalar-Vector | 标量与向量逐元素运算 | |
| Memory Load | 从 memory 读入向量 | |
| Memory Store | 将向量写回 memory |
在后面的性能计算例子中,采用如下启动延迟设定:
| 操作 | 中间功能部件拍数 | 加上输入/输出传输后的首元素时间 |
|---|---|---|
| Memory load | 6 | |
| Vector add | 6 | |
| Vector multiply | 7 |
其中,流水线在输出第一个元素后,可以继续每拍输出一个后续元素。
Improving Vector Processor Performance
四类向量性能优化方法:
- 设置多个能够并行工作的功能部件;
- 使用 vector chaining 加速存在依赖关系的向量指令串;
- 当向量长度超过硬件可容纳长度时,使用 segmented vector;
- 引入多个向量处理器,构成多处理器系统。
Multiple Functional Units
最直接的方式是增加硬件资源,使不同种类的向量操作可以并行执行。
在 CRAY-1 中,不同单功能流水线可以分别执行:
- 向量加减与逻辑运算;
- 浮点乘法等运算;
- 标量运算;
- 地址计算;
- 向量 load / store。
只要指令之间:
- 没有 Vi conflict;
- 没有 functional conflict;
- 不存在必须等待的数据相关;
就可以同时占用不同的功能部件,提高吞吐率。
这种方法本质上是:通过叠加硬件并行度换取更高性能。
Vector Chaining
基本思想
**Vector chaining(向量链接)**用于处理存在 RAW 相关、但可以由不同功能部件完成的向量指令。
普通纵向执行需要等待前一条向量指令把全部 个元素算完,后一条指令才开始。链接技术则允许:
当前一条向量指令产生第一个结果元素后,后一条指令立即消费该元素;后续元素按流水方式继续传递。
可以使用 chaining 的重要条件是:
- 两条指令存在可逐元素传递的写后读相关;
- 两条指令使用不同功能部件,不发生 functional conflict;
- 硬件存在从前一功能部件输出到后一功能部件输入的数据通路。
例子:
并作出如下假设:
- 向量长度 ,可以一次装入 CRAY-1 的向量寄存器,不需要分段;
- 和 已经分别存放在 与 中;
- 需要从 memory 载入 ;
- load 与 add 的首元素时间都是 拍;
- multiply 的首元素时间是 拍。
对应三条向量指令为:
(1) V3 ← A // load A from memory(2) V2 ← V0 + V1 // compute B + C(3) V4 ← V2 × V3 // compute A × (B + C)依赖关系如下:
- 指令 (1) 与指令 (2) 互相独立,可以并行执行;
- 指令 (3) 同时依赖指令 (1) 的 与指令 (2) 的 ;
- 指令 (3) 使用乘法部件,而前两条分别使用 memory pipeline 与加法部件,因此不存在 functional conflict;
- 所以指令 (3) 可以与前两条建立向量链接。
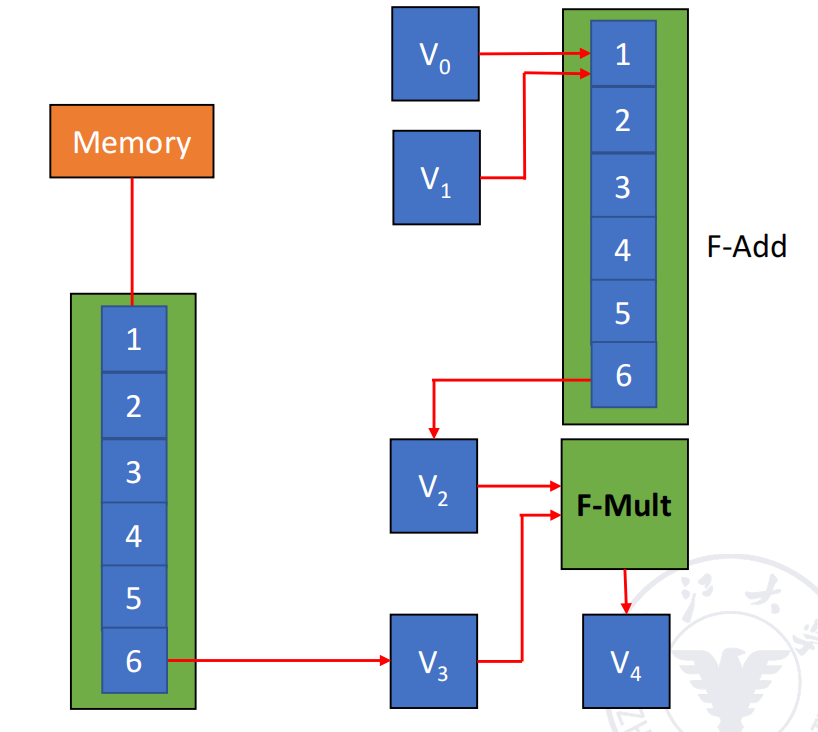
三种执行方式的时间比较
三条向量指令顺序执行
对于长度为 的向量,一条流水向量指令在产生第一个元素后,还需要 拍输出剩余元素。
因此:
前两条指令并行,第三条等待完整向量
指令 (1) 与 (2) 可以完全并行,其完成时间取两者最大值;完成后再执行指令 (3):
使用 vector chaining
指令 (1) 与 (2) 的第一个结果都在第 拍后到达。此时,不需要等待完整的 和 生成,就可以立即送入乘法流水线。
第一个乘法结果产生所需时间为:
随后每拍输出一个结果,因此:
三种方式对比如下:
| 执行方式 | 时间 |
|---|---|
| 三条指令顺序执行 | |
| 前两条并行,第三条等待完整向量 | |
| Vector chaining |
关键结论是:
- 并行功能部件已经能把时间从 降到 ;
- chaining 进一步把整个依赖链变为逐元素流动,将时间降到 ;
- 向量越长,省下的周期越明显。
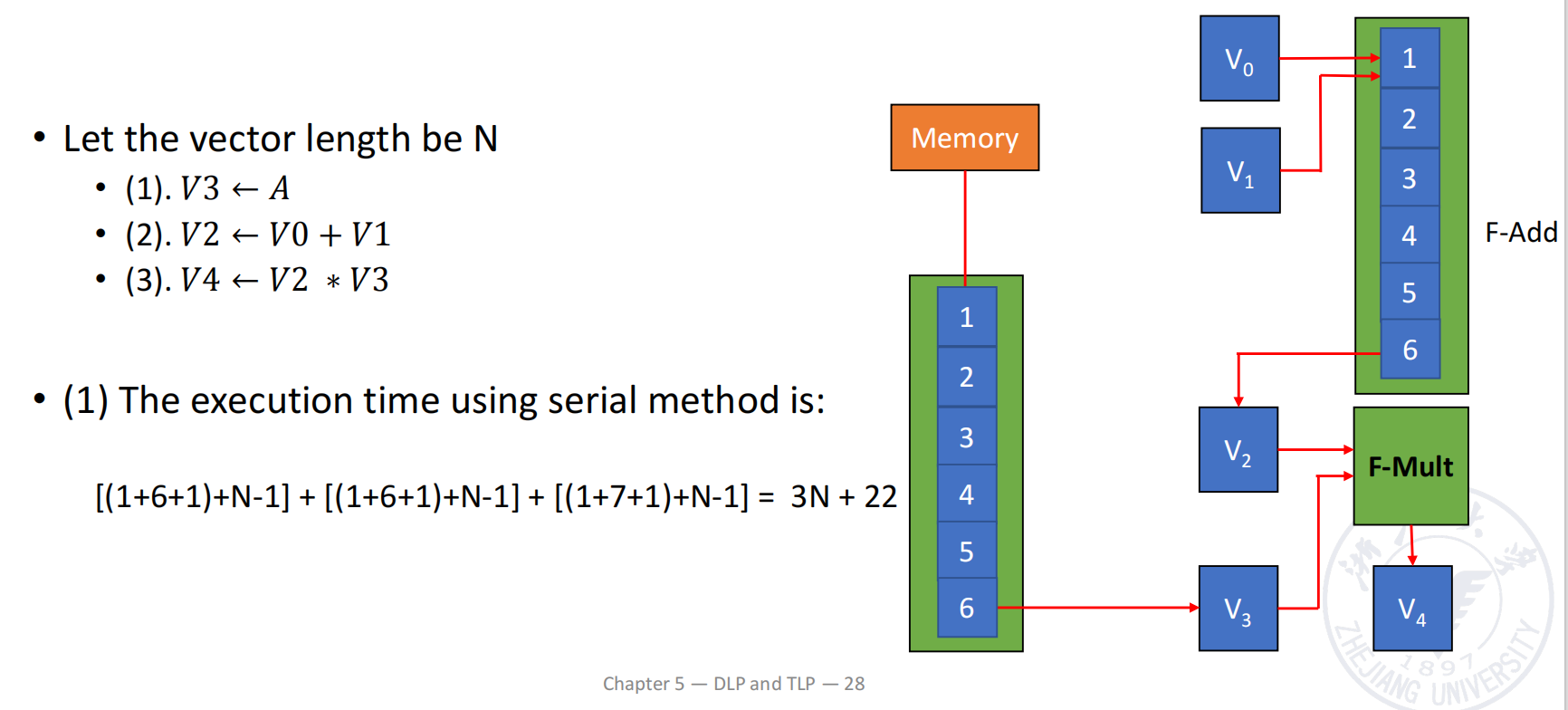
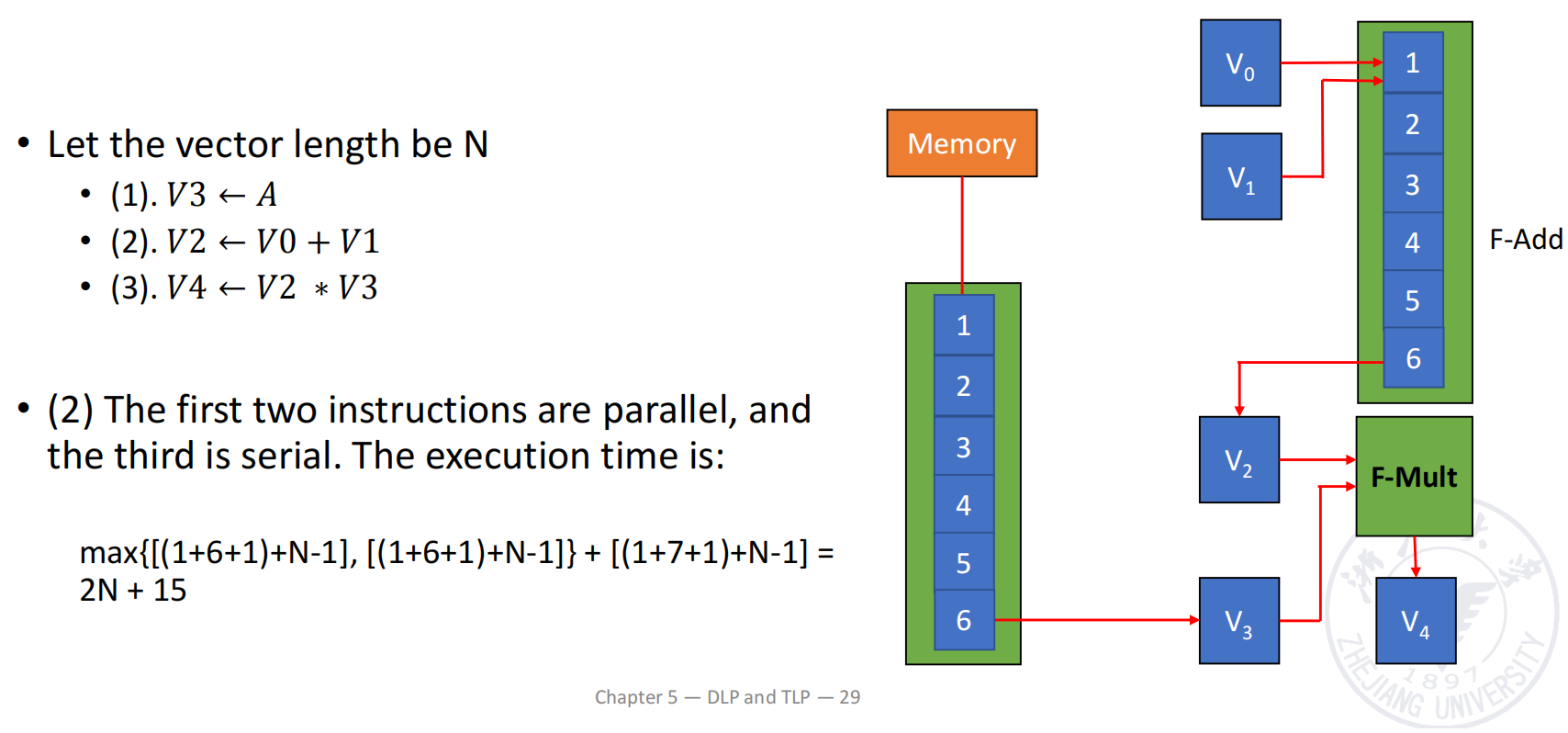
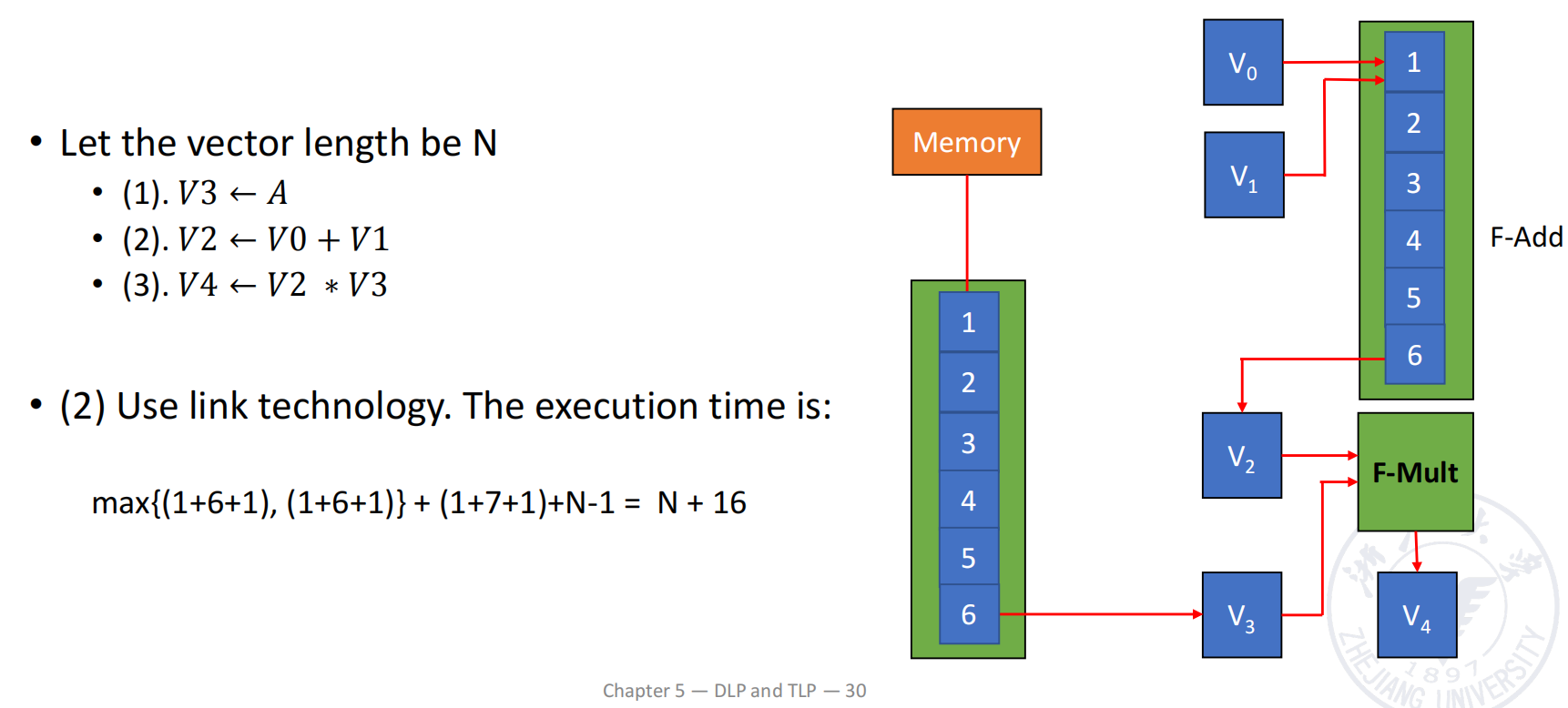
Segmented Vector
当向量长度大于向量寄存器能够一次处理的最大长度时,需要使用 segmented vector(分段向量) 技术。
核心做法是:
- 把长向量分解为若干固定长度的 segment;
- 每次循环只处理一个 segment;
- 每个 segment 内仍然采用向量指令和流水执行;
- 系统由硬件与软件共同控制这一过程,对程序员尽可能透明。
这一点与前面纵横处理方法一致:硬件资源有限时,必须通过分段让长向量继续享受向量执行优势。
Multi-Processor System
另一种提升向量性能的方法是增加更多向量处理器。
slides 给出的例子包括:
| 系统 | 结构特征 | 性能说明 |
|---|---|---|
| CRAY-2 | 4 个 vector processors | 浮点计算速度最高可达 1800 MFLOPS |
| CRAY Y-MP / C90 | 最多 16 个 vector processors | 进一步提升并行向量吞吐率 |
这种方法的本质仍然是:通过更多硬件执行资源提高整体并行能力。
Modern Vector Architecture: RV64V
RV64V 的结构
现代处理器中的向量结构仍然能够看到 CRAY-1 的设计思想。
RV64V 的结构特点包括:
- 整体设计 loosely based on Cray-1;
- 具有向量寄存器文件;
- register file 具有 16 个 read ports 与 8 个 write ports;
- 向量功能部件 fully pipelined,并检测 data hazards 与 control hazards;
- vector load-store unit fully pipelined,在初始延迟之后可以每个 clock cycle 传输一个 word;
- 同时保留标量寄存器:31 个 general-purpose registers 与 32 个 floating-point registers。
DAXPY:从标量循环到向量指令
DAXPY(Double Precision plus ) 计算:
Scalar RISC-V 实现
fld f0, a # Load scalar aaddi x28, x5, #256 # Last address to loadLoop:fld f1, 0(x5) # Load X[i]fmul.d f1, f1, f0 # a × X[i]fld f2, 0(x6) # Load Y[i]fadd.d f2, f2, f1 # a × X[i] + Y[i]fsd f2, 0(x6) # Store into Y[i]addi x5, x5, #8 # Increment index to Xaddi x6, x6, #8 # Increment index to Ybne x28, x5, Loop # Check if doneRV64V 向量实现
vsetdcfg 4*FP64 # Enable 4 DP FP vregsfld f0, a # Load scalar avld v0, x5 # Load vector Xvmul v1, v0, f0 # Vector-scalar multvld v2, x6 # Load vector Yvadd v3, v1, v2 # Vector-vector addvst v3, x6 # Store the sumvdisable # Disable vector regs在示例设定下:
- 标量实现需要执行 loop,动态执行约 258 条指令;
- 向量实现只需 8 条指令。
但这种大幅压缩指令数并不是无条件成立的。能否向量化取决于:
不同循环迭代之间是否不存在数据相关性。
对 DAXPY 而言,每个 只依赖对应的 与原 ,不同 之间互不依赖,因此可以安全地向量化。
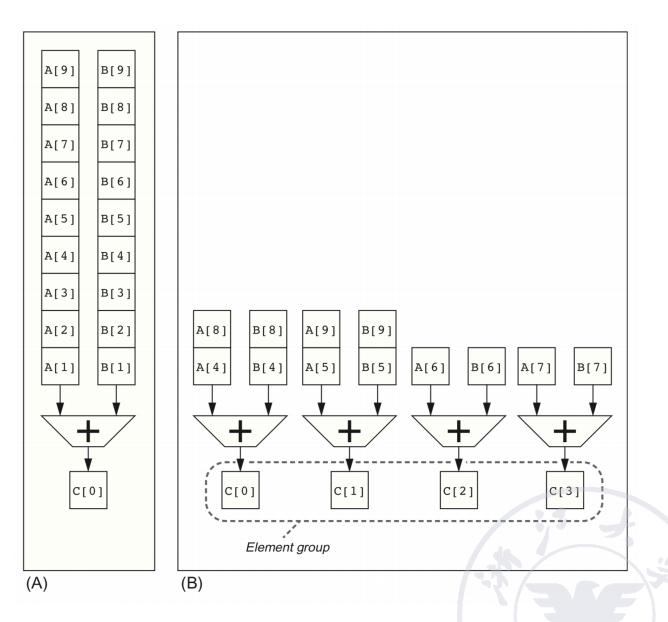
Multiple Lanes: One Cycle 处理多个元素
单条向量指令本身已经表达了多个元素的并行任务;硬件还可以进一步增加多个 lane,使同一个 clock cycle 内处理多个元素。
RV64V 类型向量指令具有一个非常重要的规律:
- 向量寄存器 的第 个元素只与向量寄存器 的第 个元素运算;
- 不会出现 与 、 的任意配对。
因此,硬件可以把不同元素稳定映射到不同 lane:
- 单 lane:每拍完成 1 个元素运算;
- 4 lanes:每拍完成 4 个元素运算;
- 多条 lane 同时生成的一组结果称为 element group。
这种固定的逐元素对应关系显著简化了高度并行向量单元的设计。
Gather-Scatter: 稀疏数据的向量访问
连续数组容易向量化,但稀疏矩阵或稀疏向量中的有效元素往往分散在不同位置。此时需要 gather-scatter 支持按索引向量完成不连续访存。
示例为:
for (i = 0; i < n; i = i + 1) A[K[i]] = A[K[i]] + C[M[i]];其中:
- 指定 中需要访问的非零元素位置;
- 指定 中需要访问的非零元素位置;
- 运算本质是对两个稀疏向量的有效元素求和。
使用索引向量后的 RV64V 风格代码为:
vsetdcfg 4*FP64 # 4 64b FP vector registersvld v0, x7 # Load K[]vldx v1, x5, v0 # Load A[K[]]vld v2, x28 # Load M[]vldi v3, x6, v2 # Load C[M[]]vadd v1, v1, v3 # Add themvstx v1, x5, v0 # Store A[K[]]vdisable # Disable vector registers这里:
vldx/vldi表示依据索引向量进行非连续读取;vstx表示依据索引向量写回离散位置;- 向量结构不只适用于连续内存,也可以用于带索引的数据访问模式。
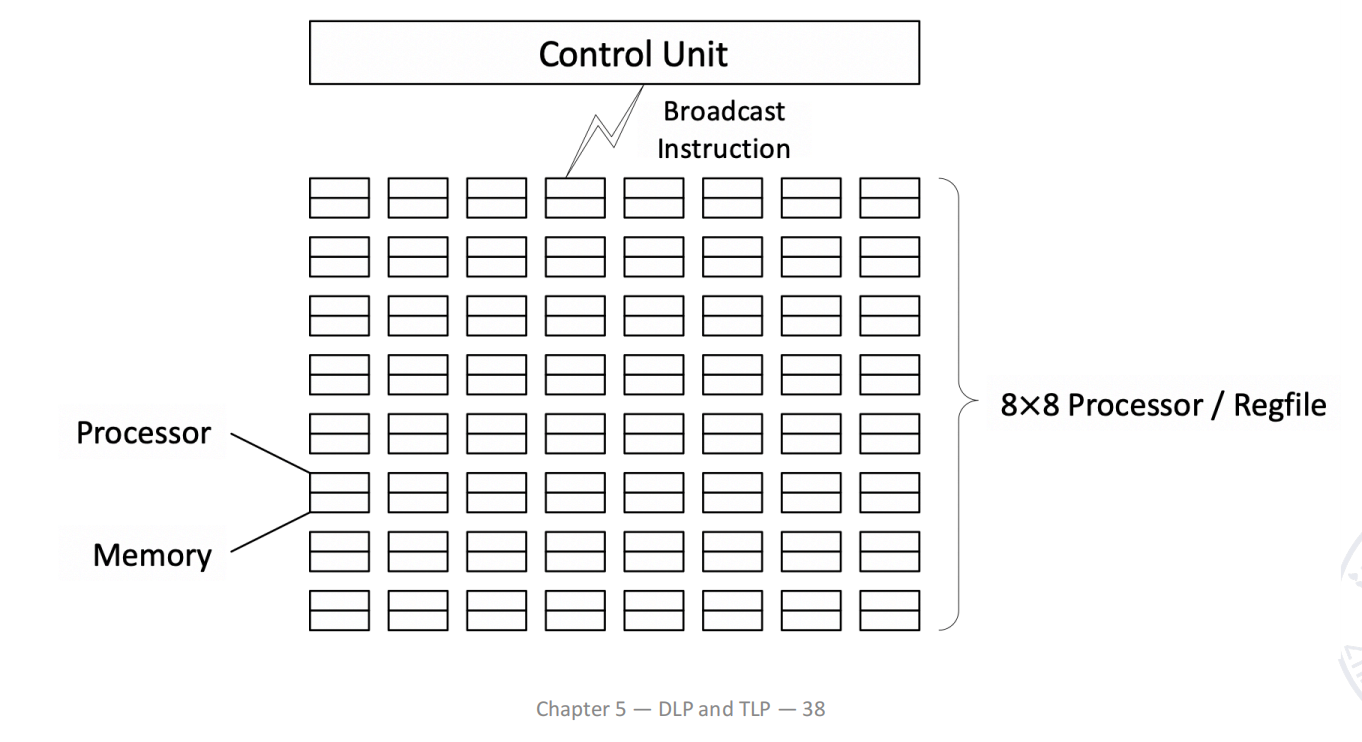
SIMD: Array Processor
阵列处理机的基本概念
SIMD 的另一种实现方式是 array processor(阵列处理机)。
阵列处理机由多个 processing element 构成:
其基本特征是:
- 设置 个 processing elements;
- 这些 PE 以某种互联方式组成阵列;
- 在单个控制单元控制下,多个 PE 对各自数据并行执行同一条指令;
- 因此它也属于 SIMD;
- 阵列处理机有时也称为 parallel processor。
典型历史机器是 ILLIAC IV。
Vector Processor 与 Array Processor 的侧重点
比较了两者的出发点:
| 结构 | 更依赖什么 | 核心直觉 |
|---|---|---|
| Vector processor | 程序中的向量化机会 | 循环迭代无相关时,用少量向量指令表达大量并行操作 |
| Array processor | 硬件本身的 PE 与互联组织 | 构造大量 processing elements,让它们在统一控制下同时执行 |
因此:
- 向量处理机首先要求程序具有适合向量化的数据并行模式;
- 阵列处理机首先要解决大量 PE 如何连接、如何访问数据的问题。
Memory Organization of Array Processors
按照系统中 memory 的组织方式,阵列处理机可以分为两类基本结构:
- Distributed memory(分布式存储器);
- Centralized shared memory(集中共享存储器)。
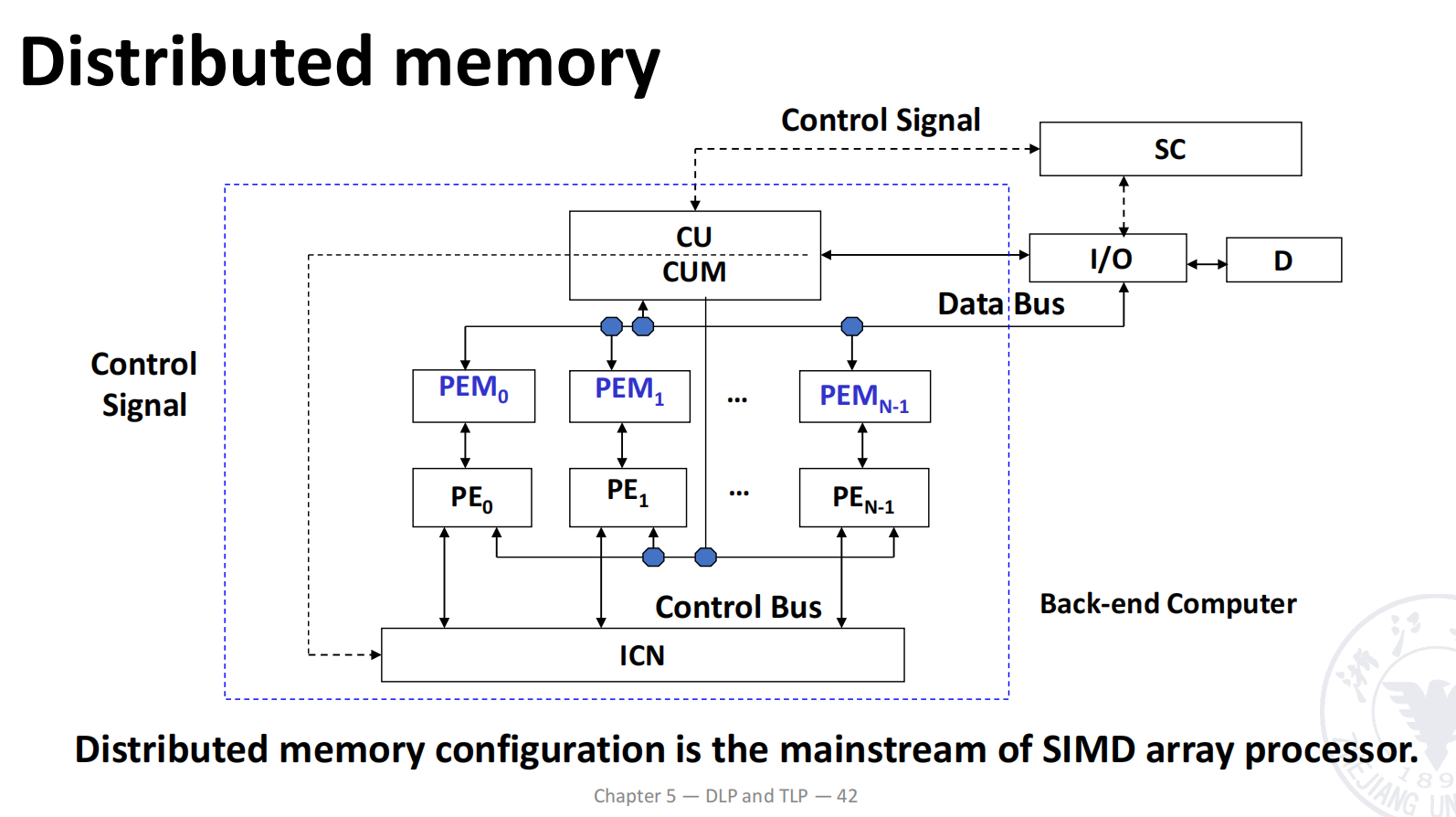
Distributed Memory
在 distributed memory 结构中:
- 系统包含 个 processing elements;
- 通常每个 PE 对应一个自己的 local memory;
- 本地 PE 访问自己的 local memory 最直接、速度最快;
- 当 PE 需要访问其他节点保存的数据时,需要通过内部互联网络进行通信。
其抽象结构为:
PE0 ↔ Local Memory 0PE1 ↔ Local Memory 1...PEN-1 ↔ Local Memory N-1 \ connected by ICN /slides 说明:distributed memory configuration 是 SIMD array processor 的主流组织形式。
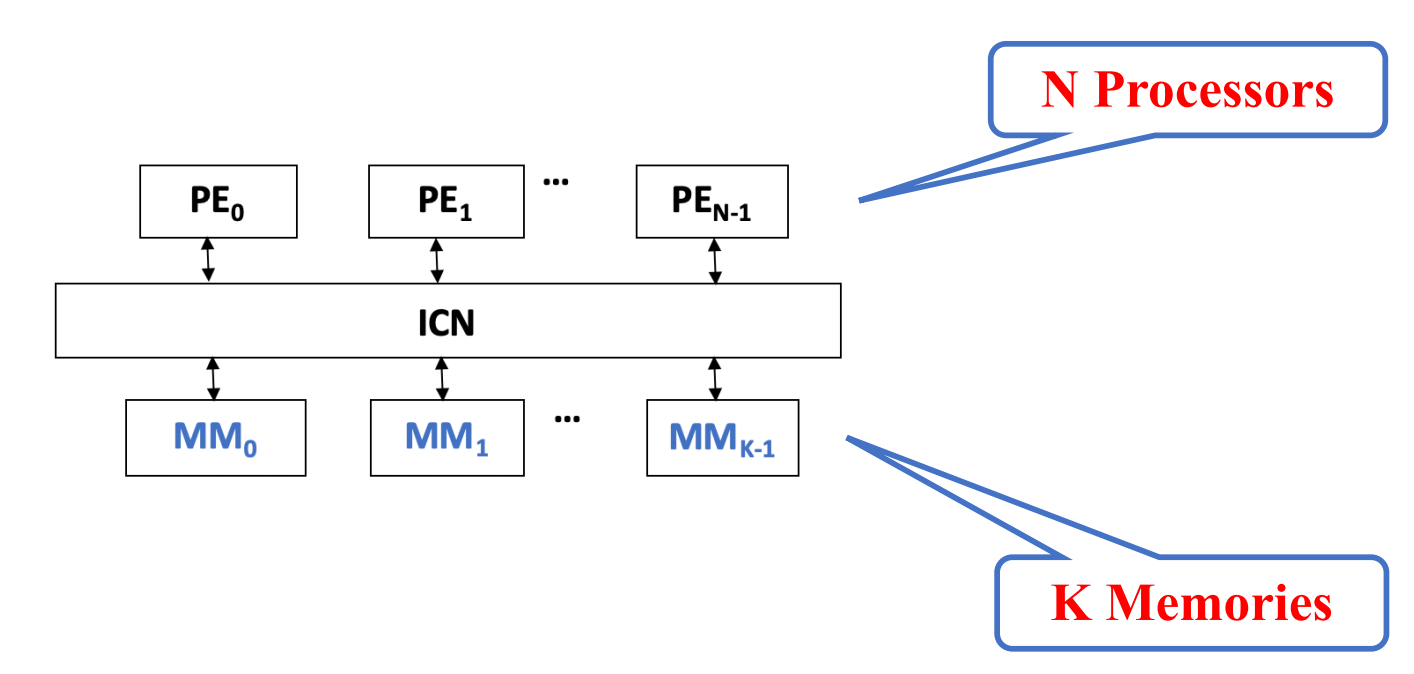
Centralized Shared Memory
在 centralized shared memory 结构中:
- 系统包含 个 processing elements;
- 系统集中设置 个 memory modules;
- 多个 PE 通过内部互联网络共同访问这些 memory modules;
- ICN 既要连接处理器,也要连接共享存储器模块。
其抽象结构为:
PE0, PE1, ..., PEN-1 ↓ ICN ↓MM0, MM1, ..., MMK-1与 distributed memory 相比:
| 对比点 | Distributed Memory | Centralized Shared Memory |
|---|---|---|
| 存储器位置 | 每个 PE 具有自己的 local memory | 多个 PE 共享 个 memory modules |
| 常见快速访问 | 访问自身 local memory | 通过 ICN 访问共享 memory |
| ICN 任务 | 连接 PE,使 PE 可以访问远程节点数据 | 在 PE 与 memory modules 之间提供访问通路 |
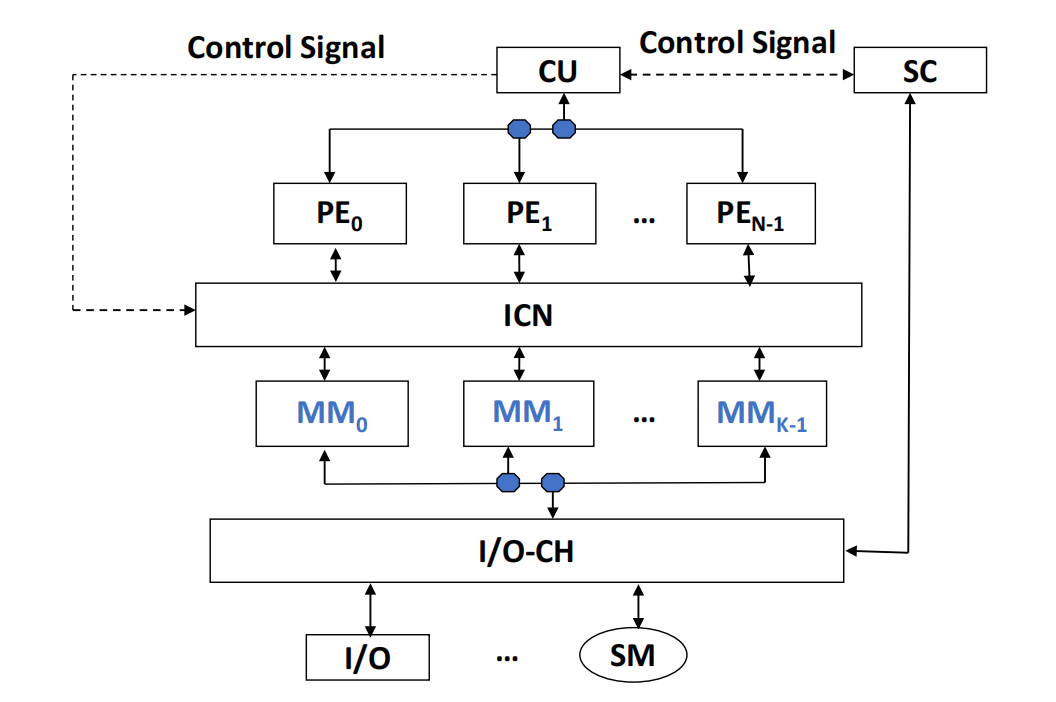
Interconnection Network
为什么需要 ICN
无论是 distributed memory 还是 centralized shared memory,阵列处理机都需要解决一个核心问题:
多个 PE 之间,或 PE 与 memory 之间,怎样以可实现的硬件成本建立数据通信路径?
并行计算机的 communication architecture(通信体系结构) 是系统设计的核心,它既包括底层互联网络,也与高层语言、软件工具、编译器和操作系统提供的通信支持有关。因此,并行计算机设计不仅要讨论互联网络,还要讨论由互联带来的性能与软件问题。
ICN(Interconnection Network,互联网络) 位于并行计算机内部,用来连接:
- 不同 processing elements;
- processing elements 与 memory modules;
- 相关的控制与数据通路。
从结构上看,ICN 是按照一定的 topology(拓扑) 与 control mode(控制方式) 组织 switching units,从而完成计算机内部多个处理器或功能部件之间互联的网络。
ICN 与普通计算机网络具有相似的术语和工作原理,但这里关注的是并行机器内部节点之间的高效数据交换;部分并行系统也可能直接采用高速 Ethernet 或 ATM 等网络技术作为互联基础。
直接连接路径的代价
如果要求 个 processing units 中任意两个都具有一条直接连接路径,那么所需无向连接对数为:
也就是说,连接数量随 以 增长。
例如,当 PE 数量达到几万级别时,完整直接连接所需的通路数量会极其庞大,几乎无法实际实现。
因此,阵列处理机必须考虑:
- 能否通过间接通路完成节点间通信;
- 怎样设计互联网络拓扑,使连接数可控;
- 怎样在硬件成本、通信能力与性能之间折中。
ICN 的组成与设计因素
Interconnection network 一般由五类部分构成:
- CPU / PE:发起计算与通信请求的处理单元;
- memory:被访问的数据存储单元,可以是 PE 的 local memory,也可以是 shared memory module;
- interface:从 CPU 或 memory 获取信息,并把信息发送到其他 CPU 或 memory 的接口设备,典型形式是 network interface card;
- link:传输 bit 的物理通道,可以是线缆、双绞线或光纤,也可以是串行或并行通路;
- switch node:互联网络中的交换与控制节点,具有多个输入端口和多个输出端口,可以进行数据缓冲与路径选择。
设计 ICN 时需要同时考虑四类问题:
| 设计因素 | 典型分类 | 含义 |
|---|---|---|
| topology | static topology / dynamic topology | 节点之间连接路径的组织方式 |
| timing mode | synchronous / asynchronous | 是否使用统一时钟 |
| exchange method | circuit switching / packet switching | 数据交换采用电路交换还是分组交换 |
| control strategy | centralized / distributed | 是否有全局控制器统一管理网络状态 |
其中 SIMD array processor 通常属于同步系统:多个 PE 在统一控制下执行同一条指令,因此更容易采用统一时钟。更一般的多处理器系统中,各处理器可能独立运行,此时就需要异步通信和更复杂的同步机制。
ICN 的分类与目标
按照连接路径是否在程序运行过程中变化,互联网络可以分为两类。
- Static network
静态网络的连接路径在系统构造后固定,程序执行过程中不会改变。它的重点是通过固定拓扑提供可预测的通信路径。
- Dynamic network
动态网络由开关构成,可以根据应用需求改变开关状态,从而改变连接路径。典型结构包括:
- bus;
- crossbar switch;
- multi-stage switching network。
互联网络的目标可以概括为:
用有限数量的连接方式,使任意两个 PE 能够在一步或少数几步内完成信息传输,从而支持并行算法执行。
如果只使用一个层次的连接来完成任意两个处理单元之间的传输,称为 single-stage interconnection network;如果把多个单级网络串联起来,称为 multi-stage interconnection network。
Interconnection Function
设互联网络有 个输入端:
如果输入端 与输出端 存在对应关系,那么 就描述了该互联网络的连接规律,称为 interconnection function(互联函数)。
通常把输入编号和输出编号都写成二进制。根据二进制位之间的变化规律,就可以写出对应的互联函数。
Single-Stage Interconnection Network
单级互联网络在一个网络层次上给出固定或有限的连接方式。它的结构简单、规则性强、成本低,适合构造大规模阵列的基本连接单元。
Cube Single-Stage Interconnection Network
对于 个输入和输出,令:
每个输入端编号写成 bit 二进制:
cube 网络有 个互联函数。第 个 cube 函数翻转编号中的第 位,其余位保持不变:
因此,cube 网络中的一条边表示两个节点的二进制编号只相差一位。
例子: 的 cube 网络
当 时,节点编号为 3 bit:
三个互联函数分别翻转不同 bit。
| 函数 | 翻转位 | 连接关系 |
|---|---|---|
如果把 8 个节点看成一个三维立方体,那么 分别对应立方体在三个维度上的边。
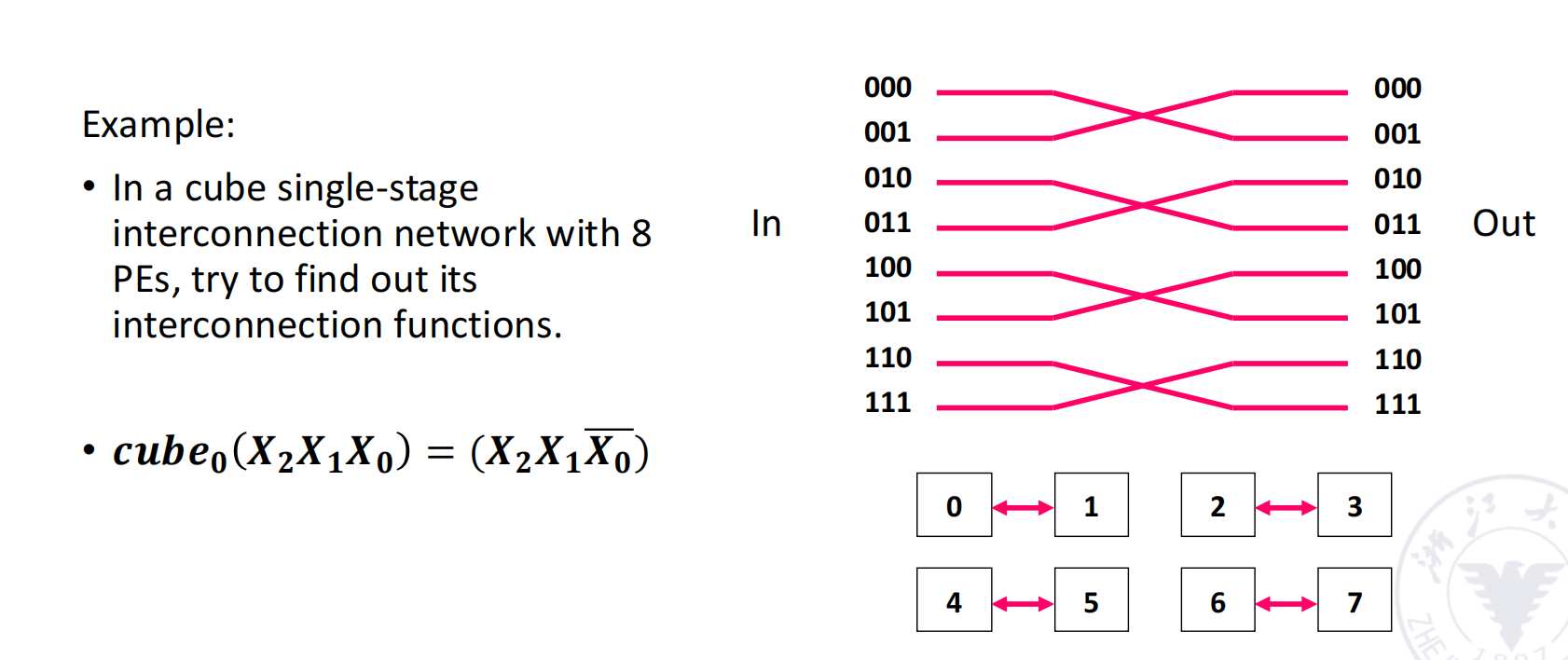
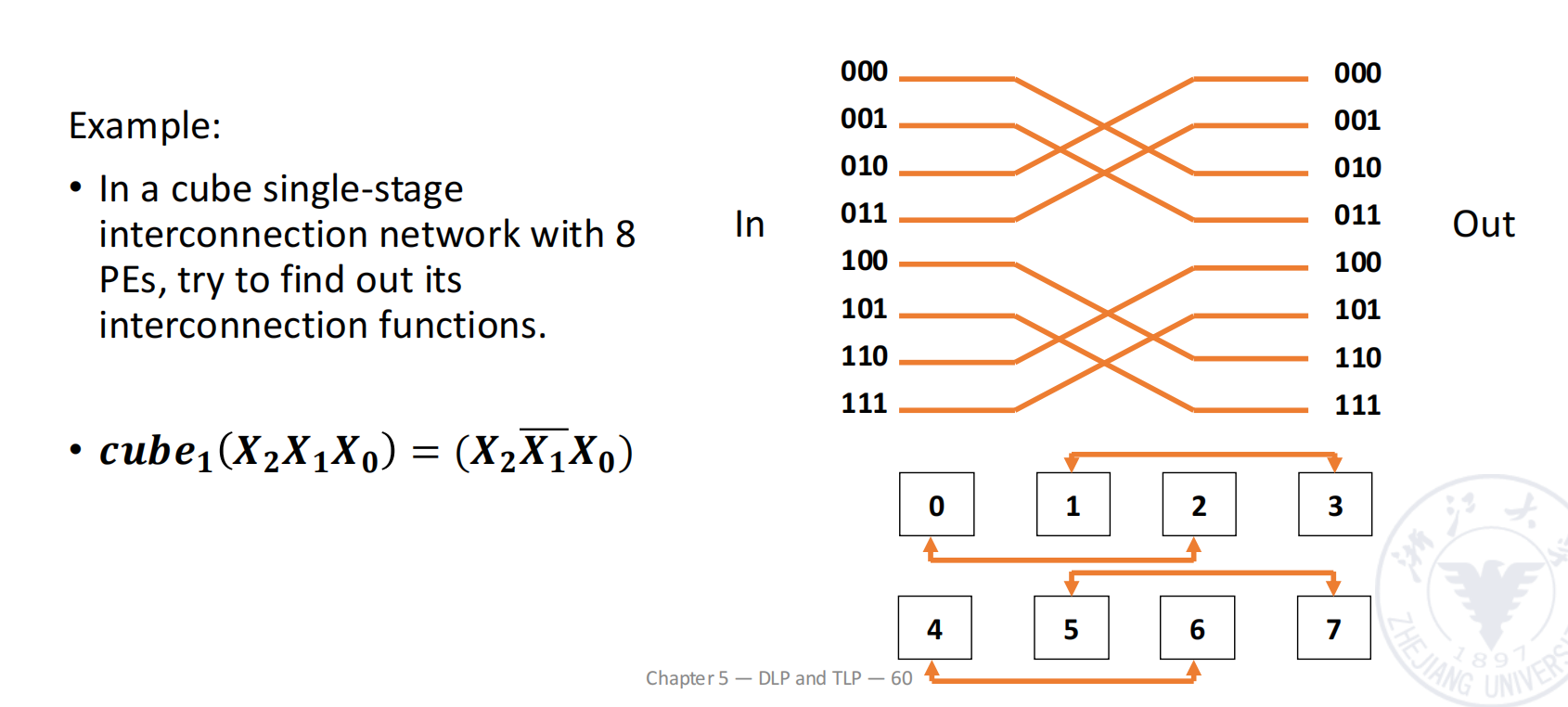
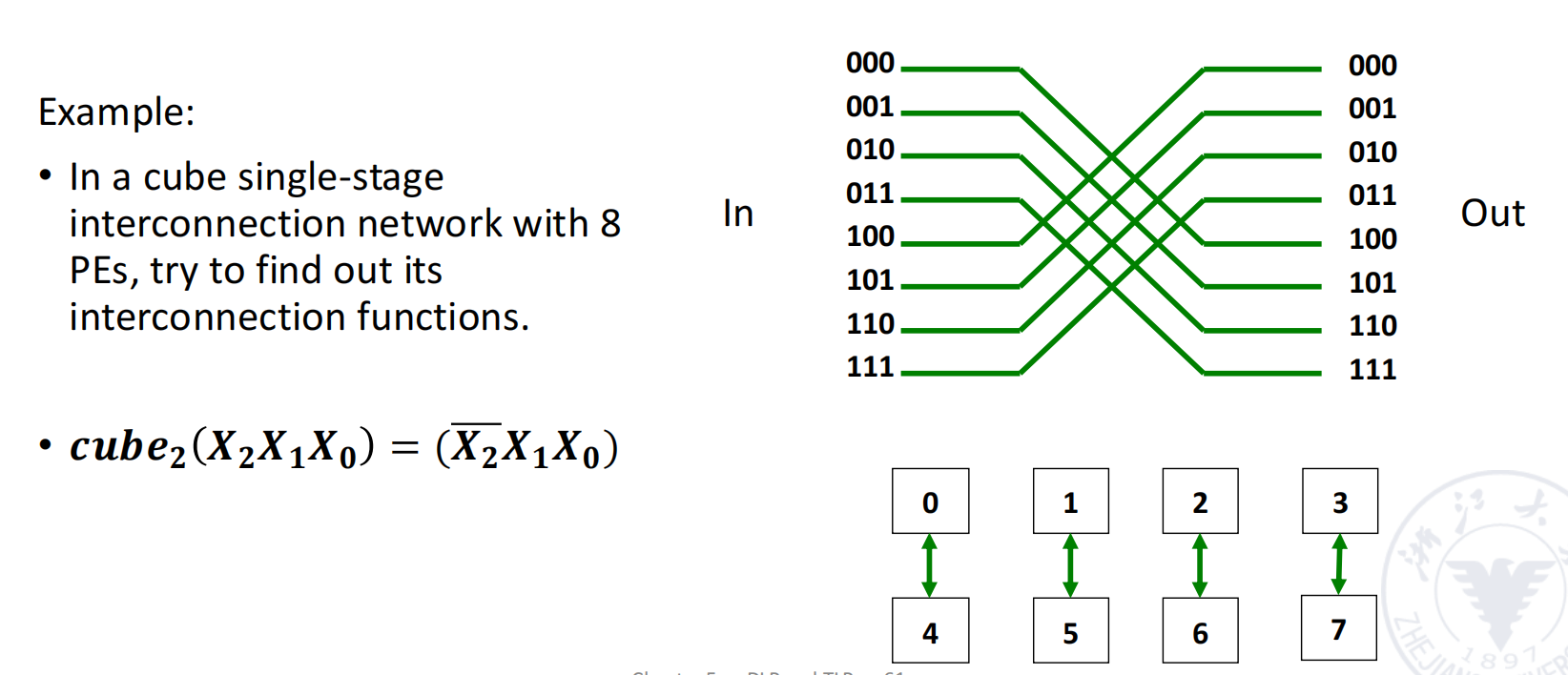
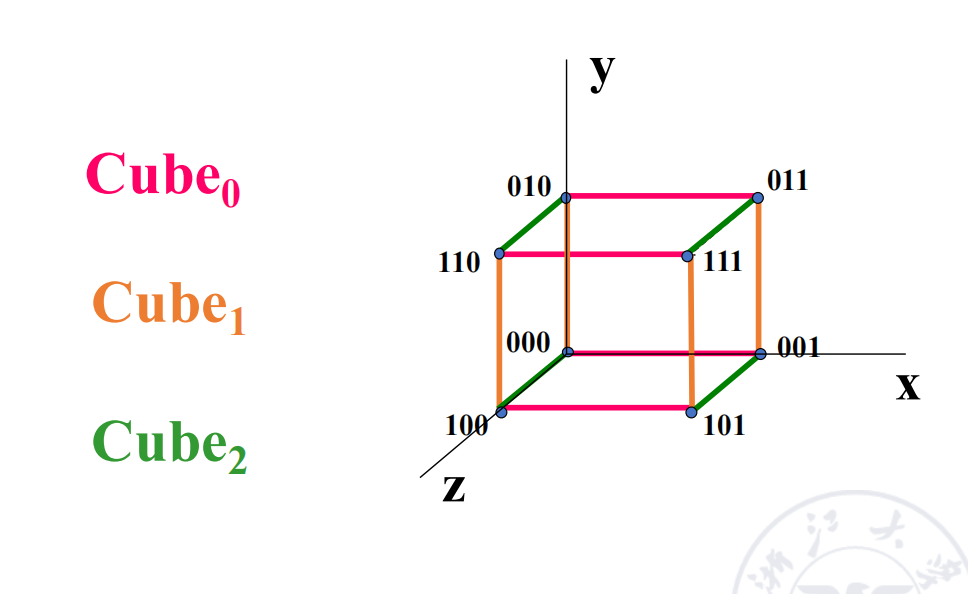
三维 cube 中,任意两个节点最多只需要经过 3 条边即可互相到达。推广到 维 hypercube:
- 节点数:;
- 每个节点度数:;
- 网络直径:;
- 最多经过 次传输即可完成任意两个 PE 之间的数据传递。
当 时,图形已经很难在三维空间直观画出,但二进制翻转 bit 的规律仍然成立。
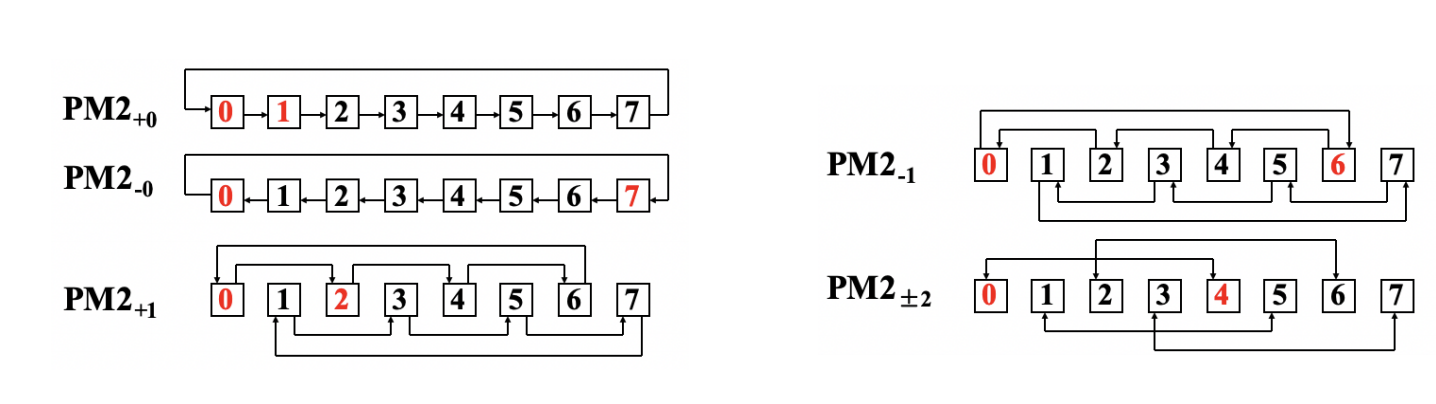
PM2I Single-Stage Interconnection Network
PM2I 的含义是 Plus Minus 。它包括加 与减 两类连接。
对于 个节点:
其中:
它的直观含义是:每个节点可以与编号相差 的节点相连,并且采用模 形成环状连接。
例子: 的 PM2I 网络
当 时:
| 步长 | 连接含义 | |
|---|---|---|
| 连接相邻节点: | ||
| 连接距离为 2 的节点: | ||
| 连接距离为 4 的节点: |
以节点 0 为例:
- 一步可以到达:;
- 两步可以到达:。
因此 PM2I 通过少量规则连接,就能让节点在少数步数内到达其他节点。
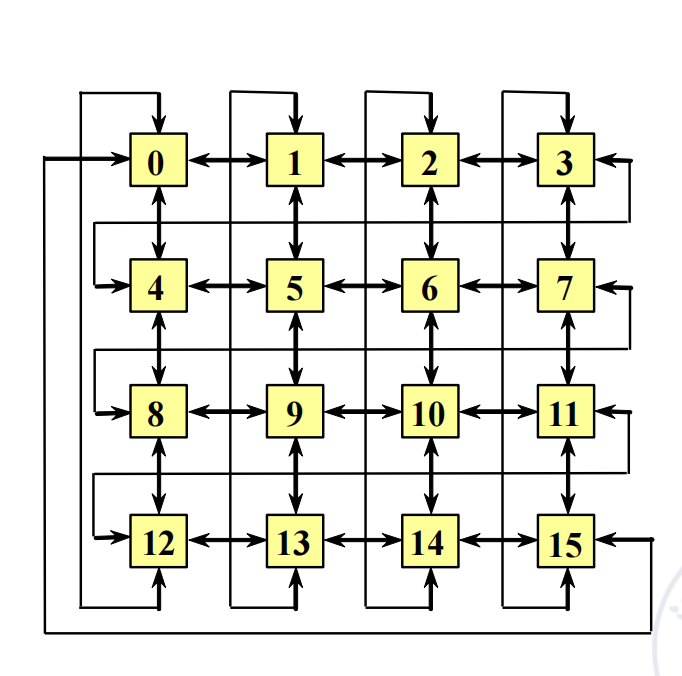
ILLIAC IV 的阵列互联使用了 和 ,从而在二维阵列中实现 PE 之间的上下左右相邻连接。
Shuffle Exchange Network
Shuffle exchange network 由两部分构成:
- shuffle:混洗函数;
- exchange:交换函数。
对于 个节点,设:
输入编号为:
shuffle 函数把最高位移动到最低位,其余位整体左移:
exchange 函数通常对应最低位翻转,也就是相邻奇偶节点之间的交换。
例子: 的 shuffle
当 时:
一次 shuffle 的映射关系为:
| 节点 | 二进制 | shuffle 后 | 连接到 |
|---|---|---|---|
| 0 | 000 | 000 | 0 |
| 1 | 001 | 010 | 2 |
| 2 | 010 | 100 | 4 |
| 3 | 011 | 110 | 6 |
| 4 | 100 | 001 | 1 |
| 5 | 101 | 011 | 3 |
| 6 | 110 | 101 | 5 |
| 7 | 111 | 111 | 7 |
二次 shuffle 的映射关系为:
| 节点 | 二进制 | shuffle 后 | 连接到 |
|---|---|---|---|
| 0 | 000 | 000 | 0 |
| 1 | 001 | 100 | 4 |
| 2 | 010 | 001 | 1 |
| 3 | 011 | 101 | 5 |
| 4 | 100 | 010 | 2 |
| 5 | 101 | 110 | 6 |
| 6 | 110 | 011 | 3 |
| 7 | 111 | 111 | 7 |
三次 shuffle 的映射关系为:
| 节点 | 二进制 | shuffle 后 | 连接到 |
|---|---|---|---|
| 0 | 000 | 000 | 0 |
| 1 | 001 | 001 | 1 |
| 2 | 010 | 010 | 2 |
| 3 | 011 | 011 | 3 |
| 4 | 100 | 100 | 4 |
| 5 | 101 | 101 | 5 |
| 6 | 110 | 110 | 6 |
| 7 | 111 | 111 | 7 |
连续 shuffle 次后,所有节点恢复到初始排列。对于 ,连续 shuffle 3 次后恢复。
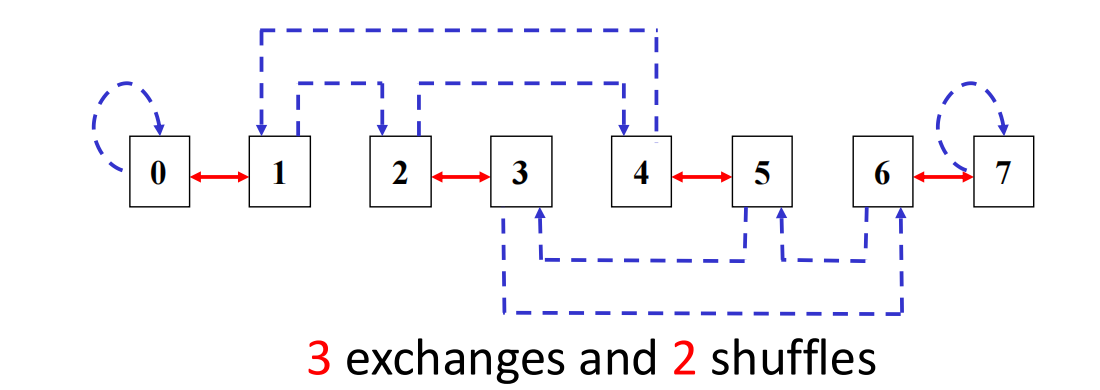
shuffle exchange 的最大距离为:
也就是最多需要 次 exchange 和 次 shuffle。例如从全 0 编号节点到全 1 编号节点,需要经过 3 次 exchange 和 2 次 shuffle。
单级互联网络的特点
单级互联网络的优点主要有:
- 结构简单,硬件成本低;
- 连接规则灵活,可以配合算法需求;
- 传输步数较少,有利于提高阵列操作速度;
- 规则性和模块化较好,便于扩展;
- 适合大规模集成。
它的限制也很明显:单级网络只提供有限种连接关系,若要支持更多连接模式,通常需要多次使用单级网络,或者把多个单级网络组合成多级网络。
Static Network Topologies
除了 cube、PM2I、shuffle exchange 这些互联函数,slides 还总结了常见的静态拓扑。它们可以从以下几个指标比较:
- scale:节点规模;
- degree:节点度数,即一个节点直接连接多少条边;
- diameter:网络直径,即任意两点之间最短路径长度的最大值;
- width / bisection width:把网络大致分成两半时需要切断的连接数量;
- symmetry:不同节点在拓扑中的地位是否等价;
- link:总连接数。
Linear Array
线性阵列有 个节点和 条边:
- 直径:;
- 节点度数:内部节点为 2,端点为 1;
- 对分宽度:1;
- 对称性差。
当 很大时,端到端距离过长,通信效率较低。

Circular Array
环形阵列把线性阵列首尾相连。
- 双向环:
- 连接数:;
- 直径:;
- 节点度数:2;
- 对称性好。
- 单向环:
- 连接数:;
- 直径:;
- 只能沿一个方向传输。
环比线性阵列更均匀,但每个节点仍然只有两个邻居,扩展到大规模时路径仍然较长。
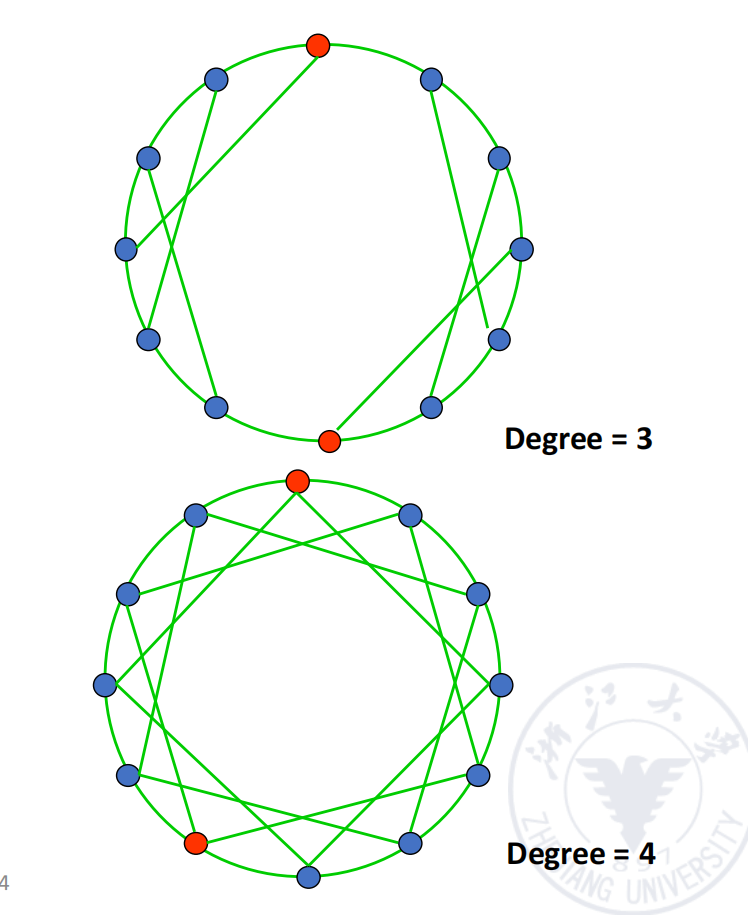
Loop with Chord Array
在环上增加 chord(弦)可以缩短通信路径,提高网络可靠性。对于 slides 中 12 个节点的双向环加弦:
- 节点度数为 3 时,连接数为 18;
- 节点度数为 4 时,连接数为 24。
增加 chord 的本质是用更多连接换取更小直径和更强容错能力。
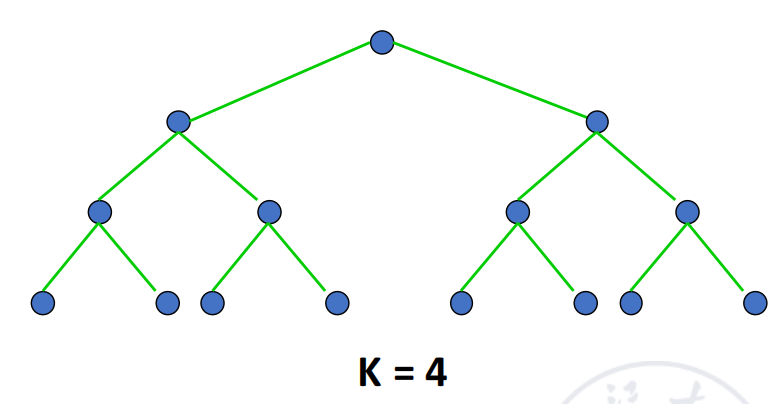
Tree Array
对于 层完全二叉树:
其特点是:
- 最大节点度数:3;
- 直径:,对应最左叶子到最右叶子的路径;
- 对分宽度:1;
- 对称性差。
树结构容易形成根部或高层节点瓶颈,因此可以扩展为 fat tree 或 tree with loop。
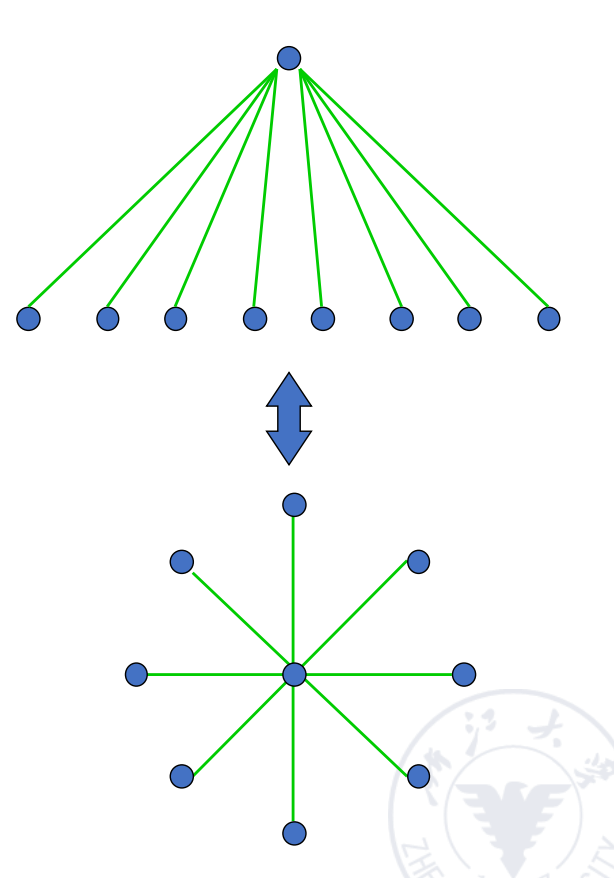
Star Array
星形阵列可以看成两层树。
- 连接数:;
- 直径:2;
- 中心节点度数:;
- 对分宽度:1;
- 对称性差。
星形结构路径很短,但中心节点压力极大,单点瓶颈明显。
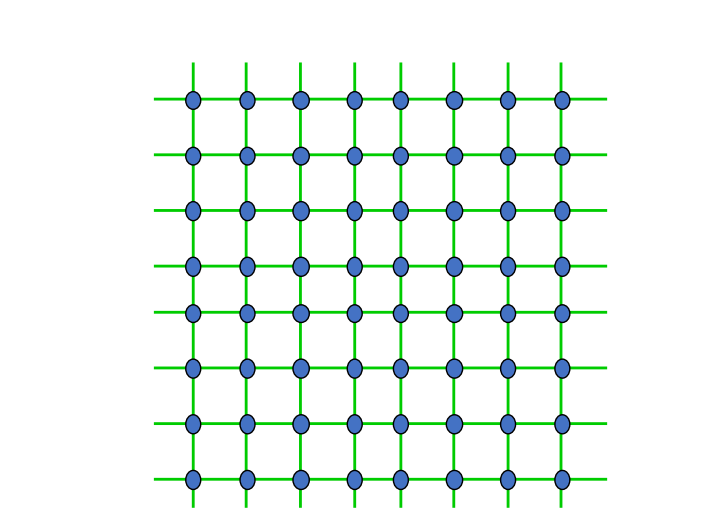
Grid 与 2D Torus
二维网格常用于规则并行计算。
对于 网格,:
- 连接数:;
- 直径:;
- 节点度数最多为 4;
- 对分宽度:。
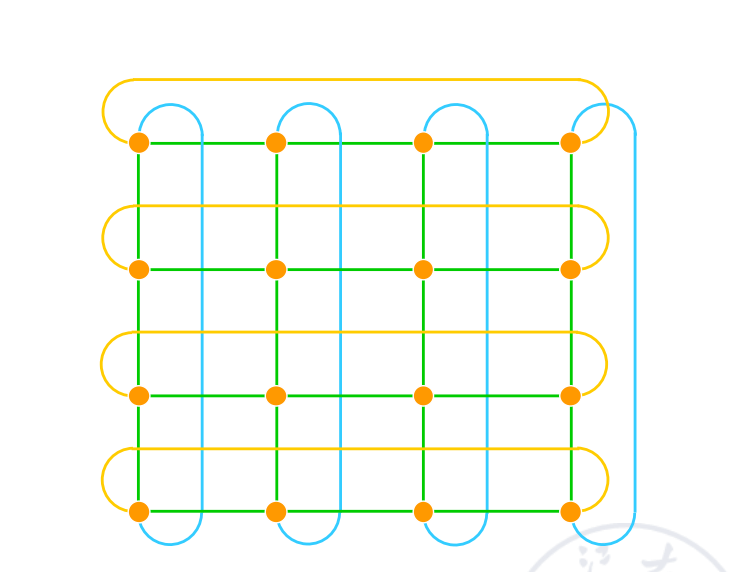
2D torus 在二维网格的基础上把每一行和每一列首尾相连:
- 连接数:;
- 直径约为 ;
- 节点度数为 4;
- 对称性更好。
Hypercube 与 Cube with Loop
维 hypercube 有:
- 节点度数:;
- 直径:;
- 对分宽度:;
- 连接数:;
- 对称性好。
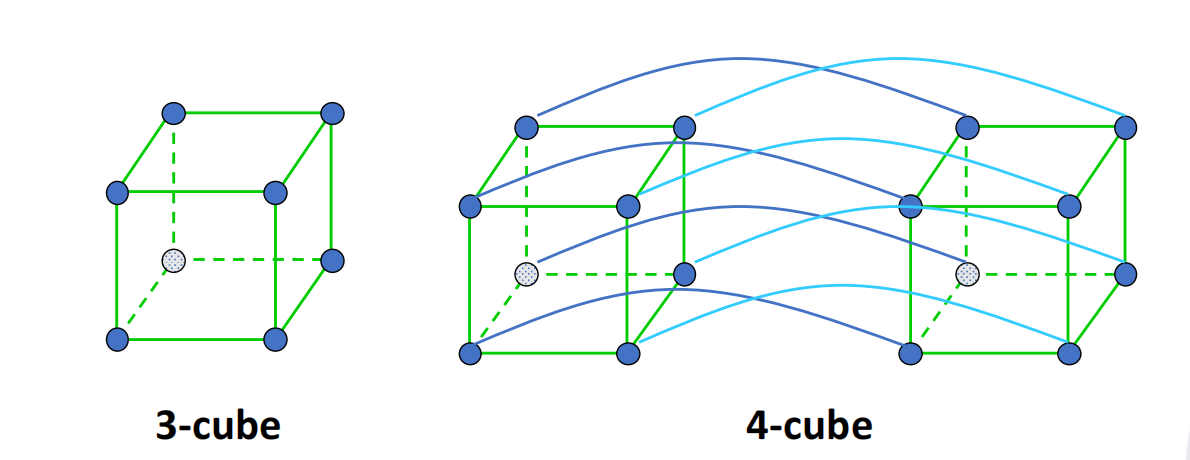
Cube with loop 则在 cube 结构上加入环形结构,使每个节点组内部也具有环状连接。slides 中给出的形式是:
- 总节点数:;
- 节点度数:3;
- 对称性好。
| Scale | Degree | Diameter | Width | Symmetry | Link | |
|---|---|---|---|---|---|---|
| Linear | No | |||||
| Circular | Yes | |||||
| Binary tree | No | |||||
| Star | No | |||||
| Grid | No | |||||
| 2D torus | Yes | |||||
| Hypercube | Yes | |||||
| Cube with loop | Yes |
Dynamic Interconnection Network
动态互联网络的连接关系可以在程序运行期间改变。它依靠主动的 switching elements,通过设置开关状态重构链路。
动态网络主要包括三类:
- bus;
- crossbar switches;
- multi-stage interconnection networks。
Bus
Bus 是一组连接 processor、memory、I/O 等部件的导线和插槽。
其特征是:
- 同一时刻只能支持一对 source 和 destination 传输数据;
- 多对节点同时请求使用 bus 时,需要 bus arbitration;
- CPU 数量较多时,bus contention 会非常严重;
- slides 给出的经验规模是通常不超过约 32 个 CPU。
Bus 与 linear array 的区别在于:
| 结构 | 特征 |
|---|---|
| linear array | 不同源/目的节点可以同时使用系统的不同部分 |
| bus | 多个节点共享同一传输介质,通过时间分割使用,同一时刻只有一对节点传输 |
因此 bus 结构简单、成本低,但扩展性差。
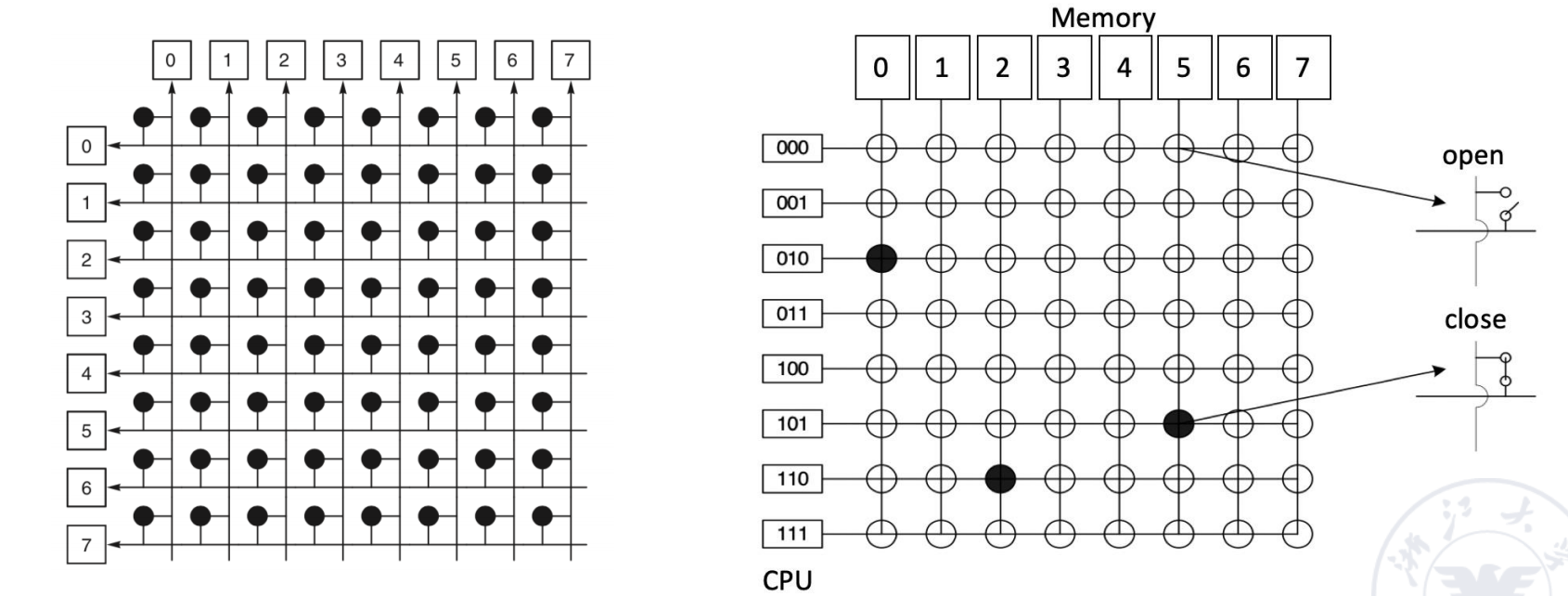
Crosspoint Switches
Crosspoint switch 在输入和输出之间布置交叉开关点。
对于 个输入和 个输出,完整 crossbar 需要 个交叉点。每个交叉点可以打开或关闭,从而控制某个输入是否连接到某个输出。
优点:
- 连接能力强;
- 可以支持较高并行通信带宽;
- 任意输入输出之间的连接较直接。
缺点:
- 硬件复杂度随 增长;
- 大规模系统中开关数量和布线成本都很高。
Multi-Stage Interconnection Network
Multi-stage interconnection network 通过多个 switch stage 串联来降低全交叉开关的硬件成本。
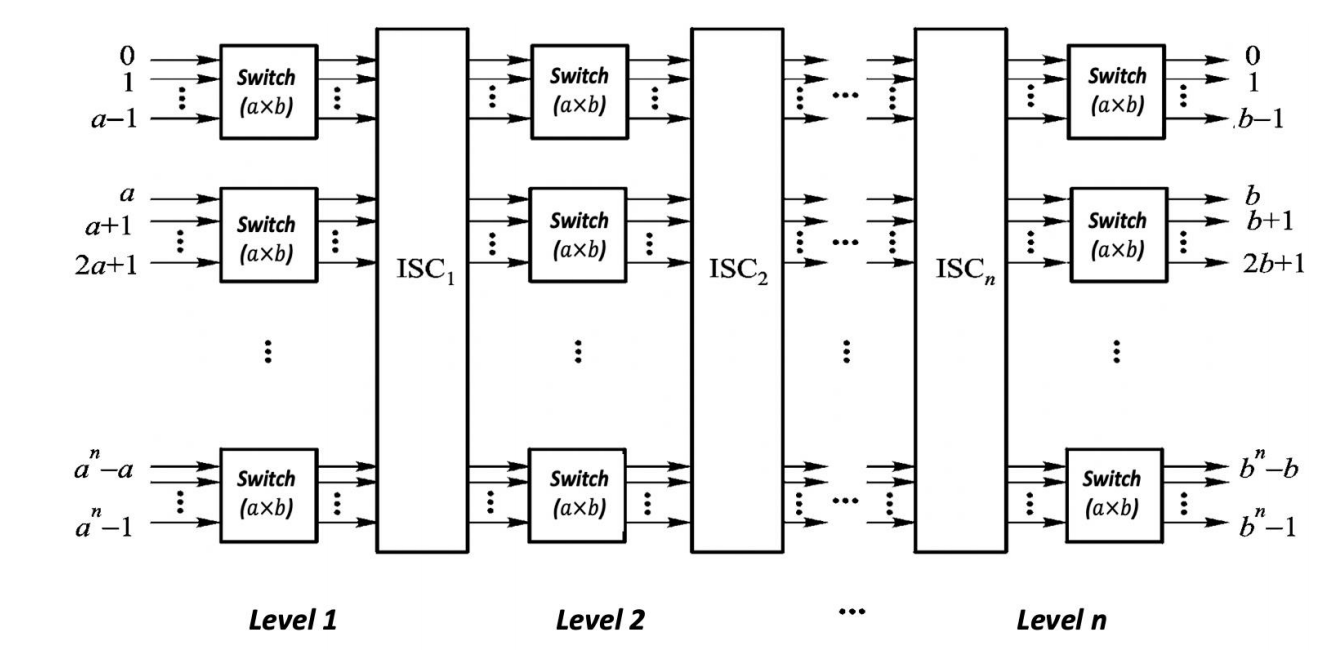
基本 switch unit 具有 个输入和 个输出,记为 switch unit,其中:
常见规模包括 、、。
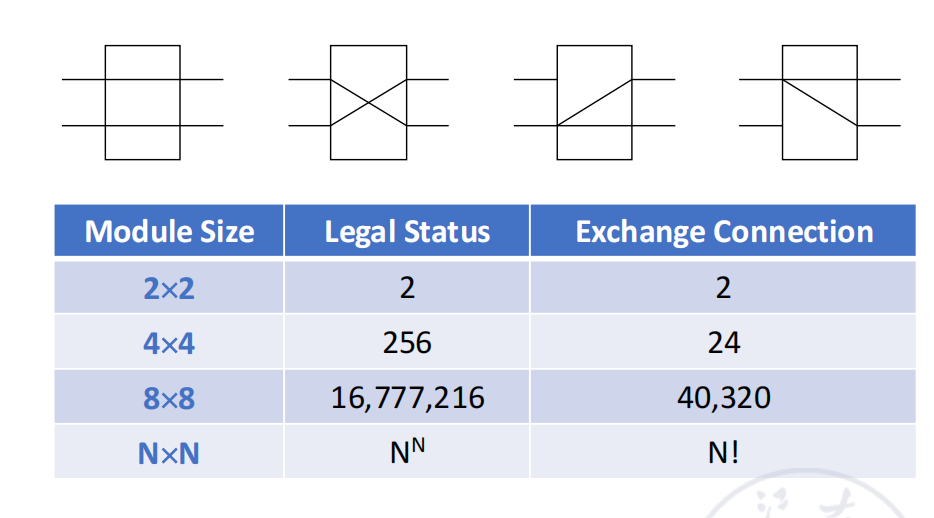
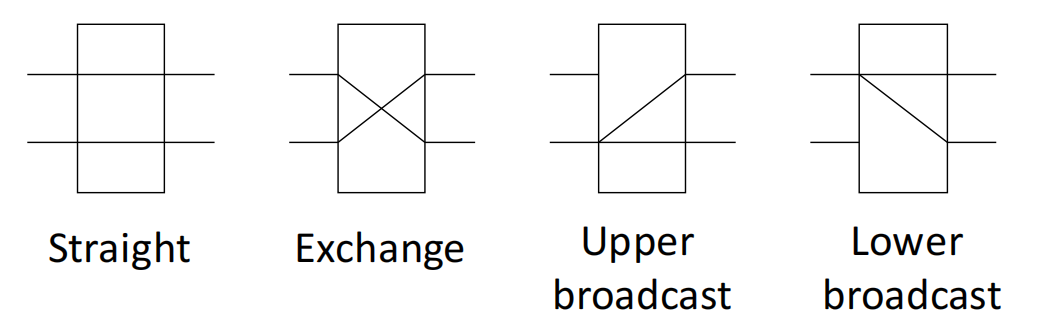
对于 switch unit,基本状态有四种:
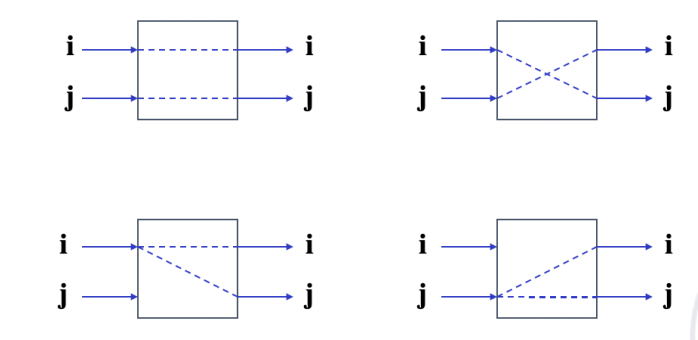
| 状态 | 含义 |
|---|---|
| straight | 上输入到上输出,下输入到下输出 |
| exchange | 上输入到下输出,下输入到上输出 |
| upper broadcast | 上输入广播到两个输出 |
| lower broadcast | 下输入广播到两个输出 |
因此:
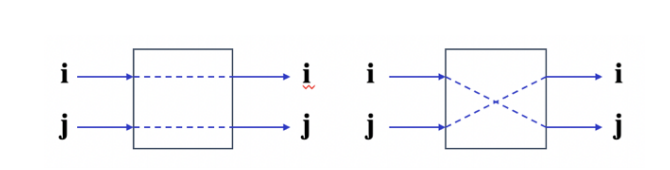
-
two-function switch:只支持 straight 和 exchange;
-
four-function switch:支持 straight、exchange、upper broadcast、lower broadcast;
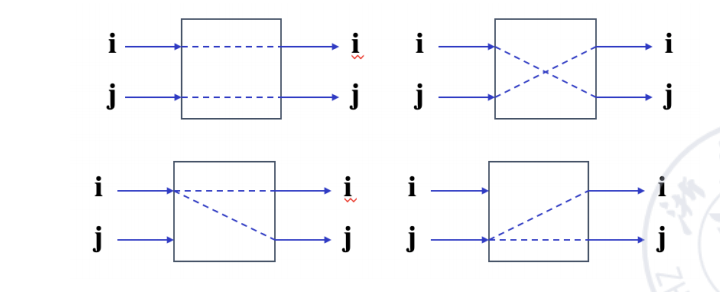
- multi-end switch:进一步加入 broadcast 和 multicast 模块。
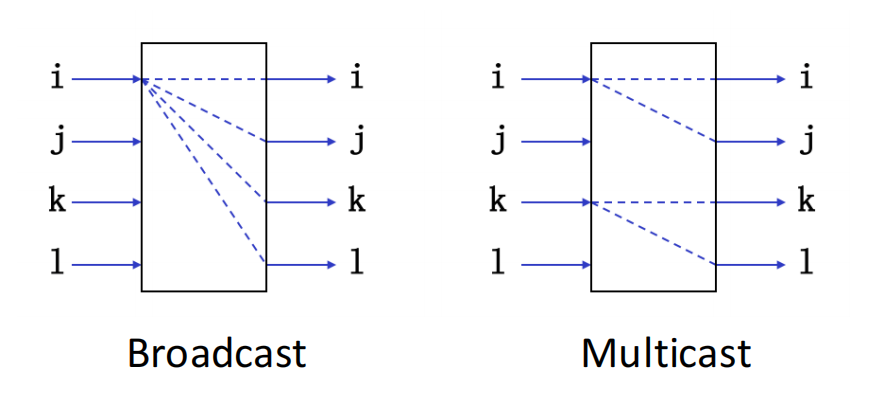
不同多级网络的差异主要来自三点:
- switch function;
- switch control method;
- topology。
在拓扑层面,常见多级网络包括:
- multi-stage cube;
- multi-stage shuffle exchange;
- multi-stage PM2I;
- 上述网络的组合。
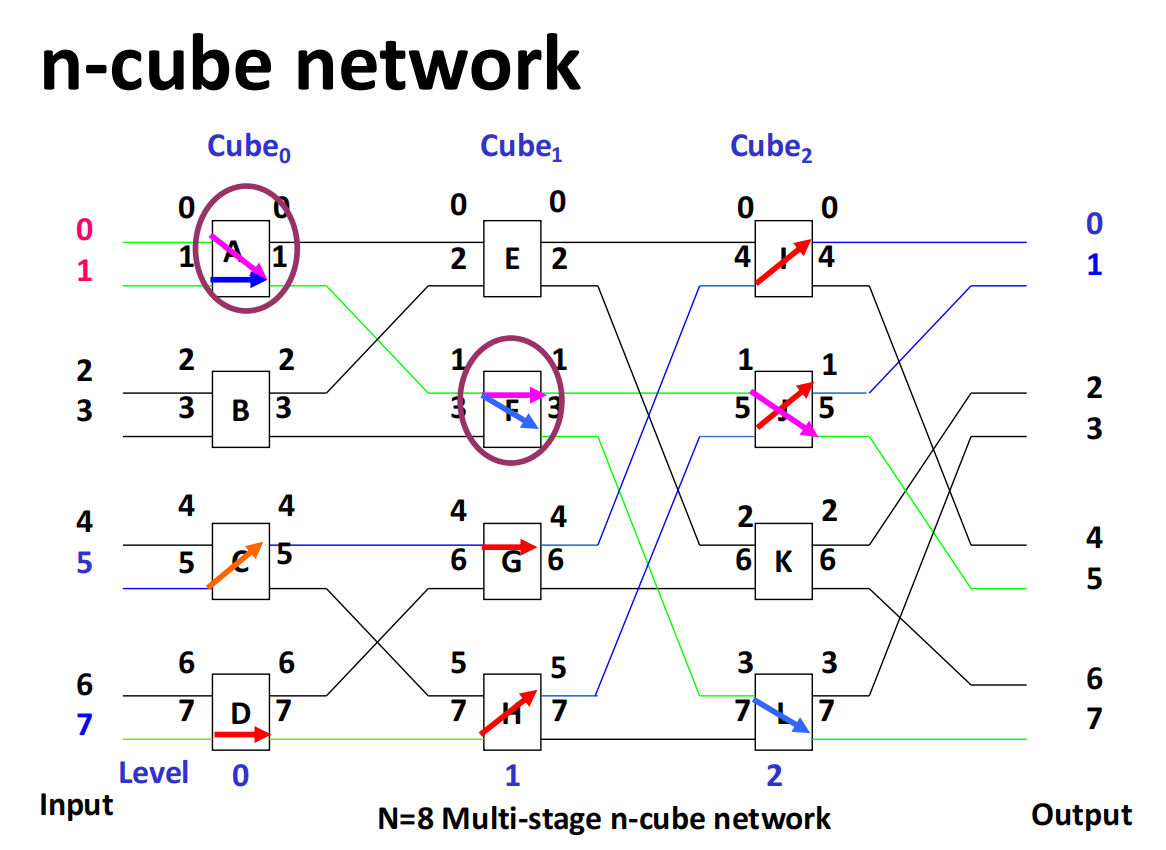
Multi-Stage Cube Interconnection Network
multi-stage cube 网络的特征是:
- switch unit:two-function switch;
- control mode:stage control、part stage control、unit control;
- topology:cube structure。
构造 个单元的 multi-stage cube 网络:
- 计算 ;
- 从输入到输出设置 stage 编号为 ;
- 每一级放置 个 two-function switch;
- 第 级的 switch 端口按照 关系编号;
- 相同编号的端点在相邻 stage 之间连接。
对于 ,共有 3 级:
input -> Cube0 -> Cube1 -> Cube2 -> output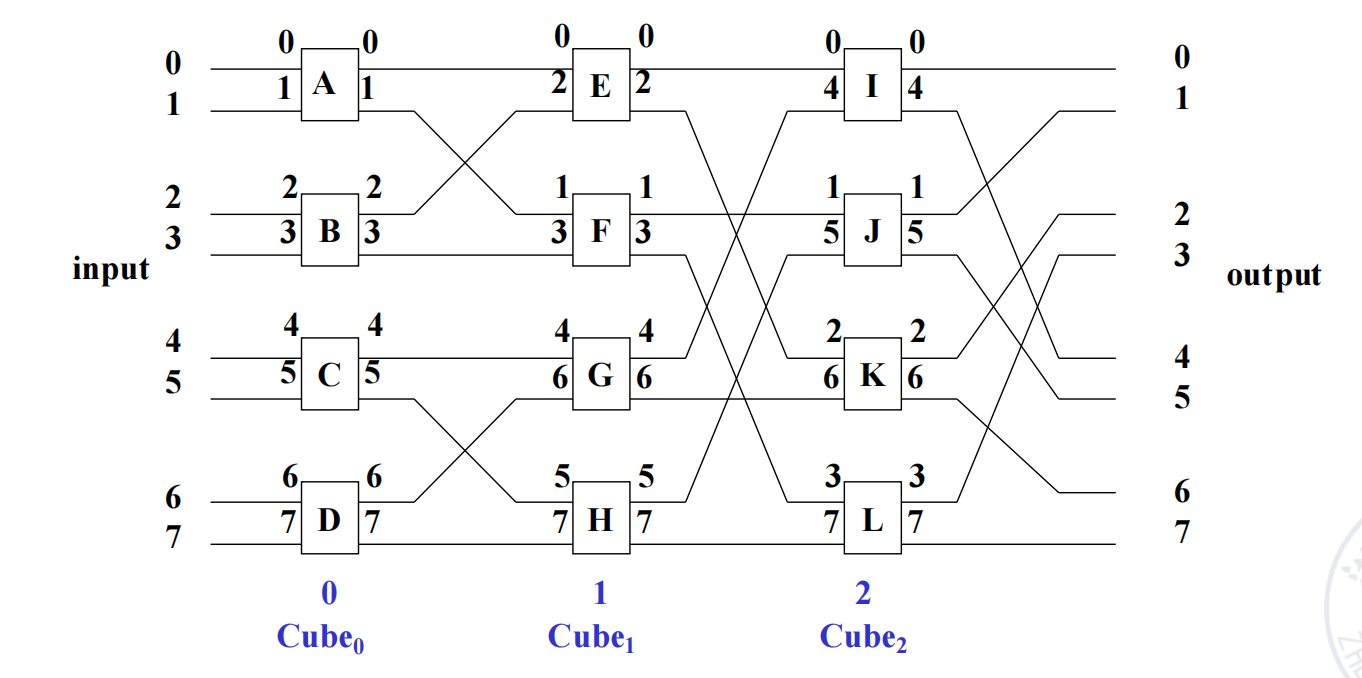
如果采用 stage control,同一级内所有 switch 共享同一个控制信号。设 stage 控制信号为:
其中 表示第 级:
- :straight;
- :exchange。
对于 ,不同控制信号对应的输出重排如下:
| 控制信号 | 输出序列 | 等价函数 |
|---|---|---|
| 000 | 0 1 2 3 4 5 6 7 | identity |
| 001 | 1 0 3 2 5 4 7 6 | |
| 010 | 2 3 0 1 6 7 4 5 | |
| 011 | 3 2 1 0 7 6 5 4 | |
| 100 | 4 5 6 7 0 1 2 3 | |
| 101 | 5 4 7 6 1 0 3 2 | |
| 110 | 6 7 4 5 2 3 0 1 | |
| 111 | 7 6 5 4 3 2 1 0 |
这说明多级 cube 网络可以通过每一级的 straight/exchange 控制,实现多种规则重排。
multi-stage cube 还可以分为:
- switched network;
- mobile number network;
- indirect binary n-cube network。
其中采用 stage control 的 multi-stage cube 网络称为 switching network / flip network,主要实现成组元素的对称交换。
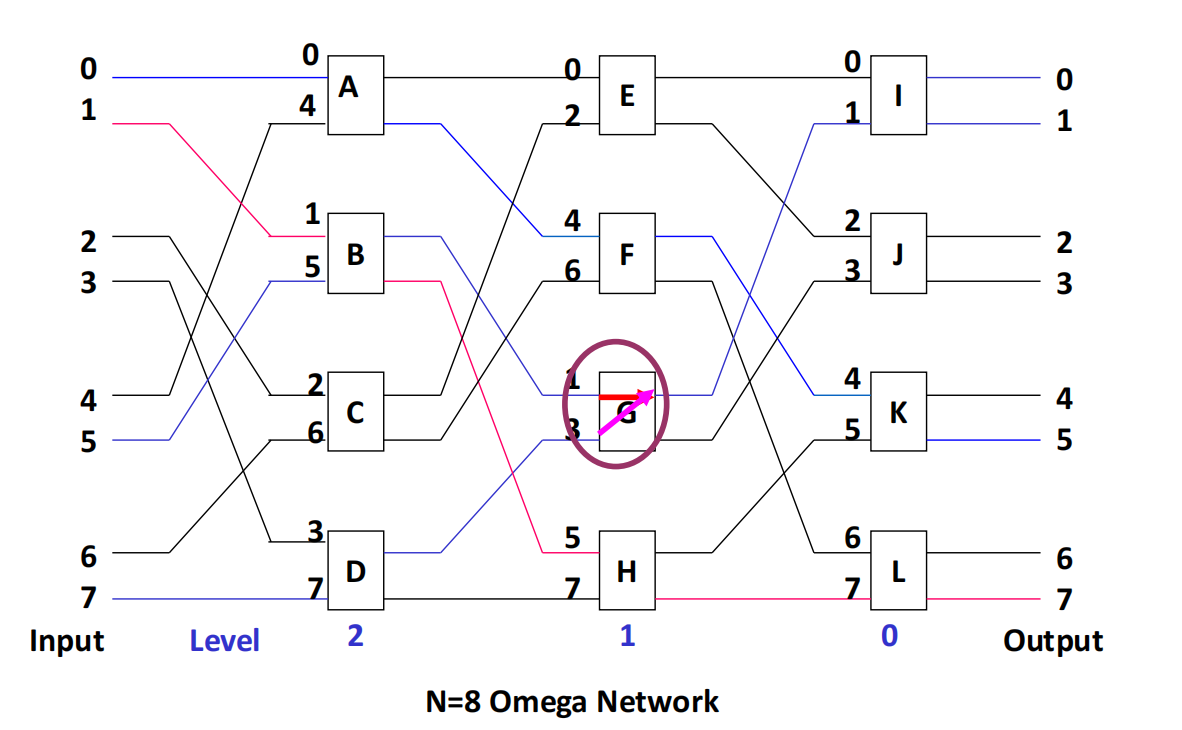
Multi-Stage Shuffle Exchange Network / Omega Network
multi-stage shuffle exchange network 又称为 Omega network。
其特征是:
- stage 数:;
- stage 编号从输入到输出为 ;
- 每一级有 个 switch unit;
- 拓扑为 shuffle topology 后接 four-function switch;
- 控制方式通常是 unit control。
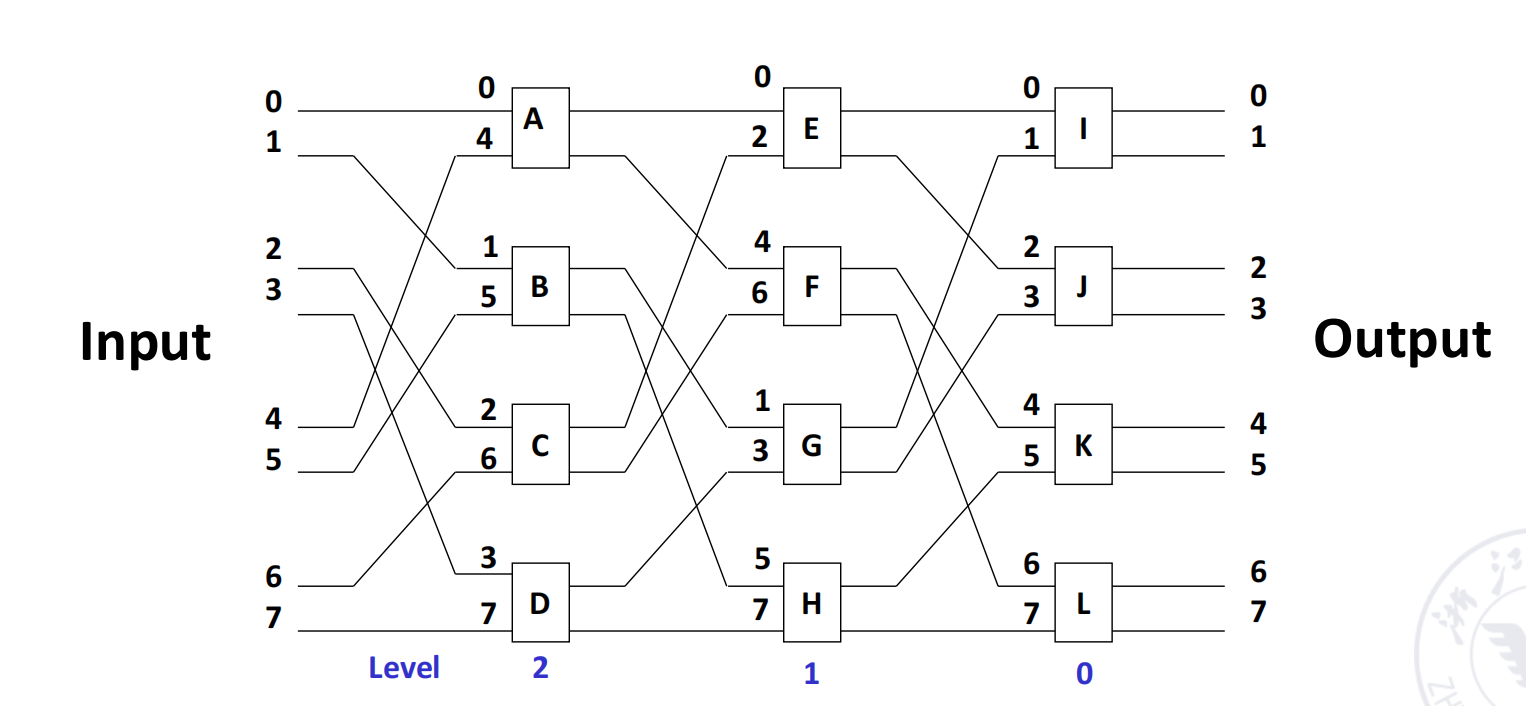
如果把 Omega network 的 switch unit 限制为只使用 straight 和 exchange,则它变成 -cube network 的逆网络。
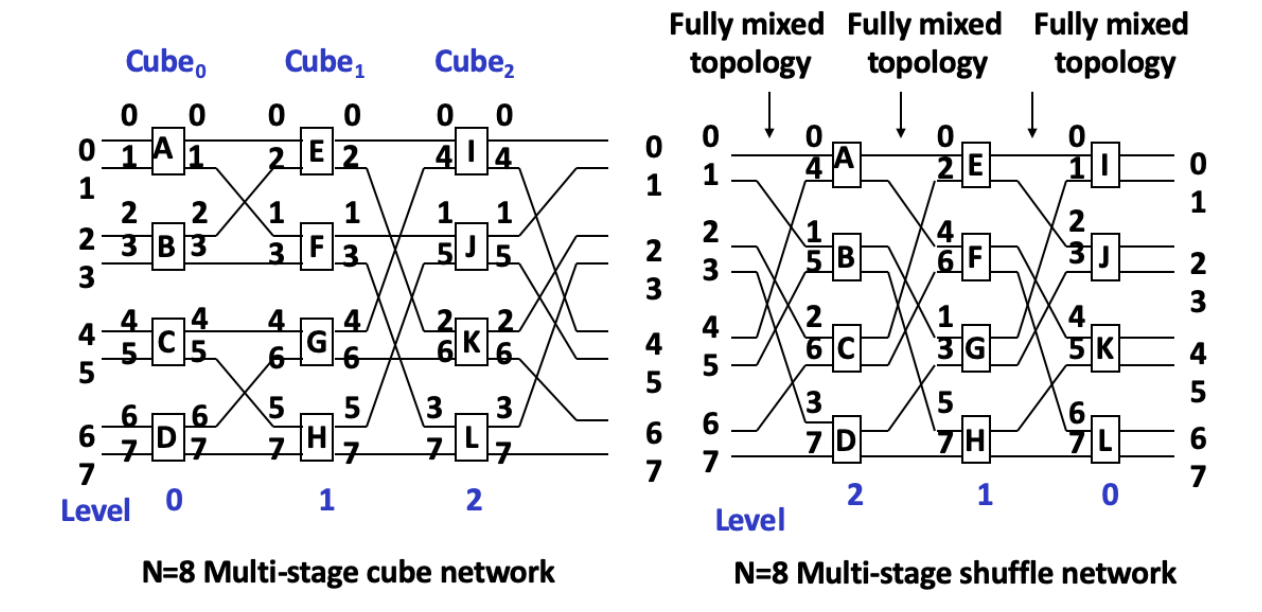
Omega Network 与 n-cube Network 的比较
两者的主要差异如下:
| 对比项 | Omega Network | n-cube Network |
|---|---|---|
| 数据流 stage 顺序 | ||
| switch unit | four-function switch | two-function switch |
| broadcast | 可以实现一定的一对多广播 | 不支持广播 |
slides 中给出的 例子强调了多级网络的一个重要特点:
- 与 可以同时实现;
- 与 无法同时实现。
原因是多级网络内部路径可能发生冲突。即使每条单独连接都可实现,多个连接同时存在时也可能竞争同一个内部 switch 或 link,这就是动态多级网络中的 blocking 问题。
动态互联网络比较
slides 从带宽、链路复杂度、开关复杂度和寻路能力比较了三种动态互联网络。
| 网络 | 带宽 | Link 复杂度 | Switch 复杂度 | 连接能力 |
|---|---|---|---|---|
| Bus system | 到 | 同一时刻一对一传输 | ||
| Multi-stage network | 到 | 支持一定程度的 broadcast 和 exchange | ||
| Crosspoint switches | 到 | 全交换能力最强 |
其中:
- 是 processor 数量;
- 是数据通路宽度;
- multi-stage network 假设采用 switch 构造 MIN;
- crosspoint switches 需要 个交叉开关。
整体来看:
- bus 成本最低,但争用最严重;
- crossbar 能力最强,但成本随 增长;
- multi-stage network 处于两者之间,是常见折中方案。
SIMD
SIMD 结构适合利用 data-level parallelism,典型应用包括:
- matrix-oriented scientific computing;
- media-oriented image and sound processors;
- GPU 中的大规模数据并行任务。
SIMD 相比 MIMD 更节能的原因之一是:一次 instruction fetch 可以驱动多个数据操作,控制开销被多个数据元素摊薄。
因此 SIMD 对 personal mobile devices、图像音频处理和深度学习等数据并行应用很有吸引力。
从程序员视角看,SIMD 仍然允许程序在较高层次上以顺序逻辑思考;编译器或编程模型负责把可并行的数据操作映射到向量、阵列或 GPU 线程结构上。
DLP in GPU
GPU 的基本思想
GPU 最初面向图形处理,但现代 GPU 已经成为通用数据并行计算的重要平台。它的基本思想是采用异构执行模型:
CPU: hostGPU: deviceCPU 负责组织程序执行、发起 kernel 调用和管理数据传输;GPU 负责执行大量高度并行的计算任务。
GPU 的硬件特征是:
- 核心数量多;
- 单个核心较小;
- 适合大规模并行;
- 典型应用包括 graphics 和 deep learning。
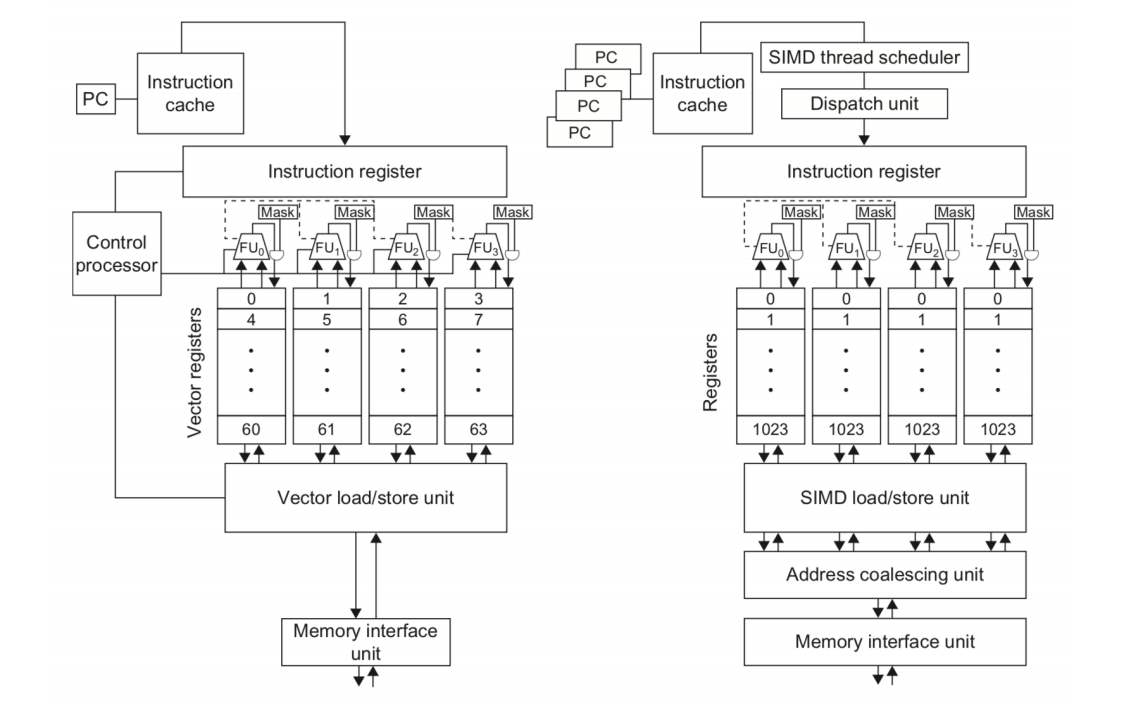
从体系结构脉络看,GPU 可以理解为从 SIMD 进一步扩展到 SIMT(Single Instruction Multiple Thread)。在 vector processor 中,最小并行单元可以看成向量元素;在 GPU 编程模型中,最小执行抽象是 thread。thread 除了数据元素,还包含寄存器、上下文等执行状态。
CUDA 与 SIMT
CUDA 的全称是 Compute Unified Device Architecture。
NVIDIA 使用 CUDA thread 统一表达 GPU 中的多种并行形式。执行一个 thread block 的硬件可以看成 multithreaded SIMD processor。
SIMT 的关键直觉是:
- 程序员写的是很多 thread;
- 硬件以 SIMD / multithreaded SIMD 的方式组织这些 thread;
- 同一组 thread 通常执行相同指令,但作用于不同数据;
- 线程管理主要由 GPU 硬件负责,而不是应用程序或操作系统显式调度每个 thread。
例子:DAXPY 的 CUDA 写法
DAXPY 的数学形式是:
标量 C 程序写法为:
// Invoke DAXPYdaxpy(n, 2.0, x, y);
// DAXPY in Cvoid daxpy(int n, double a, double *x, double *y){ for (int i = 0; i < n; ++i) y[i] = a * x[i] + y[i];}CUDA 写法把每个元素的计算交给一个 thread:
// Invoke DAXPY with 256 threads per Thread Block__host__int nblocks = (n + 255) / 256;daxpy<<<nblocks, 256>>>(n, 2.0, x, y);
// DAXPY in CUDA__global__void daxpy(int n, double a, double *x, double *y){ int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) y[i] = a * x[i] + y[i];}这里:
<<<nblocks, 256>>>表示启动nblocks个 thread block,每个 block 有 256 个 thread;blockIdx.x表示当前 block 的编号;blockDim.x表示每个 block 的 thread 数;threadIdx.x表示当前 thread 在 block 内的编号;i = blockIdx.x * blockDim.x + threadIdx.x把二维层次中的 thread 映射为全局数组下标;if (i < n)用来处理 不能被 256 整除时最后一个 block 中多出来的 thread。
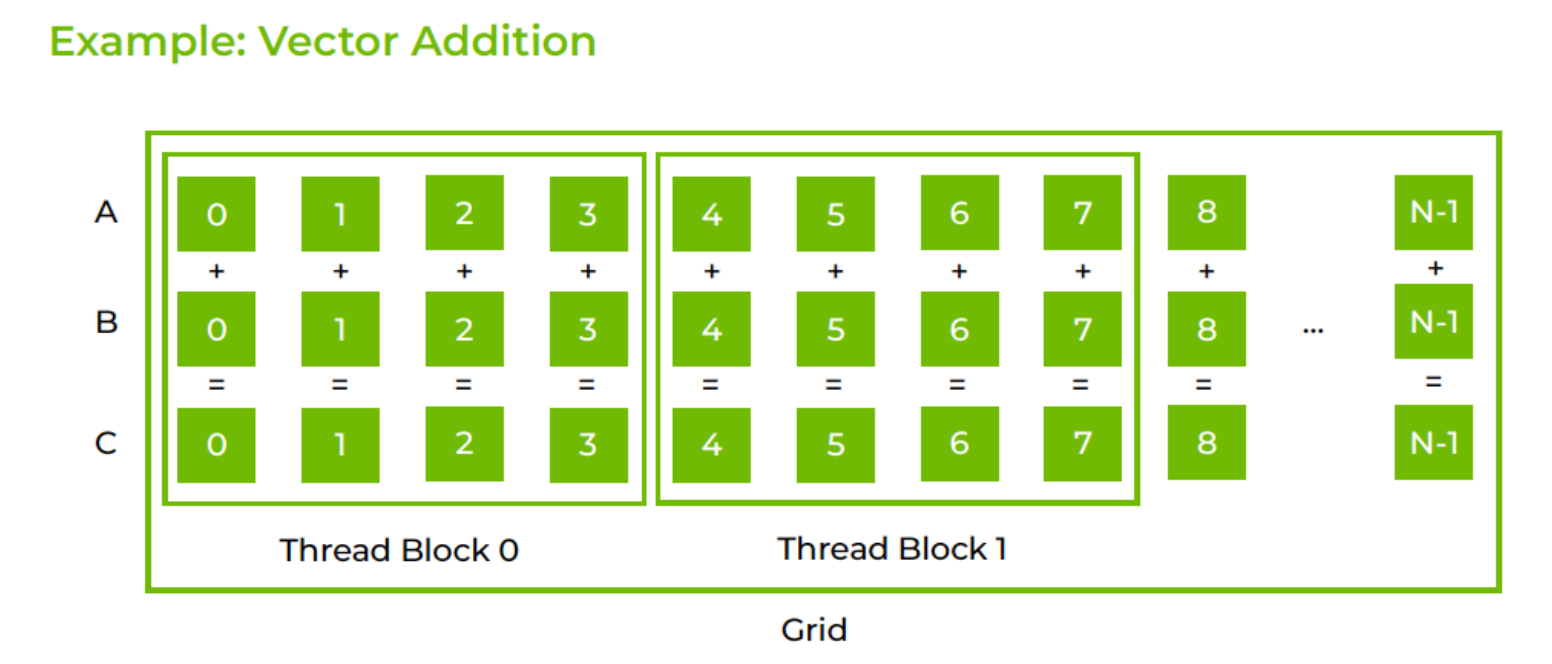
Grid, Thread Blocks and Threads
CUDA 的执行组织是三层结构:
Grid ├── Thread Block 0 │ ├── Thread 0 │ ├── Thread 1 │ └── ... ├── Thread Block 1 │ └── ... └── ...核心关系是:
- 一个 thread 通常对应一个数据元素;
- 多个 thread 组成一个 thread block;
- 多个 block 组成一个 grid;
- GPU 硬件负责 thread 管理。
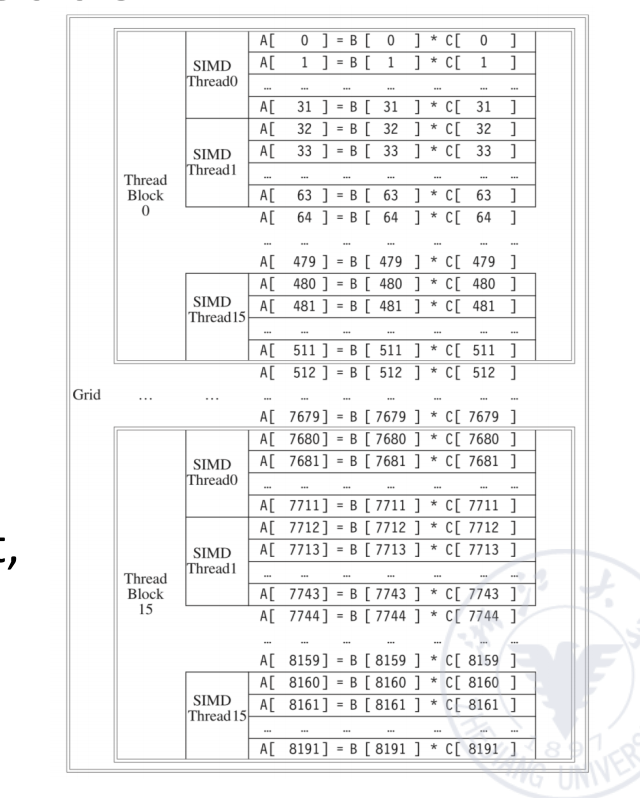
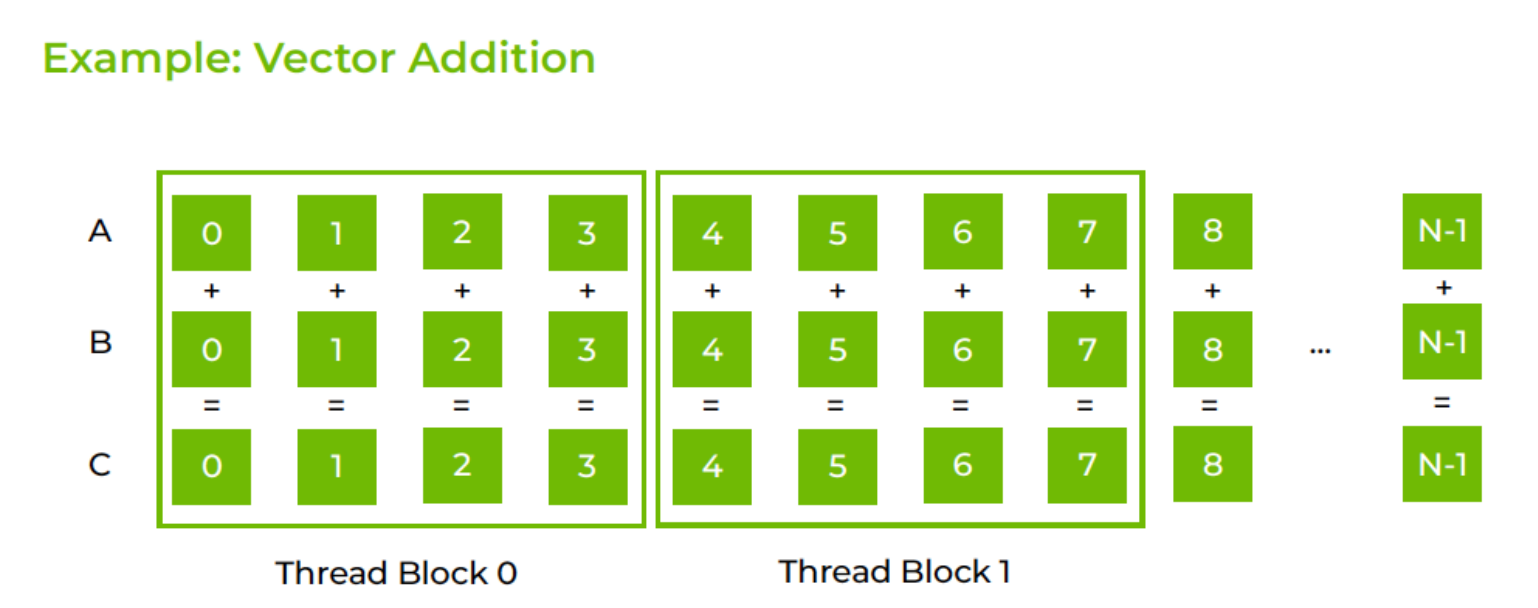
以 vector addition 为例:
__global__ void vecadd_kernel(float* A, float* B, float* C, int N) { int i = blockDim.x * blockIdx.x + threadIdx.x; C[i] = A[i] + B[i];}
vecadd_kernel<<<numBlocks, numThreadsPerBlock>>>(A_d, B_d, C_d, N);每个 thread 负责一个下标 的加法:
多个相邻元素被分配到同一个 thread block,不同 block 一起构成一个 grid。

GPU Memory Structures
GPU 的 memory 结构与 CUDA 层次直接相关。
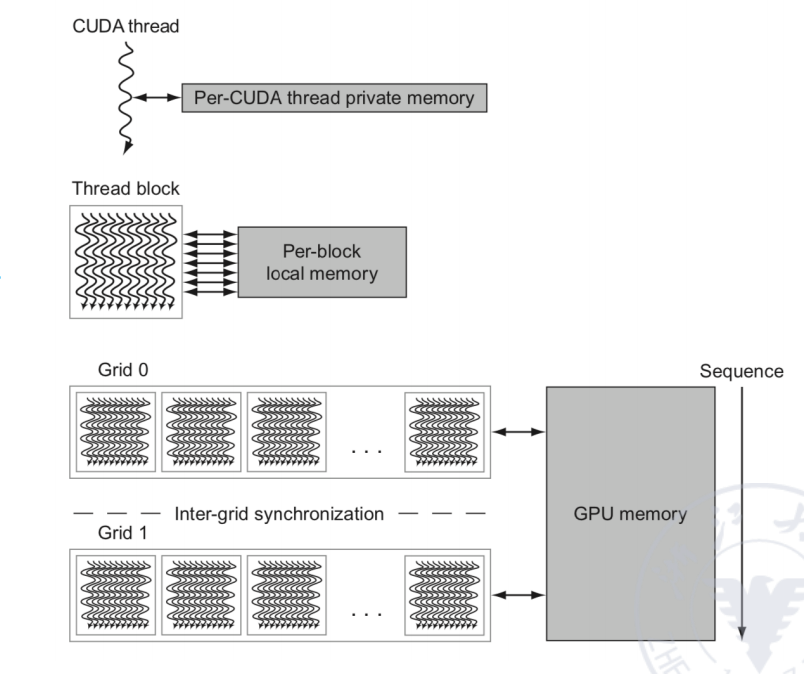
| 存储层次 | 作用范围 | 直观含义 |
|---|---|---|
| global memory / GPU memory | 所有 grid / block 可见 | 大容量、延迟高,位于 GPU DRAM 中 |
| shared memory | 一个 thread block 内共享 | 位于 SM 内,程序员可控制,适合 block 内协作 |
| private / local memory | 单个 CUDA thread 私有 | 保存单个 thread 的私有数据和溢出数据 |
| register file | 单个 thread 的寄存器上下文 | 支持快速 thread 切换和大量并发 thread |
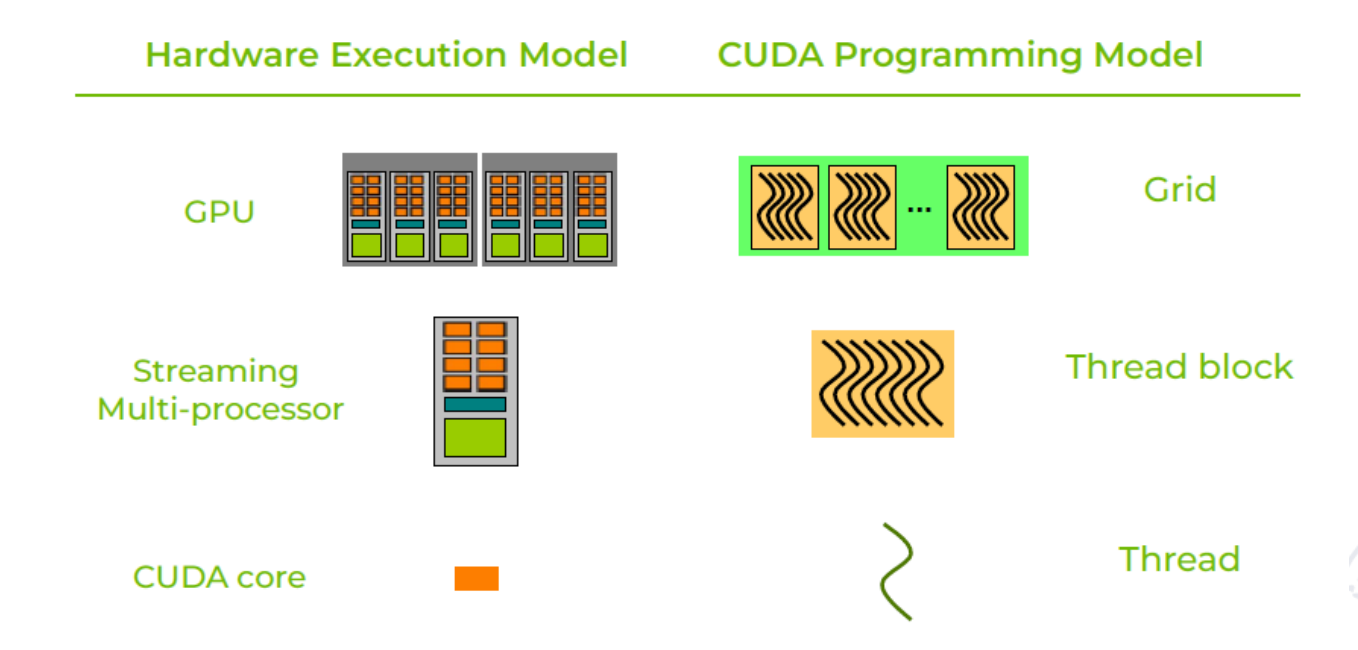
硬件执行模型与 CUDA 编程模型可以对应为:
| 硬件执行模型 | CUDA 编程模型 |
|---|---|
| GPU | Grid |
| Streaming Multiprocessor(SM) | Thread Block |
| CUDA core / lane | Thread |
这个对应关系是理解 GPU 的核心:程序员写 thread 和 block,硬件把 block 分配到 SM 上执行,并在 SM 内调度大量 thread。
Memory Hierarchy in GPU
GPU 同样需要 memory hierarchy。
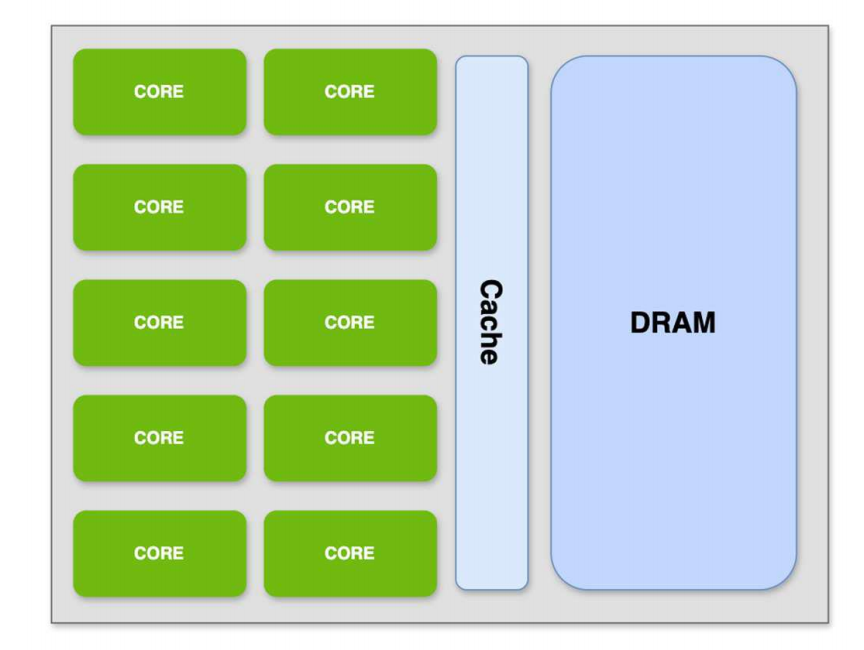
原因是:
- GPU thread 数量巨大;
- global memory 延迟较高;
- 如果没有 cache / shared memory,访存会成为严重瓶颈;
- GPU 通过多线程隐藏内存延迟,同时仍需要利用空间局部性和时间局部性。
常见结构是 two-level cache:
- L1 cache:位于 SM 内,靠近执行单元;
- L2 cache:多个 SM 共享,位于 GPU 更全局的位置;
- shared memory:通常与 L1 位置相近,受程序员显式控制。
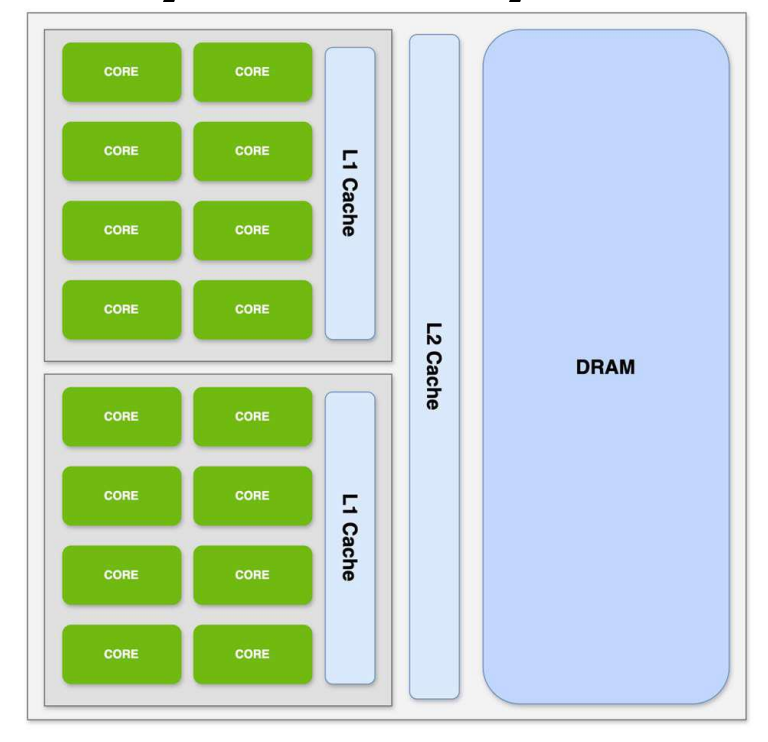
例如:A100 强调
- 增加 instruction cache;
- shared memory 由程序员控制;
- L1 cache / shared memory 位于 SM 内;
- L2 cache 连接多个 SM 与 GPU DRAM。
GPU Organization 的演化
NVIDIA GPU 代际展示了 GPU 组织结构的变化。
| 代际 / 示例 | 结构特点 |
|---|---|
| Tesla | 使用 Core、SM、GPU 的层次组织 |
| Fermi | 集成 L1 和 shared memory;SM 内 core 数增加 |
| Kepler | 巨型 SM,一个 SM 可含 192 cores;问题是更大的 SM 是否一定更好 |
| Maxwell | 把 SM 拆成 4 个 block,调度和功耗控制更灵活;L1 和 shared memory 分离 |
| Pascal | 增大 L2 cache,slides 中给出 4MB,约为上一代的 7 倍 |
| Volta | 再次集成 L1 和 shared memory;instruction buffer 变为 L0 instruction cache |
| Ampere | L2 进一步增大到 40MB;增加 global memory 到 shared memory 的额外数据通路 |
| Hopper | 继续沿着更大规模、更复杂 memory hierarchy 和更强数据通路方向演进 |
这组例子说明:GPU 的性能并不只由 core 数决定,还受到 SM 组织、cache/shared memory 结构、调度粒度、数据通路和功耗控制共同影响。
NVIDIA GPU 与 Vector Machine 的比较
NVIDIA GPU 与传统 vector machine 有许多相似点:
- 都适合 data-level parallel problems;
- 都支持 scatter-gather transfers;
- 都使用 mask / predicate 机制处理条件执行;
- 都具有较大的 register file。
主要差异是:
| 对比项 | Vector Machine | NVIDIA GPU |
|---|---|---|
| 执行抽象 | 向量指令作用于多个元素 | CUDA thread / warp / block |
| 标量处理器 | 通常有 scalar processor 配合 vector unit | GPU 中没有传统向量机意义上的 scalar processor |
| 隐藏延迟方式 | 深流水 vector functional units | 大量 multithreading 隐藏 memory latency |
| 功能部件组织 | 少数深流水功能部件 | 很多较小的 functional units |
从课程主线看,两者都服务于 DLP,只是 GPU 把数据级并行包装成更接近线程的编程模型。
Loop-Level Parallelism
基本概念
程序中的循环是并行性的主要来源。很多 DLP、TLP 以及更激进的静态 ILP 方法,都需要从循环中发现可并行的迭代。
Loop-level parallelism 的核心问题是:
后面迭代中的数据访问,是否依赖前面迭代产生的数据值?
如果存在这种依赖,就称为 loop-carried dependence(循环携带相关)。
需要区分两类相关:
| 类型 | 含义 | 对并行化的影响 |
|---|---|---|
| iteration-internal dependence | 同一次迭代内部语句之间存在相关 | 仍可能跨迭代并行,只要每次迭代内部保持顺序 |
| loop-carried dependence | 第 次迭代依赖第 次迭代的结果 | 可能迫使迭代顺序执行,限制向量化和并行化 |
循环计数变量 i 本身也跨迭代变化,但它属于 induction variable,编译器通常可以识别和消除,不构成主要限制。
Example 1:无 loop-carried dependence
for (i = 999; i >= 0; i = i - 1) x[i] = x[i] + s;每次迭代只读写自己的 x[i],不同迭代访问的数组元素不同。因此:
x[i]的读写相关只发生在同一次迭代内部;- 不存在对其他迭代结果的依赖;
- 循环可以并行化或向量化。
这类循环是最典型的数据级并行来源。
Example 2:存在循环携带相关,难以并行
for (i = 0; i < 100; i = i + 1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */}把两条语句分别记为:
S1: A[i+1] = A[i] + C[i]S2: B[i+1] = B[i] + A[i+1]依赖关系有三类:
- S1 对 S1 的 loop-carried dependence
第 次迭代计算 A[i+1],第 次迭代需要读取 A[i+1]。
S1(i) -> S1(i+1)- S2 对 S2 的 loop-carried dependence
第 次迭代计算 B[i+1],第 次迭代需要读取 B[i+1]。
S2(i) -> S2(i+1)- S1 到 S2 的同迭代相关
同一次迭代中,S2 使用 S1 刚产生的 A[i+1]。
S1(i) -> S2(i)其中第 1、2 类跨越迭代边界,会强制相邻迭代按顺序推进。为了保持正确性,就很难把这个循环直接向量化或完全并行化。
这也是老师强调的点:如果循环体之间存在跨迭代相关,就不能简单地把每一次迭代拆开并行执行;硬件再强,也必须服从程序语义。
Example 3:有 loop-carried dependence,但可以改写为并行
原始循环为:
for (i = 0; i < 100; i = i + 1) { A[i] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */}依赖关系是:
S2(i) -> S1(i+1)原因是第 次迭代的 S2 产生 B[i+1],第 次迭代的 S1 需要使用 B[i+1]。
这个相关是 loop-carried dependence,但它没有形成环:
S1依赖前一次迭代的S2;S2本身不依赖S1;- 两个语句之间没有形成互相依赖的闭环。
因此可以通过重排暴露并行性。
改写过程的关键是:
- 先单独执行第一条
S1(0),因为它需要循环开始前已经存在的B[0]; - 在循环体中先执行
S2(i),产生B[i+1]; - 再执行
S1(i+1),使用刚产生的B[i+1]; - 最后补上原循环最后一次
S2(99)产生的B[100]。
改写后的代码为:
A[0] = A[0] + B[0];
for (i = 0; i < 99; i = i + 1) { B[i+1] = C[i] + D[i]; A[i+1] = A[i+1] + B[i+1];}
B[100] = C[99] + D[99];改写后,循环体内部仍然有 B[i+1] -> A[i+1] 的同迭代相关,但跨迭代相关被消除。因此多个迭代可以并行处理,或者用向量指令配合 chaining 执行。
这一例子说明:
- 出现 loop-carried dependence 后,不能立刻判断一定无法并行;
- 需要看 dependence graph 中是否存在环;
- 没有环的依赖可以通过语句重排、循环剥离、循环重写等方式暴露并行性;
- 有些循环携带相关无法消除,此时必须保留顺序执行。
MIMD: Thread-Level Parallelism
前面 SIMD 讨论的是 一个指令流控制多个数据流,适合向量、阵列处理器和 GPU 中大量同构数据运算。本节开始进入 MIMD(Multiple Instruction streams, Multiple Data streams),也就是多个处理器或多个核各自执行自己的指令流,并处理自己的数据流。
这一节解决的问题是:当单核 ILP 和 SIMD/DLP 的收益受限后,怎样通过多个线程、多个处理器、多个节点继续提高系统吞吐量。
MIMD 不是简单地“堆很多 CPU”。只要多个执行实体之间需要共享数据、同步状态或通信,就一定会引入额外开销,其中最核心的问题就是:
- 程序本身的并行性有限;
- 处理器之间的通信、同步和数据一致性维护有成本;
- 共享内存系统必须解决 cache coherence 与 memory consistency。
从 TLP 到 MIMD
TLP(Thread-Level Parallelism,线程级并行) 是由软件系统或程序员在较高层次识别出来的并行性。一个线程通常包含成百上千甚至上百万条指令,不同线程可以并行执行。
TLP 与前面 ILP/DLP 的区别在于:
- ILP:同一个指令流内部挖掘指令间并行性,主要由硬件和编译器隐式完成;
- DLP / SIMD:一个控制流对多个数据元素做相同操作;
- TLP / MIMD:多个线程拥有不同的控制流,因此系统中需要多个 PC。
如果程序希望多个线程并行执行,底层就需要多个执行上下文、多个 PC,最终自然发展到多核或多处理器结构。
MIMD 的两类基本组织
MIMD 可以按照内存组织方式分为两大类。
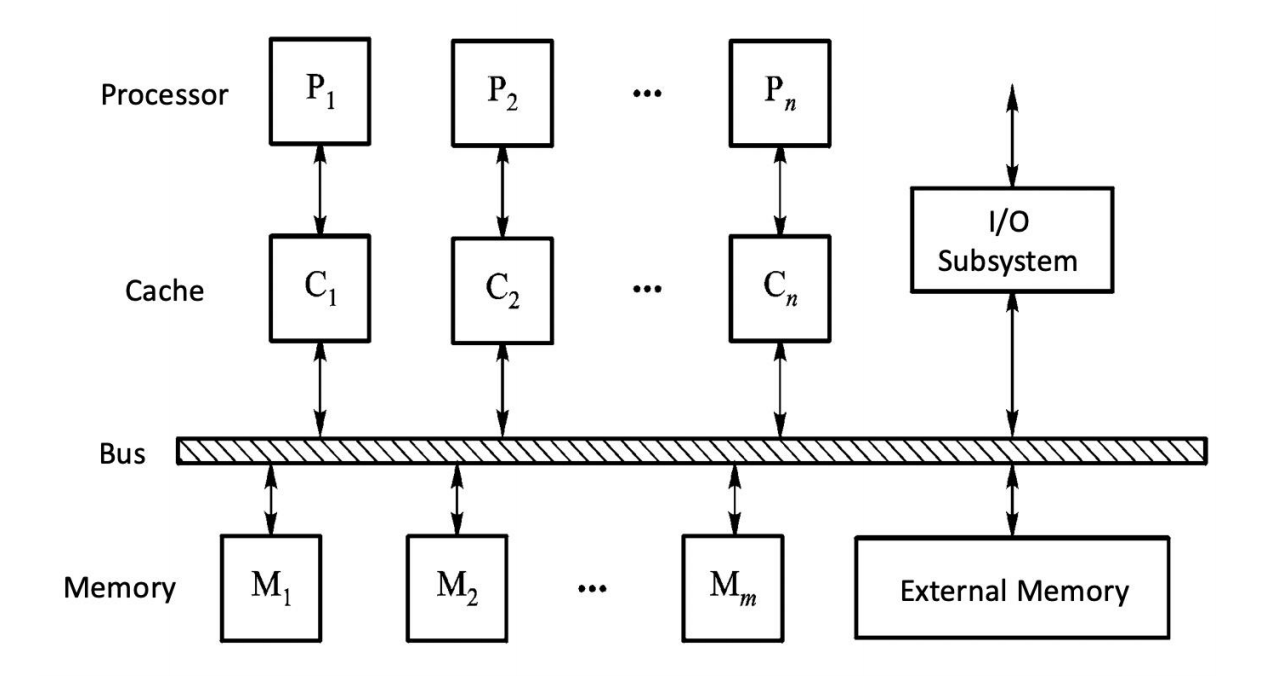
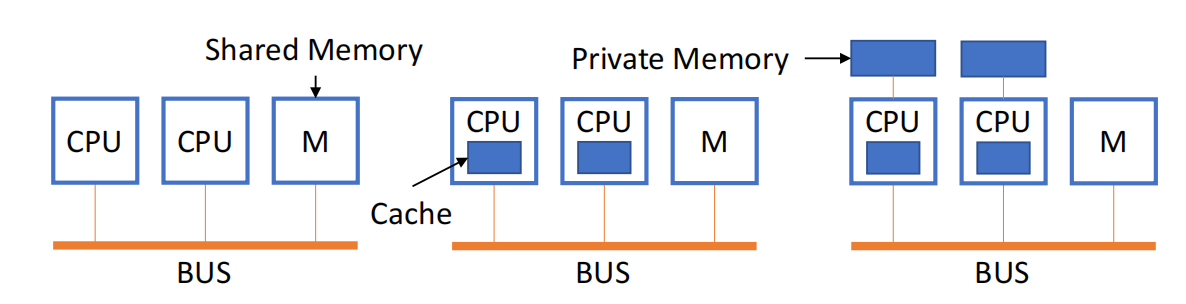
Multi-Processor System:基于 Shared Memory
共享内存多处理器系统 的特点是:整个系统只有一个统一的地址空间,所有处理器共享这个地址空间。
注意:统一地址空间不意味着物理上只有一块内存。
- 物理内存可以集中放置;
- 也可以分布在不同节点;
- 只要硬件和软件让所有处理器看到同一个全局地址空间,就属于 shared memory model。
这种模型的编程方式比较接近普通单机程序:处理器之间通过对共享变量执行 load/store 进行通信。
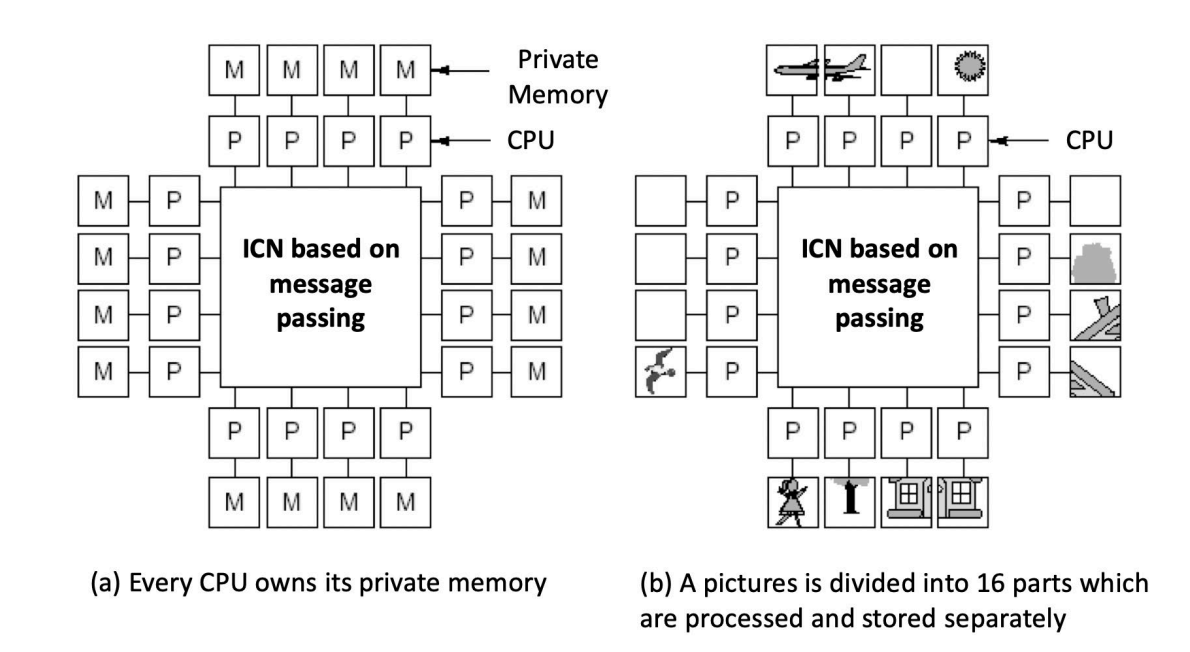
Multi-Computer System:基于 Message Passing
多计算机系统 的特点是:每个处理器或节点都有自己的本地内存,本地内存只能由本节点直接访问,其他节点不能直接 load/store。
如果处理器 A 要把数据交给处理器 B,就必须通过消息传递:
Processor A --message--> Processor B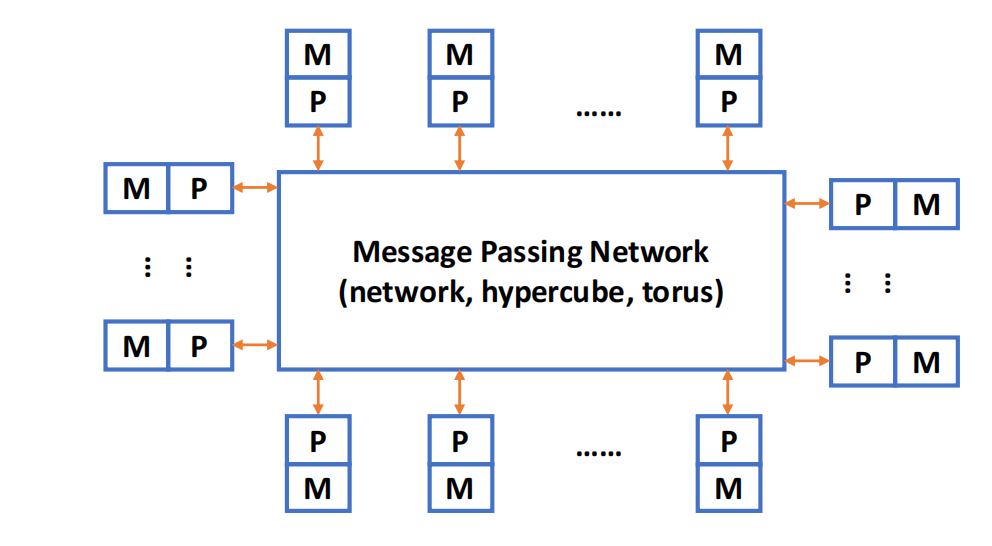
这类系统也称为 NORMA(No-Remote Memory Access) 模型:没有远程内存直接访问能力。
一个典型节点通常包含:
- 一个或多个 CPU;
- RAM;
- disk / I/O device;
- communication processor 或 NIC;
- 通过互联网络与其他节点通信。
共享内存和消息传递的核心区别如下:
| 维度 | Shared Memory Multiprocessor | Message Passing Multicomputer |
|---|---|---|
| 地址空间 | 全局唯一地址空间 | 每个节点私有地址空间 |
| 通信方式 | 共享变量,load/store | 显式发送/接收消息 |
| 硬件支持 | cache coherence / memory consistency | 网络通信、消息路由 |
| 编程直觉 | 更像多线程程序 | 更像分布式程序 |
| 主要挑战 | 一致性、同步、共享数据竞争 | 通信延迟、消息划分、数据分布 |
UMA / NUMA / COMA
共享内存 MIMD 系统又可以按照访存模型进一步分为 UMA、NUMA 和 COMA。
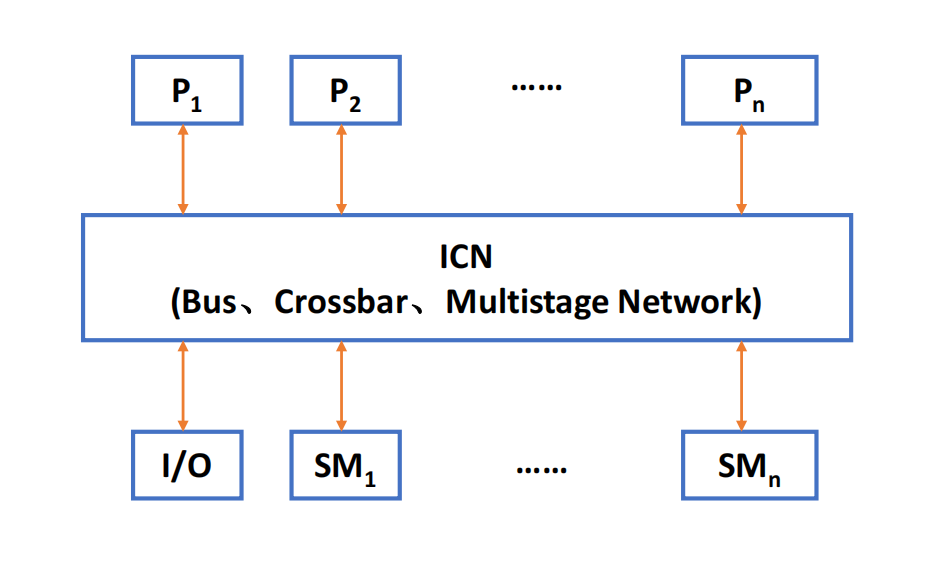
UMA:Uniform Memory Access
UMA(Uniform Memory Access,一致/均匀存储访问) 指所有处理器访问任意共享内存单元的时间相同。
特点:
- 物理内存被所有处理器均匀共享;
- 每个处理器访问任意 memory word 的时间相同;
- 每个处理器可以带 private cache 或 private memory;
- 常见实现包括基于 bus、crossbar 或 multistage network 的集中式共享内存。
UMA 也称为:
SMP = Symmetric shared-memory multiprocessor = centralized shared-memory multiprocessor这里的 symmetric 强调每个处理器地位对等,不存在某个处理器访问某段共享内存天然更近。
NUMA:Non-Uniform Memory Access
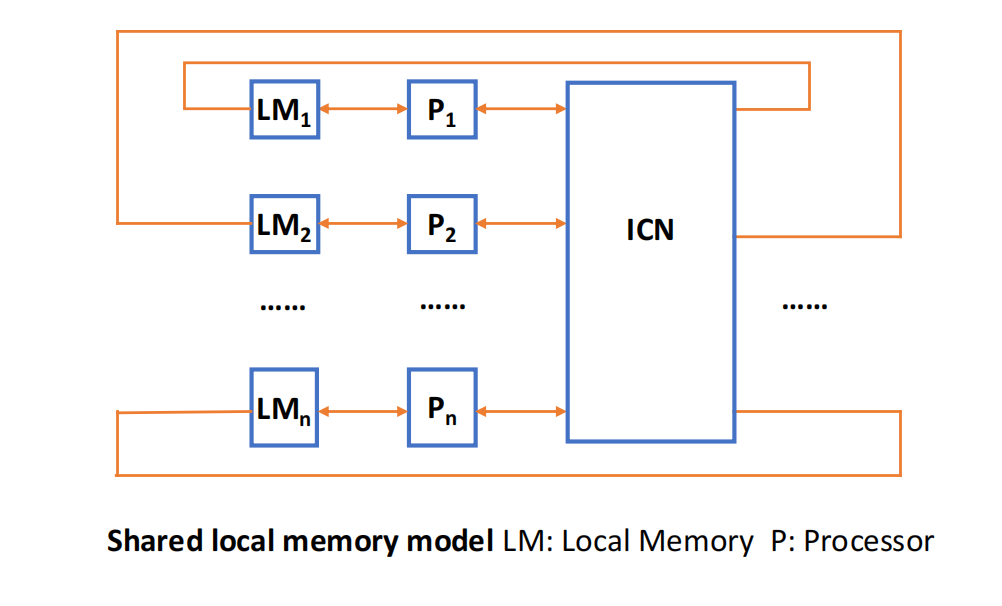
NUMA(Non-Uniform Memory Access,非均匀存储访问) 中,每个处理器或节点附近有本地内存,但系统仍然提供统一地址空间。
特点:
- 所有 CPU 共享一个统一地址空间;
- 处理器可以用
LOAD/STORE访问远程内存; - 访问本地内存更快,访问远程内存更慢;
- 处理器可以使用 cache;
- 常见于分布式共享内存系统。
NUMA 又分为:
-
NC-NUMA(Non Cache-coherent NUMA)
- 不提供 cache coherence;
- 远程访问代价不能被 cache 一致性机制隐藏;
- 程序员或系统软件需要更显式地处理数据放置和一致性。
-
CC-NUMA(Cache-coherent NUMA)
- 提供 cache coherence;
- 远程数据可以缓存在本地 cache 中;
- 硬件/协议维护多个 cache 副本之间的一致性。
NUMA 也称为:
DSP = Distributed Shared-memory Processor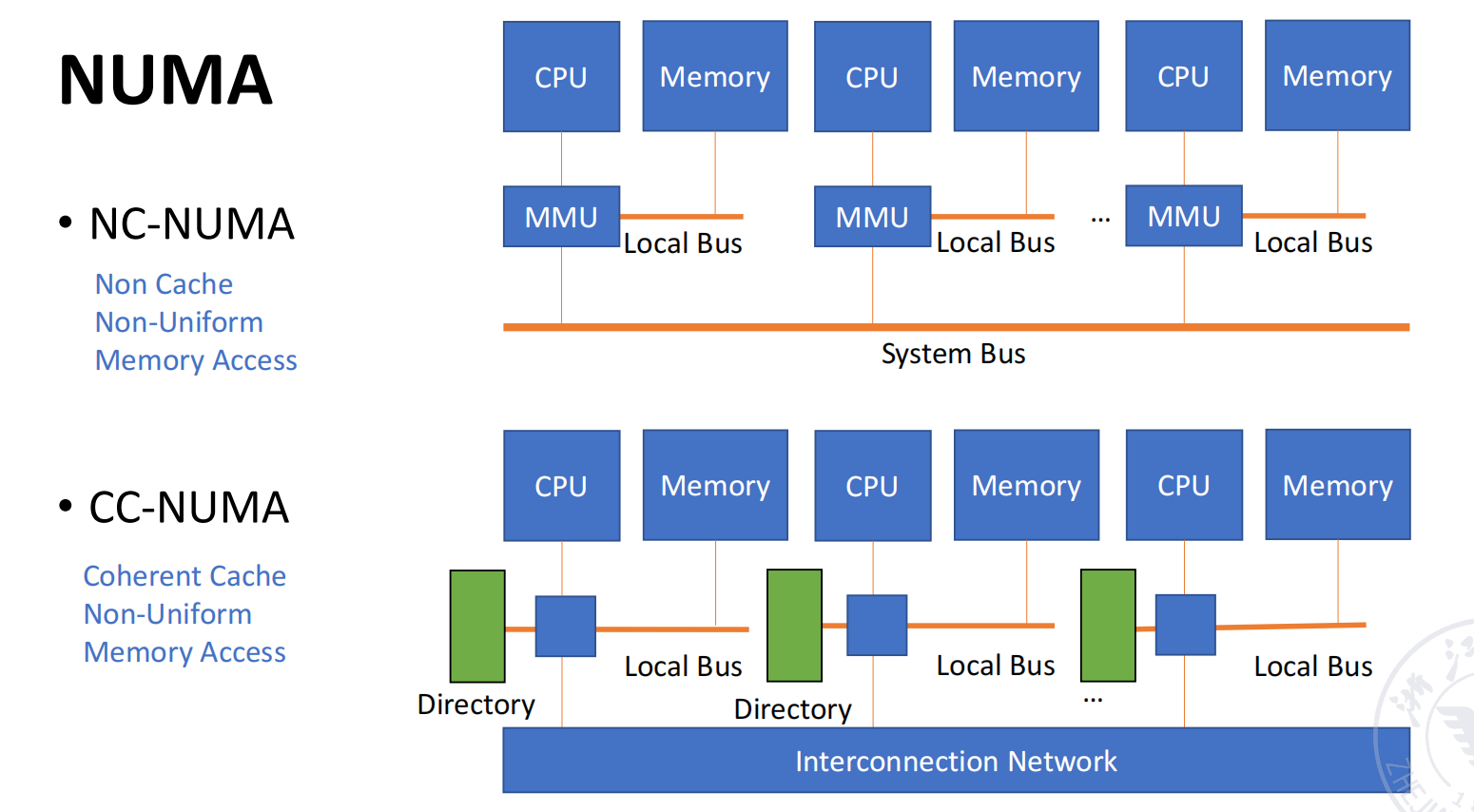
COMA:Cache Only Memory Access
COMA(Cache Only Memory Access) 可以看作 NUMA 的一种特殊形式。
特点:
- 每个处理器节点中没有传统意义上的固定内存层次;
- 所有 cache 共同构成一个全局地址空间;
- 数据块可以在运行过程中迁移到使用它的节点附近;
- 通过 distributed cache directory 支持远程 cache 访问。
COMA 的核心思想是:数据一开始可以放在任意位置,运行时会逐渐迁移到真正需要它的地方。
这类结构的直觉优势是提高数据局部性,但代价是目录维护、数据查找和一致性控制更加复杂。
Parallel Processing 的两个挑战
多处理器可以让多个任务并行执行,但并行处理有两个根本挑战。
挑战一:程序可用并行性有限
并不是处理器越多,加速比就越高。程序中总有一部分必须串行执行,或者并行度不足以填满所有处理器。
用小组分工做类比:一个任务从 1 个人变成 8 个人,并不意味着速度一定提升 8 倍。因为:
- 有些工作天然只能顺序做;
- 分工本身需要设计;
- 多人之间需要沟通、同步和协调;
- 协调开销会抵消一部分并行收益。
这可以用 Amdahl 定律量化。
若并行比例为 ,处理器数为 ,则:
例子:100 个处理器达到 80 倍加速
题目:假设有 100 个处理器,希望整体加速比达到 80,原始计算中最多允许多少比例是串行的?
设串行比例为 ,并行比例为 :
因此:
也就是:
结论:要用 100 个处理器达到 80 倍加速,串行部分只能约为 0.25%。这个比例极小,说明大规模并行对程序并行性的要求非常苛刻。
例子:100 处理器中部分时间只能用 50 个处理器
题目:一个应用运行在 100 处理器系统上。假设 95% 的时间可以完美使用全部 100 个处理器,剩下 5% 的时间只能选择使用 50 个处理器或串行执行。若希望整体加速比为 80,剩余 5% 中有多少必须使用 50 个处理器?
设使用 50 个处理器的比例为 ,串行比例为 。
改进后执行时间比例为:
希望:
代入:
所以:
- 约 4.8% 的原始执行时间必须能使用 50 个处理器;
- 只剩 0.2% 可以串行执行。
这个例子说明:高加速比不仅要求“大部分程序可以并行”,还要求并行部分能使用足够多的处理器。
挑战二:通信成本高
即使程序并行性足够,处理器之间也需要通信。通信会导致额外延迟,降低有效加速比。
例子:远程访存通信对 CPI 的影响
题目:一个 32 处理器系统中,远程内存访问延迟为 100 ns。处理器主频为 4 GHz,base CPI 为 0.5,0.2% 的指令涉及远程通信引用。问没有通信的多处理器会快多少?
先计算时钟周期:
远程访问代价为:
CPI 为:
没有通信时 CPI 为 0.5,因此无通信系统相对于有通信系统的速度提升为:
结论:即使只有 0.2% 的指令涉及远程通信,也会让 CPI 从 0.5 增加到 1.3,性能损失非常明显。
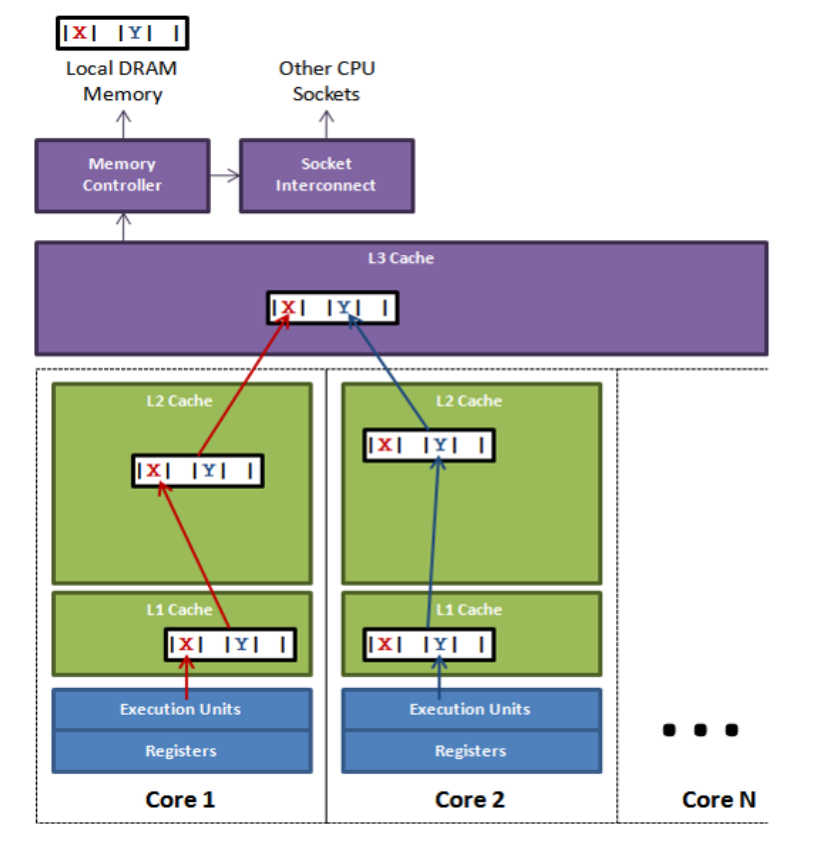
Cache Coherence
共享内存多处理器中,每个处理器通常都有自己的 private cache。这样可以降低访存延迟,但也带来了核心问题:同一个内存块可能在多个 cache 中存在多个副本。
如果其中一个处理器修改了自己的副本,其他处理器的副本就可能变成旧值。这个问题称为 cache coherence problem(缓存一致性问题)。
为什么共享内存多处理器会出现一致性问题
考虑一个内存位置 X,初始值为 1,处理器 A 和 B 都可能读写它。假设最开始两个 cache 中都没有 X。
一种典型过程是:
- B 读取
X,B 的 cache 中得到X=1; - A 写入
X=2,A 的 cache 和内存中变为新值; - B 再次读取
X,如果仍然命中自己的 cache,就会读到旧值 1。
这就违反了共享内存程序员的直觉:既然大家访问同一个地址 X,就应该看到同一个最近写入的值。
Memory Consistency 与 Cache Coherence
Cache Coherence:同一地址的多个副本是否一致
Cache coherence 关注的是 同一个内存位置 的读写行为。
它要求:
- 任意处理器对某地址的读取,都应该返回最近写入该地址的值;
- 对同一个地址的多个写入,所有处理器看到的顺序必须一致。
正确的一致性协议应该保证:程序员仅通过 loads/stores 的结果,不能判断系统到底有没有 cache、cache 在哪里。换句话说,cache 不能引入新的功能行为差异,只能改变性能。
Memory Consistency:不同地址读写之间的顺序规则
Memory consistency 关注的是 不同内存位置之间 的读写顺序。
例如:
Processor 1: Processor 2:A = 0 B = 0...A = 1 B = 1if (B == 0) ... if (A == 0) ...问题是:不同处理器对 A 和 B 的读写,应该按照什么顺序被其他处理器观察到?
因此:
Cache Coherence 解决同一地址的值是否一致。Memory Consistency 规定不同地址读写的全局可见顺序。一个共享内存系统通常需要同时定义:
- Cache coherence protocol:维护同一 cache block 的副本一致;
- Memory consistency model:规定不同地址访问的可见顺序。
Snoopy Coherence Protocols
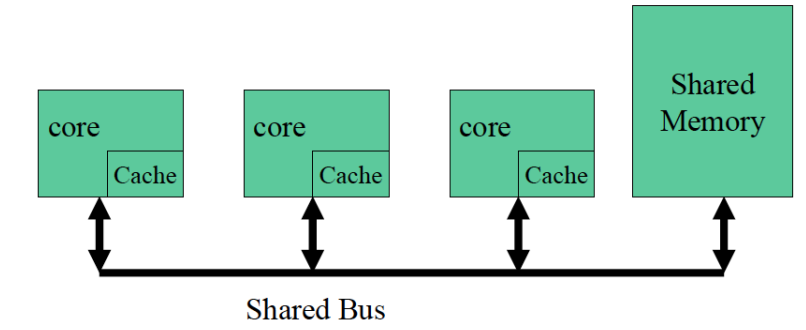
对于 UMA / SMP 系统,由于多个处理器通常连接在同一条共享总线或共享互联结构上,可以使用 snoopy coherence protocol(监听一致性协议)。
基本思想:
- 所有 cache 都监听总线上的访问请求;
- 当某个处理器修改了 private cache 中的数据,会在总线上广播信息;
- 其他 cache 根据广播消息更新或失效自己的副本。
根据写操作的处理方式,常见策略有两类。
Write Invalidate Protocol
写无效协议的思想是:一个处理器写某个块时,让其他 cache 中该块的副本失效。
这样写入者获得该块的独占修改权,后续其他处理器若要读这个块,就会 miss,并通过一致性协议获得新值。
优点:
- 对同一数据连续多次写时,只需要第一次让其他副本失效;
- 不需要每次写都广播新数据;
- 总线带宽消耗相对较低。
Write Update / Write Broadcast Protocol
写更新协议的思想是:一个处理器写某个块时,把新值广播给所有持有该块副本的 cache。
优点:其他处理器的副本可以保持有效。
缺点:每次写都需要广播新数据,带宽开销大。老师强调,更新策略和无效策略没有绝对优劣,需要看访问模式和系统设计。
Write-through 与 Write-back
Snoopy protocol 还要结合 cache 写策略理解。
- Write-through
每次写 cache line 的同时,也写入对应内存。因此内存始终保持最新。
- Write-back
写操作只修改 cache,并设置 dirty/modified 状态,表示 cache 中数据最新、内存中过期。该行最终会在替换或被其他处理器请求时写回内存。
Write-back 能减少内存写流量,但一致性协议更复杂。
Write-through + No-write Allocation 的基本行为
对于 write-through cache with no-write allocation,可以按本地请求和远程请求理解:
| 请求 | 行为 |
|---|---|
| Local Read Hit | 使用本地 cache 数据 |
| Local Read Miss | 从 memory 取数 |
| Local Write Hit | 修改 cache 和 memory,同时使其他副本失效 |
| Local Write Miss | 直接修改 memory,不一定把块调入 cache |
| Remote Write | 本地若有该块副本,则 invalidate |
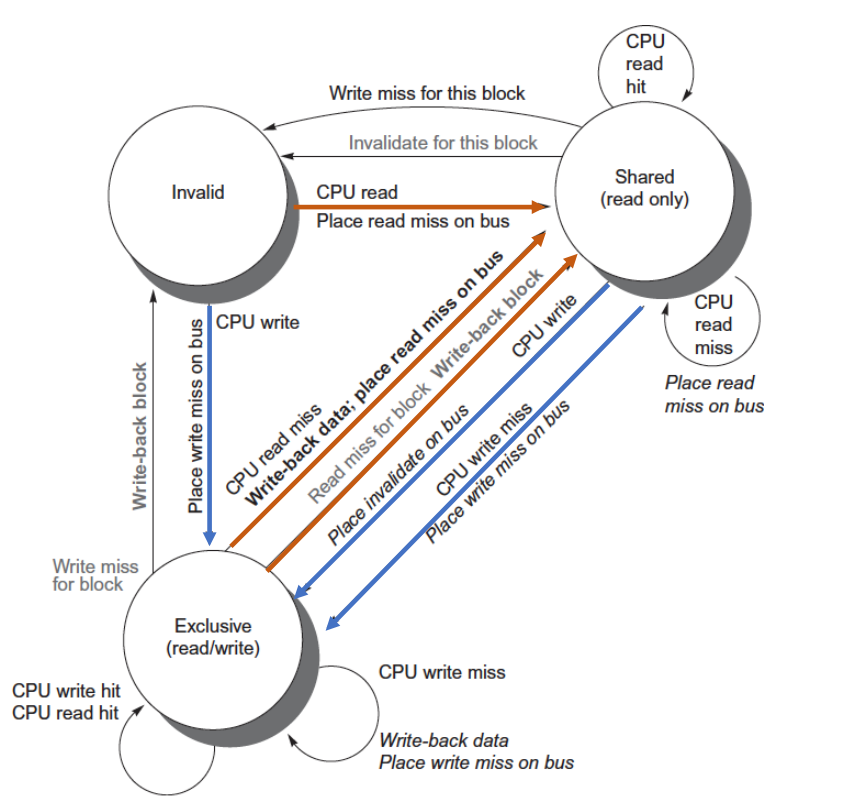
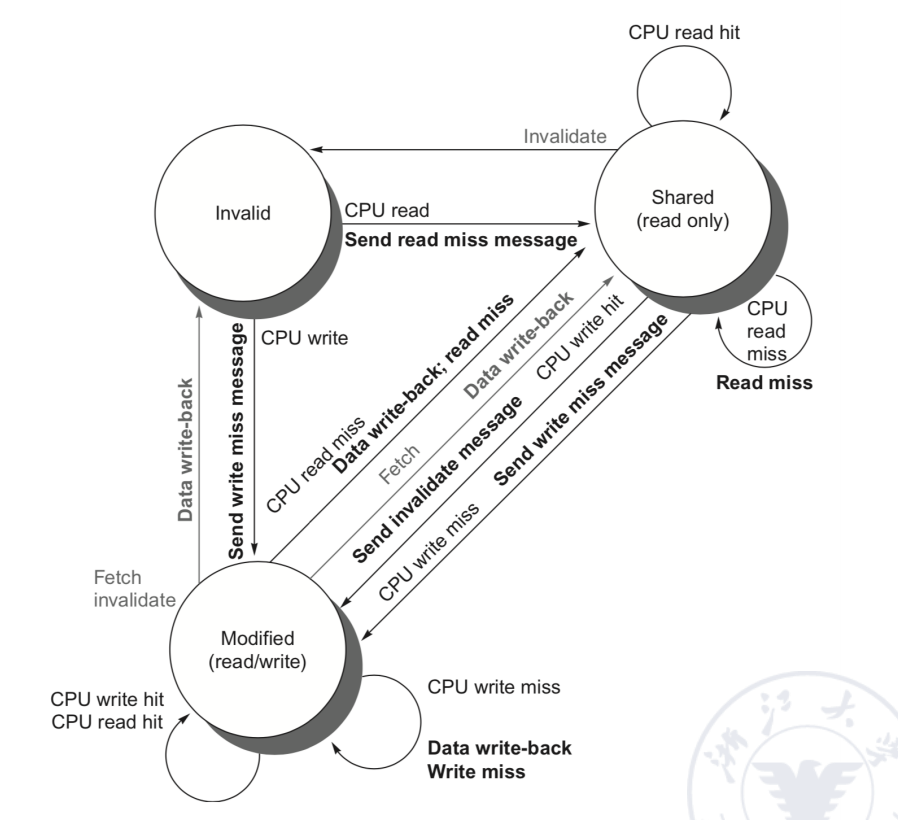
MSI Protocol
MSI 是写无效监听协议的经典实现。它给每个 cache block 增加三种状态。
| 状态 | 含义 |
|---|---|
| I = Invalid | 当前 cache block 无效,不能使用 |
| S = Shared | 当前 block 可能被多个 cache 共享,数据与内存一致 |
| M = Modified | 当前 block 已被本 cache 修改,数据有效但内存过期;该 block 在本 cache 中独占 |
MSI 的关键规则:
- 读 miss:从内存或其他 cache 获取数据,通常进入 S;
- 写 shared block:广播 invalidate,使其他副本进入 I,本地进入 M;
- 写 invalid block:先获得该块和独占权,再写入,进入 M;
- 其他处理器读到本地 M block:本地需要提供或写回最新数据,状态通常降级为 S。
例子:4-line direct-mapped write-back cache
题目设定:
- 3 个 core:Core 0、Core 1、Core 2;
- 每个 core 有 4 行 direct-mapped write-back cache;
- 使用 basic write invalidation snooping protocol;
I/S/M分别表示 Invalid / Shared / Modified。
初始状态如下。
| Core | Line | State | Addr | Data |
|---|---|---|---|---|
| C0 | 0 | I | A100 | 0000 |
| C0 | 1 | S | A104 | 0104 |
| C0 | 2 | M | A108 | 0208 |
| C0 | 3 | I | A10C | 0000 |
| C1 | 0 | S | A100 | 0100 |
| C1 | 1 | S | A104 | 0104 |
| C1 | 2 | I | A108 | 0000 |
| C1 | 3 | S | A11C | 011C |
| C2 | 0 | I | A000 | 0000 |
| C2 | 1 | S | A104 | 0104 |
| C2 | 2 | I | A108 | 0000 |
| C2 | 3 | M | A10C | 020C |
内存初始状态:
| Addr | Data |
|---|---|
| A100 | 0100 |
| A104 | 0104 |
| A108 | 0108 |
| A10C | 010C |
| A110 | 0110 |
| A114 | 0114 |
| A118 | 0118 |
| A11C | 011C |
示例:C0, R, A100
A100 映射到 C0 的 line 0。C0 line 0 当前为 I,因此 read miss。
内存返回 0100 给 C0:
C0 Read MissMemory return 0100 to C0C0.0 (S, A100, 0100)Action 1:C0, R, A10C
A10C 映射到 C0 的 line 3。C0 line 3 当前为 I,因此 C0 read miss。
但 C2 line 3 中有 A10C 且状态为 M,说明 C2 拥有最新值,内存中的 A10C=010C 已经过期。
处理过程:
C0 Read missC2 write back A10CMemory A10C, 010C -> 020CC2.3 (S, A10C, 020C)Memory returns 020C to C0C0.3 (S, A10C, 020C)要点:当其他 cache 中有 M 状态副本时,读请求不能直接相信内存,必须先让 M 状态拥有者写回或提供最新数据。
Action 2:C1, W, A104, 0204
C1 line 1 中已有 A104,状态为 S,因此这是 write hit on shared block。
写无效协议要求 C1 写入前使其他副本失效。C0 line 1 和 C2 line 1 都有 A104 的 S 副本,因此都被 invalidated。
处理过程:
C1 write hitC0 invalidationC0.1 (I, A104, 0104)C2 invalidationC2.1 (I, A104, 0104)C1.1 (M, A104, 0204)注意:write-back 策略下,C1 写完后进入 M,内存中的 A104 暂时没有更新。
Action 3:C0, W, A118, 0308
A118 映射到 C0 line 2。C0 line 2 当前是 A108,状态为 M,数据为 0208。
因此 C0 要把 A108 这个 dirty block 写回内存,然后取入 A118,再写入新值。
处理过程:
C0 write missC0 write back A108Memory A108, 0108 -> 0208Memory returns 0118 to C0C0.2 (M, A118, 0118)C0.2 (M, A118, 0308)要点:写 miss 需要替换本地 cache line;如果被替换行是 M,必须先 write back。
MESI 与 MOESI
MSI 中,读入一个没有任何其他 cache 持有的块时,也只能放入 S。这样如果随后本处理器写这个块,还需要广播一次 bus transaction 从 S 变为 M。
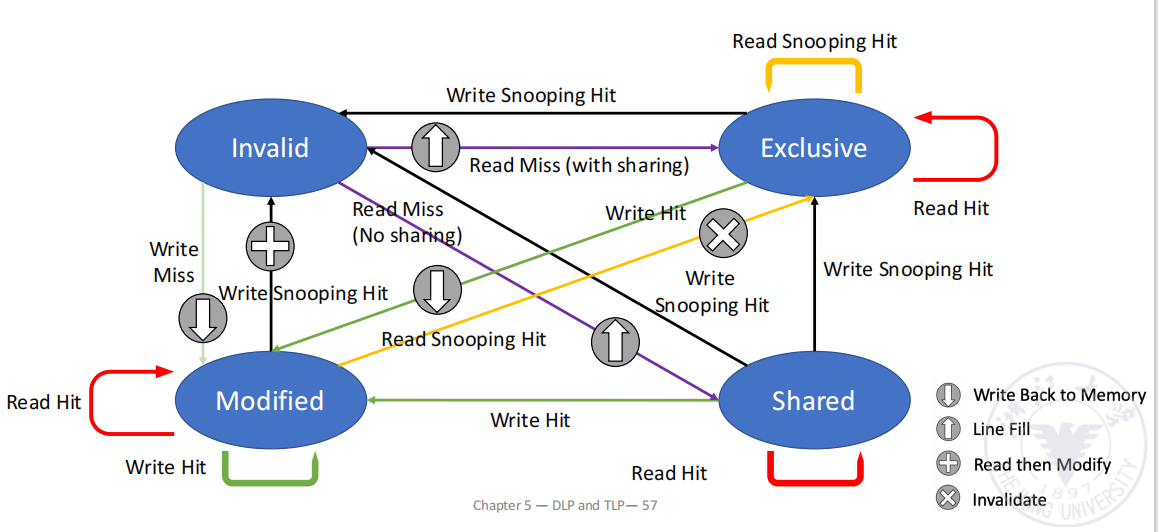
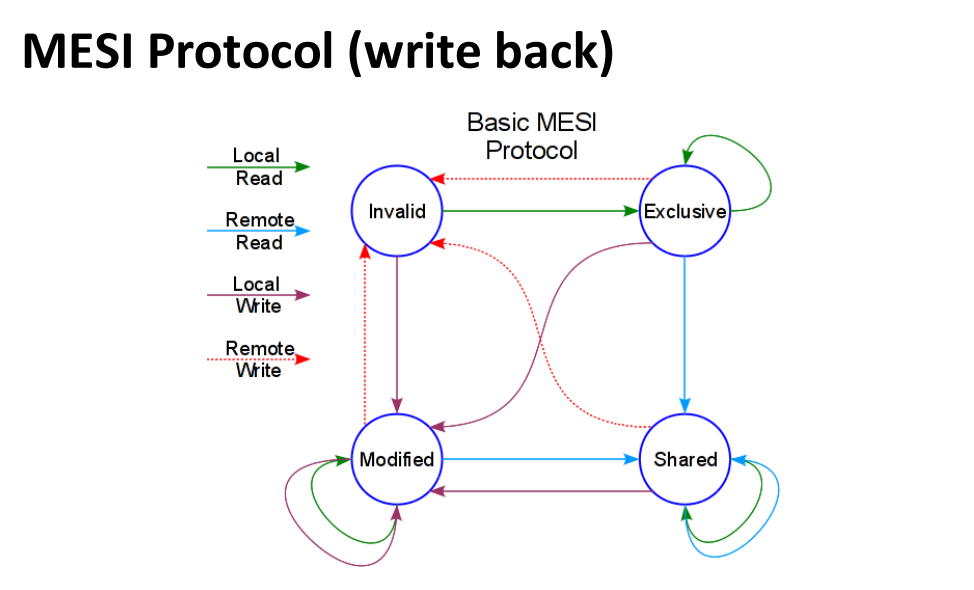
MESI 增加了一个状态 E(Exclusive)来优化这种情况。
| 状态 | 含义 |
|---|---|
| M = Modified | 本 cache 独占且已修改,内存过期 |
| E = Exclusive | 本 cache 独占但未修改,内存最新 |
| S = Shared | 多个 cache 可能有副本,内存最新 |
| I = Invalid | 无效 |
E 状态的关键价值:
- 如果读 miss 时没有其他 cache 持有该 block,则本地进入 E;
- E 状态下本地写 hit 可以 silent upgrade 到 M,不需要总线广播;
- 如果其他处理器读该 block,则 E 降级为 S。
MESI 状态变化例子
假设四个处理器 P0/P1/P2/P3 起始都没有块 a。
| 处理器活动 | P0 | P1 | P2 | P3 |
|---|---|---|---|---|
| Initial state | I | I | I | I |
| P0 reads a | E | I | I | I |
| P1 reads a | S | S | I | I |
| P2 reads a | S | S | S | I |
| P3 writes a | I | I | I | M |
| P0 reads a | S | I | I | S |
这个例子体现了 MESI 的两条核心逻辑:
- 第一个读取者若没有共享者,可以进入 E;
- 一旦出现多个读取者,就必须进入 S;
- 写入者需要使其他共享者失效,并进入 M。
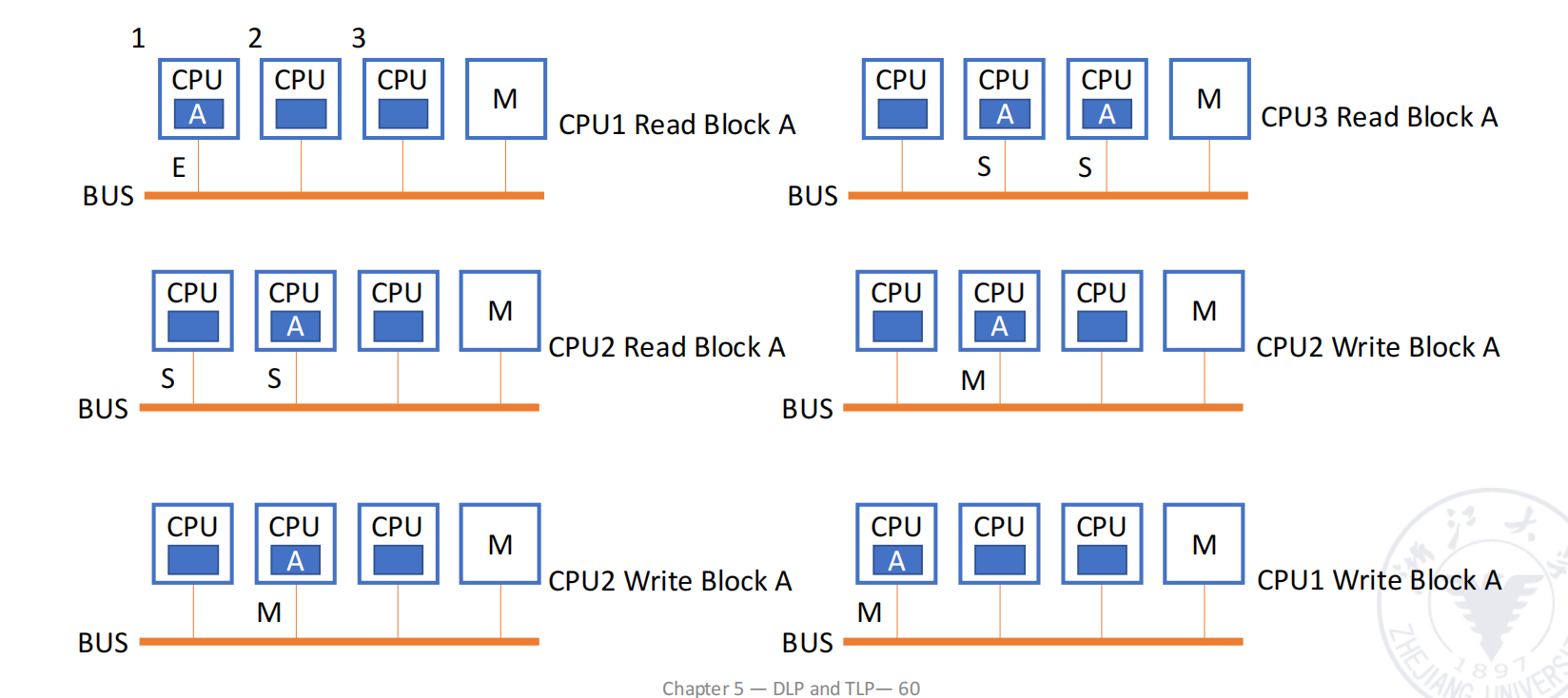
- If P0 writes to Block 0, what happens to its coherency state?
P0 的 Block 0 已经是 M,写命中后仍然保持 M。
- If P1 writes to Block 1, is Block 1 on P0 invalidated?
不一定看 cache line 编号,要看是否是同一个 memory block。图中 P1 的 Block 1 tag 为 8000,P0 的 Block 1 tag 为 4000,不是同一个块,因此 P0 的 Block 1 不会被 invalidated。
- If P1 brings in Block M for reading, and no other cache has a copy, what state is it cached in?
如果没有其他 cache 拥有副本,读入后进入 E 状态。
MOESI
MOESI 在 MESI 基础上增加 O(Owned)状态。
O 状态表示:
- 该 cache 拥有最新数据;
- 内存中的副本已经过期;
- 其他 cache 可以持有 shared copy;
- modified block 可以降级为 owned,而不必立刻写回内存。
MOESI 可以减少某些共享读场景下的写回开销,但状态机更复杂。课程中重点掌握 MSI 和 MESI。
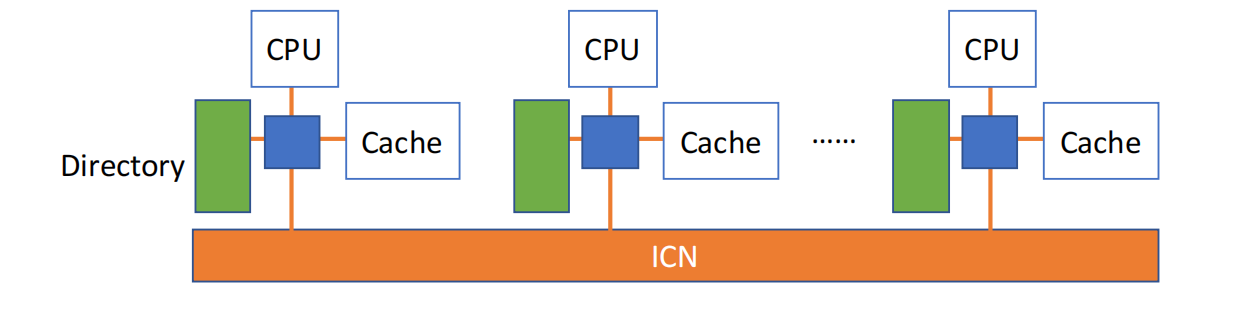
Directory-Based Coherence Protocol
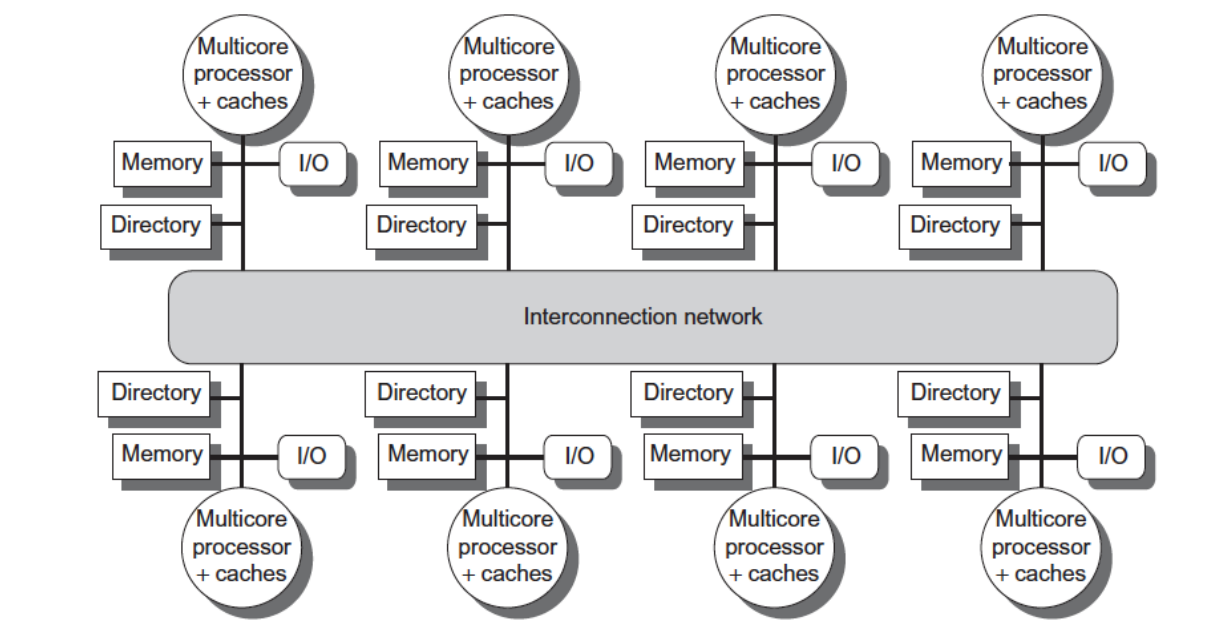
Snoopy protocol 适合 UMA / SMP,因为所有处理器都能监听共享总线。但在 NUMA / distributed shared memory 中,节点数更多、互联网络更复杂,不可能让所有请求都广播到所有节点。
因此 NUMA 通常使用 directory protocol(目录协议)。
基本思想:
- 每个节点增加 directory;
- directory 记录每个内存块的共享状态;
- directory 维护哪些 cache 持有该块副本、该块是否 dirty、谁是 owner;
- 当某处理器想写共享块时,directory 只向持有副本的节点发送 invalidate 消息。
这是一种点对点的一致性维护方式,避免了全局广播。
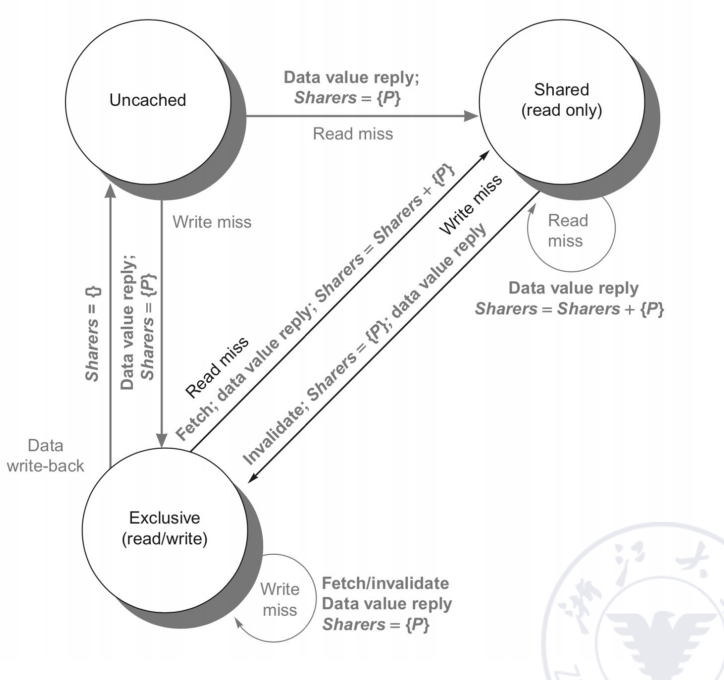
Directory 的三种状态
对每个 block,directory 至少维护三种状态。
| 状态 | 含义 |
|---|---|
| Uncached | 没有任何节点缓存该 block |
| Shared | 一个或多个节点缓存该 block,内存中数据最新 |
| Modified / Exclusive | 只有一个节点缓存该 block 且已写入,内存中过期;该节点是 owner |
状态转移规则
Uncached block
- Read miss:把数据发给请求节点,请求节点成为唯一 sharer,block 变为 Shared。
- Write miss:把数据发给请求节点,请求节点成为 owner,block 变为 Exclusive/Modified。
Shared block
- Read miss:从内存把数据发给请求节点,并把请求节点加入 sharing set。
- Write miss:把数据发给请求节点,同时向所有 sharers 发送 invalidation,sharing set 只保留请求节点,block 变为 Exclusive/Modified。
Exclusive / Modified block
- Read miss:directory 向 owner 发送 data fetch,owner 提供数据;block 变为 Shared,旧 owner 和请求者都在 sharer set 中,必要时数据写回内存。
- Data write back:owner 写回后,block 变为 Uncached,sharer set 清空。
- Write miss:directory 通知旧 owner invalidate 并把数据交给 directory;请求者成为新 owner,block 保持 Exclusive/Modified。
Directory protocol 的核心收益是可扩展性更好,代价是:
- 每个内存块都需要目录状态;
- 目录查找和消息交互会增加延迟;
- 协议状态机比 snoopy protocol 更复杂。
False Sharing
False sharing(伪共享) 指多个线程访问的是不同变量,但这些变量落在同一个 cache line 中,导致 coherence protocol 把它们当成同一个共享块来维护。
典型代码如下:
class Pointer { volatile long x; volatile long y;}如果线程 1 不断写 x,线程 2 不断写 y,从程序语义看二者没有共享变量。但如果 x 和 y 位于同一个 cache line,那么:
- 线程 1 写
x会使线程 2 所在核中的该 cache line 失效; - 线程 2 写
y又会使线程 1 所在核中的该 cache line 失效; - 两个核不断互相 invalidate,产生大量 coherence traffic。
这就是“假共享”:变量层面没有共享,cache line 粒度上发生了共享。
避免 false sharing 的方法
常见方法是让频繁被不同线程写入的变量落在不同 cache line 中。
- 手动 padding
class Pointer { volatile long x; long p1, p2, p3, p4, p5, p6, p7; volatile long y;}在 x 和 y 中间插入填充字段,使它们分离到不同 cache line。
- 封装并 padding 每个对象
class Pointer { MyLong x = new MyLong(); MyLong y = new MyLong();}
class MyLong { volatile long value; long p1, p2, p3, p4, p5, p6, p7;}- 使用语言/运行时提供的 cache line padding 注解
@sun.misc.Contendedclass MyLong { volatile long value;}实际工程中应结合运行时参数、对象布局和 JVM 版本判断 padding 是否生效。
Memory Consistency
Memory consistency model 规定多处理器系统中,不同处理器对不同地址执行读写操作时,哪些顺序必须被其他处理器观察到。
Sequential Consistency
Sequential consistency(顺序一致性) 是最容易理解的模型。
它要求执行结果等价于某个全局串行顺序,并且:
- 每个处理器内部的访存顺序保持程序顺序;
- 不同处理器之间的访存可以任意交错;
- 所有处理器看到的是同一个交错顺序。
顺序一致性直观、容易编程,但会限制硬件优化。
例如:
Processor 1: Processor 2:A = 0 B = 0...A = 1 B = 1if (B == 0) ... if (A == 0) ...如果处理器允许 store buffer、乱序执行、写读重排,就可能出现程序员直觉之外的结果。Memory consistency model 就是用来明确这些行为是否合法。
Relaxed Consistency Models
放松一致性模型的核心思想是:允许普通读写乱序完成,但用同步操作显式建立顺序约束。
记号:
X -> Y表示操作 X 必须在操作 Y 之前完成。
顺序一致性要求四类顺序都保持:
R -> WR -> RW -> RW -> W不同 relaxed model 会放松其中一部分:
| 模型 | 放松内容 | 直觉 |
|---|---|---|
| Total Store Ordering / Processor Consistency | 放松 W -> R | 允许写后读重排,常由 store buffer 导致 |
| Partial Store Order | 放松 W -> W 和 W -> R | 允许不同写之间也重排 |
| Weak Ordering / Release Consistency | 放松 R -> W、R -> R、W -> W、W -> R | 普通读写可高度重排,用 acquire/release 等同步操作约束 |
放松一致性的意义是提高性能,但程序员必须通过锁、barrier、atomic、fence 等同步原语明确建立 happens-before 关系。
MIMD: MPP / COW / WSC
除了 UMA / NUMA / COMA 这类共享内存多处理器,MIMD 还包括更大规模、更松耦合的系统组织。
MPP:Massively Parallel Processor
MPP(Massively Parallel Processor,大规模并行处理机) 是由数百个甚至更多处理器组成的大规模并行计算系统。
特点:
- 通常使用标准商用 CPU 作为处理器;
- 使用高性能专用互联网络,追求低延迟和高带宽;
- 具有较强 I/O 能力;
- 支持专门的容错处理;
- 过去主要用于科学计算、工程仿真等计算密集场景,也逐渐用于商业和网络应用。
MPP 的开发难度高、价格高、市场相对有限,常被视为高性能计算能力的体现。
COW:Cluster of Workstations
COW(Cluster of Workstations,工作站集群) 由大量 PC 或工作站通过商用网络连接而成。
特点:
- 可以用商用组件组装;
- 成本较低,性价比高;
- 每个节点更像一台完整计算机,有自己的处理器、内存、本地磁盘和 I/O;
- 节点之间通常通过 Ethernet、Myrinet、ATM 等 commodity network 连接;
- 可分为 centralized 和 decentralized 两类。
COW 相比 MPP 更松耦合,硬件专用性较低,但成本优势明显。
WSC:Warehouse-Scale Computer
WSC(Warehouse-Scale Computer,仓库级计算机) 可以理解为超大规模 cluster。大量服务器通过网络连接,在软件系统协调下共同对外提供服务。
典型例子是 Google WSC。
从体系结构角度看,WSC 的重点已经不只是单个处理器性能,而是:
- 大规模请求级并行;
- 网络与存储系统;
- 容错和高可用;
- 能耗、冷却、成本;
- 集群调度与系统软件。
Domain-Specific Architectures
DSA(Domain-Specific Architecture,领域专用架构)。
DSA 的背景是:Moore’s Law 和 Dennard Scaling 放缓后,通用处理器很难继续依靠单核频率和复杂微结构获得高性能。因此,体系结构开始更多转向特定领域专用加速。
通用处理器过去依赖的复杂机制
Moore’s Law 曾经让通用处理器可以不断加入复杂硬件:
- deep memory hierarchy;
- wide SIMD units;
- deep pipelines;
- branch prediction;
- out-of-order execution;
- speculative prefetching;
- multithreading;
- multiprocessing。
这些机制的目标是:在软件不太关心底层架构的情况下,尽可能从程序中自动提取性能。
DSA 的设计原则
DSA 的设计更强调让硬件结构匹配领域特征。基本原则包括:
- 使用 dedicated memories,减少数据移动;
- 把资源投入到更多 arithmetic units 或更大的专用存储;
- 使用最适合该领域的并行形式;
- 把数据大小和类型降到领域所需的最简单形式;
- 使用 domain-specific programming language 或领域专用软件栈。
CNN 与 TPU 例子
神经网络是 DSA 的典型应用场景。
CNN 中常见的关键计算包括:
- matrix-vector multiply;
- matrix-matrix multiply;
- convolution;
- ReLU;
- sigmoid。
可以利用 batch 复用权重,提高 operational intensity;也可以使用 quantization,把数据压缩为 8-bit 或 16-bit fixed point。
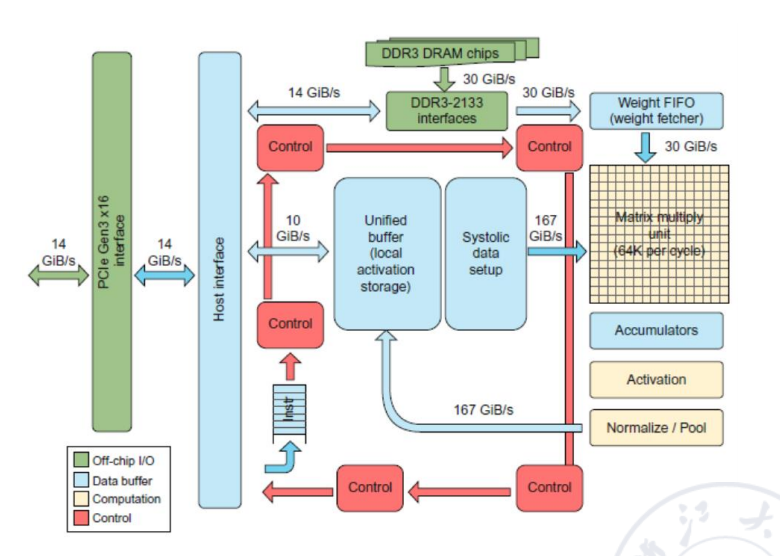
Google TPU 是典型 DNN ASIC:
- 具有
256 × 256的 8-bit matrix multiply unit; - 使用较大的 software-managed scratchpad;
- 作为 PCIe bus 上的 coprocessor;
- 通过 TensorFlow 等软件栈暴露给上层程序。
TPU ISA 中的典型操作包括:
Read_Host_Memory:从 CPU memory 读入 unified buffer;Read_Weights:把权重读入 Weight FIFO;MatrixMatrixMultiply/Convolve:执行矩阵乘、向量矩阵乘、卷积等;Activate:计算激活函数;Write_Host_Memory:把结果写回 host memory。
TPU 与 DSA 原则的对应关系:
| DSA 原则 | TPU 中的体现 |
|---|---|
| 使用专用存储 | 24 MiB dedicated buffer,4 MiB accumulator buffers |
| 投入算术单元和专用存储 | 相比 server-class CPU 有大量矩阵乘硬件 |
| 匹配领域并行形式 | 利用 2D SIMD / systolic-array 风格并行 |
| 降低数据类型复杂度 | 主要使用 8-bit integers |
| 配套领域软件栈 | 使用 TensorFlow |