

概述
这一章的核心是:
关系模型要求属性值是 atomic(原子的),但真实应用里经常需要存 非原子(non-atomic)、层次化(hierarchical)、对象化(object-based)、文本(textual)、空间(spatial) 数据。
当“表 + 原子属性”不够用了,数据库系统要怎么扩展?
主线可以分成四块:
- Semi-structured Data:模式不固定、结构可嵌套的数据,比如
XML / JSON / RDF - Object Orientation:把对象世界的一些能力带进数据库,比如类型、继承、引用、ORM
- Textual Data:怎么查非结构化文本,怎么做 relevance ranking
- Spatial Data:怎么表示地图、几何对象,以及怎么做空间查询
目录
- 概述
- 目录
- Why Complex Data Types
- Object-Based Databases / Object-Relational Ideas
- Semi-Structured Data
- Textual Data
- Spatial Data
Why Complex Data Types
为什么关系模型会遇到限制
关系模型很强,但它有一个默认前提:
- 每个属性值都应该是 atomic
- 表结构通常比较稳定
- 应用更适合拆成“多张规范化表 + join”
这在传统业务系统里很好用。
但很多现代应用并不满足这些前提,例如:
- 用户 profile 经常加新字段
- 一个属性本身就是一个集合或嵌套结构
- 前后端之间需要交换复杂对象
- 应用代码本身是面向对象写的,数据库却是关系模型
- 文本检索和地图查询,本身就不是普通等值匹配问题
所以,严格的原子属性 + 固定 schema 在这些场景里会显得过于僵硬。
三条典型路线
-
OODB(Object-Oriented Database)
- 直接做原生支持对象的数据库
- 数据和程序语言对象模型更贴近
-
ORDB(Object-Relational Database)
- 在关系数据库上加对象特性
- 保留关系模型基础,同时支持复杂类型、继承、引用等
-
ORM(Object-Relational Mapping)
- 数据库内部仍是关系模型
- 由中间层自动做对象和元组之间的映射
简单理解:
- OODB:数据库本身对象化
- ORDB:关系数据库扩展出对象能力
- ORM:数据库不一定变,程序员看到的是对象接口
图书例子理解“复杂类型”
每本书有:
title- 一组
authors publisher- 一组
keywords
这时候如果写成一个嵌套关系:
books(title, author-set, publisher(name, branch), keyword-set)它显然不是 1NF,因为:
author-set是集合publisher是复合结构keyword-set也是集合
Non-1NF relation

这种表示其实很自然,因为它和“书”这个业务对象非常贴近。
- 一本书对应一个记录
- 作者列表就是一个集合
- 关键词列表也是一个集合
- 出版社本身又是一个小结构
从建模直觉看,这个设计很好懂。
但从经典关系模型看,它违反了原子性要求。
1NF 版本为什么 awkward

如果强行改成 1NF,通常会变成:
flat-books(title, author, pub-name, pub-branch, keyword)于是一本书的每个作者和每个关键词会做笛卡尔组合。
例如 Compilers 有两个作者、两个关键词,就会变成 4 行。
问题在于:
- 出版社信息被重复很多次
- 作者和关键词之间本来没有直接关系,却被硬绑在同一行
- 更新、维护都很 awkward
这是为了满足 1NF 而牺牲语义直观性
用 4NF 分解来缓解

继续假设以下 multivalued dependencies(MVD):
title ->-> authortitle ->-> keywordtitle ->-> (pub-name, pub-branch)
于是可以把 flat-books 分解成:
(title, author)(title, keyword)(title, pub-name, pub-branch)
这说明一个很关键的点:
复杂数据有时可以用更高范式的关系分解来表达,但表达出来之后,结构往往没有原始嵌套表示直观。
TIP这组例子其实在说明两个层面的“好坏”
- 从 关系规范化 角度,
flat-books有明显冗余- 从 建模表达力 角度,
books(title, author-set, publisher, keyword-set)又更贴近现实对象所以 有些场景里,复杂结构本身就是合理的。
Object-Based Databases / Object-Relational Ideas
SQL 对复杂类型的扩展方向
SQL 扩展方向包括:
- Collection types
- Structured types
- Inheritance
- Object orientation
- object identifiers
- references
- Large object types
BLOBCLOB
这些思想主要来自 SQL:1999 及其后的对象关系扩展。
不过:
- 标准里定义得很多
- 真正的数据库系统实现得并不统一
- 各家产品语法差异也很大
Collection Types
Collection type 就是“一个属性里放多个值”。
常见形式:
setmultisetarraytable type
Example:array + multiset
create type Publisher as(name varchar(20), branch varchar(20));
create type Book as( title varchar(20), author_array varchar(20) array [10], pub_date date, publisher Publisher, keyword_set varchar(20) multiset);
create table books of Book;这里的意思是:
author_array:作者用数组表示publisher:是一个结构化类型Publisherkeyword_set:关键词是 multiset
和前面的 nested relation 类似,只不过这里作者是数组而不是集合。
set / multiset / array 的区别
- set:无重复、通常无顺序
- multiset:允许重复、通常不强调顺序
- array:有顺序,可按位置访问
选择哪个,取决于业务语义:
- 作者署名顺序重要时,
array很自然 - 关键词顺序通常不重要,
set/multiset更自然
Structured Types
Structured type 本质上就是“属性里再嵌一个 record”。
例如:
User-defined type
create type Person as( ID varchar(20) primary key, name varchar(20), address varchar(20)) ref from(ID);
create table people of Person;这和 E-R 模型里的 composite attribute 很接近。
它的价值在于:
- 结构表达更自然
- 程序语言对象和数据库类型更接近
Table Types
create type interest as table ( topic varchar(20), degree_of_interest int);
create table users ( ID varchar(20), name varchar(20), interests interest);含义是:
users的一个元组里,interests本身又是一张小表- 每个用户都可以有一组
(topic, degree_of_interest)记录
这其实已经非常接近“对象里带一个子集合”。
Inheritance
对象世界里,一个类型可以继承另一个类型。
create type Student under Person(degree varchar(20));
create type Teacher under Person(salary integer);这里:
Student继承PersonTeacher继承Person
于是 Student 自动拥有:
IDnameaddress
再额外加上:
degree
表继承
表继承语法(PostgreSQL / Oracle 风格略有不同):
create table students(degree varchar(20))inherits people;
create table teachers(salary integer)inherits people;或者:
create table people of Person;create table students of Student under people;create table teachers of Teacher under people;它表达的是“子表 / 子类型”的概念。
这类机制适合处理:
- 公共属性很多
- 子类又有各自专属属性
的场景。
Object Identity / References
关系数据库里通常靠主键关联。
对象模型里则喜欢直接“引用某个对象”。
create type Person( ID varchar(20) primary key, name varchar(20), address varchar(20))ref from(ID);
create table people of Person;
create type Department ( dept_name varchar(20), head ref(Person) scope people);
create table departments of Department;这里的 head ref(Person) 表示:
Department.head存的是一个指向Person对象的引用scope people表示这个引用的作用域来自表people
路径表达式(path expression)
引用的价值在于能直接沿对象路径访问:
select head->name, head->addressfrom departments;这和程序语言里的 dept.head.name 非常像。
比起传统外键 + join,这种写法更对象化。
不过底层实现还是数据库系统负责。
Large Objects
复杂应用里还有一类常见数据:
- 图片
- 音频
- 视频
- 长文档
所以数据库通常提供:
- BLOB:Binary Large Object
- CLOB:Character Large Object
它们处理的是“大对象存储”问题,不是对象模型问题。
但也属于“复杂数据类型”的重要一支。
ORM(Object-Relational Mapping)
ORM 是目前最常见的一条路。
它做的事是:
-
在程序里写对象 / 类
-
由 ORM 框架把对象状态映射到关系表
-
创建、更新、删除对象时,自动生成相应 SQL ORM 的能力:
-
指定对象与元组之间的映射
-
创建对象时自动建数据库记录
-
更新 / 删除对象时自动同步数据库
-
按条件查询,再把结果重新组装成对象
常见框架:
- Hibernate(Java)
- Django ORM(Python)
Hibernate Example
@Entitypublic class Student { @Id String ID; String name; String department; int tot_cred;}含义:
@Entity:这个类映射到数据库关系@Id:ID是主键- 默认情况下,类名映射成表名,字段映射成列名
- 也可以用
@Table、@Column覆盖默认映射
保存对象:
Session session = getSessionFactory().openSession();Transaction txn = session.beginTransaction();Student stud = new Student("12328", "John Smith", "Comp. Sci.", 0);session.save(stud);txn.commit();session.close();查询对象:
Student stud1 = session.get(Student.class, "12328");List students = session.createQuery("from Student as s order by s.ID asc").list();ORM 的优点与代价
优点:
- 程序员更贴近对象思维
- 少写样板 SQL
- 开发效率高
代价:
- 容易忽略底层 SQL 代价
- 复杂查询场景可能不够透明
- “对象世界”和“关系世界”并不天然一一对应
TIPORM 不是把关系模型消灭了,只是把它包起来了。
底层表、键、索引、事务,依然都在。
所以 ORM 用得好不好, 很大程度上取决于你是否仍然理解关系数据库本身。
Semi-Structured Data
半结构化数据最重要的特点是:
- schema 不固定或者经常变化
- 数据值本身可能是嵌套结构
- 不同记录可以有不同属性集
典型场景:
- 快速演化的 web 应用
- 用户画像(user profile)
- 前后端数据交换
- 配置文件
- 知识图谱
在这些场景下,关系模型里“每个元组必须有同样列”的限制会比较重。
Flexible Schema
两种“弱化固定 schema”的方式。
Wide column representation
允许不同 tuple 拥有不同属性集。
特点:
- 新属性可以随时加
- 单个记录可以稀疏地存储很多字段
适合:
- 属性种类很多
- 某条记录只会用到其中一小部分
Sparse column representation
schema 仍然是固定的大集合,但每条记录只存其中一部分。
可以理解成:
- wide column 更偏“逻辑上字段可变”
- sparse column 更偏“物理上允许大而稀疏的列集合”
这两种方法本质上都在缓解传统关系模型“列太刚性”的问题。
Multivalued / Nested Data Types
半结构化数据还常支持:
setmultisetmaparray- 嵌套对象
map(key-value map)
例如:
{(brand, Apple), (ID, MacBook Air), (size, 13), (color, silver)}支持操作:
put(key, value)get(key)delete(key)
这类结构很适合“属性名本身也比较动态”的场景。
array
例如监测数据:
[5, 8, 9, 11]可以替代:
{(1,5), (2,8), (3,9), (4,11)}当时间点是规则采样、索引天然有序时,数组表示会更自然,也更高效。
array database
有些数据库专门为数组做优化,称为 array database。
适合:
- 科学计算
- 遥感数据
- 规则采样监测数据
例子包括:
Oracle GeoRasterPostGISSciDB
XML
XML 的基本思想
XML(Extensible Markup Language)用 tag 来标记数据。
示例:
<course> <course_id>CS-101</course_id> <title>Intro. to Computer Science</title> <dept_name>Comp. Sci.</dept_name> <credits>4</credits></course>XML 的关键特点:
- self-documenting:标签本身就说明语义
- 可层次化嵌套
- 适合表达树形结构
purchase order 例子
<purchase_order> <identifier>P-101</identifier> <purchaser> <name>Cray Z. Coyote</name> <address>Route 66, Mesa Flats, Arizona 86047, USA</address> </purchaser> <supplier> <name>Acme Supplies</name> <address>1 Broadway, New York, NY, USA</address> </supplier> <itemlist> <item> <identifier>RS1</identifier> <description>Atom powered rocket sled</description> <quantity>2</quantity> <price>199.95</price> </item> <item>...</item> </itemlist> <total_cost>429.85</total_cost> ...</purchase_order>purchase_order:
- 顶层有订单标识
purchaser/supplier是嵌套对象itemlist下面又有多个item
这就是 XML 很典型的使用方式:
- 把一个业务对象打包成一个树
- 子对象直接嵌在父对象下面
再结合代码按层次读一遍,会更清晰:
- 根节点
<purchase_order>:代表“一张订单文档”。 <identifier>:订单号,值是P-101。<purchaser>:购买方对象。<supplier>:供应方对象。<itemlist>:商品明细集合。<item>:一行明细,里面包含商品编号、描述、数量和单价。<total_cost>:订单总金额。
可以把它看成一个小型对象模型:
PurchaseOrder├── identifier: string├── purchaser: Party(name, address)├── supplier: Party(name, address)├── itemlist: Item[]└── total_cost: decimal这个例子最重要的点是:
purchaser和supplier这类“复合属性”在 XML 里天然就是子树。itemlist是“多值属性”,在 XML 里天然对应多个<item>子节点。- 如果用纯 1NF 平铺成关系表,通常要拆多张表(订单头、订单行、客户、供应商)再 join;但 XML 可以把它作为一份完整业务文档一起传输。
XPath / path expressions
<bookstore> <book category="COOKING" ISBN="100-10-00"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN" ISBN="10000-100-199"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> <publisher>ABC</publisher> <edition>5</edition> </book> <book category="WEB" ISBN="10000-10-09"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB" ISBN="999-11-09"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book></bookstore>例如在书店 XML 中:
bookstore/bookbookstore/book[1]/titlebookstore/book[price>30]/titlebookstore/book[1]/title/text()
把每条 XPath 对照到上面的 XML,结果分别是:
bookstore/book
- 含义:选中
bookstore下所有book元素。 - 命中:4 本书(COOKING、CHILDREN、WEB、WEB)。
bookstore/book[1]/title
- 含义:先取第 1 本书,再取它的
title元素。 - 结果:
<title lang="en">Everyday Italian</title>bookstore/book[price>30]/title
- 含义:筛选
price大于 30 的书,再取标题。 - 命中:
<title lang="en">XQuery Kick Start</title><title lang="en">Learning XML</title>bookstore/book[1]/title/text()
- 含义:取第 1 本书标题节点中的纯文本值。
- 结果:
Everyday Italian
从这四条可以总结 XPath 的常用模式:
- 路径选择:
A/B/C - 位置过滤:
[1] - 条件过滤:
[price>30] - 取文本:
text()
再补两条高频写法:
bookstore/book[@category='WEB']/title- 通过属性过滤,选类别为 WEB 的图书标题。
bookstore/book[author='J K. Rowling']/price/text()- 先按作者过滤,再取价格文本。
这些表达式说明:
- 可以按路径走到元素
- 可以带位置条件
- 可以带谓词过滤
- 可以取文本内容
这和后来 JSON 的路径表达式思路是相通的。
Tree model of XML documents

DTD
DTD(Document Type Definition):
<!DOCTYPE bookstore [ // 这份 DTD 约束的根元素是 bookstore <!ELEMENT bookstore ((book)+)> // 根节点下必须出现 1 个或多个 book(+ 表示至少 1 次) <!ELEMENT book (title,author+,year,price,publisher*,edition*)> // 每个 book 的子元素顺序固定: // title -> author(1+) -> year -> price -> publisher(0+) -> edition(0+)
<!ELEMENT title (#PCDATA)> // title 只能是文本 <!ELEMENT author (#PCDATA)> // author 只能是文本 <!ELEMENT year (#PCDATA)> // year 只能是文本 <!ELEMENT price (#PCDATA)> // price 只能是文本
<!ATTLIST book category CDATA #REQUIRED ISBN ID #REQUIRED> // book 必须有 category 和 ISBN 两个属性: // category: 任意字符串(CDATA) // ISBN: ID 类型(要求文档内唯一,且满足 XML ID 命名规则)
<!ATTLIST title lang CDATA #REQUIRED> // title 必须带 lang 属性,例如 <title lang="en">...]>DTD 的作用是:
- 描述 XML 文档允许的结构
- 约束元素出现顺序和次数
- 约束属性
可以把这段 DTD 理解为“bookstore 文档的类型签名”:
- 元素类型:允许哪些标签
- 结构类型:标签出现顺序和次数
- 属性类型:每个标签必须带哪些属性、属性取值类型是什么
TIP
ISBN被声明为ID时,值要满足 XML Name 规则且全局唯一。像100-10-00这类以数字开头的值在严格 XML DTD 校验下通常不合法。实务中常见做法:
- 把
ISBN改为CDATA;或- 保持
ID,但把值写成如isbn100-10-00这类以字母开头的标识。
也就是:
给“灵活的 XML”再补一层结构规则。
XQuery
XQuery 用来查询嵌套 XML 结构。
例如下面这条查询,会找出“第一作者相同,但价格更高”的书籍配对:
<book_pairs>{ for $a in /bookstore/book, $b in /bookstore/book where $a/author[1] = $b/author[1] and $a/price > $b/price return <book_pair> <first_author>{data($a/author[1])}</first_author> {$a/title} {$b/title} </book_pair>}</book_pairs>按语句拆开看:
for $a ... , $b ...:把每本书和每本书做两两组合(可理解为自连接)。$a/author[1] = $b/author[1]:只保留“第一作者相同”的组合。$a/price > $b/price:在同一作者内部,保留价格更高的那本作为a。return <book_pair> ...:输出配对结果,包含:- 第一作者名
- 价格较高那本的标题(
$a/title) - 被比较的较低价标题(
$b/title)
这条查询体现了 XQuery 的三个核心能力:
- 在 XML 树上做迭代(for)
- 做条件过滤(where)
- 构造新的 XML 结果(return)
JSON
JSON 的基本结构
JSON(JavaScript Object Notation)是今天最常见的轻量级数据交换格式。
{ "ID": "22222", "name": { "firstname": "Albert", "lastname": "Einstein" }, "deptname": "Physics", "children": [ {"firstname": "Hans", "lastname": "Einstein"}, {"firstname": "Eduard", "lastname": "Einstein"} ]}JSON 支持:
stringintegerrealbooleannullobjectarray
其中:
- object:本质是 key-value map
- array:本质是从 offset 到 value 的映射
SQL 对 JSON 的支持
现代数据库通常会扩展:
- JSON 类型存储
- JSON 路径提取
- 从关系数据生成 JSON
- 聚合成 JSON 数组 / 对象
Example:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, info JSON);
INSERT INTO users(info)VALUES('{"name":"Alice", "age":30}');
SELECT *FROM usersWHERE info->'$.age' > 28;
UPDATE usersSET info = JSON_SET(info, '$.age', 31)WHERE id = 1;还可以:
json_build_object(...)json_agg(...)
不同数据库语法差异比较大,但思路差不多。
JSON 的一个缺点
JSON 比较 verbose。
所以很多系统内部会用更紧凑的二进制表示,例如:
- BSON(Binary JSON)
RDF 与 Knowledge Graph
RDF
RDF(Resource Description Framework)是知识表示里非常重要的一种形式。
它把事实表示成 triple(三元组):
(subject, predicate, object)例如:
(NBA-2019, winner, Raptors)(Washington-DC, capital-of, USA)(Washington-DC, population, 6200000)RDF 和 E-R 的关系
RDF 的思想和 E-R 模型很像:
- 对象有属性
- 对象之间有关系
但 RDF 更灵活:
- 不强制一个固定 schema
- 一切都拆成边
- 天然适合图表示
所以可以把 RDF 看成:
图化、极简化、更加灵活的 E-R 表达。
Graph view 与 triple view
- Graph view
- 实体和值是节点
- 属性名 / 关系名是边
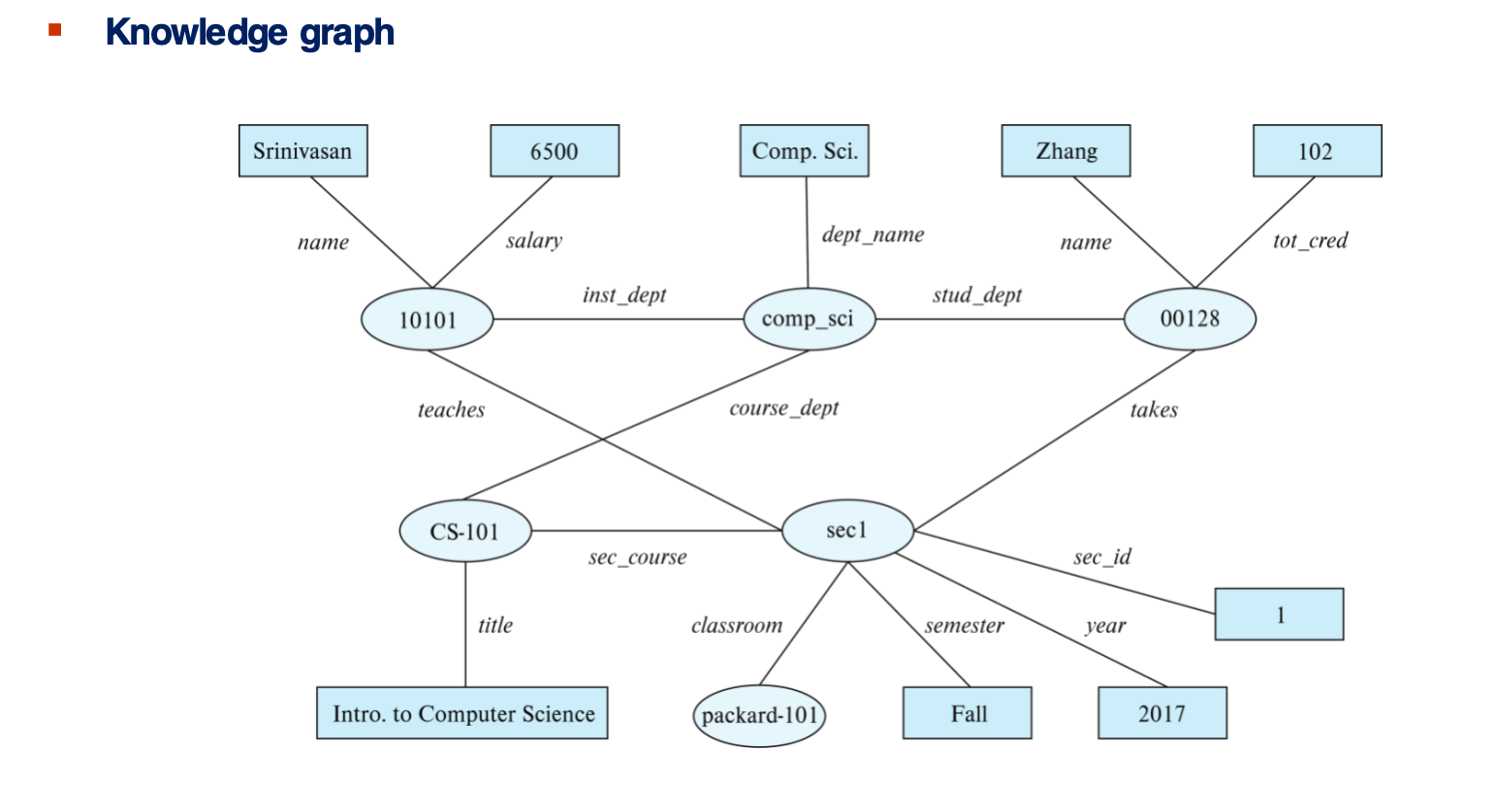
- Triple view
- 把整张图拆成很多
(subject, predicate, object)行
- 把整张图拆成很多
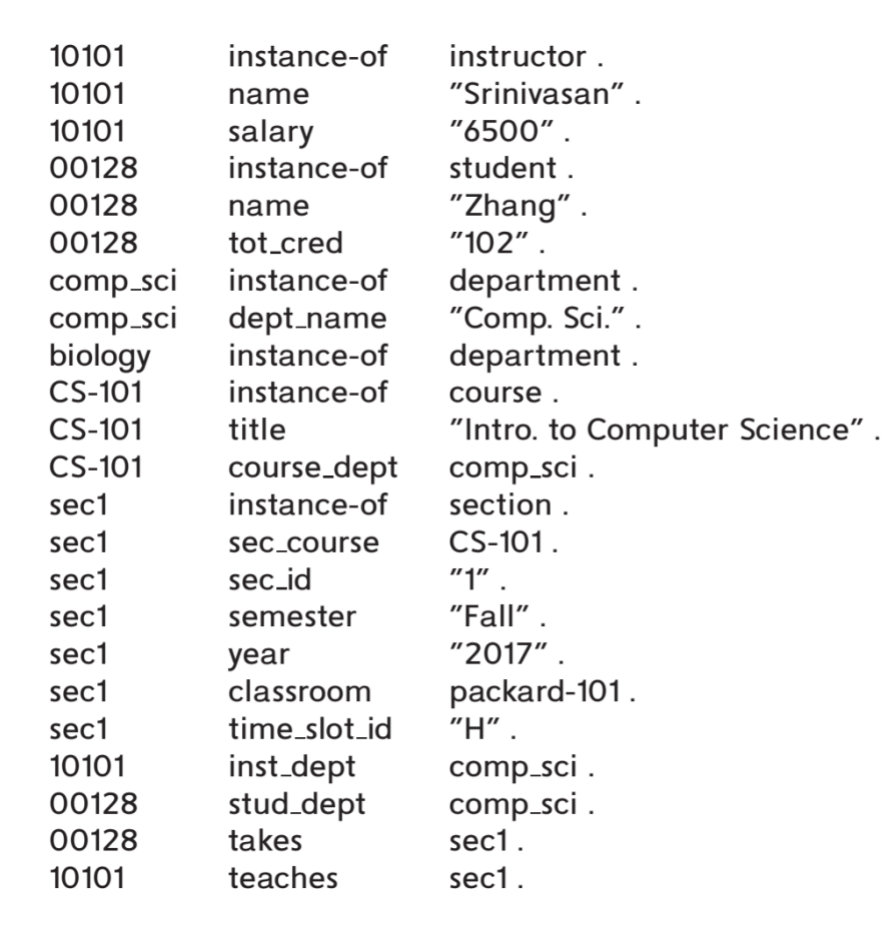
这两个视角本质等价:
- 图方便理解结构
- triple 方便存储与查询
SPARQL
SPARQL 是 RDF 的查询语言。
它的核心思想是:
- 写 triple patterns
- 让变量去匹配图中的边和节点
例如:
select ?namewhere { ?cid title "Intro. to Computer Science" . ?sid course ?cid . ?id takes ?sid . ?id name ?name .}这段查询的意思是:
- 找标题为
Intro. to Computer Science的课程 - 找到相关 section
- 找到选了该 section 的学生
- 返回这些学生的名字
在图上找一条满足模式的路径
RDF 如何表示 n-ary relationship
RDF 三元组只能直接表示二元关系。
那四元、五元关系怎么办?
两种办法。
引入人工实体
例如:
(Barack Obama, president-of, USA, 2008-2016)可以改写成:
(e1, person, Barack Obama)(e1, country, USA)(e1, president-from, 2008)(e1, president-till, 2016)本质上和 E-R 里“把 n 元联系变成一个实体集”是同一个思路。
使用 quads
例如:
(Barack Obama, president-of, USA, c1)(c1, president-from, 2008)(c1, president-till, 2016)这里 c1 就是上下文实体。
Textual Data
Information Retrieval 的基本目标
文本数据和普通结构化数据不一样。
在文本检索里,用户通常并不是要“满足精确条件的全部元组”,而是:
给我一批 最相关(most relevant) 的文档。
所以 Information Retrieval(IR) 和数据库查询最大的差别之一是:
- 传统关系查询追求 精确匹配
- 文本检索追求 相关性排序(relevance ranking)
简单 keyword query
最简单模型:
- 输入若干关键词
- 返回包含这些关键词的文档
例如:
- 查询
cricket - 返回和板球比赛相关的新闻、比分、赛程等
但光“是否包含关键词”显然不够。
所以真正重要的是:
- 哪些文档更相关
- 谁排前面
TF / IDF / relevance
Term
Term 就是出现在文档 / 查询中的关键词。
Term Frequency(TF)
其中:
n(d,t):termt在文档d中出现次数n(d):文档d的 term 总数- 某词在文档里出现越频繁
- 这个词越可能是该文档的重要主题
Inverse Document Frequency(IDF)
其中:
n(t):包含 termt的文档数- 如果一个词几乎所有文档都有,比如 “the”、“is”
- 它对区分文档没什么帮助
- 越稀有的词,区分能力越强
Relevance
即:
- 查询
Q中每个词对文档d的贡献加起来 - 文档里常出现
- 但在整个文档集合里又不太常见
- 这种词最有区分力
Stop words 与 proximity
- stop words 常被忽略
- 词语之间的 proximity(接近程度) 也会影响相关性
例如:
- 查询
database system - 两词紧挨着出现,通常比相距很远更相关
PageRank
仅靠文本内容还不够。
网页时代还会利用链接结构来判断“重要性”。
- 一个页面被很多页面链接,可能更重要
- 被重要页面链接,也会更重要
这就是 PageRank 的基本思想。
- 设
T[i,j]是随机游走者从页面i点到j的概率 - 如果页面
i有N_i个外链,则通常:
PageRank 定义为:
其中:
N:总页面数\delta:阻尼系数,常取0.15
还有:
- anchor text 里的关键词
- 用户点击行为
所以现实中的 relevance ranking 通常是多信号融合的。
Precision / Recall
检索系统常用两个指标衡量效果:
Precision
返回结果里,有多少比例是真的 relevant。
Recall
所有 relevant 结果里,有多少被系统找回来了。
这两个指标常互相拉扯:
- 返回得很少但很准,precision 高
- 返回得很全,recall 高
precision@10recall@10意思是只看前 10 个答案时的表现。
Structured Data 上的 Keyword Query
关键词检索不只可以用于纯文本,也可以用于:
- 结构化数据
- 知识图谱
适用场景:
- 用户不知道 schema
- 或者根本没有预定义 schema
Example
在 university 数据库中查询:
Zhang Katz系统可以:
- 找到匹配
Zhang的学生 - 找到匹配
Katz的教师 - 再找到连接他们的
advisor关系
于是返回“彼此连接紧密的一组元组 / 节点”。
这已经不是普通 SQL 的精确条件查询了, 而更像:
在结构化图上做关键词驱动的连接搜索。
Spatial Data
Geographic Data vs Geometric Data
空间数据库管理的是与位置有关的数据。
Geographic data
地理数据,关注真实地球上的位置。
例如:
- 路网图
- 土地利用图
- 地形高程图
- 行政区划图
- 土地所有权图
常用坐标:
(latitude, longitude, elevation)
典型系统:
- GIS(Geographic Information System)
Geometric data
几何数据,更偏人工设计对象。
例如:
- 建筑设计
- 飞机设计
- 集成电路布局
常在二维 / 三维欧氏空间中表示:
(X, Y)(X, Y, Z)
基本空间对象表示
line segment
线段可由两个端点坐标表示。
polyline / linestring
由一串相连的线段组成。
polygon
多边形由按顺序排列的一串顶点表示。
含义:
- 顶点序列定义边界
- 围成一个区域
还可以把 polygon 分解成若干三角形,也就是 triangulation(三角剖分)。
3D object
三维空间里:
- 点会多一个
z分量 - 多面体可拆成四面体
- 或直接列出各个面及其内外侧方向
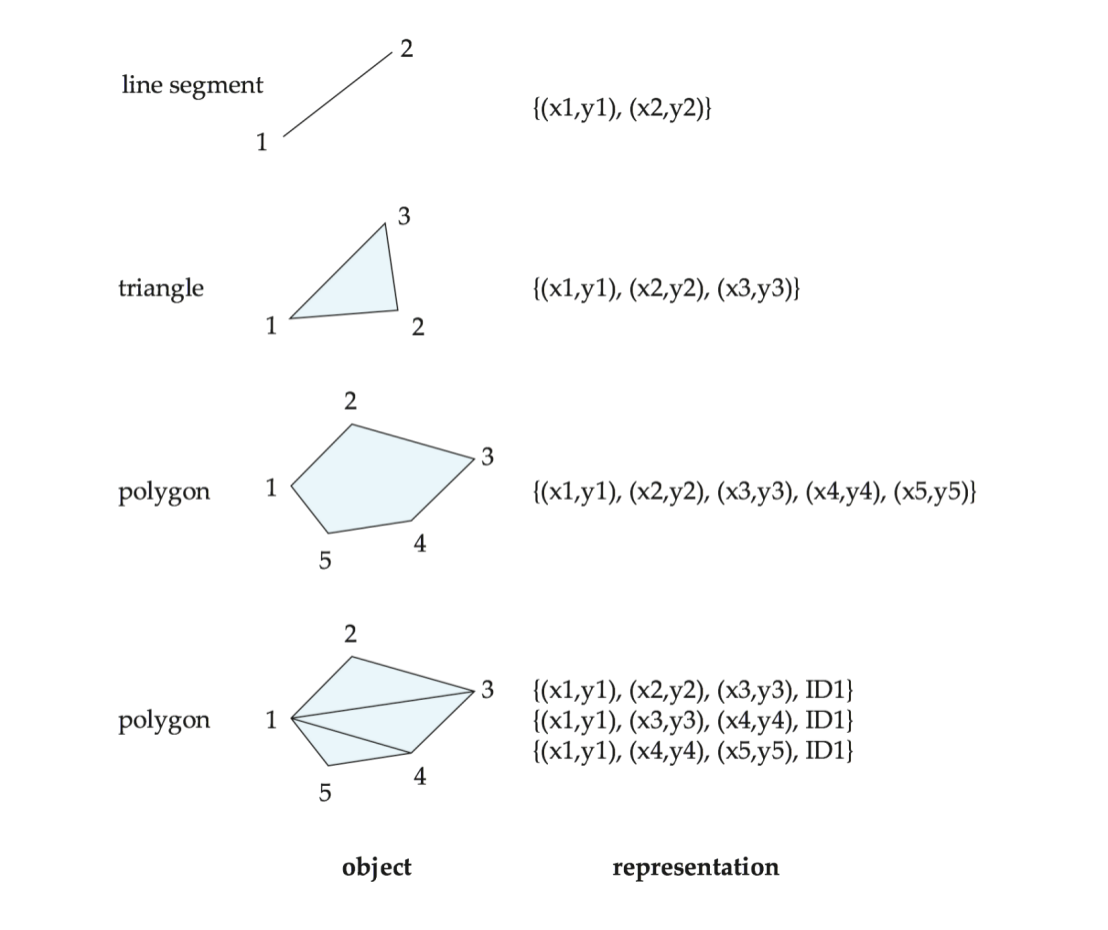
数据库中的空间类型与操作
很多数据库已经原生支持:
pointlinestringcurvepolygonmultipointmultilinestringmulticurvemultipolygon
例如:
LINESTRING(1 1, 2 3, 4 4)POLYGON((1 1, 2 3, 4 4, 1 1))常见函数:
ST_GeometryFromText()ST_GeographyFromText()ST_Union()ST_Intersection()ST_Contains()ST_Overlaps()
典型系统:
SQL ServerPostGIS
设计型空间数据库(CAD)
对设计型数据库来说,几何对象本身就是主要数据。
简单对象
- 点
- 线
- 三角形
- 矩形
- 多边形
复杂二维对象
由简单对象通过以下运算构成:
- union
- intersection
- difference
复杂三维对象
由更简单的三维几何体构成:
- sphere
- cylinder
- cuboid
再通过:
- union
- intersection
- difference
组合出来。
wireframe model
三维表面还可用更简单对象集合来表示,称为 wireframe model。
非空间属性
设计数据库通常还会存:
- 材料
- 颜色
- 构造属性
所以它不是“只有几何”,而是“几何 + 工程语义”。
空间完整性约束
空间对象之间常有特殊约束:
- 管道不能相交
- 电线不能过近
这类约束不是普通主键 / 外键能表达的。
它们是 spatial integrity constraints。
Raster Data vs Vector Data
Raster data
栅格数据,本质上是位图 / 像素图。
例如:
- 云层卫星图
- 遥感影像
- 多高度、多时刻的测量网格
特点:
- 每个像素 / 单元格存一个值
- 适合连续场信息
Vector data
矢量数据由基本几何对象组成:
- 点
- 线段
- 三角形
- 多边形
- 三维中的圆柱、球、长方体、多面体等
地图里常见表示:
- 道路:线 / 曲线
- 湖泊 / 区域:多边形
- 河流:线或多边形,取决于是否关心宽度
简单区分:
- Raster:像“很多格子”
- Vector:像“几何对象集合”
常见空间查询
Region query
问某个区域里有哪些对象。
例如:
- 找出某区域内的学校
- 找出某行政区覆盖的道路
Nearness query
问某位置附近有哪些对象。
例如:
- 离某点最近的餐馆
Nearest neighbor query
在满足条件的对象里找最近那个。
例如:
- 最近的、且价格低于 10 美元、并且有素食选项的餐馆
Spatial graph query
空间图查询,基于道路网、铁路网等图结构。
例如:
- 求两地间最短路径
Spatial join
两张空间关系按空间条件连接。
例如:
- 找所有相交的区域对
- 人口密度图和降雨图按区域交叠来 join
本质上:
- 普通 join 用等值 / 比较条件
- spatial join 用的是
contains、overlaps、intersects等空间谓词