

概述
这一章的核心是:
从 E-R 设计 走到 关系模式 之后,问题还没有结束。
你还要继续判断这些表是不是“设计得好”。
判断的标准,核心看三件事:
- 有没有 信息重复(redundancy)
- 分解之后能不能 无损恢复(lossless join)
- 分解之后能不能 保持依赖(dependency preserving)
本质上讲的是 关系模式层的结构优化理论。
Chapter 6 解决的是:
- 现实世界怎么抽象成实体、联系、约束
- E-R 图怎么规约成关系模式
Chapter 7 解决的是:
- 已经得到的关系模式,怎样判断它是不是“坏设计”
- 如果它有问题,怎样用 functional dependency / multivalued dependency 去分解
- 如何在 BCNF / 3NF / 4NF 等不同目标之间做权衡
所以
- Chapter 6:先把表设计出来
- Chapter 7:再把表设计对
目录
- 概述
- 目录
- Features of Good Relational Design
- Atomic Domains and First Normal Form
- Functional Dependencies
- Functional-Dependency Theory
- Canonical Cover
- BCNF
- Third Normal Form (3NF)
- Multivalued Dependencies and 4NF
- More Normal Forms
- Database-Design Process Revisited
- Modeling Temporal Data
Features of Good Relational Design
一个关系模式设计得好,通常至少要满足:
- 不重复存同一事实
- 插入、删除、更新都不会很别扭
- 分解后还能正确拼回去
- 重要约束最好能在单表上检查,而不是每次都 join
这一章里最核心的坏设计有三个:
- Information repetition:同一信息在很多元组里重复出现。
- Insertion anomalies:想录入一个事实,却被迫顺带录入别的事实。
- Update difficulty / update anomalies:修改一个事实时,要改很多地方,一旦漏改就不一致。
坏设计的核心
大学数据库的 E-R 图:
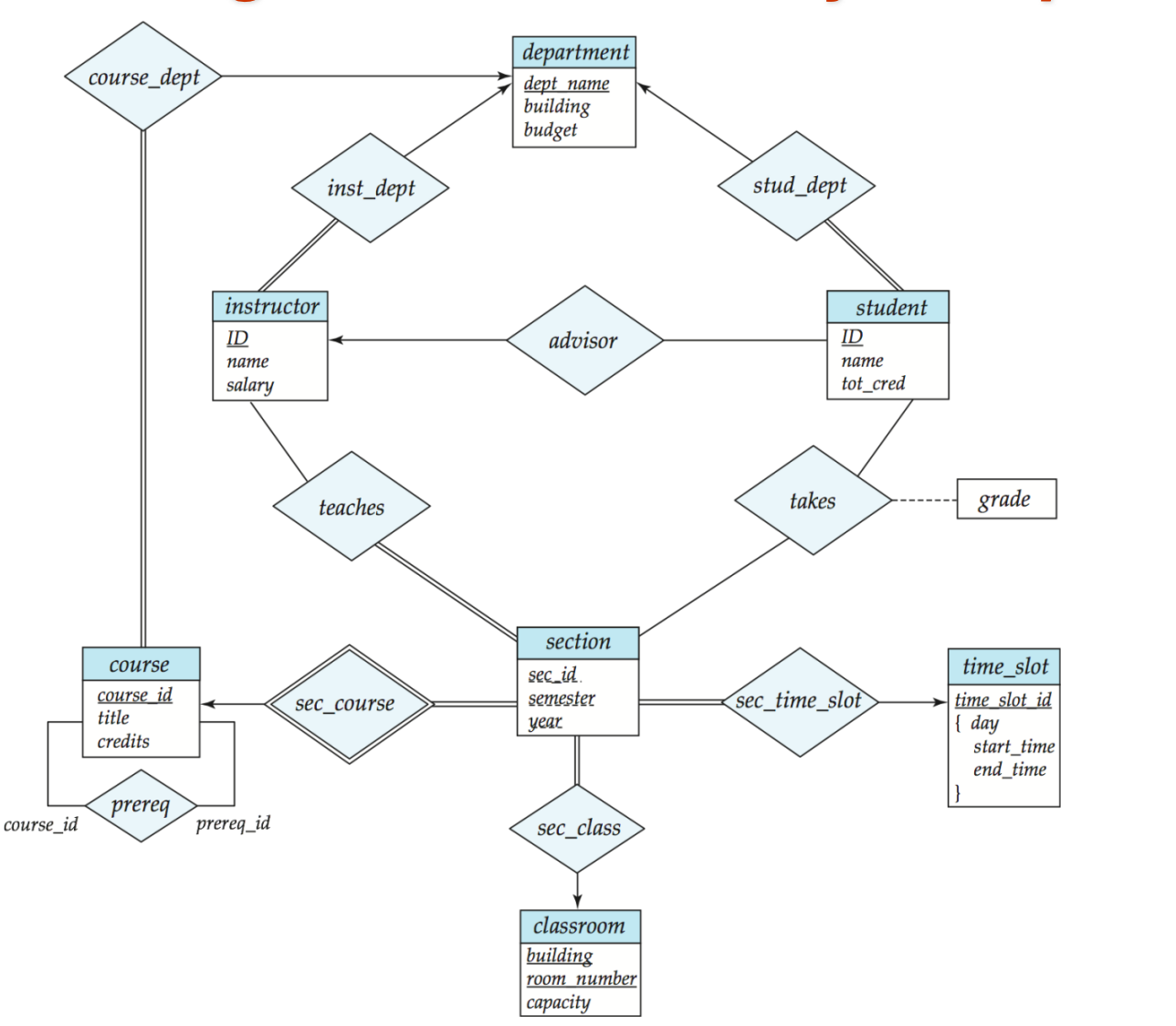
规约后的关系模式:
这里每个实体的_abc_共同构成Primary Key。
classroom(_building_, _room_number_, capacity)department(_dept_name_, building, budget)course(_course_id_, title, dept_name, credits)instructor(_ID_, name, dept_name, salary)section(_course_id_, _sec_id_, _semester_, _year_, building, room_number, time_slot_id)teaches(_ID_, _course_id_, _sec_id_, _semester_, _year_)student(_ID_, name, dept_name, tot_cred)takes(_ID_, _course_id_, _sec_id_, _semester_, _year_, grade)advisor(_s_ID_, i_ID)time_slot(_time_slot_id_, _day_, _start_time_, end_time)prereq(_course_id_, _prereq_id_)
提出三个问题:
- 能不能把
instructor和department合并? - 能不能把
instructor和teaches合并? - 能不能把
student拆成两个表?
坏设计的典型症状
例 1:把 instructor 和 department 合并成 inst_dept
假设合并成:
inst_dept(ID, name, salary, dept_name, building, budget)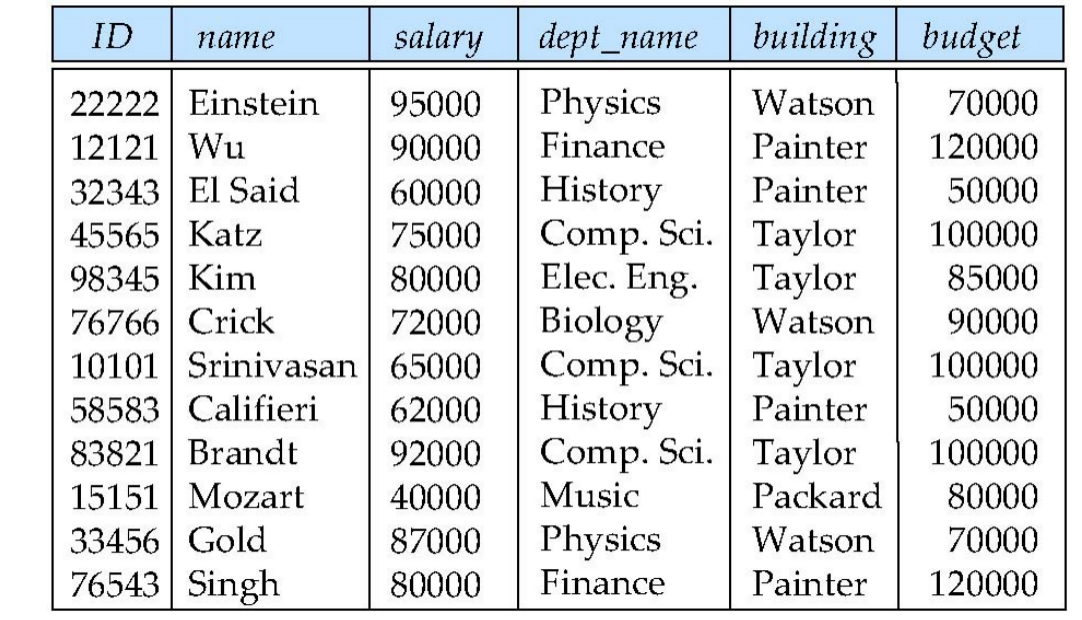
这时会出现什么?
- 每个 Physics 系老师那一行都会重复写一次
Watson, 70000 - 每个 Comp. Sci. 系老师那一行都会重复写一次
Taylor, 100000
于是部门信息被重复很多次。
这会直接导致:
- 信息重复:同一个系馆和预算在多行里重复
- 插入异常:如果新建一个系,但这个系还没有老师,你很难只插入 department 事实
- 更新困难:系预算改了,要改所有该系老师所在行
NOTE但是有一种合并是合理的
student(id, name, tot_cred)stud_dept(id, dept_name)如果合并成:
这里通常不会产生额外重复。
原因是:
- 一个学生只有一个
iddept_name只是这个学生的一个普通属性- 并没有“一个部门信息被很多学生行反复展开”的结构性重复问题
例 2:为什么会发生这种重复
如果我们知道:
以及
那么 dept_name 决定了 building, budget。
但在 inst_dept 里,dept_name 又不是整个表的候选键,于是同一个 dept_name 会在多行中反复出现,对应的 building, budget 也就被迫重复。
这正是:
非键属性决定别的非键属性 往往意味着要分解。
分解的核心是只留下key是决定作用,其他属性是可以被key决定的
例 3:employee 的 lossy decomposition
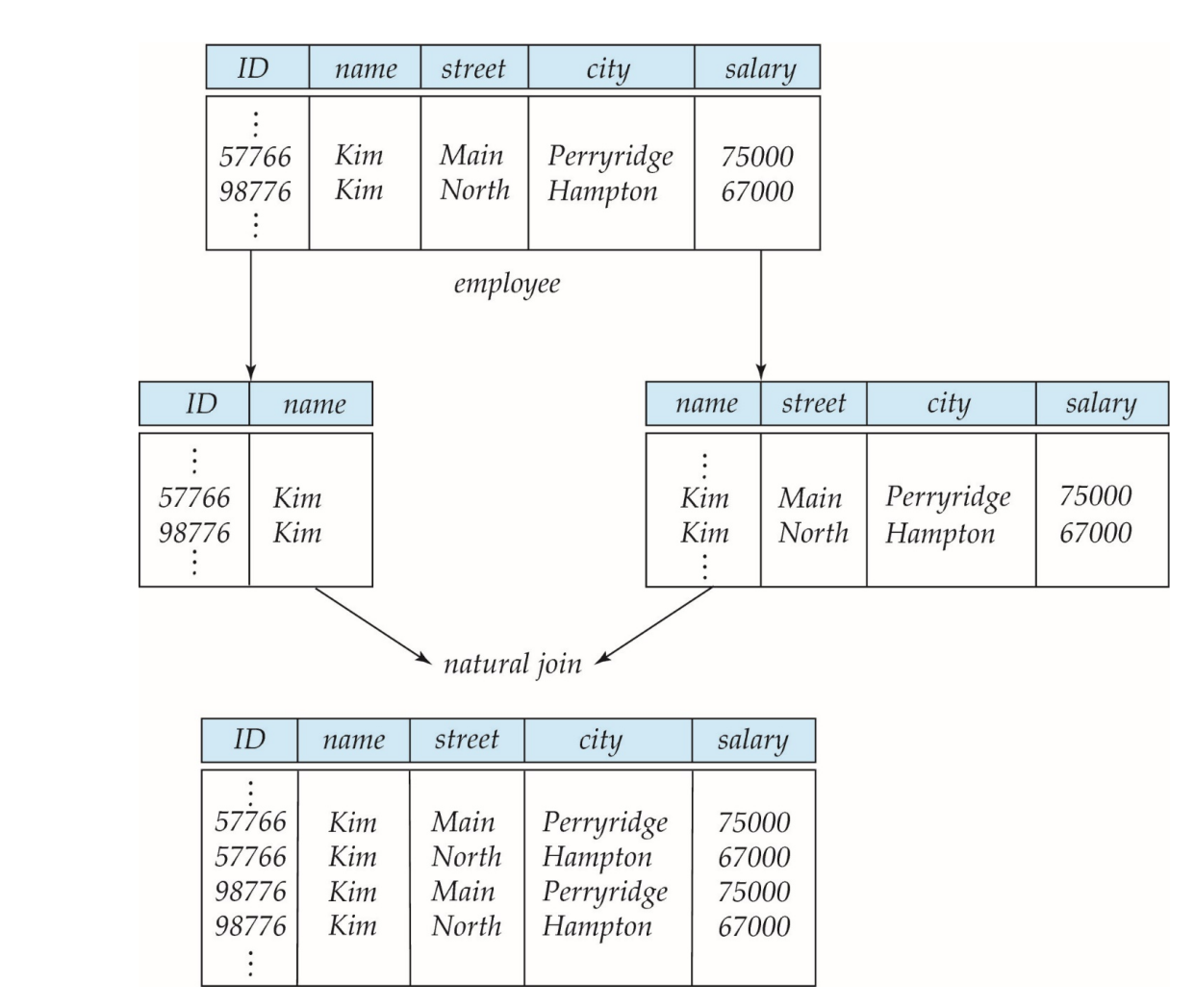
原关系:
employee(ID, name, street, city, salary)错误分解成:
employee1(ID, name)employee2(name, street, city, salary)看上去像是把身份信息和住址工资信息拆开了,但这是错的。为什么?
因为 name 不是唯一的。
如果有两个人都叫 Kim:
(57766, Kim, Main, Perryridge, 75000)(98776, Kim, North, Hampton, 67000)
分解后再自然连接,会得到四行组合,其中两行是假的:
- 57766 + Main + 75000
- 57766 + North + 67000 ← 假
- 98776 + Main + 75000 ← 假
- 98776 + North + 67000
这正是拆解之后key没有能够决定其他属性的现象。
分解之后 join 回来,比原表多了额外元组。
这类分解叫 lossy decomposition。
Lossless Join Decomposition
如果关系模式 被分解成 ,并且对任意合法实例 都有:
那么这个分解就是 lossless decomposition。

否则,如果:
那就是 lossy decomposition。
join 回来“元组变多”,代表信息反而变少了。 因为数据库不知道哪些组合是真的,只能把所有可能组合都算进去,不确定性增加了。
二元分解的无损判定条件
如果 被分解成 ,那么只要满足下面两条中的任意一条,就能保证无损:
或
直观理解:
- 两个子表公共部分,至少要能唯一决定其中一个子表
- 也就是公共属性必须像“连接锚点”一样可靠
经典例子:
如果有:
那么公共属性 能决定 ,分解无损。
Atomic Domains and First Normal Form
Atomic domain
一个域是 atomic,意思是:
它的值在当前数据库语义下,被当作不可再分的基本单位。
即:语义上不应该靠拆字符串来编码额外信息。
非原子域的典型例子
- 一组名字组成的集合
- 复合属性
- 看似字符串,实际内部编码了业务含义的编号
Example:
- 学号长这样:
CS0012或EE1127 - 如果你通过前两个字符去判断院系
那学号这个字段其实就不是原子的。
因为你把院系信息偷偷编码进字符串内部了。
这会带来一个问题:
部分业务语义被埋到应用程序字符串处理逻辑里,而不是显式存成数据库属性。
这通常是坏设计。
1NF
一个关系模式在 第一范式(1NF) 中,当且仅当:
所有属性的域都是 atomic domains。
所以 1NF 主要解决的是:
- 属性值该不该再拆
- 一列里能不能塞一个集合 / 复合对象 / 编码串
1NF 处理的是“属性值原子性”问题。
3NF / BCNF / 4NF 处理的是“依赖与冗余”问题。
可以把各个范式理解成一层层加强的“消冗余规则”:
- 1NF:每个属性值都必须是原子的
- 2NF:在 1NF 基础上,非主属性不能只依赖复合主键的一部分
- 3NF:在 2NF 基础上,非主属性不能传递依赖于主键
- BCNF:进一步加强,任何决定因素都必须是超键
- 4NF:再进一步,处理多值依赖造成的冗余
一个常见的包含关系是:
也就是说,后面的范式更严格。
Functional Dependencies
Legal instance
函数依赖讨论是:在所有符合业务规则的 legal instances 上,什么约束一定成立。
例如大学数据库里,常见约束有:
- 学生 ID 唯一标识学生
- 每个学生只有一个姓名
- 每个学生主要隶属于一个系
- 每个系只有一个 building 和一个 budget
这些业务规则,就是函数依赖背后的来源。
函数依赖的定义
设关系模式为 ,且 。
如果对任意合法关系实例 ,只要任意两个元组在 上相等,就一定在 上也相等,那么称:
在 上成立。
形式化写法:
α → β 的意思是:在这个业务世界里,α 的值一旦固定,β 的值就不能乱变。
Example:
表示:
- 一个系名确定后,它所在 building 唯一确定
Superkey 与 Candidate Key 的关系
Superkey
如果:
那么 是 的 superkey。
也就是:
- 能唯一标识整个元组
Candidate Key
如果 是 superkey,并且任何真子集都不是 superkey,那么 是 candidate key。
也就是:
- 既能唯一标识
- 又是最小的
关键关系:
- 键是一种特殊的函数依赖
- 函数依赖比键表达力更强
因为很多约束不是“标识整个元组”,而是“某些属性决定另一些属性”。
例如在:
inst_dept(ID, name, salary, dept_name, building, budget)里我们期望:
但不期望:
Trivial functional dependency
如果:
那么:
一定成立,这叫 trivial functional dependency。也就是右侧的属性,左侧全有了,那必然就是决定性。
例如:
ID, name → IDname → name
这类依赖不提供额外约束信息。
函数依赖比键更强:
键只能表达:
- 哪些属性唯一标识元组 但函数依赖还能表达:
- 哪些非键属性之间存在稳定决定关系 而数据库设计里最危险的冗余,恰恰经常来自:
- 一个非键属性决定另一个非键属性
例如:
这就是为什么规范化理论以函数依赖为核心。
Functional-Dependency Theory
Closure of F
给定函数依赖集 ,从 可以逻辑推出的所有函数依赖构成 closure of F,记为:
例如:
那么可以推出:
所以 。
Armstrong’s Axioms
Armstrong 公理是函数依赖推理的基础规则。
1. Reflexivity(自反)
如果:
则:
2. Augmentation(增补)
如果:
则:
3. Transitivity(传递)
如果:
则:
这三条规则是:
- sound:不会推出假的 FD
- complete:能推出所有真的 FD
Example
对于:
可以推出:
- :因为 且
- :先由 增补得到 ,再结合
- :,,再传递得到 。
Additional Rules
这几条常用规则都能由 Armstrong 公理推出。
1. Union
如果:
则:
推导过程:
2. Decomposition
如果:
则:
推导过程:
3. Pseudotransitivity
如果:
则:
推导过程:
Exercise 1:
在关系模式 上,若函数依赖成立,证明它与等价。也就是说,函数依赖右侧的重复属性可以去掉。
证明:
先证:
由反身性(Reflexivity),有:
再由传递性(Transitivity):
再证:
由反身性可得:
由并规则(Union):
两边都成立,因此:
证毕。
Attribute Closure
给定属性集 ,在 下由它能决定的所有属性集合,记为:
计算算法
result := αwhile result 还在变化: 对每个 β → γ in F: 如果 β ⊆ result: result := result ∪ γExample
Example 1
对:
有:
Example 2
对于:
计算 :
- 初始:
AG - 由 与 得:
ABCG - 因为有
CG,由 得:ABCGH - 再由 得:
ABCGHI
所以:
如果这已经包含了 的全部属性,那么 AG 就是 superkey。
再进一步检查其真子集是否还是 superkey,就能判断是不是 candidate key。
Attribute Closure 的用途
1. 测试 superkey
判断 是否为 superkey,只要看:
是否成立。
2. 测试函数依赖是否成立
判断:
是否在 中,只要看:
是否成立。
3. 枚举 closure of F
理论上可以对每个属性子集 算 ,进而得到完整的 。
但这通常代价很高,所以实际更常做局部判断。
计算属性闭包和函数依赖闭包:

Canonical Cover
-
依赖本身冗余:某条 FD 能由其他 FD 推出。
例如在 中,A \to C是冗余依赖,因为它可由A \to B与B \to C传递推出。 -
依赖内部属性冗余:某条 FD 的左侧或右侧有多余属性。
-
例如在 中,右侧的
C可删,得到等价集合 ;
因为 ,再与 用 union 可得 。 -
又如在 中,左侧的
C可删,得到等价集合 ;
因为 ,从而 ,结合 得 ;反过来由增补可得 。
-
canonical cover :与原 FD 集等价的“最简集合”,既没有冗余依赖,也没有依赖内部的冗余属性。
Extraneous Attribute
如果一个函数依赖中的某个属性删掉以后,整个依赖系统表达的约束不变,那么这个属性就是 extraneous。
分两种情况。
1. 左边多余:
在 中,若 ,并且:
仍与原来等价,那么 在左边是多余的。
例子:
这里 AB → C 里的 B 是多余的,因为 A → C 已经够了。
2. 右边多余:
在 中,若 ,删掉它以后其余 FD 仍能推出原来的全部依赖,
那么 在右边是多余的。
例子:
这里 AB → CD 里的 C 是多余的,因为 AB → C 可从 A → C 推出。
Canonical Cover 的定义
函数依赖集 的 canonical cover,记作 ,满足:
- 与 逻辑等价
- 中没有 extraneous attributes
- 每个左部唯一
canonical cover 就是与原依赖集等价、但尽量精简的版本。
计算思路:
- 先用 union 把左边相同的 FD 合并。
- 检查左右两边是否有多余属性。
- 删除冗余依赖。
- 循环直到不再变化。
Example
Example 1
给定:
步骤:
A → BC和A → B合并后还是A → BCAB → C里A多余,因为B → C已经在- 得到:
A → BC的右边C也多余,因为A → B且B → C可推出A → C
最终 canonical cover:
Example 2
对于:
可以化简得到:
再算:
候选键是:
BCNF
BCNF 定义
关系模式 关于函数依赖集 属于 Boyce–Codd Normal Form (BCNF),如果对所有属于 的函数依赖:
都满足下面至少一个条件:
- 该依赖是 trivial 的,即
- 是 的 superkey
BCNF 的意思:每个“真正有约束力”的决定因素,都必须是超键。
反例:inst_dept
inst_dept(ID, name, salary, dept_name, building, budget)因为:
而 dept_name 不是 superkey,所以它不在 BCNF。
BCNF 分解思路
如果某个非平凡 FD:
违反 BCNF,那么把 分成:
例如对于 inst_dept:
于是分解成:
(dept_name, building, budget)(ID, name, salary, dept_name)
这正对应 department 与 instructor。
BCNF 分解算法
result := {R}done := falsewhile not done: 如果 result 中有某个 Ri 不在 BCNF: 选一个在 Ri 上成立且违反 BCNF 的非平凡 FD α → β, 满足 α+ 不包含 Ri,且 α ∩ β = ∅ result := (result - Ri) ∪ (Ri - β) ∪ (α, β) 否则 done := true要点:
- 每一步分解都保证 lossless join
- 但不保证 dependency preserving
Example
给定:
候选键:
A+ = ABCD- 所以候选键是
A
分解:
因为:
且 B 不是 superkey,所以违反 BCNF。
分解为:
R1(B,C,D)R2(A,B)
其中:
R1中B是键R2中A是键
所以二者都在 BCNF。
并且无损,因为交集是 B,且:
也就是 B 是 R1 的候选键。
Dependency Preserving
如果一个分解 ,令 表示 在 上的限制,那么若:
则这个分解是 dependency preserving。
意思是:
- 原来所有函数依赖,都能只靠子表中的依赖推出
- 不需要把子表 join 起来才能检验约束
这在实际系统里很重要,因为:
跨表 join 去检查更新是否合法,代价通常比较高。
BCNF 与依赖保持的冲突
Example 1:同一个关系的两种 BCNF 分解
给定:
候选键是 A,原关系不在 BCNF。
分解一
R1(A,B)R2(B,C)
这是:
- lossless
- dependency preserving
- 且两表都在 BCNF
分解二
R1(A,B)R2(A,C)
这也是:
- lossless
- 两表都在 BCNF
但它不 dependency preserving,因为 B → C 无法只从子表依赖推出。
Example 2:存在保持依赖的 BCNF 分解,但标准 BCNF 分解算法未必得到
给定:
先求 candidate key。
由于 A 和 E 从未出现在任何函数依赖的右边,因此任何 candidate key 都必须包含 A 和 E。又因为:
所以候选键为:
AE
原关系不属于 BCNF,因为:
A \to B中,A不是 superkeyB \to CD中,B不是 superkeyE \to D中,E不是 superkey
分解一:标准算法可能得到的 BCNF 分解
R1(B,C,D)R2(A,B)R3(A,E)
这个分解满足:
- lossless-join
- 每个子关系都在 BCNF
但它不是 dependency preserving,因为:
无法从各子关系的依赖中推出。各子关系上的依赖为:
R1上:B -> CDR2上:A -> BR3上:没有关于D的依赖
因此 E -> D 丢失。
分解二:保持依赖的 BCNF 分解
R1(B,C,D)R2(A,B)R3(E,D)R4(A,E)
这个分解满足:
- lossless-join
- dependency preserving
- 每个子关系都在 BCNF
原因如下:
-
BCNF
R1(B,C,D)中,B -> CD,而B是该关系的 keyR2(A,B)中,A -> B,而A是该关系的 keyR3(E,D)中,E -> D,而E是该关系的 keyR4(A,E)中不存在非平凡函数依赖,因此也属于 BCNF
-
dependency preserving 原始依赖都可以在某个单独子关系中直接检查:
A -> B在R2(A,B)中B -> CD在R1(B,C,D)中E -> D在R3(E,D)中
-
lossless-join 因为
R4(A,E)包含原关系的 candidate keyAE,所以该分解是无损连接的。
这个例子说明:
同一个关系可能既存在
- 不保持依赖的 BCNF 分解
- 也存在保持依赖的 BCNF 分解
但要注意:
标准 BCNF decomposition algorithm 通常只能保证
- 分解后各子关系属于 BCNF
- 分解是 lossless-join
但不能保证得到 dependency-preserving 的那个版本。
所以:
- “存在 dependency-preserving 的 BCNF 分解”
- 和“标准 BCNF 分解算法一定能产生它”
是两件不同的事。
Example 3:有些关系根本做不到“既 BCNF 又依赖保持”
给定:
有两个候选键:
JKJL
这个关系不在 BCNF。
如果分解为:
R1(L,K)R2(J,L)
则会丢失依赖:
这个例子里,任何 BCNF 分解都无法保持所有依赖。
这正是 3NF 出场的动机。
Third Normal Form (3NF)
BCNF 很干净,但有时太严格。
有些场景中我们更关心:
- 更新时能不能高效检查依赖
- 能不能保证分解后依赖保持
于是定义一个稍微放松一点的范式:3NF。
它允许少量冗余,换来:
- 一定能构造出 lossless + dependency-preserving 的分解
3NF 定义
关系模式 在 3NF 中,如果对所有属于 的依赖:
至少满足以下一个条件:
- 是 trivial 的
- 是 superkey
- 中每个属性,都属于某个 candidate key
第三条就是对 BCNF 的最小放松。
关系:
- BCNF 一定属于 3NF
- 3NF 不一定属于 BCNF
Example
Example 1:dept_advisor
关系:
dept_advisor(s_ID, i_ID, dept_name)函数依赖:
候选键有两个:
(s_ID, dept_name)(i_ID, s_ID)
为什么它在 3NF:
- :左边是 superkey
- :右边的
dept_name属于候选键(s_ID, dept_name)
所以它满足 3NF。
但它未必在 BCNF,因为 i_ID 本身不一定是 superkey。
Example 2:3NF 也可能仍有冗余
它可以在 3NF,但仍会有:
- 信息重复
- 某些事实需要用
null表示
所以:
3NF 是折中,不是彻底消除冗余。
3NF Synthesis Algorithm
3NF 的构造法依赖 canonical cover。直接根据函数依赖去“合成”一组关系模式。
- 让每条重要依赖都能落在某一个关系里
- 从而尽量保证 dependency preserving
- 同时再补上 candidate key,保证 lossless join
算法思路:
-
先求
也就是先求函数依赖集 的 canonical cover。
这一步的作用是先把依赖集整理成一个“精简但等价”的版本,避免后面因为冗余依赖而生成重复或不必要的关系模式。 -
对 中每个依赖 ,建立一个关系模式
这一步的含义是:
如果 能决定 ,那就把它们放进同一个关系中。
这样这条依赖就能在单个关系里被直接检查,而不需要通过 join 多个关系才能验证。
这正是 dependency preserving 的关键来源。 -
如果当前没有任何一个模式包含原关系的 candidate key,则额外加入一个候选键关系
前两步按依赖生成的关系,不一定会自动包含原关系的某个候选键。
如果分解后的关系中没有任何一个关系包含 candidate key,就可能无法保证无损连接。所以这里要额外检查:
- 是否已经有某个关系包含原关系的 candidate key
- 如果没有,就专门加入一个“候选键关系”
这样做是为了保证整个分解是 lossless join。
-
可选地删掉被其他关系完全包含的冗余关系
如果某个关系模式的属性集合完全包含于另一个关系模式中,那它通常就是冗余的,可以删除。
这一步不会破坏前面的主要性质,但可以让最终分解更简洁。
Let Fc be a canonical cover for F;i := 0;for each functional dependency α → β in Fc dobegin i := i + 1; Ri := α βend
if none of the schemas Rj, 1 ≤ j ≤ i contains a candidate key for Rthen begin i := i + 1; Ri := any candidate key for R;end
/* Optionally, remove redundant relations */repeat if any schema Rj is contained in another schema Rk then /* delete Rj */ begin Rj := Ri; i = i - 1; enduntil no more Rj can be deleted
return (R1, R2, ..., Ri)这个算法保证:
- 分解是 lossless
- 分解是 dependency preserving
- 各关系都在 3NF
BCNF vs 3NF
BCNF
优点:
- 冗余更少
- 语义更干净
缺点:
- 可能不 dependency preserving
3NF
优点:
- 一定能做到 lossless + dependency preserving
缺点:
- 可能保留一定冗余
所以实际设计里常见策略是:
- 能上 BCNF 就优先 BCNF
- 如果 BCNF 破坏依赖保持且代价太高,就退回 3NF
Multivalued Dependencies and 4NF
为什么 BCNF 还不够
看这个关系:
inst_info(ID, child_name, phone)一个老师:
- 可能有多个孩子
- 也可能有多个电话号码
如果某老师 99999:
- 孩子有
David, William - 电话有
512-555-1234, 512-555-4321
那么表中会出现四行笛卡尔组合:
(99999, David, 512-555-1234)(99999, David, 512-555-4321)(99999, William, 512-555-1234)(99999, William, 512-555-4321)这张表其实已经在 BCNF 里,因为没有非平凡 FD。
但问题仍然非常明显:
- 新加一个电话号码,要插入两行
- 新加一个孩子,也要插入两行
- 数据有大量结构性重复
所以:
仅靠 FD 还抓不住“多个独立多值事实被乘起来”的冗余。
于是需要 multivalued dependency (MVD)。
MVD
如果给定某个 ID:
- 它对应一组
child_name - 它也对应一组
phone_number
而且这两组彼此独立,那么可以写:
意思不是“ID 唯一决定某一个 child_name”,而是:
ID 决定的是一整组 child_name 值;并且这组值与其他属性独立组合。
MVD 的形式定义
设关系模式 ,且 。
若在任意合法实例中,只要两个元组在 上相同,就可以交换它们的 与其余部分并仍得到合法元组,则称:
成立。
更直观点说,设 被划分成 三部分,那么:
表示只要有:
就必须也有:
这就是“独立组合”的数学表达。
MVD 与 FD 的关系
一个重要结论:
也就是:
每个函数依赖都是多值依赖。
但反过来不成立。
所以 MVD 比 FD 更一般。
4NF
4NF的定义
关系模式 关于依赖集 (其中既可有 FD 也可有 MVD)属于 Fourth Normal Form (4NF),如果对所有属于 的多值依赖:
都满足至少一个条件:
- 它是 trivial 的,即 或
- 是 superkey
注意:
- 若关系在 4NF,则一定在 BCNF
- 4NF 是为了消除由独立多值属性引起的冗余
4NF 分解算法
思路与 BCNF 类似:
- 找一个违反 4NF 的非平凡 MVD
- 把关系分成:
result := {R};done := false;compute D+;Let Di denote the restriction of D+ to Ri
while (not done) if (there is a schema Ri in result that is not in 4NF) then begin let α ↠ β be a nontrivial multivalued dependency that holds on Ri such that α → Ri is not in Di, and α ∩ β = ϕ; result := (result - Ri) ∪ (Ri - β) ∪ (α, β); end else done := true;
Note: each Ri is in 4NF, and decomposition is lossless-join- 每一步分解都是 lossless join
- 最终每个子关系都在 4NF
Example
Example 1:inst_info
原表:
inst_info(ID, child_name, phone)更合理的分解是:
inst_child(ID, child_name)inst_phone(ID, phone)因为:
- 孩子集合独立于电话集合
- 不应该在同一表里做笛卡尔展开
Example 2:
给定:
由于:
且 A 不是 superkey,所以违反 4NF。
按 4NF 分解算法逐步分解:
- 由 分解:
R1(A,B)(在 4NF)R2(A,C,G,H,I)(暂时不在 4NF,继续分解)
- 在
R2上,由 分解:
R3(C,G,H)(在 4NF)R4(A,C,G,I)(暂时不在 4NF,继续分解)
- 说明为什么
R4还能分:
由 MVD 传递性:
再把该 MVD 限制到 R4(A,C,G,I),得到:
且 A 不是 R4 的 superkey,因此 R4 违反 4NF。
- 由 分解
R4:
R5(A,I)(在 4NF)R6(A,C,G)(在 4NF)
最终得到关系集合:
并且该分解是 lossless-join,且每个子关系都在 4NF。
Example 3:从 E-R 图到 4NF

- 实体
E(A, {B}, {C}, D) - 其中
B, C是多值属性
规约成关系后,有依赖:
候选键是:
因为 A ↠ B 非平凡,且 A 不是键,所以不在 4NF。
正确分解:
R1(A,B)R2(A,C)R3(A,D)
这和我们在 E-R 模型里“多值属性最好单独拆表”的直觉完全一致。
More Normal Forms
4NF 也不是终点。
更高的范式还包括:
- PJNF / 5NF(Project-Join Normal Form)
- DKNF(Domain-Key Normal Form)
这些范式用于消除更微妙的冗余,但实际中较少用,主要因为:
- 约束更难表述
- 推理更难
- 实务收益往往不如复杂度增幅明显
Database-Design Process Revisited
R 从哪里来
规范化总是假设“先有一个关系模式 ”。
这个 可能来自三种来源:
- 从 E-R 图规约而来
- 一开始把所有感兴趣属性先塞进一个 universal relation
- 某个拍脑袋的 ad hoc 设计
规范化的任务就是:
- 检验这个 是否在好范式中
- 如果不是,则分解
为什么 E-R 设计好时往往不需要再规范化
如果 E-R 图设计得足够仔细、实体识别正确、该独立的实体都独立出来,那么规约出的表通常已经比较合理,不需要再做太多规范化。
如果在 employee 实体里放:
department_namebuilding
并存在:
那就说明:
department其实本来就应该是一个独立实体
也就是说,很多规范化问题,追根到底是 E-R 建模阶段没有把对象边界识别对。
什么时候会故意不规范化
有时为了性能,会故意采用非规范化设计。
- 展示课程时,希望同时看到
course_id, title, prereq - 如果表是规范化的,就需要
course ⋈ prereq
这时有两种提速方式:
方案 1:直接建 denormalized relation
优点:
- 查询快
缺点:
- 更占空间
- 更新更贵
- 程序员需要自己维护冗余一致性,容易出错
方案 2:使用 materialized view
优点:
- 同样能减少查询 join 成本
- 不需要应用层自己手写额外维护逻辑
缺点:
- 依旧要承担存储和更新代价
所以:
规范化和性能优化不是对立关系。
规范化负责把“逻辑结构”设计对;反规范化负责在确定语义正确的前提下做工程折中。
Normalization 抓不住的设计问题
即使一个模式在 BCNF,仍可能不是“最适合业务”的表示方式。
Example: 关于公司每年盈利数据的建模,以下三种设计都可能满足 BCNF,但它们在查询习惯和长期演进方面的表现却大不相同: 方案 1
earnings(company_id, year, amount)这是最自然的按时间建模方式,通常也是最便于跨年份查询与扩展的方式。
方案 2
earnings_2012(company_id, earnings)earnings_2013(company_id, earnings)earnings_2014(company_id, earnings)问题:
- 这类设计在形式上也可能满足 BCNF
- 跨年份查询困难
- 每年都要新建表
方案 3
company_year(company_id, earnings_2012, earnings_2013, earnings_2014)问题:
- 这种设计在形式上也可能满足 BCNF
- 跨年份计算也别扭
- 每多一年都要加新列
- 这其实是 crosstab(交叉表):把某个属性的取值变成列名
- crosstab 常见于电子表格与数据分析工具,但不一定适合作为核心事务表结构
规范化理论只处理“依赖导致的冗余”。
它不自动替你解决“数据建模方式是否顺着业务查询习惯、是否便于长期演进”这类问题。
Modeling Temporal Data
为什么需要 temporal data
普通数据库默认表达的是:
当前时刻世界是什么样。
但很多时候我们还想表达:
- 某课程过去叫什么名字
- 某个老师过去在哪个系
- 某条规则在什么时间段有效
这就需要 temporal data。
也就是:
- 不仅记录事实是什么
- 还记录事实在什么时间段内成立
Snapshot 与 Temporal FD
某一时刻的数据状态叫 snapshot。
如果一个函数依赖是在每个时间点的 snapshot 上都成立,那么它是 temporal functional dependency。
记号上可以写成一种“带时间语义的 FD”,其意思是:
在任意时间点切出快照,该快照都满足普通 FD。
例如课程数据里:
- 某个时间点上,一个
course_id对应一个title - 但跨越多年看,同一个
course_id的title可能改名过
于是:
- 普通 FD 在整个历史表上未必成立
- temporal FD 在每个 snapshot 上成立
Temporal Primary Key
在 temporal relation 中,原主键通常不再足够。
例如课程历史表中,同一个 course_id 可以在不同时段对应多条记录。
但也不能简单地把 (course_id, start, end) 当主键就结束,因为这样无法阻止时间区间重叠。
真正需要的是:
若两条元组的主键值相同,则它们的 valid time interval 不能重叠。
这就是 temporal primary key 的核心。
Temporal Foreign Key
普通外键只要求:
- 引用值在被引用表中存在
temporal foreign key 还要额外关心:
- 时间区间是否匹配
课本给出的形式化要求是:
对于引用关系 ,若 中某元组时间区间是 ,则在被引用关系 中,必须能找到一组同键值元组,它们的时间区间并起来能覆盖 。
这点很关键。
因为 temporal FK 要求的不是:
- 恰好存在一条时间区间完全相同的记录
而是:
- 被引用事实在该时间段内整体持续有效
Example:transcript
学生成绩单中的 takes.course_id,应该引用“学生修这门课时,当时版本的课程信息”。
也就是说:
- 不是随便找当前 course 表里 course_id 相同的记录
- 而是找 valid time 覆盖当时学期的那条历史记录
这正是 temporal FK 的必要性。
Temporal Join
普通 join 只看键值匹配。
temporal join 还要看时间区间是否相交。
规则是:
- 如果两个元组键值匹配且时间区间相交,则可 join
- join 结果的有效时间 = 两区间的交集
- 若区间不相交,则该组合丢弃
这和普通 join 非常不同。
SQL:2011 的 temporal 支持
- 声明有效时间区间
例如可写:
period for validtime (start, end)表示 start, end 共同定义该元组的有效时间段。
- Temporal primary key
例如:
primary key (course_id, validtime without overlaps)含义是:
- 相同
course_id的多个版本可以存在 - 但它们的 validtime 不能重叠
- Temporal foreign key
SQL:2011 也支持这类语义声明。
不过课本指出:
- 真正支持 temporal PK / temporal FK 的数据库并不多
- IBM DB2、Teradata 有部分支持
- PostgreSQL 不原生支持 temporal primary key,但可以曲线实现
PostgreSQL workaround
PostgreSQL 可以借助:
tsrange类型&&区间重叠运算符exclude约束
例如:
exclude (course_id with =, validtime with &&)含义是:
- 若
course_id相同,则它们的validtime不允许 overlap
这相当于手工实现 temporal primary key。