

概述
这一章的核心是:
数据库设计在建立表前面还有一层:先识别 实体(entity)、联系(relationship)、约束(constraints),再把它们组织成 E-R diagram,最后再把 E-R 图规约成关系模式。
设计链条:
- Requirement Specification:先把需求说清楚
- Conceptual Design:把需求画成 E-R 图
- Logical Design:把 E-R 图变成关系模式
- Physical Design:再考虑物理存储与实现
也就是说,这一章讲的是 数据库设计的蓝图层。
目录
- 概述
- 目录
- Database Design Process
- The E-R Model
- Attributes
- Constraints in E-R Model
- Primary Keys in E-R Model
- Weak Entity Sets
- Redundancy of Schemas
- Reduction to Relation Schemas
- Design Issues
- Extended E-R Features
- Reducing Generalization to Relational Schemas
- UML
Database Design Process
真实数据库应用里,表往往几十张、上百张,几乎不可能拿到需求后直接把所有 schema 一次性写对。
这件事本质上和软件设计、建筑设计很像。
真正困难的地方,常常不在最后编码,而在前面的 需求定义 和 设计选择。
- Requirement Specification 是最难的
- 这一步最依赖对业务领域本身的理解
- 在软件行业里,做这件事的人常常就是 BA(Business Analyst,业务分析师)
数据库设计的四个阶段
- Requirement Specification
- Conceptual Design
- Logical Design
- Physical Design
Requirement Specification
先搞清楚:
- 用户到底要管理什么数据
- 数据之间有什么真实业务关系
- 系统要支持什么操作 / 事务
这是问题定义。
Conceptual Design
选定数据模型,把需求翻译成概念结构。
- 用 Entity-Relationship Model
- 画出 E-R diagram
这是蓝图设计。
Logical Design
把概念模型落成逻辑模式。
如果后端采用关系数据库,这一步通常就是:
- 决定有哪些关系模式
- 每张表有哪些属性
- 键和外键怎么放
这是关系层落地。
Physical Design
继续往下,考虑实现层:
- 文件组织
- 存储布局
- 索引等物理结构
这是实现层优化。
设计的陷阱
- Redundancy
- Incompleteness
Redundancy(冗余)
同样的信息被重复表示。
后果:
- 存储浪费
- 更新不一致
- 维护麻烦
Incompleteness(不完整)
模型表达不出真实业务中的某些语义。
后果:
- 系统虽然有表,但业务落不下来
- 某些情况没法建模
- 设计表面完整,语义实际残缺
所以数据库设计不是能表示就行。
你还要在一个很大的设计空间里,找到:
- 不冗余
- 不缺失
- 结构清晰
- 易于落地
的那个方案。
设计本质上是在巨大的选择空间里挑一个合适点。
设计路线
设计路线分为两条主路线:
- E-R Model
- Normalization
E-R Model
从现实世界出发,先识别:
- 实体
- 联系
- 属性
- 约束
优点:
- 直观
- 贴近业务语义
- 适合概念建模
Normalization Theory
从关系模式和函数依赖出发,分析设计是否有坏味道。
优点:
- 更形式化
- 适合检验、分解坏表
简单区分:
- E-R 模型负责先把世界说清楚
- 规范化负责把关系模式修好
The E-R Model
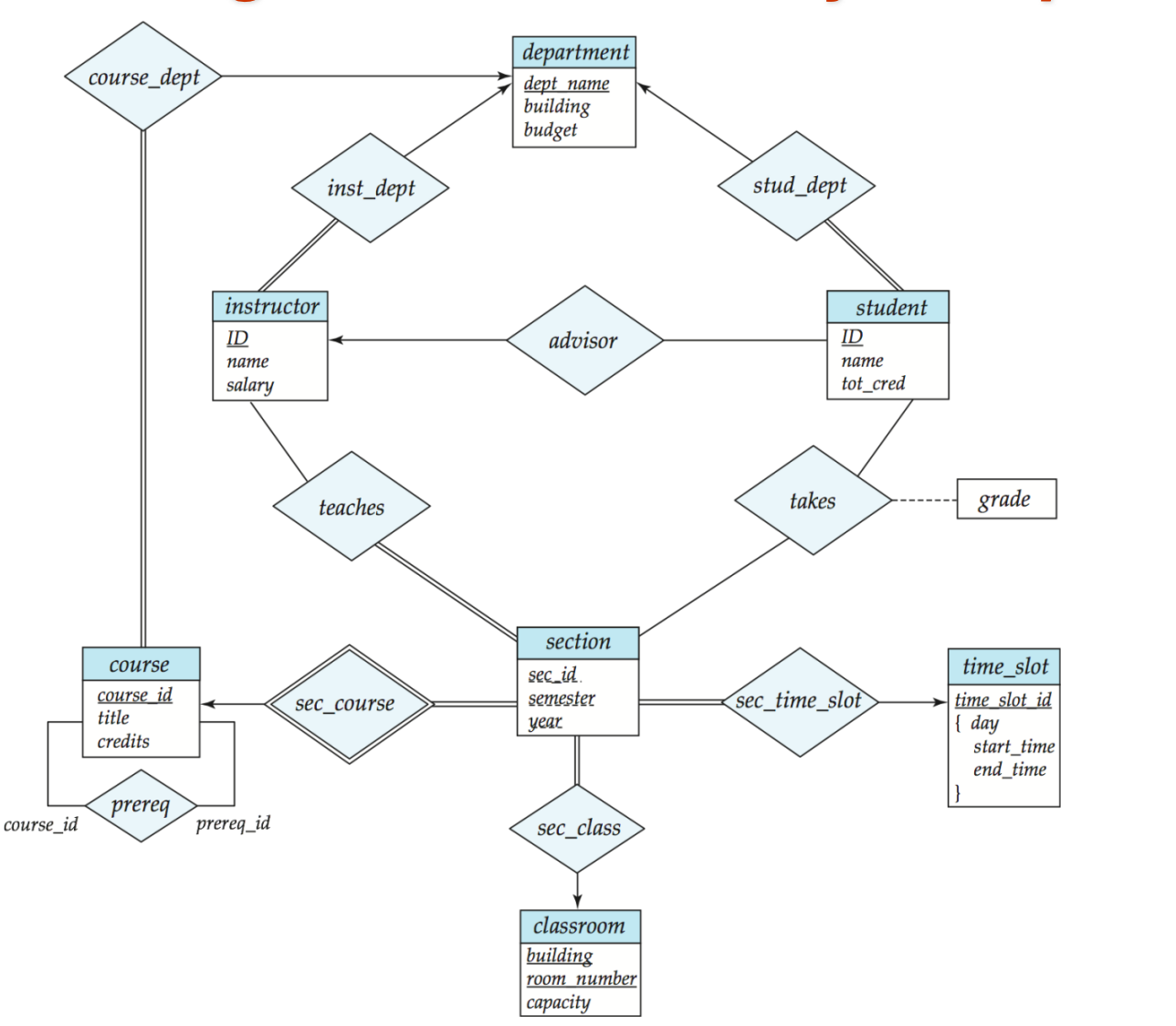
entity / entity set
entity
实体(entity)就是企业 / 应用领域里一个可区分的对象。
例如:
- 某个学生
- 某位教师
- 某门课程
- 某个教室
- 某次事件
entity set
实体集(entity set)是同一类实体的集合。
例如:
- 所有学生构成
student - 所有教师构成
instructor - 所有课程构成
course
所以:
- entity 是一个对象
- entity set 是同类对象的集合
E-R 图中:
- 矩形 rectangle 表示实体集
- 实体的属性写在矩形里或周围
- 带下划线的属性 表示主键属性
例如在大学系统里:
student(ID, name, tot_cred)instructor(ID, name, salary)
这里画的不是某一个 student,而是
student这个 实体集合。
relationship / relationship set
联系(relationship)是多个实体之间的关联。图中表示为 菱形 diamond。
例如:
- 某个学生由某位教师指导
- 某教师教授某个教学班
- 某课程有某门先修课
联系集(relationship set)是同类联系的集合。
例如:
advisor:学生和教师之间的指导关系集合teaches:教师与教学班之间的授课关系集合
数学表达:
如果联系集 R 涉及实体集 E1, E2, ..., En,
那么每个联系就是一个元组:
(e1, e2, ..., en)
其中 ei ∈ Ei。
所以 relationship set 本质上就是:
- 从多个实体集中各取一个实体
- 组成一个关系元组的集合
WARNINGrelationship set(联系集)的元素个数,一般不等于参与该联系的各实体集大小的乘积。
若一个联系集
R涉及实体集E1, E2, ..., En,那么有:这里:
- 表示这些实体集的笛卡尔积(Cartesian product)
- 它表示“从每个实体集中各取一个实体所形成的所有可能组合”
- 而真正的联系集
R,只是这些可能组合里,实际满足该联系语义的那些元组构成的集合所以,联系集可以理解成:
定义在若干实体集上的一个谓词所对应的真值集合。
也就是:
因此:
- 笛卡尔积给出的是候选元组空间
- 联系集给出的是其中真正成立的关系元组
例如:
advisor(student, instructor)
advisor是学生和教师之间的指导关系,因此:可以写成:
这里要注意:
student × instructor包含所有学生-教师的可能配对- 但只有该学生确实由该教师指导的配对,才属于
advisor所以一般有:
通常远小于这个乘积。

TIPrelationship 也可以有属性
属性不一定只属于实体,也可以属于联系。
例如
takes这个联系,可以带一个属性:
grade表示:
- 学生选了某教学班,并且得了某成绩
这类属性描述的是:
- 不是学生自身的性质
- 也不是课程自身的性质
- 而是这段关系本身的性质
这个很重要。
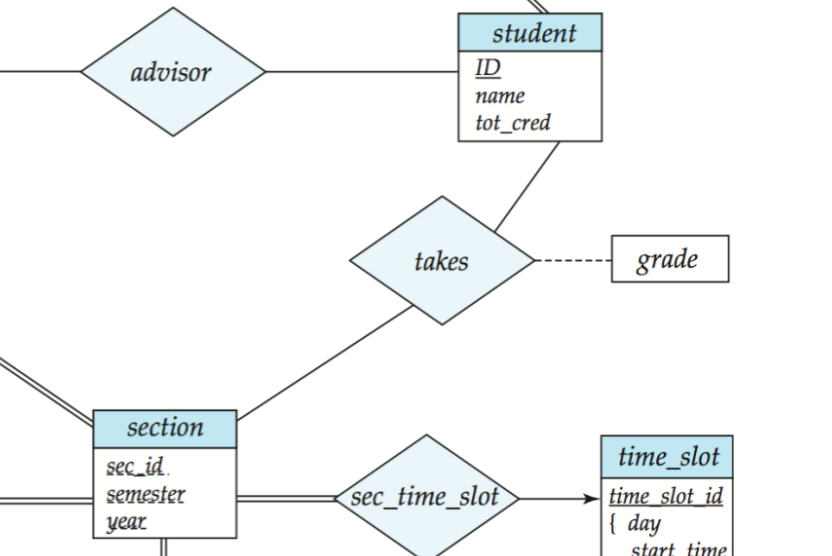
TIProle:同一个实体集在一个联系里可以出现多次
有些联系里,同一个实体集会出现多次。
经典例子:
prereq(course_id, prereq_id)这里两边其实都是
course实体集。
只是它们扮演的角色不同:
- 一个角色是当前课程
- 一个角色是先修课程
这种同一个实体集在联系中的不同身份叫 role(角色)。
所以
course_id和prereq_id不是两个不同实体集,
而是同一个course实体集在一个联系中的两个 role

Binary 与 Non-binary relationship
Binary relationship
二元联系,涉及两个实体集。
数据库里最常见的联系都是二元联系。
例如:
advisor(student, instructor)teaches(instructor, section)
Non-binary relationship
非二元联系,涉及三个及以上实体集。
例如一个三元联系:
proj_guide(instructor, student, project)
表示:
- 某教师指导某学生做某项目
这里三者共同构成一个语义单元。
这一点很关键。 因为有些语义如果硬拆成多个 binary relationship,会失真。
Attributes
属性的基本作用
属性(attribute)是实体集或联系集上记录信息的手段。
例如:
instructor = (ID, name, street, city, salary)course = (course_id, title, credits)
属性的值来自某个 domain(域):
- 也就是该属性允许的取值集合
Simple / Composite
Simple attribute
简单属性,不可再分。
例如:
salaryID
Composite attribute
复合属性,可以再拆。
例如:
name可以拆成 first name / last nameaddress可以拆成 street / city / zip

TIP设计时看应用需求决定是否拆不拆:
- 如果系统只需要显示完整地址,未必必须拆
- 如果系统需要按城市筛选、按邮编统计,那就应该拆
所以属性是不是 composite,不是语法问题,是业务问题。
Single-valued / Multivalued
Single-valued attribute
单值属性:一个实体对应一个值。
例如:
- 学生学号
- 教师工资
Multivalued attribute
多值属性:一个实体可能对应多个值。
例如:
phone_numbers
一个教师可能有多个电话号码。
注意这类属性后面落地到关系模式时,通常不能直接做成一个原子字段乱塞一串。
一般需要进一步拆成独立关系。
inst_phone= ( ID, phone_number)(22222, 456-7890)(22222, 123-4567)Derived
派生属性(derived attribute)可以由其他属性计算出来。
例如:
age可以由date_of_birth推出
这类属性的一个关键问题是:
- 要不要真的存?
一般原则:
- 如果能稳定计算出来,而且不常单独维护,优先不存
- 如果计算代价高、查询频繁,可能会物化存储
Constraints in E-R Model
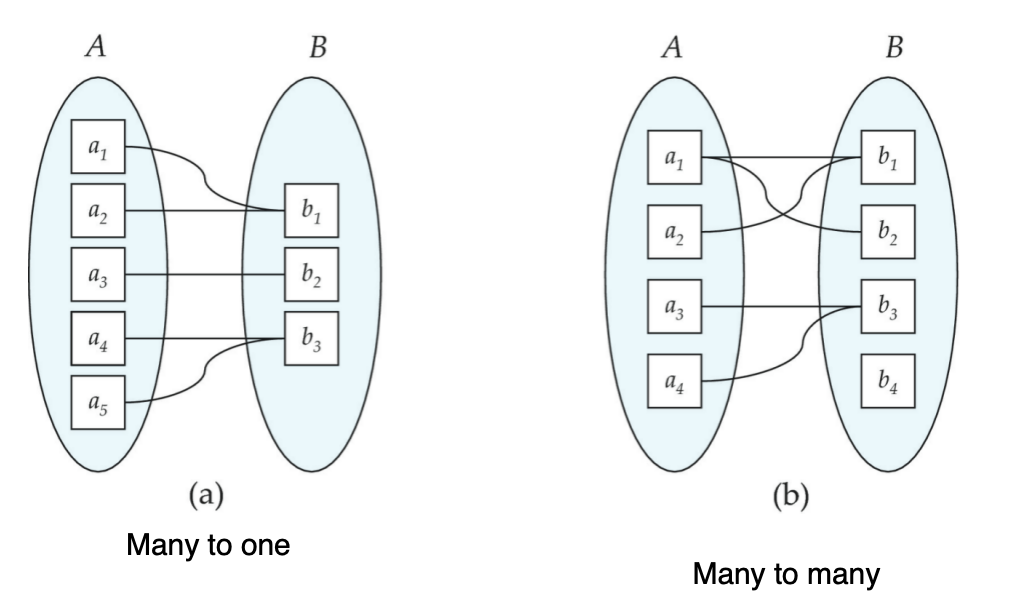
Mapping Cardinality
基数约束(mapping cardinality)描述:
一个实体通过某个联系,最多 / 最少能和另一侧多少实体关联。
对二元联系来说,有四种最基本的情况:
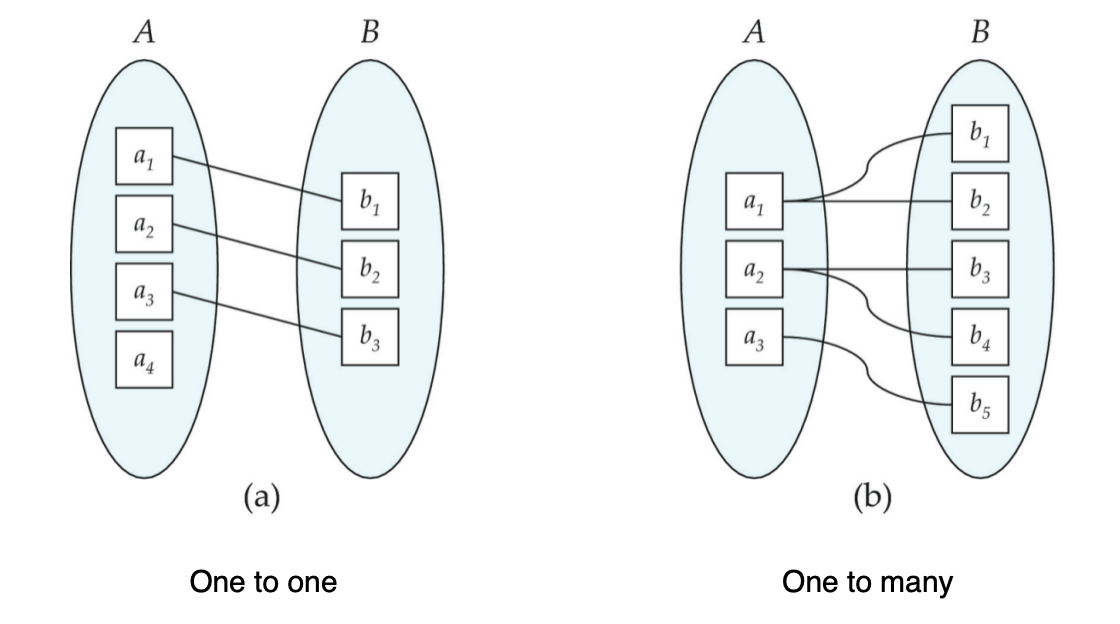
- One-to-One
一对一。
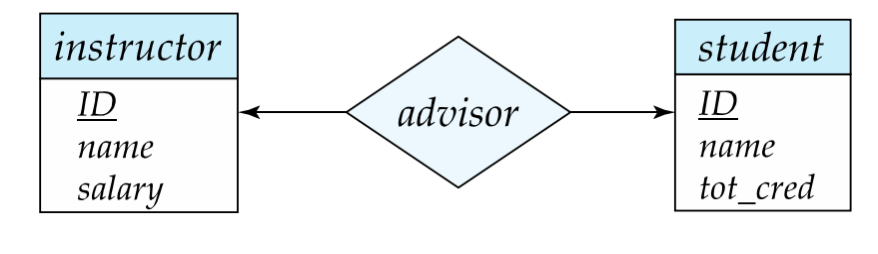
含义:
- A 中一个实体最多关联 B 中一个实体
- B 中一个实体最多关联 A 中一个实体
例如某些极特殊业务下:
- 一个学生最多一个导师
- 一个导师最多指导一个学生
- One-to-Many
一对多。

含义:
- A 中一个实体可关联多个 B
- B 中一个实体最多关联一个 A
例如:
- 一个教师可指导多个学生
- 一个学生最多一个导师
- Many-to-One
多对一。
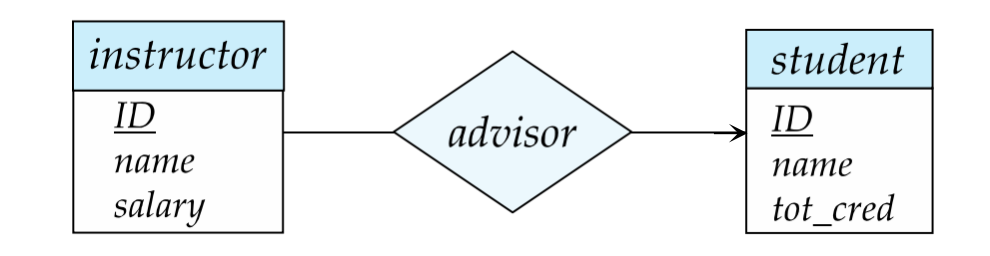
含义与一对多反过来。
例如:
- 多个教师都关联到同一个学生
- Many-to-Many
多对多。
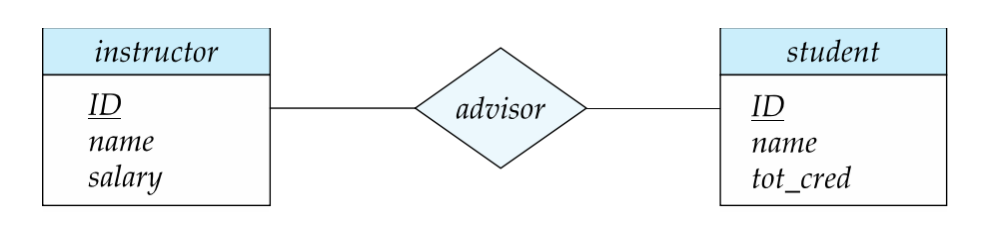
含义:
- 两边实体都可关联多个对方实体
例如:
- 学生选多个教学班
- 一个教学班也有多个学生
典型的 takes(student, section)。
Total Participation vs Partial Participation
这是另一组非常重要的约束。
Total participation
全参与。
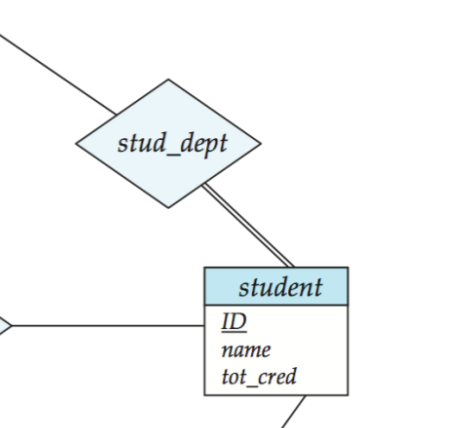
意思是:
- 实体集中的每个实体,都必须至少参与一次该联系
图中通常用 双线 表示。
例如:
- 如果规定每个学生都必须有一个系
- 那
student在stud_dept中就是 total participation
Partial participation
部分参与。
意思是:
- 某些实体可以不参加这个联系
例如:
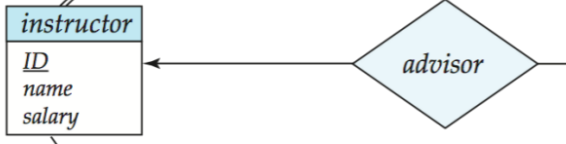
- 教师可以暂时不指导任何学生
- 那
instructor在advisor中就是 partial participation
min..max 形式
除了箭头 / 双线,也可以用 l..h 表示参与约束:
l:最小参与次数h:最大参与次数
典型解释:
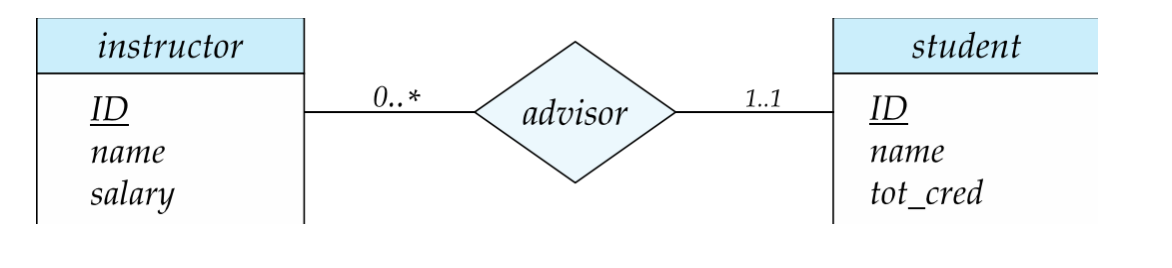
1..1:必须且至多一次0..1:可不参加;参加时最多一次0..*:可不参加;参加次数不限1..*:至少一次;上不封顶
例如:
- 教师可指导
0..*个学生 - 学生必须有且只有
1..1个导师
Ternary relationship 中的基数约束
三元联系里,基数约束更容易混乱。
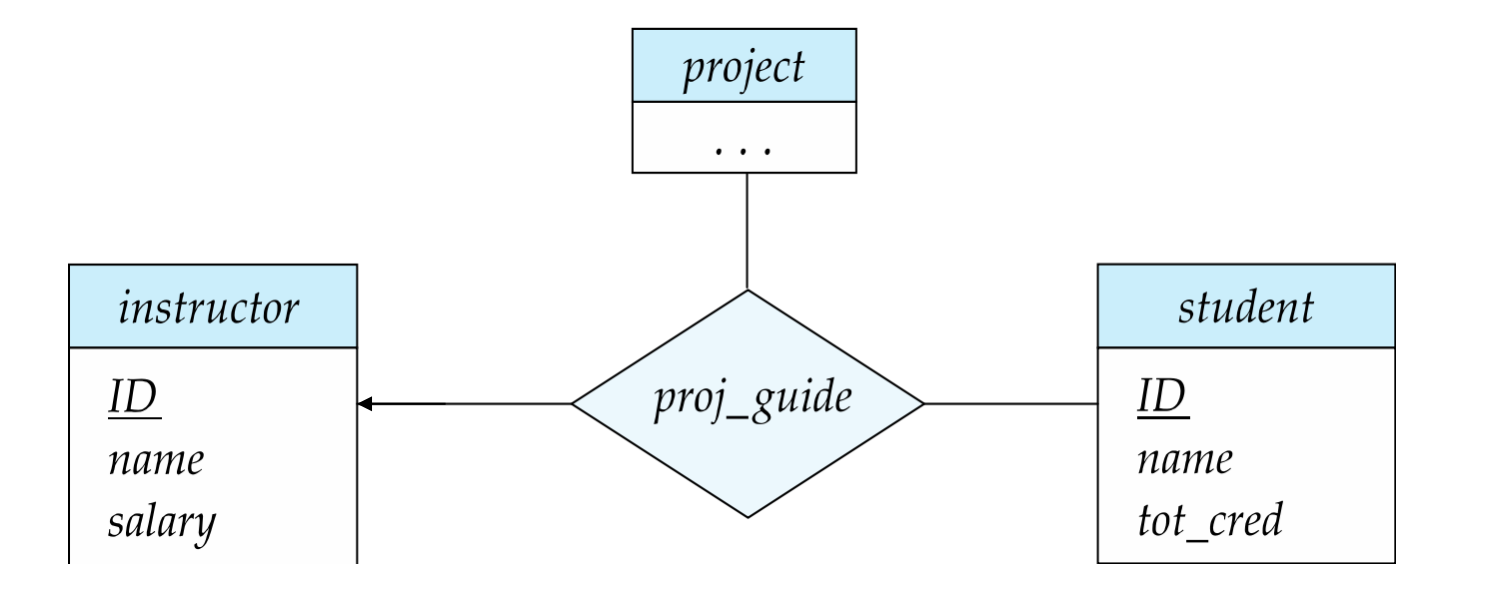
- 对 ternary(或更高元)联系,最多只允许画 一个箭头
- 例如
proj_guide指向instructor的箭头,可以表示:- 对于给定的
student和project - 最多只有一个
instructor
- 对于给定的
多个箭头叠加后语义容易歧义 为了避免混乱,禁止超过一个箭头。
Primary Keys in E-R Model
实体集的主键
对实体集来说,主键的要求很直观:
属性值必须足以唯一标识实体集中的每个实体。
也就是:
- 不允许两个实体在所有关键属性上完全相同
例如:
student的IDcourse的course_id
联系集的主键
联系集也要区分不同联系,所以它也有主键问题。
一般思路:
- 取参与实体集的主键并起来
- 如果联系本身还有属性,而且这些属性也参与区分,则也要考虑进去
设联系集 R 涉及 E1, E2, ..., En,
那么一个基本候选主键是:
primary_key(E1) ∪ primary_key(E2) ∪ ... ∪ primary_key(En)
如果 R 还有描述性属性 a1, a2, ..., am:
- 它们在某些情况下也会被纳入区分
例子:
advisor的主键可由instructor.ID与student.ID组合得到
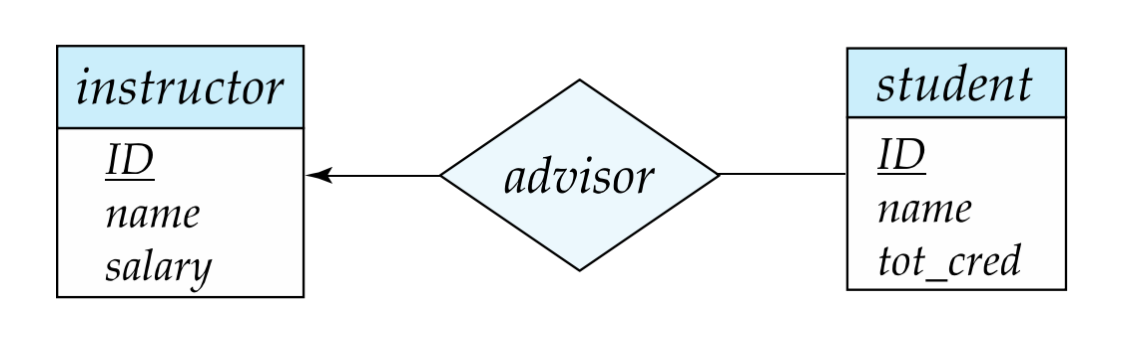
不同基数下联系主键选择策略
这一点重点
- Many-to-Many
两边都可能重复,所以必须用两边主键并集。
这是最自然的最小超键。
- One-to-Many
主键取 many 这一侧的主键即可。
因为 many 这一侧每个实体至多对应一个 one 侧实体。
- Many-to-One
同理,也是取 many 侧主键。
- One-to-One
任意一侧主键都可以作为联系主键。
因为两边都是最多一个。
联系主键跟会重复的一侧走。
多对多两边都重复,所以两边都要。
Weak Entity Sets
如果一个实体集本身没有足够属性形成主键,它就是 弱实体集(weak entity set)。
反过来,能自己形成主键的实体集叫 强实体集(strong entity set)。
弱实体的核心语义不等同于属性少:
它的存在依赖于别的实体。
它必须靠 别人 + 自己的局部区分信息 才能被唯一标识。
弱实体相关的三个术语:
- identifying entity set
标识性实体集。
也就是它依赖的那个强实体集。
- identifying relationship
标识性联系。
弱实体通过它和标识性实体集连接。
图中用 双菱形 表示。
- discriminator / partial key
分辨符、部分键,虚下划线标出。
它只能在已知所属强实体的前提下,区分该弱实体。

section
大学系统里最经典的例子就是:
coursesection
单独一个 sec_id 往往不能全局唯一。
例如:
- CS61A可能有 section 1, section 2
- MATH101也可能有 section 1, section 2
所以一个 section 真正唯一,需要:
course_id- 再加上
sec_id, semester, year
于是:
course是 identifying strong entitysection是 weak entitysec_course是 identifying relationshipsec_id(加上 semester/year 等局部属性)是 discriminator 的一部分
最后 section 的主键形成方式是:
- 强实体
course的主键 - 加上弱实体的 discriminator
即:
(course_id, sec_id, semester, year)
弱实体在 identifying relationship 中必须满足:
- total participation
- 并且该联系朝标识实体方向是 many-to-one
直观理解:
- 每个弱实体都必须挂靠到某个强实体
- 一个弱实体只能挂靠到一个对应的 owner
Redundancy of Schemas

student.dept_name 是冗余的
假设我们已经有:
studentdepartmentstud_dept(student, department)这个联系
如果这时你又在 student 实体里放一个属性:
dept_name
那它就可能重复表达了同样的信息:
- 学生属于哪个系,本来已经能从
stud_dept里看出来 - 现在又在
student属性里存一遍
这就是冗余。
一个数据库设计最危险的 是:
- 你不知道它和别处表达的是不是同一件事
一旦是同一件事,就会产生同步更新问题。
但转成表时,student 表里又可能会有 dept_name 字段。
WARNING在 E-R 图层面:
dept_name作为student属性可能是冗余但在 E-R 向关系模式规约时:
- 如果
stud_dept是 many-to-one / one-to-many 且满足条件- 我们可能会把系的主键并回到
student表里于是表结构里又出现了:
student(..., dept_name)所以这里并不矛盾。
关键区别是:
- 概念层面:不应重复表达同一个语义
- 关系实现层面:可以通过外键并入来更紧凑地表示联系
也就是:
前面去掉的是概念冗余,
后面加回来的可能是关系规约后的实现性字段。
Reduction to Relation Schemas
E-R 图最后是要落到关系数据库上的。
总原则是:
对每个实体集、每个联系集,都能构造出对应的 relation schema。
也就是说,E-R 是概念模型,关系模式是逻辑模型。
强实体转表
- 直接变成同名关系
- 属性照搬
- 主键照搬
例如:
course(course_id, title, credits)弱实体转表
弱实体集转成表时,必须把其 identifying strong entity 的主键带进来。
- 表包含弱实体自己的属性
- 再加上 identifying strong entity 的主键
- 新表主键 = 强实体主键 + 弱实体 discriminator
例如:
section(course_id, sec_id, semester, year)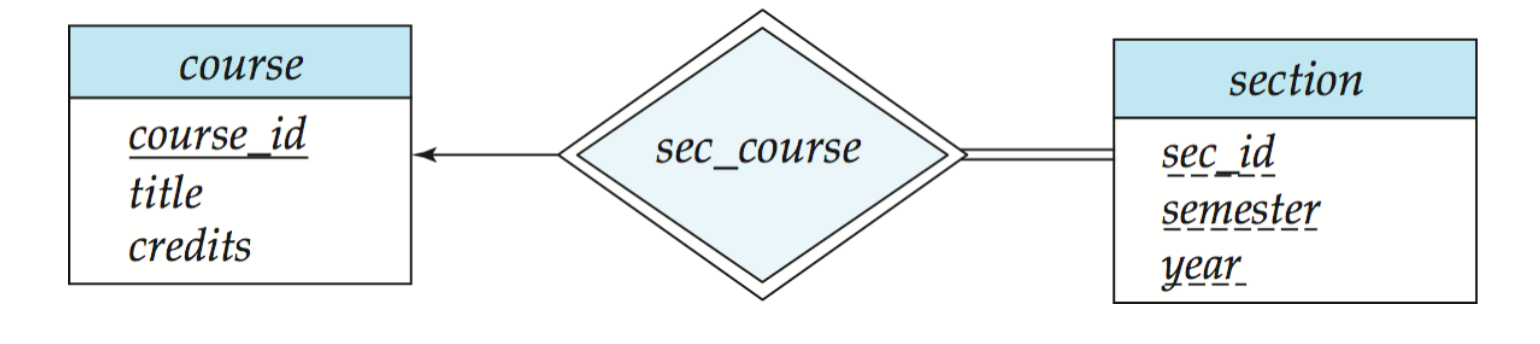
这里 course_id 来自 course,
其余局部属性负责区分具体 section。
多对多联系转表
many-to-many 联系集要单独建表。
表中应包含:
- 两边实体集的主键
- 联系自己的描述性属性(如果有)
例如:
advisor(s_id, i_id)如果 advisor 还有属性 date,就应变成:
advisor(s_id, i_id, date)
因为 date 描述的是这段指导关系,不属于单独一边实体。
多对一 / 一对多联系怎么优化进实体表
对于:
- many-to-one
- one-to-many
如果 many 一侧是 total participation,
则不一定要为联系单独建表,
可以把 one 侧主键作为额外属性,塞进 many 侧的实体表中。
例子:
原始方案:
department(dept_name, building, budget)instructor(ID, name, salary)inst_dept(ID, dept_name)可以优化成:
department(dept_name, building, budget)instructor(ID, name, salary, dept_name)也就是把 inst_dept 吸收到 instructor 里。
直观理解:
- 每个 instructor 都属于一个 department
- 那就直接在 instructor 表里放外键
dept_name - 没必要再单独维护一个联系表
一对一联系转表
one-to-one 联系中:
- 任意一侧都可以被视为 many 侧来吸收外键
也就是:
- 可以把一方主键作为额外属性加到另一方表中
但如果参与是 partial 的,要注意:
- 这么做可能引入
null
所以一对一通常要结合:
- 哪边 total / partial
- 哪边更常访问
- 是否会引入过多空值
来决定并入哪边。
NOTE弱实体与标识联系对应的表为什么往往冗余?
弱实体和 identifying strong entity 之间的 identifying relationship,
在规约后往往不需要单独建表。原因是:
- 弱实体表里已经包含了强实体主键
- 也就已经隐含了那条标识联系
例如:
section(course_id, sec_id, semester, year)已经足够表达:
- 这个 section 属于哪个 course
所以
sec_course再单独建表,就重复了。
Multivalued Attribute 的特殊规约
time_slot(time_slot_id)
它除了主键 time_slot_id 外,没有普通单值属性,只有一个多值属性组:
daystart_timeend_time
也就是说,一个 time_slot_id 可以对应多条时间明细,例如:
- Mon 09:00–10:15
- Wed 09:00–10:15
- 按标准做法的规约
一般会拆成两张表:
time_slot(time_slot_id)
time_slot_detail(time_slot_id, day, start_time, end_time)其中:
time_slot表示实体本身time_slot_detail表示这个实体对应的多值属性明细
- 这个例子的优化
由于 time_slot 除了主键外没有别的普通属性,所以可以省去那张只有主键的表,直接只保留多值属性对应的表:
time_slot(time_slot_id, day, start_time, end_time)这时这张表的每一行表示某个 time_slot 的一个具体时间明细。
- 这个优化的代价
优化后,time_slot_id 本身通常不再唯一,真正的键会变成类似:
(time_slot_id, day, start_time, end_time)因此,section 中通过 sec_time_slot 得到的 time_slot_id
不能再直接作为外键引用这张优化后的 time_slot 表,因为它引用的不是一个唯一键。
Design Issues
entity vs attribute
有些现实对象,到底应该画成 entity,还是某个 entity 的 attribute?
例如 phone:
attribute:
如果你只关心“电话号码这个值”,
那放成属性最简单。
entity:
如果你还关心号码本身的更多信息,例如:
- 号码类型
- 归属地
- 一个对象多个号码
- 号码和别的对象的关系
那把 phone 画成实体会更合理。
entity vs relationship
有些概念到底应该表示成实体,还是联系?
动作 / 交互 / 关联事件 更像 relationship。
可独立讨论、可单独拥有属性和身份的对象 更像 entity。
例如:
- 教师指导学生 更像
advisor关系 - 但如果指导记录本身要被单独管理、审核、归档
- 它也可能被抽象成一个实体
所以这不是死规则,而是看语义边界。
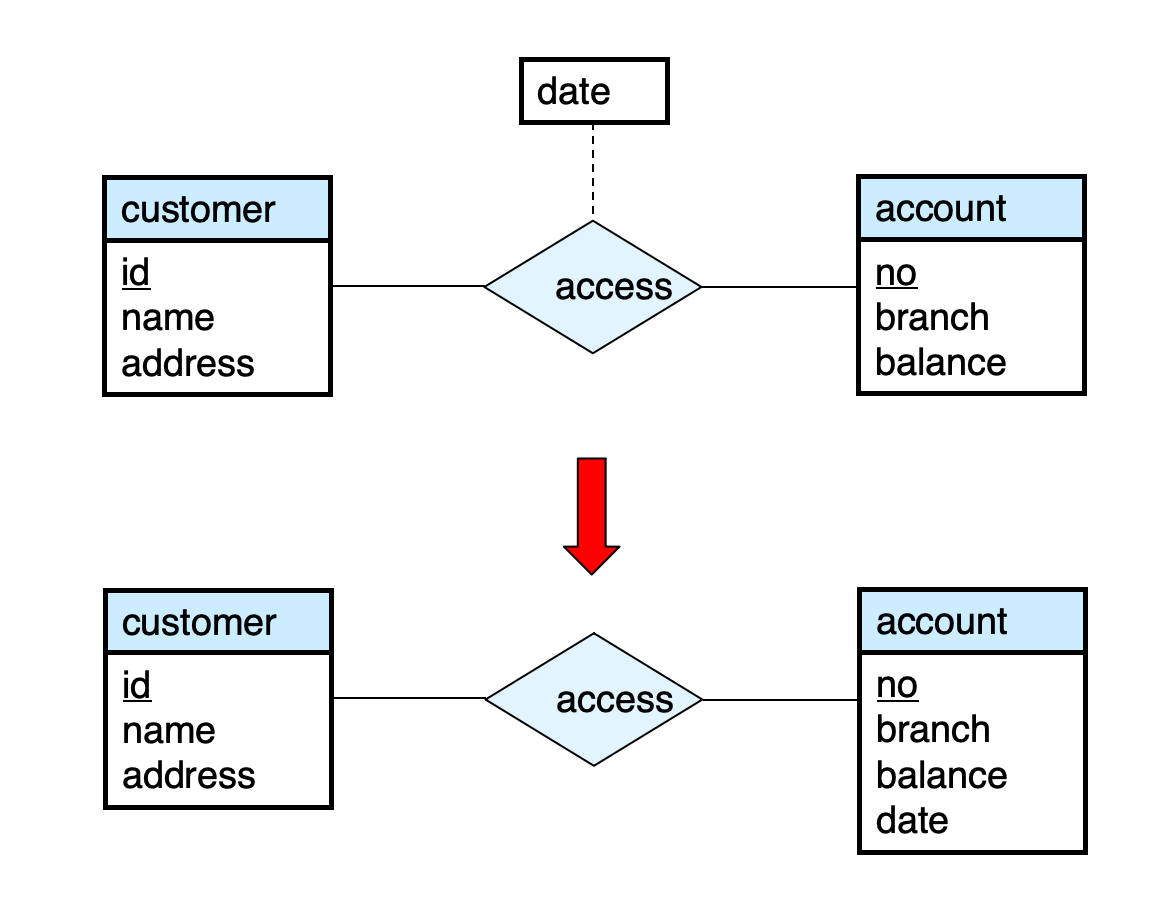
NOTErelationship 的属性应该挂在哪里?
date该挂在access关系上- 还是挂在
account实体上?判断标准很直接:
- 如果
date描述的是客户访问该账户的这次行为
- 那它属于 relationship
- 如果它描述的是账户本身的开户日期
- 那它属于 entity
所以判断一个属性放哪,关键要问:这个属性描述的到底是谁?
Binary vs n-ary
- 虽然理论上任意 n 元联系都能拆成若干二元联系
- 但 n 元联系往往更能准确表达多个实体共同参与一个语义事件
例如:
proj_guide(instructor, student, project)
这个关系强调的是三者共同形成一个指导语义。
你如果拆开成多个二元关系,可能会丢掉这三者是同一次关联的含义。
NOTE把 n 元联系改写成若干二元联系
如果有三元联系
R(A, B, C),
可以引入一个人工实体E,然后建立:
RA(E, A)RB(E, B)RC(E, C)再把
R的属性放到E上。也就是把:
- 一个三元联系实例 变成
- 一个中介实体实例
e- 它分别连向
A/B/C它能表示结构,但不一定能完整保留原约束。
例如:
- 你还得额外保证一个
E恰好对应一个 A、一个 B、一个 C- 有些原联系中的约束很难完全翻译出来
能改写,不等于改写后就一样自然。
strong entity vs weak entity
有些对象到底应该表示成 strong entity,还是 weak entity?
它能不能仅靠自身属性被唯一标识?
如果一个实体集能够只靠自己的属性形成主键,它就是 strong entity。
如果一个实体集不能仅靠自身属性形成完整主键,必须依赖另一个实体集的主键才能唯一标识,它就是 weak entity。
Extended E-R Features
基础 E-R 模型已经能覆盖大多数场景。
但对于 层次结构、子类、把联系当对象继续参与关系这类问题,需要扩展特性。
Specialization
特化(specialization)是 top-down 的。
- 先有一个较一般的高层实体集
- 再把其中某些有特殊性质的子集单独抽出来

例如:
personemployeestudent
这里:
person是高层实体集employee/student是低层实体集
employee 比一般 person 多一个 salary。
student 比一般 person 多一个 tot_cred。
所以 specialization 的本质是:从更一般往更具体细分。
Generalization
概化(generalization)是 bottom-up 的。
意思是:
- 先看到多个相似的实体集
- 再把它们抽象成一个更一般的高层实体集
例如:
- 把
student和employee提炼成上层person
所以 specialization 和 generalization 本质上是反向过程。
图上的表示方式也相同。
Attribute Inheritance
在特化 / 概化层次里,低层实体会继承高层实体的:
- 属性
- 联系参与能力
例如:
person有ID, name, street, city- 那
student自动继承这些 - 再额外加自己的
tot_cred
这就叫 attribute inheritance。
Disjoint vs Overlapping
这是子类之间的成员关系约束。
Disjoint
不相交。
一个高层实体最多属于一个低层实体集。
例如:
- 一个
person只能是student或employee其中之一

Overlapping
重叠。
一个高层实体可同时属于多个低层实体集。
例如大学里就很自然:
- 某人既是
student - 也是
employee
比如研究生助教就是这种典型例子。

Total vs Partial Completeness
这是高层到低层的覆盖约束。
Total
全部。
高层实体集中的每个实体,必须至少落入某个低层实体集。
例如:
- 每个
person都必须是student或employee
Partial
部分。
高层实体不一定非要属于某个低层实体集。
例如:
- 系统里也可能有既不是学生也不是教职工的人员记录
Aggregation
aggregation 非常重要。
它解决的问题是:
当“一个联系本身”还要继续参与别的联系时,怎么办?
经典例子:
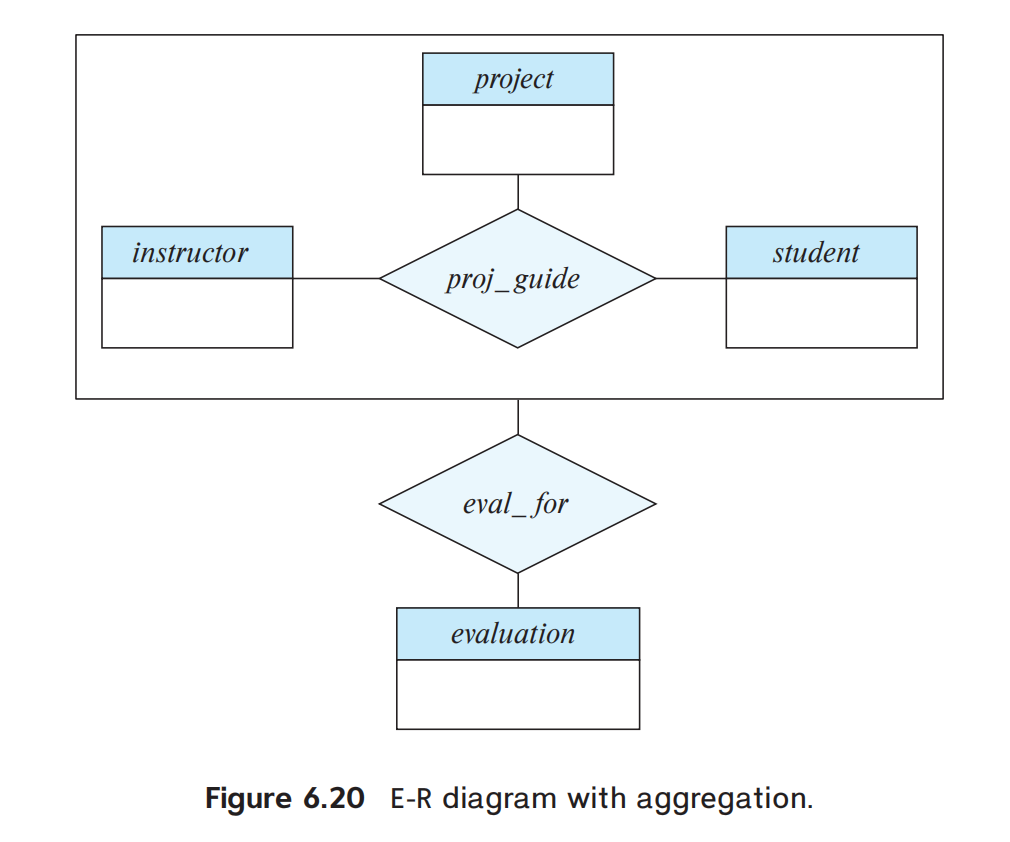
proj_guide(instructor, student, project)evaluationeval_for
如果你想表示:
- 某个 evaluation 是针对某个
(instructor, student, project)指导组合的
这时普通 E-R 模型会很 awkward。
aggregation 的做法是:
- 把关系
proj_guide连同它涉及的实体,看成一个更高层对象 - 然后再让它与
evaluation建立新的联系eval_for
直观理解:
aggregation 就是“把一个 relationship 打包成一个可再参与关系的对象”。
Reducing Generalization to Relational Schemas
特化 / 概化层次最后还是要转成关系模式。
Method 1:高层一张表,低层各一张表
做法:
- 高层实体一张表
- 每个低层实体各一张表
- 低层表包含高层主键和自己的局部属性
例如:
person(ID, name, street, city)employee(ID, salary)student(ID, tot_cred)优点:
- 规范
- 不冗余
- 层次语义清楚
缺点:
- 查一个低层对象时,常常要 join 高层表
- 访问成本更高
Method 2:每个低层实体单独带上全部继承属性
做法:
- 不单独建高层表
- 每个低层表都直接带全部继承属性
例如:
employee(ID, name, street, city, salary)student(ID, name, street, city, tot_cred)优点:
- 查低层对象方便
- 不必再 join 高层
缺点:
- 如果某人同时是 student 和 employee
- 那
name/street/city会重复存储
也就是 overlapping 场景下会有明显冗余。
Method 3:整棵层次合成一张表
做法:
- 整个 super/sub hierarchy 用一张表表示
- 加一个类型字段区分身份
例如:
person(ID, name, street, city, person_type, tot_cred, salary)其中:
person_type区分是 student / employee / both / other
优点:
- 表少
- 查整类对象方便
缺点:
- 不同子类专属属性会产生很多
null - 类型约束需要额外维护
- 语义可读性下降
UML
UML(Unified Modeling Language)本身是更通用的软件建模语言。
其中的 UML Class Diagram 和 E-R 图有很强对应关系。
- 数据建模不只存在于数据库
- 它和更一般的软件系统建模是连通的
UML 和 E-R 的主要对应关系
- E-R 的 entity set ↔ UML 的 class
- E-R 的 relationship set ↔ UML 的 association
- 基数约束依然能表达
- generalization / specialization 在 UML 里也有
对于 binary relationship,UML 常用做法是:
- 直接用一条线连两个类
- 关系名写在线旁边
- role 名也可写在靠近对应端的位置
如果 relationship 自己带属性:
- 还可以把关系名和属性写进一个小框
- 用虚线连到那条 association 上
这和 E-R 里 relationship 可带属性 的思想是一致的。
UML 和 E-R 的几个重要差别
- UML 不支持 composite / multivalued attribute 的直接画法
- E-R 图里这些更自然。
- UML 更偏向类与对象建模,不强调这一套属性分类符号。
-
Derived attribute 在 UML 里更像无参方法
-
可见性控制是 UML 独有常见元素
-
属性 / 方法前可以写:
+public-private#protected
这个明显带有面向对象风格。
- 基数约束的位置和 E-R 图正好反过来
UML 中基数标注的位置,和 E-R 图里是反过来的。
所以做题或看图时,别把 UML 的 0..1 / 0..* 按 E-R 读法直接照搬。
- UML 支持把 association box 当作更高层对象继续连关系
这和 E-R 的 aggregation 思想是相通的。