
概述
本章围绕关系模型展开,主要回答三个问题:
- 关系模型如何表示数据? 关系、属性、元组、域、原子性,以及 schema 和 instance 的区别
- 关系数据库如何保证正确组织与关联? 通过主键、候选键、外键和参照完整性来刻画表内与表间约束
- 关系查询是如何表达的? 从查询语言分类入手,重点介绍关系代数的基本运算、典型查询写法与扩展操作
目录
- Structure of Relational Databases
- 关系模型的基本表示
- 关系的形式化定义
- relation schema 与 relation instance
- 属性与域(domain)
- 原子性(atomic)
- null(空值)
- 关系是无序的
- Database Schema
- Database schema 的含义
- Database instance 的含义
- relation schema 与 database schema 的层次区别
- schema 中通常还包含什么
- Keys
- Why key?
- Superkey
- Candidate key
- Primary key
- Foreign key
- Referencing relation 与 Referenced relation
- Referential integrity
- Schema Diagram
- Schema of University Database 理解
- Relational Query Languages
- 查询语言的两种风格
- 三种 pure 关系查询语言
- 关系代数的特点
- The Relational Algebra
- 关系代数的 6 个基本操作
- Example Queries
- 最大工资例子
- 常见扩展操作
- 广义投影与聚合
- null 与三值逻辑
- 关系代数与 SQL 的联系
Structure of Relational Databases
关系模型的基本表示
关系模型用 表(table) 来组织数据:
- relation(关系):一张表
- attribute(属性):表中的列
- tuple(元组):表中的行
例如 instructor 表中:
ID, name, dept_name, salary是属性- 每一位教师对应的一行记录是一个元组。
关系的形式化定义
从数学上说,若有若干集合:
则一个关系 是它们笛卡尔积的一个子集:
也就是说,一个关系本质上是若干个 n 元组 组成的集合,每个元组的第 个分量取自集合 。slides 中用 name × dept_name × salary 的例子说明了这一点。
relation schema 与 relation instance
- Relation schema(关系模式):描述表的结构
记作:
例如:
-
Relation instance(关系实例):某一时刻表中的实际数据内容
-
表中的每一行是一个 tuple(元组)
-
schema = 表长什么样
-
instance = 表里当前有什么数据。
属性与域(domain)
每个属性都有自己的 domain(域),也就是该属性允许取值的集合。
例如:
dept_name的域:所有合法院系名salary的域:所有合法工资值
可以把“域”简单理解成:这一列允许放什么值。
原子性(atomic)
关系模型通常要求属性值是 atomic(原子的),即 不可再分。
例如:
"Physics"是原子的- 如果一个属性里同时塞多个电话号码、多个课程号,就不满足原子性
这体现了关系模型希望一个单元格中只放一个基本值。
null(空值)
null 表示:
- 值未知
- 值不存在
- 值暂时缺失
null 会使很多运算的定义变复杂。因此在数据库理论和 SQL 中,null 是一个非常特殊的值。
关系是无序的
关系中的元组顺序 没有意义:
- 哪一行排前面,哪一行排后面,不影响关系本身
- 数据库内部可以按任意顺序存储元组
这点很重要,因为关系从理论上看是一个集合,集合本身就是无序的。
Database Schema
Database schema 的含义
Database schema(数据库模式) 是数据库的 逻辑结构。
也就是:数据库里有哪些表、每张表有哪些属性、属性之间有哪些约束。
instructor(ID, name, dept_name, salary)这就是一个关系模式;多个关系模式共同组成数据库模式。
Database instance 的含义
Database instance 是数据库在某一时刻的数据快照,也就是那一刻数据库中实际存放的内容。
因此:
- schema:相对稳定,描述结构
- instance:经常变化,描述当前数据
可以类比为:
- schema 像“类/类型定义”
- instance 像“变量当前的值”
relation schema 与 database schema 的层次区别
要区分两个层次:
Relation schema
单张表的结构,例如:
instructor(ID, name, dept_name, salary)Database schema
整个数据库的结构,例如数据库里有:
instructorstudentcoursedepartment
以及这些表之间的联系。
schema 中通常还包含什么
教材总结里指出,关系模式除了属性外,通常还会包含属性类型,以及一些约束,例如:
- primary key constraints
- foreign-key constraints。
所以 schema 不只是“列名列表”,它还会隐含:
- 属性类型
- 主键
- 外键
- 其他完整性约束
Keys
Why key ?
在一张表中,我们需要某种机制来 唯一标识一条记录。 否则:
- 无法准确区分两行
- 无法建立表与表之间的联系
- 更新、删除、查询都会变得不可靠
因此引入了 key(键) 的概念。
Superkey(超键)
设 ,如果属性集 的取值足以唯一标识关系 中的一个元组,那么 就是一个 superkey。slides 中直接给出了这个定义。
例如在 instructor(ID, name, dept_name, salary) 中:
{ID}是超键{ID, name}也是超键
因为只要包含 ID,就已经能唯一标识教师。
超键的要求只有一个:
- 能唯一
但它可以包含多余属性。
Candidate key(候选键)
如果一个超键还是 minimal(最小的),也就是去掉其中任何一个属性后都不再能唯一标识元组,那么它就是 candidate key。
例如:
{ID}是候选键{ID, name}不是候选键,因为name是多余的
候选键 = 最小超键
也就是:
- 既要唯一
- 又不能冗余
Primary key(主键)
从若干候选键中,选定一个作为主要标识,就得到 primary key(主键)。
例如:
instructor表中通常选ID作为主键
主键的作用
- 唯一标识一行
- 是表中最核心的识别属性
- 其他表常通过它来引用该表
Foreign key(外键)
定义是:
若关系 中属性组 引用关系 的主键 ,则在任意数据库实例中, 中每个元组的 值都必须在 中某个元组的 值中出现。
简单说:
外键就是“一个表中的属性去引用另一个表的主键”。
例子
如果:
department(dept_name, building, budget)instructor(ID, name, dept_name, salary)
那么 instructor.dept_name 可以作为外键,引用 department.dept_name。
它的意义是:
- 教师所在院系必须是真实存在的院系
- 不能在
instructor里写一个根本不存在的dept_name
Referencing relation 与 Referenced relation
和外键关联的两个表称为:
- Referencing relation:引用别人的那个表
- Referenced relation:被引用的那个表
例如:
instructor引用department- 那么
instructor是 referencing relation department是 referenced relation
Referential integrity(参照完整性)
参照完整性要求:
在引用关系中出现的外键值,必须在被引用关系中实际存在。
这是外键约束背后的核心思想。
Schema Diagram
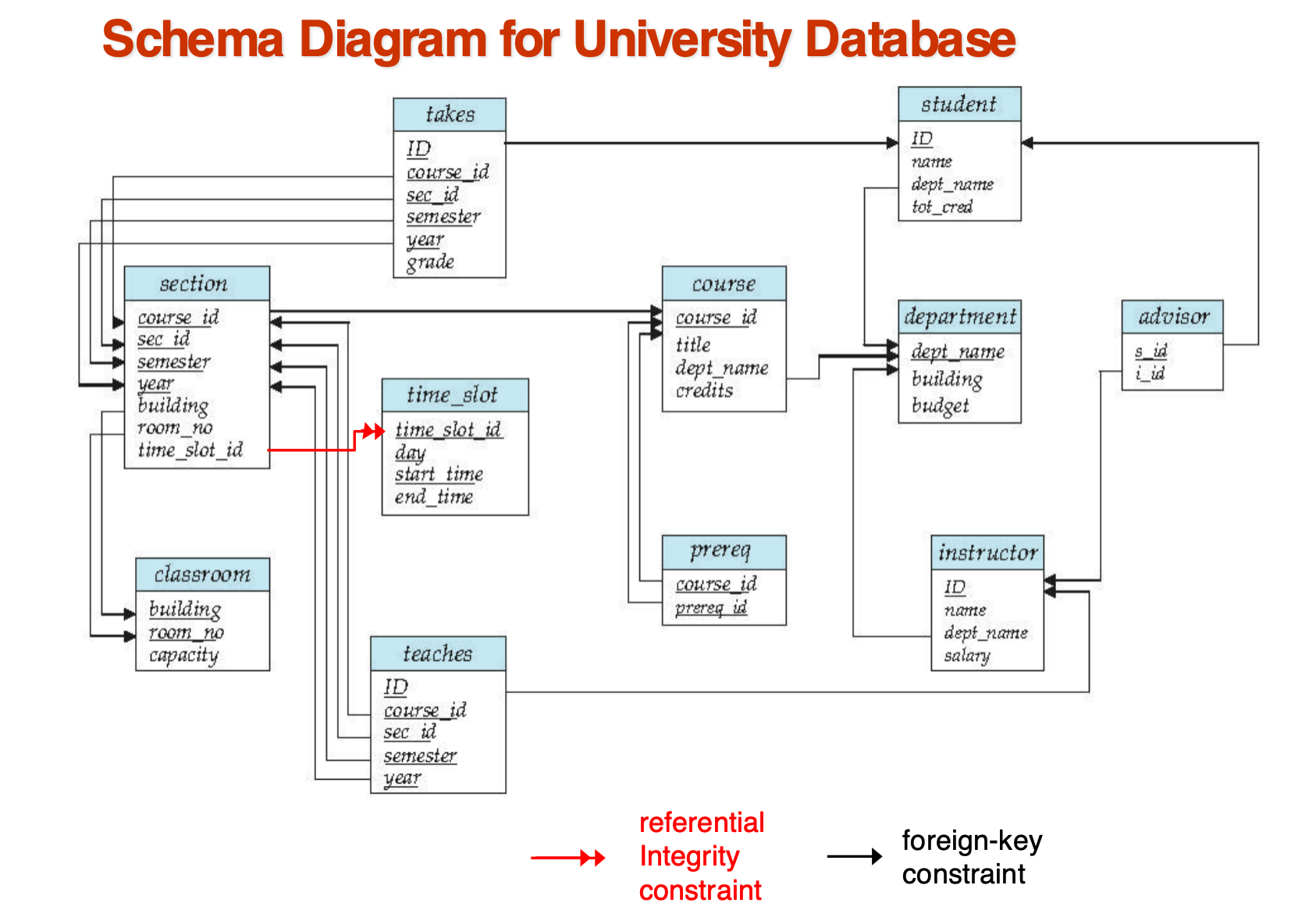
Schema of University Database 理解
数据库由多个 relations 组成
- 一个数据库不是一张表,而是多张表共同组成
- 企业信息会被拆成多个部分分别存储
两类表
实体表
- student
- instructor
- course
- department
- classroom
- time_slot
联系表
- takes:学生选课
- teaches:教师授课
- advisor:导师关系
- prereq:先修课关系
下划线含义
- 下划线属性表示 primary key
- 有的表主键是单属性,如 student(ID)
- 有的表主键是复合主键,如 section(course_id, sec_id, semester, year)
schema diagram 的含义
- 每个 box 表示一张 relation
- box 中列出属性
- 主键带下划线
- 箭头表示约束关系
黑色箭头
- 表示 foreign-key constraint
- 引用关系中的属性必须在被引用关系主键中存在
典型外键关系
- student.dept_name -> department.dept_name
- instructor.dept_name -> department.dept_name
- course.dept_name -> department.dept_name
- teaches.ID -> instructor.ID
- takes.ID -> student.ID
- advisor.s_id -> student.ID
- advisor.i_id -> instructor.ID
- section.course_id -> course.course_id
- section(building, room_no) -> classroom(building, room_no)
红色双箭头
- 表示 referential integrity constraint
- 比 foreign key 更一般
- 例:section.time_slot_id -> time_slot.time_slot_id
- 原因:time_slot_id 不是 time_slot 表的主键,只是主键的一部分,因此不能作为普通外键
Relational Query Languages
查询语言的两种风格
- Procedural(过程式):既说明要什么数据,也说明怎么得到这些数据
- Declarative / non-procedural(陈述式 / 非过程式):只说明要什么数据,不说明具体执行步骤
三种“pure”关系查询语言
-
Relational algebra(关系代数)
-
Tuple relational calculus(元组关系演算)
-
Domain relational calculus(域关系演算)
-
三者在 computing power(表达能力) 上等价
-
即:一种能表达的查询,另外两种原则上也能表达
关系代数的特点
- 属于功能性/操作型查询语言
- 输入是一个或多个 relation
- 输出仍然是 relation
- 不是通用编程语言,not Turing-machine equivalent
The Relational Algebra
关系代数(Relational Algebra)是一种 procedural query language(过程式查询语言)。
它由一组运算组成,这些运算把 一个或两个 relation 作为输入,并产生 一个新的 relation 作为输出。
- 输入是表(relation)
- 运算结果仍然是表
- 因此可以把多个运算不断组合,构成更复杂的查询表达式
这点非常重要,因为它说明关系代数具有封闭性:
relation 运算 relation,结果还是 relation
关系代数的 6 个基本操作
slides 列出的 6 个基本操作是:
- Select(选择):
- Project(投影):
- Union(并):
- Set Difference(差):
- Cartesian Product(笛卡尔积):
- Rename(重命名):
Select(选择)
选择操作用于从一个关系中取出 满足给定条件的元组(行)。
其中:
- 是关系
- 是选择谓词(selection predicate)
定义
谓词 谓词由逻辑连接词组成:
- :and
- :or
- :not
基本比较形式:
<attribute> op <attribute><attribute> op <constant>
其中 op 可以是:
σ dept_name="Physics"(instructor)σ salary > 90000(instructor)σ dept_name="Physics" ∧ salary > 90000(instructor)直观理解
选择 = 选行
它很像 SQL 的:
WHERE 条件Project(投影)
投影操作用于从一个关系中保留 指定属性(列),把其他列删去。
定义
结果是一个只包含这些属性列的新关系。
投影后要去重,因为关系是集合。 也就是说,若两行在保留下来的列上完全相同,则只保留一行。
例子
直观理解
投影 = 选列
它很像 SQL 的:
SELECT 列名...Union(并)
把两个关系中的元组合并到一起。
定义
使用条件
要使 合法,必须满足:
- 和 有相同的 arity(元数),即列数相同
- 对应列的域必须兼容(compatible)
例子
查找 2009 Fall 或 2010 Spring 开设过的课程:
直观理解
并 = 两个结果合起来
Set Difference(差)
找出 在一个关系中但不在另一个关系中 的元组。
定义
使用条件
和并运算一样:
- 列数相同
- 对应列兼容
例子
查找 2009 Fall 开过但 2010 Spring 没开过 的课程:
直观理解
差 = 从前者里减去后者
Cartesian Product(笛卡尔积)
笛卡尔积把两个关系中的每一行两两配对,形成所有可能组合。
定义
WARNING
- 和 的属性集合不相交,即 如果属性名有重复,就需要先做 rename(重命名)。
直观理解
若:
- 有 3 行
- 有 4 行
则 有 12 行。
笛卡尔积本身通常“太大”,实际常配合选择一起使用,构成连接。
Rename(重命名)
重命名操作用来给关系表达式的结果起新名字,或者给属性改名。
给表达式结果改名:
给关系和属性一起改名:
- 给中间结果起名,便于后续引用
- 一个关系需要以多个名字出现时使用
- 避免属性名冲突
- 自连接时非常重要
在找最大工资时,用 d 作为 instructor 的一个副本:
Examples
关系代数表达式可以嵌套。
意思是:
- 先做
- 再从结果中选出满足 的元组
Example Queries
题目:
- 找出 Physics 系所有教师的名字,以及他们教过的课程号
course_id
涉及关系:
instructor(ID, name, dept_name, salary)teaches(ID, course_id, sec_id, semester, year)
核心思路:
- 用
instructor.ID = teaches.ID把教师信息和授课信息连接起来 - 再筛出
dept_name = "Physics"的教师 - 最后只保留
name和course_id
Query 1
含义:
- 先做
instructor × teaches - 再选出
instructor.ID = teaches.ID的匹配元组 - 再筛出
dept_name = "Physics" - 最后投影出
name和course_id
特点:
- 先连接,后筛选
Query 2
含义:
- 先从
instructor中选出 Physics 系教师 - 再与
teaches做笛卡尔积 - 再按
ID匹配 - 最后投影出
name和course_id
特点:
- 先筛选,后连接
两者比较
- 两个查询结果相同
- Query 2 更高效,因为它先做选择,减少了中间结果规模
- 关系代数表达式可以有多种等价写法
- 尽量早做选择(selection push-down)有利于查询优化
最大工资例子
如何不用聚合也能找最大工资。思路是:
Step 1
找出“比别人小”的工资(即不是最大值的工资):
Step 2
用所有工资减去这些“非最大工资”:
- 先找不是最大值的
- 再从全集中删掉它们
- 剩下的就是最大值
这是关系代数很经典的构造思路。
关系代数的封闭性
如果 和 是关系代数表达式,那么下面这些也是合法的关系代数表达式:
这再次体现了封闭性。
常见扩展操作
additional operations:它们不增加表达能力,但能让常见查询写得更简洁。
包括:
- Intersection(交)
- Natural Join(自然连接)
- Semijoin(半连接)
- Assignment(赋值)
- Outer Join(外连接)
- Division(除法)
Intersection(交)
- 相同 arity
- 对应列兼容
与基本操作的关系
找两个结果都包含的元组。
Natural Join(自然连接)
自然连接把两个关系中 同名属性值相等 的元组合并起来。
设:
- 在模式 上
- 在模式 上
则: 是模式 上的关系,其中只有当两个元组在公共属性 上取值相同,才合并。
等价写法
若公共属性是 B 和 D,则:
性质
- 结合律:
- 交换律:
Example
查找计算机系教师及其授课课程标题:
Theta Join(-join)
先做笛卡尔积,再按任意条件 进行筛选。
自然连接 vs theta 连接
- 自然连接:自动按公共属性相等匹配
- theta 连接:匹配条件由你显式指定
Outer Join(外连接)
普通连接只保留“匹配成功”的元组,可能丢信息。 外连接是为了 避免信息丢失。
先做连接,再把没匹配上的元组补回来,缺失部分用 null 填充。
类型
- Left Outer Join:保留左边所有元组
- Right Outer Join:保留右边所有元组
- Full Outer Join:两边都全保留
Example
若 instructor 中某个老师没有出现在 teaches 中:
- 普通 join 会把他丢掉
- left outer join 会保留这位老师,只是
course_id填 null
与 null 的关系
null表示未知或不存在- 所有涉及
null的比较大致上都视为 false - 以后会进一步学习三值逻辑。
用基本操作表示外连接
Left Outer Join( ⟕ ):
Right Outer Join( ⟖ ):
Full Outer Join( ⟗ ):
Semijoin(半连接)
记号
含义
从 中挑出那些 至少能和 中某个元组按条件 匹配 的元组。
定义
其中 是 的属性集合。
直观理解
- 连接后只保留左表 的列
- 先判断左表这一行能不能在右表里找到匹配;能找到就保留这行,找不到就删掉。最后只保留左表的列。
- 本质上是“筛左表”
和 SQL 的对应
它很接近:
EXISTSIN
Assignment(赋值)
赋值运算让复杂查询可以像“顺序程序”那样分步写。
形式
temp ← 某个关系代数表达式用途
- 把中间结果存到临时关系变量
- 后续表达式继续使用
这在写复杂查询、特别是 division 的等价表达式时很常见。
Division(除法)
含义
除法用于表达“对所有”这类查询。
定义
给定:
- 且
则: 是最大的关系 ,使得
直观理解
它用于找出那些“和 中每个元组都配对成功”的对象。
经典例子
设:
,
那么: 表示:
选修了 所有 Biology 系课程 的学生 ID。
重要理解
除法常对应自然语言中的:
- “所有”
- “全部”
- “every”
- “all”
广义投影与聚合
Generalized Projection(广义投影)
含义
广义投影在普通投影的基础上,允许在投影列表中出现算术表达式。
形式
其中每个 都可以是常量和属性构成的算术表达式。
例子
若 salary 是年薪,求月薪:
如果不额外重命名,这一列的名字通常就只是“这个表达式本身”,也就是可以理解成一列“salary/12”。
作用
不仅能“选列”,还能“算新列”。
Aggregate Functions(聚合函数)
常见聚合函数
slides 列出了:
avgminmaxsumcount
它们把一组值汇总成一个值。
聚合操作形式
设 是一个关系代数表达式:
- 是分组属性
- 是聚合函数
- 是属性名
则可以写成分组聚合表达式。
例子:求每个系的平均工资
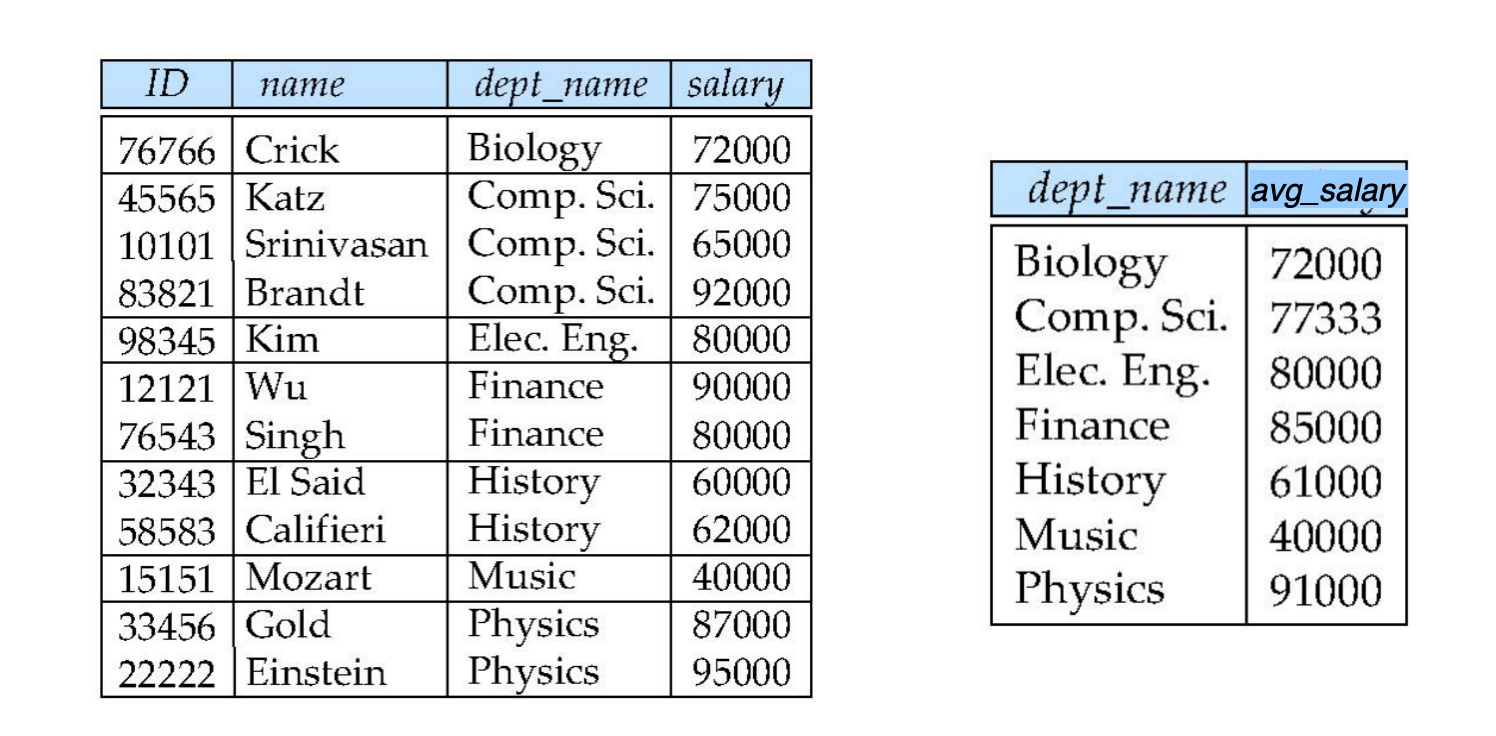
每个 dept_name 对应一个平均工资。
注意
聚合结果默认没有名字,可以:
- 用
rename - 或在聚合表达式中直接写别名 例如:
null 与三值逻辑
null 的逻辑语义
- 与
null比较,结果不是 true/false,而可能是 unknown - 因此采用三值逻辑:true / false / unknown
规则
unknown OR true = trueunknown OR false = unknowntrue AND unknown = unknownfalse AND unknown = falseNOT unknown = unknown
在选择中的影响
若选择条件计算为 unknown,则通常按 false 处理,不会选中该元组。
关系代数与 SQL 的联系
纯关系代数 vs 多重集关系代数
- Pure relational algebra:去重,因为 relation 是集合
- Multiset relational algebra:保留重复,更接近 SQL 语义。
为什么 SQL 更像 multiset
因为 SQL 默认允许重复行存在,除非显式 DISTINCT。
多重集下的规则
- selection:保留满足条件元组的重复次数
- projection:每个输入元组都投影,重复不自动消除
- cross product:重复次数相乘
- union:重复次数相加
- intersection:取较小重复次数
- difference:做差后的剩余次数
SQL 和关系代数的对应
- 普通 SQL
select A1, A2, ..., Anfrom r1, r2, ..., rmwhere P可理解为:
-
from:先把表放在一起,底层可看成笛卡尔积 -
where:在结果上做条件筛选 -
select:只保留需要的列
所以整体对应:
- 带 group by 的 SQL
select A1, A2, sum(A3)from r1, r2, ..., rmwhere Pgroup by A1, A2逻辑上是:
from:取基础数据where:筛选满足条件的行group by A1, A2:按A1, A2分组sum(A3):对每组做聚合
核心理解
from:准备数据 / 构造组合where:选行select:选列group by:分组聚合