

概述
这份笔记围绕计算机体系结构的入门核心展开,按“性能建模 → 定量分析 → ISA 组织方式”逐步展开。前半部分先建立性能比较与 CPU 时间公式,后半部分进入 ISA 设计与不同指令风格(Stack / Accumulator / Register-memory / Load-store)的对比,并配有表达式翻译示例,适合复习考试中的概念题与计算题。
目录
- Classes of Computers
- 按用途分类(PC / Server / Embedded / Mobile / Supercomputer)
- Flynn 并行分类(SISD / SIMD / MISD / MIMD)
- Understanding Performance
- Response Time 与 Throughput
- Performance 定义与执行时间关系
- Elapsed Time 与 CPU Time
- Quantitative Approaches
- CPU Performance Formula(IC / CPI / Clock)
- 加权平均 CPI
- Amdahl’s Law(含并行扩展上限)
- Great Architecture Ideas
- 8 个经典体系结构思想
- ISA
- ISA 的位置与作用
- ISA 规定内容与设计原则
- 4 类 ISA 写法与表达式示例
Classes of Computers
不同类型的计算机,设计目标不同,因此体系结构优化的重点也不同。
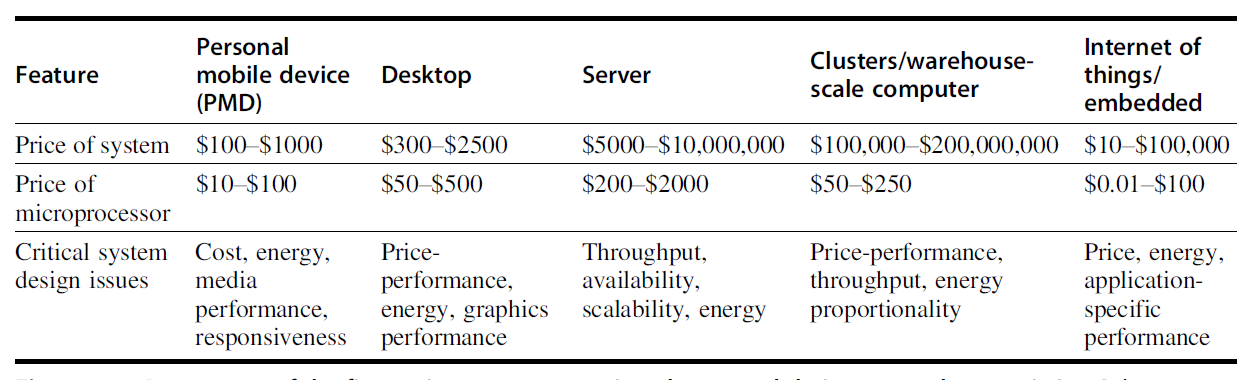
- Desktop computers / Personal Computers 特点:
- 通用性强,可运行多种第三方软件
- 面向单个用户
- 强调较低成本下的良好性能
关注重点:
- 单用户体验
- 响应速度
- 性价比
- Server computers 特点:
- 为少数复杂应用提供高性能
- 或为大量用户同时提供可靠服务
- 计算、存储、网络能力通常强于个人计算机
关注重点:
- 吞吐量(throughput)
- 可靠性(reliability)
- 可扩展性(scalability)
- Embedded computers 特点:
- 数量最多、种类最广
- 常作为系统内部的组成部分存在
- 对功耗、性能、成本有严格约束
关注重点:
- 低功耗
- 低成本
- 面向专用任务的效率
- Personal Mobile Devices 如:
- 智能手机
- 平板电脑
特点:
- 某些设计需求与 PC 相似
- 但更强调功耗、体积、交互体验
关注重点:
- 能效
- 响应速度
- 用户体验
- Supercomputer / Computer Cluster 特点:
- 由大量计算节点组成
- 规模可非常大,甚至达到建筑物级别
- 强调高性能、高容量、高可靠性
关注重点:
- 并行计算能力
- 总吞吐能力
- 大规模系统协同能力
Flynn 分类:按并行结构分类
前面的分类是“按用途分类”,Flynn 分类则是“按内部并行结构分类”。
- SISD
Single Instruction Stream, Single Data Stream
单指令流,单数据流
特点:
- 传统串行计算机模型
- 一条指令处理一组数据
- SIMD
Single Instruction Stream, Multiple Data Streams
单指令流,多数据流
特点:
- 同一条指令同时作用于多组数据
- 适合数据并行
- 常见于向量处理、GPU 等场景
- MISD
Multiple Instruction Streams, Single Data Stream
多指令流,单数据流
特点:
- 实际中较少见
- 理论意义大于工程应用
- MIMD
Multiple Instruction Streams, Multiple Data Streams
多指令流,多数据流
特点:
- 多个处理单元独立执行不同指令、处理不同数据
- 是现代多核处理器、并行机、服务器集群的重要基础模型
Understanding Performance
性能受到很多层面共同影响,不只是硬件本身。
- Algorithm 算法决定:
- 需要执行多少操作
算法越高效,总工作量通常越小。
- Programming language / Compiler / Architecture 它们共同决定:
- 每个操作会被翻译成多少条机器指令
即使完成同一个功能,不同语言、编译器、体系结构也可能导致机器指令数量不同。
- Processor and Memory System 它们决定:
- 指令执行得有多快 例如:
- 流水线
- cache
- 并行执行
- 存储层次结构
- I/O System(including OS) 它决定:
- 输入输出相关操作执行得有多快
系统性能不只取决于 CPU,也取决于:
- 磁盘
- 网络
- 操作系统调度
- I/O 开销
两个最基本的性能指标
- Response Time / Latency 定义:
- 一个事件从开始到完成所需要的时间
- 也可以理解为“做完一件事要多久”
适用场景:
- 单用户程序
- 交互式任务
- 关注单次任务完成速度的场景
例子:
- 打开一个程序需要几秒
- 运行一个程序需要几秒
- Throughput / Bandwidth 定义:
- 单位时间内完成的总工作量
- 也可理解为“单位时间能做多少事”
适用场景:
- 服务器
- 数据中心
- 多用户并发场景
例子:
- 每秒处理多少请求
- 每小时完成多少事务
Performance 的数学定义
体系结构中常把性能定义为执行时间的倒数:
这意味着:
- 执行时间越短,性能越高
- 执行时间越长,性能越低
Example
若 X 比 Y 快 n 倍,则有:
例子:
若程序在 A 上运行 10s,在 B 上运行 15s,则
所以:
- A 的性能是 B 的 1.5 倍
- 或者说 A 比 B 快 1.5 倍
Measuring Execution Time
- Elapsed Time 又称:
- 总响应时间
- 墙上时间(wall-clock time)
包括:
- CPU 处理时间
- I/O 时间
- 操作系统开销
- 等待时间
- 空闲时间等
作用:
- 反映整个系统层面的真实完成时间
- CPU Time 定义:
- CPU 真正用于处理该任务的时间
不包括:
- I/O 等待时间
- 其他程序占用 CPU 的时间
通常又可以分为:
- User CPU time:程序本身使用 CPU 的时间
- System CPU time:操作系统为该程序服务所花的 CPU 时间
Quantitative Approaches
- CPU Performance Formula
- Amdahl’s Law
目标是回答两类问题:
- 一个程序为什么快/慢?
- 某种改进到底能带来多大性能提升?
CPU Performance Formula
- 数据大小的基本单位
- bit:二进制位
- nibble:4 bits
- byte:8 bits
- word:字长
- 在很多嵌入式/移动处理器中常为 4 bytes(32 bits)
- 在很多桌面机/服务器中常为 8 bytes(64 bits)
- 二进制容量单位
- KiB = bytes = 1024 bytes
- MiB = bytes
- GiB = bytes
- TiB = bytes
- PiB = bytes
注意:
KiB / MiB / GiB 是二进制单位;
KB / MB / GB 在工程中有时按十进制使用,需根据具体语境区分。
CPU 性能的基本公式
CPU 执行时间可表示为:
也可写成:
其中:
- CPU Clock Cycles:程序执行所需总时钟周期数
- Clock Cycle Time:时钟周期长度
- Clock Rate:时钟频率,满足
Clock 的概念
- Clock Period 一个时钟周期持续的时间,即:
例如:
- Clock Frequency / Clock Rate 单位时间内的时钟周期数,即频率:
例如:
如何提升 CPU 性能
由
可知,提升性能(即减少 CPU Time)的方法有两种:
- 减少 Clock Cycles
- 减小 Clock Cycle Time(等价于提高 Clock Rate)
TIP硬件设计中常常存在 trade-off:
- 更高的时钟频率,可能会导致更多的时钟周期
- 更少的时钟周期,可能要求更复杂的设计,从而限制频率提升
所以不能只看一个指标,必须综合分析。
CPU Time Example
- Computer A: 2GHz clock, 10s CPU time
- 设计 Computer B
- 目标 CPU time = 6s
- 但新设计会使所需 clock cycles 变为 A 的 1.2 倍
问:Computer B 的时钟频率至少应为多少?
NOTE先求 A 的总时钟周期数:
由于 B 需要 1.2 倍周期数:
又因为:
所以:
Computer B 至少需要 4GHz 时钟频率。
Instruction Count 与 CPI
为了进一步拆解 CPU 时间,引入两个核心概念:
- Instruction Count(IC) 程序执行过程中实际执行的指令总数。
Instruction Count 由以下因素决定:
- 程序本身
- ISA(指令集体系结构)
- 编译器
- CPI(Cycles Per Instruction) 平均每条指令需要的时钟周期数:
CPI 主要由 CPU 硬件实现 决定。
CPU 性能公式的完整展开
由
可得:
或者写成:
CPU Performance 的三个核心因素
CPU 执行时间由三个因素共同决定:
- Instruction Count
- CPI
- Clock Cycle Time(或 Clock Rate)
即:
- IC:程序需要多少条指令
- CPI:每条指令平均花多少周期
- Clock Cycle Time:每个周期有多长
分析 CPU 性能时,不能只看单一指标,比如:
- 时钟频率高,不一定更快
- CPI 低,不一定更快
- Instruction Count 少,也不一定更快
必须综合比较三者。
平均 CPI(加权平均)
平均 CPI 不是简单平均,而是按指令占比加权:
其中:
表示第 类指令在程序中的相对频率。
Amdahl’s Law
Amdahl 定律用于分析:
对系统某一部分进行加速后,整体性能最多能提升多少。
公式为:
其中:
- :原执行时间中,可被改进部分所占比例
- :该部分本身被加速的倍数
若程序中只有一部分能受益于优化,那么整体加速比一定受限。
即使局部提速很多倍,整体提升也不可能无限大。
Amdahl 定律体现了一个核心思想:
系统性能瓶颈往往由“没有被优化的那部分”决定。
因此体系结构设计中要特别重视:
- 找到主要瓶颈
- 优先优化最常用、最耗时的部分
Amdahl 定律的等价理解
把总执行时间归一化为 1:
- 其中 这一部分可以被优化
- 剩下的 无法被优化
优化之后:
- 不可优化部分时间不变
- 可优化部分时间缩短为原来的
所以新时间为:
而整体加速比就是:
若把旧时间归一化为 1,就得到上面的标准形式。
常见结论
- 局部优化再强,也受“未优化部分”限制 若 ,则:
这说明:
- 能优化的部分再快也不是无限提升
- 真正卡上限的是不能优化的那部分
- 应优先优化占时间最多的部分
若某部分只占总时间 5%,即使把它加速 100 倍,整体收益也很有限。
所以体系结构设计不是“哪里能优化就优化哪里”,而是:
优先优化 common case / bottleneck。
Amdahl 定律在并行中的意义
Amdahl 定律也常用于分析多处理器加速:
- 可并行部分:可以分给多个处理器同时做
- 串行部分:仍然只能顺序执行
若程序串行部分占比为 ,并行部分占比为 ,使用 个处理器,则:
当 时:
所以:
- 处理器数量不是越多越“线性加速”
- 串行部分会成为并行扩展的根本上限
Great Architecture Ideas
- Design for Moore’s Law
- 设计不能只看今天的工艺条件
- 要预判未来晶体管数量、集成度、成本变化
- 架构要有前瞻性
- 好的设计应该能随着工艺进步继续获益
- Use Abstraction to Simplify Design
- 用层次化、抽象化的方法管理复杂系统
- 没有抽象,大系统无法设计、验证和维护
- Make the Common Case Fast
- 不要平均用力,而要优先优化最常见、最耗时的情况
- cache 利用局部性
- branch prediction 优化高频分支
- 常见指令走快路径
- Performance via Parallelism
- 用并行来提升吞吐与性能
- instruction-level parallelism
- data-level parallelism
- thread-level parallelism
- request-level parallelism
- Performance via Pipelining
- 把任务拆成多个阶段重叠执行
- 不是缩短单条指令的延迟
- 而是提升整体吞吐率
- Performance via Prediction
- 在结果还没真正出来之前,先大胆猜测并提前执行
- branch prediction
- speculative execution
- memory dependence prediction
- Hierarchy of Memories
- 用多级存储层次平衡速度、容量、成本
- register
- cache
- main memory
- storage
- 快的存储小而贵
- 慢的存储大而便宜
- 通过 locality 让程序“感觉自己总在用快存储”
- Dependability via Redundancy
- 用冗余来换取可靠性
- ECC
- RAID
- 多模冗余
- 容错设计
ISA
ISA = Instruction Set Architecture,即指令集体系结构。
它规定了程序员可见的机器接口,因此常被称为:
hardware / software interface
ISA 在系统中的位置
ISA 往上连接软件:
- compiler
- assembler
- operating system
- application
ISA 往下连接硬件实现:
- datapath
- control
- pipeline
- cache
- execution units
因此:
- 同一套 ISA 可以对应不同微结构实现
- 程序只要面向 ISA 编写,就不需要关心具体实现细节
- 一个处理器更快、另一个更省电,不代表 ISA 不同,可能只是 microarchitecture 不同
从高级语言到机器执行
可以按下面理解:
- 高级语言程序经过 compiler 变成汇编
- 汇编经过 assembler 变成机器码
- CPU 按 ISA 规定解释并执行机器码
这里要区分三层:
- 高级语言:面向人写算法与逻辑
- 汇编语言:机器指令的符号化表示
- 机器语言:CPU 真正执行的 bit pattern
结论:
- 一条高级语言语句通常会变成多条汇编指令
- 一条汇编通常对应一条机器指令
- 指令集就是该机器支持的全部机器指令集合
ISA 主要规定什么
- 操作数存在哪里
- register
- memory
- stack
- accumulator
这是后面分类的基础。
- 一条指令有几个显式操作数
- 0 地址
- 1 地址
- 2 地址
- 3 地址
这里的“地址”可以理解为:一条指令里,显式写出来的操作数个数(通常是寄存器号/内存地址,不含隐式操作数)。
- 0 地址指令:不写操作数,操作数默认在栈顶(隐式)。
- 例:
add(默认取栈顶两个数相加)
- 例:
- 1 地址指令:写 1 个显式操作数,另一个操作数通常是隐式累加器
ACC。- 例:
ADD X,语义常为ACC = ACC + M[X]
- 例:
- 2 地址指令:写 2 个显式操作数,常见语义是“第一个既是源也是目的”。
- 例:
ADD R1, R2,语义常为R1 = R1 + R2
- 例:
- 3 地址指令:写 3 个显式操作数,两个源 + 一个目的。
- 例:
ADD R3, R1, R2,语义为R3 = R1 + R2
- 例:
一般来说,地址数越多,单条指令表达能力越强,但指令编码与硬件实现也会更复杂。
操作数个数会影响:
- 指令格式
- 代码长度
- 硬件复杂度
- 编译难度
- 如何指定操作数位置
也就是 addressing modes(寻址方式):
- register
- immediate
- indirect
- displacement
寻址方式越丰富,表达能力通常越强,但硬件也更复杂。
- 支持哪些数据类型与宽度
- byte
- int
- float
- double
- string
- vector
- 支持哪些操作
- add
- sub
- mul
- move
- compare
- load / store
- branch
指令集设计原则与影响因素
基本原则
- Compatibility:兼容已有软件,降低迁移成本
- Versatility:能支持多种应用需求
- High efficiency:执行与编码都要高效
- Security:要支持权限、异常、隔离等机制
影响因素
- Technology:工艺水平决定可实现的复杂度与寄存器规模
- Computer architecture:系统目标不同,ISA 风格也不同
- Operating system:要求 ISA 支持特权、中断、地址空间等机制
- Compiler:编译器越强,ISA 越可以简洁规则
- Application:不同应用会推动专用指令或数据类型支持
4 类 ISA 写法
- Stack
- Accumulator
- Register-memory
- Load-store
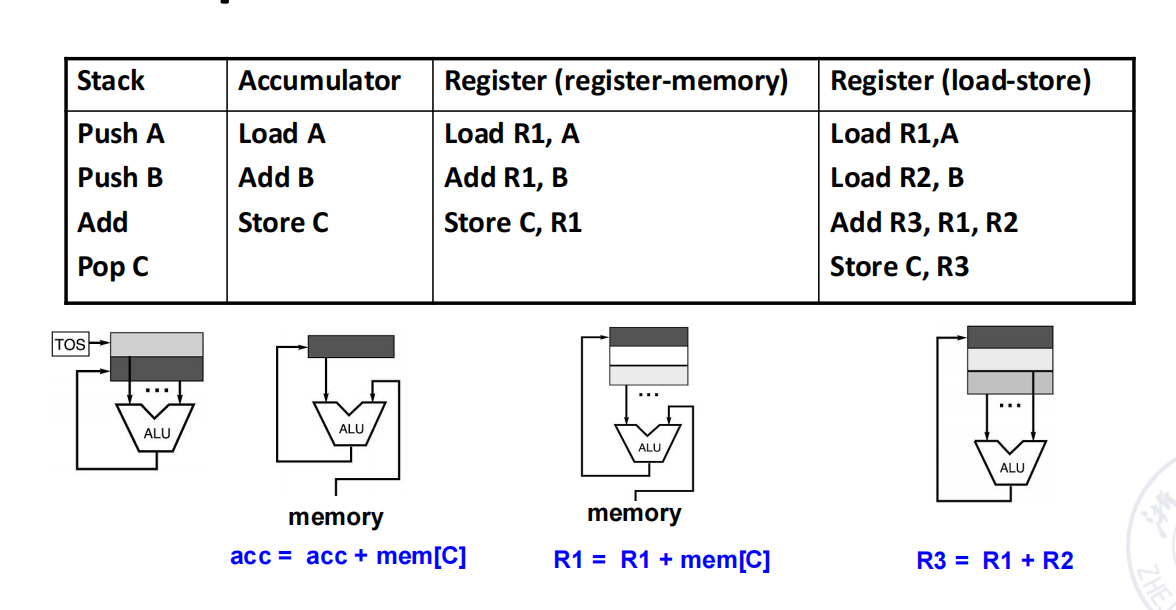
其中:
- Stack 和 Accumulator 都有隐式操作数
- Register-memory 和 Load-store 都属于 GPR(通用寄存器) 思路
- 区别在于 ALU 指令能不能直接访问内存
| 类型 | 操作数特点 | ALU 指令是否可直接访存 | 记忆点 |
|---|---|---|---|
| Stack | 0 地址,操作数默认在 TOS | 不直接写地址,靠 push/pop 间接访存 | 栈顶隐式取数 |
| Accumulator | 1 个隐式操作数 acc + 1 个显式内存操作数 | 可以,围绕 acc 运算 | 结果始终回到累加器 |
| Register-memory | 寄存器显式出现,ALU 可直接读内存 | 可以 | 少一次 load,但指令格式不规整 |
| Load-store | ALU 只操作寄存器 | 不可以 | 先装入寄存器再算,最规则 |
补充:
- Memory-memory architecture,属于扩展知识点
- 它把操作数直接放在内存里计算,但现代通用处理器中并不主流
Example 1
C = A + B
这个例子是最基础的分类题,关键是看“操作数放哪、结果放哪”。
- Stack
push Apush Baddpop C分析:
push A、push B把两个操作数压到栈顶add默认取栈顶两个数作为隐式操作数- 运算结果仍留在栈顶
pop C再把结果写回内存位置C
要点:
- 指令最短
- 但中间值管理严重依赖栈
- Accumulator
load Aadd Bstore C分析:
load A:把A送入累加器accadd B:执行acc = acc + mem[B]store C:把acc的值写回C
要点:
- 一个操作数是隐式的
acc - 运算始终围绕累加器展开
- Register-memory
load R1, Aadd R1, Bstore C, R1分析:
load R1, A:先把A放入寄存器add R1, B:执行R1 = R1 + mem[B]store C, R1:把结果写回C
要点:
- ALU 指令既能用寄存器,也能直接读内存
- 指令数比 load-store 少,但实现较复杂
- Load-store
load R1, Aload R2, Badd R3, R1, R2store C, R3分析:
- 先用
load把A、B都搬到寄存器 add只在寄存器之间运算- 最后再
store回内存
要点:
- 规则最整齐
- 是现代 RISC 最典型的风格
Example 2
D = A * B - (A + C * B)
也就是:
- 先算
A * B - 再算
A + C * B - 最后做减法
不同 ISA 的区别,主要体现在中间结果存放位置。
- Stack
1. push A2. push B3. mul4. push A5. push C6. push B7. mul8. add9. sub10. pop D分析:
- 第 1 到 3 步先把
A * B压成一个栈顶结果 - 第 4 到 8 步继续在栈上算出
A + C * B - 此时栈顶两个值正好是
A * B和A + C * B sub直接对栈顶两个隐式操作数做减法- 最后
pop D
要点:
- 代码完全围绕栈展开
- 中间结果不显式命名,但执行顺序必须非常清楚
- Accumulator
1. load B2. mul C3. add A4. store D5. load A6. mul B7. sub D8. store D分析:
- 第 1 到 4 步先算出
A + C * B,暂存到D - 第 5 到 6 步再算
A * B - 第 7 步执行
acc = acc - mem[D] - 第 8 步把最终结果写回
D
要点:
- 因为只有一个累加器,中间结果必须及时落内存
- 所以 accumulator 架构经常出现“算一点,存一次”
- Register-memory
1. load R1, A2. mul R1, B /* A * B */3. store D, R14. load R2, C5. mul R2, B /* C * B */6. add R2, A /* A + C * B */7. sub D, R2 /* A * B - (A + C * B) */8. store D, R2分析:
R1先保存A * B- 因为后面还要继续算
A + C * B,所以把R1的结果先存到D R2再负责另一部分表达式sub D, R2是把内存中的D直接拿来做减法
要点:
- ALU 可以直接读内存,所以最后一步不必先把
D再load到寄存器 - 比 load-store 少一些搬运,但格式不够统一
- Load-store
1. load R1, A2. load R2, B3. load R3, C4. mul R7, R3, R2 /* C * B */5. add R8, R7, R1 /* A + C * B */6. mul R9, R1, R2 /* A * B */7. sub R10, R9, R8 /* A * B - (A + C * B) */8. store D, R10分析:
- 所有源数据先进入寄存器
- 中间结果全部保存在寄存器
R7、R8、R9、R10 - 最后只在结果写回时访问一次内存
要点:
- 结构最规则,最适合流水线和编译器优化
- 代价是前面要多写几条
load
- Memory-memory(补充)
mul D, A, Bmul E, C, Badd E, A, Esub E, D, E理解即可:
- 操作数直接来自内存
- 中间结果也常直接放内存
- 表达力强,但现代高性能处理器中并不常见
TIP为什么现代 ISA 更偏向 GPR / Load-store?
- Registers 比 memory 快得多
- 寄存器值可以立即使用
- 编译器更容易做变量分配
- 寄存器编号比内存地址短,代码更紧凑
- 规则化的 load-store 更适合流水线和并行执行
因此现代新架构通常采用:
GPR + load-store 的组织方式。