
概述
本章是数据库系统的导论,回答三个核心问题:
- 为什么需要数据库系统? — 文件系统的七大缺陷驱使我们转向 DBMS
- 数据库系统如何组织数据? — 三层抽象(物理层 / 逻辑层 / 视图层)与数据独立性
- 数据库系统由哪些部分构成? — 数据模型、数据库语言(DDL/DML)、数据库引擎(存储管理器 / 查询处理器 / 事务管理)、用户与 DBA
目录
- Database Systems
- Files vs. Databases
- Database & DBMS
- 数据库的两种使用模式
- 数据库系统核心要求
- View of Data
- Three-Level Abstraction
- Physical / Logical / View Level
- Schema and Instance
- Data Independence
- Data Models
- Relational Model
- Database Languages
- DDL / Data Dictionary
- DML / SQL / API
- Database Design
- Entity-Relationship Model
- Normalization Theory
- Database Engine
- Storage Manager
- Query Processor
- Transaction Management
- Database Users and Administrators
- 四类用户
- DBA 职责
Database Systems
数据库系统用于管理具有以下特征的数据集合:
- 高价值(Highly valuable)
- 规模较大(Relatively large)
- 多用户并发访问(Accessed by multiple users and applications, often at the same time)
Files vs. Databases
| 文件系统 | 数据库系统 | |
|---|---|---|
| 架构 | App → Files | App → DBMS → Database |
| 数据管理 | 各应用独立维护 | 集中统一管理 |
| 问题 | 冗余、不一致、难并发、难恢复 | 由 DBMS 统一解决 |
👉 DBMS 是应用和数据库之间的中间层
file system会导致:
- Data redundancy and inconsistency(数据冗余和不一致)
- Data isolation(数据孤立)
- Difficulties in accessing data(数据访问困难)
- Integrity problems(完整性问题)
- 例如:年龄不能为负数,成绩必须在0-100之间
- Atomicity problems(原子性问题)
- 例如:转账操作中,扣款成功但未到账,导致数据不一致
- Concurrent access anomalies(并发访问异常)
- 例如:两个用户同时修改同一条记录,可能导致数据丢失或不一致
- Security problems(安全问题)
- 例如:未经授权的用户访问敏感数据,导致数据泄露或篡改
Characteristics of Databases:
- Data persistence(数据持久性)
- Convenience in accessing data(数据访问便利性)
- Data integrity (数据完整性)
- Concurrency control for multiple users(多用户并发控制)
- Failure recovery(故障恢复)
- Security control(安全控制)
Database & DBMS
Database: 一个企业中相互关联的数据集合(A collection of interrelated data about an enterprise)
DBMS(Database Management System): 管理数据库的软件系统,目标是:
Provide a way to store and retrieve data conveniently and efficiently.
DBMS 负责:存储与检索、权限控制、并发处理、崩溃恢复
数据库的两种使用模式
Online Transaction Processing
- 大量用户同时使用
- 每次操作数据量小(查询 + 小更新)
- 典型场景:银行转账、电商下单
Data Analytics
- 处理数据以得出结论、推断规则
- 结果用于驱动业务决策
- 典型场景:用户行为分析、销售预测
数据管理两方面
Defining Structures
定义数据的组织方式:表结构、字段类型、主键/外键、约束等。
create table student ( id int primary key, name varchar(20), age int);Manipulation
增删改查(INSERT / DELETE / UPDATE / SELECT)
数据库系统核心要求
Safety
- 防止数据丢失与未授权访问
- 崩溃后可恢复(日志机制 + 备份)
Concurrency Control
多用户同时操作时必须保证数据正确性。
例:余额 100,T1 和 T2 各存 50,无并发控制结果可能为 150,正确结果应为 200。
View of Data
数据库系统的一个重要目标:
Provide users with an abstract view of the data. 隐藏数据如何存储和维护的细节。
为此,数据库采用 Three-level abstraction(三层抽象结构)。
Three-Level Abstraction of Databases
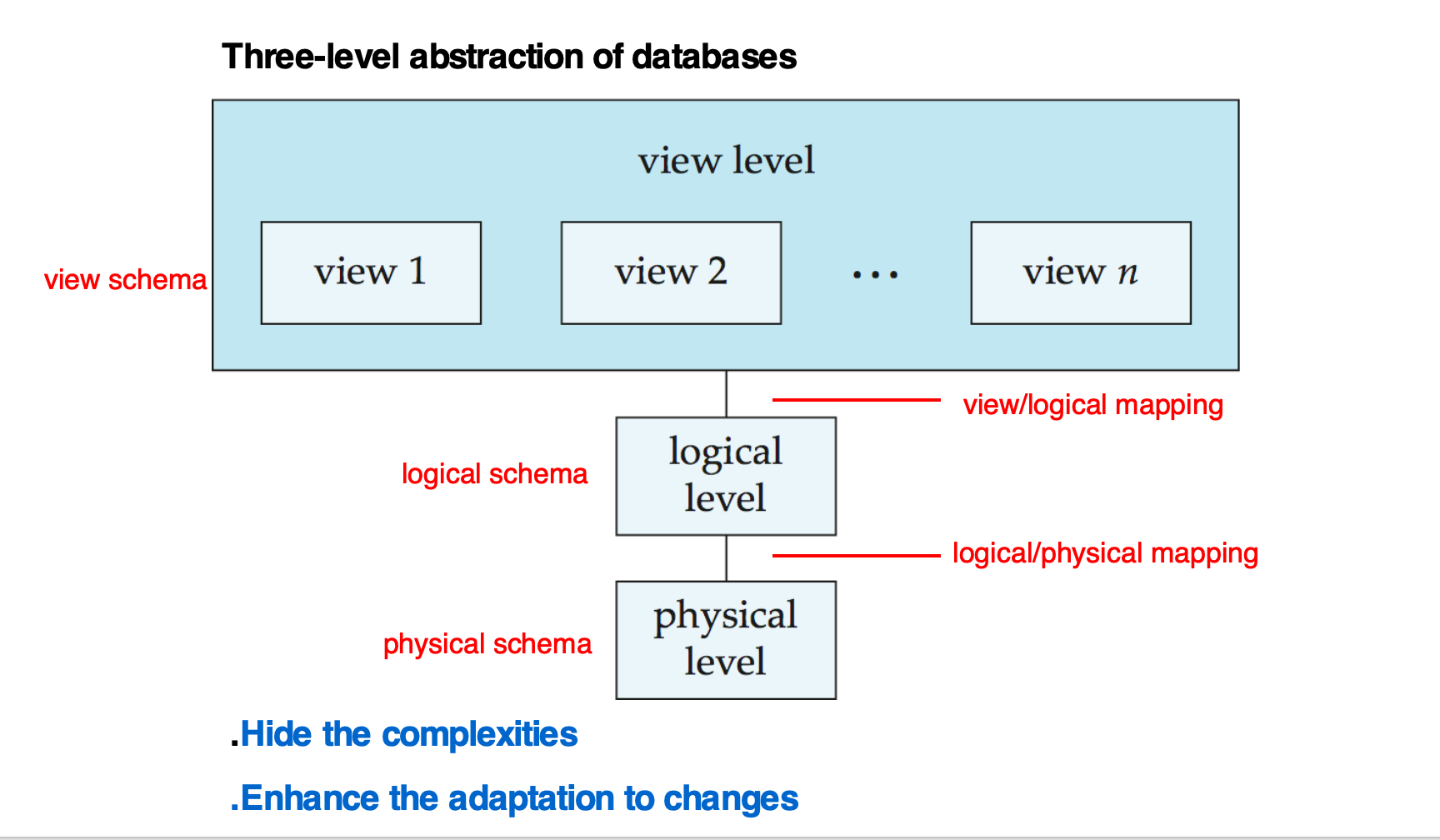
数据库分为三层:
View Level ↓ (view/logical mapping)Logical Level ↓ (logical/physical mapping)Physical LevelPhysical Level(物理层)
- 描述数据如何真正存储
- 文件组织方式
- 索引结构
- 存储块结构
👉 关注 “how data are stored”
例如:
- 表是否顺序存储?
- 是否有 B+ 树索引?
- 数据在磁盘页中如何排列?
Logical Level(逻辑层)
- 描述数据库存储了什么数据
- 描述数据之间的关系
- 定义表、属性、约束
👉 关注 “what data are stored”
例如:
Instructor(ID, name, dept_name, salary)Department(dept_name, building, budget)程序员和 DBA 主要工作在这一层。
View Level(视图层)
- 只显示数据库的一部分
- 不同用户看到不同视图
- 用于简化使用与安全控制
例如:
教务人员:
- 只能看到 student 信息
不能看到:
- instructor 的 salary
👉 View = 数据库的子集表示
三层抽象的作用
- Hide the complexities(隐藏复杂性)
- Enhance the adaptation to changes(增强对变化的适应能力)
Schema and Instance
类似于编程语言中的:
- type(类型)
- variable(变量)
Schema
数据库的逻辑结构
类似于程序中的“类型定义”。
例如:
数据库包含:
- customers
- accounts
- 以及它们之间的关系
Schema 是设计,不是数据本身。
分类
-
Physical Schema(物理模式)
- 数据库在物理层的设计
-
Logical Schema(逻辑模式)
- 数据库在逻辑层的设计
- 最重要,应用程序依赖它
-
View Schema(视图模式)
- 不同用户看到的子模式
Instance
数据库在某一时刻的实际内容
类似于变量当前的 value。
Schema 是“结构”, Instance 是“数据”。
Data Independence
数据独立性 = 某一层改变,不影响上一层。
Physical Data Independence(物理数据独立性)
可以修改 physical schema 而不改变 logical schema
例如:
- 改变索引结构
- 改变文件存储方式
应用程序不需要修改。
👉 Applications depend on logical schema, not physical schema.
Logical Data Independence(逻辑数据独立性)
可以修改 logical schema 而不改变 user view schema
例如:
- 增加字段
- 重构表结构
用户视图不需要改变。
Data Models
数据模型是:
A collection of tools for describing:
- Data(数据)
- Data relationships(联系)
- Data semantics(语义)
- Data constraints(约束)
常见数据模型
- Relational Model(关系模型)
- Entity-Relationship Model(实体-联系模型)
- Object-based Data Models
- Object-oriented
- Object-relational
- Semistructured Data Model(XML)
- 旧模型:
- Network Model(网状模型)
- Hierarchical Model(层次模型)
Relational Model(关系模型)
由 Ted Codd 提出(Turing Award 1981)
特点:
- 数据以表(table)形式表示
- 每张表由:
- Columns(Attributes,属性)
- Rows(Tuples,元组)
例如:
| ID | name | dept_name | salary |
|---|
- 列 = 属性(Attribute)
- 行 = 元组(Tuple)
关系模型是当前最广泛使用的数据模型。
👉 Chapter 2 将详细讨论。
Database Languages
Data Definition Language (DDL)
DDL 用于定义数据库的 schema(结构规范),例如:
create table instructor ( ID char(5), name varchar(20), dept_name varchar(20), salary numeric(8,2), primary key (ID), foreign key (dept_name) references Department, check (salary >= 60000));DDL 编译器会生成一组表模板,存储在 数据字典(Data Dictionary) 中。
Data Dictionary(数据字典)
数据字典保存 元数据(Metadata,即关于数据的数据),包括:
- Database schema(数据库模式)
- Integrity constraints(完整性约束)
- Primary key:唯一标识一条记录
- 例:
ID唯一标识每位 instructor
- 例:
- Referential integrity(参照完整性):外键引用必须在目标表中存在
- 例:instructor 中的
dept_name必须出现在 department 表中
- 例:instructor 中的
- Check 约束:字段值满足指定条件
- 例:
salary >= 60000
- 例:
- Primary key:唯一标识一条记录
- Authorization(权限):哪些用户可以访问哪些数据
Data Manipulation Language (DML)
数据控制语言用于查询和修改数据库中的数据,例如:
主要分为两类:
- Procedural DML(过程式 DML):用户指定如何获取结果,例如:使用游标(cursor)逐行处理数据。
- 过程式语言是类似C语言要将怎么查找,用什么查找写出来的。
- Nonprocedural DML(非过程式 DML):用户只指定想要什么结果,数据库系统负责如何获取,例如:SQL 查询语言。
- 非过程式语言是类似SQL语言只要写出想要什么结果,数据库系统会自己决定怎么查找。数据库系统会自行优化。
SQL Query Language
SQL 是最流行的非过程式 DML,具有以下特点:
- Declarative(声明式):用户只描述想要的结果,不关心实现细节。
- Set-oriented(面向集合):操作整个数据集,而不是逐行处理。
- High-level(高级):比过程式语言更抽象,易于使用。
select name from instructor where dept_name = 'Comp. Sci.';Application Program Interface(API)
SQL 不是完整编程语言,
应用程序必须通过嵌入式 SQL 或数据库 API 来访问数据库,
数据处理与业务逻辑分离。
Web 应用访问数据库完整流程
┌──────────────────────┐│ 用户浏览器 ││ (Browser / Client) │└──────────┬───────────┘ │ HTTP Request ▼┌──────────────────────┐│ Web Server ││ (Nginx / Apache) │└──────────┬───────────┘ │ 转发请求 ▼┌──────────────────────┐│ 应用程序服务器 ││ (Java / Python / Go) ││ 业务逻辑处理层 │└──────────┬───────────┘ │ │ 调用数据库 API │ (JDBC / ODBC / ORM) ▼┌──────────────────────┐│ DBMS ││ (MySQL / PostgreSQL)││ SQL解析 + 优化 + 执行 │└──────────┬───────────┘ │ │ 访问数据文件 ▼┌──────────────────────┐│ 数据库文件 ││ (磁盘上的数据页/索引) │└──────────────────────┘数据返回流程
数据库文件 ▲ │DBMS 执行结果 ▲ │API 返回结果集 ▲ │应用程序处理数据 ▲ │Web Server 返回 HTTP Response ▲ │用户浏览器显示页面每一层的职责:
- 浏览器
- 发送 HTTP 请求
- 接收 HTML / JSON 响应
- 展示页面
- Web Server
- 处理网络连接
- 转发请求给应用程序
- 应用程序服务器(Host Language)
- 编写业务逻辑
- 构造 SQL
- 调用数据库 API
- 处理返回数据
例如:
cursor.execute("SELECT * FROM instructor")- API 层
- JDBC / ODBC / ORM
- 负责把 SQL 发送给数据库
- 接收结果
- DBMS
内部做:
- SQL 解析
- 查询优化
- 执行计划生成
- 数据读取
- 事务管理
- 并发控制
- 数据库文件
- 数据页
- 索引页
- 日志文件
Database Design
数据库设计主要有两种方法:
Entity-Relationship Model(实体-联系模型)
- 将企业建模为一组数据实体(entities)和联系(relationships)
- 用 E-R 图(entity-relationship diagram) 直观表示
例如,instructor 与 department 之间通过 member 联系:
┌─────────────────┐ ◇ ┌─────────────────┐│ instructor │─────── member ────── │ department ││─────────────────│ │─────────────────││ <u>ID</u> │ │ <u>dept_name</u>││ name │ │ building ││ salary │ │ budget │└─────────────────┘ └─────────────────┘矩形 = 实体集,菱形 = 联系集,下划线属性 = 主键。
👉 E-R 模型将在 Part Two(Chapter 6, 7) 详细介绍。
Normalization Theory(规范化理论)
规范化理论用于形式化地判断哪些数据库设计是”坏”的,并提供检验方法。
考虑下面这张将 instructor 与 department 合并的表:
| ID | name | salary | dept_name | building | budget |
|---|---|---|---|---|---|
| 22222 | Einstein | 95000 | Physics | Watson | 70000 |
| 12121 | Wu | 90000 | Finance | Painter | 120000 |
| 32343 | El Said | 60000 | History | Painter | 50000 |
| 45565 | Katz | 75000 | Comp. Sci. | Taylor | 100000 |
| 98345 | Kim | 80000 | Elec. Eng. | Taylor | 85000 |
| 76766 | Crick | 72000 | Biology | Watson | 90000 |
| 10101 | Srinivasan | 65000 | Comp. Sci. | Taylor | 100000 |
| 58583 | Califieri | 62000 | History | Painter | 50000 |
| 83821 | Brandt | 92000 | Comp. Sci. | Taylor | 100000 |
| 15151 | Mozart | 40000 | Music | Packard | 80000 |
| 33456 | Gold | 87000 | Physics | Watson | 70000 |
| 76543 | Singh | 80000 | Finance | Painter | 120000 |
❓ 这个设计有什么问题?
- 数据冗余(Redundancy):
dept_name、building、budget在每个属于同一系的教师行中重复存储 - 更新异常(Update Anomaly):若某系搬楼,需修改多行,容易遗漏导致不一致
- 插入异常(Insertion Anomaly):若一个系还没有教师,该系的信息无法被记录
- 删除异常(Deletion Anomaly):若删掉某系最后一个教师,该系的所有信息也随之丢失
👉 规范化理论将在 Part Two(Chapter 6, 7) 详细讨论。
Database Engine
数据库系统(database engine)被划分为若干模块,每个模块负责整体系统的一部分功能。
数据库系统的功能组件可分为三大类:
- Storage Manager(存储管理器)
- Query Processor(查询处理器)
- Transaction Management(事务管理组件)
Storage Manager
Storage Manager 是一个程序模块,提供底层数据库数据与应用程序/查询之间的接口。
负责的任务:
- 与 OS 文件管理器交互
- 数据的高效存储、检索与更新
Storage Manager 的组成组件:
| 组件 | 描述 |
|---|---|
| File manager | 管理磁盘存储空间的分配及数据文件结构 |
| Buffer manager | 负责将数据从磁盘读入内存,管理内存缓冲区 |
| Authorization and integrity manager | 检验完整性约束,处理用户权限 |
| Transaction manager | 确保在事务并发执行和系统故障时数据库保持一致状态 |
Storage Manager 实现的数据结构:
- Data files:存储数据库本身
- Data dictionary:存储数据库结构的元数据,特别是数据库的 schema
- Indices:提供对数据项的快速访问;数据库索引存储指向持有特定值的数据项的指针
- Statistical data:存储关于数据的统计信息,供查询优化器使用
👉 将在 Part Five(Chapters 12, 13, 14) 详细介绍。
Query Processor
Query Processor 的组成组件:
- DDL interpreter:解释 DDL 语句,并将定义记录到数据字典中
- DML compiler:将查询语言中的 DML 语句翻译为由低级指令组成的evaluation plan,供查询执行引擎理解
- DML compiler 执行query optimization:从多种可能的执行计划中选取代价最低的方案
- Query evaluation engine:执行由 DML compiler 生成的低级指令
Query Processing 的步骤:
- Parsing and translation
- Optimization
- Evaluation
query │ ▼parser and translator ──→ relational-algebra expression │ ▼ optimizer ←── statistics about data │ ▼evaluation engine ←────────── execution plan │ ▼query output │ └── data (from data files)👉 将在 Part Six(Chapters 15, 16) 详细介绍。
Transaction Management
Transaction 是执行单一逻辑功能的一组操作集合。
Transaction Management 的两大组件:
- Recovery Manager:确保在系统故障和事务故障发生时,数据库仍能保持一致的状态
- Concurrency-control manager:控制并发事务之间的交互,确保数据库的一致性
👉 将在 Part Seven(Chapters 17, 18, 19) 详细介绍。
Database Users and Administrators
系统整体架构
数据库系统的用户与组件层次如下:
Naïve users Application programmer DBA / Data Analyst │ │ │ ▼ │ │ Database application ←─────────────┘ │ │ │ ▼ │ API (ODBC, JDBC, Hibernate …) │ │ │ ▼ ▼ DBMS (Oracle, MySQL, PostgreSQL, 达梦, GaussDB …) ◄──┘ │ ▼ OS (Unix/Linux, Windows, Mac OS …) │ ▼ Database四类数据库用户
用户根据与系统交互方式的不同进行区分:
| 用户类型 | 描述 | 使用工具 |
|---|---|---|
| Naïve users(普通用户) | 调用已有的应用程序,不直接编写 SQL;典型例子:网页用户、银行柜员、文职人员 | Application interfaces(应用程序界面) |
| Application programmers(应用程序员) | 通过 DML 调用与系统交互,编写应用程序 | Application programs(应用程序) |
| Sophisticated users(高级用户 / 分析师) | 直接使用查询工具提交查询,进行数据分析 | Query tools(查询工具) |
| Database administrators(数据库管理员) | 协调数据库系统的所有活动,深入了解企业信息资源与需求 | Administration tools(管理工具) |
Database Administrator(DBA)
DBA 负责协调数据库系统的所有活动,对企业的信息资源和需求有深刻理解。
DBA 的职责包括:
- Schema definition:定义数据库模式
- Storage structure and access method definition:定义存储结构和访问方法
- Schema and physical organization modification:修改模式和物理组织结构
- Granting user authority:授予用户访问数据库的权限
- Routine maintenance:
- Performance Tuning:监控性能,响应需求变化
- Backing up:定期将数据库备份到远程服务器
- Disk space management:确保有足够的磁盘空间用于正常运营,并按需扩容