
Classes of Computers
不同类型的计算机,设计目标不同,因此体系结构优化的重点也不同。
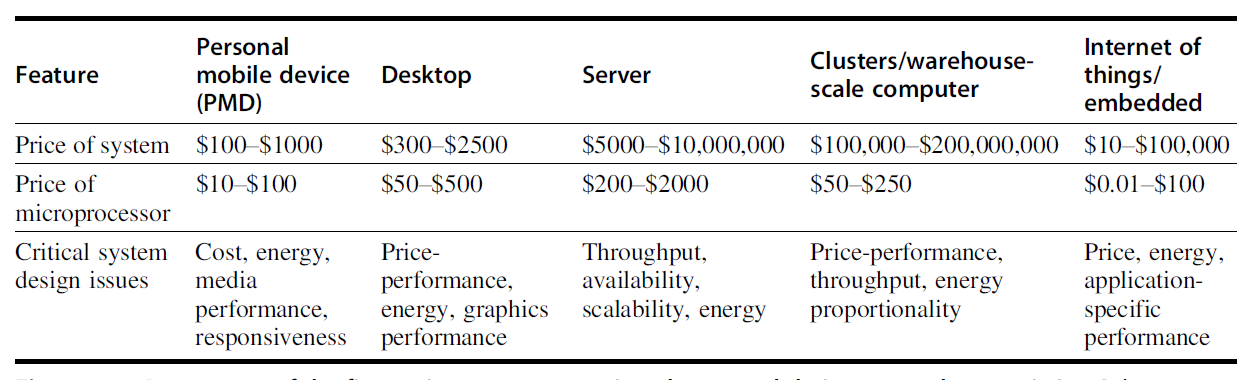
Desktop computers / Personal Computers
特点:
- 通用性强,可运行多种第三方软件
- 面向单个用户
- 强调较低成本下的良好性能
关注重点:
- 单用户体验
- 响应速度
- 性价比
Server computers
特点:
- 为少数复杂应用提供高性能
- 或为大量用户同时提供可靠服务
- 计算、存储、网络能力通常强于个人计算机
关注重点:
- 吞吐量(throughput)
- 可靠性(reliability)
- 可扩展性(scalability)
Embedded computers
特点:
- 数量最多、种类最广
- 常作为系统内部的组成部分存在
- 对功耗、性能、成本有严格约束
关注重点:
- 低功耗
- 低成本
- 面向专用任务的效率
Personal Mobile Devices
如:
- 智能手机
- 平板电脑
特点:
- 某些设计需求与 PC 相似
- 但更强调功耗、体积、交互体验
关注重点:
- 能效
- 响应速度
- 用户体验
Supercomputer / Computer Cluster
特点:
- 由大量计算节点组成
- 规模可非常大,甚至达到建筑物级别
- 强调高性能、高容量、高可靠性
关注重点:
- 并行计算能力
- 总吞吐能力
- 大规模系统协同能力
Flynn 分类:按并行结构分类
前面的分类是“按用途分类”,Flynn 分类则是“按内部并行结构分类”。
SISD
Single Instruction Stream, Single Data Stream
单指令流,单数据流
特点:
- 传统串行计算机模型
- 一条指令处理一组数据
SIMD
Single Instruction Stream, Multiple Data Streams
单指令流,多数据流
特点:
- 同一条指令同时作用于多组数据
- 适合数据并行
- 常见于向量处理、GPU 等场景
MISD
Multiple Instruction Streams, Single Data Stream
多指令流,单数据流
特点:
- 实际中较少见
- 理论意义大于工程应用
MIMD
Multiple Instruction Streams, Multiple Data Streams
多指令流,多数据流
特点:
- 多个处理单元独立执行不同指令、处理不同数据
- 是现代多核处理器、并行机、服务器集群的重要基础模型
Understanding Performance
性能受到很多层面共同影响,不只是硬件本身。
Algorithm
算法决定:
- 需要执行多少操作
算法越高效,总工作量通常越小。
Programming language / Compiler / Architecture
它们共同决定:
- 每个操作会被翻译成多少条机器指令
即使完成同一个功能,不同语言、编译器、体系结构也可能导致机器指令数量不同。
Processor and Memory System
它们决定:
- 指令执行得有多快 例如:
- 流水线
- cache
- 并行执行
- 存储层次结构
I/O System(including OS)
它决定:
- 输入输出相关操作执行得有多快
系统性能不只取决于 CPU,也取决于:
- 磁盘
- 网络
- 操作系统调度
- I/O 开销
两个最基本的性能指标
Response Time / Latency
定义:
- 一个事件从开始到完成所需要的时间
- 也可以理解为“做完一件事要多久”
适用场景:
- 单用户程序
- 交互式任务
- 关注单次任务完成速度的场景
例子:
- 打开一个程序需要几秒
- 运行一个程序需要几秒
Throughput / Bandwidth
定义:
- 单位时间内完成的总工作量
- 也可理解为“单位时间能做多少事”
适用场景:
- 服务器
- 数据中心
- 多用户并发场景
例子:
- 每秒处理多少请求
- 每小时完成多少事务
Performance 的数学定义
体系结构中常把性能定义为执行时间的倒数:
这意味着:
- 执行时间越短,性能越高
- 执行时间越长,性能越低
比较两台机器的性能
若 X 比 Y 快 n 倍,则有:
例子:
若程序在 A 上运行 10s,在 B 上运行 15s,则
所以:
- A 的性能是 B 的 1.5 倍
- 或者说 A 比 B 快 1.5 倍
Measuring Execution Time
老师接着区分了两种时间概念。
Elapsed Time
又称:
- 总响应时间
- 墙上时间(wall-clock time)
包括:
- CPU 处理时间
- I/O 时间
- 操作系统开销
- 等待时间
- 空闲时间等
作用:
- 反映整个系统层面的真实完成时间
CPU Time
定义:
- CPU 真正用于处理该任务的时间
不包括:
- I/O 等待时间
- 其他程序占用 CPU 的时间
通常又可以分为:
- User CPU time:程序本身使用 CPU 的时间
- System CPU time:操作系统为该程序服务所花的 CPU 时间
Quantitative Approaches
- CPU Performance Formula
- Amdahl’s Law
目标是回答两类问题:
- 一个程序为什么快/慢?
- 某种改进到底能带来多大性能提升?
CPU Performance Formula
数据大小的基本单位
- bit:二进制位
- nibble:4 bits
- byte:8 bits
- word:字长
- 在很多嵌入式/移动处理器中常为 4 bytes(32 bits)
- 在很多桌面机/服务器中常为 8 bytes(64 bits)
二进制容量单位
- KiB = bytes = 1024 bytes
- MiB = bytes
- GiB = bytes
- TiB = bytes
- PiB = bytes
注意:
KiB / MiB / GiB 是二进制单位;
KB / MB / GB 在工程中有时按十进制使用,需根据具体语境区分。
CPU 性能的基本公式
CPU 执行时间可表示为:
也可写成:
其中:
- CPU Clock Cycles:程序执行所需总时钟周期数
- Clock Cycle Time:时钟周期长度
- Clock Rate:时钟频率,满足
Clock 的概念
Clock Period
一个时钟周期持续的时间,即:
例如:
Clock Frequency / Clock Rate
单位时间内的时钟周期数,即频率:
例如:
如何提升 CPU 性能
由
可知,提升性能(即减少 CPU Time)的方法有两种:
- 减少 Clock Cycles
- 减小 Clock Cycle Time(等价于提高 Clock Rate)
TIP硬件设计中常常存在 trade-off:
- 更高的时钟频率,可能会导致更多的时钟周期
- 更少的时钟周期,可能要求更复杂的设计,从而限制频率提升
所以不能只看一个指标,必须综合分析。
CPU Time Example
- Computer A: 2GHz clock, 10s CPU time
- 设计 Computer B
- 目标 CPU time = 6s
- 但新设计会使所需 clock cycles 变为 A 的 1.2 倍
问:Computer B 的时钟频率至少应为多少?
NOTE先求 A 的总时钟周期数:
由于 B 需要 1.2 倍周期数:
又因为:
所以:
Computer B 至少需要 4GHz 时钟频率。
Instruction Count 与 CPI
为了进一步拆解 CPU 时间,引入两个核心概念:
Instruction Count(IC)
程序执行过程中实际执行的指令总数。
Instruction Count 由以下因素决定:
- 程序本身
- ISA(指令集体系结构)
- 编译器
CPI(Cycles Per Instruction)
平均每条指令需要的时钟周期数:
CPI 主要由 CPU 硬件实现 决定。
CPU 性能公式的完整展开
由
可得:
或者写成:
CPU Performance 的三个核心因素
CPU 执行时间由三个因素共同决定:
- Instruction Count
- CPI
- Clock Cycle Time(或 Clock Rate)
即:
- IC:程序需要多少条指令
- CPI:每条指令平均花多少周期
- Clock Cycle Time:每个周期有多长
分析 CPU 性能时,不能只看单一指标,比如:
- 时钟频率高,不一定更快
- CPI 低,不一定更快
- Instruction Count 少,也不一定更快
必须综合比较三者。
平均 CPI(加权平均)
平均 CPI 不是简单平均,而是按指令占比加权:
其中:
表示第 类指令在程序中的相对频率。
Amdahl’s Law
Amdahl 定律用于分析:
对系统某一部分进行加速后,整体性能最多能提升多少。
公式为:
其中:
- :原执行时间中,可被改进部分所占比例
- :该部分本身被加速的倍数
若程序中只有一部分能受益于优化,那么整体加速比一定受限。
即使局部提速很多倍,整体提升也不可能无限大。
Amdahl 定律体现了一个核心思想:
系统性能瓶颈往往由“没有被优化的那部分”决定。
因此体系结构设计中要特别重视:
- 找到主要瓶颈
- 优先优化最常用、最耗时的部分